

In dieser umfangreichen Anleitung wird Folgendes behandelt:
- Die besten C#-Bibliotheken für Web Scraping
- Voraussetzungen
- Scraping von statischen Websites in C#
- Scraping von dynamischen Websites in C#
- Umgang mit den gescrapten Daten
- Datenschutz mit Proxys
- Fazit
Die besten C#-Bibliotheken für Web Scraping
Web Scraping lässt sich mit den richtigen Tools wesentlich einfacher gestalten. Sehen wir uns daher die besten NuGet-Scraping-Bibliotheken für C# an:
HtmlAgilityPack: die beliebteste C#-Scraper-Bibliothek.HtmlAgilityPackermöglicht den Download von Webseiten, das Parsen ihrer HTML-Inhalte, die Auswahl von HTML-Elementen und das Scrapen von Daten aus diesen Seiten.HttpClient: der beliebteste C#-HTTP-Client.HttpClientist vor allem für das Web Crawling nützlich, da HTTP-Anfragen damit einfach und asynchron durchgeführt werden können.Selenium WebDriverist eine Bibliothek, die mehrere Programmiersprachen unterstützt und das Schreiben automatisierter Tests für Webanwendungen ermöglicht. Außerdem kann sie zum Web Scraping verwendet werden.Puppeteer Sharpist die C#-Portierung von Puppeteer. Puppeteer Sharp verfügt über Funktionen als Headless Browser und ermöglicht das Scraping von Seiten mit dynamischen Inhalten.
In diesem Tutorial lernen Sie, wie das Web Scraping mit C# sowie HtmlAgilityPack und Selenium funktioniert.
Voraussetzungen für Web Scraping mit C#
Bevor Sie die erste Codezeile Ihres C#-Web-Scrapers schreiben, müssen einige Voraussetzungen erfüllt sein:
- Visual Studio: Die kostenlose Community Edition von Visual Studio 2022 ist ausreichend.
- .NET 6+: Alle LTS-Versionen ab Version 6 sind ausreichend.
Falls eine dieser Voraussetzungen nicht erfüllt ist, klicken Sie auf den obigen Link, um die Tools herunterzuladen, und befolgen Sie zur Einrichtung die Anweisungen des Installationsassistenten.
Nun ist alles bereit, um ein C#-Web-Scraping-Projekt in Visual Studio zu erstellen.
Einrichten eines Projekts in Visual Studio
Öffnen Sie Visual Studio und klicken Sie auf die Option „Neues Projekt erstellen“.

Wählen Sie im Dialogfeld „Neues Projekt erstellen“ aus der Dropdown-Liste die Option „C#“ aus. Nach Festlegung der Programmiersprache wählen Sie die Vorlage „Konsolen-App“ und klicken Sie dann auf „Weiter“.

Geben Sie dann Ihrem Projekt den Namen StaticWebScraping, klicken Sie auf „Auswählen“ und wählen Sie die .NET-Version aus. Falls Sie .NET 6.0 installiert haben, sollte Visual Studio diese Version automatisch für Sie auswählen.

Klicken Sie auf die Schaltfläche „Erstellen“, um Ihr C#-Web-Scraping-Projekt zu initialisieren. Visual Studio initialisiert einen StaticWebScraping-Ordner, der eine App.cs-Datei für Sie enthält. In dieser Datei wird Ihre Web-Scraping-Logik in C# gespeichert:
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
Als nächstes möchten wir Ihnen erklären, wie Sie einen Web Scraper in C# erstellen können!
Scraping von statischen Websites in C#
Bei Websites mit statischen Inhalten ist der Inhalt der Webseiten bereits in den vom Server gelieferten HTML-Dokumenten gespeichert. Dies bedeutet, dass eine statische Webseite keine XHR-Anfragen zum Abrufen von Daten durchführt oder JavaScript zum Rendern benötigt.
