
Web Scraping spielt eine wichtige Rolle bei der Sammlung von Daten in großem Umfang, insbesondere wenn es darum geht, schnelle und fundierte Entscheidungen zu treffen.
In diesem Lernprogramm lernen Sie:
- Was Midscene.js ist und wie es funktioniert,
- Die Einschränkungen bei der Verwendung von Midscene.js,
- Wie Bright Data hilft, diese Herausforderungen zu meistern
- Integration von Midscene.js mit Bright Data für effektives Web-Scraping
Lasst uns eintauchen!
Was ist Midscene.js?
Midscene.js ist ein Open-Source-Tool, mit dem Sie Browser-Interaktionen in einfachem Englisch automatisieren können. Anstatt komplexe Skripte zu schreiben, können Sie einfach Befehle wie “Klicken Sie auf die Anmeldeschaltfläche” oder “Geben Sie das E-Mail-Feld ein” eingeben. Midscene wandelt diese Anweisungen dann mithilfe von KI-Agenten in Automatisierungsschritte um.
Es unterstützt auch moderne Browser-Automatisierungstools wie Puppeteer und Playwright, was es besonders nützlich für Aufgaben wie Tests, UI-Automatisierung und Scraping dynamischer Websites macht.
Im Einzelnen bietet es die folgenden Hauptfunktionen:
- Steuerung in natürlicher Sprache: Automatisieren Sie Aufgaben mithilfe klarer, englischsprachiger Aufforderungen anstelle von Code.
- AI-Integration mit MCP-Server: Verbindet sich mit KI-Modellen über einen MCP-Server, um die Erstellung von Automatisierungsskripten zu unterstützen.
- Integrierte Unterstützung für Puppeteer und Playwright: Dient als High-Level-Ebene über gängigen Frameworks, sodass Ihre Workflows einfach zu verwalten und zu erweitern sind.
- Plattformübergreifende Automatisierung: Unterstützt sowohl Web (über Puppeteer/Playwright) als auch Android (über das JavaScript-SDK).
- Erfahrung ohne Code: Bietet Tools wie die Midscene Chrome-Erweiterung, mit der Sie Automatisierungen erstellen können, ohne Zeilen von Code schreiben zu müssen.
- Einfaches API-Design: Bietet eine saubere, gut dokumentierte API für die Interaktion mit Seitenelementen und die effiziente Extraktion von Inhalten.
Einschränkungen bei der Verwendung von Midscene für die Webbrowser-Automatisierung
Midscene verwendet KI-Modelle wie GPT-4o oder Qwen zur Automatisierung von Browsern durch natürlichsprachliche Befehle. Es funktioniert mit Tools wie Puppeteer und Playwright, hat aber entscheidende Einschränkungen.
Die Genauigkeit von Midscene hängt von der Klarheit Ihrer Anweisungen und der zugrunde liegenden Seitenstruktur ab. Vage Aufforderungen wie “Klicken Sie auf die Schaltfläche” können fehlschlagen, wenn es mehrere ähnliche Schaltflächen gibt. Die KI stützt sich auf Screenshots und visuelle Layouts, sodass kleine strukturelle Änderungen oder fehlende Beschriftungen zu Fehlern oder Fehlklicks führen können. Aufforderungen, die auf einer Webseite funktionieren, funktionieren möglicherweise nicht auf einer anderen mit ähnlichem Aussehen.
Um Fehler zu minimieren, schreiben Sie klare, spezifische Anweisungen, die der Struktur der Seite entsprechen. Testen Sie Prompts immer mit der Midscene Chrome Extension, bevor Sie sie in Automatisierungsskripte integrieren.
Eine weitere wichtige Einschränkung ist der hohe Ressourcenverbrauch. Jeder Automatisierungsschritt mit Midscene sendet einen Screenshot und eine Eingabeaufforderung an das KI-Modell, wobei viele Token verwendet werden – insbesondere bei dynamischen oder datenintensiven Seiten. Dies kann zu Ratenbeschränkungen der KI-API und höheren Nutzungskosten führen, wenn die Anzahl der automatisierten Schritte steigt.
