In diesem Leitfaden erfahren Sie:
- Alles, was Sie wissen müssen, um Ihre ersten Schritte mit DuckDuckGo-Scraping zu machen.
- Die beliebtesten und effektivsten Ansätze für das Web-Scraping von DuckDuckGo.
- Wie Sie einen benutzerdefinierten DuckDuckGo-Scraper erstellen.
- Wie Sie die DDGS-Bibliothek für das Scraping von DuckDuckGo verwenden.
- Wie Sie Suchmaschinenergebnisse über die Bright Data SERP-API abrufen.
- Wie Sie einem KI-Agenten über MCP DuckDuckGo-Suchdaten zur Verfügung stellen.
Lassen Sie uns loslegen!
Erste Schritte mit DuckDuckGo-Scraping
DuckDuckGo ist eine Suchmaschine, die einen integrierten Schutz vor Online-Trackern bietet. Nutzer schätzen sie wegen ihrer datenschutzorientierten Politik, da sie weder Suchanfragen noch den Browserverlauf verfolgt. Damit hebt sie sich von den gängigen Suchplattformen ab und verzeichnet seit Jahren einen stetigen Anstieg der Nutzung.
Die Suchmaschine DuckDuckGo ist in zwei Varianten verfügbar:
- Dynamische Version: Die Standardversion, die JavaScript erfordert und Funktionen wie„Search Assist” enthält, eine Alternative zu den Google-KI-Übersichten.
