

In diesem Blogbeitrag zum Thema „Managed vs. API-basiertes Web-Scraping” erfahren Sie:
- Einen Überblick über verwaltete Web-Scraping-Dienste und API-basierte Web-Scraping-Lösungen.
- Was Managed Web-Scraping ist, wie es funktioniert, seine wichtigsten Anwendungsfälle und wann es die beste Wahl ist.
- Was Web-Scraping-APIs sind, wie sie funktionieren, ihre wichtigsten Anwendungsfälle und wann sie den größten Nutzen erzielen.
- Einen abschließenden Vergleich, der Ihnen bei der Entscheidung hilft, welcher Ansatz am besten zu Ihren Anforderungen bei der Webdatenerfassung passt.
Lassen Sie uns eintauchen!
Einführung in verwaltete Web-Scraping-Dienste und Web-Scraping-APIs
Managed Web-Scraping und API-basiertes Web-Scraping sind zwei der gängigsten Ansätze zur Erfassung von Webdaten. In beiden Fällen werden die größten Herausforderungen des Web-Scrapings (z. B. Browser-Fingerprinting, JavaScript-Rendering, TLS-Fingerprints, Ratenbeschränkungen, CAPTCHAs und ähnliche Hindernisse) an einen Drittanbieter ausgelagert.
Bei Managed Services wird der gesamte Scraping-Prozess vollständig ausgelagert. Der Anbieter arbeitet mit Ihnen zusammen, um Ihre Anforderungen zu verstehen, und liefert die erforderlichen Daten, oft angereichert mit Erkenntnissen und benutzerdefinierten Analysen. Im Wesentlichen handelt es sich um eine End-to-End-Komplettlösung.
Auf der anderen Seite umfasst API-basiertes Web-Scraping die Erstellung benutzerdefinierter Skripte, KI-Agenten oder Pipelines, die eine Verbindung zu Scraping-APIs herstellen. Diese Endpunkte sammeln strukturierte Webdaten aus bekannten Domänen und kümmern sich gleichzeitig um Anti-Scraping-Umgehung, Skalierbarkeit und Infrastruktur. Sie sind jedoch weiterhin für die Integration, Datenspeicherung und andere technische Aspekte verantwortlich.
Bei beiden Ansätzen ist die Wahl eines zuverlässigen Anbieters von entscheidender Bedeutung. Bright Data ist ein führender Anbieter von Web-Scraping-Lösungen, der beide Ansätze abdeckt:
- Verwaltete Datenerfassung: Greifen Sie ohne Entwicklungs- oder Wartungsaufwand auf Daten und Erkenntnisse zu – dank eines vollständig verwalteten Dienstes der Enterprise-Klasse.
- Web-Scraping-APIs: Eine umfangreiche Sammlung von Scraping-Endpunkten für über 120 beliebte Plattformen. Sie unterstützen automatische Proxy-Rotation, Anti-Bot-Umgehung, JavaScript-Rendering und vieles mehr.
Was Bright Data auszeichnet, ist seine unternehmensgerechte Infrastruktur, die weltweit über 20.000 Unternehmen mit einer Verfügbarkeit und Erfolgsquote von 99,99 %, einem 24/7-Experten-Support, konformen und ethisch einwandfreien Daten sowie Zugriff auf über 150 Millionen echte Nutzer-IPs in 195 Ländern unterstützt – eines der größten Proxy-Netzwerke der Welt.
Managed Web-Scraping: Ein tiefer Einblick
Beginnen wir diesen Artikel zum Thema Managed Scraping vs. API-basiertes Scraping mit einem Blick auf Managed Web Data Acquisition Services und einer Erläuterung, wofür sie am besten geeignet sind.
Was ist das
Managed Web-Scraping ist ein End-to-End-Datenerfassungsdienst, bei dem ein Anbieter alles für Sie übernimmt.
