

Da die Datenmenge im Internet ständig wächst, wird das Web-Crawling, also das automatische Durchsuchen und Extrahieren von Informationen aus Websites, für Entwickler zu einer immer wichtigeren Fähigkeit. Dazu werden HTTP-Anfragen an Webserver gesendet und das Parsing der HTML-Antworten durchgeführt, um die gewünschten Daten zu extrahieren.
Der Prozess des Web Crawling kann komplex und zeitaufwändig sein, jedoch können die richtigen Tools und Techniken dabei helfen. Aufgrund seiner Flexibilität und Benutzerfreundlichkeit hat sich Python zu einer beliebten Sprache für die Erstellung von Web Crawlern entwickelt, mit der Entwickler schnell Skripte schreiben können, um den Datenextraktionsprozess zu automatisieren.
In diesem Artikel erfahren Sie alles über das Web Crawling mit Python unter Verwendung der Scrapy-Bibliothek.
Warum Sie Web-Crawling benötigen
Bevor wir uns mit dem Tutorial befassen, ist es wichtig, den Unterschied zwischen Web-Scraping und Web-Crawling zu kennen. Obwohl beide Verfahren ähnlich sind, extrahiert Web-Scraping bestimmte Daten aus Webseiten, während Web-Crawling Webseiten zum Indizieren durchsucht und Informationen für Suchmaschinen sammelt.
Web Crawling ist in allen möglichen Szenarien nützlich, darunter die folgenden:
- Datenextraktion: Web Crawling kann verwendet werden, um bestimmte Daten aus Websites zu extrahieren, die dann für Analysen oder Recherchen verwendet werden können.
- Website-Indizierung: Suchmaschinen verwenden häufig Web Crawling, um Websites zu indizieren und für Benutzer durchsuchbar zu machen.
- Überwachung: Web Crawling kann verwendet werden, um Websites auf Änderungen oder Aktualisierungen zu überwachen. Diese Informationen sind oft nützlich, um Wettbewerber zu verfolgen.
- Inhaltsaggregation: Web Crawling kann verwendet werden, um Inhalte von mehreren Websites zu sammeln und an einem einzigen Ort zu aggregieren, um den Zugriff zu erleichtern.
- Sicherheitstests: Web Crawling kann für Sicherheitstests verwendet werden, um Schwachstellen oder Schwächen in Websites und Webanwendungen zu identifizieren.
Web-Crawling mit Python
Python ist aufgrund seiner einfachen Programmierung und intuitiven Syntax eine beliebte Wahl für das Web-Crawling. Darüber hinaus basiert Scrapy, eines der beliebtesten Web-Crawling-Frameworks, auf Python. Dieses leistungsstarke und flexible Framework macht es einfach, Daten aus Websites zu extrahieren, Links zu verfolgen und die Ergebnisse zu speichern.
Scrapy ist für die Verarbeitung großer Datenmengen ausgelegt und kann für eine Vielzahl von Web-Scraping-Aufgaben eingesetzt werden. Die in Scrapy enthaltenen Tools, wie der HTTP-Downloader, der Spider zum Crawlen von Websites, der Scheduler zur Verwaltung der Crawling-Häufigkeit und die Item-Pipeline zur Verarbeitung der gescrapten Daten, machen es für verschiedene Web-Crawling-Aufgaben bestens geeignet.
Um mit dem Web-Crawling mit Python zu beginnen, müssen Sie das Scrapy-Framework auf Ihrem System installieren.
Öffnen Sie Ihr Terminal und führen Sie den folgenden Befehl aus:
pip install scrapyn
Nach Ausführung dieses Befehls ist Scrapy auf Ihrem System installiert. Scrapy stellt Ihnen Klassen namens Spiders zur Verfügung, die definieren, wie eine Web-Crawling-Aufgabe ausgeführt wird. Diese Spiders sind für die Navigation auf der Website, das Senden von Anfragen und das Extrahieren von Daten aus dem HTML-Code der Website verantwortlich.
