

In diesem Tutorial lernen wir, wie man Stellenanzeigen von JOBKOREA, einem modernen Jobportal, scrapt.
Wir behandeln folgende Themen:
- Manuelles Python-Scraping durch Extrahieren eingebetteter Next.js-Daten
- Scraping mit Bright Data Web MCP für eine stabilere und skalierbarere Lösung
- No-Code-Scraping mit Bright Data’s KI Scraper Studio
Jede Technik wird mithilfe des in diesem Repository bereitgestellten Projektcodes implementiert, wobei wir vom Low-Level-Scraping bis hin zur vollständig agentenbasierten, KI-gestützten Extraktion voranschreiten.
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.9+
- Grundkenntnisse in Python und JSON
- Ein Bright Data-Konto mit Zugriff auf MCP
- Claude Desktop installiert (wird als KI-Agent für den No-Code-Ansatz verwendet)
Projekt einrichten
Klonen Sie das Projekt-Repository und installieren Sie die Abhängigkeiten:
python -m venv venv
source venv/bin/activate # macOS / Linux
venvScriptsactivate # Windows
pip install -r requirements.txtProjektstruktur
Das Repository ist so organisiert, dass jede Scraping-Technik leicht nachvollziehbar ist:
jobkorea_scraper/
│
├── manual_scraper.py # Manuelles Python-Scraping
├── mcp_scraper.py # Bright Data Web MCP-Scraping
├── parsers/
│ └── jobkorea.py # Gemeinsame Parsing-Logik
├── schemas.py # Jobdaten-Schema
├── requirements.txt
├── README.mdJedes Skript kann unabhängig ausgeführt werden, je nachdem, welche Methode Sie ausprobieren möchten.
Technik 1: Manuelles Python-Scraping
Wir beginnen mit dem grundlegendsten Ansatz: Scraping von JOBKOREA mit einfachem Python, ohne Browser, MCP oder KI-Agent.
Diese Technik ist nützlich, um zu verstehen, wie JOBKOREA seine Daten bereitstellt, und um schnell einen Scraper zu prototypisieren, bevor wir zu robusteren Lösungen übergehen.
Die Seite abrufen
Öffnen Sie manual_scraper.py.
Der Scraper beginnt mit dem Senden einer Standard-HTTP-Anfrage unter Verwendung von Requests. Um eine sofortige Blockierung zu vermeiden, fügen wir browserähnliche Header hinzu.
headers = {
"User-Agent": "Mozilla/5.0 (...)",
"Accept": "text/html,application/xhtml+xml,*/*",
"Accept-Language": "en-US,en;q=0.9,ko;q=0.8",
"Referer": "https://www.jobkorea.co.kr/"
}Das Ziel besteht einfach darin, die Anfrage wie normalen Web-Traffic aussehen zu lassen. Anschließend rufen wir die Seite ab und erzwingen die UTF-8- Kodierung, um Probleme mit koreanischem Text zu vermeiden:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
response.encoding = "utf-8"
html = response.textZur Fehlerbehebung wird der rohe HTML-Code lokal gespeichert:
with open("debug.html", "w", encoding="utf-8") as f:
f.write(html)Diese Datei ist äußerst hilfreich, wenn sich die Website ändert und das Parsen plötzlich nicht mehr funktioniert.
Parsing der Antwort
Sobald der HTML-Code heruntergeladen ist, wird er an eine gemeinsame Parsing-Funktion übergeben:
jobs = parse_job_list(html)Diese Funktion befindet sich in parsers/jobkorea.py und enthält die gesamte JOBKOREA-spezifische Logik.
Versuch eines traditionellen HTML-Parsing
In parse_job_list versuchen wir zunächst, Stellenanzeigen mit BeautifulSoup zu extrahieren, als wäre JOBKOREA eine herkömmliche, vom Server gerenderte Website.
soup = BeautifulSoup(html, "html.parser")
job_lists = soup.find_all("div", class_="list-default")Wenn keine Stellenanzeigen gefunden werden, wird ein sekundärer Selektor ausprobiert:
job_lists = soup.find_all("ul", class_="clear")Wenn dies funktioniert, extrahiert der Scraper Felder wie:
- Berufsbezeichnung
- Firmenname
- Standort
- Datum der Veröffentlichung
- Link zur Stellenanzeige
Dieser Ansatz funktioniert jedoch nur, wenn JOBKOREA aussagekräftige HTML-Elemente bereitstellt, was nicht immer der Fall ist.
