

Perlist eine der beliebtesten Sprachen und dank seiner umfangreichen Modulsammlung eine gute Wahl für das Schreiben von Web-Scrapern.
In diesem Artikel werden wir Folgendes besprechen:
- Wie man mit Perl Web-Scraping mit den folgenden Methoden durchführt:
LWP::UserAgentundHTML::TreeBuilderWeb::ScraperMojo::UserAgentundMojo::DOMXML::LibXML
- Herausforderungen beim Web-Scraping mit Perl
- Fazit
Web-Scraping mit Perl
Um den Artikel nachvollziehen zu können, stellen Sie sicher, dass Sie die neueste Version von Perl installiert haben. Der Code in diesem Artikel wurde mit Perl 5.38.2 getestet. Dieser Artikel setzt außerdem voraus, dass Sie wissen, wie manPerl-Module mitcpanm installiert.
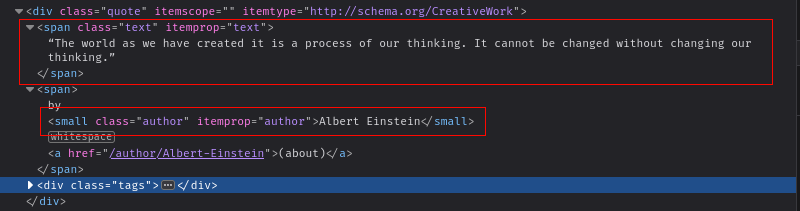
In diesem Artikel werden Sie dieWebsite „Quotes to Scrape“scrapen, um die Zitate zu extrahieren. Bevor Sie Daten von der Website scrapen können, müssen Sie verstehen, wie der HTML-Code strukturiert ist. Öffnen Sie die Website im Browser und drücken SieSTRG + Umschalt + I(Windows) oderBefehl + Umschalt + C(Mac), um das Dialogfeld„Element untersuchen“zu öffnen.
Wenn Sie die Elemente untersuchen, sehen Sie, dass jedes Zitat in einemdivmit der Klassequote gespeichert ist. Jedes Zitat enthält einspanmit der Klassetextund einkleinesElement, in dem der Text bzw. der Name des Autors gespeichert ist:
Verwendung von LWP::UserAgent und HTML::TreeBuilder
LWP::UserAgentist Teil vonLWP, einer Gruppe von Modulen, die mit dem Web interagieren. Mit dem ModulLWP::UserAgentkönnen Sie eine HTTP-Anfrage an eine Webseite senden und den HTML-Inhalt zurückgeben. Anschließend können Sie das ModulHTML::TreeBuilderausHTML::Treeverwenden, um den HTML-Code zu parsen und Informationen zu extrahieren.
Um LWP::UserAgent und HTML::TreeBuilder zu verwenden, installieren Sie die Module mit den folgenden Befehlen:
cpanm Bundle::LWP
cpanm HTML::Tree
Erstellen Sie eine Datei mit dem Namen lwp-and-tree-builder.pl. Hier schreiben Sie den Code. Fügen Sie dann die folgenden zwei Zeilen in diese Datei ein:
use LWP::UserAgent;
use HTML::TreeBuilder;
Dieser Code weist den Perl-Interpreter an, die Module LWP::UserAgent und HTML::TreeBuilder einzubinden.
Definieren Sie eine Instanz von LWP::UserAgent und setzen Sie den User-Agent -Header auf „Quotes Scraper“:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
Definieren Sie die URL der Zielwebsite und erstellen Sie eine Instanz von HTML::TreeBuilder:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
Jetzt können Sie die HTTP-Anfrage stellen:
my $request = $ua->get($url) or die "Ein Fehler ist aufgetreten $!n";
Fügen Sie die folgende if-else-Anweisung ein, die überprüft, ob die Anfrage erfolgreich war oder nicht:
if ($request->is_success) {
} else {
print "Das Ergebnis kann nicht parsed werden. " . $request->status_line . "n";
}
Wenn die Anfrage erfolgreich war, können Sie mit dem Scraping beginnen.