Erstellen eines Scrapy-Projekts
In diesem Artikel werden Sie eine Website namens „Books to Scrape” crawlen und den Namen, die Kategorie und den Preis jedes Buches in einer CSV-Datei speichern. Diese Website wurde als Sandbox für Scraping-Projekte erstellt.
Sobald Scrapy installiert ist, müssen Sie mit dem folgenden Befehl eine neue Projektstruktur erstellen:
scrapy startproject bookcrawlern
(Hinweis: Wenn Sie die Fehlermeldung „Befehl nicht gefunden” erhalten, starten Sie Ihr Terminal neu.
Die Standardverzeichnisstruktur bietet einen klaren und übersichtlichen Rahmen mit separaten Dateien und Verzeichnissen für jede Komponente des Web-Scraping-Prozesses. Dies erleichtert das Schreiben, Testen und Warten Ihres Spider-Codes sowie die Verarbeitung und Speicherung der extrahierten Daten nach Ihren Wünschen. So sieht Ihre Verzeichnisstruktur aus:
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
Um den Crawling-Prozess in Ihrem Scrapy-Projekt zu starten, müssen Sie eine neue Spider-Datei im Verzeichnis bookcrawler/spiders erstellen, da dies das Standardverzeichnis ist, in dem Scrapy nach Spiders sucht, um den Code auszuführen. Navigieren Sie dazu zum Verzeichnis bookcrawler/spiders und erstellen Sie eine neue Datei mit dem Namen bookspider.py. Schreiben Sie dann den folgenden Code in die Datei, um Ihren Spider zu definieren und sein Verhalten festzulegen:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
Dieser Code definiert einen BookCrawler, der eine Unterklasse des integrierten CrawlSpider ist und eine bequeme Möglichkeit bietet, Regeln für das Verfolgen von Links und das Extrahieren von Daten zu definieren. Das Attribut start_urls gibt eine Liste von URLs an, von denen aus das Crawling gestartet werden soll. In diesem Fall enthält es nur eine URL, nämlich die Startseite der Website.
Das Attribut rules gibt eine Reihe von Regeln an, um zu bestimmen, welchen Links der Spider folgen soll. In diesem Fall ist nur eine Regel definiert, die mit der Klasse Rule aus dem Modul scrapy.spiders erstellt wurde. Die Regel wird mit einer LinkExtractor-Instanz definiert, die das Muster der Links angibt, denen der Spider folgen soll. Der Parameter allow des LinkExtractor ist auf /catalogue/category/books/ gesetzt, was bedeutet, dass der Spider nur Links folgen soll, die diese Zeichenfolge in ihrer URL enthalten.
Um den Spider auszuführen, öffnen Sie Ihr Terminal und führen Sie den folgenden Befehl aus:
scrapy crawl bookspidern
Sobald Sie diesen Befehl ausführen, initialisiert Scrapy die Spider-Klasse BookCrawler, erstellt eine Anfrage für jede URL im Attribut start_urls und sendet diese an den Scrapy-Scheduler. Wenn der Scheduler eine Anfrage erhält, überprüft er, ob die Anfrage durch das Attribut allowed_domains (falls angegeben) des Spiders zugelassen ist. Wenn die Domain zulässig ist, wird die Anfrage an den Downloader weitergeleitet, der eine HTTP-Anfrage an den Server sendet und die Antwort abruft.
