
In diesem Tutorial behandeln wir:
- Wie man Naver-Suchergebnisse mit der SERP-API von Bright Data scrapt
- Erstellen eines benutzerdefinierten Naver-Scrapers mit Bright Data-Proxys
- Scraping von Naver mit Bright Data Scraper Studio (KI Scraper) mit einem No-Code-Workflow
Los geht’s!
Warum Naver scrapen?
Naver ist die führende Plattform in Südkorea und eine wichtige Quelle für Suchanfragen, Nachrichten, Shopping und nutzergenerierte Inhalte. Im Gegensatz zu globalen Suchmaschinen zeigt Naver proprietäre Dienste direkt in seinen Ergebnissen an, was es zu einer wichtigen Datenquelle für Unternehmen macht, die den koreanischen Markt ansprechen.
Das Scraping von Naver ermöglicht den Zugriff auf strukturierte und unstrukturierte Daten, die über öffentliche APIs nicht verfügbar sind und manuell nur schwer in großem Umfang erfasst werden können.
Welche Daten können gesammelt werden?
- Suchergebnisse (SERPs): Rankings, Titel, Snippets und URLs
- Nachrichten: Herausgeber, Schlagzeilen und Zeitstempel
- Shopping: Produktlisten, Preise, Verkäufer und Bewertungen
- Blogs und Cafés: nutzergenerierte Inhalte und Trends.
Wichtige Anwendungsfälle
- SEO und Keyword-Tracking für den koreanischen Markt
- Marken- und Reputationsüberwachung in Nachrichten und Nutzerinhalten
- E-Commerce und Preisanalyse mit Naver Shopping
- Marktforschung und Trendforschung anhand von Blogs und Foren
Vor diesem Hintergrund wollen wir uns nun mit dem ersten Ansatz befassen und sehen, wie man mit der SERP-API von Bright Data Naver-Suchergebnisse scrapen kann.
Scraping von Naver mit der SERP-API von Bright Data
Dieser Ansatz ist ideal, wenn Sie Naver-SERP-Daten ohne die Verwaltung von Proxys, CAPTCHAs oder Browsereinstellungen erhalten möchten.
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie:
- Ein Bright Data -Konto
- Zugriff auf die SERP-API, Proxys oder Scraper Studio im Bright Data-Dashboard
- Python 3.9 oder neuer
- Grundkenntnisse in Python und Web-Scraping-Konzepten
Für die Beispiele für benutzerdefinierte Scraper benötigen Sie außerdem:
- Playwright lokal installiert und eingerichtet
- Chromium über Playwright installiert
Erstellen Sie eine SERP-API-Zone in Bright Data
In Bright Data erfordert die SERP-API eine eigene Zone. So richten Sie diese ein:
- Melden Sie sich bei Bright Data an.
- Gehen Sie im Dashboard zu SERP-API und erstellen Sie eine neue SERP-API-Zone.
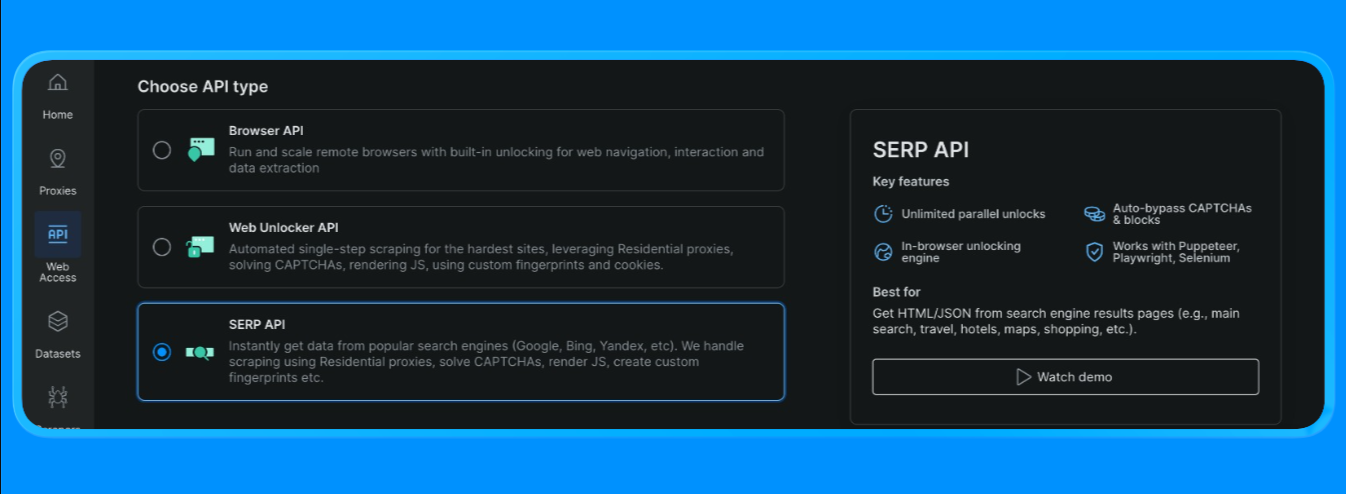
- Kopieren Sie Ihren API-Schlüssel.
