

Web-Scraping ist der Prozess der Extraktion von Inhalten und Daten aus Websites mithilfe von Skripten oder automatisierten Softwaretools. Die extrahierten Informationen werden dann in der Regel in ein nützlicheres Format wie eine Rohdatei oder CSV exportiert, um sie leichter nutzen zu können.
Wenn Sie Ihre Web-Scraping-Workflows vereinfachen möchten, istGoogle Sheetsgenau das Richtige für Sie. Es handelt sich um ein beliebtes Datenmanagement-Tool, das sich hervorragend zum Scraping strukturierter oder tabellarischer Daten von Websites sowie zur Analyse oder Visualisierung Ihrer Daten eignet. Sie können es beispielsweise verwenden, um Produktdetails und Preise von E-Commerce-Websites abzurufen oder Kontaktinformationen aus Unternehmensverzeichnissen zu extrahieren. Es ist auch hilfreich, um die Interaktion in sozialen Medien zu verfolgen oder öffentliche Stimmungsanalysen durchzuführen, um die Wirksamkeit von Kampagnen zu messen.
In diesem Tutorial erfahren Sie, wie Sie Google Sheets für das Web-Scraping einrichten und verwenden.
Einrichten Ihrer Google Tabellen
Um mit dem Web-Scraping mit Google Sheets zu beginnen, müssen Sie ein neues Google Sheet erstellen, indem Sie zuhttps://sheets.google.comnavigieren und auf die Schaltfläche+klicken:
In diesem Tutorial wird gezeigt, wie Sie Buchpreisinformationen von derWebsite„Books to Scrape“ scrapen können. Sie können jedoch auch eine andere Website verwenden, indem Sie die folgende URL und die Abfragen entsprechend anpassen.
Google Sheets-Formeln verstehen
Google Sheets unterstützt zahlreicheZellformeln, die für eine Vielzahl von Vorgängen verwendet werden können, darunter auch Web-Scraping. Schauen wir uns einmal an, wie einige dieser Formeln funktionieren.
IMPORTXML
Mit der FunktionIMPORTXMLkönnen Sie strukturierte Daten abfragen und in Google Sheets importieren. Sie unterstützt die Dateiformate XML, HTML, CSV und TSV. Die Syntax der Funktion lautet wie folgt:
=IMPORTXML(url, xpath_query)
Die Funktion importiert Daten aus der angegebenen Web-URL und verwendet denXPath-Locator, um das relevante Element auf der Webseite zu finden. Sie können beispielsweise dieH1-Überschriftvon der Website„Books to Scrape“abrufen, indem Sie die folgende Formel in eine Google Sheets-Zelle einfügen:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//h1")
Bei der ersten Verwendung fordert Google Sheets Sie auf, den Zugriff zu aktivieren, bevor Daten von Websites Dritter abgerufen werden können:
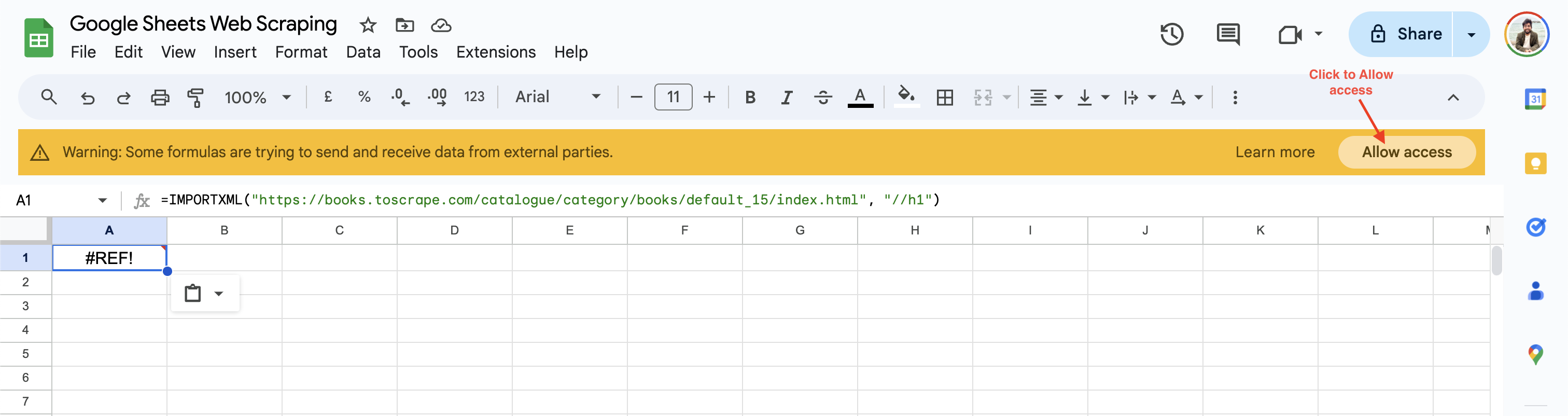
Sobald Sie auf „Zugriff zulassen“ klicken, löst Google Sheets den Wert der Zelle in die H1-Überschrift der Webseite „Default“ auf.
