

In diesem Leitfaden werden Sie sehen:
- Die Gründe, warum das Parsen von HTML in PHP nützlich ist
- Die Voraussetzungen, um mit dem Ziel des Artikels zu beginnen
- Wie man HTML in PHP parst:
DomHTMLDocument- Einfacher HTML-DOM-Parser
DomCrawlervon Symfony
- Eine Vergleichstabelle der drei Ansätze
Lasst uns eintauchen!
Warum HTML in PHP parsen?
Beim HTML-Parsing in PHP wird der HTML-Inhalt in seine DOM-Struktur(Document Object Model) umgewandelt. Sobald das DOM-Format vorliegt, können Sie den HTML-Inhalt leicht navigieren und manipulieren.
Die wichtigsten Gründe für das Parsen von HTML in PHP sind insbesondere:
- Datenextraktion: Erfassen bestimmter Inhalte von Webseiten, wie z. B. Text oder Attribute von HTML-Elementen.
- Automatisierung: Automatisieren Sie Aufgaben wie Content Scraping, Reporting und Datenaggregation aus HTML-Inhalten.
- Serverseitige Verarbeitung von HTML-Inhalten: Analysieren Sie HTML, um Webinhalte auf dem Server zu bearbeiten, zu bereinigen oder zu formatieren, bevor sie in Ihrer Anwendung angezeigt werden.
Entdecken Sie die besten HTML-Parsing-Bibliotheken!
Voraussetzungen
Bevor Sie mit der Programmierung beginnen, stellen Sie sicher, dass Sie PHP 8.4+ auf Ihrem Rechner installiert haben. Sie können dies überprüfen, indem Sie den folgenden Befehl ausführen:
php -v
Die Ausgabe sollte in etwa so aussehen:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies
Als nächstes möchten Sie ein Composer-Projekt initialisieren, um die Verwaltung von Abhängigkeiten zu erleichtern. Wenn Composer nicht auf Ihrem System installiert ist, laden Sie es herunter und folgen Sie den Installationsanweisungen.
Erstellen Sie zunächst einen neuen Ordner für Ihr PHP-HTML-Projekt:
mkdir php-html-parser
Navigieren Sie in Ihrem Terminal zu dem Ordner und initialisieren Sie darin ein Composer-Projekt mit dem Befehl composer init:
composer init
Während dieses Vorgangs werden Sie zu einigen Fragen aufgefordert. Die Standardantworten sind ausreichend, aber Sie können auch spezifischere Angaben zu Ihrem PHP-HTML-Parsing-Projekt machen, falls gewünscht.
Als nächstes öffnen Sie den Projektordner in Ihrer bevorzugten IDE. Visual Studio Code mit der PHP-Erweiterung oder IntelliJ WebStorm sind eine gute Wahl für die PHP-Entwicklung.
Fügen Sie nun eine leere index.php-Datei in den Projektordner ein. Ihre Projektstruktur sollte nun wie folgt aussehen:
php-html-parser/
├── vendor/
├── composer.json
└── index.php
Öffnen Sie index.php und fügen Sie den folgenden Code ein, um Ihr Projekt zu initialisieren:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...
Diese Datei wird bald die Logik zum Parsen von HTML in PHP enthalten.
Sie können Ihr Skript nun mit diesem Befehl ausführen:
php index.php
Großartig! Sie sind nun in der Lage, HTML in PHP zu parsen. Von hier aus können Sie damit beginnen, Ihrem Skript die notwendige Logik zum Abrufen und Parsen von HTML hinzuzufügen.
HTML-Abruf in PHP
Bevor Sie HTML in PHP parsen können, benötigen Sie etwas HTML zum Parsen. In diesem Abschnitt werden wir uns zwei verschiedene Ansätze für den Zugriff auf HTML-Inhalte in PHP ansehen.