Erstellen Sie die Naver-Such-URL
Naver-SERPs können über ein Standard-Such-URL-Format angefordert werden:
- Basis-Endpunkt:
https://search.naver.com/search.naver - Abfrageparameter:
query=<Ihr Schlüsselwort>
Die Abfrage wird mit quote_plus() URL-codiert, damit mehrteilige Schlüsselwörter (wie „machine learning tutorials”) korrekt formatiert werden.
Senden Sie die SERP-API-Anfrage (Bright Data-Anfrageendpunkt)
Der Schnellstart-Ablauf von Bright Data verwendet einen einzigen Endpunkt (https://api.brightdata.com/request), an den Sie Folgendes übergeben:
zone:den Namen Ihrer SERP-API-Zoneurl:die Naver-SERP-URL, die Bright Data abrufen sollformat:auf „raw” setzen, um den HTML-Code zurückzugeben
Bright Data unterstützt auch geparste Ausgabemodi (z. B. JSON-Struktur über brd_json=1 oder schnellere „Top-Ergebnisse“ über data_format- Optionen), aber für diesen Tutorial-Abschnitt verwenden wir Ihren HTML-Parsing- Ablauf
Sie können nun eine Python-Datei erstellen und die folgenden Codes einfügen
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "your_brightdata_username"
BRIGHTDATA_PASSWORD = "your_brightdata password"
PROXY_SERVER = "your_proxy_host"
def clean_text(text: str) -> str:
return re.sub(r"s+", " ", (text or "")).strip()
def blocked_link(href: str) -> bool:
"""Blockiere Werbe-/Dienstprogramme-Links; erlaube blog.naver.com, da wir Blog-Ergebnisse wollen."""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# blockiere Werbe-Weiterleitungen + offensichtliche Nicht-Inhalts-Dienstprogramme
blocked_domains = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# Im Blog-Modus haben Sie zwei Möglichkeiten:
# (A) Nur Naver-Blog-/Post-Domains zulassen (eher „Naver-typisch”)
allowed = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
return not any(netloc == d or netloc.endswith("." + d) for d in allowed)
def pick_snippet(container) -> str:
"""
Heuristik: Wähle einen satzähnlichen Textblock in der Nähe des Titels aus.
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# breadcrumb-ähnliche Zeilen vermeiden
if "›" in txt:
continue
best = txt
break
return best
def extract_blog_results(html: str, limit: int = 10):
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
# Blog-SERP-Layouts ändern sich; mehrere Fallbacks verwenden
selectors = [
"a.api_txt_lines", # allgemeiner Titel-Link-Wrapper
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
for sel in selectors:
for a in soup.select(sel):
if a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 5:
continue
if blocked_link(href):
continue
if href in seen:
continue
seen.add(href)
container = a.find_parent(["li", "article", "div", "section"]) or a.parent
snippet = pick_snippet(container) if container else ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# Naver-Blog-Vertikal
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# Proxy-freundliche Timeouts
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# Blockieren Sie ressourcenintensive Elemente, um die Geschwindigkeit zu erhöhen und Abstürze zu reduzieren.