IMPORTHTML
Mit der Funktion IMPORTHTML können Sie Daten aus einer Tabelle oder einer Liste auf einer HTML-Seite importieren. Die Syntax der Funktion lautet wie folgt:
=IMPORTHTML(URL, Abfrage, Index)
Diese Funktion importiert die Daten aus der URL in das Blatt basierend auf der angegebenen Abfrage. Das Abfrageattribut kann je nach Art der zu importierenden Daten entweder auf eine Liste oder eine Tabelle gesetzt werden. Der Index beginnt bei 1 und bestimmt, welche Tabelle oder Liste importiert werden soll. Mit dieser Formel können Sie beispielsweise die Liste der Bücher aus „Books to Scrape“ abrufen:
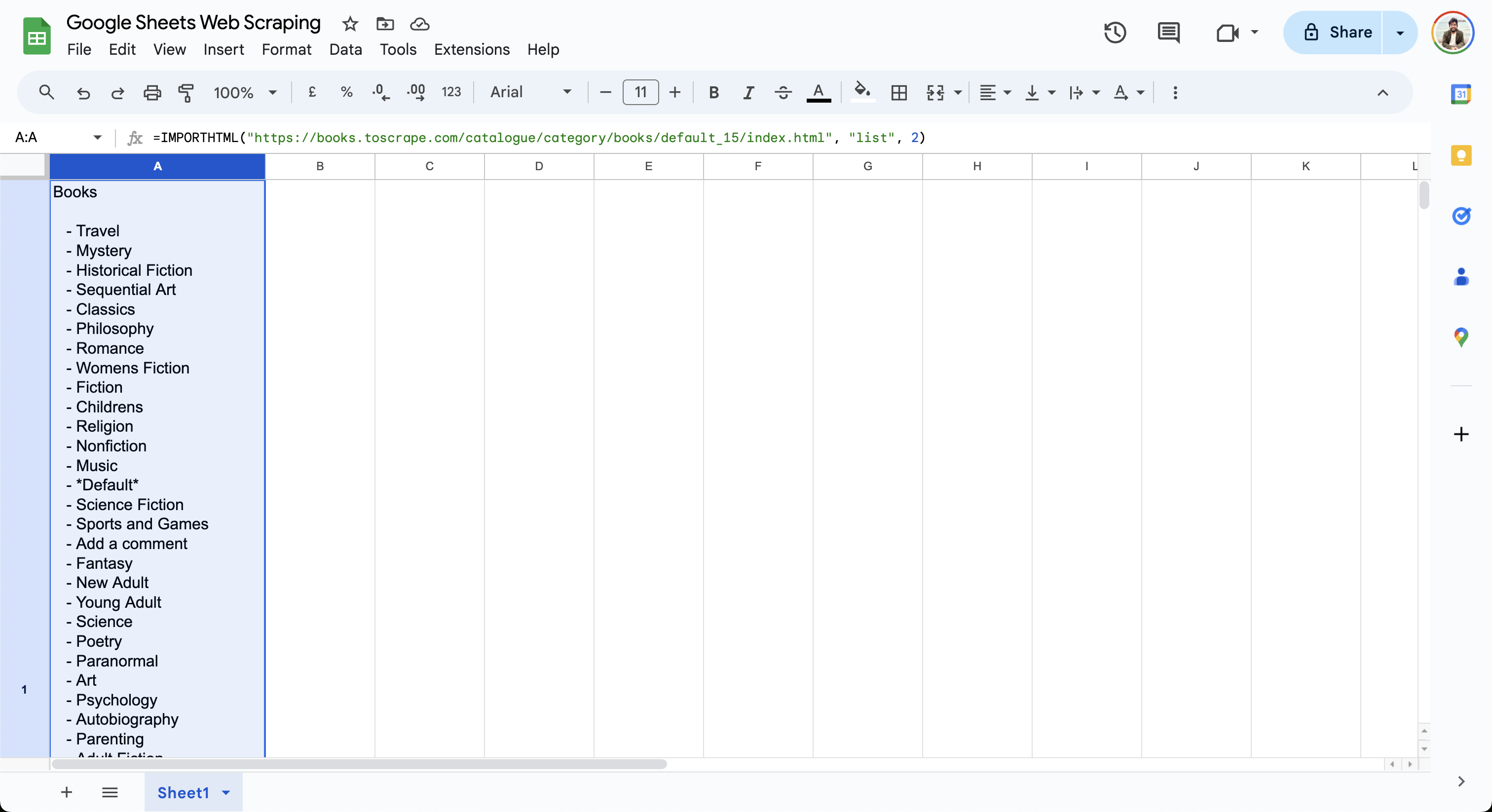
=IMPORTHTML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "list", 2)
Diese Formel gibt die Liste der Bücher in der aktuellen Zelle aus, wie hier gezeigt:
Wie Sie sehen, sind die FormelnIMPORTXMLundIMPORTHTMLeinfach zu verwenden und ermöglichen es Ihnen, mit einfachen Abfragen Daten von einer Webseite zu scrapen. Für komplexere Anwendungsfälle lesen Sie diesen Leitfaden, in dem die Verwendung von VBA und Selenium für das Web-Scraping in Excel erläutert wird.