Mit CURL
PHP unterstützt von Haus aus cURL, einen beliebten HTTP-Client, der zur Durchführung von HTTP-Anfragen verwendet wird. Aktivieren Sie die cURL-Erweiterung oder installieren Sie sie auf Linux mit:
sudo apt-get install php8.4-curl
Sie können cURL verwenden, um eine HTTP-GET-Anfrage an einen Online-Server zu senden und das vom Server zurückgegebene HTML-Dokument abzurufen.
Hier ist ein Beispielskript, das eine einfache GET-Anfrage stellt und HTML-Inhalte abruft:
// initialize cURL session
$ch = curl_init();
// set the URL you want to make a GET request to
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// return the response instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// execute the cURL request and store the result in $response
$html = curl_exec($ch);
// close the cURL session
curl_close($ch);
// output the HTML response
echo $html;
Fügen Sie das obige Snippet in index.php ein und starten Sie es. Es wird den folgenden HTML-Code erzeugen:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hockey Teams: Forms, Searching and Pagination | Scrape This Site | A public sandbox for learning web scraping</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- Omitted for brevity... -->
</html>
Erfahren Sie mehr in unserer Anleitung zu cURL GET-Anfragen in PHP.
Aus einer Datei
Eine andere Möglichkeit, den HTML-Inhalt zu erhalten, besteht darin, ihn in einer eigenen Datei zu speichern. Um das zu tun:
- Besuchen Sie eine Seite Ihrer Wahl im Browser
- Klicken Sie mit der rechten Maustaste auf die Seite
- Wählen Sie die Option “Seitenquelle anzeigen”.
- Kopieren Sie den HTML-Code und fügen Sie ihn in eine Datei ein.
Alternativ können Sie auch Ihre eigene HTML-Logik in eine Datei schreiben.
Für dieses Beispiel nehmen wir an, dass die Datei index.html heißt. Diese enthält den HTML-Code der Seite “Hockey Teams” von Scrape This Site, die zuvor mit cURL abgerufen wurde:
HTML-Parsing in PHP: 3 Herangehensweisen
In diesem Abschnitt lernen Sie, wie Sie drei verschiedene Bibliotheken zum Parsen von HTML in PHP verwenden können:
- Verwendung von
DomHTMLDocumentfür vanilla PHP - Verwendung der Simple HTML DOM Parser-Bibliothek
- Verwendung der
DomCrawler-Komponentevon Symfony
In allen drei Fällen werden Sie sehen, wie man entweder den über cURL abgerufenen HTML-String oder den aus der lokalen index.html-Datei gelesenen HTML-Inhalt analysiert.
Anschließend lernen Sie, wie Sie die Methoden der einzelnen PHP-HTML-Parsing-Bibliotheken nutzen können, um alle Eishockeymannschaftseinträge auf der Seite auszuwählen und Daten daraus zu extrahieren:
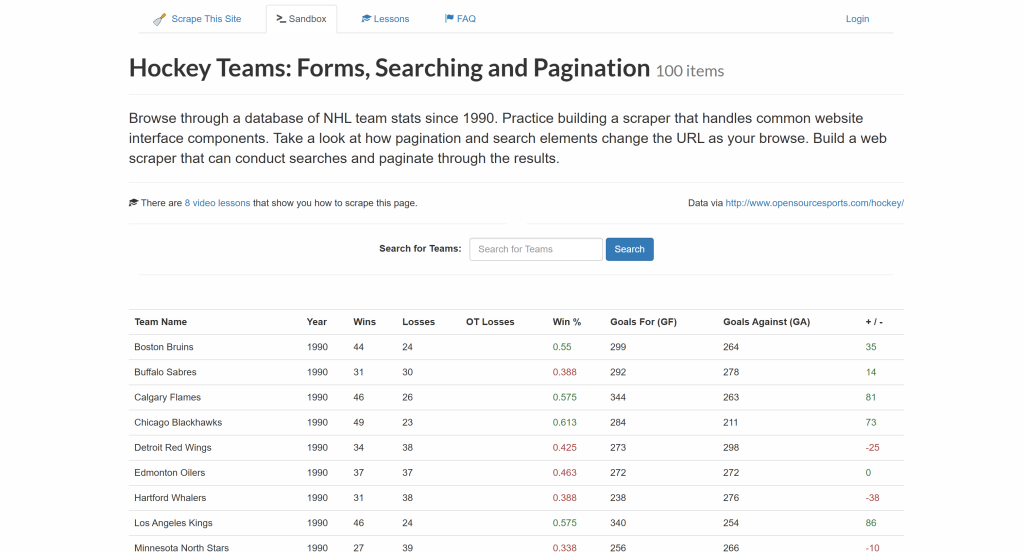
Das Endergebnis ist eine Liste der gescrapten Eishockey-Mannschaftseinträge mit den folgenden Angaben:
- Name der Mannschaft
- Jahr
- Gewinnt
- Verluste
- Gewinn %
- Ziele für (GF)
- Gegentore (GA)
- Tordifferenz
Sie können sie mit dieser Struktur aus der HTML-Tabelle extrahieren:
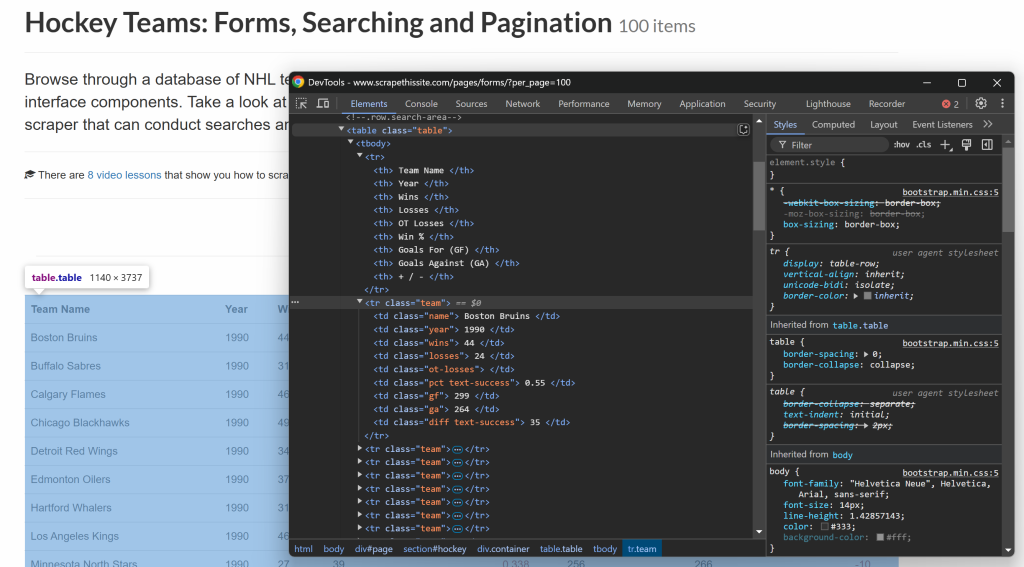
Wie Sie sehen können, hat jede Spalte in einer Tabellenzeile eine bestimmte Klasse. Sie können Daten daraus extrahieren, indem Sie Elemente mit ihrer Klasse als CSS-Selektor auswählen und dann ihren Inhalt abrufen, indem Sie auf ihren Text zugreifen.
Denken Sie daran, dass das Parsen von HTML nur ein Schritt in einem Web-Scraping-Skript ist. Wenn Sie tiefer einsteigen möchten, lesen Sie unser Tutorial über Web Scraping mit PHP.
Lassen Sie uns nun drei verschiedene Ansätze für das HTML-Parsing in PHP untersuchen.
Ansatz #1: Mit DomHTMLDocument
PHP 8.4+ kommt mit einer eingebauten DomHTMLDocument Klasse. Diese stellt ein HTML-Dokument dar und ermöglicht es Ihnen, HTML-Inhalte zu analysieren und im DOM-Baum zu navigieren. Sehen Sie, wie man sie für das Parsen von HTML in PHP verwendet!
