

Warum Produktdaten von Zalando scrapen?
Zalando ist eine der beliebtesten Online-Plattformen für den Verkauf von Bekleidung in Europa. Mit mehr als 50 Millionen aktiven Nutzern ist es Europas führende E-Commerce-Website für Mode. Es bietet eine riesige Auswahl an Produkten, darunter Schuhe, Kleidung und Accessoires sowohl von etablierten Marken als auch von aufstrebenden Designern.
Die drei wichtigsten Gründe für das Scraping von Produktdaten von Zalando sind:
- Marktforschung: Gewinnen Sie wertvolle Einblicke in aktuelle Modetrends. Diese Informationen helfen Unternehmen, fundierte Entscheidungen zu treffen, wettbewerbsfähig zu bleiben und ihr Angebot effektiv auf die Kundenbedürfnisse abzustimmen.
- Preisüberwachung: Verfolgen Sie Preisschwankungen, um von günstigen Angeboten zu profitieren und den Markt zu studieren.
- Markenbeliebtheit: Konzentrieren Sie sich auf beliebte Produkte bei Zalando, um zu sehen, welche Marken derzeit bei Kunden besonders beliebt sind, und deren Strategie zu analysieren.
Kurz gesagt: Das Scraping von Zalando eröffnet eine Welt voller Möglichkeiten und ist sowohl für Unternehmen als auch für Nutzer von großem Vorteil.
Bibliotheken und Tools für das Scraping von Zalando
Um zu verstehen, welches der vielen verfügbaren Scraping-Tools sich am besten für das Scraping von Zalando eignet, öffnen Sie es in Ihrem Browser. Untersuchen Sie das DOM und vergleichen Sie es mit dem rohen Quellcode. Sie werden feststellen, dass sich die DOM-Struktur geringfügig von dem vom Server erzeugten HTML-Dokument unterscheidet. Das bedeutet, dass die Website für die Darstellung auf JavaScript angewiesen ist. Um eine Website mit dynamischen Inhalten zu scrapen, benötigen Sie ein Tool, das JavaScript ausführen kann, wie z. B. Selenium!
Nun ist die Programmiersprache an der Reihe. Wenn es um Web-Scraping geht, ist Python die beliebteste Sprache. Dank ihrer einfachen Syntax und ihrem reichhaltigen Ökosystem an Bibliotheken eignet sie sich perfekt für unsere Zwecke. Verwenden wir also Python
Bevor Sie beginnen, lesen Sie diese beiden Anleitungen:
- Web-Scraping mit Python – Schritt-für-Schritt-Anleitung
- Scraping dynamischer Websites mit Python
Selenium rendert Websites in einem steuerbaren Webbrowser, den Sie anweisen können, bestimmte Vorgänge auszuführen. Wenn Sie es in Python verwenden, können Sie einen effektiven Zalando-Scraper erstellen. Schauen wir uns an, wie das geht!
Produktdaten von Zalando mit Selenium scrapen
Folgen Sie dieser Schritt-für-Schritt-Anleitung und lernen Sie, wie Sie einen Zalando-Scraper in Python erstellen.
Schritt 1: Einrichten eines Python-Projekts
Bevor Sie mit dem Web-Scraping beginnen, stellen Sie sicher, dass Sie die folgenden Voraussetzungen erfüllen:
- Python 3+ auf Ihrem Rechner installiert: Laden Sie das Installationsprogramm herunter, doppelklicken Sie darauf und folgen Sie den Anweisungen des Installationsassistenten.
- Eine Python-IDE Ihrer Wahl: PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung sind geeignet.
Jetzt haben Sie alles, was Sie zum Einrichten eines Python-Projekts und zum Schreiben von Code benötigen!
Starten Sie das Terminal und führen Sie die folgenden Befehle aus, um:
- Erstellen Sie einen Ordner namens „zalando-Scraper“.
- Öffnen Sie ihn.
- Initialisieren Sie ihn mit einer virtuellen Python-Umgebung.
mkdir zalando-scraper
cd zalando-scraper
python -m venv envUnter Linux oder macOS führen Sie den folgenden Befehl aus, um die Umgebung zu aktivieren:
./env/bin/activate UnterWindows führen Sie Folgendes aus:envScriptsactivate.ps1
Erstellen Sie als Nächstes eine Datei namens scraper.py im Projektordner und fügen Sie die folgende Zeile hinzu:
print("Hello, World!")Dies ist das einfachste Python-Skript, das Sie schreiben können. Im Moment gibt es nur „Hello, World!“ aus, aber bald wird es die Zalando-Scraping-Logik enthalten.
Starten Sie es, um zu überprüfen, ob es funktioniert:
python Scraper.pyIm Terminal sollte folgende Meldung angezeigt werden:
Hallo, Welt!Nachdem Sie sich vergewissert haben, dass das Skript wie erwartet funktioniert, öffnen Sie den Projektordner in Ihrer Python-IDE.
Großartig! Machen Sie sich bereit, die ersten Zeilen Ihres Scrapers zu schreiben.
Schritt 2: Installieren Sie die Scraping-Bibliotheken
Wie bereits erwähnt, ist Selenium das Tool der Wahl für die Erstellung eines Zalando-Scrapers. Führen Sie in der aktivierten virtuellen Python-Umgebung den folgenden Befehl aus, um es zu den Abhängigkeiten des Projekts hinzuzufügen:
pip install seleniumDer Installationsvorgang kann eine Weile dauern, haben Sie also etwas Geduld.
Beachten Sie, dass sich dieses Tutorial auf Selenium 4.13.x bezieht, das über eine automatische Treibererkennungsfunktion verfügt. Wenn Sie eine ältere Version von Selenium auf Ihrem Rechner haben, aktualisieren Sie diese mit:
pip install selenium -UEntfernen Sie den gesamten Inhalt aus scraper.py und initialisieren Sie einen Selenium-Scraper mit:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Richten Sie eine steuerbare Chrome-Instanz ein.
service = Service()
options = webdriver.ChromeOptions()
# Ihre Browser-Optionen...
driver = webdriver.Chrome(
service=service,
options=options
)
# Maximieren Sie das Fenster, um die reaktionsschnelle Darstellung zu vermeiden.
driver.maximize_window()
# Scraping-Logik...
# Schließen Sie den Browser und geben Sie seine Ressourcen frei.
driver.quit()Das obige Skript importiert Selenium und verwendet es, um ein WebDriver-Objekt zu instanziieren. Auf diese Weise können Sie eine Chrome-Browserinstanz programmgesteuert steuern.
Standardmäßig wird das Browserfenster geöffnet und Sie können die auf der Seite ausgeführten Aktionen überwachen. Dies ist bei der Entwicklung nützlich.
Um Chrome im Headless-Modus ohne GUI zu öffnen, konfigurieren Sie die Optionen wie folgt:
options.add_argument('--headless=new')
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')Beachten Sie, dass die zusätzliche Option „user-agent” erforderlich ist, da Zalando Anfragen von Headless-Browsern ohne diesen Header blockiert. Diese Konfiguration ist in der Produktion häufiger anzutreffen.
Großartig! Jetzt ist es an der Zeit, Ihren Web-Scraping-Zalando-Python-Scraper zu erstellen.
Schritt 3: Öffnen Sie die Zielseite
In dieser Anleitung erfahren Sie, wie Sie Detailinformationen zu einem Schuhprodukt von Zalando UK scrapen können. Wenn Sie einen anderen Produkttyp anvisieren, müssen Sie geringfügige Änderungen an dem Skript vornehmen, das Sie erstellen möchten. Der Grund dafür ist, dass jedes Produkt spezifische Seitenstrukturen mit unterschiedlichen Informationen haben kann.
