In dieser Anleitung erfahren Sie, warum Go eine der besten Sprachen für effizientes Web-Scraping ist und wie Sie mit Go einen Scraper von Grund auf neu erstellen.
In diesem Artikel geht es um Folgendes:
Können Sie Websites mit Go scrapen?
Die besten Bibliotheken für das Web Scraping mit Go.
Erstellen eines Web Scrapers mit Go
Können Sie Websites mit Go scrapen?
Go, auch bekannt unter dem Namen Golang, ist eine statisch typisierte Programmiersprache, die von Google entwickelt wurde. Sie ist so konzipiert, dass sie effizient, nebenläufig, einfach zu schreiben und instandzuhalten ist. Diese Eigenschaften haben Go in letzter Zeit zu einer beliebten Wahl für verschiedene Anwendungen gemacht, unter anderem für das Web Scraping.
Go bietet leistungsstarke Funktionen, die sehr nützlich für das Web Scraping sind. Dazu gehört das integrierte Nebenläufigkeitsmodell, das die gleichzeitige Verarbeitung mehrerer Webanfragen unterstützt. Das macht Go zur idealen Sprache, um große Datenmengen von mehreren Websites zu scrapen. Außerdem enthält die Standardbibliothek von Go HTTP-Client- und HTML-Parsing-Pakete, die zum Abrufen von Websites, Parsen von HTML-Dokumenten und Extrahieren von Daten aus Websites verwendet werden können.
Wenn diese Funktionen und Standardpakete nicht ausreichen oder zu schwierig zu verwenden sind, gibt es weitere Bibliotheken für das Web Scraping mit Go. Werfen wir nun einen Blick auf die beliebtesten!
Die besten Bibliotheken für das Web Scraping mit Go.
Hier finden Sie eine Liste mit einigen der besten Bibliotheken für das Web Scraping mit Go:
Colly: Ein leistungsfähiges Framework für Web Scraping und Crawling mit Go. Colly bietet eine funktionale API für die Erstellung von HTTP-Anfragen, die Verwaltung von Headern und das Parsen der Spezifikation einer Programmierschnittstelle (Document Object Model, DOM). Sie unterstützt auch paralleles Scraping, Ratenbegrenzungen und automatische Cookie-Verarbeitung.
Goquery: Eine beliebte Bibliothek zum Parsen von HTML mit Go, die auf einer jQuery-ähnlichen Syntax basiert. Damit können Sie mithilfe von CSS-Selektoren HTML-Elemente auswählen, das DOM manipulieren und Daten daraus extrahieren.
Selenium: Ein Go-Client des beliebtesten Frameworks zum Testen von Websites. Damit können Sie Webbrowser für verschiedene Aufgaben automatisieren, auch für das Web Scraping. Insbesondere kann Selenium einen Webbrowser steuern und ihn anweisen, mit den Seiten so zu interagieren, wie es ein menschlicher Benutzer tun würde. Er ist auch in der Lage, Websites zu scrapen, die JavaScript zum Abrufen oder Rendern von Daten verwenden.
Voraussetzungen
Bevor Sie beginnen, installieren Sie Go auf Ihrem Computer. Denken Sie daran, dass das Installationsverfahren je nach Betriebssystem unterschiedlich sein kann.
Öffnen Sie die heruntergeladene Datei und folgen Sie den Installationsanweisungen. Das Paket installiert Go in dem Pfad /usr/local/go und fügt /usr/local/go/bin in Ihre UmgebungsvariablePATH ein.
Starten Sie alle Sitzungen neu, die in Ihrem Endgerät noch geöffnet sind.
Starten Sie die MSI-Datei, die Sie heruntergeladen haben, und folgen Sie dem Installationsassistenten. Das Installationsprogramm installiert Go unter C:/Programme oder C:/Programme (x86) und fügt den Ordner bin der Umgebungsvariable PATH hinzu.
Schließen Sie alle Eingabeaufforderungen und öffnen Sie sie erneut.
Vergewissern Sie sich, dass der Ordner /usr/local/go in Ihrem System nicht vorhanden ist. Falls er vorhanden ist, löschen Sie ihn folgendermaßen:
rm -rf /usr/local/go
Entpacken Sie das heruntergeladene Archiv nach /usr/local:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gz
Ersetzen Sie X.Y.Z durch die Version des heruntergeladenen Go-Pakets.