Midscene kann auch nicht mit geschützten Browserelementen wie CAPTCHAs, herkunftsübergreifenden Iframes oder Inhalten hinter Authentifizierungswänden interagieren. Folglich ist das Scraping von sicheren oder geschützten Inhalten nicht möglich. Midscene ist am effektivsten auf statischen oder mäßig dynamischen Websites mit zugänglichen, strukturierten Inhalten.
Warum Bright Data eine effektivere Lösung ist
Bright Data ist eine leistungsstarke Datenerfassungsplattform, die Sie bei der Erstellung, Ausführung und Skalierung Ihrer Web-Scraping-Aktivitäten unterstützt. Sie bietet eine leistungsstarke Proxy-Infrastruktur, Automatisierungstools und Datensätze für Unternehmen und Entwickler, mit denen Sie auf jede öffentliche Website zugreifen, sie extrahieren und mit ihr interagieren können.
- Für dynamische und JavaScript-lastige Websites Bright Data bietet verschiedene Tools wie die SERP-API, Crawl-API, Browser-API und Unlocker-API, mit denen Sie auf komplexe Websites, die Inhalte dynamisch laden, zugreifen, Daten extrahieren und mit ihnen interagieren können. Mit diesen Tools können Sie Daten von jeder Plattform abrufen, was sie ideal für E-Commerce-, Reise- und Immobilienplattformen macht.
- Effiziente Proxy-Infrastruktur Bright Data bietet eine leistungsstarke und flexible Proxy-Infrastruktur über seine vier Hauptnetze: Privatkunden, Rechenzentren, ISP und Mobilfunk. Diese Netzwerke bieten Zugang zu Millionen von IP-Adressen weltweit und ermöglichen es den Nutzern, zuverlässig Webdaten zu sammeln und gleichzeitig die Zahl der Blockierungen zu minimieren.
- Unterstützt Multimedia-Inhalte Bright Data ermöglicht die Extraktion verschiedener Inhaltstypen, einschließlich Videos, Bilder, Audio und Text, aus öffentlich zugänglichen Quellen. Die Infrastruktur ist darauf ausgelegt, umfangreiche Mediensammlungen zu verarbeiten und fortgeschrittene Anwendungsfälle zu unterstützen, wie z. B. das Training von Computer-Vision-Modellen, die Entwicklung von Spracherkennungs-Tools und die Unterstützung von Systemen zur Verarbeitung natürlicher Sprache.
- Bright Databietet vorgefertigteDatensätze, die vollständig strukturiert, hochwertig und sofort einsatzbereit sind. Diese Datensätze decken eine Vielzahl von Bereichen ab, darunter E-Commerce, Stellenanzeigen, Immobilien und soziale Medien, wodurch sie für verschiedene Branchen und Anwendungsfälle geeignet sind.
Integration von Midscene.js mit Bright Data
In diesem Tutorial erfahren Sie, wie Sie mit Midscene und der Browser-API von Bright Data Daten von Websites scrapen können und wie Sie beide Tools für bessere Web-Scraping-Funktionen kombinieren können.
Um dies zu demonstrieren, werden wir eine statische Webseite scrapen, die eine Liste von Mitarbeiterkontaktkarten anzeigt. Wir werden zunächst Midscene und Bright Data einzeln verwenden und dann beide mit Puppeteer integrieren, um zu zeigen, wie sie zusammenarbeiten können.
Voraussetzungen
Um dieser Anleitung folgen zu können, benötigen Sie folgende Voraussetzungen:
- Ein Bright Data-Konto.
- einen Code-Editor, wie z. B. Visual Studio Code, Cursor, usw.
- Ein OpenAI-API-Schlüssel, der das GPT-4o-Modell unterstützt.
- Grundkenntnisse in der Programmiersprache JavaScript.