Dazu gehören das Auffinden von Webseiten, das Umgehen von Anti-Bot-Systemen, das Parsing von Daten aus den identifizierten Seiten, die Validierung und Bereinigung der Ergebnisse, die Skalierung der Infrastruktur und die Bereitstellung strukturierter, zuverlässiger und konformer Daten, die Ihren Anforderungen entsprechen.
Anstatt Scraping-Bots zu erstellen und zu warten und die gesamte Infrastruktur zu verwalten, beschreiben Sie dem Anbieter einfach Ihre Wünsche. Im Gegenzug liefert der Anbieter gebrauchsfertige Datensätze, Dashboards oder Erkenntnisse, die Ihren Anforderungen entsprechen.
Das Ziel des Managed Web-Scraping ist es, Zeit zu sparen, den technischen Aufwand zu reduzieren und die Betriebskosten zu senken, während Sie weiterhin Zugriff auf die gewünschten Daten haben.
So funktioniert es
Wenn Sie sich für eine Managed Web Data Acquisition-Lösung entscheiden, wird der gesamte Datenfluss für Sie abgewickelt. Von der Ersteinrichtung bis zur endgültigen Lieferung kümmert sich der Anbieter um jeden Schritt, der erforderlich ist, um Ihnen die gewünschten Daten im gewünschten Format oder in der gewünschten Darstellung zu liefern.
Der Prozess umfasst in der Regel die folgenden Phasen:
- Projektstart: Sie beginnen mit der Auswahl eines Managed Data Collection Service. Anschließend arbeiten Sie eng mit den Experten des Anbieters zusammen, um Datenquellen, erforderliche Felder, Erkenntnisse und KPIs zu definieren, die Ihren Geschäftszielen entsprechen.
- Datenerfassung: Der Managed-Scraping-Anbieter leitet den gesamten Datenerfassungsprozess. Sein Team erstellt, automatisiert und skaliert die Extraktionslösung entsprechend Ihren Anforderungen und führt sie kontinuierlich aus, während Ihr Projektmanager die Ausführung überwacht.
Sie haben nun Zugriff auf die von Ihnen angeforderten Daten. Bei den besten Anbietern ist der Prozess damit jedoch noch nicht abgeschlossen, sondern umfasst zwei weitere Schritte:
- Datenvalidierung und -anreicherung: Der Anbieter verfeinert die Daten mithilfe automatisierter Deduplizierung, Querverweisen und kontinuierlicher Qualitätsüberwachung. Das Ziel ist es, genaue, konsistente, angereicherte und qualitativ hochwertige Daten zu liefern.
- Berichte und Erkenntnisse: Sobald die Daten gesammelt und aufbereitet sind, kann der Anbieter auch Erkenntnisse über Dashboards, Echtzeit-Tracking und fachkundige Beratung liefern, um bessere Geschäftsentscheidungen zu unterstützen.
Wie Sie sehen, ist dieser Ansatz wirklich ganzheitlich. Er stellt sicher, dass der gesamte Prozess der Datenbeschaffung, -verarbeitung und -finalisierung für Sie vollständig verwaltet wird, von den Rohdaten bis hin zu verwertbaren Erkenntnissen.
Anforderungen
Für verwaltete Web-Scraping-Dienste sind praktisch keine technischen Kenntnisse Ihrerseits erforderlich. Der Grund dafür ist, dass der gesamte Daten-Scraping-Prozess ausgelagert wird. Sie benötigen also kein technisches Fachwissen, um Scraper zu erstellen, Proxy-Server zu verwalten oder die zugrunde liegende Infrastruktur zu verwalten.
Die wichtigste Voraussetzung ist ein klares Verständnis Ihrer Datenanforderungen, einschließlich Aspekten wie Zielquellen, Datenfeldern, Anzahl der Datensätze und Aktualisierungshäufigkeit. Natürlich müssen Sie auch in der Lage sein, die gelieferten Ergebnisse zu verstehen und zu nutzen.
Anwendungsfälle
Managed Web-Scraping kann praktisch alle Branchen unterstützen. Anbieter können sogar Daten aus mehreren Quellen gleichzeitig aggregieren, z. B. Informationen aus mehreren E-Commerce-Plattformen mit Social-Media-Daten für Stimmungsanalysen kombinieren.
