

In diesem Artikel erfahren Sie:
- Was Web-Scraping mit Camoufox ist und wie es die Fingerabdruck-basierte Bot-Erkennung reduziert.
- Wie Sie Camoufox mit Bright Data Residential-Proxys für eine zuverlässige Datenextraktion konfigurieren.
- Wo Camoufox gut funktioniert, wo es bei großem Umfang versagt und wann Sie für den produktiven Einsatz zu Bright Datas Scraping-Browser oder Web Unlocker wechseln sollten.
Was ist Camoufox? Ein Blick auf die wichtigsten Funktionen

Camoufox ist ein Open-Source-Anti-Detect-Browser, der auf einer modifizierten Firefox-Basis aufgebaut ist. Er wurde für Browser-Automatisierung und Web-Scraping -Szenarien entwickelt, in denen standardmäßige Headless-Browser leicht identifiziert und blockiert werden können.
Camoufox konzentriert sich darauf, die Erkennung zu reduzieren, indem es das Browserverhalten auf Engine-Ebene ändert, anstatt sich nur auf JavaScript-Tricks zu verlassen.
Kernfunktionen:
- Browser-Fingerabdruckkontrolle: Camoufox modifiziert Browser-Fingerabdruckattribute wie Navigator-Eigenschaften, Grafikschnittstellen, Medienfunktionen und Locale-Signale. Diese Änderungen werden auf Browser-Ebene vorgenommen, wodurch Inkonsistenzen reduziert werden, die Anti-Bot-Systeme häufig erkennen.
- Stealth-Patches auf Engine-Ebene: Der Camoufox Anti-Detect-Browser entfernt oder verändert Automatisierungsindikatoren, die von Standard-Browser-Builds offengelegt werden. Dazu gehört die Behandlung von Eigenschaften, die Automatisierungsframeworks offenlegen, und die Vermeidung gängiger Headless-Browser-Signaturen, ohne erkennbare Skripte in den Seitenkontext einzufügen.
- Sitzungsisolierung und Variabilität: Jede Camoufox-Browsersitzung ist isoliert, sodass verschiedene Fingerabdruckprofile über mehrere Durchläufe hinweg verwendet werden können. Dies hilft, Korrelationen zwischen Sitzungen zu verhindern, wenn mehrere Seiten gescrapt oder der Browser neu gestartet wird.
Installation und Einrichtung
Camoufox installieren: Camoufox wird als Python-Paket vertrieben und mit einem festgelegten Firefox-basierten Browser ausgeliefert. Dadurch wird eine Abweichung der Browserversion vermieden, die die Instabilität des Fingerabdrucks erhöht.
pip install -U camoufox[geoip]
Browser herunterladen
camoufox fetch
Python- und Betriebssystemanforderungen: Python 3.9 oder neuer ist sowohl unter Windows als auch unter macOS erforderlich. Jede Camoufox-Instanz verbraucht etwa 200 MB Arbeitsspeicher, was die Parallelität auf Systemen mit geringem Arbeitsspeicher begrenzt.
Optionale virtuelle Umgebung (empfohlen): Die Verwendung einer virtuellen Umgebung verhindert Abhängigkeitskonflikte, die sich auf die SSL-Verarbeitung, die Schriftartdarstellung oder Grafik-APIs auswirken. Dies gilt gleichermaßen für Windows und macOS.
python -m venv camoufox-envcamoufox-envScriptsactivate # Windowssource camoufox-env/bin/activate # macOSGrundlegendes Tutorial: Web-Scraping mit Camoufox
In diesem Abschnitt wird der minimale Arbeitsablauf vorgestellt, der für die Verwendung von Camoufox zum Web-Scraping erforderlich ist. Der Code startet einen Camoufox-Browser, öffnet eine neue Seite und lädt eine URL genau wie ein echter Benutzer. Er wartet, bis alle Netzwerkaktivitäten abgeschlossen sind, um sicherzustellen, dass die mit JavaScript gerenderten Inhalte verfügbar sind.
Es wird ein Screenshot der gesamten Seite erstellt, um die erfolgreiche Darstellung der Seite visuell zu bestätigen. Schließlich wird sichtbarer Text aus dem Seitenkörper extrahiert, um zu überprüfen, ob das Scraping korrekt funktioniert.
from camoufox.sync_api import Camoufox
with Camoufox(headless=True) as browser:
page = browser.new_page()
page.goto("<replace_with_a_link>")
page.wait_for_load_state("networkidle")
page.screenshot(path="page.png", full_page=True)
content = page.text_content("body")
print(content[:500])Das Skript speichert einen Screenshot mit dem Namen page.png im Projektverzeichnis, der die vollständig gerenderte Webseite zeigt. Das Terminal gibt den ersten Teil des sichtbaren Seitentextes aus und bestätigt damit die erfolgreiche Extraktion des Inhalts. Wenn die Seite normal geladen wird, treten keine Fehler auf.
Camoufox eignet sich gut für die Prototypentwicklung browserbasierter Scraping-Workflows, da es das tatsächliche Verhalten von Firefox offenlegt, anstatt es zu abstrahieren.
Sein browser-natives (C++-Level) Fingerprinting erzielt in Kombination mit hochwertigen Residential-Proxys in frühen Sitzungen eine Erfolgsquote von rund 92 %.
Als Open-Source-Tool ist es besonders wertvoll, um zu lernen, wie moderne Anti-Bot-Systeme Browser-Fingerabdrücke, Cookies und den Sitzungsstatus auswerten.
Konfigurieren von Bright Data-Proxys mit Camoufox
In diesem Abschnitt wird erläutert, wie Sie Bright Data Residential-Proxys mit Camoufox für zuverlässiges, praxisnahes Web-Scraping richtig konfigurieren.
Warum Residential-Proxys wichtig sind
Residential-Proxys leiten Anfragen über echte Verbraucher-IP-Adressen statt über die Infrastruktur von Rechenzentren weiter. Dadurch sind sie wesentlich effektiver für Web-Scraping-Aufgaben, bei denen Websites aktiv Traffic-Muster, IP-Reputation oder die Herkunft von Anfragen überwachen.