Fügen Sie /usr/local/go/bin in die Umgebungsvariable PATH ein:
export PATH=$PATH:/usr/local/go/bin
Starten Sie Ihren Computer erneut.
Unabhängig von Ihrem Betriebssystem prüfen Sie mit dem folgenden Befehl, ob Go erfolgreich installiert wurde:
go version
Es sollte etwas ähnliches wie das Folgende angezeigt werden:
go version go1.20.3
Gut gemacht! Sie können nun mit Go mit dem Web-Scraping beginnen.
Erstellen eines Web Scrapers mit Go
Hier erfahren Sie, wie Sie mit Go einen Web Scraper erstellen. Dieses automatisierte Skript ist in der Lage, automatisch Daten von der Bright Data-Homepage abzurufen. Beim Web Scraping mit Go sollen HTML-Elemente von der Website ausgewählt, Daten daraus extrahiert und die gescrapten Daten in ein nützlicheres Format konvertiert werden.
Während des Schreibens sieht die Zielwebsite folgendermaßen aus:
Folgen Sie der Schritt-für-Schritt-Anleitung und lernen Sie, wie Sie Websites mit Go scrapen können!
Schritt 1: Erstellen eines Go-Projekts
Es ist an der Zeit, dass Sie Ihr Go-Projekt für das Web Scraping initialisieren. Öffnen Sie das Endgerät und legen Sie den Ordner go-web-scraper an:
mkdir go-web-scraper
Dieses Verzeichnis enthält dann das Go-Projekt.
Als nächstes führen Sie den untenstehenden init-Befehl aus:
go mod init web-scraper
Dadurch wird ein Web-Scraper-Modul im Stammverzeichnis des Projekts initialisiert.
Das Verzeichnis go-web-scraper enthält nun die folgende go.mod-Datei:
module web-scraper
go 1.20
Denken Sie daran, dass die letzte Zeile je nach Ihrer Go-Version unterschiedlich aussieht.
Sie sind nun bereit, die Go-Logik in Ihrer IDE zu schreiben! In dieser Anleitung werden wir Visual Studio Code verwenden. Da es Go nicht nativ unterstützt, müssen Sie zunächst die Go-Erweiterung installieren.
Starten Sie VS Code, klicken Sie in der linken Leiste auf das Symbol „Erweiterungen“ und geben Sie „Go“ ein.
Klicken Sie auf die Schaltfläche „Installieren“ auf der ersten Karte, um die Erweiterung Go für Visual Studio Code hinzuzufügen.
Klicken Sie auf „Datei“, wählen Sie „Ordner öffnen…“ und öffnen Sie das Verzeichnis „go-web-scraper“.
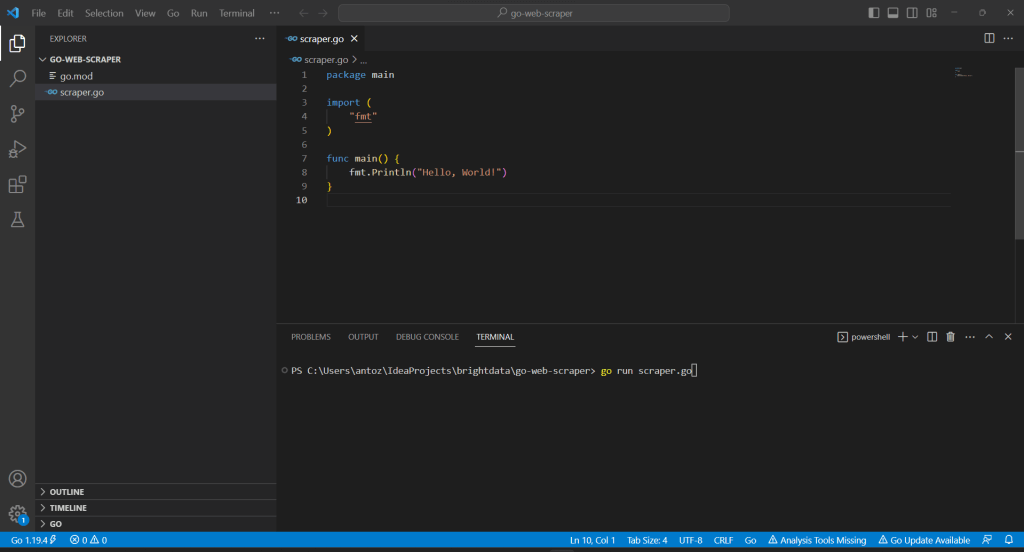
Klicken Sie mit der rechten Maustaste auf den Bereich „Explorer“, wählen Sie „Neue Datei…“ aus und erstellen Sie wie folgt eine scraper.go-Datei:
Denken Sie daran, dass die Funktion main() der Einstiegspunkt jeder Go-Anwendung ist. Hier müssen Sie Ihre Web-Scraping-Logik für Golang eingeben.