- Statische Version: Eine vereinfachte Version, die auch ohne JavaScript-Rendering funktioniert.
Je nach der von Ihnen gewählten Version benötigen Sie unterschiedliche Scraping-Ansätze, wie in dieser Übersichtstabelle dargestellt:
| Funktion | Dynamische SERP-Version | Statische SERP-Version |
|---|---|---|
| JavaScript erforderlich | Ja | Nein |
| URL-Format | https://duckduckgo.com/?q=<SEARCH_QUERY> |
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY> |
| Dynamischer Inhalt | Ja, wie KI-Zusammenfassungen und interaktive Elemente | Nein |
| Paginierung | Komplex, basierend auf einer Schaltfläche „Weitere Ergebnisse“ | Einfach, über eine herkömmliche Schaltfläche „Weiter“ mit Neuladen der Seite |
| Scraping-Ansatz | Browser-Automatisierungstools | HTTP-Client + HTML-Parser |
Zeit, die Auswirkungen des Scrapings auf die beiden DuckDuckGo-SERP-Versionen (Search Engine Results Page) zu untersuchen!
DuckDuckGo: Dynamische SERP-Version
Standardmäßig lädt DuckDuckGo eine dynamische Webseite, die JavaScript-Rendering erfordert, mit einer URL wie:
https://duckduckgo.com/?q=<SEARCH_QUERY>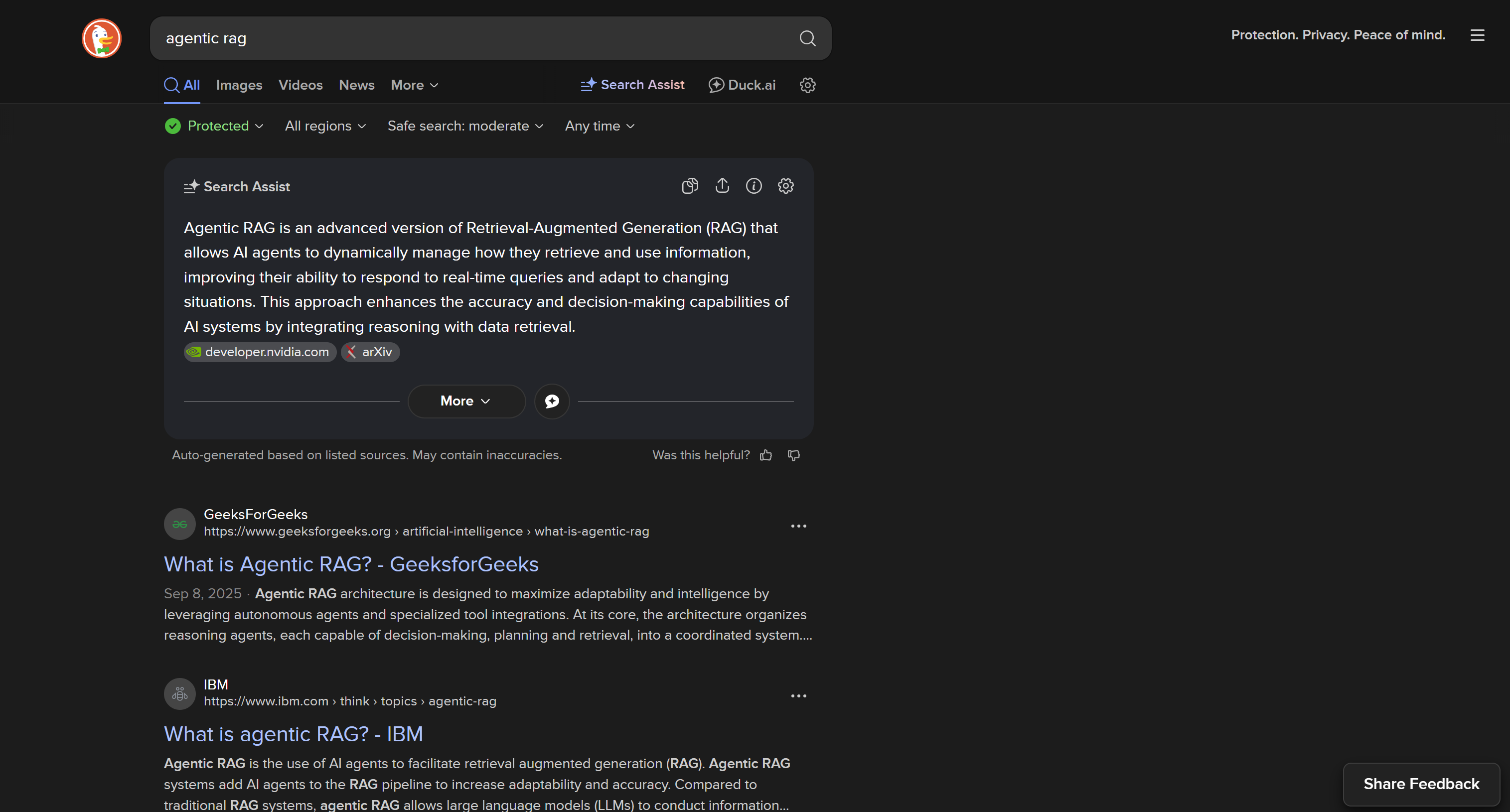
Diese Version umfasst komplexe Benutzerinteraktionen auf der Seite, wie beispielsweise die Schaltfläche „Weitere Ergebnisse“, mit der dynamisch weitere Ergebnisse geladen werden können:
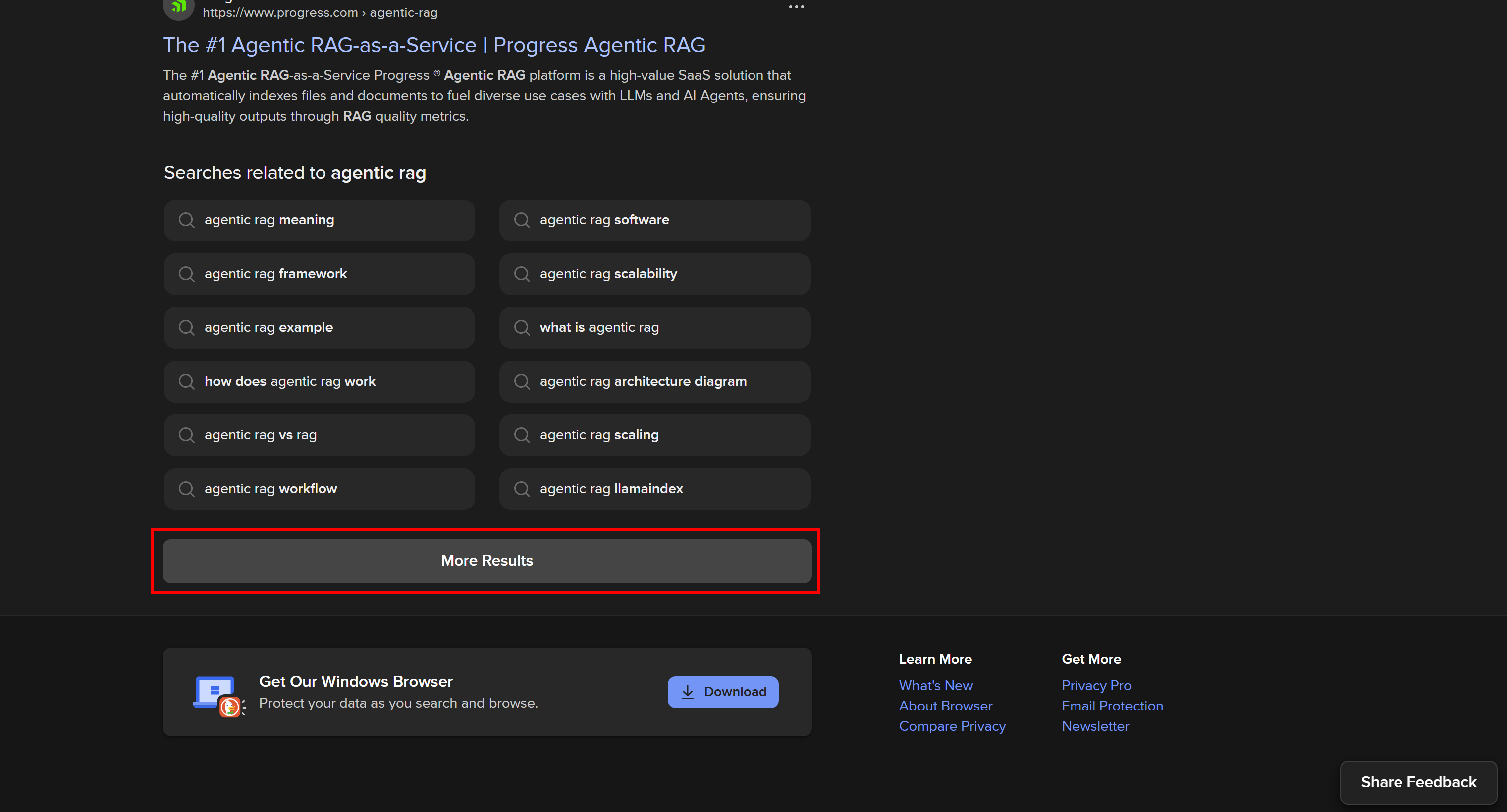
Die dynamische DuckDuckGo-SERP bietet mehr Funktionen und umfangreichere Informationen, erfordert jedoch Browser-Automatisierungstools für das Scraping. Der Grund dafür ist, dass nur ein Browser Seiten rendern kann, die von JavaScript abhängig sind.
Das Problem ist, dass die Steuerung eines Browsers zusätzliche Komplexität und Ressourcenverbrauch mit sich bringt. Aus diesem Grund verlassen sich die meisten Scraper auf die statische Version der Website!
DuckDuckGo: Statische SERP-Version
Für Geräte, die JavaScript nicht unterstützen, bietet DuckDuckGo auch eine statische Version seiner SERPs an. Diese Seiten folgen einem URL-Format wie dem folgenden:
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY>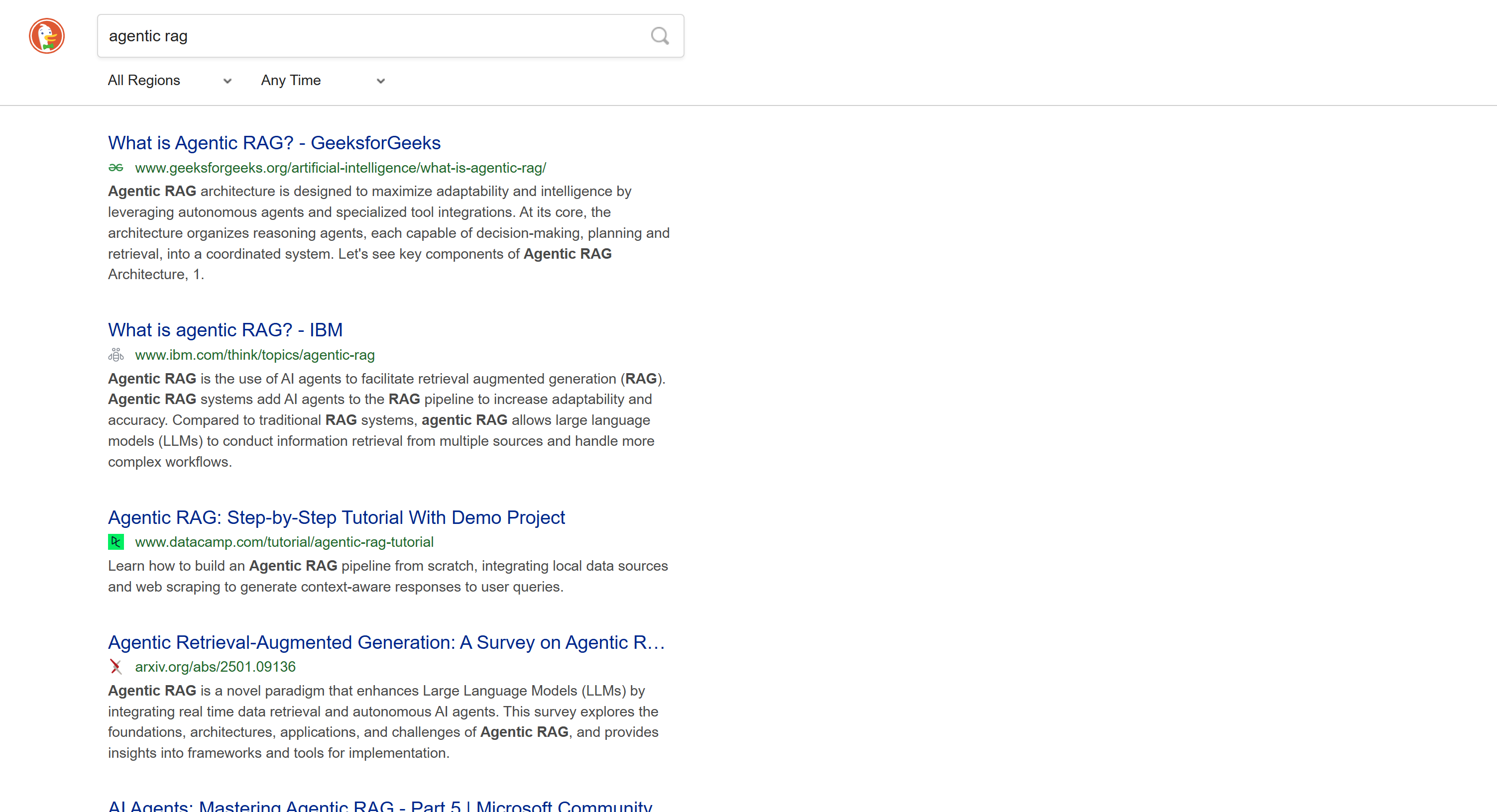