Fallback: Extrahieren von Next.js-Hydrationsdaten
Wenn durch HTML-Parsing keine Stellen gefunden werden, wechselt der Scraper zu einer Fallback-Strategie, die auf eingebettete Next.js-Hydration-Daten abzielt.
nextjs_jobs = parse_nextjs_data(html)Diese Funktion durchsucht die Seite nach JSON-Strings, die während der clientseitigen Rendering-Phase eingefügt wurden. Eine vereinfachte Version der Abgleichlogik sieht wie folgt aus:
pattern = r'\"id\":\"(?P<id>d+)\",\"title\":\"(?P<title>.*?)\",\"postingCompanyName\":\"(?P<company>.*?)\"'Aus diesen Daten rekonstruieren wir die URLs der Stellenanzeigen:
link = f"https://www.jobkorea.co.kr/Recruit/GI_Read/{job_id}"Dieser Fallback ermöglicht es dem Scraper, ohne Browser zu arbeiten.
Speichern der Ergebnisse
Jede Stellenanzeige wird anhand eines gemeinsamen Schemas validiert und auf die Festplatte geschrieben:
with open("jobs.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)Führen Sie den Scraper wie folgt aus:
python manual_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"Sie sollten nun eine Datei „jobs.json” mit den extrahierten Einträgen haben.
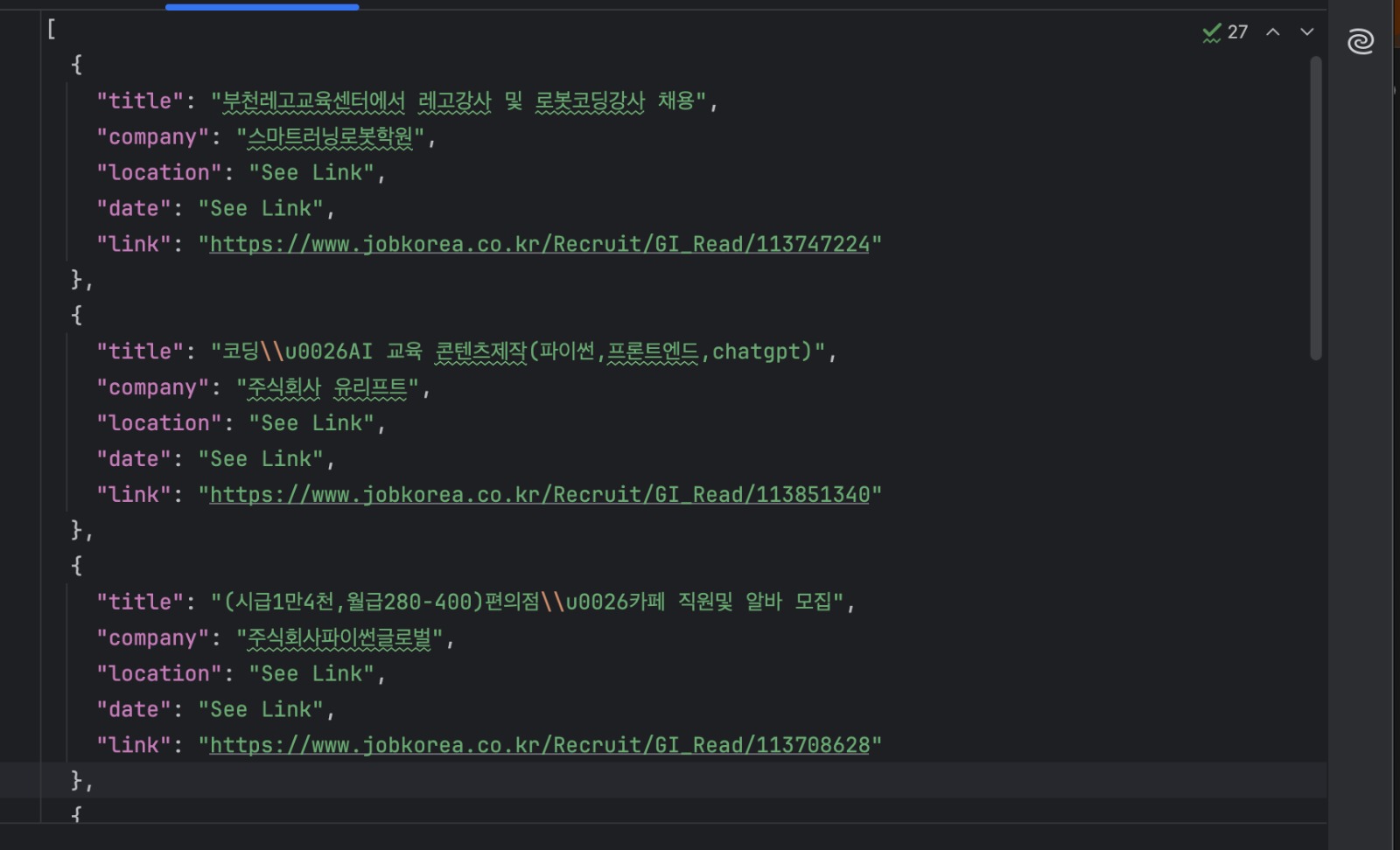
Wann dieser Ansatz ideal ist
Manuelles Scraping ist nützlich, wenn Sie die Funktionsweise einer Website erkunden oder einen schnellen Prototyp erstellen möchten. Es ist schnell, einfach und unabhängig von externen Diensten.