Zum Zeitpunkt der Erstellung dieses Artikels sieht die Zielseite wie folgt aus:
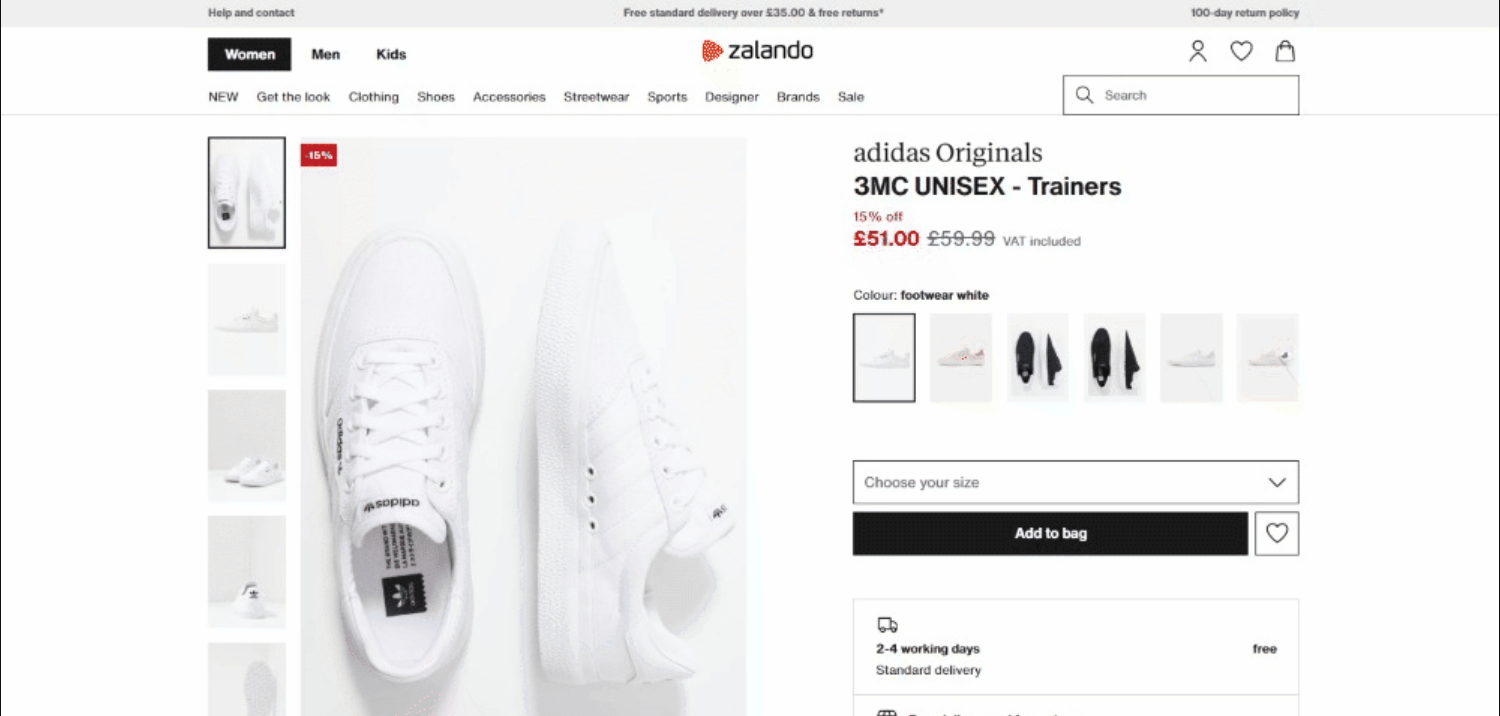
Im Detail lautet die URL der Zielseite:
Verbinden Sie sich in Selenium mit der Zielseite über:
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')get() weist den Browser an, die Seite aufzurufen, die durch die als Parameter übergebene URL angegeben ist.
Dies ist das bisherige Zalando-Scraping-Skript:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service()
# Chrome-Instanz konfigurieren
options = webdriver.ChromeOptions()
# Ihre Browser-Optionen...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximieren Sie das Fenster, um das responsive Rendering zu vermeiden
driver.maximize_window()
# besuchen Sie die Zielseite im kontrollierten Browser
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# Scraping-Logik...
# Schließen Sie den Browser und geben Sie seine Ressourcen frei.
driver.quit()Führen Sie die Anwendung aus. Das untenstehende Fenster wird weniger als eine Sekunde lang geöffnet, bevor die Anwendung beendet wird:
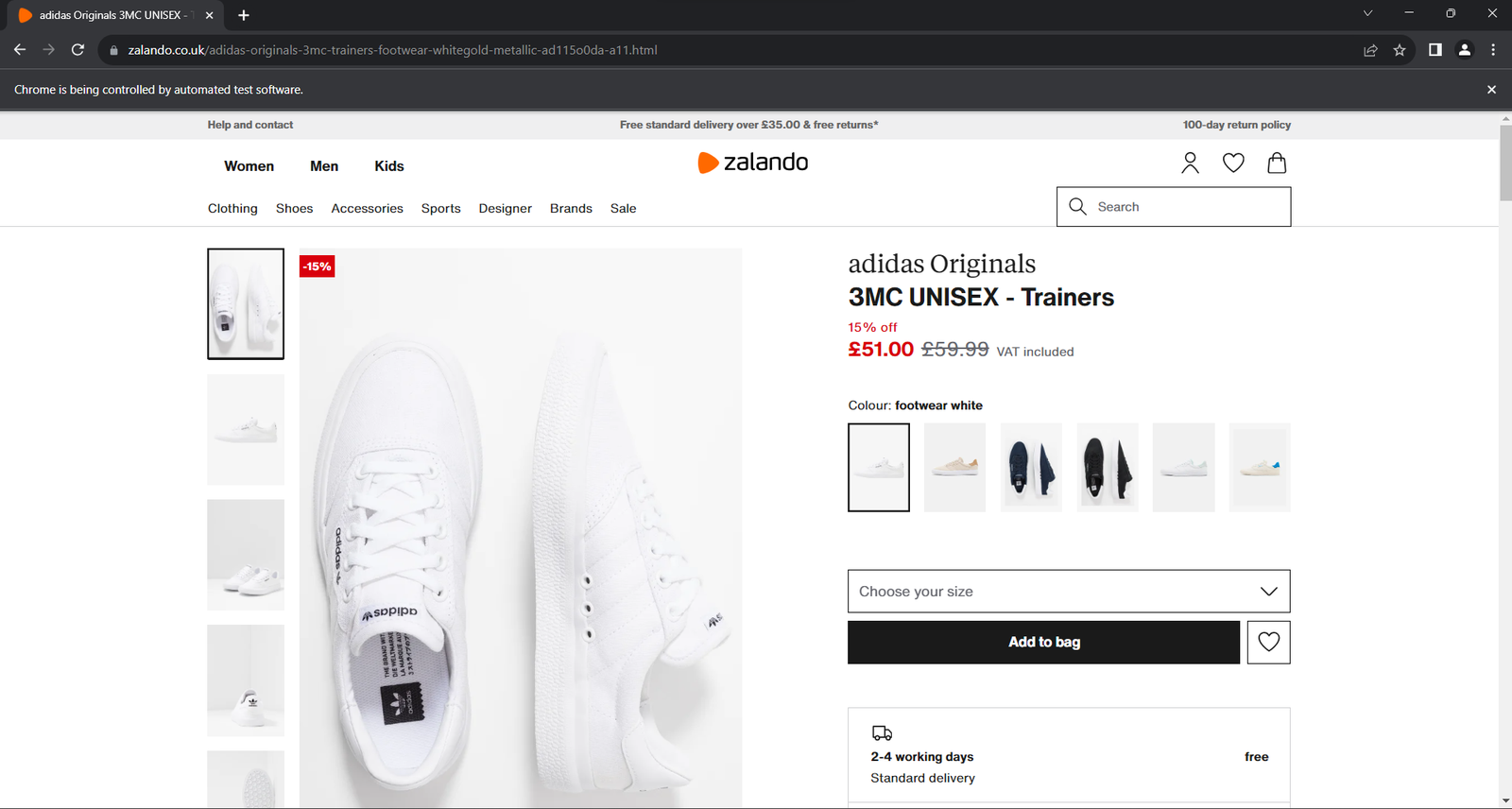
Der Hinweis „Chrome wird von einer automatisierten Software gesteuert“ stellt sicher, dass Selenium wie erwartet funktioniert.