Schritt 1: Installation und Einrichtung
DomHTMLDocument ist Teil der Standard PHP Library. Dennoch müssen Sie die DOM-Erweiterung aktivieren oder sie mit diesem Linux-Befehl installieren, um sie zu verwenden:
sudo apt-get install php-dom
Es sind keine weiteren Maßnahmen erforderlich. Sie sind nun bereit, DomHTMLDocument für das HTML-Parsing in PHP zu verwenden.
Schritt #2: HTML-Parsing
Sie können die HTML-Zeichenfolge wie folgt auswerten:
$dom = DOMHTMLDocument::createFromString($html);
Entsprechend können Sie die Datei index.html mit parsen:
$dom = DOMHTMLDocument::createFromFile("./index.html");
$dom ist ein DomHTMLDocument-Objekt, das die für das Parsen von Daten erforderlichen Methoden bereitstellt.
Schritt #3: Datenanalyse
Sie können alle Hockeymannschaftseinträge mit Hilfe von DOMHTMLDocument mit dem folgenden Ansatz auswählen:
// select each row on the page
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// iterate through each row and extract data
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// extracting the data from each column
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// create an array for the scraped team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
}
DOMHTMLDocument bietet keine erweiterten Abfragemethoden. Sie müssen sich also auf Methoden wie getElementsByTagName() und manuelle Iteration verlassen.
Hier eine Aufschlüsselung der verwendeten Methoden:
getElementsByTagName(): Ruft alle Elemente eines bestimmten Tags (wie<table>,<tr>oder<td>) im Dokument ab.item(): Gibt ein einzelnes Element aus einer Liste von Elementen zurück, die vongetElementsByTagName()zurückgegeben wurden.textInhalt: Diese Eigenschaft gibt den rohen Textinhalt eines Elements an, so dass Sie die sichtbaren Daten (wie den Mannschaftsnamen, das Jahr usw.) extrahieren können.
Wir haben auch trim() verwendet, um zusätzliche Leerzeichen vor und nach dem Textinhalt zu entfernen, damit die Daten sauberer sind.
Wenn der obige Ausschnitt in index.php eingefügt wird, führt er zu diesem Ergebnis:
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// omitted for brevity...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[win_pct] => 0.688
[goals_for] => 180
[goals_against] => 117
[goal_diff] => 63
)
Ansatz Nr. 2: Verwendung eines einfachen HTML-DOM-Parsers
Simple HTML DOM Parser ist eine leichtgewichtige PHP-Bibliothek, die es einfach macht, HTML-Inhalte zu parsen und zu manipulieren. Die Bibliothek wird aktiv gepflegt und hat über 880 Sterne auf GitHub.
Schritt 1: Installation und Einrichtung
Sie können Simple HTML Dom Parser über Composer mit diesem Befehl installieren:
composer require voku/simple_html_dom
Alternativ können Sie die Datei simple_html_dom.php auch manuell herunterladen und in Ihr Projekt einbinden.
Dann importieren Sie es in index.php mit dieser Codezeile:
use vokuhelperHtmlDomParser;
Schritt #2: HTML-Parsing
Um einen HTML-String zu analysieren, verwenden Sie die Methode file_get_html():
$dom = HtmlDomParser::str_get_html($html);
Um index.html zu analysieren, schreiben Sie stattdessen file_get_html():
$dom = HtmlDomParser::file_get_html($str);
Dadurch wird der HTML-Inhalt in ein $dom-Objekt geladen, mit dem Sie leicht im DOM navigieren können.
Schritt #3: Datenanalyse
Extrahieren Sie die Daten der Eishockeymannschaft aus dem HTML mit dem Simple HTML DOM Parser:
// find all rows in the table
$rows = $dom->findMulti("table tr.team");
// loop through each row to extract the data
foreach ($rows as $row) {
// extract data using CSS selectors
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print("n");
}
Die oben verwendeten Funktionen des Simple HTML DOM Parser sind:
findMulti(): Wählt alle Elemente aus, die durch den angegebenen CSS-Selektor identifiziert werden.findEins(): Findet das erste Element, das dem angegebenen CSS-Selektor entspricht.Klartext: Ein Attribut zum Abrufen des Rohtextinhalts innerhalb eines HTML-Elements.