Dieser Ansatz ist jedoch eng mit der aktuellen Seitenstruktur von JOBKOREA verbunden. Da er von bestimmten HTML-Layouts und eingebetteten Hydrationsmustern abhängt, kann er bei Änderungen an der Website fehlschlagen.
Für ein stabileres, langfristiges Scraping ist es besser, sich auf Tools zu verlassen, die das Rendering und Website-Änderungen für Sie übernehmen. Genau das werden wir als Nächstes mit Bright Data Web MCP tun.
Technik 2: Scraping mit Bright Data Web MCP
Im vorherigen Abschnitt haben wir JOBKOREA gescrapt, indem wir HTML manuell heruntergeladen und eingebettete Daten extrahiert haben. Dieser Ansatz funktioniert zwar, ist jedoch eng mit der aktuellen Struktur der Website verbunden.
Bei dieser Technik verwenden wir Bright Data Web MCP, um das Abrufen und Rendern von Seiten zu übernehmen. Wir konzentrieren uns dann nur darauf, die zurückgegebenen Inhalte in strukturierte Jobdaten umzuwandeln.
Dieser Ansatz wird in mcp_scraper.py implementiert.
So erhalten Sie Ihren Bright Data API-Schlüssel/Token
- Melden Sie sich beim Bright Data-Dashboard an
- Öffnen Sie die Einstellungen in der linken Seitenleiste
- Gehen Sie zu „Benutzer und API-Schlüssel“
- Kopieren Sie Ihren API-Schlüssel
Später in diesem Tutorial zeigen Screenshots genau, wo sich diese Seite befindet und wo das Token angezeigt wird.
Erstellen Sie eine .env -Datei im Projektstammverzeichnis und fügen Sie Folgendes hinzu:
BRIGHT_DATA_API_TOKEN=Ihr_Token_hierDas Skript lädt das Token zur Laufzeit und bricht vorzeitig ab, wenn es fehlt.
Anforderungen für MCP
Bright Data Web MCP wird lokal mit npx gestartet. Stellen Sie daher sicher, dass Sie über Folgendes verfügen:
- Node.js installiert
- npx in Ihrem PATH verfügbar
Der MCP-Server wird von Python aus gestartet mit:
server_params = StdioServerParameters( command="npx", args=["-y", "@brightdata/mcp"], env={"API_TOKEN": BRIGHT_DATA_API_TOKEN, **os.environ} )Ausführen des MCP-Scrapers
Führen Sie das Skript mit einer JOBKOREA-Such-URL aus:
python mcp_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"Das Skript öffnet eine MCP-Sitzung und initialisiert die Verbindung:
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()Sobald die Verbindung hergestellt ist, ist der Scraper bereit, Inhalte abzurufen.
Abrufen der Seite mit MCP
In diesem Projekt verwendet der Scraper das MCP-Tool scrape_as_markdown:
result = await session.call_tool(
"scrape_as_markdown",
arguments={"url": url}
)Der zurückgegebene Inhalt wird gesammelt und lokal gespeichert:
with open("scraped_data.md", "w", encoding="utf-8") as f:
f.write(content_text)Dadurch erhalten Sie einen lesbaren Snapshot der von MCP zurückgegebenen Daten, was für die Fehlerbehebung und das Parsing nützlich ist.
Parsing von Jobs aus Markdown
Die von MCP zurückgegebenen Markdown-Daten werden anschließend in strukturierte Jobdaten umgewandelt.
Die Parsing-Logik sucht nach Markdown-Links:
link_pattern = re.compile(r"[(.*?)]((.*?))")Stellenanzeigen werden anhand von URLs identifiziert, die Folgendes enthalten:
if "Recruit/GI_Read" in url:Sobald ein Job-Link gefunden wurde, werden die umgebenden Zeilen verwendet, um den Firmennamen, den Standort und das Veröffentlichungsdatum zu extrahieren.