Verwenden Sie die parse -Methode von HTML::TreeBuilder, um die HTML-Antwort zu parsen. Fügen Sie den folgenden Code in den if -Block ein:
$root->parse($request->content);
Verwenden Sie nun die Methode „look_down“, um die div-Elemente mit der Klasse „quote“ zu finden:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
Durchlaufen Sie das Array mit den Zitaten, verwenden Sie „look_down“, um den Text und den Autor zu finden, und geben Sie diese aus:
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
Der vollständige Code sieht wie folgt aus:
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "Ein Fehler ist aufgetreten $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "Cannot parse the result. " . $request->status_line . "n";
}
Führen Sie diesen Code mit perl lwp-and-tree-builder.pl aus, und Sie sollten die folgende Ausgabe sehen:
„Die Welt, wie wir sie geschaffen haben, ist ein Produkt unseres Denkens. Sie kann nicht verändert werden, ohne unser Denken zu verändern.“: Albert Einstein
„Es sind unsere Entscheidungen, Harry, die zeigen, wer wir wirklich sind, viel mehr als unsere Fähigkeiten.“: J.K. Rowling
„Es gibt nur zwei Möglichkeiten, sein Leben zu leben. Die eine ist, als wäre nichts ein Wunder. Die andere ist, als wäre alles ein Wunder.“: Albert Einstein
„Wer, ob Mann oder Frau, keine Freude an einem guten Roman hat, muss unerträglich dumm sein.“: Jane Austen
„Unvollkommenheit ist Schönheit, Wahnsinn ist Genialität, und es ist besser, absolut lächerlich zu sein als absolut langweilig.“: Marilyn Monroe
„Versuche nicht, ein erfolgreicher Mensch zu werden. Werde lieber ein wertvoller Mensch.“: Albert Einstein
„Es ist besser, für das, was man ist, gehasst zu werden, als für das, was man nicht ist, geliebt zu werden.“: André Gide
„Ich habe nicht versagt. Ich habe nur 10.000 Wege gefunden, die nicht funktionieren.“: Thomas A. Edison
„Eine Frau ist wie ein Teebeutel: Man weiß nie, wie stark sie ist, bis sie in heißem Wasser liegt.“: Eleanor Roosevelt
„Ein Tag ohne Sonnenschein ist wie, na ja, die Nacht.“: Steve Martin
Verwendung von Web::Scraper
Web::Scraperist eine Web-Scraping-Bibliothek, die vonRubys ScrAPI inspiriert wurde. Sie bietet eine domänenspezifische Sprache (DSL) zum Scraping von HTML- und XML-Dokumenten. In diesem Artikel erfahren Sie mehr über Web-Scraping mit Ruby.
Um Web::Scraper zu verwenden, installieren Sie das Modul mit cpanm Web::Scraper.
Erstellen Sie eine neue Datei mit dem Namen web-scraper.pl und fügen Sie die folgenden erforderlichen Module ein:
use URI;
use Web::Scraper;
use Encode;
Als Nächstes müssen Sie einen Scraper-Block mit der DSL des Moduls definieren. Mit der DSL lässt sich ein Scraper ganz einfach in nur wenigen Zeilen definieren. Beginnen Sie mit der Definition eines Scraper-Blocks namens $quotes:
my $quotes = Scraper {
};
Die Scraper-Methode definiert die Logik des Scrapers, die ausgeführt wird, wenn später die Scrape-Methode aufgerufen wird. Innerhalb des Scraper-Blocks verwenden Sie die Process-Methode, um Elemente mithilfe von CSS-Selektoren zu finden und eine Funktion auszuführen.
Beginnen Sie damit, alle div -Elemente mit der Klasse quote zu finden:
# Alle `div` mit der Klasse `quote` analysieren
process 'div.quote', "quotes[]" => Scraper {
};
Dieser Code findet alle div -Elemente mit der Klasse „quote” und speichert sie im Array „quotes ”. Für jedes Element wird die Scraper -Methode ausgeführt, die Sie wie folgt definieren:
# Und in jedem div `span` mit der Klasse `text` suchen
process_first "span.text", text => 'TEXT';
# `small` mit der Klasse `author` abrufen
process_first "small", author => 'TEXT';
Die Methode process_first findet das erste Element, das dem CSS-Selektor entspricht. Hier suchen Sie das erste span-Element mit der Klasse text, extrahieren dessen Text und speichern ihn im Schlüssel text. Für den Namen des Autors suchen Sie das erste small-Element und extrahieren den Text, um ihn im Schlüssel author zu speichern.