Schritt 4: Machen Sie sich mit der Seitenstruktur vertraut
Um eine effektive Scraping-Logik zu schreiben, müssen Sie sich etwas Zeit nehmen, um die DOM-Struktur der Zielseite zu studieren. Das hilft Ihnen zu verstehen, wie Sie HTML-Elemente auswählen und Daten aus ihnen extrahieren können.
Öffnen Sie Ihren Browser im Inkognito-Modus und besuchen Sie die ausgewählte Zalando-Produktseite. Klicken Sie mit der rechten Maustaste und wählen Sie die Option „Untersuchen”, um die DevTools Ihres Browsers zu öffnen:
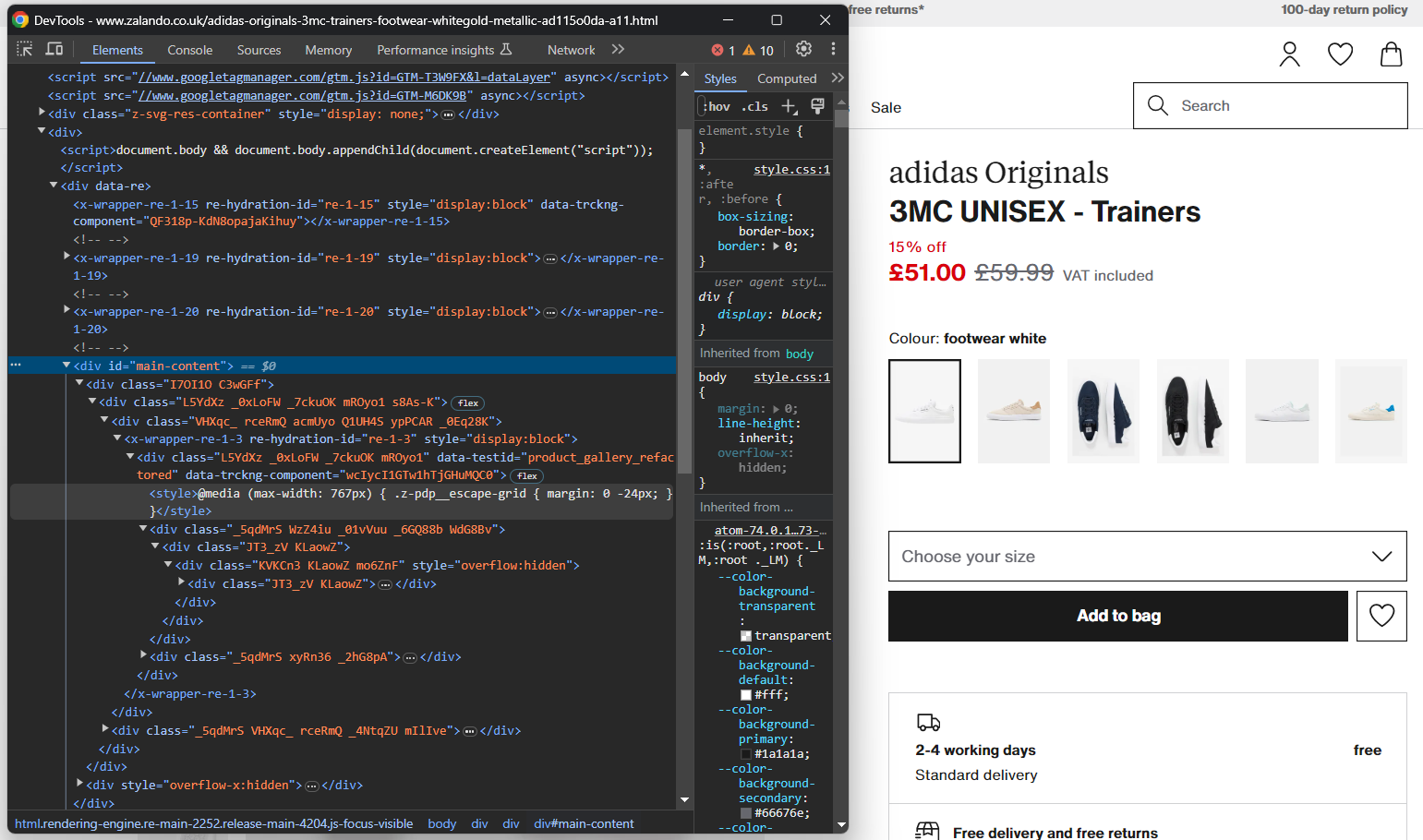
Hier werden Sie sicherlich feststellen, dass die meisten CSS-Klassen offenbar zufällig zum Zeitpunkt der Erstellung generiert werden. Mit anderen Worten: Sie sollten Ihre Auswahlstrategie nicht auf ihnen basieren, da sie sich bei jeder Bereitstellung ändern. Gleichzeitig haben einige Elemente ungewöhnliche HTML-Attribute wie data-testid. Das hilft Ihnen dabei, effektive Selektoren zu definieren.
Interagieren Sie mit der Seite, um zu untersuchen, wie sich das DOM nach dem Klicken auf bestimmte Elemente, wie z. B. die Akkordeons, verändert. Sie werden feststellen, dass einige Daten basierend auf Benutzeraktionen dynamisch zum DOM hinzugefügt werden.
Untersuchen Sie die Zielseite weiter und machen Sie sich mit ihrer HTML-Struktur vertraut, bis Sie bereit sind, fortzufahren.
Schritt 5: Beginnen Sie mit der Extraktion der Produktdaten
Initialisieren Sie zunächst eine Datenstruktur, in der Sie die gescrapten Daten verfolgen können. Ein Python-Dictionary ist dafür ideal:
product = {}Beginnen Sie mit der Auswahl von Elementen auf der Seite und extrahieren Sie Daten aus ihnen!