Am besten geeignet
Managed Web-Scraping ist ideal, wenn Ihnen die Fähigkeiten, die Infrastruktur oder die Kapazitäten für ein Datenerfassungsprojekt fehlen.
Der Grund dafür ist, dass der Aufbau einer zuverlässigen Datenpipeline, die durch Web-Scraping gespeist wird, alles andere als einfach ist. Sie müssen die richtigen Scraping-Tools auswählen, Proxies integrieren und Anti-Scraping-Bypass-Lösungen implementieren, damit Ihre Skripte in realen Szenarien effektiv sind.
Darüber hinaus müssen Sie Websites auf strukturelle Änderungen überwachen, überprüfen, ob Ihre benutzerdefinierte Software konsistent läuft, und die Skalierbarkeit Ihrer Infrastruktur verwalten. Und das sind nur einige der Aspekte, die bei der Erstellung und Verwaltung eines produktionsreifen Web-Scraping-Prozesses eine Rolle spielen…
All dies führt zu einem erheblichen Zeit- und Kostenaufwand für Personal, Server und Lösungen von Drittanbietern. Durch die Nutzung eines Managed Service anstelle einer internen Lösung entfallen diese Anforderungen. Das bedeutet einen optimierten Workflow, mit dem Sie erhebliche Kosten einsparen können, insbesondere wenn Ihr Team wenig oder keine Erfahrung mit Web-Scraping hat.
Betrachten Sie beispielsweise den geschätzten ROI, wenn Sie sich für die Managed Web-Scraping Services von Bright Data entscheiden, anstatt den Prozess selbst zu implementieren und zu verwalten: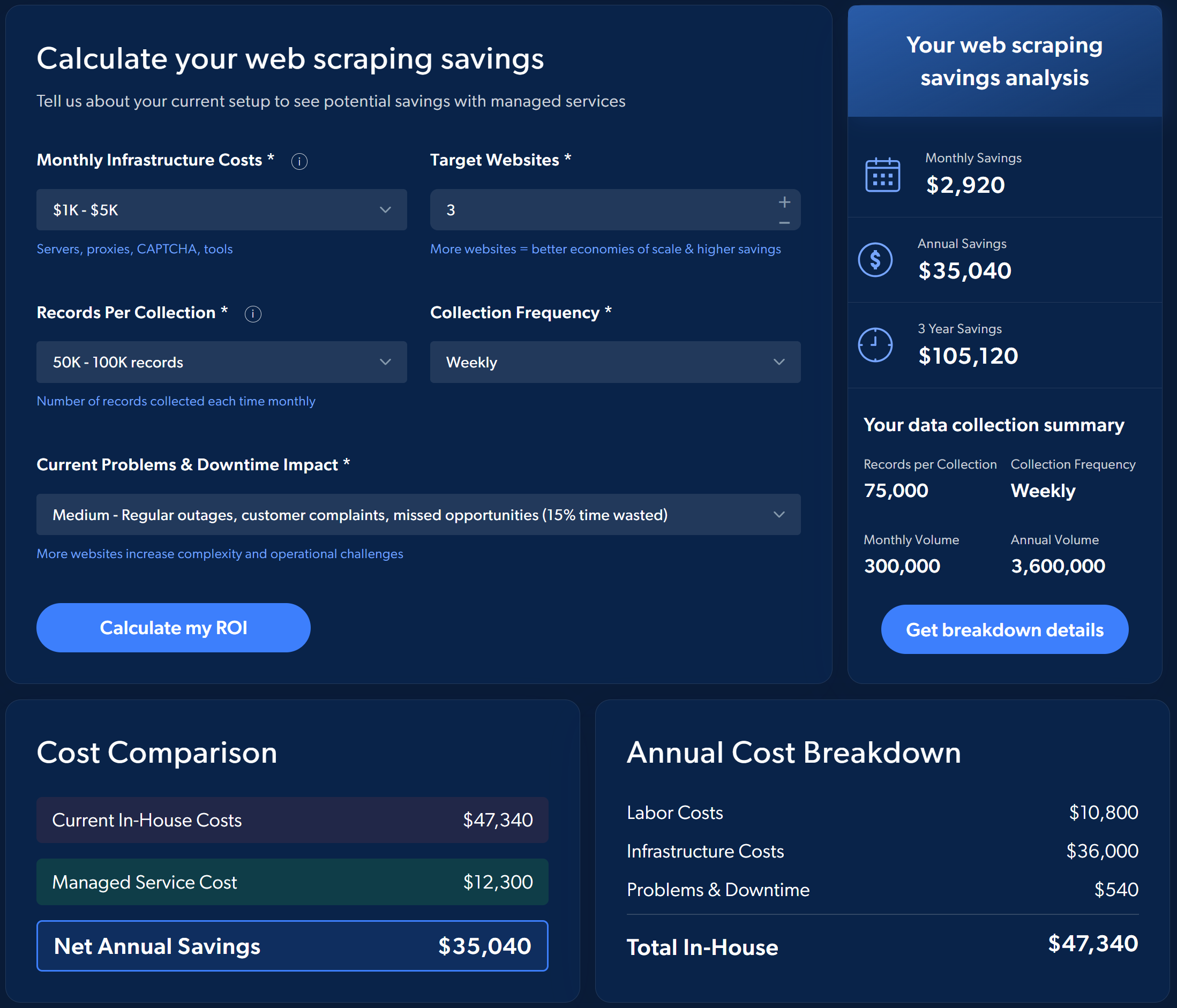
Um eine Vorstellung von den potenziellen Einsparungen zu bekommen, führen Sie eine einfache Simulation direkt auf der Seite des Managed Data Collection Service von Bright Data durch.