Wenn Sie noch kein Bright Data-Konto haben, machen Sie sich keine Sorgen. In den folgenden Schritten erfahren Sie, wie Sie ein solches Konto erstellen können.
Schritt 1: Projekt einrichten
Öffnen Sie Ihr Terminal und führen Sie den folgenden Befehl aus, um einen neuen Ordner für Ihre Automatisierungsskripte zu erstellen:
mkdir automation-scripts
cd automation-scripts
Fügen Sie mit dem folgenden Codeschnipsel eine package.json-Datei in den neu erstellten Ordner ein:
npm init -y
Ändern Sie den Wert des Typs package.json von commonjs in module.
{
"type": "module"
}
Als Nächstes installieren Sie die erforderlichen Pakete, um die Ausführung von TypeScript zu ermöglichen und auf die Midscene.js-Funktionalität zuzugreifen:
npm install tsx @midscene/web --save
Als nächstes installieren Sie die Pakete Puppeteer und Dotenv.
npm install puppeteer dotenv
Puppeteer ist eine Node.js-Bibliothek, die eine High-Level-API zur Steuerung von Chrome- oder Chromium-Browsern bietet. Mit Dotenv können Sie Ihre API-Schlüssel sicher speichern.
Nun sind alle erforderlichen Pakete installiert. Wir können mit dem Schreiben der Automatisierungsskripte beginnen.
Schritt #2: Automatisieren Sie Web Scraping mit Midscene.js
Bevor wir fortfahren, erstellen Sie eine .env-Datei im Ordner automation-scripts und kopieren Sie den OpenAI-API-Schlüssel als Umgebungsvariable in diese Datei.
OPENAI_API_KEY=<your_openai_key>
Midscene verwendet das OpenAI GPT-4o-Modell, um die Automatisierungsaufgaben auf der Grundlage der Befehle des Benutzers auszuführen.
Als Nächstes erstellen Sie eine Datei innerhalb des Ordners.
cd automation-scripts
touch midscene.ts
Importieren Sie Puppeteer, Midscene Puppeteer Agent und die dotenv-Konfiguration in die Datei:
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";
Fügen Sie den folgenden Codeschnipsel in die Datei midscene.ts ein:
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 initialize puppeteer