Untersuchen Sie das HTML-Element, das die Schuhmarke enthält:
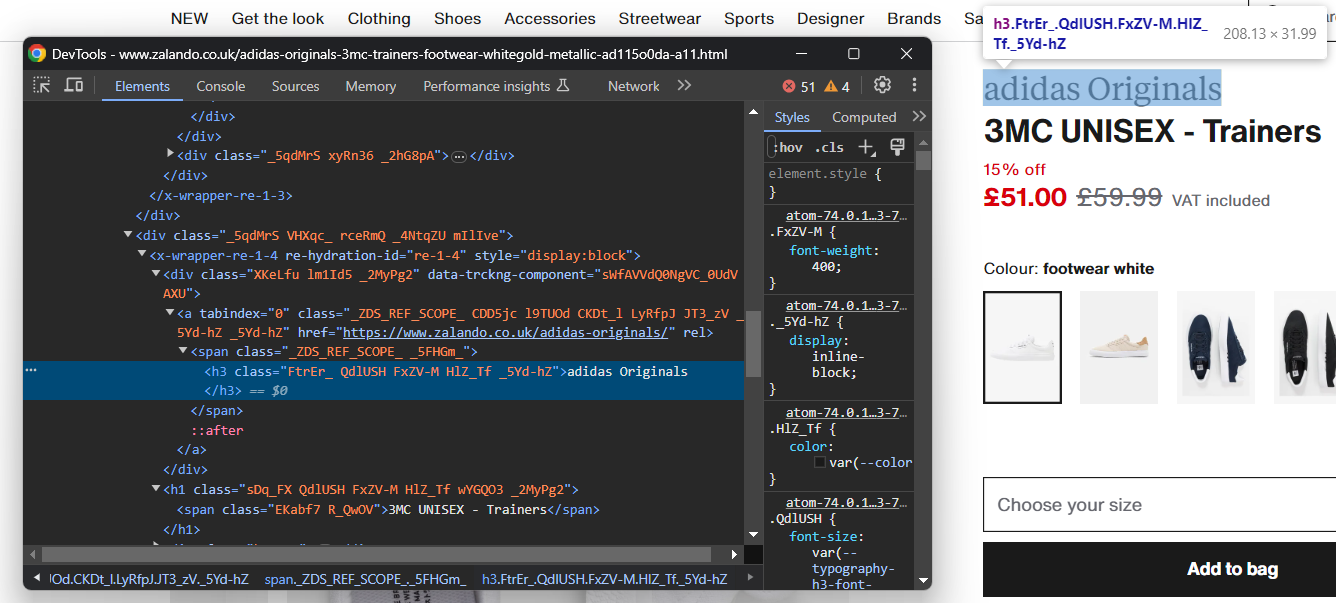
Beachten Sie, dass die Marke ein <h3> und der Produktname ein <h1> ist. Extrahieren Sie diese Daten mit:
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.textfind_element() ist eine Selenium-Methode, die das erste Element zurückgibt, das der als Parameter übergebenen Auswahlstrategie entspricht. Insbesondere weist By.CSS_SELECTOR den Treiber an, eine CSS-Selektor-Strategie zu verwenden. Selenium unterstützt auch:
- By.TAG_NAME: Zum Suchen von Elementen anhand ihres HTML-Tags.
- By.XPATH: Zum Suchen von Elementen über einen XPath-Ausdruck.
Ähnlich gibt es auch find_elements(), das die Liste aller Knoten zurückgibt, die der Auswahlabfrage entsprechen.
Denken Sie daran, By mit folgendem Befehl zu importieren:
from selenium.webdriver.common.by import ByBei einem HTML-Element können Sie dann mit dem Attribut text auf dessen Textinhalt zugreifen. Verwenden Sie bei Bedarf die Python-Methode replace(), um die Textzeichenfolgen zu bereinigen.
Das Extrahieren von Preisinformationen ist etwas schwieriger. Wie Sie auf dem Bild unten sehen können, gibt es keine einfache Möglichkeit, diese Elemente auszuwählen:
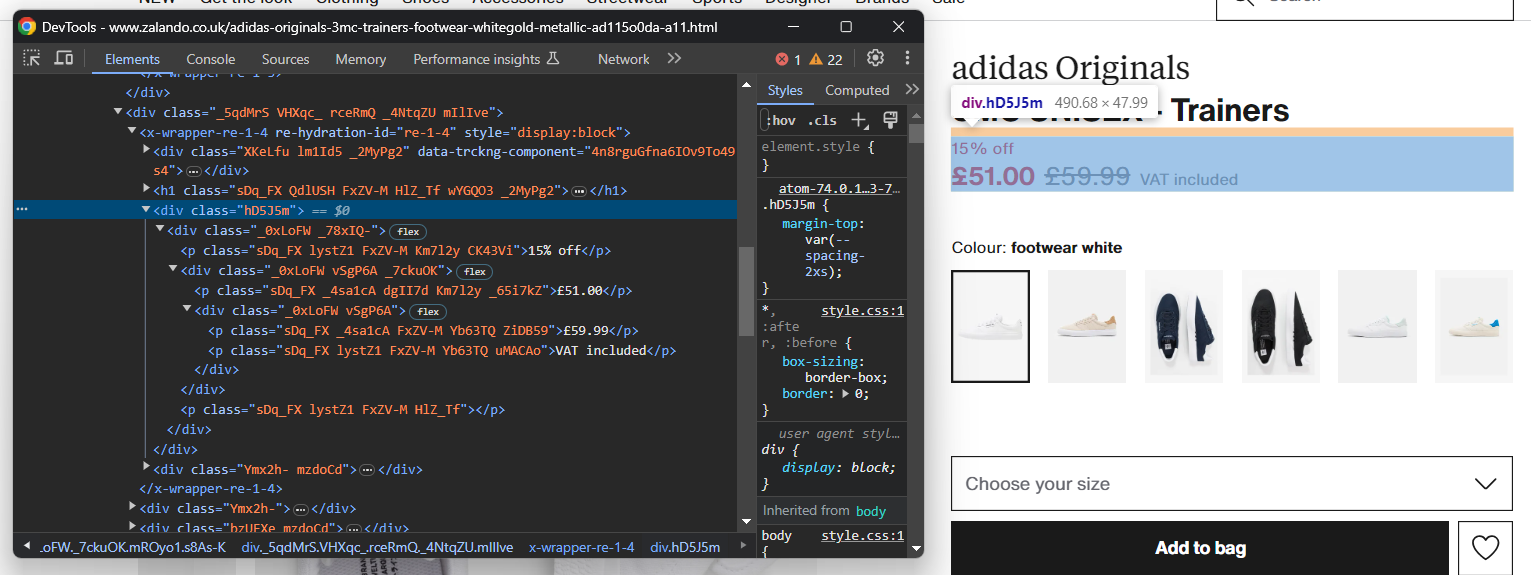
Sie können Folgendes tun:
- Greifen Sie auf den Preis <div> als erstes Geschwisterelement des <h1>-Namenselements zu.
- Rufen Sie alle <p>-Knoten darin ab.
Erreichen Sie dies mit:
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")Beachten Sie, dass Selenium keine Hilfsmethode für den Zugriff auf die Geschwister eines Knotens bereitstellt. Aus diesem Grund müssen Sie stattdessen den Xpath-Ausdruck following-sibling::* verwenden.