Das Scraping statischer Webseiten ist recht einfach. Es ist lediglich Folgendes zu tun:
- Installieren Sie eine C#-Bibliothek für das Web Scraping
- Laden Sie Ihre Zielwebseite herunter und parsen Sie deren HTML-Dokument
- Verwenden Sie eine Web-Scraping-Bibliothek, um die relevanten HTML-Elemente auszuwählen
- Extrahieren von Daten aus diesen Elementen
Nun wollen wir die genannten Schritte auf die Wikipedia-Seite mit der „Liste der Episoden von SpongeBob Schwammkopf“ anwenden:

Der C#-Web-Scraper, den Sie gleich erstellen werden, soll automatisch sämtliche Episodendaten dieser statischen Wikipedia-Seite abrufen.
Legen wir los!
Schritt 1: Installieren des HtmlAgilityPack
HtmlAgilityPack ist eine Open-Source-C#-Bibliothek, die es ermöglicht, HTML-Dokumente zu parsen, Elemente aus dem DOM auszuwählen und Daten daraus zu extrahieren. Somit bietet HtmlAgilityPack grundsätzlich alles, was Sie zum Scrapen einer Website mit statischem Inhalt benötigen.
Zur Installation klicken Sie im „Solution Explorer“ mit der rechten Maustaste unter Ihrem Projektnamen auf die Option „Abhängigkeiten“. Wählen Sie anschließend „NuGet-Pakete verwalten“. Suchen Sie im Fenster des NuGet-Paketmanagers nach „HtmlAgilityPack“ und klicken Sie dann auf die Schaltfläche „Installieren“ im rechten Bereich des Bildschirms.

In einem Dialogfenster werden Sie gefragt, ob Sie mit den Änderungen an Ihrem Projekt einverstanden sind. Klicken Sie auf „OK“, um HtmlAgilityPack zu installieren. Damit sind Sie zum Web Scraping in C# auf einer statischen Website bereit.
Fügen Sie nun die folgende Zeile oben in Ihre App.cs-Datei ein, um HtmlAgilityPack zu importieren:
using HtmlAgilityPack;Schritt 2: Laden einer HTML-Webseite
Die Verbindung zur Zielwebseite kann mit HtmlAgilityPack wie folgt hergestellt werden:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
Die Instanz der Klasse HtmlWeb ermöglicht es dank ihrer Methode Load(), eine Webseite zu laden. Diese Methode führt im Hintergrund eine HTTP-GET-Anfrage zum Abrufen des HTML-Dokuments durch, das mit der als Parameter übermittelten URL verknüpft ist. Daraufhin gibt Load() eine Instanz HtmlAgilityPack HtmlDocument aus, die Sie zur Auswahl von HTML-Elementen auf der Seite verwenden können.
Schritt 3: Auswahl der HTML-Elemente
Mithilfe von XPath-Selektoren können Sie HTML-Elemente auf einer Webseite auswählen. Im Einzelnen erlaubt XPath die Auswahl von einem oder mehreren spezifischen DOM-Elementen. Um den XPath-Selektor für ein HTML-Element zu erhalten, klicken Sie mit der rechten Maustaste darauf, öffnen Sie die Browsertools unter der Option „Untersuchen“, vergewissern Sie sich, dass das gewünschte DOM-Element ausgewählt ist, klicken Sie mit der rechten Maustaste auf das betreffende DOM-Element und wählen Sie „XPath kopieren“.
Das Ziel des Web Scrapers in C# besteht in der Extraktion der mit jeder einzelnen Episode verknüpften Daten. Extrahieren Sie dafür den XPath-Selektor, indem Sie das oben beschriebene Verfahren auf ein <tr>-Episodenelement anwenden.

Das Ergebnis sieht folgendermaßen aus:
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
Achten Sie darauf, alle <tr>-Elemente auszuwählen. Dazu müssen Sie den mit dem Element „Zeile auswählen“ verknüpften Index ändern. Die erste Zeile der Tabelle soll nicht extrahiert werden, da sie lediglich Tabellenüberschriften enthält. In XPath beginnen die Indizes bei 1. Sie können also alle <tr>-Elemente der ersten Episodentabelle auf der Seite auswählen, indem Sie die XPath-Syntax position()>1 hinzufügen.