Diese Version enthält keine dynamischen Inhalte wie die KI-generierte Zusammenfassung. Außerdem folgt die Paginierung einem traditionelleren Ansatz mit einer Schaltfläche „Weiter“, die Sie zur nächsten Seite führt:
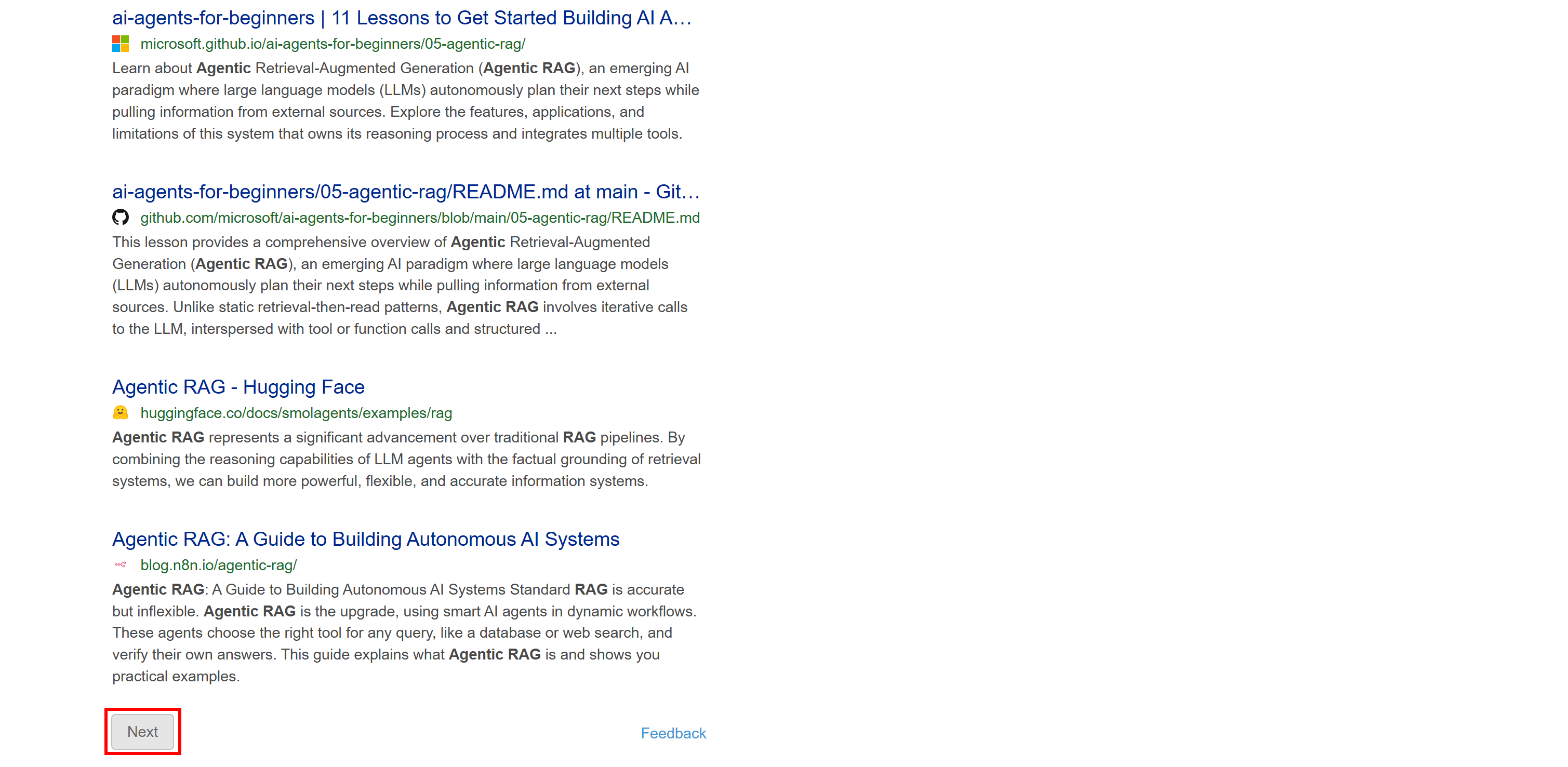
Da diese SERP statisch ist, können Sie sie mit einem traditionellen HTTP-Client + HTML-Parser-Ansatz scrapen. Diese Methode ist schneller, einfacher zu implementieren und verbraucht weniger Ressourcen.
Mögliche Ansätze zum Scraping von DuckDuckGo
Sehen Sie sich die vier möglichen Ansätze zum Web-Scraping von DuckDuckGo an, die wir in diesem Artikel vorstellen werden:
| Ansatz | Komplexität der Integration | Erfordert | Preis | Risiko von Blockierungen | Skalierbarkeit |
|---|---|---|---|---|---|
| Erstellen Sie einen benutzerdefinierten Scraper | Mittel/Hoch | Python-Programmierkenntnisse | Kostenlos (möglicherweise sind Premium-Proxys erforderlich, um Blockierungen zu vermeiden) | Möglich | Eingeschränkt |