Der vollständige Scraper -Block sieht wie folgt aus:
my $quotes = Scraper {
# Alle `div` mit der Klasse `quote` parsen
process 'div.quote', "quotes[]" => Scraper {
# Und in jedem div `span` mit der Klasse `text` suchen
process_first "span.text", text => 'TEXT';
# `small` mit der Klasse `author` abrufen
process_first "small", author => 'TEXT';
};
};
Rufe nun die Scrape-Methode auf und übergebe die URL, um das Scraping zu starten:
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
Schließlich durchlaufen Sie das Array mit den Zitaten und geben das Ergebnis aus:
# Durchlaufen des Arrays
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
Der vollständige Code sieht wie folgt aus:
use URI;
use Web::Scraper;
use Encode;
my $quotes = scraper {
# Alle `div` mit der Klasse `quote` analysieren
process 'div.quote', "quotes[]" => scraper {
# Und in jedem div `span` mit der Klasse `text` suchen
process_first "span.text", text => 'TEXT';
# `small` mit der Klasse `author` abrufen
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# Durchlaufen Sie das Array.
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
Führen Sie den vorherigen Code mit perl web-scraper.pl aus, und Sie sollten die folgende Ausgabe erhalten:
„Die Welt, wie wir sie geschaffen haben, ist ein Produkt unseres Denkens. Sie kann nicht verändert werden, ohne unser Denken zu verändern.“: Albert Einstein
„Es sind unsere Entscheidungen, Harry, die zeigen, wer wir wirklich sind, viel mehr als unsere Fähigkeiten.“: J.K. Rowling
„Es gibt nur zwei Möglichkeiten, sein Leben zu leben. Die eine ist, als wäre nichts ein Wunder. Die andere ist, als wäre alles ein Wunder.“: Albert Einstein
„Wer, ob Mann oder Frau, keine Freude an einem guten Roman hat, muss unerträglich dumm sein.“: Jane Austen
„Unvollkommenheit ist Schönheit, Wahnsinn ist Genialität, und es ist besser, absolut lächerlich zu sein als absolut langweilig.“: Marilyn Monroe
„Versuche nicht, ein erfolgreicher Mensch zu werden. Werde lieber ein wertvoller Mensch.“: Albert Einstein
„Es ist besser, für das, was man ist, gehasst zu werden, als für das, was man nicht ist, geliebt zu werden.“: André Gide
„Ich habe nicht versagt. Ich habe nur 10.000 Wege gefunden, die nicht funktionieren.“: Thomas A. Edison
„Eine Frau ist wie ein Teebeutel: Man weiß nie, wie stark sie ist, bis sie in heißem Wasser liegt.“: Eleanor Roosevelt
„Ein Tag ohne Sonnenschein ist wie, na ja, die Nacht.“: Steve Martin
Verwendung von Mojo::UserAgent und Mojo::DOM
Mojo::UserAgentundMojo::DOMsind Teil desMojolicious-Frameworks, einem Echtzeit-Webframework für Perl. In Bezug auf ihre Funktionalität ähneln sieLWP::UserAgentundHTML::TreeBuilder.