Kurz gesagt: Managed Services sind ideal für Unternehmen, die zuverlässige, aktuelle, skalierbare und validierte Daten wünschen, ohne in ein spezielles Team investieren zu müssen.
API-basiertes Web-Scraping: Eine eingehende Analyse
Setzen Sie diesen Blogbeitrag zum Thema Managed vs. API-basiertes Web-Scraping fort, indem Sie sich mit der Web-Datenerfassung durch Scraping-APIs befassen, die alle wichtigen Informationen enthalten, die Sie wissen müssen.
Was ist das
API-basiertes Web-Scraping beinhaltet die direkte Verbindung mit einer Scraping-API-Lösung, um Webdaten zu sammeln. Diese APIs lassen sich in drei Typen einteilen:
- Offizielle Website-APIs: Bieten Zugriff auf einen vordefinierten Datensatz direkt von der Website.
- Allgemeine Web-Unblocker-APIs: Endpunkte, die Anti-Bot-Schutzmaßnahmen auf jeder Webseite umgehen.
- Spezifische Web-Scraping-APIs: Scrapen bestimmte Domains und geben strukturierte Daten mit einem vorgegebenen Schema zurück.
Hier konzentrieren wir uns auf die letzten beiden Arten von Web-Scraping-APIs. Der Grund dafür ist, dass offizielle Website-APIs oft teuer sind, strenge Ratenbeschränkungen haben und Ihnen wenig Kontrolle bieten, da die Website jederzeit die Bereitstellung von Daten einstellen kann. Weitere Informationen finden Sie in unserem Leitfaden zu Web-Scraping vs. API.
So funktioniert es
API-basiertes Web-Scraping ist ein guter Mittelweg zwischen vollständig internen und vollständig ausgelagerten Ansätzen.
Die Idee besteht darin, einfache Skripte zu erstellen, die sich mit diesen APIs verbinden, die alle aufwändigen Aufgaben übernehmen, darunter das Abrufen von Seiten, die Verarbeitung von JavaScript-Renderings, das Umgehen von Anti-Scraping-Schutzmaßnahmen und möglicherweise sogar die Rückgabe bereits strukturierter Daten.
