

In diesem Leitfaden erfahren Sie mehr:
- Was Ferret ist und was es als deklarative Web Scraping Bibliothek bietet
- So konfigurieren Sie es für die lokale Verwendung in einer Go-Umgebung
- Wie man damit Daten von einer statischen Website sammelt
- Wie man damit eine dynamische Website scrapen kann
- Die wichtigsten Einschränkungen von Ferret und wie man sie umgehen kann
Lasst uns eintauchen!
Einführung in Ferret für Web Scraping
Bevor Sie es in Aktion sehen, erfahren Sie, was Ferret ist, wie es funktioniert, was es bietet und wann es eingesetzt werden sollte.
Was ist ein Frettchen?
Ferret ist eine in Go geschriebene Open-Source-Bibliothek für Web-Scraping. Ihr Ziel ist es, die Datenextraktion aus Webseiten mithilfe eines deklarativen Ansatzes zu vereinfachen. Insbesondere abstrahiert sie die technischen Komplexitäten des Parsens und der Extraktion, indem sie eine eigene deklarative Sprache verwendet: die Ferret Query Language (FQL).
Mit fast 6k Sternen auf GitHub ist Ferret eine der beliebtesten Web-Scraping-Bibliotheken für Go. Sie ist einbettbar und unterstützt sowohl statisches als auch dynamisches Web Scraping.
FQL: Die Ferret-Abfragesprache für deklaratives Web-Scraping
Die Ferret Query Language (FQL) ist eine allgemeine Abfragesprache, die sich stark an der AQL von ArangoDB orientiert. Obwohl sie mehr kann, wird FQL hauptsächlich für die Extraktion von Daten aus Webseiten verwendet.
FQL verfolgt einen deklarativen Ansatz, d. h. es geht darum, welche Daten abgerufen werden sollen und nicht darum , wie sie abgerufen werden. Wie AQL weist es Ähnlichkeiten mit SQL auf. Aber im Gegensatz zu AQL ist FQL streng schreibgeschützt. Beachten Sie, dass jede Form der Datenmanipulation mit speziellen eingebauten Funktionen durchgeführt werden muss.
Weitere Informationen über FQL-Syntax, Schlüsselwörter, Konstrukte und unterstützte Datentypen finden Sie auf der FQL-Dokumentationsseite.
Anwendungsfälle
Wie auf der offiziellen GitHub-Seite hervorgehoben wird, gehören zu den Hauptanwendungsfällen von Ferret:
- UI-Tests: Automatisieren Sie das Testen von Webanwendungen, indem Sie Browser-Interaktionen simulieren und das korrekte Verhalten und die korrekte Darstellung von Seitenelementen in verschiedenen Szenarien überprüfen.
- Maschinelles Lernen: Extrahieren Sie strukturierte Daten aus Webseiten und verwenden Sie diese, um hochwertige Datensätze zu erstellen. Diese können dann verwendet werden, um Modelle für maschinelles Lernen effektiver zu trainieren oder zu validieren. Sehen Sie, wie Sie Web Scraping für maschinelles Lernen nutzen können.
- Analytik: Scrapen und aggregieren Sie Webdaten wie Preise, Bewertungen oder Nutzeraktivitäten, um Erkenntnisse zu gewinnen, Trends zu verfolgen oder Dashboards zu erstellen.
Gleichzeitig sollten Sie bedenken, dass die möglichen Anwendungsfälle für Web Scraping weit über diese Beispiele hinausgehen.
Erste Schritte mit Ferret
Nun, da Sie wissen, was Ferret ist, können Sie es sowohl auf statischen als auch auf dynamischen Webseiten in Aktion sehen. Wenn Sie mit dem Unterschied zwischen den beiden nicht vertraut sind, lesen Sie unseren Leitfaden über statische und dynamische Inhalte beim Web Scraping.
Richten wir eine Umgebung ein, um Ferret für Web Scraping zu verwenden!
Voraussetzungen
Vergewissern Sie sich, dass Sie Folgendes auf Ihrem lokalen Rechner installiert haben:
- Weiter
- Docker
Um zu überprüfen, ob Golang installiert und bereit ist, führen Sie den folgenden Befehl im Terminal aus:
go versionSie sollten eine ähnliche Ausgabe wie die folgende erhalten:
go version go1.24.3 windows/amd64Wenn Sie eine Fehlermeldung erhalten, installieren Sie Golang und konfigurieren Sie es für Ihr Betriebssystem.