Visual Studio Code wird Sie auffordern, einige Pakete zu installieren, um die Integration mit Go zu vervollständigen. Installieren Sie alle. Führen Sie dann das Go-Skript aus, indem Sie den folgenden Befehl im VS Terminal aufrufen:
go run scraper.go
Die Ausgabe lautet wie folgt:
Hello, World!
Schritt 2: Erste Schritte mit Colly
Um einen Web Scraper für Go zu erstellen, sollten Sie eines der oben vorgestellten Pakete verwenden. Aber zuerst müssen Sie herausfinden, welche Golang Web Scraping Bibliothek Ihren Zielen am besten entspricht. Besuchen Sie dazu die Zielwebsite, klicken Sie mit der rechten Maustaste auf den Hintergrund und wählen Sie die Option „Untersuchen“ (inspect). Damit werden die DevTools Ihres Browsers geöffnet. Sehen Sie sich auf der Registerkarte „Netzwerk“ den Abschnitt „Fetch/XHR“ an.
Denken Sie daran, dass die Ziel-Website keine nennenswerten AJAX-Anfragen ausführt.
Wie Sie oben sehen können, führt die Zielwebsite nur wenige AJAX-Anfragen aus. Wenn Sie die einzelnen XHR-Anfragen untersuchen, werden Sie feststellen, dass keine aussagekräftigen Daten zurückgegeben werden. Mit anderen Worten: Das vom Server zurückgegebene HTML-Dokument enthält bereits alle Daten. Dies ist im Allgemeinen bei Websites mit statischen Inhalten der Fall.
Das bedeutet, dass die Zielwebsite nicht auf JavaScript angewiesen ist, um Daten dynamisch abzurufen oder um diese zu rendern. Daher benötigen Sie für das Abrufen von Daten von der Zielwebseite keine Bibliothek mit Headless-Browser-Funktionen. Sie können immer noch Selenium verwenden, aber das würde nur zu einem Leistungs-Overhead führen. Deshalb sollten Sie vorzugsweise einen einfachen HTML-Parser wie Colly wählen.
Fügen Sie Colly den Abhängigkeiten Ihres Projekts hinzu, und zwar mit:
go get github.com/gocolly/colly
Dieser Befehl erstellt eine go.sum-Datei und aktualisiert die go.mod-Datei entsprechend.
Bevor Sie Colly verwenden, machen Sie sich mit einigen wichtigen Konzepten von Colly vertraut.
Collys wichtigste Einheit ist der Collector. Dieses Objekt ermöglicht es Ihnen, HTTP-Anfragen und Web Scraping mithilfe der folgenden Callbacks durchzuführen:
OnRequest(): Wird aufgerufen, bevor eine HTTP-Anfrage mit Visit() ausgeführt wird.
OnError(): Wird aufgerufen, wenn bei einer HTTP-Anfrage ein Fehler auftritt.
OnResponse(): Wird aufgerufen, nachdem eine Antwort vom Server eingegangen ist.
OnHTML(): Wird nach OnResponse() aufgerufen, wenn der Server ein gültiges HTML-Dokument zurückgegeben hat.
OnScraped(): Wird aufgerufen, nachdem alle OnHTML()-Aufrufe beendet wurden.