Ferner sollen Daten aus den Tabellen aller Staffeln abgerufen werden. Die Wikipedia-Seite enthält Tabellen mit Episodendaten, die von der zweiten bis zur fünfzehnten HTML-Tabelle im HTML-Dokument reichen. Der endgültige XPath-String sieht demnach folgendermaßen aus:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Nun können Sie mithilfe der von HtmlAgilityPack bereitgestellten Methode SelectNodes() die relevanten HTML-Elemente wie folgt auswählen:
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");Bitte beachten Sie, dass Sie die Methode SelectNodes() nur für eine HtmlNode-Instanz aufrufen können. Sie müssen daher den HTML-Stammknoten des HTML-Dokuments mit der Eigenschaft DocumentNode ermitteln.
Bedenken Sie außerdem, dass XPath-Selektoren nur eine von vielen Methoden zur Auswahl von HTML-Elementen auf einer Webseite sind. CSS-Selektoren gehören in dieser Hinsicht zu den beliebten Alternativen.
Schritt 4: Extrahieren von Daten aus HTML-Elementen
Zunächst benötigen Sie eine benutzerdefinierte Klasse, in der die gescrapten Daten gespeichert werden. Erstellen Sie eine Episode.cs-Datei im Ordner WebScraping und initialisieren Sie diese wie folgt:
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
Wie Sie sehen, besitzt diese Klasse vier Attribute zur Speicherung der wichtigsten Informationen, die zu einer Episode gesammelt werden. Man beachte, dass OverallNumber ein String ist, da die Episodennummer von SpongeBob stets ein Zeichen enthält.
Jetzt können Sie die C#-Logik zum Web Scraping wie unten beschrieben in Ihrer App.cs-Datei implementieren:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
// selecting the HTML nodes of interest
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new List<Episode>();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
Title = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
Directors = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Dieser C#-Web-Scraper durchläuft eine Schleife über die ausgewählten HTML-Knoten, erstellt für jeden von ihnen eine Instanz der Klasse Episode und speichert diese in der Liste episodes. Berücksichtigen Sie in diesem Zusammenhang, dass die relevanten HTML-Knoten Zeilen einer Tabelle sind. Sie müssen daher einige Elemente mit der Methode SelectSingleNode() auswählen. Verwenden Sie anschließend das Attribut InnerText, um die gewünschten Daten zu extrahieren, die daraus ausgelesen werden sollen. Man beachte die Verwendung der statischen Funktion HtmlEntity.DeEntitize(), um die HTML-Sonderzeichen durch ihre natürlichen Repräsentationen zu ersetzen.
Schritt 5: Export der gescrapten Daten in CSV
Nachdem Sie gelernt haben, wie das Web Scraping in C# funktioniert, können Sie die gescrapten Daten nach Belieben weiterverarbeiten. Eine der häufigsten Vorgehensweisen ist die Konvertierung der gescrapten Daten in ein von Menschen lesbares Format (z. B. CSV). Dadurch kann jeder in Ihrem Team die gescrapten Daten direkt in Excel einsehen.
Im Folgenden erfahren Sie, wie Sie mit C# gescrapte Daten in CSV exportieren können.
Um das Ganze einfacher zu gestalten, verwenden wir eine Bibliothek. CSVHelper ist eine schnelle, einfach zu bedienende und leistungsstarke .NET-Bibliothek zum Lesen und Schreiben von CSV-Dateien. Um die CSVHelper-Abhängigkeit hinzuzufügen, öffnen Sie in Visual Studio den Abschnitt „NuGet-Pakete verwalten“, suchen Sie nach „CSVHelper“ und führen Sie die Installation durch.
Sie können CSVHelper verwenden, um die gescrapten Daten wie unten gezeigt in CSV zu konvertieren:
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// scraping logic…
// initializing the CSV file
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(episodes);
}
Falls Sie mit dem Schlüsselwort using nicht vertraut sind: Dieses definiert einen Bereich, an dessen Ende die darin enthaltenen Objekte verworfen werden. using bietet sich daher für den Umgang mit Dateiressourcen an. Die CSVHelper-Funktion WriteRecords() sorgt dann für die automatische Konvertierung der gescrapten Daten in CSV und die Speicherung in der Datei output.csv.