Vergewissern Sie sich ebenfalls, dass Docker installiert und ordnungsgemäß für Ihr System konfiguriert ist.
Erstellen Sie das Frettchen-Projekt
Erstellen Sie nun einen Ordner für Ihr Ferret-Web-Scraping-Projekt und navigieren Sie in diesen Ordner:
mkdir ferret-web-scraping
cd ferret-web-scrapingLaden Sie das Ferret CLI für Ihr Betriebssystem herunter und entpacken Sie es direkt in den Ordner ferret-web-scraping/. Überprüfen Sie, ob es funktioniert, indem Sie es ausführen:
./ferret helpDie Ausgabe sollte sein:
Usage:
ferret [flags]
ferret [command]
Available Commands:
browser Manage Ferret browsers
config Manage Ferret configs
exec Execute a FQL script or launch REPL
help Help about any command
update
version Show the CLI version information
Flags:
-h, --help help for ferret
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
Use "ferret [command] --help" for more information about a command.Öffnen Sie dann den Projektordner in Ihrer bevorzugten IDE, z. B. in Visual Studio Code. Erstellen Sie innerhalb des Projektordners eine Datei namens scraper.fql:
ferret-web-scraping/
├── ferret
├── CHANGELOG.md
├── LICENSE
├── README.md
└── scraper.fql # <-- The FQL file for web scraping in Ferretscraper.fql enthält Ihre deklarative FQL-Logik für Web Scraping.
Konfigurieren Sie das Ferret Docker Setup
Um alle Ferret-Funktionen nutzen zu können, müssen Sie Chrome oder Chromium lokal installiert haben oder in Docker ausführen. In den offiziellen Dokumenten wird empfohlen, Chrome/Chromium in einem Docker-Container auszuführen.
Sie können ein beliebiges Chromium-basiertes Headless-Image verwenden, aber das montferret/chromium-Image wird empfohlen. Rufen Sie es mit ab:
docker pull montferret/chromiumStarten Sie dann das Docker-Image mit diesem Befehl:
docker run -d -p 9222:9222 montferret/chromiumHinweis: Wenn Sie sehen möchten, was während der Ausführung Ihrer FQL-Skripte im Browser passiert, starten Sie Chrome auf Ihrem Host-Rechner mit aktiviertem Remote-Debugging mit:
chrome.exe --remote-debugging-port=9222Scrapen einer statischen Website mit Ferret
Führen Sie die folgenden Schritte aus, um zu erfahren, wie Sie Ferret zum Scrapen einer statischen Website verwenden können. In diesem Beispiel wird die Zielseite die Sandbox-Site “Books to Scrape” sein:
Das Ziel ist es, Schlüsselinformationen aus jedem Buch auf der Seite zu extrahieren, indem der deklarative Ansatz von Ferret über FQL verwendet wird.
Schritt 1: Verbinden Sie sich mit der Zielsite
Verwenden Sie in scraper.fql die Funktion DOCUMENT, um eine Verbindung mit der Zielseite herzustellen:
LET doc = DOCUMENT("https://books.toscrape.com/")LET ermöglicht es Ihnen, eine Variable in FQL zu definieren. Nach dieser Anweisung wird doc den HTML-Code der Zielseite enthalten.
