
Ein globales Finanzinstitut muss Live-Marktdaten aus dem Internet mit vertraulichen internen Analysen kombinieren. Die Daten sind aufgeteilt zwischen einem lokalen Warehouse (für sensible Kundendaten) und Azure Data Lake (für skalierbare Analysen). In diesem Leitfaden erfahren Sie, wie Sie beide über die APIs von Bright Data für eine sichere Integration nahezu in Echtzeit verbinden können.
Sie erfahren:
- Warum Finanzorganisationen hybride Datenkonfigurationen benötigen
- Wie Sie mit Bright Data konforme Webdaten sammeln
- Wie Sie eine sichere bidirektionale Synchronisierung zwischen Azure Data Lake und einem lokalen Warehouse einrichten
- Wie Sie die End-to-End-Datensynchronisierung validieren
- Wie Sie einheitliche Analysen durchführen, ohne sensible Daten zu verschieben
- Wo Sie die Beispielkonfigurationen und Skripte in GitHub finden
Was ist hybride Datenintegration und warum braucht die Finanzbranche sie?
Finanzorganisationen unterliegen strengen Vorschriften wie DSGVO, SOC 2, MiFID II und Basel III, die regeln, wo Daten gespeichert werden dürfen. Öffentliche Webdaten liefern Echtzeit-Marktinformationen, während vorhandene interne Datensätze die langfristige Modellierung und Compliance unterstützen. Herkömmliche ETL-Systeme vereinen beide Aspekte selten auf sichere Weise.
Die Herausforderung: Wie lassen sich externe Marktdaten mit internen Analysen kombinieren, ohne die Sicherheit oder Compliance zu beeinträchtigen?
Die Lösung: Bright Data stellt strukturierte, konforme Webdaten über APIs bereit, während die hybride Infrastruktur von Azure sensible Daten vor Ort speichert.
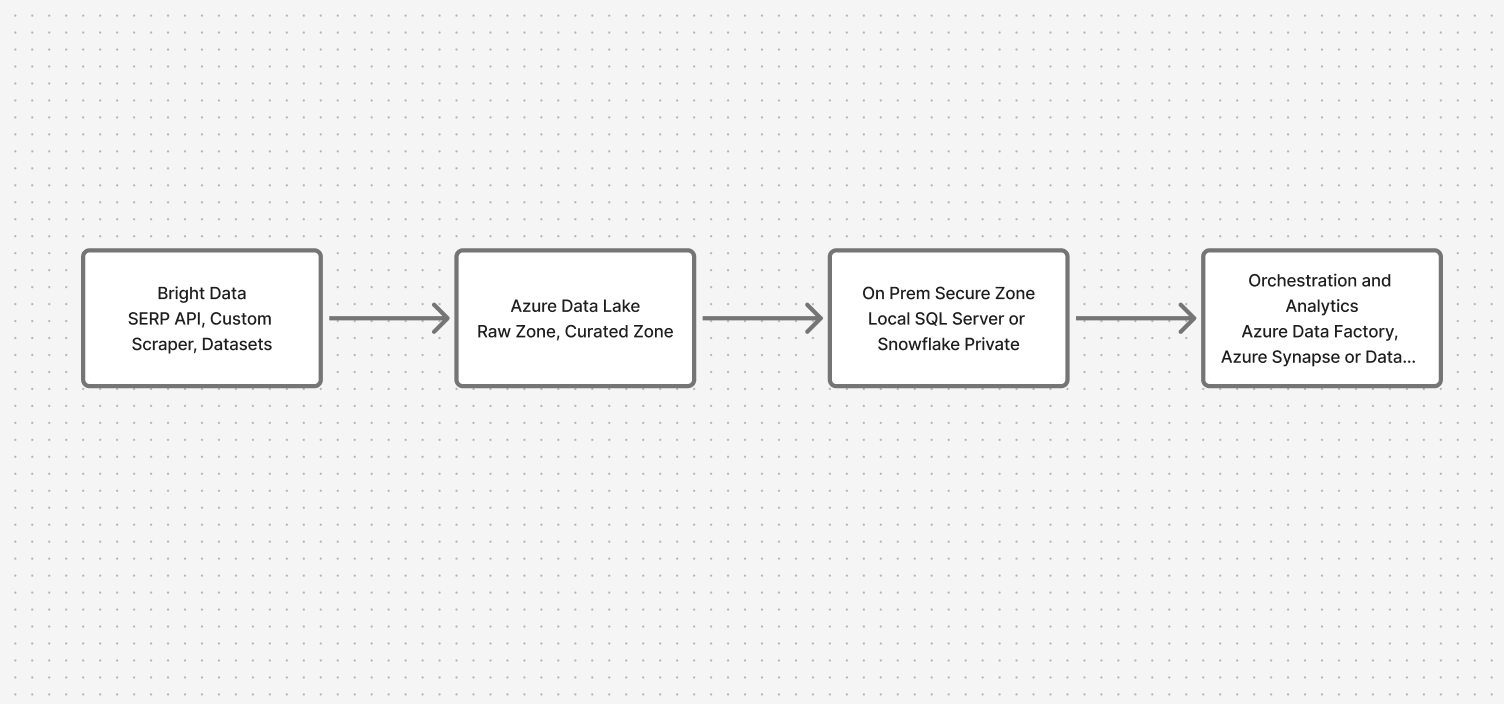
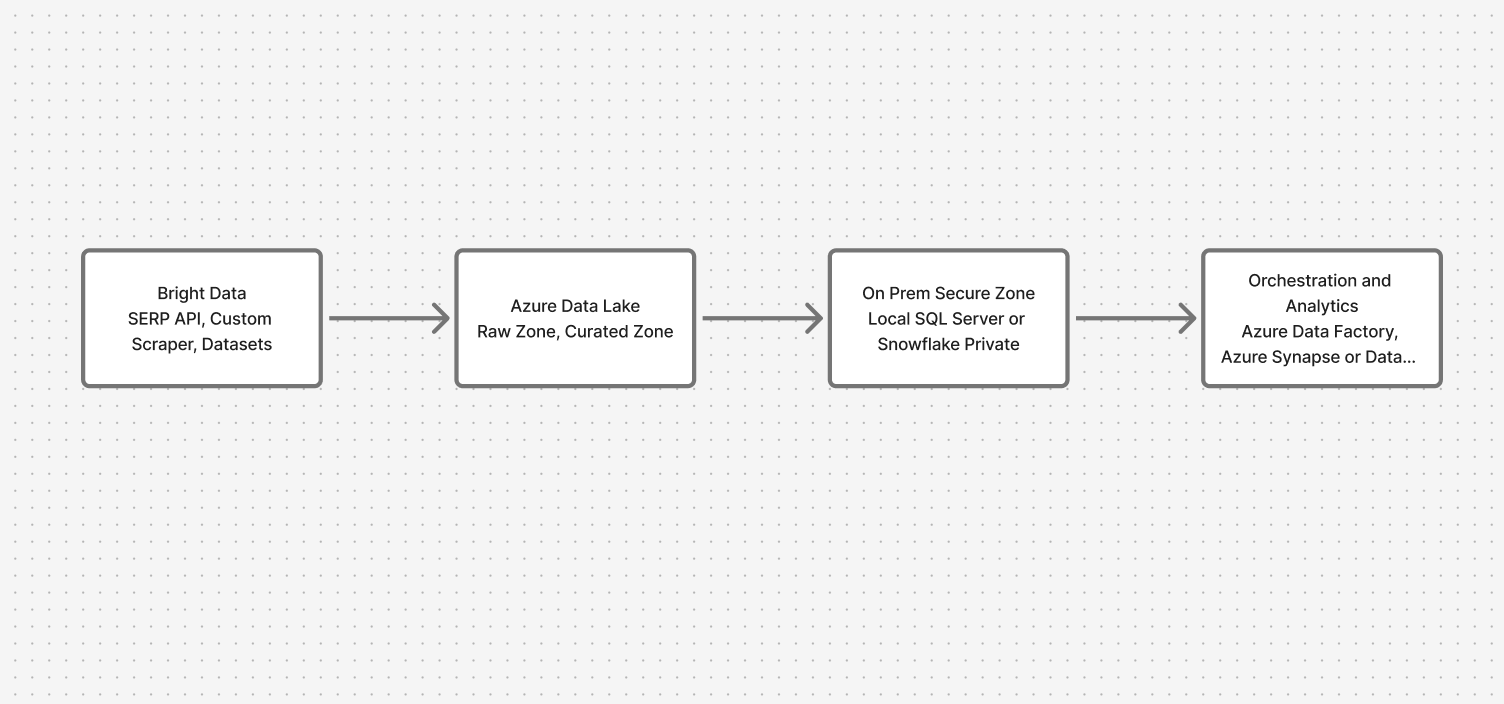
Architekturübersicht: Sichere Verbindung zwischen Cloud und lokalen Systemen
Das System durchläuft vier wichtige Ebenen:
- Datenerfassung: Bright Data-APIs (SERP-API, Custom Scraper, Datensätze)
- Cloud-Landing-Zone: Azure Data Lake (Rohdaten- und kuratierte Zonen)
- Sichere lokale Zone: Lokaler SQL Server oder Snowflake
- Orchestrierung und Analyse: Azure Data Factory mit privaten Endpunkten, Synapse/Databricks für föderierte Abfragen
Dadurch wird sichergestellt, dass Webdaten einfließen, während sensible Daten geschützt bleiben.
