

Wenn Sie das Web scrapen, ist das Parsing von HTML unabhängig von den verwendeten Tools von entscheidender Bedeutung.Das Web-Scraping mit Java bildet hier keine Ausnahme. In Python verwenden wir Tools wieRequestsundBeautifulSoup. Mit Java können wir unsere HTTP-Anfragen senden und unser HTML mitjsoup parsen. Für dieses Tutorial verwenden wirBooks to Scrape.
Erste Schritte
In diesem Tutorial verwenden wir Maven für das Abhängigkeitsmanagement. Wenn Sie es noch nicht haben, können Sie Mavenhier installieren.
Sobald Sie Maven installiert haben, müssen Sie ein neues Java-Projekt erstellen. Mit dem folgenden Befehl erstellen Sie ein neues Projekt namens jsoup-scraper.
mvn archetype:generate -DgroupId=com.example -DartifactId=jsoup-scraper -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Als Nächstes müssen Sie relevante Abhängigkeiten hinzufügen. Ersetzen Sie den Code inpom.xmldurch den folgenden Code. Dies ähnelt der Abhängigkeitsverwaltung inRustmit Cargo.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<ARTIFACTID>jsoup-scraper</ARTIFACTID>
<PACKAGING>jar</PACKAGING>
<VERSION>1.0-SNAPSHOT</VERSION>
<NAME>jsoup-scraper</NAME>
<URL>http://maven.apache.org</URL>
<DEPENDENCIES>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
</project>
Fügen Sie den folgenden Code in App.java ein. Es ist nicht viel, aber dies ist der grundlegende Scraper, auf dem wir aufbauen werden.
package com.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//Verbindung zu einer Website herstellen und deren HTML abrufen
Document doc = Jsoup.connect(url).get();
//Titel ausgeben
System.out.println("Seitentitel: " + doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Gesamtzahl der gecrawlten Seiten: "+(pageCount-1));
}
}
Jsoup.connect("https://books.toscrape.com").get(): Diese Zeile ruft die Seite ab und gibt einDocument-Objektzurück, das wir bearbeiten können.doc.title()gibt den Titel im HTML-Dokument zurück, in diesem Fall:Alle Produkte | Bücher zum Scrapen – Sandbox.
Verwendung von DOM-Methoden mit Jsoup
jsoup enthält eine Vielzahl von Methoden zum Auffinden von Elementen im DOM (Document Object Model). Wir können jede der folgenden Methoden verwenden, um Seitenelemente einfach zu finden.
getElementById(): Sucht ein Element anhand seinerID.getElementsByClass(): Findet alle Elemente anhand ihrer CSS-Klasse.getElementsByTag(): Findet alle Elemente anhand ihres HTML-Tags.getElementsByAttribute(): Findet alle Elemente, die ein bestimmtes Attribut enthalten.
getElementById
Auf unserer Zielseite enthält die Seitenleiste ein div mit der ID promotions_left. Dies ist in der Abbildung unten zu sehen.
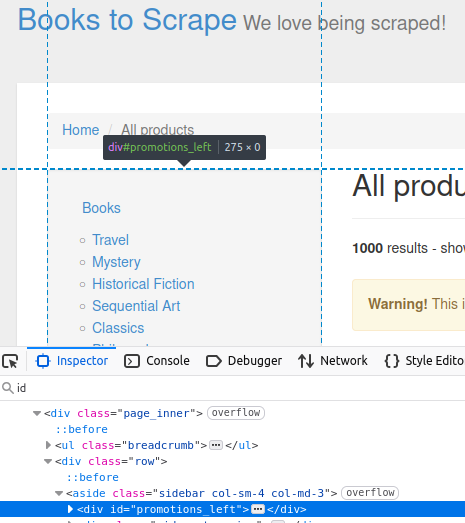
//Nach ID abrufen
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);
Dieser Code gibt das HTML-Element aus, das Sie auf der Inspektionsseite sehen.
Sidebar: <div id="promotions_left">
</div>
getElementsByTag
Mit getElementsByTag() können wir alle Elemente auf der Seite mit einem bestimmten Tag finden. Schauen wir uns die Bücher auf dieser Seite an.
Jedes Buch ist in einem eindeutigen Artikel- Tag enthalten.