Anschließend können Sie die Produktpreisdaten mit folgendem Befehl abrufen:
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].textKonzentrieren Sie sich nun auf die Produktbildgalerie:
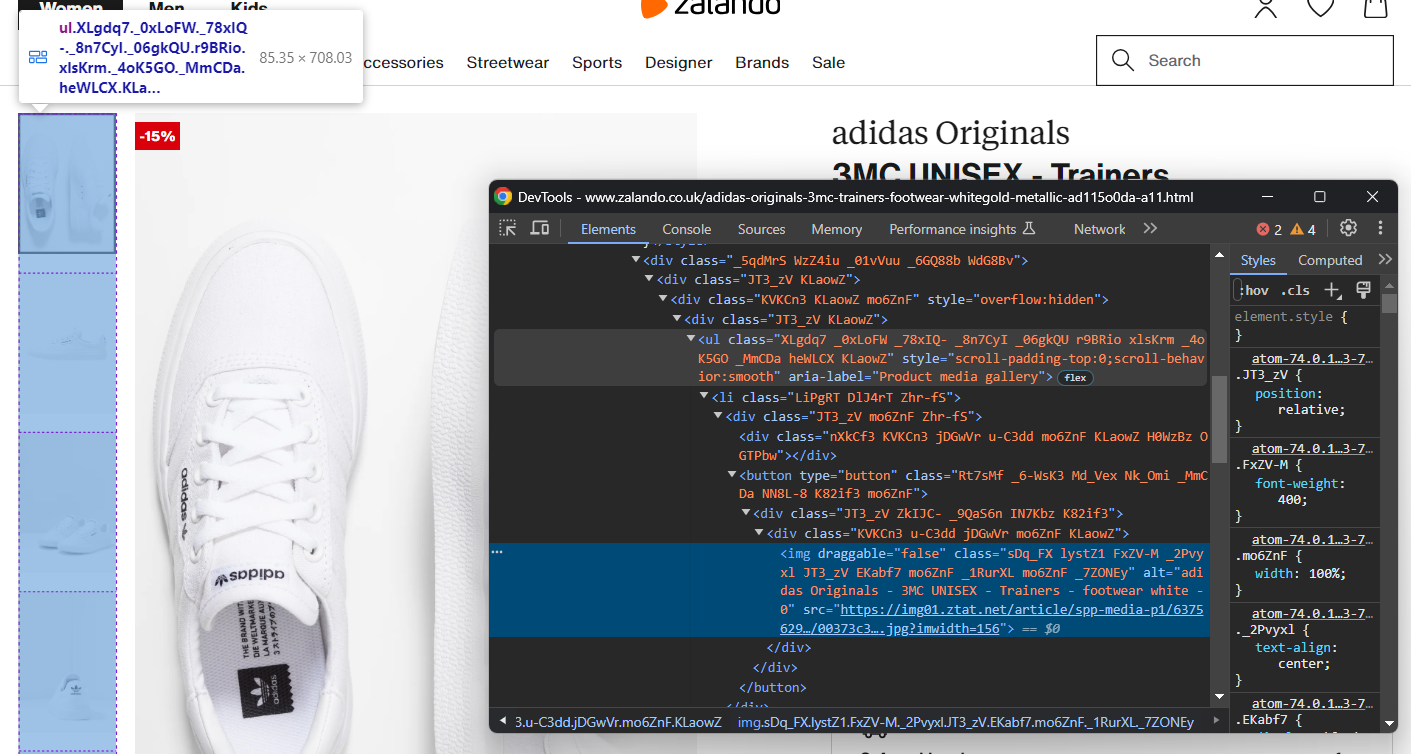
Diese enthält mehrere Bilder, initialisieren Sie also ein Array, um sie alle zu speichern:
images = []Auch hier ist die Auswahl von <img> nicht einfach, aber Sie können dies erreichen, indem Sie die <li>-Elemente innerhalb der „Produktmediengalerie” <ul> anvisieren:
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Produktmediengalerie"] li')for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)Auf ähnliche Weise können Sie die Schuhfarboptionen erfassen:
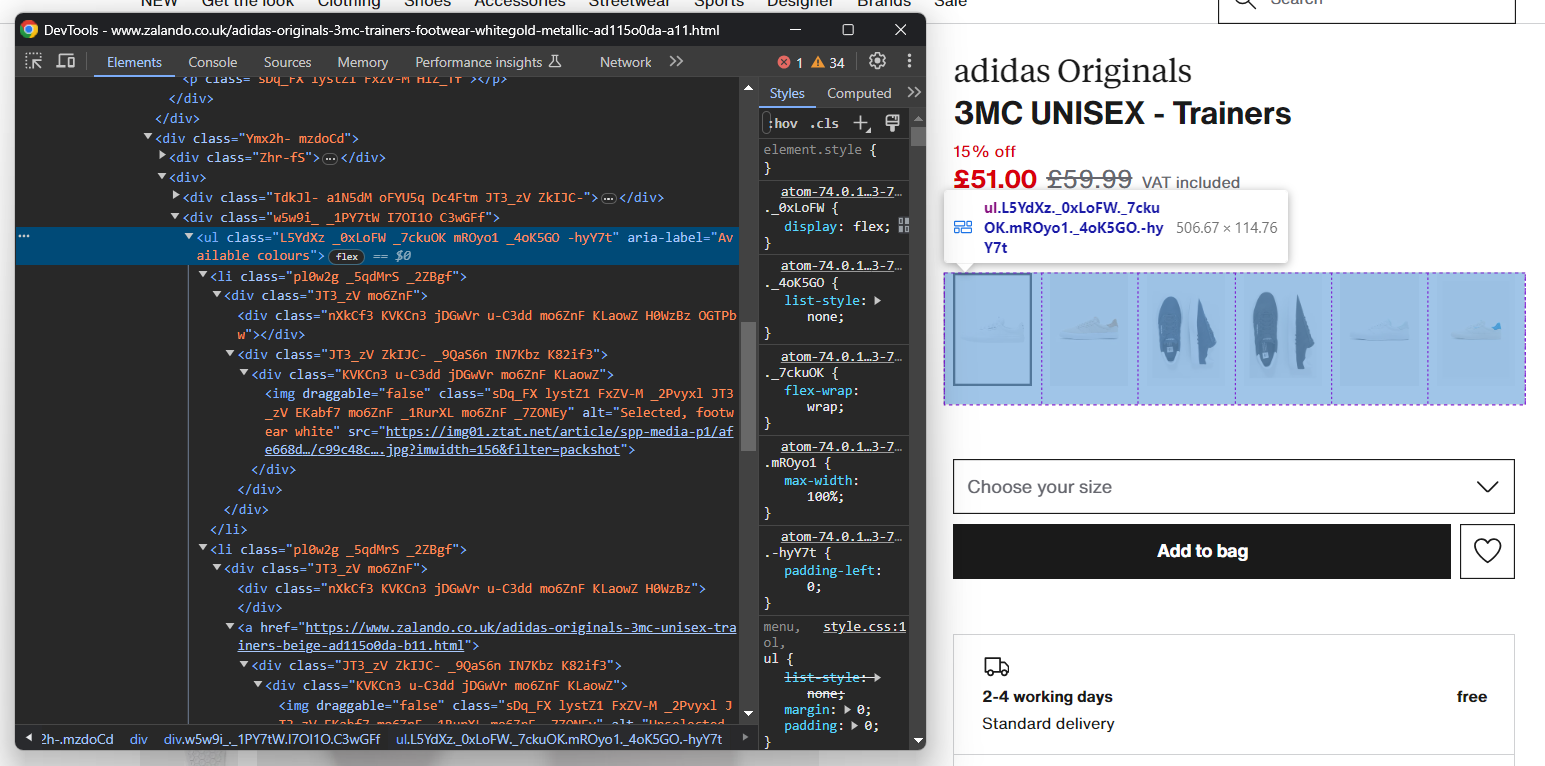
Wie zuvor ist jedes Farbelement ein <li>. Im Einzelnen enthält jeder Farbabschnitt:
- Einen optionalen Link.
- Ein Bild.
- Einen Namen, der im Alt-Attribut des Bildelements gespeichert ist.
Extrahieren Sie alle Farben mit:
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Available colours"] li')
for color_element in color_elements:
# initialize a new color object
color = {
'color': None,
'image': None,
'link': None
}
# Überprüfen Sie, ob der Farblink vorhanden ist, und extrahieren Sie dessen URL.
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
# Überprüfen, ob das Farbbild vorhanden ist, und dessen Daten extrahieren
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)Perfekt! Sie haben gerade eine Scraping-Logik implementiert, aber es gibt noch mehr Daten abzurufen.