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# Einmal wiederholen (Navers kann etwas unzuverlässig sein)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "machine learning tutorial"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Scraped from:", scraped_url)
print("HTML length:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("nExtrahierte Naver-Blog-Ergebnisse:")
for i, r in enumerate(results, 1):
print(f"n{i}. {r['title']}n {r['link']}n {r['snippet']}")Mit der Funktion fetch_naver_html() haben wir eine Naver-Such-URL an den Request-Endpunkt von Bright Data gesendet und die vollständig gerenderte SERP-Seite abgerufen. Bright Data hat die IP-Rotation und den Zugriff automatisch übernommen, sodass die Anfrage ohne Blockierungen oder Ratenbeschränkungen erfolgreich durchgeführt werden konnte.
Anschließend haben wir den HTML-Code mit BeautifulSoup geparst und eine benutzerdefinierte Filterlogik angewendet, um Anzeigen und interne Naver-Module zu entfernen. Die Funktion extract_web_results() hat die Seite nach gültigen Ergebnistiteln, Links und nahegelegenen Textblöcken durchsucht, diese dedupliziert und eine saubere Liste mit Suchergebnissen zurückgegeben.
Wenn Sie das Skript ausführen, erhalten Sie eine Ausgabe, die wie folgt aussieht: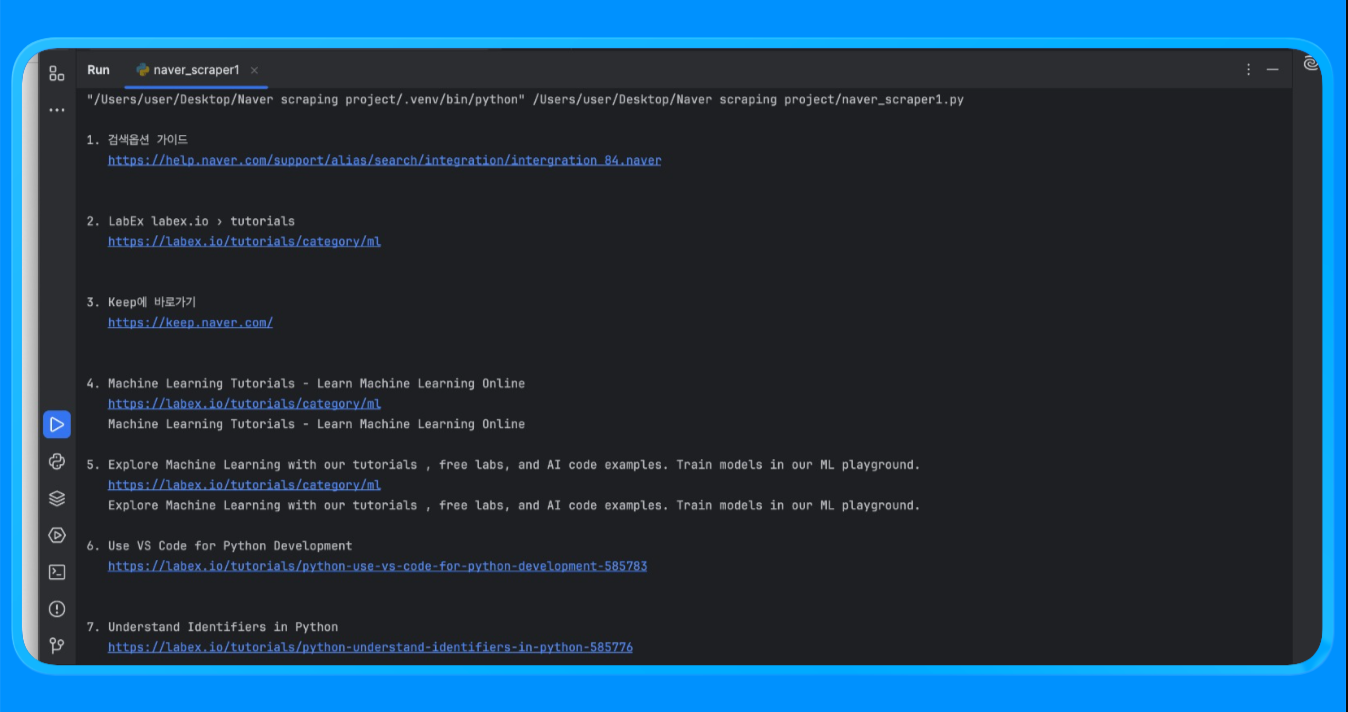
Diese Methode wird verwendet, um strukturierte Naver-Suchergebnisse zu sammeln, ohne einen benutzerdefinierten Scraper erstellen oder warten zu müssen.