Zunächst suchen Sie den richtigen Web-Scraping-API-Anbieter für Ihre Anforderungen. Wenn Scraping-APIs verfügbar sind, die die gewünschten Daten bereitstellen, sollten Sie diese direkt verwenden. Andernfalls können Sie sich für eine Web-Unblocker-API entscheiden, die den entsperrten HTML-Code der gewünschten Webseiten liefert.
Bei der Verwendung von Scraping-APIs müssen Sie nur einfache Skripte erstellen, die die API aufrufen, Fehler mit einer Wiederholungslogik im Falle gelegentlicher Ausfälle behandeln und die abgerufenen Daten in einer Datenbank, in lokalen Dateien, in der Cloud oder mit Ihrer bevorzugten Speichermethode speichern.
Wenn Sie sich für eine Web-Unblocker-API entscheiden, müssen Sie eine benutzerdefinierte Datenparsing-Logik implementieren, entweder mithilfe von CSS-Selektoren/XPath-Ausdrücken oder künstlicher Intelligenz. Sobald die Daten aus dem entsperrten HTML extrahiert wurden, sollten sie wie zuvor beschrieben gespeichert werden.
Schließlich müssen die Daten validiert, bereinigt, verarbeitet und analysiert werden, um Erkenntnisse zu gewinnen.
Anforderungen
Obwohl API-basiertes Web-Scraping viel einfacher ist als die Erstellung eines Web-Scrapers von Grund auf, erfordert es dennoch einige technische Vorbereitungen.
Sie benötigen grundlegende Programmierkenntnisse, um Skripte zu schreiben, die die APIs in Ihrer bevorzugten Programmiersprache programmgesteuert aufrufen. Außerdem sollten Sie wissen, wie Sie die Authentifizierung angehen, parallele HTTP-Anfragen verwalten und mit häufigen Fehlern umgehen.
Hinweis: Führende Anbieter bieten oft No-Code-Lösungen an, mit denen Sie Web-Scraping-APIs nutzen können, ohne Code schreiben zu müssen oder technische Kenntnisse zu benötigen.
Um die gesammelten Daten zu speichern, müssen Sie auch mit den Optionen zur Datenspeicherung vertraut sein. Außerdem müssen Sie über Datenmanagement-Kenntnisse verfügen, um Duplikate zu vermeiden und regelmäßige Aktualisierungen mit korrekter Versionierung sicherzustellen.
Wenn Sie eine Web-Unblocker-API anstelle einer dedizierten Web-Scraping-API verwenden, benötigen Sie zusätzliche Kenntnisse, um HTML zu parsen und die Daten entsprechend Ihren Anforderungen zu strukturieren. Schließlich sind datenbezogene Kenntnisse erforderlich, um die Daten für die Verarbeitung, Visualisierung und Analyse vorzubereiten.
Anwendungsfälle
Web-Scraping-APIs unterstützen eine lange Liste von Anwendungsfällen, darunter
- E-Commerce: Abrufen von Produktinformationen, Preisen, Bewertungen und Verkäuferdaten von Websites wie Amazon, eBay und Walmart.
- Finanzen: Zugriff auf Aktiendaten, Finanzberichte und Markttrends von Plattformen wie Yahoo Finance oder Nasdaq.
- Arbeitsmarkt: Sammeln Sie Stellenanzeigen und Unternehmensdaten von LinkedIn, Indeed und anderen.
- Reisen: Verfolgen Sie Flüge, Hotelverfügbarkeit und Preise von Expedia, Booking.com und ähnlichen Websites.
- B2B: Abrufen von Unternehmensdaten aus Quellen wie Crunchbase oder ZoomInfo.
- Soziale Medien: Überwachen Sie Beiträge, Trends und Interaktionen von X, Instagram und TikTok.
- Suchmaschinen: Führen Sie programmatische Suchen in Suchmaschinen wie Google, Bing, Yandex und anderen mithilfe spezieller SERP-API und Web-Such-API durch.