Dieses Mal haben wir CSS-Selektoren mit einer vollständigeren und robusteren Logik verwendet. Das Ergebnis ist jedoch dasselbe wie beim ursprünglichen PHP-Ansatz für das HTML-Parsing.
Ansatz #3: Verwendung der DomCrawler-Komponente von Symfony
Die DomCrawler-Komponente von Symfony bietet eine einfache Möglichkeit, HTML-Dokumente zu parsen und Daten aus ihnen zu extrahieren.
Hinweis: Die Komponente ist Teil des Symfony-Frameworks, kann aber auch eigenständig verwendet werden, wie wir in diesem Abschnitt tun werden.
Schritt 1: Installation und Einrichtung
Installieren Sie die DomCrawler-Komponente von Symfony mit diesem Composer-Befehl:
composer require symfony/dom-crawler
Dann importieren Sie sie in die Datei index.php:
use SymfonyComponentDomCrawlerCrawler;
Schritt #2: HTML-Parsing
Um einen HTML-String zu analysieren, erstellen Sie eine Crawler-Instanz mit der Methode html():
$crawler = new Crawler($html);
Um eine Datei zu parsen, verwenden Sie file_get_contents() und erstellen Sie die Crawler-Instanz:
$crawler = new Crawler(file_get_contents("./index.html"));
Die obigen Zeilen laden den HTML-Inhalt in das $crawler-Objekt, das einfache Methoden zum Durchsuchen und Extrahieren von Daten bietet.
Schritt #3: Datenanalyse
Extrahieren Sie die Eishockey-Mannschaftsdaten mit Hilfe der DomCrawler-Komponente:
// select all rows within the table
$rows = $crawler->filter("table tr.team");
// loop through each row to extract the data
$rows->each(function ($row, $i) {
// extract data using CSS selectors
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
});
Die verwendeten DomCrawler-Methoden sind:
each(): Zur Iteration über eine Liste ausgewählter Elemente.filter(): Elemente anhand von CSS-Selektoren auswählen.text(): Extrahiert den Textinhalt der ausgewählten Elemente.
Wunderbar! Sie sind jetzt ein Meister des PHP-HTML-Parsing.
Parsen von HTML in PHP: Vergleichstabelle
Sie können die drei hier untersuchten Ansätze zum Parsen von HTML in PHP in der nachstehenden Übersichtstabelle vergleichen:
| DOMHTMLDocument | Einfacher HTML-DOM-Parser | DomCrawler von Symfony | |
|---|---|---|---|
| Typ | Native PHP-Komponente | Externe Bibliothek | Symfony-Komponente |
| GitHub-Sterne | – | 880+ | 4,000+ |
| XPath-Unterstützung | ❌ | ✔️ | ✔️ |
| CSS-Selektor-Unterstützung | ❌ | ✔️ | ✔️ |
| Lernkurve | Niedrig | Niedrig bis mittel | Mittel |
| Einfachheit der Nutzung | Mittel | Hoch | Hoch |
| API | Grundlegend | Reich | Reich |
Schlussfolgerung
In diesem Artikel haben Sie drei Ansätze für das HTML-Parsing in PHP kennengelernt, die von der Verwendung eingebauter Vanilla-Erweiterungen bis hin zu Bibliotheken von Drittanbietern reichen.
Auch wenn alle diese Lösungen funktionieren, sollten Sie bedenken, dass die Ziel-Webseite möglicherweise JavaScript zum Rendern verwendet. In diesem Fall funktionieren einfache HTML-Parsing-Ansätze wie die oben vorgestellten nicht. Stattdessen benötigen Sie einen vollwertigen Scraping-Browser mit erweiterten HTML-Parsing-Funktionen wie Scraping Browser.
Sie möchten das HTML-Parsing überspringen und die Daten sofort abrufen? Sehen Sie sich unsere gebrauchsfertigen Datensätze für Hunderte von Websites an!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und testen Sie unsere Daten- und Scraping-Lösungen in einer kostenlosen Testversion!