Schließlich werden die Ergebnisse auf die Festplatte geschrieben:
with open("jobs_mcp.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)Ausgabedateien
Nach Abschluss des Skripts sollten Sie Folgendes haben:
scraped_data.md
Die von Bright Data Web MCP zurückgegebene Roh-Markdown-Datei
jobs_mcp.json
Die geparsten Stellenanzeigen im strukturierten JSON-Format
Wann dieser Ansatz ideal ist
Die direkte Verwendung von Bright Data Web MCP aus Python heraus ist ideal, wenn Sie einen Scraper suchen, der sowohl zuverlässig als auch wiederholbar ist.
Da MCP das Rendering, die Vernetzung und grundlegende Website-Sicherheitsmaßnahmen übernimmt, ist dieser Ansatz weitaus weniger empfindlich gegenüber Layoutänderungen als manuelles Scraping. Gleichzeitig erleichtert die Beibehaltung der Logik in Python die Automatisierung, Planung und Integration in größere Datenpipelines.
Diese Technik eignet sich gut, wenn Sie über einen längeren Zeitraum hinweg konsistente Ergebnisse benötigen oder wenn Sie mehrere Suchseiten oder Schlüsselwörter scrapen. Sie bietet auch einen klaren Upgrade-Pfad vom manuellen Scraping, ohne dass eine vollständige Umstellung auf einen KI-gesteuerten Workflow erforderlich ist.
Als Nächstes gehen wir zur dritten Technik über, bei der wir Claude Desktop als KI-Agenten verwenden, der mit Bright Data Web MCP verbunden ist, um JOBKOREA zu scrapen, ohne einen Scraping-Code schreiben zu müssen.
Technik 3: KI-generierter Scraping-Code mit Bright Data IDE
Bei dieser letzten Technik generieren wir Scraping-Code mit dem KI-gestützten Scraper von Bright Data innerhalb der Web-Scraping IDE.
Sie müssen die Scraping-Logik nicht manuell von Grund auf neu schreiben. Vielmehr beschreiben Sie, was Sie wollen, und die IDE hilft Ihnen bei der Generierung und Verfeinerung des Scrapers.
Öffnen der Scraper-IDE
Über das Bright Data-Dashboard:
Öffnen Sie „Data“ in der linken Seitenleiste
- Klicken Sie auf „Meine Scraper“

- Wählen Sie „Neu“ in der oberen rechten Ecke
- Wählen Sie „Entwickeln Sie Ihren eigenen Web-Scraper“

Dadurch wird die integrierte JavaScript-Entwicklungsumgebung (IDE) geöffnet
Geben Sie Ihre Ziel-URL „https://www.jobkorea.co.kr/Search/“ ein und klicken Sie auf „Code generieren“
Die IDE verarbeitet Ihre Anfrage und generiert eine gebrauchsfertige Code-Vorlage. Sie erhalten eine E-Mail-Benachrichtigung, sobald diese fertig ist. Sie können den Code dann nach Bedarf bearbeiten oder ausführen.
Vergleich der drei Scraping-Techniken
Jede Technik in diesem Projekt löst das gleiche Problem, eignet sich jedoch für einen anderen Arbeitsablauf. Die folgende Tabelle zeigt die praktischen Unterschiede auf.
| Technik | Aufwand für die Einrichtung | Zuverlässigkeit | Automatisierung | Wo sie läuft | Bester Anwendungsfall |
|---|---|---|---|---|---|
| Manuelles Python-Scraping | Gering | Niedrig bis mittel | Begrenzt | Lokaler Rechner | Lernen, schnelle Experimente |
| Bright Data MCP (Python) | Mittel | Hoch | Hoch | Lokal + Bright Data | Produktions-Scraping, geplante Aufgaben |
| KI-generierter Scraper (Bright Data IDE) | Niedrig | Hoch | Hoch | Bright Data-Plattform | Schnelle Einrichtung, wiederverwendbare verwaltete Scraper |
Zusammenfassung
In diesem Tutorial haben wir drei verschiedene Methoden zum Scrapen von JOBKOREA behandelt: manuelles Python-Scraping, einen stabileren Bright Data Web MCP-basierten Workflow und die Verwendung von Bright Datas AI Scraper Studio für einen No-Code-Ansatz.
Jede Technik baut auf der vorherigen auf. Manuelles Scraping hilft dabei, die Funktionsweise der Website zu verstehen, MCP-basiertes Scraping bietet Zuverlässigkeit und Automatisierung, und der KI-Agent-Ansatz bietet den schnellsten Weg zu strukturierten Daten mit minimalem Einrichtungsaufwand.
Wenn Sie moderne, clientseitig gerenderte Websites wie JOBKOREA scrapen und eine zuverlässigere Alternative zu instabilen Selektoren und Browser-Automatisierung benötigen, bietet Bright Data Web MCP eine starke Grundlage, die sowohl mit traditionellen Skripten als auch mit KI-gesteuerten Workflows funktioniert.