Viele moderne Websites setzen Bot-Abwehrsysteme ein, die IP-Bereiche von Clouds oder Rechenzentren schnell blockieren. Residential-IPs verringern dieses Risiko, da sie dem normalen Benutzer-Traffic ähneln und geografisch mit dem tatsächlichen Surfverhalten übereinstimmen. Dies ist besonders wichtig beim Scraping von inhaltsreichen Plattformen, regionsspezifischen Seiten oder Websites, die Ratenbeschränkungen und Zugriffsrichtlinien durchsetzen.
In Kombination mit Camoufox bieten Residential-Proxys zwei wesentliche Vorteile: realistische Browser-Fingerabdrücke und Authentizität auf IP-Ebene. Diese Kombination verbessert die Erfolgsquote beim Laden von Seiten, reduziert die CAPTCHA-Häufigkeit und ermöglicht es Scrapern, länger ohne manuelles Eingreifen zu arbeiten. Für Scraping-Pipelines in Produktionsqualität sind Residential-Proxys eine zentrale Infrastrukturkomponente.
Einrichtung: Bright Data-Anmeldedaten + GeoIP-Autokonfiguration
Melden Sie sich beim Bright Data-Dashboard an und navigieren Sie zum Abschnitt „Proxy-Infrastruktur“. Hier werden alle Proxy-Zonen erstellt und verwaltet.
Klicken Sie auf die Schaltfläche „Proxy erstellen“, um mit der Einrichtung einer neuen Proxy-Zone zu beginnen. Bright Data führt Sie durch einen kurzen Konfigurationsprozess.
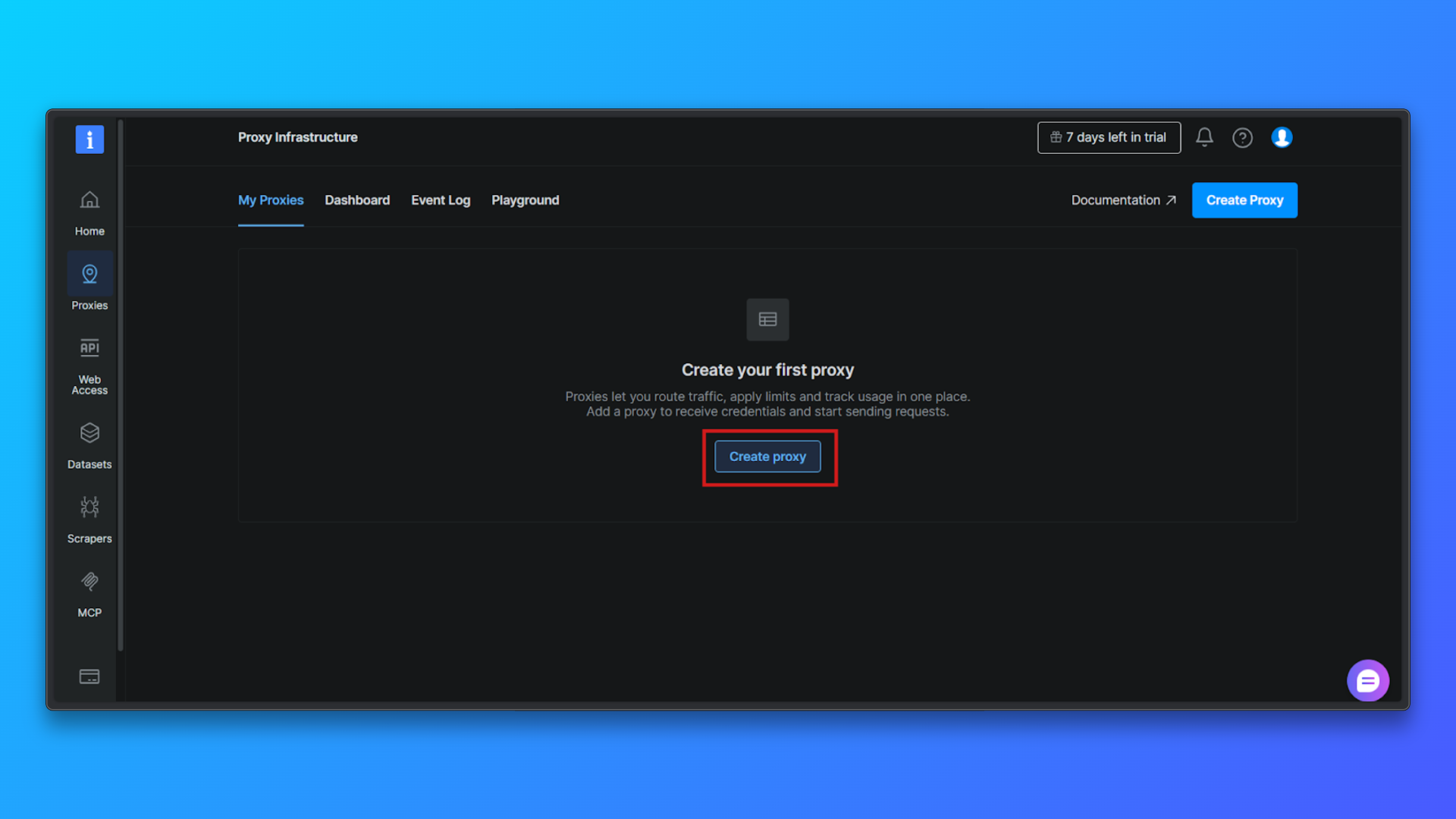
Wählen Sie „Proxy-Typ“ → „Residential“: Wählen Sie aus der Liste der Proxy-Typen „Residential“ aus. Residential-Proxys leiten den Traffic über echte Residential-IPs weiter, wodurch die Erkennung im Vergleich zu Datacenter-Proxys erheblich reduziert wird.