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 set the page config
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 Write automation scripts here 👈🏼
-----------
*/
})()
);
Der Codeschnipsel initialisiert Puppeteer innerhalb einer asynchronen Immediately Invoked Function Expression (IIFE). Mit dieser Struktur können Sie await auf der obersten Ebene verwenden, ohne die Logik in mehrere Funktionsaufrufe zu verpacken.
Fügen Sie anschließend die folgenden Codeschnipsel in das IIFE ein:
//👇🏻 Navigates to the web page
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 init Midscene agent
const agent = new PuppeteerAgent(page as any);
//👇🏻 gives the AI model a query
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 Waits for 5secs
await sleep(5000);
// 👀 log the results
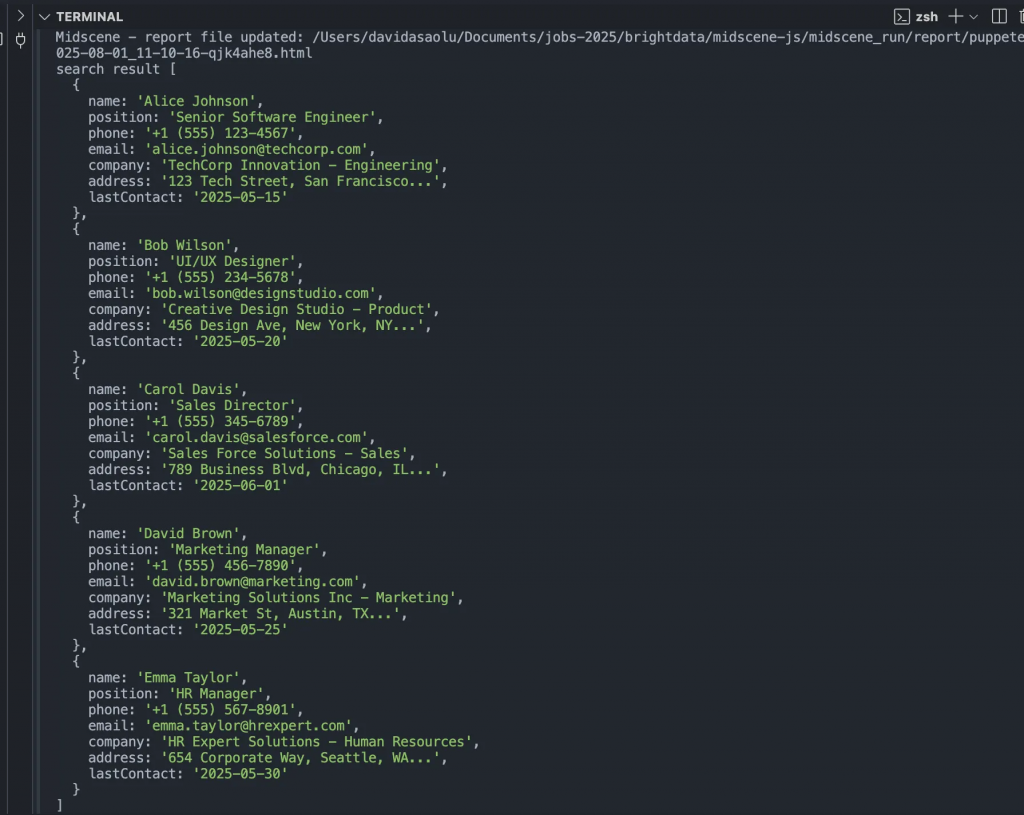
console.log("search result", items);
Das obige Codeschnipsel ruft die Adresse der Webseite auf, initialisiert den Puppeteer-Agenten, ruft alle Kontaktinformationen von der Webseite ab und protokolliert das Ergebnis.
Schritt 3: Automatisieren Sie Web Scraping mit Bright Data Browser API
Erstellen Sie eine brightdata.ts-Datei im Ordner automation-scripts.
cd automation-scripts
touch brightdata.ts
Rufen Sie die Bright Data-Homepage auf und erstellen Sie ein Konto.
Wählen Sie auf Ihrem Dashboard die Option Browser-API und geben Sie dann den Zonennamen und die Beschreibung ein, um eine neue Browser-API zu erstellen.
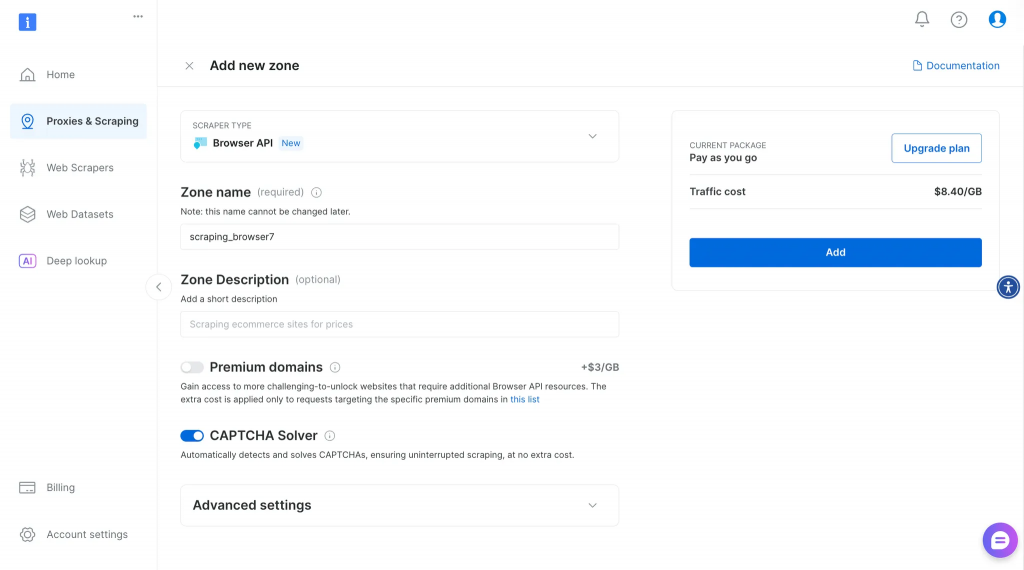
Kopieren Sie anschließend Ihre Puppeteer-Anmeldedaten und speichern Sie sie in der Datei brightdata.ts, wie unten gezeigt:
const BROWSER_WS = "wss://brd-customer-******";
Ändern Sie die Datei brightdata.ts wie unten gezeigt:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
Im Codeausschnitt wird eine Variable für die URL der Webseite und die Browser-API-Anmeldeinformationen von Bright Data deklariert, und anschließend wird eine Funktion deklariert, die die URL als Parameter akzeptiert.