Extrahieren von Daten mit IMPORTXML
Im vorherigen Abschnitt haben Sie die grundlegende Verwendung vonIMPORTXMLzum Abrufen von Seitenüberschriften durch Angabe des entsprechenden XPath-Attributs kennengelernt. Das XPath-Attribut ist sehr leistungsfähig und ermöglicht es Ihnen, zu jedem Element einer Webseite zu navigieren, unabhängig von dessen Hierarchie. Im folgenden Abschnitt verwenden SieIMPORTXML, um den Titel, den Preis und die Bewertung aller Bücher aufdieserWebseite„Books to Scrape“abzurufen.
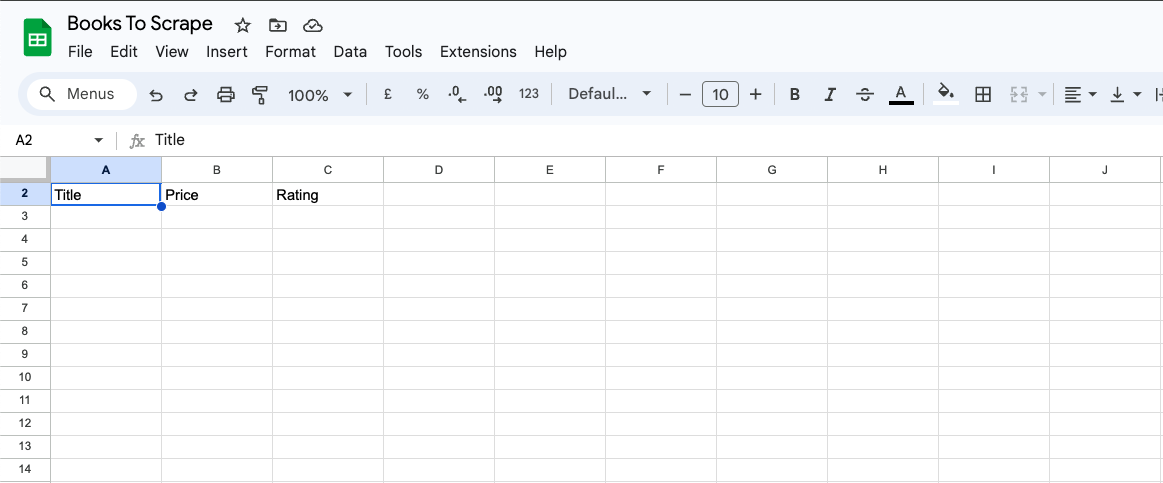
Fügen Sie zunächst die Spalten „Titel“, „Preis“ und „Bewertung“ in Google Sheets hinzu:
Um den Buchtitel aus „Books to Scrape“ abzurufen, benötigen Sie dessen XPath-Position, die Sie mit dem Inspektions werkzeug des Browsers finden können. Um den XPath für den Buchtitel zu finden, klicken Sie mit der rechten Maustaste auf den Titel des ersten Buches und klicken Sie auf „Inspizieren“. Klicken Sie dann auf „Kopieren“ > „XPath“, um den XPath-Locator zu kopieren:
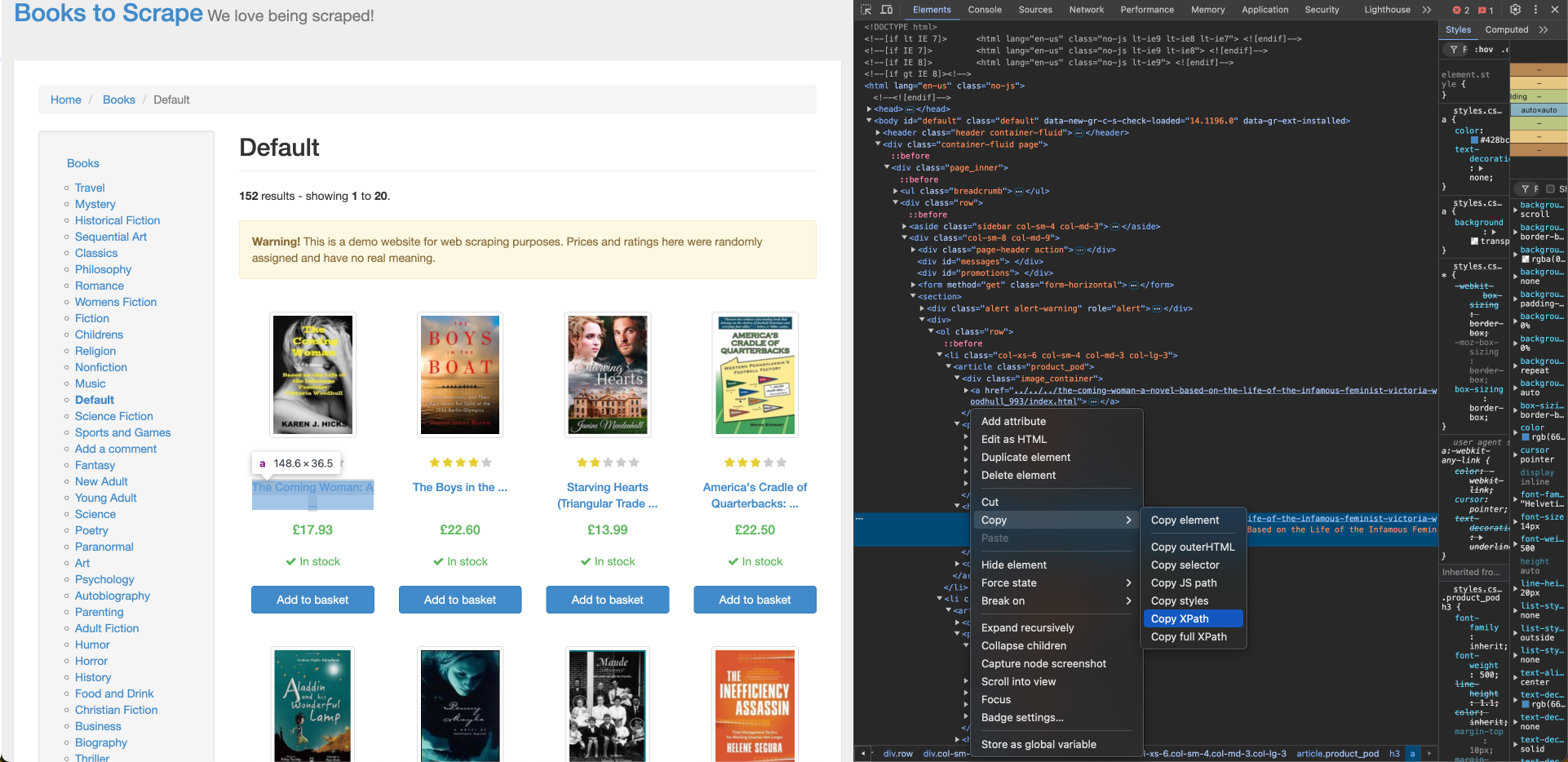
Der XPath für den Titel des ersten Buches entspricht einem Anker-Tag (a) und sieht in etwa so aus:
//*[@id="default"]/div/div/div/div/section/div[2]/ol/li[1]/article/h3/a
Sie müssen einige Anpassungen am XPath vornehmen, um sicherzustellen, dass der Buchtitel für alle Bücher in der Liste korrekt importiert wird:
- Der XPath enthält
li[1]im Pfad, was bedeutet, dass das erste Buch ausgewählt ist. Ersetzen Sie es durchli, um alle Elemente abzurufen. - Der innere Inhalt des
a-Tagsenthält einen abgeschnittenen Buchtitel, aber dasa-Tag enthält einTitelattributmit dem vollständigen Buchtitel. Ändern Sie dasaim XPath ina/@title, um das Titelattribut zu verwenden. - Ersetzen Sie alle doppelten Anführungszeichen innerhalb des XPath durch einfache Anführungszeichen, um Escape-Probleme in der Formel zu vermeiden.
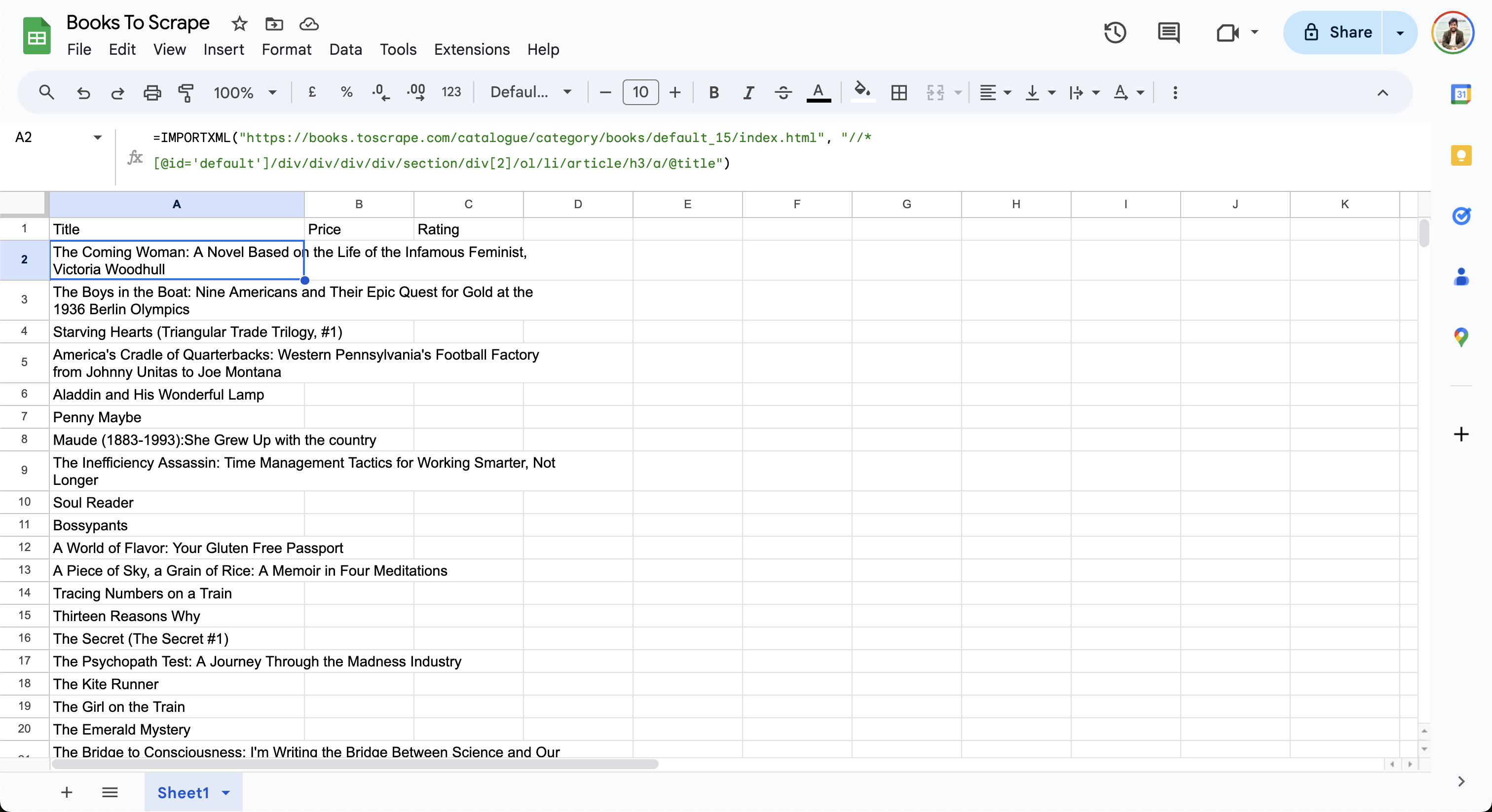