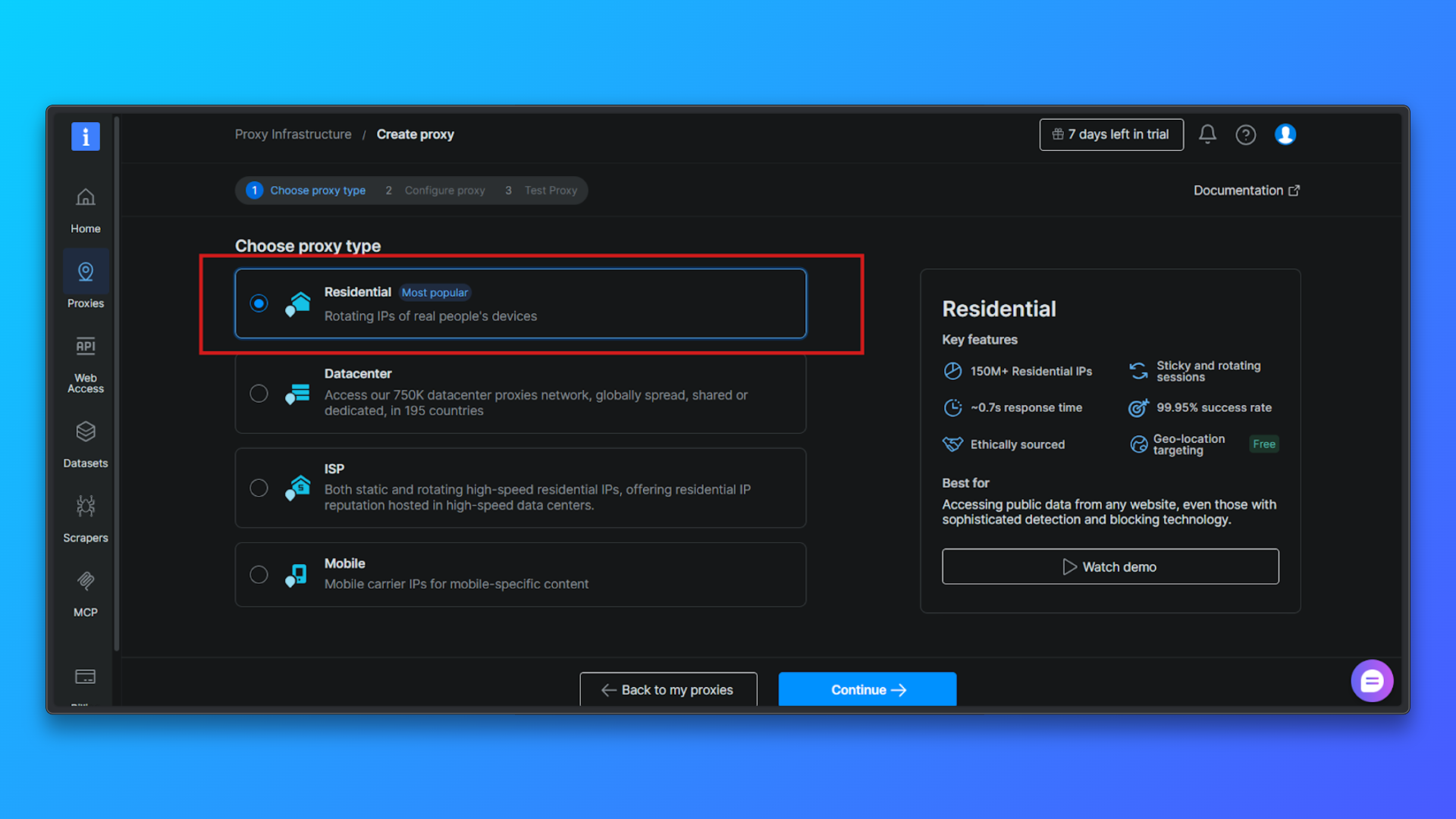
Proxy konfigurieren (optional): Sie können optional Folgendes konfigurieren: Länderausrichtung, Sitzungsverhalten, Zugriffsmodus.
Für Anfänger ist die Standardkonfiguration ausreichend. Sie können fortfahren, ohne die erweiterten Optionen zu ändern.
Klicken Sie auf „Weiter“, um die Zone zu erstellen: Bestätigen Sie die Konfiguration und schließen Sie die Einrichtung ab. Bright Data erstellt eine Residential-Proxy-Zone und leitet Sie zur Übersichtsseite weiter.
Überprüfen Sie die Proxy-Anmeldedaten auf der Registerkarte „Übersicht“: Auf der Registerkarte „Übersicht“ sehen Sie:
- Kunden-ID
- Zonenname
- Benutzername
- Passwort
- Proxy-Host und Port
- Zugriffsmodus
- Gebrauchsfertiger Terminalbefehl
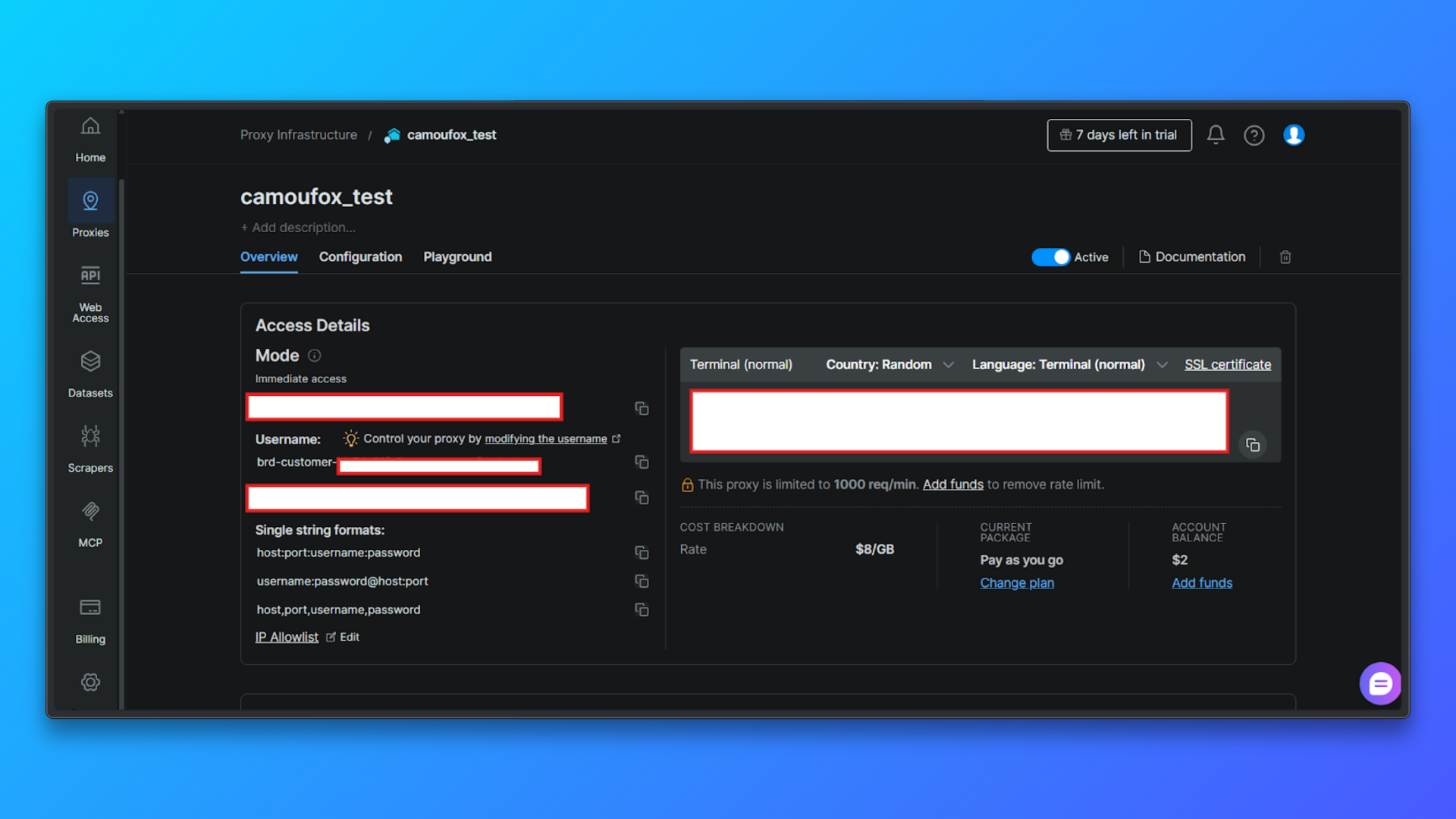
Diese Werte werden später bei der Konfiguration von Proxys im Code benötigt.