| Verlässt sich auf eine DuckDuckGo-Scraping-Bibliothek | Gering | Python-Kenntnisse / CLI-Nutzung | Kostenlos (möglicherweise sind Premium-Proxys erforderlich, um Blockierungen zu vermeiden) | Möglich | Eingeschränkt |
| Verwenden Sie die SERP-API von Bright Data | Gering | Jeder HTTP-Client | Kostenpflichtig | Keine | Unbegrenzt |
| Integrieren Sie den Web-MCP-Server | Niedrig | KI-Agent-Frameworks/Lösungen, die MCP unterstützen | Kostenlose Stufe verfügbar, danach kostenpflichtig | Keine | Unbegrenzt |
Im Laufe dieses Tutorials erfahren Sie mehr über die einzelnen Funktionen.
Unabhängig davon, welchen Ansatz Sie verfolgen, lautet die Zielsuchanfrage in diesem Blogbeitrag „agentic rag”. Mit anderen Worten: Sie werden sehen, wie Sie DuckDuckGo-Suchergebnisse für diese Anfrage abrufen können.
Wir gehen davon aus, dass Sie Python bereits lokal installiert haben und mit der Sprache vertraut sind.
Ansatz Nr. 1: Erstellen Sie einen benutzerdefinierten Scraper
Verwenden Sie ein Browser-Automatisierungstool oder einen HTTP-Client in Kombination mit einem HTML-Parser, um einen DuckDuckGo -Web-Scraping-Bot von Grund auf neu zu erstellen.