Nachdem Sie den XPath angepasst haben, fügen Sie die folgende Formel mit dem aktualisierten XPath in die Zelle A2 Ihres Google Sheets ein:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/h3/a/@title")
Das Blatt importiert Daten aus der Webseite und aktualisiert die Zeilen wie folgt:
Erstellen Sie als Nächstes den XPath für den Preis und fügen Sie ihn in die Zelle B2 in Google Sheet ein:
=IMPORTXML("https://books.toscrape.com/catalogue/category/books/default_15/index.html", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/div[2]/p[1]")
Suchen Sie schließlich den XPath für die Bewertung und fügen Sie ihn in die Zelle C2 des Google-Sheets ein:
=IMPORTXML("https://books.toscrape.com/", "//*[@id='default']/div/div/div/div/section/div[2]/ol/li/article/p/@class")
Die endgültigen Daten in der Tabelle sehen wie folgt aus:
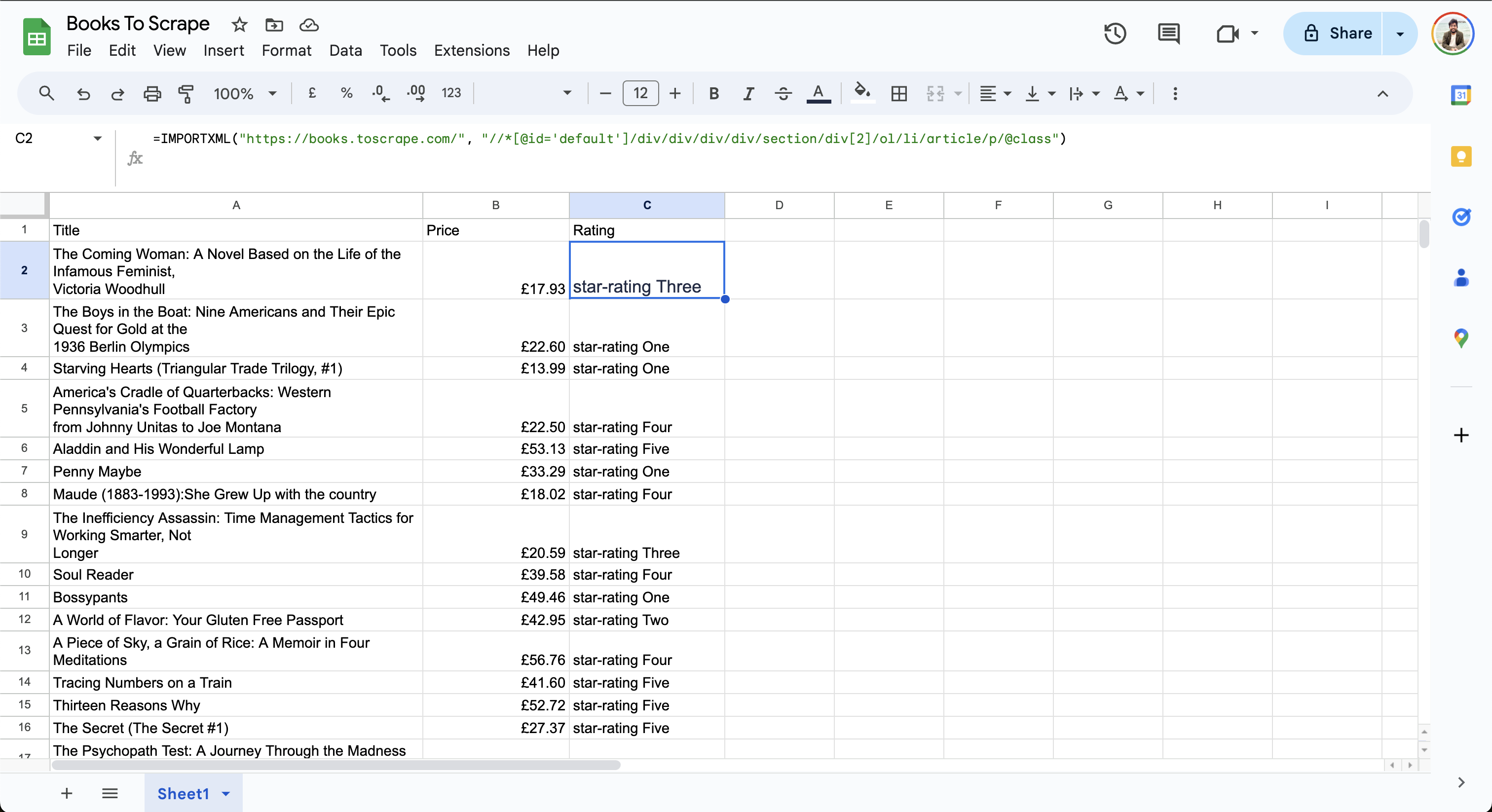
Beachten Sie, dass in der Spalte„Bewertung“die SternebewertungDreioderVier angezeigt wird. DaXPath 2.0von Google Sheets noch nicht unterstützt wird, können Sie die Daten nicht bearbeiten, um die Ausgabe zu vereinfachen.