Um Mojo::UserAgent und Mojo::DOM zu verwenden, installieren Sie die Module mit dem folgenden Befehl:
cpanm Mojo::UserAgent
cpanm Mojo::DOM
Erstellen Sie eine neue Datei mit dem Namen mojo.pl und fügen Sie die Module Mojo::USeragent und Mojo::DOM ein:
use Mojo::UserAgent;
use Mojo::DOM;
Definieren Sie eine Instanz von Mojo::UserAgent und stellen Sie die HTTP-Anfrage:
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
Ähnlich wie bei LWP::UserAgent verwenden Sie den folgenden if-else-Block, um zu überprüfen, ob die Anfrage erfolgreich war:
if ($res->is_success) {
} else {
print "Das Ergebnis kann nicht parsed werden. " . $res->message . "n";
}
Initialisieren Sie im if -Block eine Instanz von Mojo::DOM:
my $dom = Mojo::DOM->new($res->body);
Verwenden Sie die find -Methode, um alle div -Elemente mit der Klasse „quote” zu finden:
my @quotes = $dom->find('div.quote')->each;
Durchlaufen Sie das Array „quotes” und extrahieren Sie den Text und die Namen der Autoren:
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
Nachfolgend finden Sie den vollständigen Code:
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
} else {
print "Cannot parse the result. " . $res->message . "n";
}
Führen Sie diesen Code mit perl mojo.pl aus, und Sie sollten die folgende Ausgabe erhalten:
„Die Welt, wie wir sie geschaffen haben, ist ein Produkt unseres Denkens. Sie kann nicht verändert werden, ohne unser Denken zu verändern.“: Albert Einstein
„Es sind unsere Entscheidungen, Harry, die zeigen, wer wir wirklich sind, viel mehr als unsere Fähigkeiten.“: J.K. Rowling
„Es gibt nur zwei Möglichkeiten, sein Leben zu leben. Die eine ist, als wäre nichts ein Wunder. Die andere ist, als wäre alles ein Wunder.“: Albert Einstein
„Wer, ob Mann oder Frau, keine Freude an einem guten Roman hat, muss unerträglich dumm sein.“: Jane Austen
„Unvollkommenheit ist Schönheit, Wahnsinn ist Genialität, und es ist besser, absolut lächerlich zu sein als absolut langweilig.“: Marilyn Monroe
„Versuche nicht, ein erfolgreicher Mensch zu werden. Werde lieber ein Mensch von Wert.“: Albert Einstein
„Es ist besser, für das, was man ist, gehasst zu werden, als für das, was man nicht ist, geliebt zu werden.“: André Gide
„Ich habe nicht versagt. Ich habe nur 10.000 Wege gefunden, die nicht funktionieren.“: Thomas A. Edison
„Eine Frau ist wie ein Teebeutel: Man weiß nie, wie stark sie ist, bis sie in heißem Wasser liegt.“: Eleanor Roosevelt
„Ein Tag ohne Sonnenschein ist wie, na ja, die Nacht.“: Steve Martin
Verwendung von XML::LibXML
Das Perl-ModulXML::LibXMList ein Wrapper um die Bibliotheklibxml2. Das ModulXML::LibXMLbietet einen leistungsstarken XHTML-Parser mitXPath-Fähigkeiten.
Verwenden Sie cpanm, um das Modul zu installieren:
cpanm XML::LibXML
Erstellen Sie dann eine neue Datei mit dem Namen xml-libxml.pl. Wie bei HTML::TreeBuilder müssen Sie eine Bibliothek wie LWP::UserAgent verwenden, um die HTTP-Anfrage an die Website zu stellen und den HTML-Inhalt abzurufen, den Sie an XML::LibXML übergeben.
Fügen Sie den folgenden Code ein, der das Modul LWP:UserAgent einrichtet und den HTML-Inhalt der Webseite abruft:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Ein Fehler ist aufgetreten $!n";
if ($request->is_success) {
} else {
print "Das Ergebnis kann nicht parsed werden. " . $request->status_line . "n";
}
Beginnen Sie innerhalb des if -Blocks mit dem Parsing des HTML-Dokuments mithilfe der Methode load_html:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
Die Option recover weist den Parser an, das Parsing der HTML-Datei im Falle eines Fehlers fortzusetzen, und die Option suppress_errors bewirkt, dass der Parser keine HTML-Parsing-Fehler auf der Konsole ausgibt. Da HTML-Dokumente nicht so streng validiert werden wie XHTML-Dokumente, treten wahrscheinlich nicht schwerwiegende Parsing-Fehler auf. Diese Optionen sorgen dafür, dass der Code auch dann weiter funktioniert, wenn solche Fehler auftreten.