👍 Vorteile:
- Volle Kontrolle über die Scraping-Logik.
- Kann genau an Ihre Anforderungen angepasst werden.
👎 Nachteile:
- Erfordert Einrichtung und Programmierung.
- Bei groß angelegten Scraping-Aktivitäten kann es zu IP-Sperren kommen.
Ansatz Nr. 2: Verwenden Sie eine DuckDuckGo-Scraping-Bibliothek
Verwenden Sie eine vorhandene Scraping-Bibliothek für DuckDuckGo, wie DDGS (Duck Distributed Global Search), die alle erforderlichen Funktionen bereitstellt, ohne dass Sie eine einzige Zeile Code schreiben müssen.
👍 Vorteile:
- Minimale Einrichtung erforderlich.
- Führt Suchmaschinen-Scraping-Aufgaben automatisch über Python-Code oder einfache CLI-Befehle aus.
👎 Nachteile:
- Geringere Flexibilität im Vergleich zu einem benutzerdefinierten Scraper, mit eingeschränkter Kontrolle über fortgeschrittene Anwendungsfälle.
- Es kommt immer noch zu IP-Sperren.
Ansatz Nr. 3: Verwenden Sie die SERP-API von Bright Data
Nutzen Sie den Premium-Endpunkt der SERP-API von Bright Data, den Sie von jedem HTTP-Client aus aufrufen können. Dieser unterstützt mehrere Suchmaschinen, darunter DuckDuckGo. Er übernimmt alle komplexen Aufgaben für Sie und bietet gleichzeitig skalierbares Scraping mit hohem Volumen.
👍 Vorteile:
- Unbegrenzte Skalierbarkeit.
- Vermeidet IP-Sperren und Anti-Bot-Maßnahmen.
- Integriert sich in HTTP-Clients in jeder Programmiersprache oder sogar in visuelle Tools wie Postman.
👎 Nachteile:
- Kostenpflichtiger Dienst.
Ansatz Nr. 4: Integration des Web-MCP-Servers
Statten Sie Ihren KI-Agenten mit DuckDuckGo-Scraping-Funktionen aus, indem Sie über den Bright Data Web MCP kostenlos auf die Bright Data SERP-API zugreifen.
👍 Vorteile:
- Einfache KI-Integration.
- Kostenlose Stufe verfügbar.
- Einfache Verwendung in KI-Agenten und Workflows.
👎 Nachteile:
- Sie können LLMs nicht vollständig kontrollieren.
Ansatz Nr. 1: Erstellen Sie einen benutzerdefinierten DuckDuckGo-Scraper mit Python
Befolgen Sie die folgenden Schritte, um zu erfahren, wie Sie ein benutzerdefiniertes DuckDuckGo-Scraping-Skript in Python erstellen.
Hinweis: Für ein vereinfachtes und schnelles Parsing verwenden wir die statische Version von DuckDuckGo. Wenn Sie daran interessiert sind , KI-generierte „Suchhilfen” zu sammeln , lesen Sie unseren Leitfaden zum Scraping von KI-Übersichtsresultaten aus Google. Sie können diesen leicht an DuckDuckGo anpassen.
Schritt 1: Richten Sie Ihr Projekt ein
Öffnen Sie zunächst Ihr Terminal und erstellen Sie einen neuen Ordner für Ihr DuckDuckGo-Scraper-Projekt:
mkdir duckduckgo-ScraperDer Ordner duckduckgo-scraper/ enthält Ihr Scraping-Projekt.
Navigieren Sie als Nächstes in das Projektverzeichnis und erstellen Sie darin eine virtuelle Python-Umgebung:
cd duckduckgo-Scraper
python -m venv .venvÖffnen Sie nun den Projektordner in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie eine neue Datei mit dem Namen scraper.py im Stammverzeichnis Ihres Projektverzeichnisses. Ihre Projektstruktur sollte wie folgt aussehen:
duckduckgo-Scraper/
├── .venv/
└── agent.pyAktivieren Sie die virtuelle Umgebung im Terminal. Führen Sie unter Linux oder macOS folgenden Befehl aus:
source venv/bin/activateUnter Windows führen Sie stattdessen folgenden Befehl aus:
venv/Scripts/activateNachdem die virtuelle Umgebung aktiviert ist, installieren Sie die Projektabhängigkeiten mit:
pip install requests beautifulsoup4Die beiden erforderlichen Bibliotheken sind:
requests: Ein beliebter Python-HTTP-Client. Er wird verwendet, um die statische Version der DuckDuckGo-SERP abzurufen.beautifulsoup4: Eine Python-Bibliothek für das Parsing von HTML, mit der Sie Daten aus der DuckDuckGo-Ergebnisseite extrahieren können.