Umgang mit komplexen Webseiten
Während Google Sheets für einfache Scraping-Aufgaben gut geeignet ist, kann das Scraping zu einer Herausforderung werden, wenn die Zielwebsite dynamische Inhalte und Paginierung enthält oder wenn Klick-Interaktionen erforderlich sind. Wenn Ihre Webseite beispielsweise Inhalte asynchron mit JavaScript lädt, können die FormelnIMPORTXMLundIMPORTHTMLvon Google Sheets keine Daten daraus extrahieren, da sie nur statische Webseiten unterstützen. Wenn der Inhalt auf Benutzerinteraktionen wie Klicken, Tippen oder Scrollen basiert, können diese Formeln die Daten ebenfalls nicht scrapen. Wenn Sie dynamische Inhalte scrapen möchten, können Sie ein Skript schreiben, das einen Headless-Browser wie Selenium verwendet.
Google Sheets kann auch paginierte Extraktionsaufgaben nicht automatisch verarbeiten. Sie können zwar die IMPORTXML-Formel manuell nach der letzten Zeile mit einer aktualisierten URL hinzufügen, diese Methode ist jedoch nicht skalierbar, da der Vorgang für jede Seite wiederholt werden muss.
Wenn Sie nach fortgeschritteneren Anwendungsfällen suchen, wie z. B. der Verarbeitung dynamischer Inhalte oder großer Datenmengen, sollten Sie die Produkte von Bright Data für eine effiziente Datenextraktion in Betracht ziehen. Bright Data bietet eine einheitliche Web-Scraping-API für alle Datenextraktionsaufgaben und kümmert sich um die Komplexität von Proxys, CAPTCHAs und User-Agents. Die API verarbeitet Massenanfragen, Parsing und Validierung, sodass Sie schneller bereitstellen und skalieren können. Darüber hinaus bietet sie eine große Sammlung vorgefertigter Datensätze vonbeliebten Websites wieLinkedInundZillow, die in Ihre bestehenden Workflows integriert werden können, wodurch der Aufwand für die Pflege der Scraping-Skripte reduziert wird.
Automatisierung der Datenaktualisierung in Google Sheets
Für einige Scraping-Aufgaben, wie die Verfolgung von Preisen oder Social-Media-Aktivitäten, müssen Sie die gescrapeten Daten in regelmäßigen Abständen automatisch aktualisieren, um sicherzustellen, dass Sie für Analysen und Entscheidungen auf genaue Daten zugreifen können.