Fügen Sie den folgenden Codeschnipsel in den Platzhalter für den Webautomatisierungs-Workflow ein:
//👇🏻 connect to Bright Data Browser API
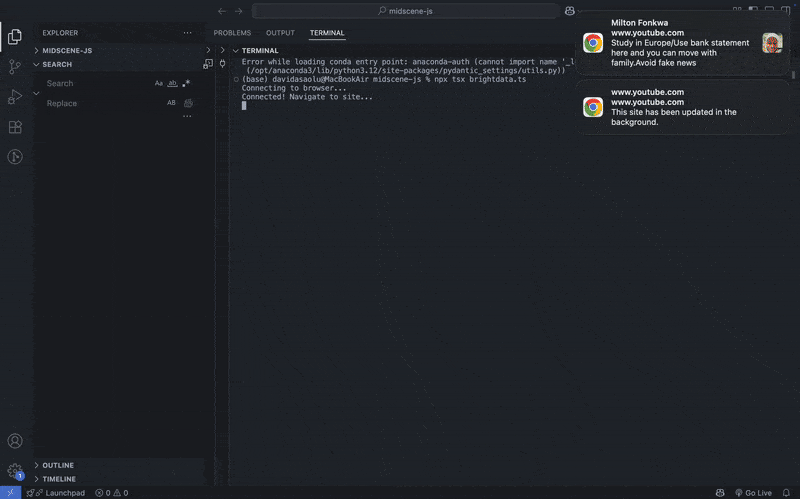
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
Das folgende Codeschnipsel verbindet Puppeteer mit dem Bright Data Browser über Ihren API-WebSocket-Endpunkt. Sobald die Verbindung hergestellt ist, wird eine neue Browserseite geöffnet und zur URL navigiert, die an die Funktion run() übergeben wurde.
Abschließend rufen Sie die Daten auf der Webseite mit Hilfe von CSS-Selektoren mit dem folgenden Codeausschnitt ab:
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
Das obige Codeschnipsel durchläuft jede Kontaktkarte auf der Webseite und extrahiert wichtige Details wie den Namen, die Berufsbezeichnung, die Telefonnummer, die E-Mail-Adresse, das Unternehmen, die Adresse und das letzte Kontaktdatum.
Hier ist das vollständige Automatisierungsskript:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 connect to Bright data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
Schritt Nr. 4: KI-Automatisierungsskripte mit Midscene und Bright Data
Bright Data unterstützt die Webautomatisierung mit KI-Agenten durch die Integration mit Midscene. Da beide Tools Puppeteer unterstützen, können Sie durch die Kombination dieser Tools einfache KI-gestützte Automatisierungsworkflows schreiben. Erstellen Sie eine Datei combine.ts und kopieren Sie den folgenden Codeschnipsel in diese Datei:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
})()
);
Das obige Codeschnipsel erstellt einen asynchronen IIFE (Immediately Invoked Function Expression) und enthält eine Sleep-Funktion, mit der Sie Verzögerungen innerhalb des KI-Automatisierungsskripts hinzufügen können.