Großartig! Ihre Python-Entwicklungsumgebung ist nun bereit, um ein DuckDuckGo-Scraping-Skript zu erstellen.
Schritt 2: Verbindung zur Zielseite herstellen
Beginnen Sie mit dem Importieren von requests in scraper.py:
import requestsFühren Sie als Nächstes eine browserähnliche GET-Anfrage an die statische Version von DuckDuckGo mit der Methode requests.get() aus:
# Basis-URL der statischen Version von DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Beispiel für eine Suchanfrage
search_query = "agentic rag"
# Um eine Browseranfrage zu simulieren und 403-Fehler zu vermeiden
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Verbindung zur Ziel-SERP-Seite herstellen
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)Wenn Sie mit dieser Syntax nicht vertraut sind, lesen Sie unseren Leitfaden zu Python-HTTP-Anfragen.
Der obige Ausschnitt sendet eine GET-HTTP-Anfrage an https://html.duckduckgo.com/html/?q=agentic+rag (die Ziel-SERP dieses Tutorials) mit dem folgenden User-Agent-Header:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36Die Einstellung eines realen User-Agent wie dem oben genannten ist erforderlich, um 403 Forbidden-Fehler von DuckDuckGo zu vermeiden. Erfahren Sie mehr über die Bedeutung des User-Agent-Headers beim Web-Scraping.
Der Server antwortet auf die GET-Anfrage mit dem HTML-Code der statischen Seite von DuckDuckGo. Greifen Sie darauf zu mit:
html = response.textÜberprüfen Sie den Seiteninhalt, indem Sie ihn ausdrucken:
print(html)Sie sollten einen HTML-Code sehen, der in etwa so aussieht:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=3.0, user-scalable=1" />
<meta name="referrer" content="origin" />
<meta name="HandheldFriendly" content="true" />
<meta name="robots" content="noindex, nofollow" />
<title>agentic rag bei DuckDuckGo</title>
<!-- Der Kürze halber ausgelassen... -->
</head>
<!-- Der Kürze halber ausgelassen... -->
<body>
<div>
<div class="serp__results">
<div id="links" class="results">
<div class="result results_links results_links_deep web-result">
<div class="links_main links_deep result__body">
<h2 class="result__title">
<a rel="nofollow" class="result__a"
href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9">
Was ist Agentic RAG? – GeeksforGeeks
</a>
</h2>
<!-- Der Kürze halber ausgelassen... -->
</div>
</div>
<!-- Weitere Ergebnisse ... -->
</div>
</div>
</div>
</body>
</html>Großartig! Dieser HTML-Code enthält alle SERP-Links, die Sie scrapen möchten.
Schritt 3: Parsing des HTML
Importieren Sie Beautiful Soup in scraper.py:
from bs4 import BeautifulSoupVerwenden Sie es dann, um die zuvor abgerufene HTML-Zeichenfolge in eine navigierbare Baumstruktur zu parsen:
soup = BeautifulSoup(html, "html.parser")Dadurch wird der HTML-Code mit dem in Python integrierten „html.parser” parsed. Sie können auch andere Parser konfigurieren, z. B. lxml oder html5lib, wie in unserem Leitfaden zum Web-Scraping mit BeautifulSoup erläutert.
Gut gemacht! Sie können nun die BeautifulSoup-API verwenden, um HTML-Elemente auf der Seite auszuwählen und die benötigten Daten zu extrahieren.