Voraussetzungen
Vor dem Start:
- Aktives Bright Data -Konto mit API-Zugriff
- Azure-Abonnement mit Data Lake, Data Factory und Synapse oder Databricks
- Lokale Datenbank, die über ein privates Netzwerk (ODBC oder JDBC) erreichbar ist
- Sichere private Verbindung (ExpressRoute, Site-to-Site-VPN oder privater Endpunkt)
- GitHub-Konto zum Klonen des Beispiel-Repositorys
💡 Tipp: Führen Sie alle Schritte zunächst in einem Nicht-Produktions-Arbeitsbereich aus.
Schrittweise Implementierung
1. Finanzdaten aus dem Internet mit Bright Data sammeln
Wir konfigurieren den benutzerdefinierten Scraper von Bright Data, um Aktienkurse, behördliche Meldungen und Finanznachrichten zu extrahieren. Der Scraper gibt strukturierte JSON-Daten aus, die für die Analyse bereit sind.
So sehen die Daten aus:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
Einfache Konfiguration: Die Datei scraper_config.yaml legt fest, was wie oft gescrapt werden soll. Sie zielt auf Finanzwebsites ab, extrahiert bestimmte Datenpunkte und plant stündliche Erfassungen mit Webhook-Benachrichtigungen.
Dieser Ansatz stellt sicher, dass Sie saubere, strukturierte Daten ohne manuellen Eingriff erhalten.
# scraper_config.yaml
name: financial_data_aggregator
description: >
Sammelt Echtzeit-Aktienkurse, SEC-Meldungen und Finanznachrichten-Schlagzeilen
für die Hybrid-Cloud-Integration.
targets:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
selectors:
- name: symbol
type: text
selector: "h1[data-testid='quote-header'] span"
- name: price
type: text
selector: "fin-streamer[data-field='regularMarketPrice']"
- name: headline
type: text
selector: "article h3 a"
- name: filing_type
type: text
selector: "td[class*='filetype']"
- name: filing_date
type: text
selector: "td[class*='filedate']"
- name: filing_url
type: link
selector: "td[class*='filedesc'] a"
pagination:
type: next-link
selector: "a[aria-label='Next']"
output:
format: json
file_name: financial_data.json
schedule:
frequency: hourly
timezone: UTC
webhook: "https://<your-webhook-endpoint>/brightdata/ingest"
notifications:
email_on_success: [email protected]
email_on_failure: [email protected]2. Daten sicher in Azure Data Lake einlesen
Nun leiten wir die gesammelten Daten mithilfe einer Azure-Funktion an Azure Data Lake weiter. Diese Funktion dient als sicheres Gateway:
- Empfängt JSON-Daten über HTTPS POST von Bright Data
- Authentifizierung mithilfe von Managed Identity (keine Geheimnisse zu verwalten)
- Organisiert Dateien nach Quelle und Zeitstempel, um die Nachverfolgung zu erleichtern
- Fügt Metadaten-Tags für die Compliance-Verfolgung hinzu
Das Ergebnis: Ihre Marktdaten landen in partitionierten Ordnern, wodurch sie einfach zu verwalten und abzufragen sind.
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# Umgebungsvariablen
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # z. B. „https://myaccount.blob.core.windows.net”
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# Blob-Client mit verwalteter Identität initialisieren
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Eingehende JSON-Daten von Bright Data analysieren
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# Zielpfad vorbereiten
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# JSON-Datei hochladen
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"Daten aus {source} gespeichert unter {blob_path}",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""Einfacher Helfer zur Identifizierung des Quellennamens."""
# Suche nach dem Feld „source” im ersten Element des Arrays
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. Nicht sensible Teilmengen mit lokalen Systemen synchronisieren
Nicht alle Daten müssen zwischen Umgebungen übertragen werden. Wir verwenden Azure Data Factory als intelligenten Filter, der sorgfältig nur die Teilmengen auswählt, die sicher mit Ihrem lokalen Warehouse synchronisiert werden können.
So funktioniert der Prozess in der Praxis:
Die Pipeline beginnt mit der Suche nach neuen Dateien, die in Ihrem Data Lake gelandet sind. Anschließend wendet sie eine intelligente Filterung an, um nur öffentliche, nicht sensible Daten einzubeziehen – denken Sie dabei an Marktpreise und Börsenkürzel, nicht an Kundeninformationen oder proprietäre Analysen.