Schritt #2: Alle Buchelemente auswählen
Machen Sie sich zunächst mit der Struktur der Ziel-Webseite vertraut, indem Sie sie in Ihrem Browser besuchen und inspizieren. Klicken Sie dazu mit der rechten Maustaste auf ein Buchelement und wählen Sie die Option “Inspect”, um die DevTools zu öffnen:
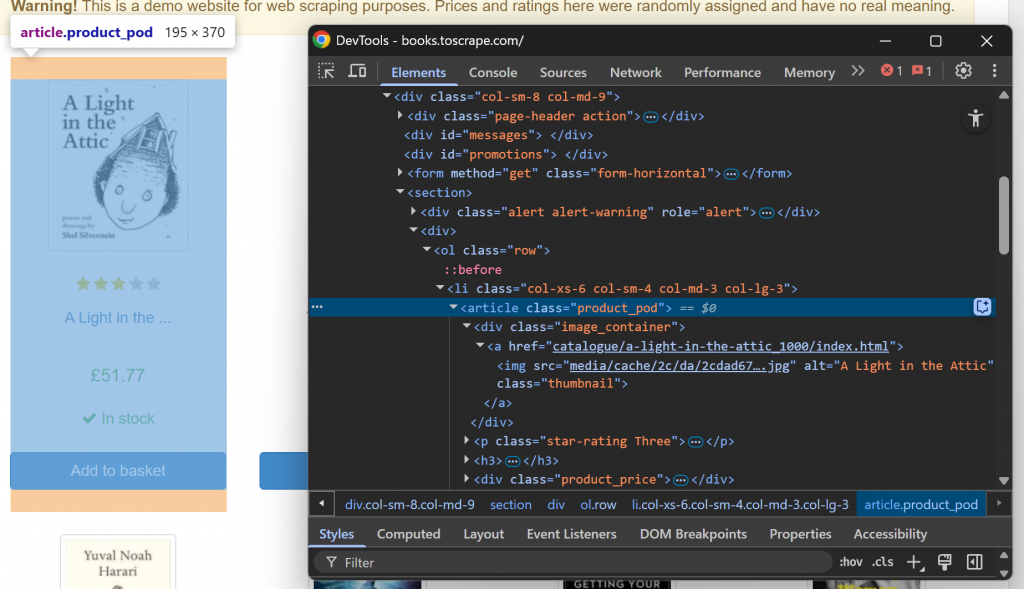
Beachten Sie, dass jedes Buchelement ein
. Wählen Sie alle Bücher-Elemente mit der Funktion ELEMENTS() aus:
LET book_elements = ELEMENTS(doc, "section article")ELEMENTS() wendet den als zweites Argument übergebenen CSS-Selektor auf das Dokument an. Mit anderen Worten, sie wählt die gewünschten HTML-Elemente auf der Seite aus.
Iterieren Sie über die Liste der ausgewählten Elemente und bereiten Sie die Anwendung der Scraping-Logik auf sie vor:
FOR book_element IN book_elements
// book scraping logic...Erstaunlich! Es ist an der Zeit, jedes Buchelement zu durchlaufen und Daten aus jedem Element zu extrahieren.
Schritt #3: Extrahieren Sie Daten aus jedem Angebot
Prüfen Sie nun ein einzelnes HTML-Book-Element:
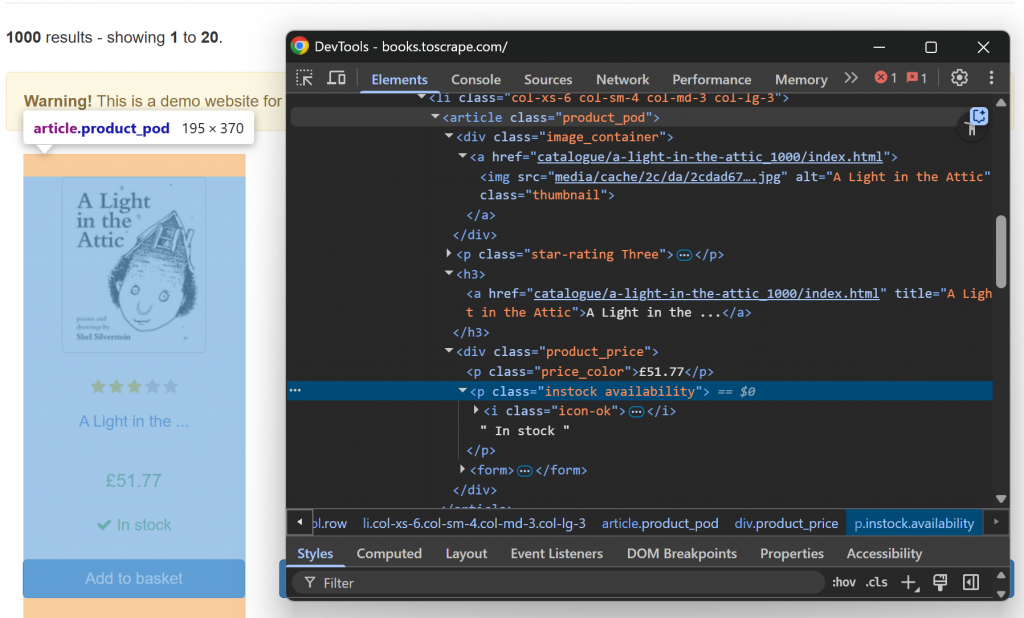
Beachten Sie, dass Sie kratzen können:
- Die Bild-URL aus dem
src-Attributdes Elements.image_container img. - Der Buchtitel aus dem Attribut
titledes Elementsh3 a. - Die URL zur Buchseite aus dem
href-Attributdesh3 a-Knotens. - Der Buchpreis aus dem Text von
.price_color. - Die Verfügbarkeitsinformationen aus dem Text von
.instock.