Häufige Anwendungsfälle
- Keyword-Ranking und Sichtbarkeitsverfolgung auf Naver
- Überwachung der SEO-Leistung für koreanische Märkte
- Analyse von SERP-Funktionen wie Nachrichten, Shopping und Blog-Platzierungen
Dieser Ansatz eignet sich am besten, wenn Sie konsistente Ausgabeschemata und hohe Anfragenvolumina mit minimalem Einrichtungsaufwand benötigen.
Nachdem wir uns mit dem Scraping auf SERP-Ebene befasst haben, wollen wir nun einen benutzerdefinierten Naver-Scraper mit Bright Data-Proxys erstellen, um ein tieferes Crawling und mehr Flexibilität zu erreichen.
Erstellen eines benutzerdefinierten Naver-Scrapers mit Bright Data-Proxys
Bei diesem Ansatz werden Naver-Seiten mit einem echten Browser gerendert, während der Traffic über Bright Data-Proxys geleitet wird. Dies ist nützlich, wenn Sie die vollständige Kontrolle über Anfragen, JavaScript-Rendering und die Extraktion von Daten auf Seitenebene über SERPs hinaus benötigen.
Bevor Sie Code schreiben, müssen Sie zunächst eine Proxy-Zone erstellen und Ihre Proxy-Anmeldedaten über das Bright Data-Dashboard abrufen.
So erhalten Sie die in diesem Skript verwendeten Proxy-Anmeldedaten:
- Melden Sie sich bei Ihrem Bright Data -Konto an
- Gehen Sie im Dashboard zu „Proxies“ und klicken Sie auf „Proxy erstellen“
- Wählen Sie „Datacenter-Proxy“ (wir wählen diese Option für dieses Projekt, die Option variiert je nach Umfang und Anwendungsfall des Projekts)
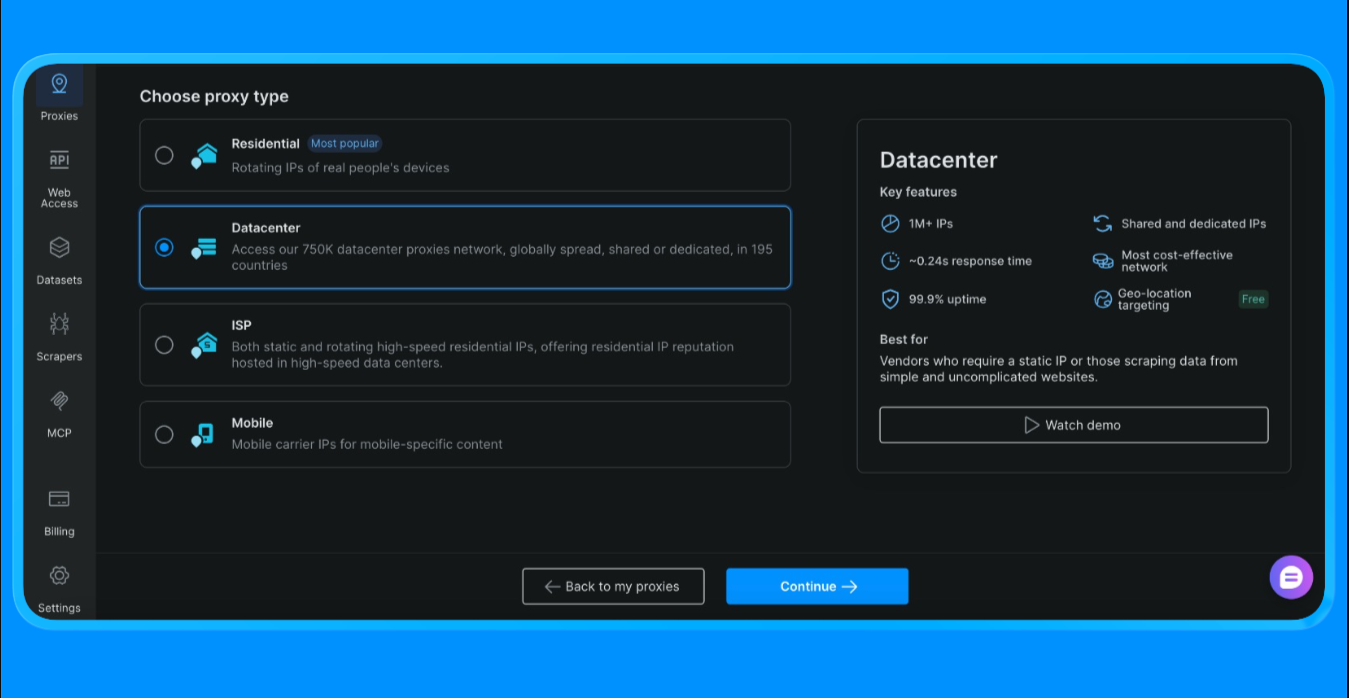
- Erstellen Sie eine neue Proxy-Zone
- Öffnen Sie die Zone-Einstellungen und kopieren Sie die folgenden Werte:
- Proxy-Benutzername
- Proxy-Passwort
- Proxy-Endpunkt und Port
Diese Werte sind erforderlich, um Anfragen zu authentifizieren, die über das Proxy-Netzwerk von Bright Data weitergeleitet werden.