Als Nächstes fügen Sie den folgenden Codeschnipsel in den Platzhalter für den Web-Automatisierungsworkflow ein:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 declares page
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to website
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
// 👇🏻 get contact details using AI agent
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 delays for 5secs
await sleep(5000);
//👇🏻 logs the result
console.log("search result", items);
Das Codeschnipsel initialisiert Puppeteer und seinen Agenten, um zur Webseite zu navigieren, alle Kontaktdetails abzurufen und die Ergebnisse in der Konsole zu protokollieren. Dies zeigt, wie Sie den Puppeteer-KI-Agenten mit der Bright Data Browser-API integrieren können, um sich auf die klaren Befehle zu verlassen, die Midscene bereitstellt.
Schritt #5: Alles zusammenfügen
Im vorherigen Abschnitt haben Sie gelernt, wie Sie Midscene in die Bright Data Browser API integrieren. Das vollständige Automatisierungsskript ist unten dargestellt:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to Booking.com
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
await sleep(5000);
console.log("search result", items);
await browser.close();
})()
);
Führen Sie das folgende Codefragment in Ihrem Terminal aus, um das Skript auszuführen:
npx tsx combine.ts
Das obige Codeschnipsel führt das Automatisierungsskript aus und protokolliert die Kontaktdaten in der Konsole.
[
{
name: 'Alice Johnson',
jobTitle: 'Senior Software Engineer',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - Engineering',
address: '123 Tech Street, San Francisco...',
lastContact: 'Last contact: 2026-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX Designer',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - Product',
address: '456 Design Ave, New York, NY...',
lastContact: 'Last contact: 2026-05-20'
},
{
name: 'Carol Davis',
jobTitle: 'Sales Director',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: 'Sales Force Solutions - Sales',
address: '789 Business Blvd, Chicago, IL...',
lastContact: 'Last contact: 2026-06-01'
},
{
name: 'David Brown',
jobTitle: 'Marketing Manager',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: 'Marketing Solutions Inc - Marketing',
address: '321 Market St, Austin, TX...',
lastContact: 'Last contact: 2026-05-25'
},
{
name: 'Emma Taylor',
jobTitle: 'HR Manager',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: 'Last contact: 2026-05-30'
}
]
Schritt #6: Nächste Schritte
Dieses Tutorial zeigt, was möglich ist, wenn Sie Midscene mit der Bright Data Browser API integrieren. Sie können auf dieser Grundlage aufbauen, um komplexere Arbeitsabläufe zu automatisieren.
Durch die Kombination beider Tools können Sie effiziente und skalierbare Aufgaben der Browser-Automatisierung durchführen, wie z. B.:
- Scraping strukturierter Daten von dynamischen oder JavaScript-lastigen Websites
- Automatisieren von Formularübermittlungen für Tests oder Datenerfassung
- Navigieren auf Websites und Interaktion mit Elementen unter Verwendung natürlichsprachlicher Anweisungen
- Ausführung umfangreicher Datenextraktionsaufträge mit Proxy-Management und CAPTCHA-Behandlung
Schlussfolgerung
Bisher haben Sie gelernt, wie man Web-Scraping-Prozesse mit Midscene und der Bright Data Browser API automatisiert und wie man beide Tools zum Scrapen von Websites durch KI-Agenten verwendet.
Midscene hängt stark von KI-Modellen für die Browser-Automatisierung ab, und die Verwendung mit dem Bright Data Scraping Browser bedeutet weniger Codezeilen mit effektiven Web Scraping-Funktionen. Die Browser-API ist nur ein Beispiel dafür, wie die Tools und Services von Bright Data eine fortschrittliche KI-gestützte Automatisierung ermöglichen können.
Melden Sie sich jetzt an, um alle Produkte zu entdecken.