Um das Berechnungsintervall in Google Sheets festzulegen, müssen Sie lediglich auf „Datei“ > „Einstellungen“ klicken und zur Registerkarte „Berechnung“ navigieren:
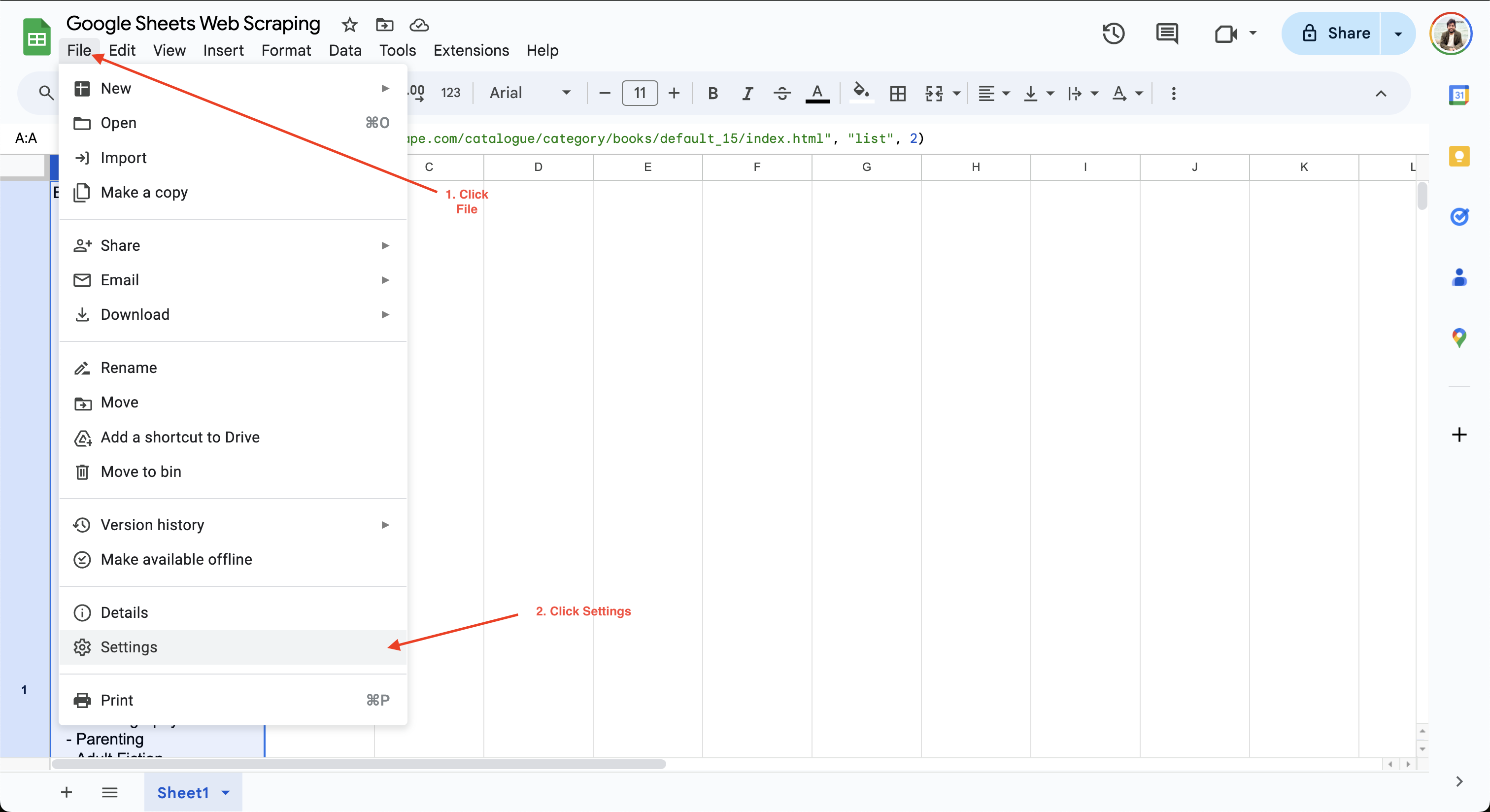
Anschließend können Sie das Berechnungsintervall auf entweder eine Minute oder eine Stunde aktualisieren. In diesem Beispiel wird die Einstellung „Neuberechnung“ auf „Bei Änderung“ und „Jede Minute“ aktualisiert, um sicherzustellen, dass die Daten jede Minute automatisch aktualisiert werden:
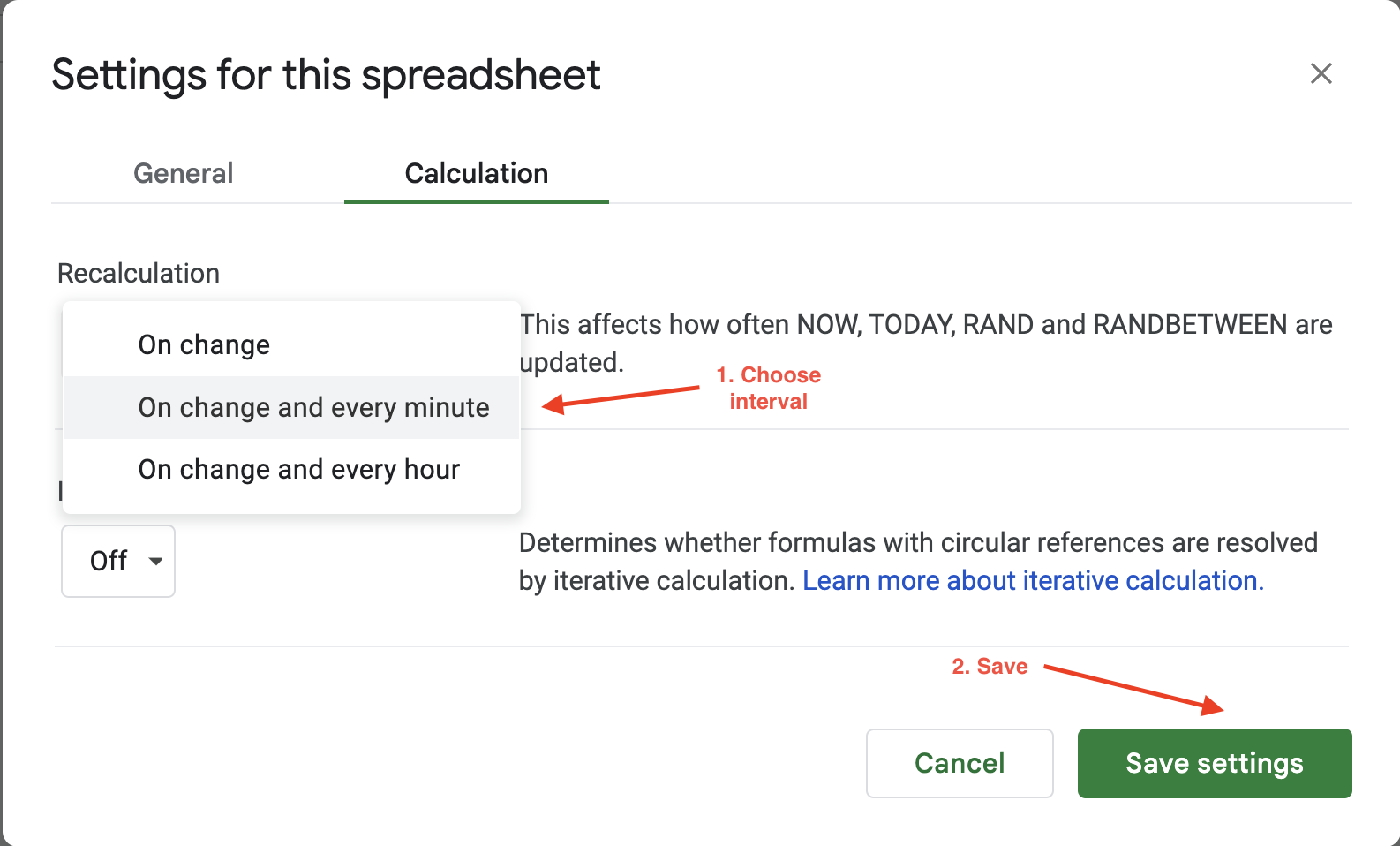
Die automatischen Aktualisierungsoptionen von Google Sheets bieten nur begrenzte Flexibilität bei der Konfiguration der Aktualisierungshäufigkeit oder der Auslöser, da Sie nur zwischen zwei Werten wählen können: stündlich oder jede Minute. Wenn Sie mehr Flexibilität wünschen, bietet Bright Data saubere, validierte und aktuelle Datensätze in verschiedenen Dateiformaten wie JSON, CSV und Parquet. Daher eignet es sich ideal für umfangreiche Scraping-Aufgaben, die sonst die Wartung einer umfangreichen Infrastruktur erfordern würden.
Implementierung von Best Practices und Fehlerbehebung
Wenn Sie die Effizienz Ihres Scrapings verbessern möchten, sollten Sie die zu extrahierenden Daten sorgfältig auswählen. Der Versuch, unnötige Daten zu scrapen, kann Ihren Prozess verlangsamen und die Belastung der Zielwebsite erhöhen.
Wenn Sie große Datenmengen scrapen möchten, fügen Sie künstliche Verzögerungen zwischen den Anfragen ein und erwägen Sie, Aufgaben außerhalb der Spitzenzeiten auszuführen, um sicherzustellen, dass die Website nicht mit unerwartetem Traffic überlastet wird. Hoher Traffic kann zu IP-Sperren oder Ratenbegrenzungen führen, wodurch Sie Ihre Scraping-Aufgabe nicht fortsetzen können. Erfahren Sie mehr über das Scraping von Websites, ohne blockiert zu werden.