Fügen Sie Ihre Bright Data-Proxy-Anmeldedaten zum Skript hinzu
Nachdem Sie die Proxy-Zone erstellt haben, aktualisieren Sie das Skript mit den Anmeldedaten, die Sie aus dem Dashboard kopiert haben.
BRIGHTDATA_USERNAMEenthält Ihre Kunden-ID und den Namen der Proxy-ZoneBRIGHTDATA_PASSWORDenthält das Passwort für die Proxy-ZonePROXY_SERVERverweist auf den Super-Proxy-Endpunkt von Bright Data
Sobald diese Werte festgelegt sind, wird der gesamte von Playwright initiierte Browser-Traffic automatisch über Bright Data geleitet.
Jetzt können wir mit den folgenden Codes mit dem Scraping fortfahren:
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "your_username"
BRIGHTDATA_PASSWORD = "your_password"
PROXY_SERVER = "your_proxy_host"
def clean_text(s: str) -> str:
return re.sub(r"s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
Proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
for a in soup.select("a[href]"):
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continue
if href in seen:
continue
seen.add(href)
results.append({"title": title, "link": href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}n {r['link']}n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))Die Funktion scrape_naver_blog() öffnet den Naver-Blog, blockiert umfangreiche Elemente wie Bilder, Medien und Schriftarten, um die Ladezeit zu verkürzen, und wiederholt die Navigation, wenn eine Zeitüberschreitung auftritt. Sobald die Seite vollständig geladen ist, ruft sie den gerenderten HTML-Code ab.
Die Funktion extract_blog_results() führt dann das Parsing des HTML-Codes mit BeautifulSoup durch, wendet blogspezifische Filterregeln an, um Anzeigen und Utility-Seiten auszuschließen, während Naver-Blog-Domains zugelassen werden, und extrahiert eine saubere Liste mit Blog-Titeln, Links und Text-Snippets aus der Umgebung.