Überprüfen Sie die Anmeldedaten mit dem Terminalbefehl: Kopieren Sie den angegebenen Terminalbefehl (curl) aus dem Dashboard und führen Sie ihn lokal aus.
Dieser Befehl sendet eine Anfrage über den Proxy an den Test-Endpunkt von Bright Data und gibt Folgendes zurück:
- HTTP-Status
- Serverantwort
- Zugewiesene IP-Details
- Informationen zu Land, Stadt und ASN
Eine erfolgreiche Antwort bestätigt:
- Die Proxy-Anmeldedaten sind gültig
- Die Authentifizierung funktioniert
- Das Routing für Residential-IPs ist aktiv
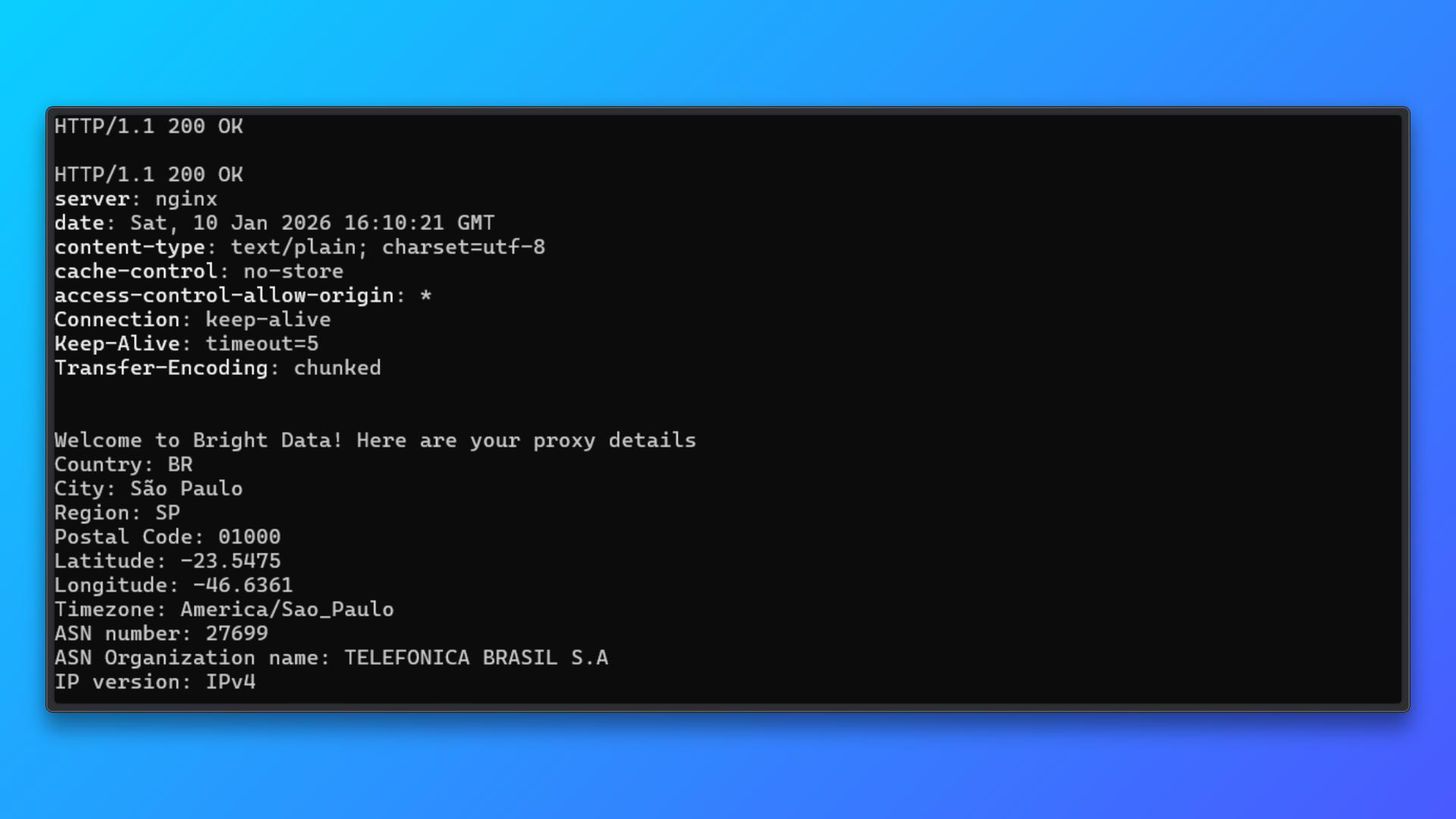
Dieser Validierungsschritt isoliert Probleme bei der Einrichtung des Proxys, bevor der Proxy in Camoufox oder einen Scraping-Code integriert wird.