Alle diese Funktionen benötigen einen Callback als Parameter. Wenn das mit der Funktion verbundene Ereignis ausgelöst wird, führt Colly den Eingabe-Callback aus. Um also einen Data Scraper in Colly zu erstellen, müssen Sie einen funktionalen Ansatz verfolgen, der auf Callbacks basiert.
Sie können ein Collector-Objekt mit der Funktion NewCollector() initialisieren:
c := colly.NewCollector()
Importieren Sie Colly und erstellen Sie einen Collector, indem Sie scraper.go wie folgt aktualisieren:
Verwenden Sie Colly, um eine Verbindung mit der Zielwebsite herzustellen:
c.Visit("https://brightdata.com/")
Im Hintergrund führt die Funktion Visit() eine HTTP GET-Anfrage durch und ruft das HTML-Zieldokument vom Server ab. Im Einzelnen: Das onRequest-Ereignis wird ausgelöst und der funktionale Lebenszyklus von Colly wird gestartet. Denken Sie daran, dass Visit() nach der Registrierung der anderen Colly-Callbacks aufgerufen werden muss.
Beachten Sie auch, dass die HTTP-Anfrage, die von Visit() gestellt wird, fehlschlagen kann. Wenn das geschieht, löst Colly das Ereignis „OnError“ aus. Die Gründe für einen solchen Fehlschlag können z. B. ein vorübergehend nicht verfügbarer Server oder eine ungültige URL sein. In der Regel scheitern Web Scraper, wenn die Zielwebsite Anti-Bot-Maßnahmen ergreift. Beispielsweise filtern diese Technologien im Allgemeinen Anfragen aus, die keinen gültigen HTTP-Header-Nutzeragenten (User-Agent) haben. Lesen Sie unsere Anleitung, um mehr über Nutzeragenten (User-Agents) für das Web Scraping zu erfahren.
Standardmäßig setzt Colly einen Platzhalter-Nutzeragenten, der nicht mit den von gängigen Browsern verwendeten Agenten übereinstimmt. Dadurch können Colly-Anfragen von Anti-Scraping-Technologien leicht identifiziert werden. Um zu vermeiden, dass Sie deswegen blockiert werden, geben Sie in Colly einen gültigen Nutzeragent-Header ein (siehe unten):
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
Jeder Visit()-Aufruf führt nun eine Anfrage mit diesem HTTP-Header aus.
Ihre scraper.go-Datei sollte nun wie folgt aussehen:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}
Schritt 4: Untersuchen der HTML-Seite
Lassen Sie uns das DOM der Zielwebsite analysieren, um eine effektive Datenabrufstrategie zu definieren.
Öffnen Sie die Bright Data-Homepage in Ihrem Browser. Wenn Sie einen Blick darauf werfen, werden Sie eine Reihe von Karten mit den Branchen entdecken, in denen die Dienstleistungen von Bright Data einen Wettbewerbsvorteil bieten können. Das ist eine interessante Information, die Sie scrapen sollten.
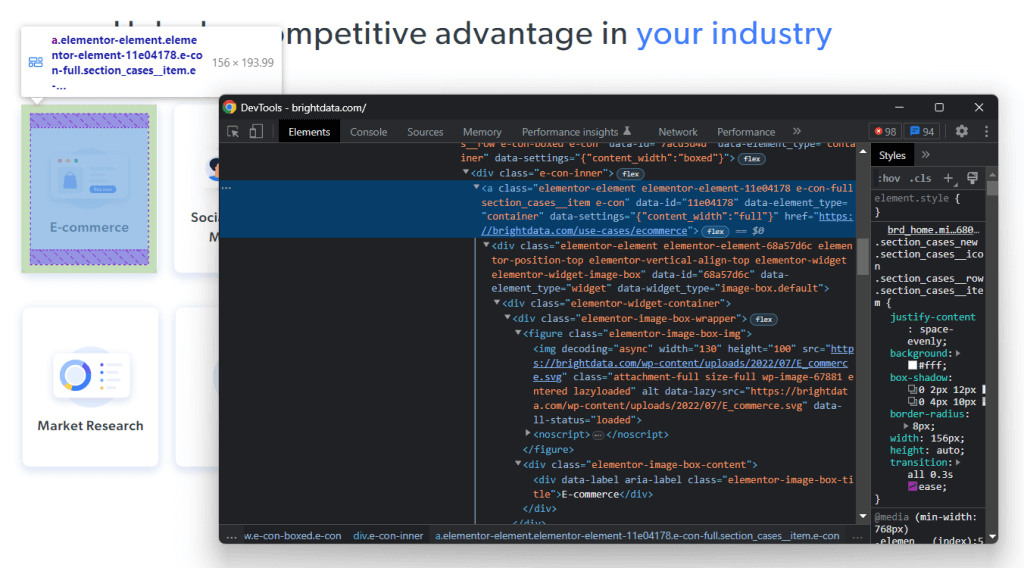
Klicken Sie dazu mit der rechten Maustaste auf eine dieser HTML-Karten und wählen Sie „Untersuchen“:
Konzentrieren Sie sich nun auf die CSS-Klassen, die von den betreffenden HTML-Elementen und deren übergeordneten Elementen verwendet werden. Dank dieser Elemente können Sie die CSS-Selektor-Strategie definieren, die erforderlich ist, um die gewünschten DOM-Elemente zu erhalten.