Wenn Sie dieses Skript ausführen, erhalten Sie die folgende Ausgabe:
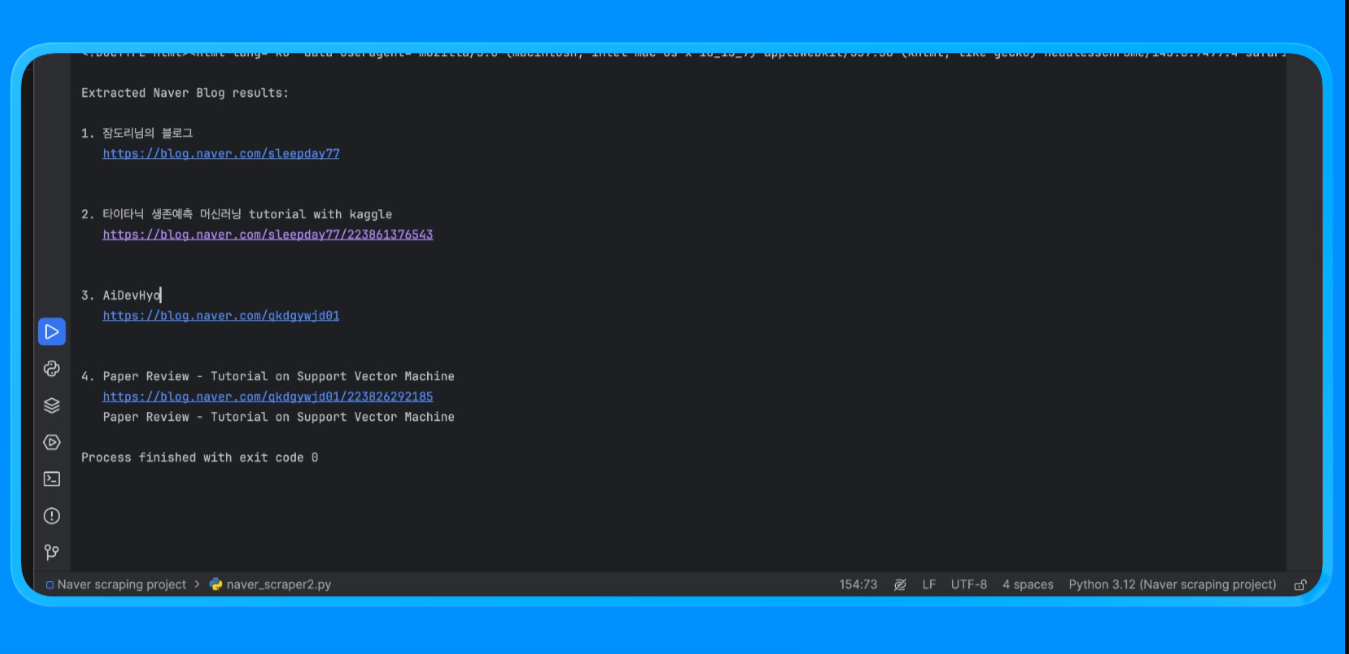
Diese Methode wird verwendet, um Inhalte aus Naver-Seiten zu extrahieren, die eine Browser-Rendering und eine benutzerdefinierte Parsing-Logik erfordern.
Häufige Anwendungsfälle
- Scraping von Naver-Blog- und Cafe-Inhalten
- Sammeln von Langformartikeln, Kommentaren und Benutzerinhalten
- Extrahieren von Daten aus JavaScript-lastigen Seiten
Dieser Ansatz ist ideal, wenn Seiten-Rendering, Wiederholungsversuche und fein abgestimmte Filterung erforderlich sind.
Nachdem wir nun einen benutzerdefinierten Scraper haben, der über Bright Data-Proxys läuft, wenden wir uns der schnellsten Option zum Extrahieren von Daten ohne Programmierung zu. Im nächsten Abschnitt werden wir Naver mit Bright Data Scraper Studio scrapen, dem no-code KI-basierten Workflow, der auf derselben Infrastruktur aufbaut.
Scraping von Naver mit Bright Data Scraper Studio (No-Code-KI-Scraper)
Wenn Sie keinen Scraping-Code schreiben oder pflegen möchten, bietet Bright Data Scraper Studio eine No-Code-Möglichkeit, Naver-Daten zu extrahieren, wobei dieselbe zugrunde liegende Infrastruktur wie die SERP-API und das Proxy-Netzwerk verwendet wird.