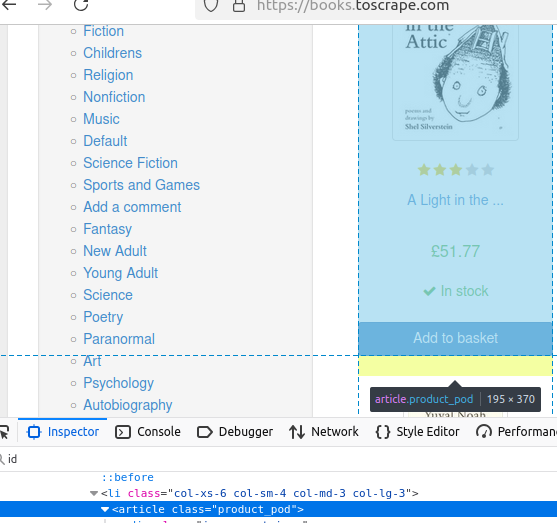
Der folgende Code gibt nichts aus, sondern gibt ein Array mit Büchern zurück. Diese Bücher bilden die Grundlage für den Rest unserer Daten.
//nach Tag abrufen
Elements books = doc.getElementsByTag("article");
getElementsByClass
Sehen wir uns den Preis eines Buches an. Wie Sie sehen können, lautet seine Klasse price_color.
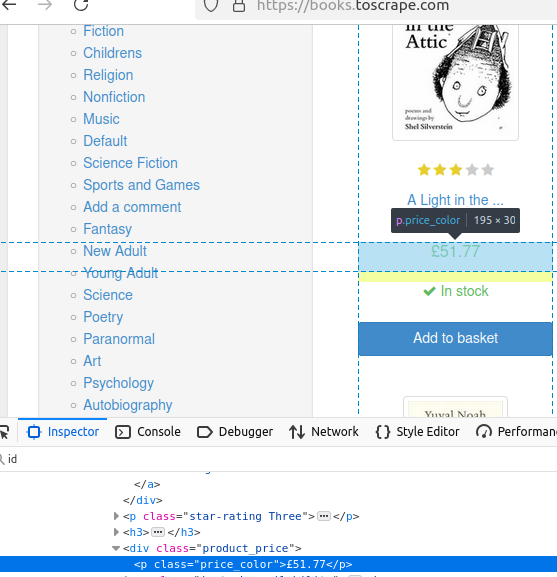
In diesem Ausschnitt finden wir alle Elemente der Klasse „price_color ”. Anschließend geben wir den Text des ersten Elements mit .first().text() aus.
System.out.println("Preis: " + book.getElementsByClass("price_color").first().text());
getElementsByAttribute
Wie Sie vielleicht bereits wissen, benötigen alle a-Elemente ein href-Attribut. Im folgenden Code verwenden wir getElementsByAttribute("href"), um alle Elemente mit einem href zu finden. Wir verwenden .first().attr("href"), um dessen href zurückzugeben.
//nach Attribut abrufen
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Link: https://books.toscrape.com/" + hrefs.first().attr("href"));
Fortgeschrittene Techniken
CSS-Selektoren
Wenn wir mehrere Kriterien zum Suchen von Elementen verwenden möchten, können wir CSS-Selektorenan die Methodeselect()übergeben. Diese Methode gibt ein Array aller Objekte zurück, die dem Selektor entsprechen. Im folgenden Beispiel verwenden wirli[class='next'], um alleli-Elementemit der Klasse„next”zu finden.
Elemente nextPage = doc.select("li[class='next']");
Umgang mit Paginierung
Um unsere Paginierung zu verarbeiten, verwenden wir nextPage.first(), um getElementsByAttribute("href").attr("href") für das erste Element aufzurufen, das aus dem Array zurückgegeben wird, und extrahieren dessen href. Interessanterweise wird nach Seite 2 das Wort „Katalog” aus den Links entfernt. Wenn es also nicht im href vorhanden ist, fügen wir es wieder hinzu. Anschließend kombinieren wir diesen Link mit unserer Basis-URL und verwenden ihn, um den Link zur nächsten Seite zu erhalten.
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
Alles zusammenfügen
Hier ist unser endgültiger Code. Wenn Sie mehr als eine Seite scrapen möchten, ändern Sie einfach die 1 in while (pageCount <= 1) auf Ihr gewünschtes Ziel. Wenn Sie 4 Seiten scrapen möchten, verwenden Sie while (pageCount <= 4).