Jede Karte ist durch die Klasse section_cases__item gekennzeichnet und in .elementor-element-6b05593c <div>enthalten. Auf diese Weise erhalten Sie alle Branchenkarten mit dem folgenden CSS-Selektor:
.elementor-element-6b05593c .section_cases__item
Aus einer Karte können Sie dann<figur> und <div> die relevanten untergeordneten Elemente auswählen, und zwar mit:
Mit dem Go Scraper sollen die URL, das Bild und die Branchenbezeichnung aus den einzelnen Karten extrahiert werden.
Schritt 5: Auswahl von HTML-Elementen mit Colly
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})
Colly ruft die als Parameter übergebene Funktion für jedes HTML-Element, das dem CSS-Selektor entspricht, auf. Mit anderen Worten: Es durchläuft automatisch alle ausgewählten Elemente.
Denken Sie daran, dass ein Collector mehrere OnHTML()-Callbacks haben kann. Diese werden in der Reihenfolge ausgeführt, in der die onHTML()-Anweisungen im Code erscheinen.
Schritt 6: Scrapen von Daten einer Website mit Colly
Erfahren Sie, wie Sie mit Cooly die gewünschten Daten aus der HTML-Website extrahieren können.
Bevor Sie die Scraping-Logik schreiben, benötigen Sie einige Datenstrukturen, in denen Sie die extrahierten Daten speichern können. Sie können zum Beispiel Struct verwenden, um einen Branchendatentyp wie folgt zu definieren:
type Industry struct {
Url, Image, Name string
}
In Go spezifiziert „Struct“ einen Satz typisierter Felder, die als Objekt instanziiert werden können. Wenn Sie mit der objektorientierten Programmierung vertraut sind, können Sie sich „Struct“ als eine Art Klasse vorstellen.
Dann brauchen Sie einen Anteilstyp (slice) vom Typ Branche:
var industries []Industry
Anteilstypen sind in Go nichts anderes als Listen.
Nun können Sie die Funktion OnHTML()verwenden, um die Scraping-Logik wie folgt zu erstellen:
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
Der obige Go-Schnipsel zum Web Scraping wählt alle Branchenkarten von der Bright Data-Homepage aus und durchläuft sie. Anschließend werden die URL, das Bild und die Branchenbezeichnung, die mit jeder Karte verbunden sind, durch Scraping ausgefüllt. Schließlich wird ein neues Branchenobjekt instanziiert und dem Branchen-Anteilstyp hinzugefügt.
Wie Sie sehen, ist das Scrapen mit Colly ganz einfach. Dank der Attr() -Methode können Sie ein HTML-Attribut aus dem aktuellen Element extrahieren. ChildAttr() und ChildText() geben hingegen den Attributwert und den Text eines mit einem CSS-Selektor ausgewählten untergeordneten HTML-Elements aus.
Denken Sie daran, dass Sie auch Daten von Branchen-Detailseiten erfassen können. Sie müssen nur noch den auf der aktuellen Seite entdeckten Links folgen und eine entsprechende neue Scaping-Logik implementieren. Um all dies geht es beim Web Crawling und Web Scraping!