So fangen Sie an:
- Melden Sie sich bei Ihrem Bright Data -Konto an
- Öffnen Sie im Dashboard die Option „Scrapers” im Menü auf der linken Seite und klicken Sie auf „Scraper Studio”. Sie sehen dann ein Dashboard, das wie folgt aussieht:
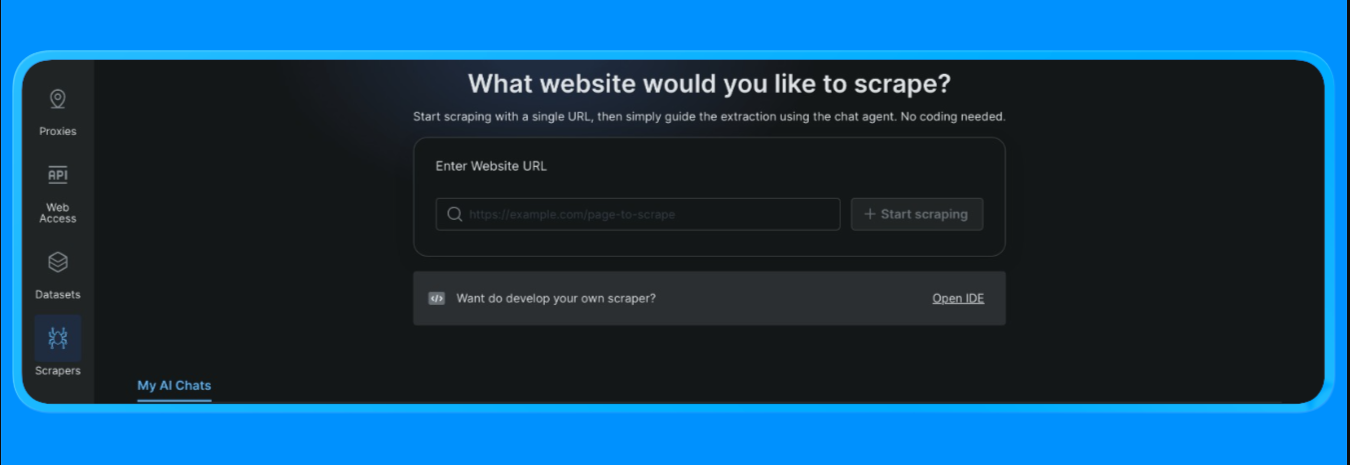
Geben Sie die Ziel-URL ein, die Sie scrapen möchten, und klicken Sie dann auf die Schaltfläche „Start Scraping”
Scraper Studio scrapt dann die Website und liefert Ihnen die benötigten Informationen.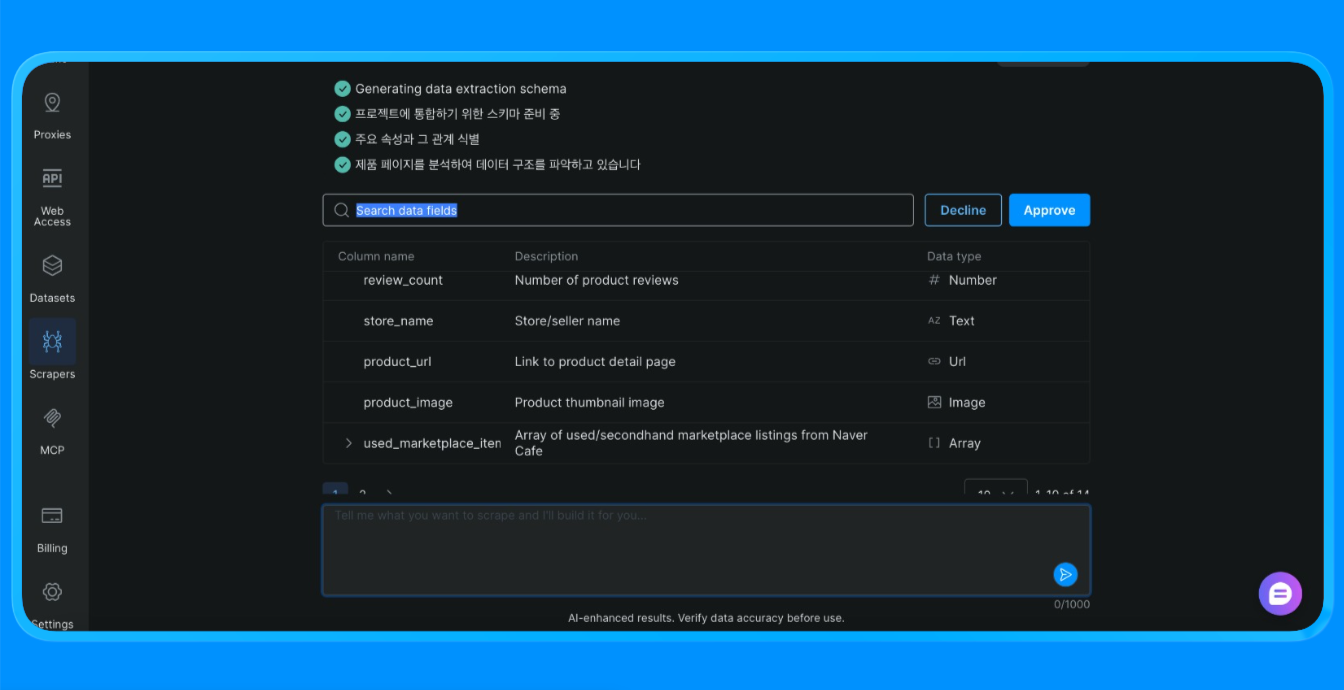
Scraper Studio hat die Naver-Seite über die Infrastruktur von Bright Data geladen, visuelle Extraktionsregeln angewendet und strukturierte Daten zurückgegeben, für die sonst ein benutzerdefinierter Scraper oder eine Browser-Automatisierung erforderlich gewesen wäre.