Schritt 6: Scrapen Sie die Produktdetail-Daten
Die Produktdetails sind in Karten gespeichert, die sich unter dem Element zur Farbauswahl befinden:
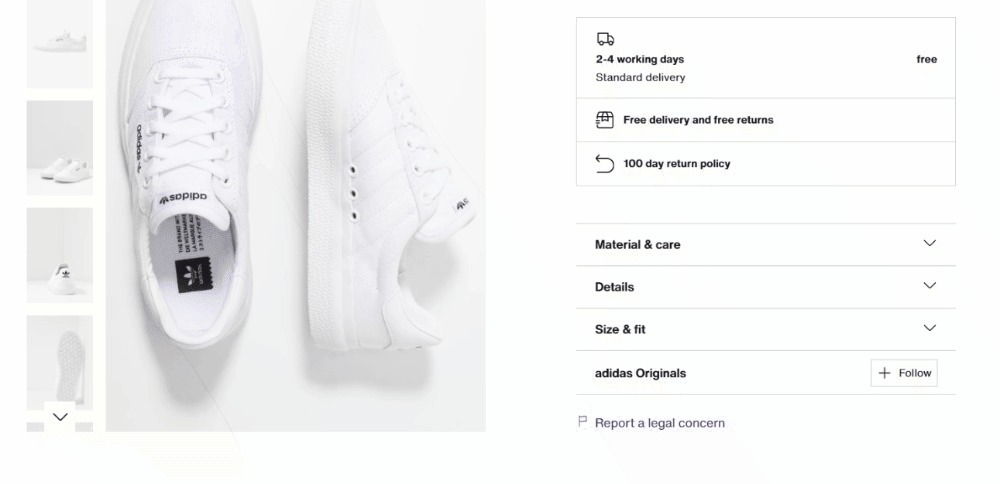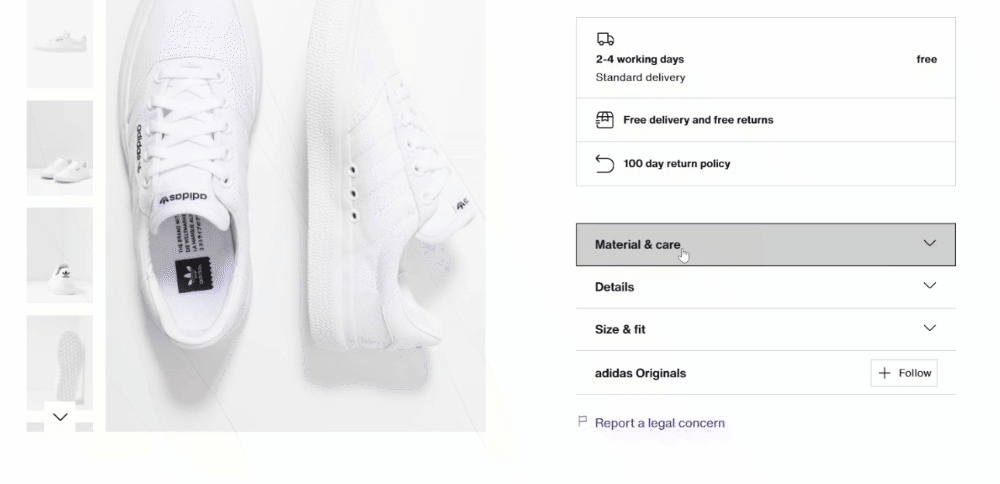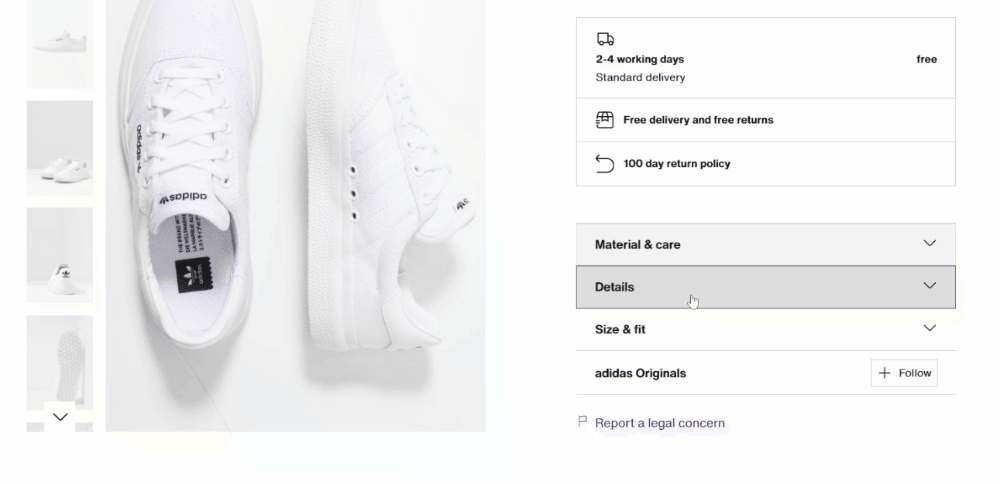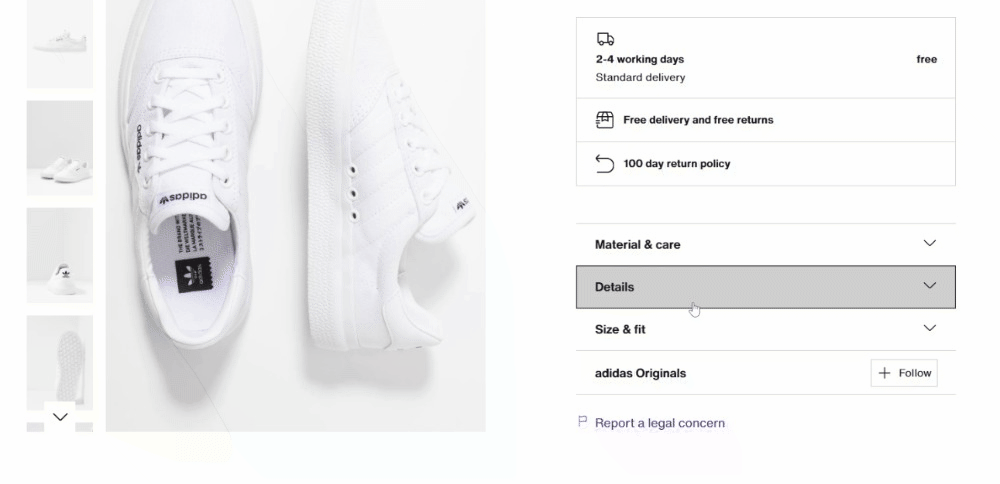
Konzentrieren Sie sich zunächst auf die Lieferinformationen:
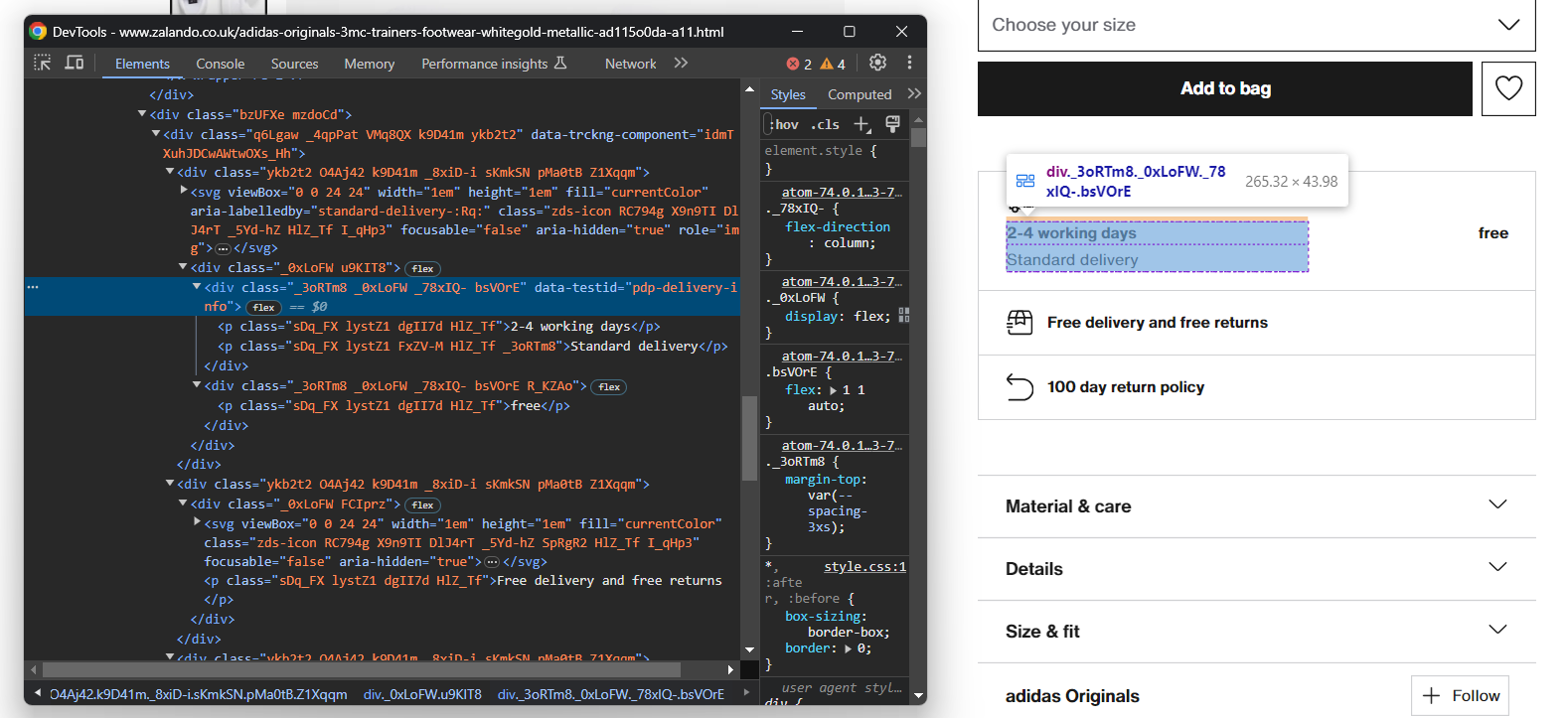
Diese bestehen aus drei Datenfeldern, initialisieren Sie also ein Lieferwörterbuch wie folgt:
delivery = {
'time': None,
'type': None,
'cost': None,
}Auch hier gibt es keinen einfachen Selektor, um diese drei Elemente auszuwählen. Sie können Folgendes tun:
- Wählen Sie den Knoten aus, dessen Attribut „data-testid” „pdp-delivery-info” lautet.