Implementieren Sie diese Logik der Datenanalyse mit:
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Dabei ist base_url eine Variable, die außerhalb der for-Schleife definiert ist:
LET base_url = "https://books.toscrape.com/"Im obigen Code:
- Mit
ELEMENT()können Sie ein einzelnes Element auf der Seite mithilfe eines CSS-Selektors auswählen. attributesist ein spezielles Attribut, das alle vonELEMENT()zurückgegebenen Objekte haben. Es enthält die Werte der HTML-Attribute des aktuellen Elements.INNER_TEXT()gibt den im aktuellen Element enthaltenen Text zurück.TRIM()entfernt führende und nachgestellte Leerzeichen.
Fantastisch! Die Logik des statischen Scrappings ist abgeschlossen.
Schritt #4: Alles zusammenfügen
Ihre scraper.fql-Datei sollte wie folgt aussehen:
// connect to the target site
LET doc = DOCUMENT("https://books.toscrape.com/")
// select the book HTML elements
LET book_elements = ELEMENTS(doc, "section article")
// the base URL of the target site
LET base_url = "https://books.toscrape.com/"
// iterate over each book element and apply the scraping logic
FOR book_element IN book_elements
// select all info elements
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
// scrape the data of interest
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Wie Sie sehen können, konzentriert sich die Scraping-Logik eher darauf, welche Daten zu extrahieren sind, als darauf, wie sie zu extrahieren sind. Das ist die Stärke des deklarativen Web Scraping mit Ferret!
Schritt #5: Ausführen des FQL-Skripts
Führen Sie Ihr Ferret-Skript mit aus:
./ferret exec scraper.fqlIm Terminal wird die Ausgabe sein:
[{"availability":"In stock","book_url":"catalogue/a-light-in-the-attic_1000/index.html","image_url":"https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg","price":"£51.77","title":"https://books.toscrape.com/A Light in the Attic"},{"availability":"In stock","book_url":"catalogue/tipping-the-velvet_999/index.html","image_url":"https://books.toscrape.com/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg","price":"£53.74","title":"https://books.toscrape.com/Tipping the Velvet"},
// omitted for brevity...
,{"availability":"In stock","book_url":"catalogue/its-only-the-himalayas_981/index.html","image_url":"https://books.toscrape.com/media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg","price":"£45.17","title":"https://books.toscrape.com/It's Only the Himalayas"}]Dies ist eine JSON-Zeichenkette, die alle Buchdaten enthält, die wie vorgesehen von der Webseite gesammelt wurden. Einen nicht-deklarativen Ansatz für das Parsen von Daten finden Sie in unserem Leitfaden zum Web Scraping mit Go.
Mission erfüllt!
Scrapen einer dynamischen Website mit Ferret
Ferret unterstützt auch das Scrapen dynamischer Websites, die die Ausführung von JavaScript erfordern. In diesem Abschnitt des Leitfadens wird die Zielsite die JavaScript-verzögerte Version der “Quotes to Scrape”-Site sein:

Die Seite verwendet JavaScript, um Zitatelemente nach einer kurzen Verzögerung dynamisch in das DOM einzufügen. Dieses Szenario erfordert die Ausführung von JavaScript, weshalb die Seite in einem Browser gerendert werden muss. (Das ist auch der Grund, warum wir zuvor einen Chromium-Docker-Container eingerichtet haben).
Führen Sie die folgenden Schritte aus, um zu lernen, wie man dynamische Webseiten mit Ferret!
Schritt 1: Verbinden mit der Zielseite im Browser
Verwenden Sie die folgenden Zeilen, um über einen Headless-Browser eine Verbindung mit der Zielseite herzustellen:
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})Beachten Sie die Verwendung des Feldes driver in der Funktion DOCUMENT(). Dadurch wird Ferret angewiesen, die Seite in der über Docker konfigurierten headless Chroumium-Instanz zu rendern.