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//Verbindung zu einer Website herstellen und deren HTML abrufen
Document doc = Jsoup.connect(url).get();
//Titel ausgeben
System.out.println("Seitentitel: " + doc.title());
//Nach ID abrufen
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);
//Nach Tag abrufen
Elements books = doc.getElementsByTag("article");
for (Element book : books) {
System.out.println("------Buch------");
System.out.println("Titel: " + book.getElementsByTag("img").first().attr("alt"));
System.out.println("Preis: " + book.getElementsByClass("price_color").first().text());
System.out.println("Verfügbarkeit: " + book.getElementsByClass("instock availability").first().text());
//nach Attribut abrufen
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Link: https://books.toscrape.com/" + hrefs.first().attr("href"));
}
//nächste Schaltfläche anhand ihres CSS-Selektors suchen
Elements nextPage = doc.select("li[class='next']");
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Gesamtzahl der gescraped Seiten: "+(pageCount-1));
}
}
Bevor Sie den Code ausführen, denken Sie daran, ihn zu kompilieren.
mvn package
Führen Sie ihn dann mit dem folgenden Befehl aus.
mvn exec:java -Dexec.mainClass="com.example.App"
Hier ist die Ausgabe der ersten Seite.
---------------------SEITE 1--------------------------
Seitentitel: Alle Produkte | Bücher zum Scrapen – Sandbox
Seitenleiste: <div id="promotions_left">
</div>
------Buch------
Titel: A Light in the Attic
Preis: 51,77 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
------Buch------
Titel: Tipping the Velvet
Preis: 53,74 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html
------Buch------
Titel: Soumission
Preis: 50,10 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/soumission_998/index.html
------Buch------
Titel: Sharp Objects
Preis: 47,82 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/sharp-objects_997/index.html
------Buch------
Titel: Sapiens: Eine kurze Geschichte der Menschheit
Preis: 54,23 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html
------Buch------
Titel: The Requiem Red
Preis: 22,65 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/the-requiem-red_995/index.html
------Buch------
Titel: The Dirty Little Secrets of Getting Your Dream Job
Preis: 33,34 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
------Buch------
Titel: The Coming Woman: Ein Roman, basierend auf dem Leben der berüchtigten Feministin Victoria Woodhull
Preis: 17,93 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
------Buch------
Titel: The Boys in the Boat: Neun Amerikaner und ihr epischer Kampf um Gold bei den Olympischen Spielen 1936 in Berlin
Preis: 22,60 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
------Buch------
Titel: The Black Maria
Preis: 52,15 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/the-black-maria_991/index.html
------Buch------
Titel: Starving Hearts (Triangular Trade Trilogy, #1)
Preis: £13,99
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html
------Buch------
Titel: Shakespeare's Sonnets
Preis: £20,66
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html
------Buch------
Titel: Set Me Free
Preis: £17,46
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/set-me-free_988/index.html
------Buch------
Titel: Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)
Preis: 52,29 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
------Buch------
Titel: Rip it Up and Start Again
Preis: 35,02 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html
------Buch------
Titel: Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Preis: £57,25
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
------Buch------
Titel: Olio
Preis: £23,88
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/olio_984/index.html
------Buch------
Titel: Mesaerion: Die besten Science-Fiction-Geschichten 1800–1849
Preis: £37,59
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
------Buch------
Titel: Libertarianism for Beginners (Libertarismus für Anfänger)
Preis: £51,33
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html
------Buch------
Titel: It's Only the Himalayas
Preis: 45,17 £
Verfügbarkeit: Auf Lager
Link: https://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html
Gesamtzahl der gescraped Seiten: 1
Fazit
Nachdem Sie nun gelernt haben, wie Sie HTML-Daten mit jsoup extrahieren können, können Sie mit der Erstellung komplexerer Web-Scraper beginnen. Unabhängig davon, ob Sie Produktlisten, Nachrichtenartikel oder Forschungsdaten scrapen, sind der Umgang mit dynamischen Inhalten und die Umgehung von Blockierungen zentrale Herausforderungen.
Um Ihre Scraping-Aktivitäten effizient zu skalieren, sollten Sie die Tools von Bright Data in Betracht ziehen:
- Residential-Proxys – Vermeiden Sie IP-Sperren und greifen Sie auf geografisch eingeschränkte Inhalte zu.
- Scraping-Browser – Rendern Sie JavaScript-lastige Websites mühelos.
- Gebrauchsfertige Datensätze – Überspringen Sie das Scraping ganz und erhalten Sie sofort strukturierte Daten.
Durch die Kombination von jsoup mit der richtigen Infrastruktur können Sie Daten in großem Umfang extrahieren und gleichzeitig das Risiko einer Erkennung minimieren. Sind Sie bereit, Ihr Web-Scraping auf die nächste Stufe zu heben? Melden Sie sich jetzt an und starten Sie die Gratis-Testversion.