- Wechseln Sie zu seinem übergeordneten Element.
- Rufen Sie alle untergeordneten <p>-Elemente ab.
Implementieren Sie diese Logik und extrahieren Sie die Lieferdaten mit:
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].textDa Selenium keine Möglichkeit bietet, auf den übergeordneten Knoten zuzugreifen, müssen Sie den Xpath-Ausdruck parent::* verwenden.
Als Nächstes konzentrieren Sie sich auf die Akkordeons mit den Produktdetails:
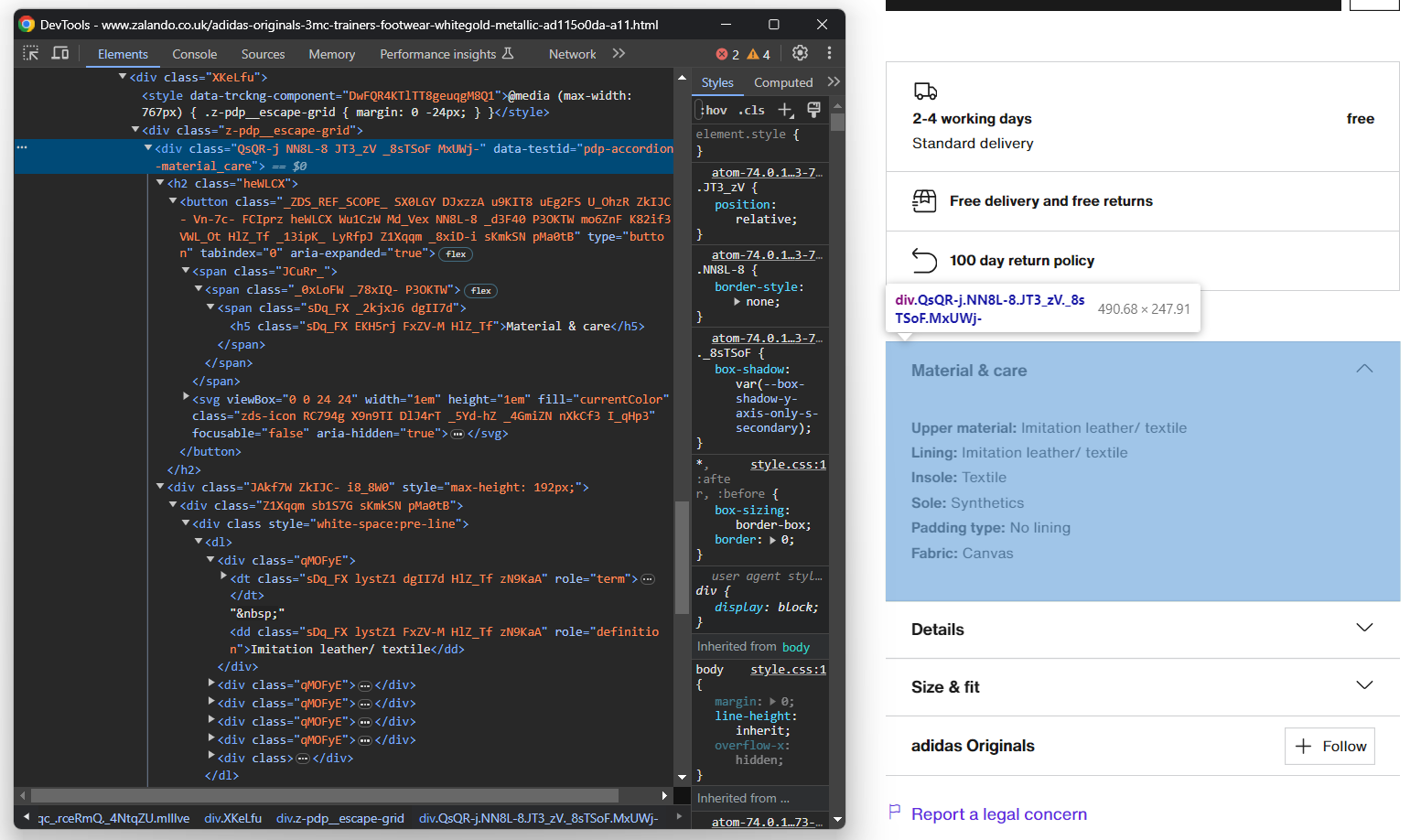
Dieses Mal können Sie alle Akkordeonelemente abrufen, indem Sie Knoten ansprechen, deren data-testid-Attribut mit „pdp-accordion-“ beginnt. Verwenden Sie dazu den folgenden CSS-Selektor:
[data-testid^="pdp-accordion-"]Dieser Abschnitt enthält mehrere Felder, daher müssen Sie ein Wörterbuch erstellen, um den Überblick zu behalten:
info = {}Wenden Sie dann den oben genannten CSS-Selektor an, um die Akkordeons mit den Produktdetails auszuwählen:
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]Das Element „Größe & Passform” enthält keine relevanten Daten, sodass Sie es ignorieren können. [:2] reduziert die Liste wie gewünscht auf die ersten beiden Elemente.
Diese HTML-Elemente sind dynamisch und ihr Inhalt wird erst beim Öffnen zum DOM hinzugefügt. Daher müssen Sie die Klick-Interaktion mit der Methode click() simulieren:
for info_element in info_elements:
info_element.click()
// Scraping-Logik...
Als Nächstes füllen Sie das Info-Objekt programmgesteuert mit:
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').textDie obige Logik extrahiert dynamisch die Informationen in den Akkordeons und ordnet sie nach Namen.