Schritt #2: Warten Sie, bis die Zielelemente auf der Seite sind
Rufen Sie die Zielseite in Ihrem Browser auf, warten Sie, bis die Zitatelemente geladen sind, und prüfen Sie eines von ihnen:
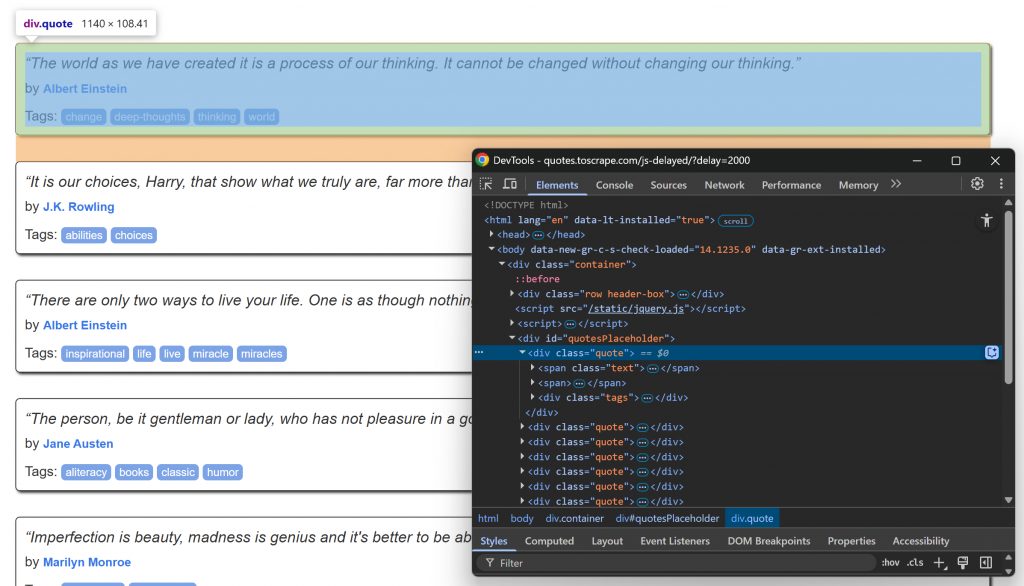
Beachten Sie, dass die Zitatelemente mit dem CSS-Selektor .quote ausgewählt werden können. Diese Zitatelemente werden nach einer kurzen Verzögerung über JavaScript gerendert, Sie müssen also darauf warten.
Verwenden Sie die Funktion WAIT_ELEMENT() in Ferret, um zu warten, bis die Zitatelemente auf der Seite erscheinen:
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)Dies ist ein wesentliches Konstrukt, das beim Scraping dynamischer Webseiten, die zur Darstellung von Inhalten auf JavaScript angewiesen sind, verwendet wird.
Schritt #3: Anwendung der Scraping-Logik
Konzentrieren Sie sich nun auf die HTML-Struktur der Info-Elemente innerhalb eines .quote-Knotens:
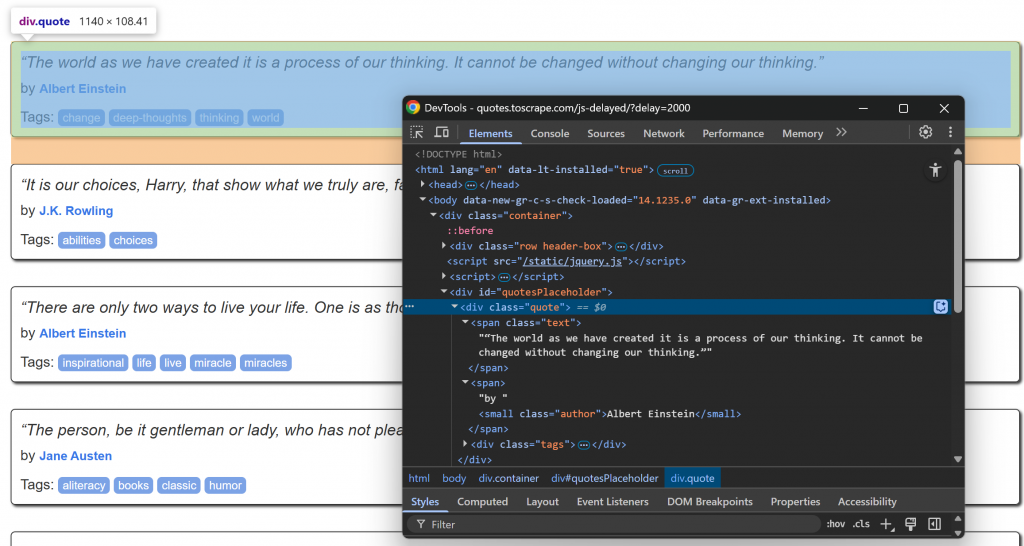
Beachten Sie, dass Sie kratzen können:
- Der Anführungstext von
.quote - Der Autor von
.author
Implementieren Sie die Ferret Web Scraping Logik mit:
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
} Wahnsinn! Parsing-Logik abgeschlossen.