Gut gemacht! Sie haben gerade gelernt, wie Sie mit Go Ihre Ziele beim Web Scraping erreichen!
Schritt 7: Export der extrahierten Daten
Nach der OnHTML()-Anweisung enthalten die Branchen die ausgewerteten Daten in Go-Objekten. Um die aus der Website extrahierten Daten besser zugänglich zu machen, müssen Sie sie in ein anderes Format umwandeln. Erfahren Sie, wie Sie die gescrapten Daten nach CSV und JSON exportieren können.
Beachten Sie, dass die Standardbibliothek von Go über erweiterte Datenexportfunktionen verfügt. Sie benötigen kein externes Paket, um die Daten in CSV und JSON umzuwandeln. Sie müssen lediglich sicherstellen, dass Ihr Go-Skript die folgenden Importe enthält:
Für den CSV-Export:
import (
"encoding/csv"
"log"
"os"
)
Für den JSON-Export:
import (
"encoding/json"
"log"
"os"
)
Exportieren Sie mit Go den Branchenanteilstyp wie folgt in die Datei industries.csv:
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
Der obige Schnipsel erstellt eine CSV-Datei und initialisiert sie anhand der Header-Zeile. Anschließend durchläuft er den Anteilstyp der Branchenobjekte, wandelt jedes Element in Slice-Strings um und fügt sie der Ausgabedatei bei. Der CSV Writer von Go wandelt die Liste mit den Strings automatisch in einen neuen Datensatz im CSV-Format um.
Führen Sie das Skript aus mit:
go run scraper.go
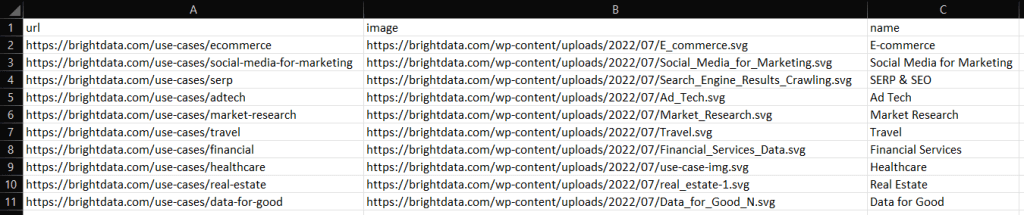
Nach der Ausführung finden Sie die Datei industries.csv im Stammverzeichnis Ihres Go-Projekts. Öffnen Sie die Datei. Sie sollten die folgenden Daten sehen:
Auf ähnliche Weise können Sie auch Branchen in die Datei industry.json exportieren (siehe unten):
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]
Et voilà! Jetzt wissen Sie, wie sie die erfassten Daten in ein nützlicheres Format umwandeln!
Schritt 8: Fügen Sie alles zusammen
So sieht der vollständige Code des Golang-Scrapers aus:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}
Mit Go können Sie in weniger als 100 Zeilen Code einen Web Scraper erstellen!
Fazit
In dieser Anleitung haben Sie gesehen, warum Go eine geeignete Sprache für das Web Scraping ist. Außerdem haben Sie erfahren, welches die besten Scraping-Bibliotheken für Go sind und was sie bieten. Sie haben auch gelernt, wie Sie Colly und die Standardbibliothek von Go verwenden, um eine Anwendung für das Web Scraping zu erstellen. Der hier entwickelte Go-Scraper kann Daten von einer realen Ziel-Website abrufen. Wie Sie wissen, sind für das Web Scraping mit Go nur ein paar Zeilen Code erforderlich.
Bedenken sie aber auch, dass bei der Extraktion von Daten aus dem Internet viele Hindernisse zu berücksichtigen sind. Deshalb werden auf vielen Websites Anti-Scraping- und Anti-Bot-Lösungen eingesetzt, die Ihr Go-Scraping-Skript erkennen und blockieren können. Glücklicherweise können Sie mit Bright Datas Web Scraper IDE der nächsten Generation einen Web Scraper erstellen, der in der Lage ist, alle Blockaden zu umgehen und zu vermeiden.