Um besser zu verstehen, wie dieser Code funktioniert, versuchen Sie, info auszudrucken. Sie sehen dann Folgendes:
{'Material & Pflege': {'Obermaterial': 'Kunstleder/Textil', 'Futter': 'Kunstleder/Textil', 'Innensohle': 'Textil', 'Sohle': 'Synthetik', 'Polsterungstyp': 'Ohne Futter', 'Stoff': 'Canvas'}, 'Details': {'Schuhspitze': 'Rund', 'Absatztyp': 'Flach', 'Verschluss': 'Schnürsenkel', 'Schuhverschluss': 'Schnürsenkel', 'Muster': 'Einfarbig', 'Artikelnummer': 'AD115O0DA-A11'}}Fantastisch! Zalando-Produktdetails erfolgreich extrahiert!
Schritt 7: Produkt-Objekt füllen
Jetzt müssen nur noch die gescrapten Daten in das Produkt-Dictionary eingefügt werden:
# Die gescraped Daten dem Wörterbuch zuweisen
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = infoSie können auch eine Protokollanweisung hinzufügen, um zu überprüfen, ob der Zalando-Scraper wie erwartet funktioniert:
print(job)
Führen Sie das Skript aus:
python scraper.pyDies erzeugt eine Ausgabe ähnlich wie:
{'brand': 'adidas Originals', 'name': '3MC UNISEX - Trainers', 'price': '£51.00', 'original_price': '£59.99', 'discount': '15%', ... }Et voilà! Sie haben gerade gelernt, wie Sie Produktdaten von Zalando scrapen können.
Schritt 8: Exportieren Sie die extrahierten Daten nach JSON
Derzeit werden die extrahierten Daten in einem Python-Wörterbuch gespeichert. Exportieren Sie sie in JSON, um sie leichter teilen und lesen zu können:
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)Der obige Ausschnitt erstellt mit open() eine Ausgabedatei product.json und füllt sie mit JSON-Daten über json.dump(). In unserem Leitfaden erfahren Sie mehr darüber, wie Sie Daten in Python in JSON parsen und serialisieren können.
Denken Sie daran, den json-Import hinzuzufügen:
import jsonDieses Paket stammt aus der Python-Standardbibliothek, sodass Sie es nicht einmal manuell installieren müssen.
Fantastisch! Sie haben mit rohen Produktdaten aus einer Webseite begonnen und verfügen nun über semistrukturierte JSON-Daten. Sie sind bereit, sich den vollständigen Zalando-Scraper anzusehen.
Schritt 8: Alles zusammenfügen
Hier ist der vollständige Code der Datei scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
service = Service()
# Chrome-Instanz konfigurieren
options = webdriver.ChromeOptions()
# Ihre Browser-Optionen...
driver = webdriver.Chrome(
service=service,
options=options)
# Fenster maximieren, um das responsive Rendering zu vermeiden
driver.maximize_window()
# Zielseite im kontrollierten Browser aufrufen
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# Instanziieren Sie das Objekt, das die gescrapten Daten enthalten wird.
product = {}
# Scraping-Logik
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.text
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].text
images = []
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Produktmediengalerie"] li')
for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Verfügbare Farben"] li')
for color_element in color_elements:
color = {
'color': None,
'image': None,
'link': None
}
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)
delivery = {
'time': None,
'type': None,
'cost': None,
}
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].text
info = {}
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]
for info_element in info_elements:
info_element.click()
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text
# Schließen Sie den Browser und geben Sie seine Ressourcen frei.
driver.quit()
# die gescrapten Daten dem Wörterbuch zuweisen
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info
print(product)
# exportiere die gescrapten Daten in eine JSON-Datei
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)Mit etwas mehr als 100 Zeilen Code haben Sie gerade einen voll funktionsfähigen Zalando-Scraper erstellt, um Produktdetailinformationen abzurufen.
Führen Sie ihn aus mit:
python Scraper.pyWarten Sie einige Sekunden, bis das Skript fertig ist.
Am Ende des Scraping-Prozesses erscheint eine Datei namens product.json im Stammverzeichnis Ihres Projekts. Öffnen Sie sie und Sie sehen:
{
"brand": "adidas Originals",
"name": "3MC UNISEX - Trainers",
"price": "£51.00",
"original_price": "£59.99",
"discount": "15%",
„images”: [
„https://img01.ztat.net/article/spp-media-p1/637562911a7e36c28ce77c9db69b4cef/00373c35a7f94b4b84a4e070879289a2.jpg?imwidth=156“,
// der Kürze halber ausgelassen...
„https://img01.ztat.net/article/spp-media-p1/7d4856f0e4803b759145755d10e8e6b6/521545d1286c478695901d26fcd9ed3a.jpg?imwidth=156“
],
„colors”: [
{
„color”: „footwear white”,
„image”: „https://img01.ztat.net/article/spp-media-p1/afe668d0109a3de0a5175a1b966bf0c9/c99c48c977ff429f8748f961446f79f5.jpg?imwidth=156&filter=packshot",
"link": null
},
// der Kürze halber ausgelassen...
{
"color": "white",
"image": "https://img01.ztat.net/article/spp-media-p1/87e6a1f18ce44e3cbd14da8f10f52dfd/bb1c3a8c409544a085c977d6b4bef937.jpg?imwidth=156&filter=packshot",
„link“: „https://www.zalando.co.uk/adidas-originals-3mc-unisex-trainers-white-ad115o0da-a16.html“
}
],
„delivery“: {
„time“: „2–4 Werktage“,
„type“: „Standardlieferung“,
„cost“: „kostenlos“
},
„info“: {
„Material & Pflege“: {
„Obermaterial“: „Kunstleder/Textil“,
„Futter“: „Kunstleder/Textil“,
„Innensohle“: „Textil“,
„Sohle“: „Synthetik“,
„Polsterung“: „Ohne Futter“,
„Stoff“: „Canvas“
},
„Details“: {
„Schuhspitze“: „Rund“,
„Absatzform“: „Flach“,
„Verschluss“: „Schnürsenkel“,
„Schuhverschluss“: „Schnürsenkel“,
„Muster“: „Einfarbig“,
„Artikelnummer“: „AD115O0DA-A11“
}
}
}Herzlichen Glückwunsch! Sie haben gerade gelernt, wie man Zalando in Python scrapt!
Fazit
In diesem Tutorial haben Sie verstanden, warum Zalando eine großartige E-Commerce-Website zum Scrapen ist und wie Sie Daten daraus extrahieren können. Hier haben Sie gesehen, wie Sie einen Zalando-Scraper erstellen, der automatisch Daten von einer Produktseite abruft.
Wie hier gezeigt, ist das Scraping von Zalando aus mindestens drei Gründen keine leichte Aufgabe:
- Die Website implementiert einige Anti-Scraping-Maßnahmen, die Ihr Skript blockieren könnten.
- Die Webseiten enthalten zufällige CSS-Klassen.
- Jede Produktseite hat eine bestimmte Struktur und kann unterschiedliche Informationen enthalten.
Um das erste Problem zu vermeiden und sich keine Gedanken mehr über eine Blockierung machen zu müssen, probieren Sie unsere neue Lösung aus! Der Scraping-Browser ist ein steuerbarer Browser, der CAPTCHAs, Fingerprinting, automatische Wiederholungsversuche und vieles mehr automatisch für Sie übernimmt. Sie müssen jedoch weiterhin Code schreiben und diesen pflegen. Beheben Sie die beiden verbleibenden Probleme mit einer sofort einsatzbereiten Lösung – sehen Sie sich unseren Zalando-Scraper an!
Hinweis: Dieser Leitfaden wurde zum Zeitpunkt der Erstellung von unserem Team gründlich getestet, aber da Websites ihren Code und ihre Struktur häufig aktualisieren, funktionieren einige Schritte möglicherweise nicht mehr wie erwartet.