An dieser Stelle sollten Sie in Ihrem Konsolenfenster alle URLs sehen können, die Ihr Spider gecrawlt hat:
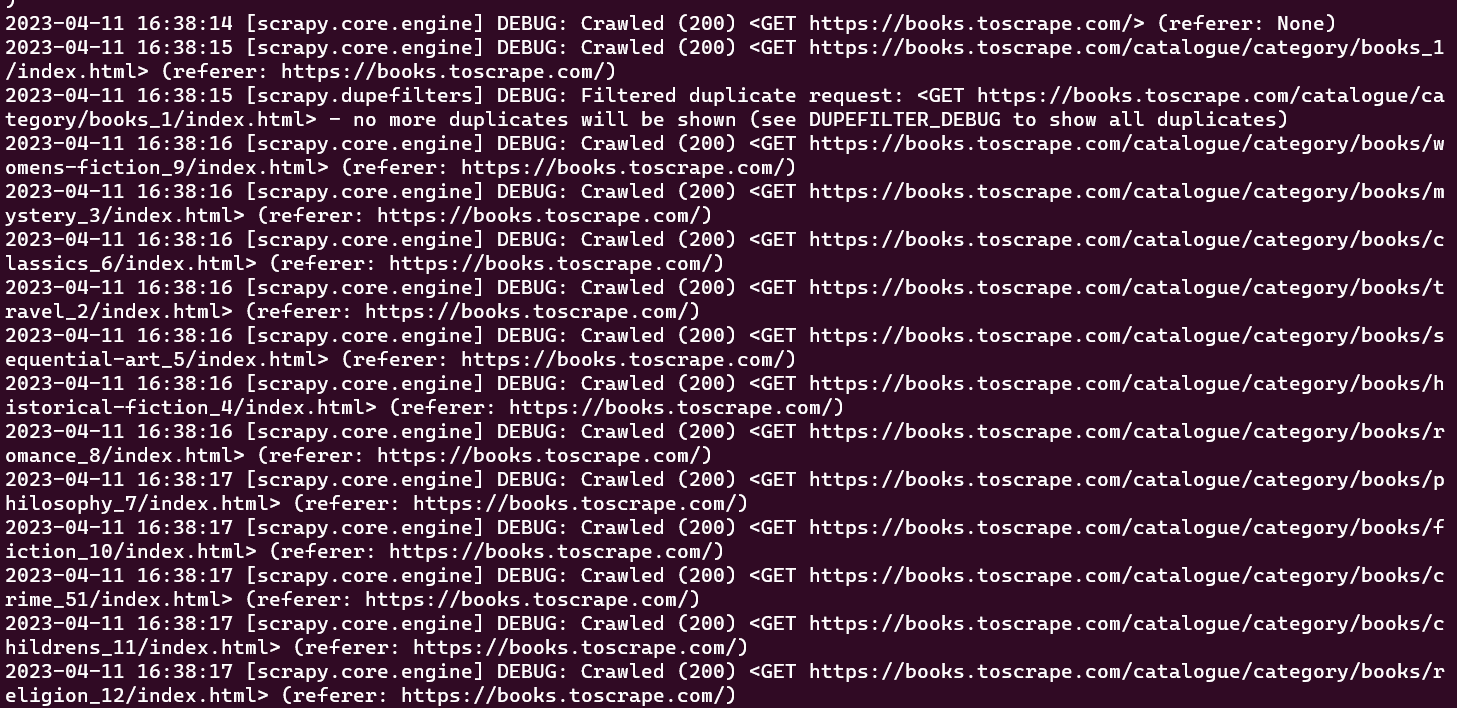
Der ursprünglich erstellte Crawler führt nur die Aufgabe aus, eine vordefinierte Reihe von URLs zu crawlen, ohne Informationen zu extrahieren. Um während des Crawling-Prozesses Daten abzurufen, müssen Sie eine parse_item-Funktion innerhalb der Crawler-Klasse definieren. Die parse_item-Funktion hat die Aufgabe, die Antwort auf jede vom Crawler gestellte Anfrage zu empfangen und relevante Daten aus der Antwort zurückzugeben.
Bitte beachten Sie: Die Funktion
„parse_item”funktioniert nur, nachdem Sie das Attribut„callback”in IhremLinkExtractorfestgelegt haben.
Um Daten aus der Antwort zu extrahieren, die durch das Crawlen von Webseiten in Scrapy erhalten wurde, müssen Sie CSS-Selektoren verwenden. Der nächste Abschnitt enthält eine kurze Einführung in CSS-Selektoren.