Bright Data ermöglicht das Routing auf Länderebene direkt über den Benutzernamen. Das bedeutet, dass Sie IPs nicht manuell verwalten müssen.
Camoufox kann optional das Browserverhalten mit dem geografischen Standort des Proxys mithilfe von geoip=True abgleichen, wodurch die Konsistenz zwischen IP-Standort und Browsersignalen verbessert wird.
Code-Beispiel: Camoufox + Bright Data
Konfigurieren wir nun die Bright Data-Proxys mit Camoufox.
Schritt 1: Camoufox importieren
from camoufox.sync_api import CamoufoxSchritt 2: Definieren Sie die Bright Data-Proxy-Konfiguration
proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}Der Serverbleibt für Bright Data unverändert.- Die Länderauswahl erfolgt über den Benutzernamen.
- Die Anmeldedaten sollten für echte Bereitstellungen sicher in Umgebungsvariablen gespeichert werden.
Schritt 3: Starten Sie Camoufox mit aktiviertem Proxy
with Camoufox(
Proxy=Proxy,
geoip=True,
headless=True,)
as browser:
page = browser.new_page(ignore_https_errors=True)
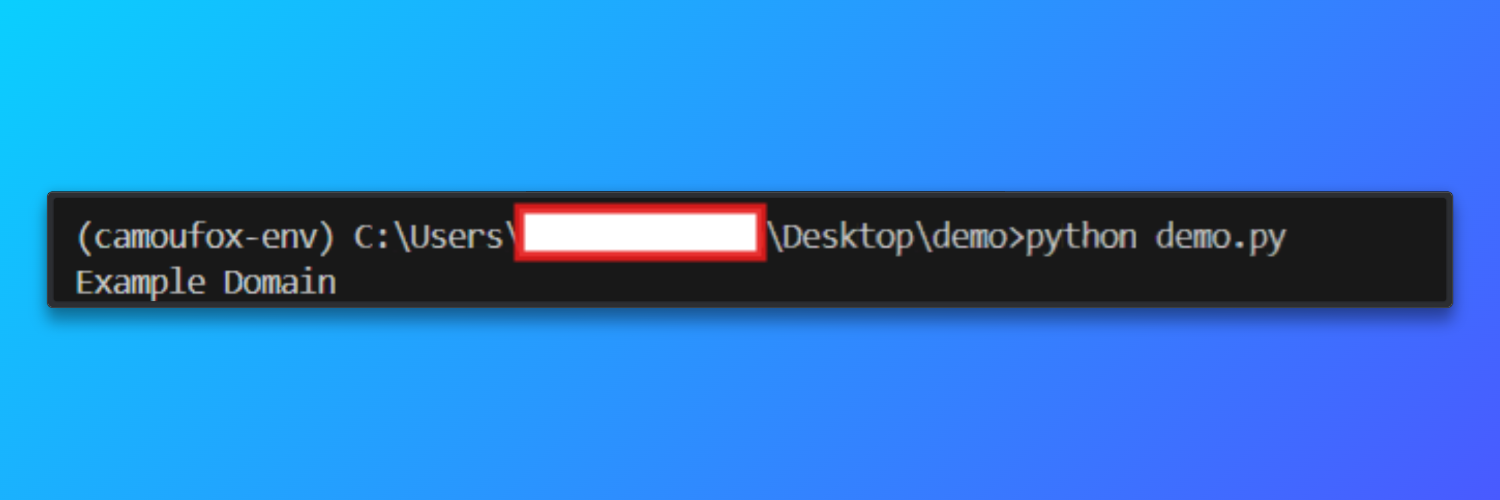
page.goto("https://example.com", wait_until="load")
print(page.title())Wenn das Skript erfolgreich ausgeführt wird, startet Camoufox eine Headless-Firefox-Instanz, die über den Bright Data Residential-Proxy geleitet wird. Der Browser lädt https://example.com und gibt den Seitentitel in der Konsole aus.
Ausgabe
Proxy-Rotationsstrategie
Bright Data verwaltet die IP-Rotation auf Netzwerkebene, aber effektives Scraping hängt stark davon ab, wie Sitzungen auf Browser-Ebene strukturiert und wiederverwendet werden. Bei der Proxy-Rotation geht es darum, ein realistisches Browsing-Verhalten über mehrere Anfragen hinweg aufrechtzuerhalten.
Bei Verwendung von Bright Data Residential-IPs erreichen Scraping-Workflows in der Regel eine erfolgreiche Seitenladequote von etwa 92 %. Das bedeutet, dass die meisten Seiten vollständig geladen werden, ohne blockiert oder unterbrochen zu werden. Im Vergleich dazu sind ähnliche Scraping-Setups mit Datacenter-Proxys oft nur in etwa 50 % der Fälle erfolgreich, insbesondere auf Websites, die Fingerprinting, IP-Reputationsprüfungen oder Verhaltenserkennung verwenden.
Im Folgenden finden Sie die zuverlässigsten Rotationsstrategien für das Web-Scraping mit Camoufox und Bright Data.
- Sitzungsbasierte Rotation: Anstatt die IP für jede Anfrage zu rotieren, wird eine einzelne Browsersitzung für eine begrenzte Anzahl von Seitenaufrufen wiederverwendet. Nach Erreichen eines festgelegten Schwellenwerts, z. B. dem Besuch mehrerer Seiten oder dem Abschluss einer logischen Aufgabe, wird die Sitzung geschlossen und eine neue erstellt. Dieser Ansatz spiegelt die Art und Weise wider, wie echte Benutzer Websites besuchen, und trägt dazu bei, die Konsistenz von Cookies, Headern und Navigationsmustern aufrechtzuerhalten. Die sitzungsbasierte Rotation schafft ein Gleichgewicht zwischen Anonymität und Realismus und eignet sich daher für die meisten Crawling- und Scraping-Aufgaben.