Sobald der HTML-Code parsed ist, können Sie die Methode indnodes verwenden, um die Elemente anhand ihres XPath-Ausdrucks zu finden:
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
Der vollständige Code sieht wie folgt aus:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Ein Fehler ist aufgetreten $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
} else {
print "Cannot parse the result. " . $request->status_line . "n";
}
Führen Sie den Code mit perl xml-libxml.pl aus, und Sie sollten die folgende Ausgabe sehen:
„Die Welt, wie wir sie geschaffen haben, ist ein Produkt unseres Denkens. Sie kann nicht verändert werden, ohne unser Denken zu verändern.“: Albert Einstein
„Es sind unsere Entscheidungen, Harry, die zeigen, wer wir wirklich sind, viel mehr als unsere Fähigkeiten.“: J.K. Rowling
„Es gibt nur zwei Möglichkeiten, sein Leben zu leben. Die eine ist, als wäre nichts ein Wunder. Die andere ist, als wäre alles ein Wunder.“: Albert Einstein
„Wer, ob Mann oder Frau, keine Freude an einem guten Roman hat, muss unerträglich dumm sein.“: Jane Austen
„Unvollkommenheit ist Schönheit, Wahnsinn ist Genialität, und es ist besser, absolut lächerlich zu sein als absolut langweilig.“: Marilyn Monroe
„Versuche nicht, ein erfolgreicher Mensch zu werden. Werde lieber ein wertvoller Mensch.“: Albert Einstein
„Es ist besser, für das, was man ist, gehasst zu werden, als für das, was man nicht ist, geliebt zu werden.“: André Gide
„Ich habe nicht versagt. Ich habe nur 10.000 Wege gefunden, die nicht funktionieren.“: Thomas A. Edison
„Eine Frau ist wie ein Teebeutel: Man weiß nie, wie stark sie ist, bis sie in heißem Wasser liegt.“: Eleanor Roosevelt
„Ein Tag ohne Sonnenschein ist wie, na ja, die Nacht.“: Steve Martin
Den gesamten Code für dieses Tutorial findest du in diesemGitHub-Repo.
Herausforderungen beim Web-Scraping in Perl
Obwohl Perl mit seinen leistungsstarken Modulen das Scraping von Webseiten vereinfacht, stoßen Entwickler häufig auf einige häufige Probleme, die das Web-Scraping verlangsamen oder vollständig behindern können. Im Folgenden sind einige der Herausforderungen aufgeführt, mit denen Sie wahrscheinlich konfrontiert werden.
Umgang mit Paginierung
Websites, die mit großen Datenmengen arbeiten, senden oft nicht alle Daten auf einmal. In der Regel werden die Daten auf mehreren Seiten gesendet, und Sie müssen die Paginierung verarbeiten, um sicherzustellen, dass Sie alle Daten extrahieren. Die Paginierung lässt sich in zwei Schritten verarbeiten:
- Überprüfen Sie, ob weitere Seiten vorhanden sind. In der Regel können Sie auf der Seite nach einer Schaltfläche„Nächste Seite“ suchen oder versuchen, die nächste Seite zu laden und nach einem Fehler zu suchen.
- Wenn andere Seiten vorhanden sind, laden Sie die nächste Seite und scrapen Sie sie.
Bei statischen Websites, bei denen jede Seite eine eigene URL hat, können Sie eine Schleife ausführen und neue Seiten laden, indem Sie den Parameternummer in der URL erhöhen. Wenn Sie ein Modul wieWWW::Mechanize verwenden, können Sie einfach der URLder nächsten Seitefolgen.
Hier ist der Quotes-Scraper, der für die Paginierung mit WWW::Mechanize modifiziert wurde. Beachten Sie die Verwendung von follow_link:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}
Um dynamische Websites zu verarbeiten, die die nächste Seite mit JavaScript laden, lesen Sie unseren Leitfaden zumScraping dynamischer Websites mit Python oder lesen Sie weiter.
Rotierender Proxy
Proxys werden häufig von Web-Scrapers verwendet, um ihre Privatsphäre und Anonymität zu schützen und IP-Adresssperren zu umgehen. Module wieLWP::UserAgentbieten die Möglichkeit, Proxys für das Web-Scraping festzulegen. Bei Verwendung eines einzelnen Proxy-Servers besteht jedoch weiterhin das Risiko, dass die IP-Adresse gesperrt wird. Aus diesem Grund wird empfohlen, mehrere Proxy-Server zu verwenden und diese zu rotieren. Hier ist ein sehr einfaches Beispiel dafür, wie man dies mitLWP::UserAgent macht.