Was macht dies sicher und zuverlässig?
Private Endpunkte erstellen einen dedizierten Tunnel zwischen Azure und Ihrer lokalen Infrastruktur, der das öffentliche Internet vollständig umgeht. Dadurch werden externe Bedrohungen ausgeschlossen und eine konsistente Leistung gewährleistet.
Durch inkrementelles Laden mit Wasserzeichen-Tracking werden nur neue oder geänderte Datensätze verschoben. In Kombination mit der automatischen Schema-Validierung werden so Duplikate vermieden und beide Umgebungen bleiben perfekt aufeinander abgestimmt.
Sehen wir uns nun an, wie sich dies in tatsächlichem Pipeline-Code niederschlägt:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"name": "Filter_PublicData",
"type": "Filter",
"dependsOn": [
{
"activity": "Get_Metadata",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
„preCopyScript“: „IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));“
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Log_Load_Status",
"type": "StoredProcedure",
"dependsOn": [
{
"activity": "Copy_To_OnPrem_SQL",
"dependencyConditions": ["Succeeded", "Failed"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
„linkedServiceName”: {
„referenceName”: „OnPrem_SQL_LinkedService”,
„type”: „LinkedServiceReference”
}
}
],
„annotations”: [„HybridIntegrationDemo”]
}
}Aufschlüsselung der wichtigsten Komponenten:
- Lookup_NewFiles fungiert als Prüffunktion Ihrer Pipeline und identifiziert zunächst, welche neuen Daten im Data Lake angekommen sind und verarbeitet werden müssen. Dadurch wird verhindert, dass das System alte Dateien unnötigerweise erneut verarbeitet.
- Get_Metadata untersucht diese Dateien dann genau und überprüft ihre Größe, Änderungsdaten und Struktur. Dieser Schritt stellt sicher, dass wir mit vollständigen, gültigen Dateien arbeiten, bevor wir fortfahren.
- Filter_PublicData ist der Ort, an dem die Sicherheitsmagie stattfindet. Mithilfe der zuvor eingebetteten Klassifizierungsmetadaten filtert es automatisch alle sensiblen Daten heraus und stellt sicher, dass nur öffentliche Marktinformationen die Pipeline durchlaufen.
- Copy_To_OnPrem_SQL übernimmt die eigentliche Übertragung, jedoch mit intelligenten Sicherheitsvorkehrungen. Das preCopyScript stellt sicher, dass die Zieltabelle mit dem richtigen Schema vorhanden ist, während die private Endpunktverbindung dafür sorgt, dass alles innerhalb Ihres sicheren Netzwerks bleibt.
- Log_Load_Status bietet wichtige Transparenz, da jeder Synchronisierungsvorgang in Ihrer lokalen Datenbank aufgezeichnet wird. Dadurch wird der von Compliance-Teams geforderte Prüfpfad erstellt, während das Betriebspersonal sofort Einblick in den Zustand der Pipeline erhält.
Der eigentliche Vorteil: Ihr lokales Team erhält den erforderlichen Marktkontext und Echtzeitinformationen, während Ihre sensiblen Kundendaten und proprietären Modelle sicher dort bleiben, wo sie hingehören. Das Beste aus beiden Welten: Agilität trifft auf Sicherheit.
4. Bidirektionale Synchronisierungsvalidierung aktivieren
Datenkonsistenz ist für zuverlässige Geschäftsentscheidungen unerlässlich. Sie müssen darauf vertrauen können, dass Ihre Cloud-Analysen und lokalen Berichte die gleichen Zahlen anzeigen. Wir haben automatisierte Datenvalidierungsprüfungen entwickelt, die kontinuierlich ausgeführt werden, um diese Sicherheit zu gewährleisten.
So funktioniert der Validierungsprozess:
- Der Vergleich der Zeilenanzahl dient als erstes Warnsystem. Diese erste Überprüfung identifiziert schnell größere Probleme wie fehlgeschlagene Übertragungen oder unvollständige Datenladungen. Wenn die Zahlen in der Cloud und vor Ort nicht übereinstimmen, wissen Sie sofort, dass etwas untersucht werden muss.
- Hash-Prüfsummen erstellen digitale Fingerabdrücke Ihrer Daten. Anstatt Tausende von Datensätzen manuell zu vergleichen, generieren wir für jeden Datensatz einzigartige kryptografische Hashes. Selbst eine einzige Zeichenänderung erzeugt einen völlig anderen Hash. Mit dieser Methode lassen sich Datenbeschädigungen oder unvollständige Übertragungen sofort erkennen.