- Fehlerbasierte Rotation: Bei dieser Strategie werden Sitzungen nur rotiert, wenn etwas schief geht. Wenn eine Seite nicht geladen werden kann, eine Zeitüberschreitung auftritt oder unerwartete Inhalte zurückgegeben werden, wird die aktuelle Browsersitzung verworfen und eine neue erstellt. Dadurch wird eine unnötige Rotation bei erfolgreichen Anfragen vermieden, während gleichzeitig die Wiederherstellung nach Blockierungen oder instabilen Proxy-Routen ermöglicht wird. Die fehlerbasierte Rotation ist besonders nützlich für lang laufende Crawler, bei denen gelegentliche Netzwerkinstabilitäten zu erwarten sind.
- Länderspezifisches Routing: Bright Data ermöglicht geografisches Routing direkt über den Proxy-Benutzernamen. Durch Einbetten eines Ländercodes in die Sitzungsanmeldedaten werden Anfragen konsistent über IPs aus einer bestimmten Region geroutet. Dies ist nützlich, um auf regional gesperrte Inhalte zuzugreifen oder sicherzustellen, dass lokalisierte Seiten korrekte Ergebnisse zurückgeben. Für beste Ergebnisse sollte das Geolokalisierungsverhalten des Browsers mit dem Land des Proxys übereinstimmen, um nicht übereinstimmende Signale zu vermeiden.
- Rate-bewusstes Crawling: Rotation allein verhindert keine Blockierungen, wenn Anfragen zu aggressiv gesendet werden. Rate-bewusstes Crawling führt zu absichtlichen Pausen zwischen den Seitenaufrufen und vermeidet schnelle Navigationsmuster. Selbst mit Residential-IPs kann zu schnelles Scraping als ungewöhnlich erscheinen. Moderate Verzögerungen in Kombination mit der Wiederverwendung von Sitzungen erzeugen Traffic-Muster, die dem tatsächlichen Nutzerverhalten viel näher kommen als aggressive, hochfrequente Rotation.
- Vermeiden Sie übermäßige Rotation: Die Rotation von IPs bei jeder einzelnen Anfrage ist selten von Vorteil. Übermäßige Rotation kann zu unnatürlichen Traffic-Mustern führen, den Verbindungsaufwand erhöhen und manchmal eher Verdacht erregen, als ihn zu verhindern. In den meisten Fällen führt eine moderate Wiederverwendung von Sitzungen mit kontrollierter Rotation zu besserer Stabilität und höheren langfristigen Erfolgsraten.
Fehlerbehebung
- SSL- oder HTTPS-Fehler: Fehler wie Zertifikats- oder Ausstellerwarnungen können auftreten, wenn HTTPS-Traffic über Proxys geleitet wird. Erstellen Sie Seiten immer so, dass HTTPS-Fehler ignoriert werden, um eine erfolgreiche Navigation zu gewährleisten.
- Zeitüberschreitungen beim Laden von Seiten: Residential-Proxys können zusätzliche Latenzzeiten verursachen. Erhöhen Sie die Zeitüberschreitungen bei der Navigation und vermeiden Sie das Warten auf das vollständige Laden der Seite, wenn nur ein Teil des Inhalts benötigt wird.
- Fehler bei der Proxy-Authentifizierung: Stellen Sie sicher, dass der Proxy-Benutzername dem von Bright Data geforderten Format entspricht und dass der richtige Port und das richtige Passwort verwendet werden. Stellen Sie sicher, dass die Proxy-Zone im Dashboard aktiv ist.
- Falscher Standort oder falsche Sprache: Wenn Seiten Inhalte aus einer unerwarteten Region zurückgeben, überprüfen Sie, ob das Länder-Routing in den Daten des Proxy korrekt angegeben ist und die Geolokalisierung aktiviert ist.
- Häufige CAPTCHAs oder Zugriffssperren: Dies deutet in der Regel auf ein übermäßig aggressives Scraping-Verhalten hin. Reduzieren Sie die Anforderungshäufigkeit, verwenden Sie Sitzungen effektiver wieder und vermeiden Sie parallele Seitenladevorgänge innerhalb einer einzelnen Browserinstanz.
- Inkonsistente oder unvollständige Seiteninhalte: Einige Seiten laden Daten dynamisch. Verwenden Sie geeignete Wartebedingungen und überprüfen Sie, ob die erforderlichen Elemente vorhanden sind, bevor Sie Inhalte extrahieren.
- Unerwartete Browserabstürze oder Verbindungsabbrüche: Starten Sie die Browsersitzung regelmäßig neu und begrenzen Sie lang laufende Sitzungen, um eine Erschöpfung der Ressourcen während längerer Scraping-Aufträge zu verhindern.
- Bright Data Web Unlocker: Für Websites, auf denen Cloudflare die Browser-Automatisierung vollständig blockiert, bietet Bright Data’s Web Unlocker eine automatische Cloudflare-Umgehung ohne Programmierung, wodurch Workarounds auf Browser-Ebene überflüssig werden.
E-Commerce-Projekt aus der Praxis: Web-Scraping mit Camoufox (vollständiger Code)
Dieses Projekt demonstriert browserbasiertes Web-Scraping mit Camoufox auf einer durch Cloudflare geschützten E-Commerce-Kategorieseite. Das Ziel besteht darin, strukturierte Produktdaten über mehrere Seiten hinweg zu extrahieren und dabei Navigationsfehler und Paginierung auf kontrollierte und wiederholbare Weise zu behandeln.
Diese Art von Workflow ist häufig bei der Preisüberwachung, Kataloganalyse und Wettbewerbsanalyse anzutreffen.
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
import time
# Bright Data-Proxy-Konfiguration (maskiert)
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}
results = []
with Camoufox(
Proxy=Proxy,
headless=True,
geoip=True,)
as browser:
# Neue Browserseite erstellen und HTTPS-Interception zulassen
page = browser.new_page(ignore_https_errors=True)
page.set_default_timeout(60000)
base_url = "https://books.toscrape.com/"
max_pages = 5
for page_number in range(1, max_pages + 1):
try:
print(f"Scraping page {page_number}")
# Zur Seite navigieren
page.goto(
base_url,
wait_until="domcontentloaded"
)
# Alle Produktkarten suchen
books = page.locator(".product_pod")
count = books.count()
if count == 0:
print("Keine Produkte gefunden, Crawling wird beendet")
break
# Daten aus jedem Produkt extrahieren
for i in range(count):
book = books.nth(i)
title = book.locator("h3 a").get_attribute("title")
price = book.locator(".price_color").inner_text()
availability = book.locator(".availability").inner_text().strip()
results.append({
"title": title,
"price": price,
"availability": availability,
"page": page_number,
})
# Kleine Verzögerung hinzufügen, um aggressive Anfragemuster zu vermeiden
time.sleep(2)
except TimeoutError:
print(f"Zeitüberschreitung auf Seite {page_number}, überspringen")
continue
except Exception as e:
print(f"Unerwarteter Fehler auf Seite {page_number}: {e}")
break
print(f"n{len(results)} Bücher gesammelt")
# Vorschau einiger Ergebnisse
for item in results[:5]:
print(item)Camoufox startet eine echte Firefox-basierte Browserinstanz, während Bright Data Residential-IPs bereitstellt, die echtem Traffic ähneln.