Sobald Ihr C#-Web-Scraper läuft, erscheint im Stammverzeichnis des Projekts die Datei output.csv. Wenn Sie diese in Excel öffnen, sehen Sie folgende Daten:
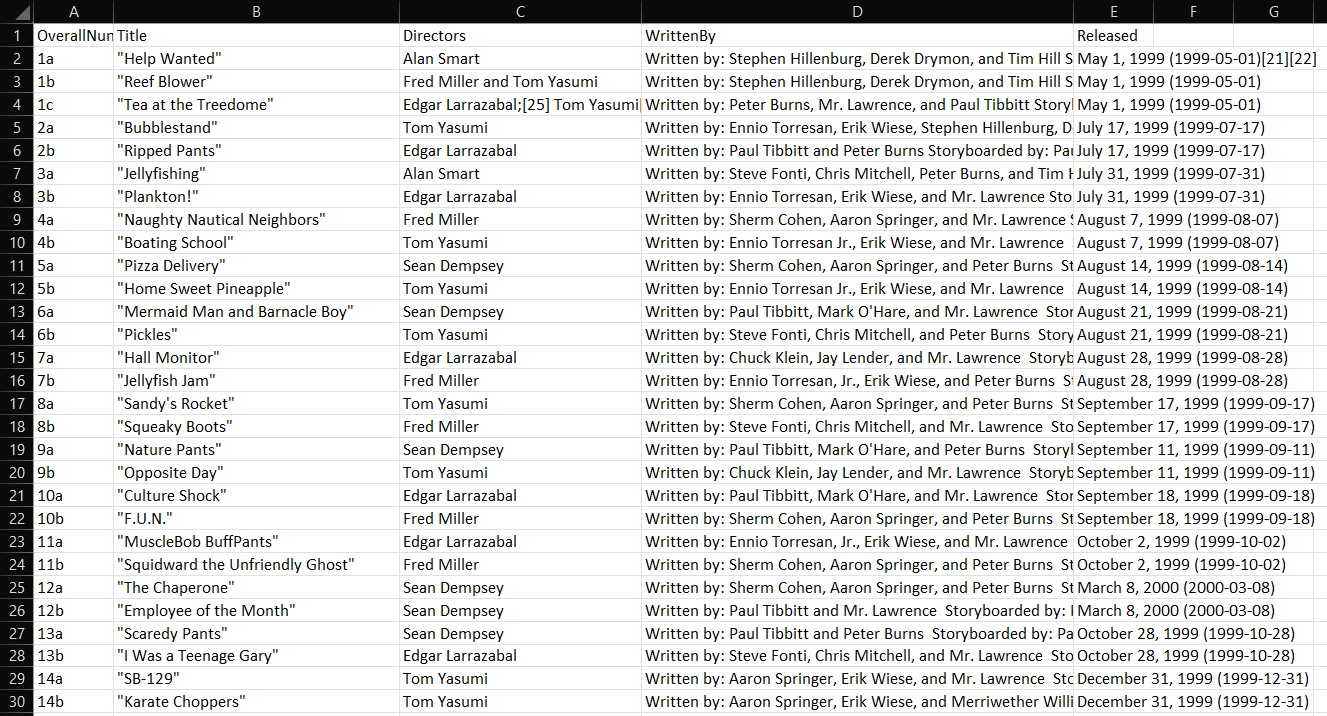
Et voilà! Jetzt wissen Sie, wie das Web Scraping mit C# auf statischen Websites funktioniert!
Scraping von dynamischen Websites in C#
Websites mit dynamischen Inhalten verwenden JavaScript, um Daten mithilfe der AJAX-Technologie dynamisch abzurufen. Die mit dynamischen Seiten verbundenen HTML-Dokumente können grundsätzlich leer sein. Gleichzeitig enthalten sie JavaScript-Skripte, die für den dynamischen Abruf und die Darstellung von Daten zum Zeitpunkt des Renderings sorgen. Wenn Sie also Daten daraus extrahieren wollen, benötigen Sie einen Browser zum Rendern der Seiten. Das liegt daran, dass nur ein Browser JavaScript ausführen kann.