Ein wenig über CSS-Selektoren
CSS-Selektoren sind eine Möglichkeit, Daten aus einer Webseite zu extrahieren, indem Tags, Klassen und Attribute angegeben werden. Hier ist beispielsweise eine Scrapy-Shell-Sitzung, die mit scrapy shell books.toscrape.com initialisiert wurde:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003en All products | Books to S...'u003e]n
In dieser Sitzung nimmt die css- Funktion ein Tag (d. h. title) und gibt das Selector- Objekt zurück. Um den Text innerhalb des title- Tags zu erhalten, müssen Sie die folgende Abfrage schreiben:
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
In diesem Ausschnitt wird der Text -Pseudo-Selektor verwendet, um das umgebende Titel -Tag zu entfernen und nur den inneren Text zurückzugeben. Die get- Methode wird verwendet, um nur den Datenwert anzuzeigen.
Um die Klassen der Elemente zu erhalten, müssen Sie den Quellcode der Seite anzeigen, indem Sie mit der rechten Maustaste klicken und „Inspect“ auswählen:
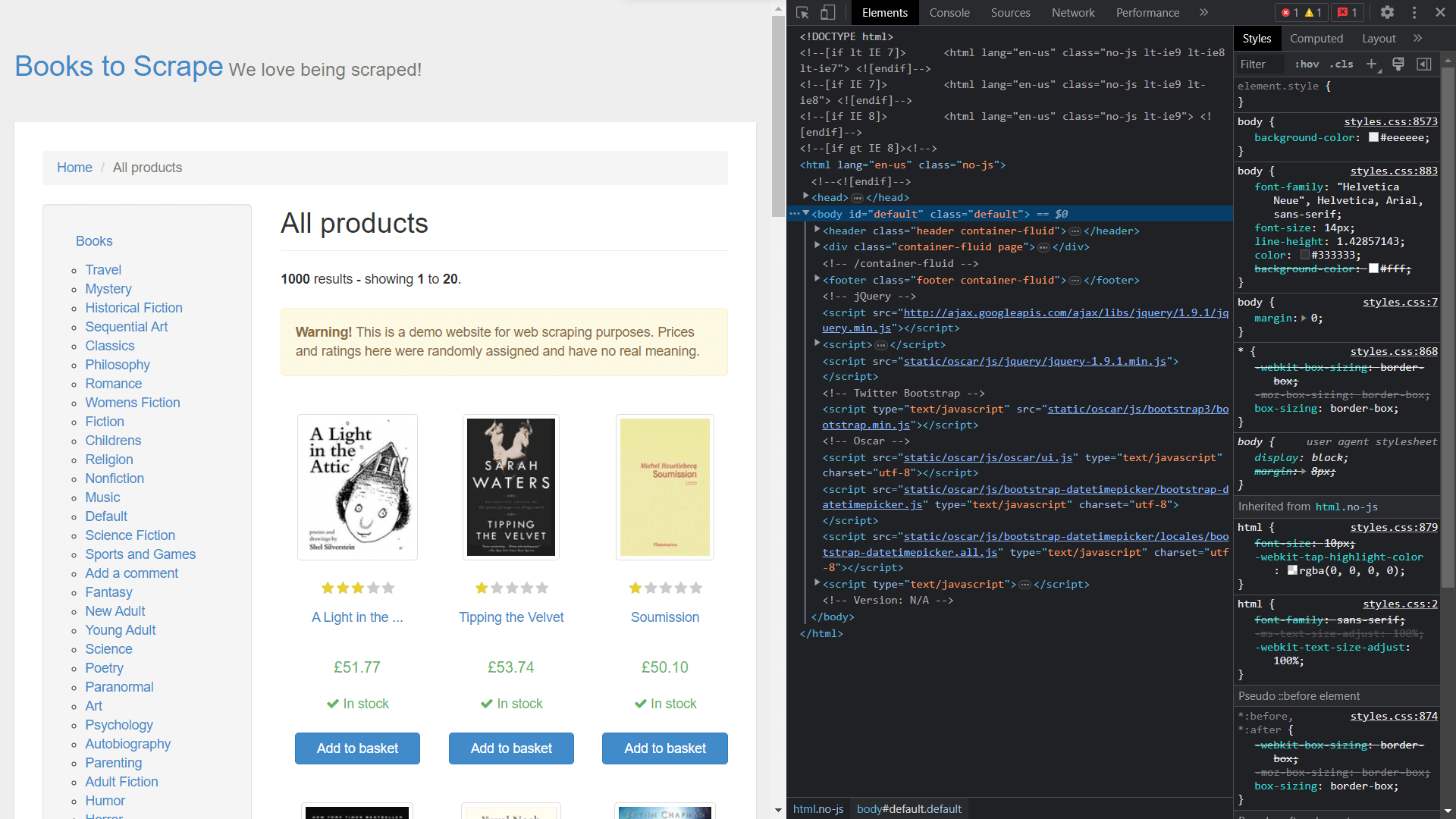
Extrahieren von Daten mit Scrapy
Um Elemente aus dem Antwortobjekt zu extrahieren, müssen Sie eine Callback-Funktion definieren und diese als Attribut in der Rule-Klasse zuweisen.