- Durch die Synchronisierung in Echtzeit werden Validierungen alle paar Minuten durchgeführt. Sie müssen nicht auf Batch-Jobs über Nacht warten, um Probleme zu entdecken. Das System erkennt Probleme innerhalb von Minuten statt Tagen und hält Ihre Daten aktuell und zuverlässig.
- Automatische Warnmeldungen verwandeln Datenprobleme in sofortige Maßnahmen. Wenn das System Unstimmigkeiten feststellt, sendet es Benachrichtigungen über Slack, E-Mail oder Ihre vorhandenen Überwachungstools. Ihr Team kann Probleme beheben, bevor sie sich auf Geschäftsentscheidungen auswirken.
So sieht das in der Praxis aus:
def validate_sync():
# Vergleich der Datensatzanzahl zwischen den Systemen
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"Datensatzanzahl stimmt nicht überein: Cloud {cloud_count} vs. On-Prem {onprem_count}")
return False
# Prüfsummen für die Validierung der Datenintegrität generieren
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"Fehler bei der Datenintegrität: Prüfsummen stimmen nicht überein")
return False
# Überprüfen der Synchronisierungszeit
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"Synchronisierungsverzögerung erkannt: Letzte Synchronisierung {last_sync_time}")
return False
return True5. Erstellen Sie einheitliche Analysen, ohne sensible Daten zu verschieben
Das Besondere daran: Sie können Cloud- und lokale Daten virtuell zusammenführen, ohne sensible Informationen zu verschieben.
Beispielabfrage:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapse erstellt externe Tabellen, die auf Ihr lokales Warehouse verweisen, während Databricks JDBC-Verbindungen mit rollenbasierten Zugriffskontrollen verwendet.
Best Practices für Compliance und Prüfpfade
Die Erfüllung von Audit- und gesetzlichen Anforderungen erfordert einen systematischen Ansatz für die Datenverfolgung und -sicherheit. So erstellen wir ein konformes Framework:
- Durch die vollständige Protokollierung der Datenbewegungen wird sichergestellt, dass jede Übertragung in Azure Monitor und Ihrem lokalen SIEM aufgezeichnet wird. So entsteht eine unveränderliche Aufzeichnung darüber, welche Daten wann und wohin übertragen wurden, wodurch Auditoren eine vollständige Rückverfolgbarkeit erhalten.
- Die eindeutige Datenherkunft nutzt Bright Data-Quell-IDs als digitale Fingerabdrücke. Diese Tags bleiben während des gesamten Lebenszyklus Ihrer Daten erhalten, sodass Sie jede Analyse bis zu ihrer ursprünglichen Quelle zurückverfolgen können.
- Die automatisierte Herkunftsverfolgung mit Azure Purview bildet ab, wie sich Daten durch Ihre Pipelines transformieren. Es dokumentiert automatisch, welche Rohdaten zu bestimmten Berichten beitragen und welche Transformationen angewendet wurden.
- Die zentralisierte Zugriffskontrolle synchronisiert Azure AD mit lokalem LDAP. Dadurch werden Ihre bestehenden Sicherheitsrichtlinien auf beide Umgebungen angewendet, was eine konsistente Berechtigungsverwaltung über Cloud- und lokale Systeme hinweg gewährleistet.
Das Ergebnis sind automatisierte Compliance-Berichte, eine zentralisierte Sicherheitsverwaltung und ein Framework, das Daten schützt, ohne Ihr Team zu verlangsamen.
Häufige Herausforderungen und wie Bright Data hilft
| Herausforderung | Bright Data-Funktion |
|---|---|
| IP-Blöcke oder Ratenbeschränkungen | Residential- und ISP-Proxys (über 150 Millionen IPs) |
| CAPTCHAs oder Anmeldebarrieren | Web Unlocker für automatisierte Lösung |
| JavaScript-intensive Websites | Scraping-Browser (Playwright-basiertes Rendering) |
| Häufige Website-Änderungen | Verwaltete Datendienste mit automatischer Korrektur durch KI |
Fazit und nächste Schritte
Finanzorganisationen können öffentliche und private Daten sicher zusammenführen, indem sie die APIs von Bright Data zusammen mit der Hybrid-Infrastruktur von Azure nutzen.
Das Ergebnis ist ein konformes System, das sowohl Agilität als auch Kontrolle bietet.
💡 Wenn Sie einen vollständig verwalteten Datenzugriff bevorzugen, nutzen Sie die Managed Data Services von Bright Data, um das Scraping und die Bereitstellung durchgängig zu verwalten.