Das Scraping dynamischer Websites kann sich als knifflig erweisen und ist definitiv schwieriger als das Scraping statischer Websites. Zum Scrapen solcher Websites benötigen Sie einen Headless Browser. Falls Sie mit dieser Technologie nicht vertraut sind: Ein Headless Browser ist ein Browser ohne grafische Benutzeroberfläche. Wenn Sie also Websites mit dynamischen Inhalten in C# scrapen möchten, ist eine Bibliothek mit Funktionen eines Headless Browsers erforderlich (wie z. B. Selenium).
Befolgen Sie zur Einrichtung eines neuen C#-Projekts die Anweisungen im Abschnitt am Anfang dieses Artikels. Geben Sie dem Projekt dieses Mal den Namen DynamicWebScraping.
Schritt 1: Selenium installieren
Selenium ist ein Open-Source-Framework für automatisierte Tests, welches mehrere Programmiersprachen unterstützt. Selenium kann als Headless Browser eingesetzt werden und ermöglicht es Ihnen, einen Webbrowser zur Ausführung bestimmter Aktionen anzuweisen.
Um Selenium zu den Abhängigkeiten Ihres Projekts hinzuzufügen, gehen Sie erneut zum Abschnitt „NuGet-Pakete verwalten“, suchen Sie nach „Selenium.WebDriver“ und führen Sie die Installation durch.
Importieren Sie Selenium, indem Sie die folgenden zwei Zeilen am Anfang Ihrer App.cs-Datei hinzufügen:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Schritt 2: Verbinden mit der Zielwebsite
Da Selenium die Zielwebsite in einem Browser öffnet, muss keine manuelle HTTP-GET-Anforderung durchgeführt werden. Sie müssen lediglich den Selenium WebDriver wie folgt verwenden:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
Hier haben Sie eine WebDriver-Instanz für Chrome erstellt. Bei Verwendung eines anderen Browsers ist der Code durch Verwendung des richtigen Browsertreibers entsprechend anzupassen. Anschließend können Sie dank der Navigate()-Methode der Variable driver die Methode GoToUrl() aufrufen, um eine Verbindung mit der Zielwebseite herzustellen. Diese Funktion erkennt einen URL-Parameter und verwendet diesen, um die mit der URL verknüpfte Webseite im Headless Browser aufzurufen.
Schritt 3: Scrapen von Daten aus HTML-Elementen
Wie zuvor beschrieben, können Sie folgenden XPath-Selektor verwenden, um die relevanten HTML-Elemente auszuwählen:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Verwenden Sie einen XPath-Selektor in Selenium mit:
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
Konkret ermöglicht die Selenium-Methode By.XPath() die Anwendung einer XPath-Zeichenkette, um HTML-Elemente aus dem DOM der Seite auszuwählen.
Nehmen wir an, Sie haben bereits eine Klasse Episode.cs innerhalb des Namespace DynamicWebScraping definiert. Dann können Sie jetzt einen C#-Web-Scraper mit Selenium wie nachfolgend beschrieben erstellen:
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
// selecting the HTML nodes of interest
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Wie man sieht, hat sich die Web-Scraping-Logik im Vergleich zu den Schritten mit HtmlAgilityPack nicht wesentlich verändert. Dank der Selenium-Methoden FindElements() und FindElement() können Sie dasselbe Scraping-Ziel erreichen. Der wesentliche Unterschied besteht darin, dass Selenium alle diese Vorgänge in einem Browser ausführt.
Beachten Sie, dass Sie bei dynamischen Websites möglicherweise warten müssen, bis die Daten abgerufen und gerendert werden. Erreicht werden kann dies mit WebDriverWait.
Herzlichen Glückwunsch! Sie wissen nun, wie das Web Scraping mit C# auf dynamischen Websites funktioniert. Jetzt müssen Sie nur noch entscheiden, was mit den gescrapten Daten geschehen soll.