Öffnen Sie bookspider.py und führen Sie den folgenden Code aus:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
Die Funktion parse_item in der Klasse BookCrawler enthält die Logik für die zu extrahierenden Daten und gibt sie an die Konsole aus. Durch die Verwendung von yield kann Scrapy die Daten in Form von Elementen verarbeiten, die dann zur weiteren Verarbeitung oder Speicherung durch Element-Pipelines geleitet werden können.
Die Auswahl der Kategorie ist eine einfache Aufgabe, da sie in einem einfachen <h1> -Tag codiert ist. Die Auswahl von book_titles erfolgt jedoch über einen mehrstufigen Auswahlprozess, bei dem im ersten Schritt das <article> -Tag mit der Klasse product_pod ausgewählt wird. Anschließend wird der Durchlaufprozess fortgesetzt, um das <a> -Tag zu identifizieren, das innerhalb des <h3> -Tags verschachtelt ist. Der gleiche Ansatz wird bei der Auswahl von book_prices angewendet, wodurch die erforderlichen Informationen von der Webseite abgerufen werden können.
An dieser Stelle haben Sie einen Spider erstellt, der eine Website crawlt und Daten abruft. Um den Spider auszuführen, öffnen Sie das Terminal und führen Sie den folgenden Befehl aus:
scrapy crawl bookspider -o books.jsonn
Nach der Ausführung werden die vom Crawler gecrawlten Webseiten und die entsprechenden Daten auf der Konsole angezeigt. Die Verwendung des Flags -o weist Scrapy an, alle abgerufenen Daten in einer Datei namens books.json zu speichern. Nach Abschluss des Skripts wird im Projektverzeichnis eine neue Datei namens books.json erstellt. Diese Datei enthält alle vom Crawler abgerufenen Daten zu Büchern:
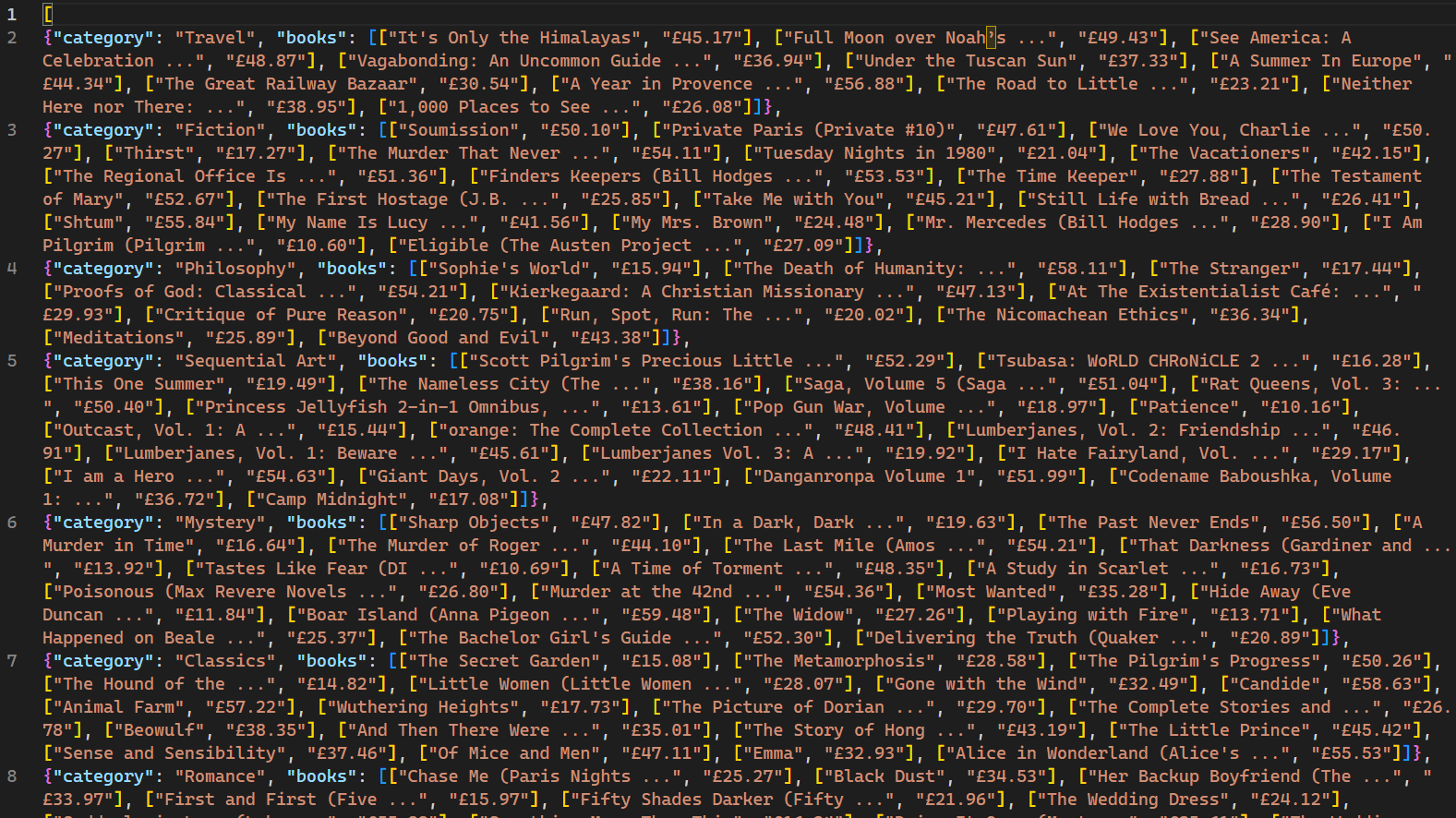
Es ist wichtig zu beachten, dass dieser Web-Crawler nur für Websites effektiv ist, die keine IP-Blockierungsmechanismen als Reaktion auf mehrere Anfragen einsetzen. Für Websites, die weniger offen für Web-Bots und Crawler sind, ist ein Proxy-Dienst wie Bright Data erforderlich, um Daten in großem Umfang zu extrahieren. Die Dienste von Bright Data ermöglichen es Benutzern, Webdaten aus mehreren Quellen zu sammeln und dabei IP-Blockierungen und -Erkennungen zu vermeiden.
Fazit
Web-Crawling in Verbindung mit Web-Scraping ist eine äußerst wertvolle Fähigkeit für die Datenerfassung und Datenwissenschaft. Scrapy, ein für das Web-Crawling entwickeltes Framework, vereinfacht den Prozess durch integrierte Crawler und Scraper.
In diesem Artikel haben Sie gelernt, wie Sie einen Web-Crawler erstellen und dann Daten mit dem Scrapy-Framework scrapen. Sie haben gelernt, wie Sie CrawlSpider für müheloses Web-Crawling verwenden, und Sie haben Konzepte wie Rule und LinkExtractor kennengelernt, um bestimmte Muster von URLs zu crawlen. Darüber hinaus haben Sie die Konzepte der Auswahl von HTML-Elementen mit CSS-Selektoren behandelt. Wenn Sie diese Fähigkeiten beherrschen, sind Sie gut gerüstet, um die Herausforderungen des Web-Crawlings und des Web-Scrapings in der Datenwissenschaft und darüber hinaus zu meistern.