Schritt #4: Alles zusammenbauen
Die Datei scraper.fql sollte enthalten:
// connect to the target site via the Chromium headless instance
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}Wie Sie sehen, unterscheidet sich dies nicht wesentlich von dem Skript für eine statische Website. Auch hier liegt der Grund darin, dass Ferret einen deklarativen Ansatz für Web Scraping verwendet.
Schritt 5: Ausführen des FQL-Codes
Führen Sie Ihr Ferret Scraping-Skript mit aus:
./ferret exec scraper.fqlDieses Mal wird das Ergebnis sein:
[{"author":"Albert Einstein","quote":"“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},{"author":"J.K. Rowling","quote":"“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},{"author":"Albert Einstein","quote":"“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”"},{"author":"Jane Austen","quote":"“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"},{"author":"Marilyn Monroe","quote":"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"},{"author":"Albert Einstein","quote":"“Try not to become a man of success. Rather become a man of value.”"},{"author":"André Gide","quote":"“It is better to be hated for what you are than to be loved for what you are not.”"},{"author":"Thomas A. Edison","quote":"“I have not failed. I've just found 10,000 ways that won't work.”"},{"author":"Eleanor Roosevelt","quote":"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"},{"author":"Steve Martin","quote":"“A day without sunshine is like, you know, night.”"}]Et voilà! Das ist genau der strukturierte Inhalt, der von der JavaScript-gerenderten Seite abgerufen wird.
Einschränkungen des deklarativen Web-Scraping-Ansatzes von Ferret
Ferret ist zweifellos ein leistungsfähiges Tool und eines der wenigen, das einen deklarativen Ansatz für Web Scraping verfolgt. Dennoch hat es mindestens drei große Nachteile:
- Schlechte Dokumentation und unregelmäßige Aktualisierungen: Die offizielle Dokumentation enthält zwar hilfreiche Texte, aber es fehlt an umfassenden API-Referenzen. Das macht es schwierig, komplexe Skripte zu erstellen. Außerdem wird das Projekt nicht regelmäßig aktualisiert, was bedeutet, dass es hinter modernen Scraping-Techniken zurückbleiben kann.
- Keine Unterstützung für Anti-Scraping-Bypass: Ferret bietet keine eingebauten Mechanismen zur Handhabung von CAPTCHAs, Ratenbeschränkungen oder anderen fortschrittlichen Anti-Scraping-Verfahren. Dies macht es ungeeignet für das Scraping geschützterer Websites.
- Begrenzte Ausdruckskraft: FQ, die Ferret Query Language, befindet sich noch in der Entwicklung und bietet nicht das gleiche Maß an Flexibilität oder Kontrolle wie modernere Scraping-Tools wie Playwright oder Puppeteer.
Diese Einschränkungen lassen sich nicht durch einfache Integrationen beheben. Vergessen Sie auch nicht, dass der Schwerpunkt von Ferret auf dem Abruf von Webdaten liegt. Die Lösung besteht also darin, eine robustere Alternative in Betracht zu ziehen.
Die KI-Infrastruktur von Bright Data umfasst eine Reihe fortschrittlicher Services, die auf eine zuverlässige und intelligente Extraktion von Webdaten zugeschnitten sind. Diese ermöglichen es Ihnen, Daten von jeder beliebigen Website in großem Umfang abzurufen.
Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie man Ferret für deklaratives Web Scraping in Go verwendet. Wie gezeigt, können Sie mit dieser Bibliothek Daten sowohl aus statischen als auch aus dynamischen Seiten extrahieren, indem Sie sich darauf konzentrieren, was abgerufen werden soll und nicht, wie es abgerufen werden soll.
Das Problem ist, dass Ferret einige Einschränkungen hat, so dass es nicht unbedingt die beste Lösung ist. Wenn Sie auf der Suche nach einer optimierten und skalierbaren Methode zum Abrufen von Webdaten sind, sollten Sie die Web Scraper APIsin Betracht ziehen – spezielleEndpunkte zum Extrahieren von frischen, strukturierten und vollständig konformen Webdaten von über 120 beliebten Websites.
Melden Sie sich noch heute für ein kostenloses Bright Data-Konto an und testen Sie unsere leistungsstarke Web-Scraping-Infrastruktur!