Häufige Anwendungsfälle
- Einmalige Datenerfassung
- Proof-of-Concept-Projekte
- Nicht-technische Teams, die Webdaten sammeln
Scraper Studio ist eine gute Wahl, wenn Geschwindigkeit und Einfachheit wichtiger sind als Anpassungsmöglichkeiten.
Vergleich der drei Naver-Scraping-Ansätze
| Ansatz | Aufwandsaufwand | Kontrollniveau | Skalierbarkeit | Am besten geeignet für |
|---|---|---|---|---|
| Bright Data SERP-API | Gering | Mittel | Hoch | SEO-Tracking, Keyword-Überwachung, strukturierte SERP-Daten |
| Benutzerdefinierter Scraper mit Bright Data-Proxys | Hoch | Sehr hoch | Sehr hoch | Blog-Scraping, dynamische Seiten, benutzerdefinierte Workflows |
| Bright Data Scraper Studio | Sehr niedrig | Niedrig bis mittel | Mittel | Schnelle Extraktion, Teams ohne Programmierkenntnisse, Prototyping |
So treffen Sie die richtige Wahl:
- Verwenden Sie die SERP-API, wenn Sie zuverlässige, strukturierte Suchergebnisse in großem Umfang benötigen.
- Verwenden Sie Proxys mit einem benutzerdefinierten Scraper, wenn Sie die volle Kontrolle über Rendering, Wiederholungsversuche und Extraktionslogik benötigen.
- Verwenden Sie Scraper Studio, wenn Geschwindigkeit und Einfachheit wichtiger sind als Anpassungsmöglichkeiten.
Zusammenfassung
In diesem Tutorial haben wir drei produktionsreife Methoden zum Scrapen von Naver mit Bright Data behandelt:
- Eine verwaltete SERP-API für strukturierte Suchdaten
- Einen benutzerdefinierten Scraper mit Proxys für vollständige Flexibilität und Kontrolle
- Einen No-Code-Scraper Studio-Workflow für schnelle Datenextraktion
Jede Option basiert auf derselben Bright Data-Infrastruktur. Die richtige Wahl hängt davon ab, wie viel Kontrolle Sie benötigen, wie oft Sie scrapen möchten und ob Sie Code schreiben möchten.
Sie können Bright Data erkunden, um Zugriff auf die SERP-API, die Proxy-Infrastruktur und das no-code Scraper Studio zu erhalten, und den Ansatz wählen, der zu Ihrem Workflow passt.
Weitere Anleitungen und Tutorials zum Thema Web-Scraping:
- Web-Scraping mit Python: der vollständige Leitfaden
- So scrapen Sie dynamische Websites mit Python
- Die besten SERP-APIs für das Web-Scraping
- Web-Scraping mit Playwright
- Die besten Proxy-Anbieter für Web-Scraping
- Die besten Anbieter von Residential-Proxys
- Python-Web-Scraping-Bibliotheken
- Beste Web-Scraping-Dienste