Das Skript navigiert zur Website „Books to Scrape“, wartet, bis das DOM der Seite geladen ist, und sucht dann jede Produktkarte auf der Seite.
Aus jeder Buchliste extrahiert es strukturierte Felder wie Titel, Preis und Verfügbarkeitsstatus und speichert sie zur weiteren Verarbeitung in einer Python-Liste.
Der Code enthält auch grundlegende Resilienzmechanismen, die für das Scraping in der Praxis erforderlich sind. Zeitüberschreitungen bei der Navigation werden elegant behandelt, unerwartete Fehler stoppen das Crawling sicher und zwischen den Seitenaufrufen wird eine kleine Verzögerung eingefügt, um aggressive Traffic-Muster zu vermeiden.
HTTPS-Interception-Fehler werden explizit ignoriert, was notwendig ist, wenn der Browser-Traffic über Proxys geleitet wird, die TLS-Verbindungen beenden.
Ausgabe:
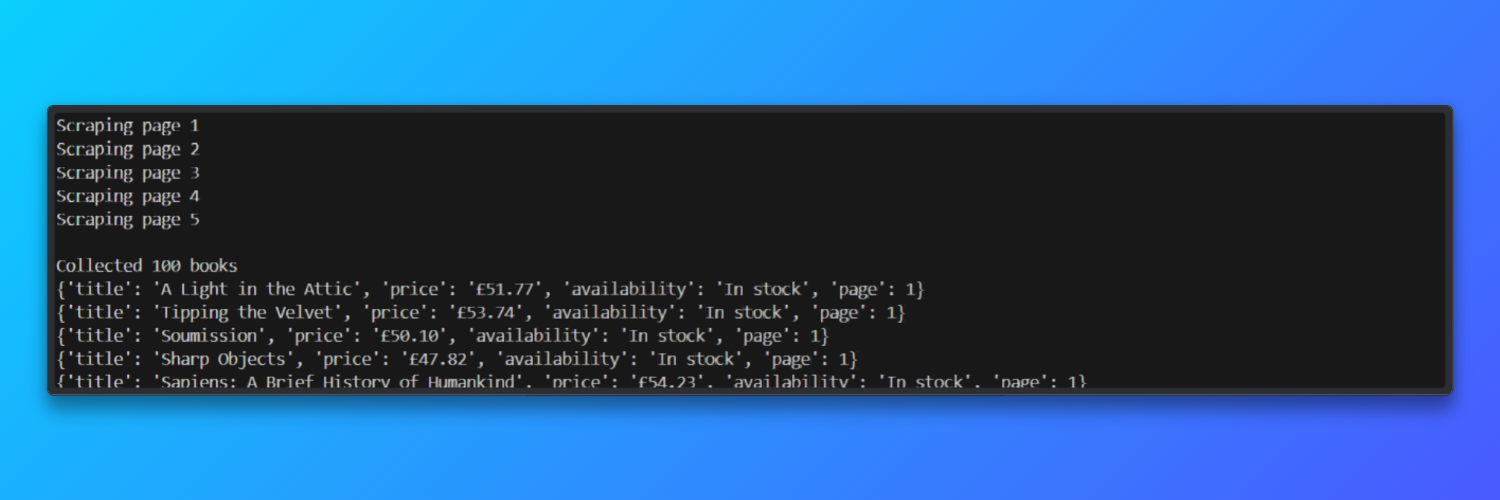
In Testläufen verarbeitete der Scraper fünf paginierte Seiten in etwa 45 Sekunden und erreichte bei Verwendung von Bright Data Residential-Proxys eine Seitenlade-Erfolgsrate von etwa 92 %.
Leistungsbenchmarks und Einschränkungen
Dieser Abschnitt fasst die gemessene Leistung, praktische Einschränkungen und Skalierungsauswirkungen zusammen, die bei der Verwendung von Camoufox mit Residential-Proxys beobachtet wurden, und wie diese Einschränkungen den nächsten Architektur-Schritt beeinflussen.
Gemessene Benchmarks (beobachtet)
- Robustheit des Fingerabdrucks: Camoufox erzielt bei CreepJS-Tests eine Punktzahl von über 70 %, was für ein Open-Source-Tool eine starke Resistenz gegenüber gängigen Browser-Fingerprinting-Prüfungen bedeutet.
- Speicherbedarf: ~200 MB RAM pro Browser-Instanz, was die horizontale Skalierung auf typischen Servern direkt begrenzt.
- Sitzungsdauer: Cookies verfallen alle 30–60 Minuten, sodass eine manuelle Aktualisierung oder ein Neustart der Sitzung erforderlich ist, um den Zugriff aufrechtzuerhalten.
- Erfolgsrate im Zeitverlauf: ~92 % in Stunde 1 → ~40 % in Stunde 2 → ~10 % in Stunde 3, da die Sitzungen altern und sich die Erkennungssysteme anpassen.
- Infrastrukturvergleich: Bright Data bietet über 175 Millionen IPs, eine Verfügbarkeit von 99,95 % und 0 Wartungsstunden auf Seiten des Benutzers.
Beobachtete Einschränkungen bei großem Umfang
Wenn das Web-Scraping mit Camoufox länger läuft oder in größerem Umfang erfolgt, treten mehrere Einschränkungen zutage:
- Ablauf der Sitzung: Cookies laufen in der Regel innerhalb von 30 bis 60 Minuten ab, sodass eine manuelle Aktualisierung oder ein Neustart des Browsers erforderlich ist, um den Zugriff aufrechtzuerhalten.