Mit einer Web-Unblocker-API können Sie dann auf strukturierte Daten von praktisch jeder Website zugreifen, auch von solchen ohne dedizierte Scraping-API.
Am besten geeignet für
API-basiertes Scraping eignet sich am besten für Situationen, in denen Sie konsistente, strukturierte Webdaten benötigen, ohne den Prozess vollständig auszulagern. Es schafft ein Gleichgewicht zwischen interner Entwicklung und Managed Services und ermöglicht es Ihnen, die Kontrolle über die Datenerfassung zu behalten, während die API die wichtigsten Herausforderungen übernimmt.
Verwaltetes vs. API-basiertes Web-Scraping: Direktvergleich
Nachdem Sie nun beide Methoden zum Abrufen von Webdaten kennen, ist es an der Zeit, sie in einem Abschnitt zum Managed Scraping vs. API-basiertem Scraping zu vergleichen.
So wählen Sie den richtigen Scraping-Ansatz
Vergleichen Sie verwaltetes Web-Scraping mit API-basiertem Web-Scraping in der folgenden Übersichtstabelle:
| Verwaltetes Web-Scraping | API-basiertes Web-Scraping | |
|---|---|---|
| Beschreibung | Sie beschreiben Ihre Anforderungen dem Anbieter, der Daten aus den ausgewählten Quellen extrahiert und liefert. | Sie stellen eine Verbindung zu APIs her, um Webdaten abzurufen. Die API übernimmt das Abrufen von Seiten, die Umgehung von Anti-Bot-Maßnahmen, die Integration von Proxy usw. |
| Für wen | Unternehmen, die eine Lösung ohne eigenen Aufwand benötigen und nicht über die erforderlichen internen Kompetenzen oder die entsprechende Infrastruktur verfügen. | Teams mit internen Ingenieuren oder technischen Ressourcen, die die Kontrolle über die Datenerfassung behalten und gleichzeitig die Schwerarbeit auslagern möchten. |
| Einrichtung und Wartung | Vollständig vom Anbieter verwaltet. Keine technische Einrichtung Ihrerseits erforderlich. | Erfordert grundlegende Programmierkenntnisse und die Einrichtung von Skripten, Fehlerbehandlung und Speicherplatz. |
| Anti-Bot-Handhabung | Wird vollständig vom Anbieter übernommen. | Wird vollständig vom Anbieter übernommen. |
| Infrastruktur | Wird vollständig vom Anbieter verwaltet. | Verwaltung durch den API-Anbieter, aber die Bereitstellung und Integration Ihrer Skripte liegt in Ihrer Verantwortung. |
| Lieferung | Die Daten werden in dem von Ihnen gewünschten Format und auf die von Ihnen gewünschte Weise geliefert. | Die Daten werden von der Scraping-API im HTML-, JSON- oder Markdown-Format zurückgegeben. |
| Datenbereinigung und Qualitätssicherung | Automatisierte Validierung, Deduplizierung, Anreicherung und fortlaufende Qualitätsprüfungen werden vom Anbieter durchgeführt. | Sie sind für die weitere Validierung, Bereinigung und Verarbeitung verantwortlich. |
| Einblicke und Dashboards | Der Anbieter kann benutzerdefinierte Dashboards, Berichte, Analysen und umsetzbare Erkenntnisse liefern. | Nicht enthalten. |
| Beratung und Strategie | Expertenempfehlungen und Anleitungen zur Optimierung der Datenerfassung und -nutzung sind enthalten. | Nicht enthalten. |
| Support | Engagiertes Support-Team, einschließlich Daten-Concierge für Fehlerbehebung und Projektmanagement. | Beschränkt auf API-Dokumentation und grundlegende technische Unterstützung. |
Verwaltetes Web-Scraping
👍 Vorteile:
- Zugriff auf gebrauchsfertige strukturierte Daten, Dashboards oder Erkenntnisse.
- End-to-End-Service, der Datenerfassung, Validierung, Anreicherung und Bereitstellung umfasst, ohne dass technische Kenntnisse erforderlich sind.