Neben IP-Sperren ist dieCAPTCHA-Prüfungeine weitere gängige Anti-Bot-Technik, die von Websites eingesetzt wird, um den Zugriff auf Inhalte zu beschränken, bis der Benutzer bestätigt, dass er ein Mensch ist. Erwägen Sie die Verwendung derBright Data Residential-Proxysfür fortgeschrittene Scraping-Aufgaben, die von IP-Rotation und automatischen CAPTCHA-Lösern profitieren würden.
Bevor Sie Daten scrapen, müssen Sie auch die Nutzungsbedingungen der Website überprüfen, um die Einhaltung sicherzustellen. Ihre Skripte sollten den Anweisungen in der Dateirobot.txtfür die Interaktion mit der Website folgen. Indiesem Leitfadenerfahren Sie mehr über die Verwendung derrobot.txt-Regelnfür das Web-Scraping.
Fazit
Google Sheets eignet sich gut zum Scraping von Daten aus statischen Websites, die keine dynamischen Inhalte, versteckten Elemente oder Paginierung enthalten. In diesem Artikel haben Sie gelernt, wie Sie Datenauszugsaufgaben mit den Formeln IMPORTXML und IMPORTHTML ganz einfach automatisieren können, ohne vorherige Skripting-Erfahrung zu haben.
Für komplexe Web-Scraping-Aufgaben mit dynamischen Inhalten oder großen Datenmengen bietetBright Databenutzerfreundliche, flexible, skalierbare und leistungsstarke APIs zum Scraping von Webdaten in verschiedenen Formaten, darunter JSON, CSV oder NDJSON. Im Hintergrund bewältigt es die Komplexität des Scrapings, indem es sich um die Rotation von IP-Adressen und User-Agents, CAPTCHAs und dynamische Inhalte kümmert. Wenn Sie bereit sind, Ihr Web-Scraping auf die nächste Stufe zu heben, sollten Sie die beste Web-Scraper-API ausprobieren.
Melden Sie sich noch heute an, um die Gratis-Testversion zu nutzen und mit der Optimierung Ihrer Daten-Workflows zu beginnen!