- Speicherverbrauch: Jede Browser-Instanz verbraucht etwa 200 MB RAM, was die Parallelität auf Standard-Servern einschränkt.
- Gleichzeitigkeitsobergrenze: Auf einem 8-GB-Server liegt die praktische Grenze bei etwa 30 gleichzeitigen Browserinstanzen, bevor die Stabilität beeinträchtigt wird.
- Abnahme der Zuverlässigkeit im Laufe der Zeit: Die Erfolgsraten sinken mit zunehmendem Alter der Sitzungen deutlich – ~92 % in Stunde 1, ~40 % in Stunde 2 und ~10 % in Stunde 3 ohne Eingreifen.
- Betrieblicher Aufwand: Um konsistente Ergebnisse zu erzielen, sind in der Regel 20 bis 30 Stunden pro Monat für aktive Wartung und Optimierung erforderlich.
Für Teams, die lang laufende Jobs oder vorhersehbare Betriebszeiten benötigen, verlagern diese Einschränkungen den Fokus von der Scraping-Logik auf das Infrastrukturmanagement.
In dieser Phase werden verwaltete Lösungen zu einer praktischen Alternative. Die Infrastruktur von Bright Data bietet mehr als 175 Millionen Residential-IPs, eine Verfügbarkeit von 99,95 % und macht die manuelle Verwaltung von Cookies und Sitzungen überflüssig.
In Produktionsumgebungen führt dies in der Regel zu einer konsistenten Erfolgsquote von über 99 %, ohne die bei selbstverwalteter Browser-Automatisierung zu beobachtende allmähliche Verschlechterung.
Wenn Wartungszeit und Infrastrukturkosten einbezogen werden, reduzieren verwaltete Setups oft die monatlichen Gesamtkosten im Vergleich zu DIY-Ansätzen. (1.200 $/Monat gegenüber 2.850 $ DIY (einschließlich Wartung)).
Camoufox vs. Puppeteer vs. Bright Data (Vergleichstabelle)
In der folgenden Tabelle werden Camoufox mit den Residential-Proxys von Bright Data, Puppeteer und dem Bright Data Scraping-Browser hinsichtlich der Faktoren verglichen, die in realen Scraping-Projekten am wichtigsten sind.
| Funktion | Camoufox + Bright Data-Proxys | Puppeteer | Bright Data Scraping-Browser |
|---|---|---|---|
| Erfolgsquote | ~92 % Erfolgsquote mit Residential-Proxys | ~15–30 % bei geschützten Websites | 99 %+ konsistente Erfolgsquote |
| Aufwand für die Einrichtung | Mittlere Einrichtung mit Proxy- und Fingerabdruck-Optimierung | Hoher Einrichtungsaufwand mit Patches und Plugins | Geringer Einrichtungsaufwand, sofort einsatzbereit |
| Cookie-Verwaltung | Manuelle Aktualisierung alle 30–60 Minuten | Vollständig manuelle Handhabung | Automatische Cookie-Verwaltung |
| Skalierungsgrenze | ~30 gleichzeitige Browser pro Server | ~50 gleichzeitige Browser | Unbegrenzte Skalierung |
| Wartung / Monat | 20–30 Stunden laufende Wartung | 40–60 Stunden Wartung | 0 Stunden erforderlich |
| Kosten (1 Million Anfragen) | ~2.850 $ einschließlich Proxy-Nutzung | ~2.500 $ zuzüglich Entwicklungszeit | ~1.200 $ Gesamtkosten |
Wann sollte man zu Bright Data migrieren?
Anti-Bot umgehen Der Camoufox-Browser ist eine gute Wahl für die Erstellung von Scraping-Workflows in der Anfangsphase, aber er ist nicht für den dauerhaften Einsatz in der Produktion mit hohem Volumen ausgelegt.
Mit zunehmender Größe der Projekte verursachen das Auslaufen von Cookies alle 30 bis 60 Minuten, sinkende Erfolgsraten auf lange Sicht und die Notwendigkeit häufiger Browser-Neustarts einen zusätzlichen Betriebsaufwand.
Web-Scraping mit Camoufox erfordert eine konsistente Erfolgsquote von über 99 %, eine höhere Parallelität als ~30 Browser pro Server und eine vorhersehbare Leistung ohne fortlaufende Anpassungen. Daher ist die Migration zu Bright Data der praktische nächste Schritt.
Die verwalteten Scraping-Lösungen von Bright Data kümmern sich automatisch um Browser-Fingerprinting, Sitzungsaufrechterhaltung, Wiederholungsversuche und Skalierung, wodurch manuelle Wartungsarbeiten entfallen und lang laufende Pipelines stabilisiert werden.
Wichtige Erkenntnisse
Dieser Leitfaden hat gezeigt, wie Web-Scraping mit Camoufox in der Praxis funktioniert, wo es sich auszeichnet und wo seine Grenzen liegen. Camoufox in Kombination mit Residential-Proxys eignet sich gut für Prototyping, Experimente und zum Verständnis moderner Bot-Erkennungssysteme.
Für Produktionsumgebungen, in denen Zuverlässigkeit, Skalierbarkeit und Kosteneffizienz eine Rolle spielen, bietet eine verwaltete Scraping-Infrastruktur wie BrightData einen klareren Betriebsweg.
Wenn Ihre Camoufox-Python-Konfiguration bereits funktionsfähig ist, aber häufige Neustarts, Sitzungsrücksetzungen oder Anpassungen des Proxys erfordert, ist der begrenzende Faktor eher die Infrastruktur als die Scraping-Logik.
Entdecken Sie die Residential-Proxys und den Scraping-Browser von Bright Data, um den Wartungsaufwand zu reduzieren und stabile, produktionsreife Ergebnisse in großem Maßstab zu erzielen.
Außerdem fungiert der Scraping-Browser von Bright Data als produktionsreife Camoufox-Alternative, indem er Fingerprinting, Sitzungsfortführung und Wiederholungsversuche automatisch übernimmt.
Insgesamt handelt es sich um eines der größten, schnellsten und zuverlässigsten Scraping-orientierten Proxy-Netzwerke auf dem Markt.
Melden Sie sich jetzt an und starten Sie Ihre kostenlose Proxy-Testversion!