Umgang mit den gescrapten Daten
- Speicherung in einer Datenbank, um sie bei Bedarf abfragen zu können.
- Konvertierung in JSON und Verwendung zum Aufrufen einiger APIs.
- Umwandlung in von Menschen lesbare Formate (z. B. CSV), um die Daten mit Excel öffnen zu können.
Dies sind nur einige Beispiele. Entscheidend ist, dass Sie die gescrapten Daten, sobald Sie Ihnen im Code vorliegen, ganz nach Belieben verwenden können. In der Regel werden die gescrapten Daten für das Team in den Bereichen Marketing, Datenanalyse oder Vertrieb in ein nützlicheres Format umgewandelt.
Bedenken Sie dabei aber, dass Web Scraping einige Herausforderungen birgt!
Datenschutz mit Proxys
Um die Offenlegung Ihrer IP-Adresse zu vermeiden, nicht blockiert zu werden und Ihre Identität zu schützen, sollten Sie den Einsatz von Web-Scraping-Proxys in Betracht ziehen. Ein Proxy-Server fungiert als Gateway zwischen Ihrer Anwendung und dem Server der Zielwebsite und verschleiert somit Ihre IP-Adresse.
Folglich ermöglicht ein Proxy-Dienst die Umgehung von IP-Sperren, die anonyme Datenerfassung und die Freischaltung von Inhalten in allen Ländern. Es gibt verschiedene Arten von Proxys, die allesamt unterschiedliche Einsatzmöglichkeiten und Zwecke haben. Achten Sie auf die Auswahl des richtigen Proxy-Anbieters.
Lassen Sie uns als nächstes die Vorteile von Web-Proxys für Ihr Web Scraping näher betrachten.
Umgehen von IP-Sperren
Wenn Ihre Web-Scraping-Anwendung versucht, eine Website im Internet zu erreichen, ist die IP-Adresse, die die Anfrage übermittelt, öffentlich. Dadurch können Websites dies nachverfolgen und Benutzer, die zu viele Anfragen stellen, blockieren. Genau darum geht es bei der Bot-Erkennung. Bei Verwendung eines Web-Proxys wird dem Zielserver anstelle Ihrer IP die IP des rotierenden Proxys angezeigt. Mithilfe von Proxys können Sie also IP-Sperren leicht umgehen.
Rotierende IP-Adressen
Premium-Proxys bieten in der Regel die Funktion rotierender IPs. Dies bedeutet, dass Ihnen bei jedem Kontakt mit dem Proxy-Server eine neue IP-Adresse aus einem umfangreichen Pool von IPs zugewiesen wird. Damit können Sie verhindern, dass Anti-Scraping-Systeme Sie aufspüren.
Regionales Scraping
Viele Websites passen die angezeigten Informationen je nachdem, woher die Anfrage kommt, an. Darüber hinaus sind einige Websites nur in bestimmten Regionen verfügbar. Das Scraping dieser Websites mit dem Ziel der weltweiten Marktforschung kann sich daher als problematisch erweisen. Bei der Verwendung anonymer Proxys können Sie jedoch glücklicherweise den Standort der Ausgangs-IP-Adresse auswählen. So können Sie auch auf Websites mit internationaler Ausrichtung wertvolle Informationen über Produkte sammeln.
Fazit
In diesem Tutorial haben Sie gelernt, wie man einen Web Scraper mit C# erstellt. Wie Sie festgestellt haben, sind dafür nicht allzu viele Codezeilen erforderlich. Wenn sich Ihre Zielwebseiten ändern, dürfen Sie allerdings nicht vergessen, den Scraper entsprechend zu aktualisieren. Da einige Websites täglich Änderungen an ihrer Struktur vornehmen, empfehlen wir, eine fortschrittliche Web Scraper IDE zu verwenden. Die Scraper von Bright Data sind stets auf dem neuesten Stand, sodass Sie sich auf die Daten konzentrieren können und Ihren Scraper nicht ständig aufs Neue konfigurieren müssen.