- Reduziert Betriebskosten und technischen Aufwand.
- Anwendbar auf praktisch jeden Anwendungsfall, jede Branche und jedes Szenario.
- Unterstützung und Empfehlungen durch ein multidisziplinäres Expertenteam.
👎 Nachteile:
- Weniger Kontrolle über den Scraping-Prozess.
- Volle Abhängigkeit von einem bestimmten Drittanbieter.
API-basiertes Web-Scraping
👍 Vorteile:
- Einfache Integration in bestehende Systeme.
- Hohe Geschwindigkeit und Parallelität, unterstützt viele gleichzeitige Anfragen.
- Keine Notwendigkeit, sich um Sperren oder Anti-Bot-Beschränkungen zu kümmern.
- Keine Infrastrukturverwaltung oder Wartung erforderlich.
- Gut geeignet für die Erstellung benutzerdefinierter Scraping-Tools für KI-Agenten oder automatisierte Workflows.
👎 Nachteile:
- Erfordert technische Kenntnisse.
- Sie sind für die Validierung, Bereinigung und Strukturierung der Daten verantwortlich.
Abschließende Bemerkung
Sowohl verwaltete Webdienste als auch Web-Scraping-APIs dienen dazu, Webdaten bereitzustellen, gehen das Problem jedoch unterschiedlich an.
Web-Scraping-APIs sind Endpunkte für die vereinfachte Datenabfrage, die Entwickler direkt in Skripte, Pipelines oder sogar KI-Agenten und Workflows integrieren können. Sie sind ideal, wenn Sie bestimmte Datenpunkte wie Produktpreise, Bewertungen oder Suchergebnisse benötigen, ohne die zugrunde liegende Infrastruktur verwalten zu müssen. Allerdings erfordern sie dennoch einige Einrichtungs- und technische Kenntnisse.
Umgekehrt übernehmen verwaltete Web-Scraping-Erfassungsdienste den gesamten Datenlebenszyklus – von der Extraktion über die Validierung und Anreicherung bis hin zur Bereitstellung –, ohne dass interne Engineering- oder Wartungsarbeiten erforderlich sind.
Insbesondere die Managed Data Acquisition-Lösung von Bright Data veranschaulicht diesen Ansatz. Sie bietet Pipelines auf Unternehmensniveau, automatisierte Qualitätsprüfungen, die Einhaltung von Datenschutzgesetzen und Dashboards für Echtzeit-Einblicke. Sie müssen lediglich Ihre Ziele und KPIs definieren, und Bright Data kümmert sich um die Skalierung, Überwachung und Bereitstellung von gebrauchsfertigen strukturierten Daten, damit Sie Ihre Kapitalrendite maximieren können.
Zusammenfassend lässt sich sagen: API geben Ihnen die Werkzeuge an die Hand, Managed Services liefern Ihnen das fertige Produkt!
Fazit
In diesem Leitfaden haben Sie die Nuancen der beiden beliebtesten Ansätze für das Web-Scraping untersucht: Managed Services und API-basierte Lösungen.
Sie haben gelernt, dass Managed Web-Scraping ideal ist, wenn Sie eine vollständig automatisierte Lösung wünschen. Es liefert Ihnen nicht nur die Daten, sondern auch validierte Datensätze und interessante Einblicke. Und das alles ohne technische Komplexität. Im Gegensatz dazu bieten Web-Scraping-APIs mehr Flexibilität und Kontrolle, erfordern jedoch möglicherweise Programmierkenntnisse.
Unabhängig davon, für welchen Ansatz Sie sich entscheiden, Bright Data hat die passende Lösung für Sie. Das Unternehmen bietet branchenführende Web-Scraping-APIs wie die Unlocker-API und domänenspezifische Scraper-APIs sowie Managed Data Acquisition Services für Unternehmen.
Melden Sie sich kostenlos bei Bright Data an und entdecken Sie noch heute unsere Web-Scraping-Lösungen!