Beginnen Sie mit der Definition eines Arrays von Proxys. Wählen Sie dann einen zufälligen Proxy aus und legen Sie ihn mit der Proxy-Methode fest:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);
Jetzt können Sie wie gewohnt eine Anfrage senden. Wenn die Anfrage fehlschlägt, bedeutet dies wahrscheinlich, dass der Proxy blockiert wurde. Sie können diesen Proxy dann aus der Liste entfernen, einen anderen Proxy auswählen und es erneut versuchen:
if(request->is_success) {
# Mit dem Scraping fortfahren
} else {
# Den Proxy aus der Liste entfernen
splice(@proxies, $index, 1);
# Erneut versuchen
}
Umgang mit Honeypot-Fallen
Honeypot-Fallensind eine gängige Technik, die von Webadministratoren eingesetzt wird, um Bots und Scraper abzufangen. In der Regel verwenden sie Links, derenAnzeigeeigenschaftauf„none” gesetzt ist, wodurch sie für menschliche Benutzer unsichtbar sind. Ein Bot kann sie jedoch erkennen und dem Link folgen, der zu einer Lockvogel-Webseite führt und vom Hauptprodukt wegführt.
Um dieses Problem zu beheben, überprüfen Sie die Anzeigeeigenschaft von Links, bevor Sie ihnen folgen. Im Folgenden finden Sie eine Möglichkeit, dies mit HTML::TreeBuilder zu tun:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# Honeypot erkannt!
} else {
# Weitermachen ist sicher
}
}
CAPTCHA-Lösung
CAPTCHAs helfen dabei, unbefugten Zugriff auf eine Website zu verhindern. Sie können jedoch auch Web-Scraper daran hindern, Webseiten zu scrapen.
Um CAPTCHAs zu umgehen, können Sie einen Dienst wie den Bright Data Web Unlocker verwenden, der eine CAPTCHA-Lösung für Sie bietet.
Im Folgenden finden Sie ein Beispiel für die Verwendung des Bright Data Web Unlockers zum Erstellen einer HTTP-Anfrage:
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->Proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-zone-residential_proxy4:[email protected]:22225");
print $agent->get('http://lumtest.com/myip.json')->content();
Wenn Sie eine HTTP-Anfrage mit Web Unlocker stellen, bietet dieser eine CAPTCHA-Lösung, umgeht Anti-Bot-Maßnahmen und übernimmt die Verwaltung der Proxys für Sie.
Dynamische Websites scrapen
Bisher haben Sie hier nur Beispiele für das Scraping statischer Websites kennengelernt. Für Single-Page-Anwendungen (SPA) und andere dynamische Websites sind jedoch fortgeschrittenere Techniken erforderlich.
Dynamische Websites verwenden JavaScript zum Laden von Seiteninhalten, was bedeutet, dass Sie Scraping-Tools benötigen, die JavaScript ausführen können.Seleniumist ein solches Tool, das einen Browser emulieren kann, um dynamische Websites auszuführen. Das folgende Beispiel zeigt einen kleinen Ausschnitt aus diesem Modul in Aktion:
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();
Fazit
Perl ist dank seiner robusten Sammlung von Modulen eine hervorragende Sprache für das Web-Scraping. In diesem Artikel haben Sie gelernt, wie Sie Webseiten in Perl mit den folgenden Modulen scrapen können:
LWP::UserAgentundHTML::TreeBuilderWeb::ScraperMojo::UserAgentundMojo::DOMXML::LibXML
Wie Sie jedoch gesehen haben, steht Web-Scraping in realen Szenarien vor vielen Herausforderungen, wenn Website-Betreiber entschlossen sind, Scraper am Scraping zu hindern. Dieser Artikel beleuchtet einige häufige Szenarien und wie man ihnen begegnen kann. Es kann jedoch mühsam und fehleranfällig sein, diese Herausforderungen selbst zu lösen. Hier kannBright Datahelfen. Mit den besten Proxy-Diensten, einemScraping-Browser,einem Web Unlocker und der ultimativen Web-Scraper-API ist Bright Data eine umfassende Lösung für einfaches Web-Scraping. Testen Sie Bright Data noch heute gratis!