Schritt 4: Vorbereiten des Scrapings aller SERP-Ergebnisse
Bevor Sie sich mit der Scraping-Logik befassen, sollten Sie sich mit der Struktur der DuckDuckGo-SERPs vertraut machen. Öffnen Sie diese Webseite im Inkognito-Modus (um eine saubere Sitzung zu gewährleisten) in Ihrem Browser:
https://html.duckduckgo.com/html/?q=agentic+ragKlicken Sie anschließend mit der rechten Maustaste auf ein SERP-Ergebniselement und wählen Sie die Option „Untersuchen“, um die DevTools des Browsers zu öffnen:
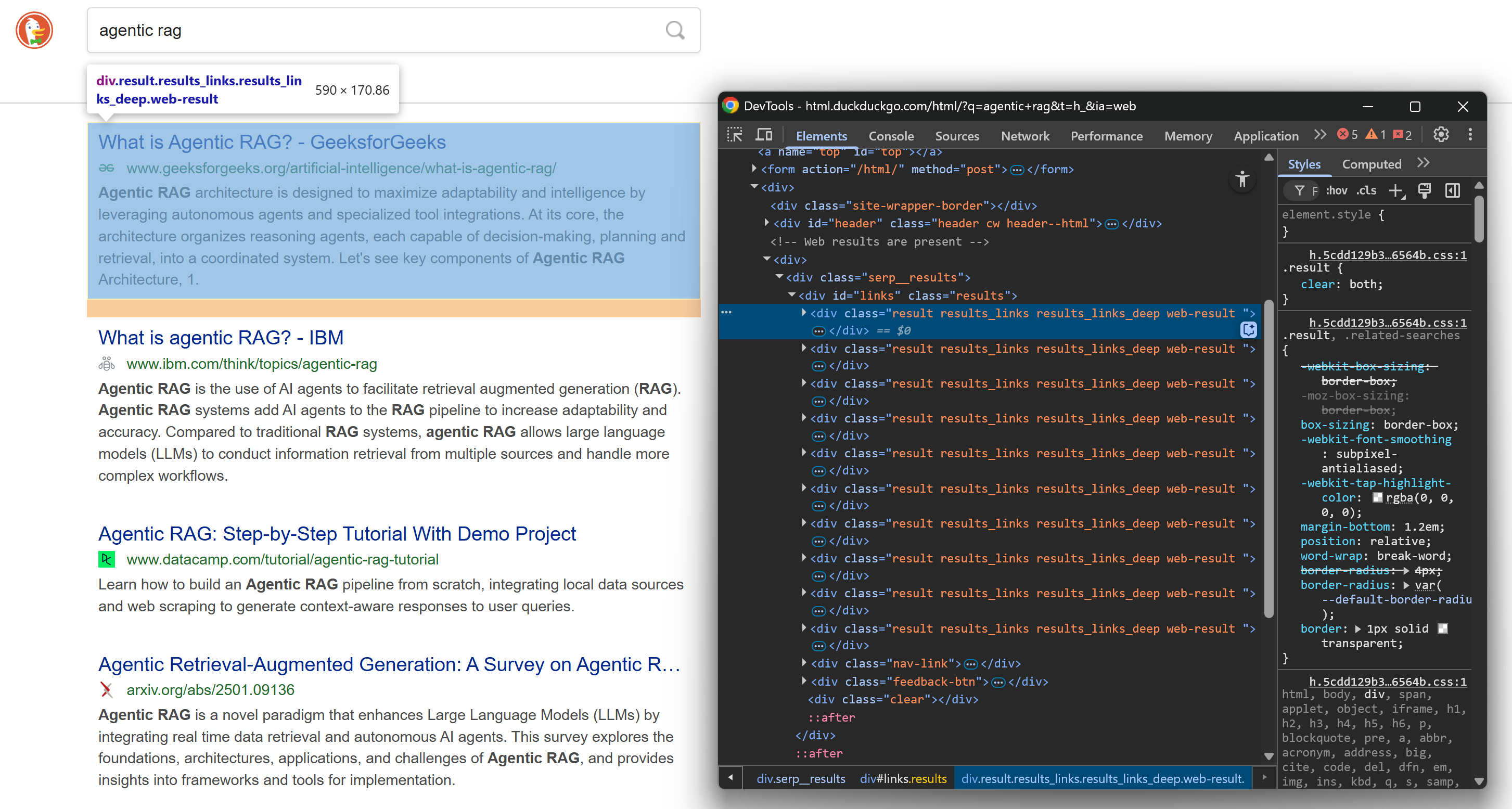
Sehen Sie sich die HTML-Struktur an. Beachten Sie, dass jedes SERP-Element die Klasse „result“ hat und in einem <div> enthalten ist, das durch die Links-ID identifiziert wird. Das bedeutet, dass Sie alle Suchergebniselemente mit diesem CSS-Selektor auswählen können:
#links .resultWenden Sie diesen Selektor mit der select() -Methode von Beautiful Soup auf die geparste Seite an:
result_elements = soup.select("#links .result") Da die Seite mehrere SERP-Elemente enthält, benötigen Sie eine Liste, um die gescrapten Daten zu speichern. Initialisieren Sie eine wie folgt:
serp_results = []Schließlich durchlaufen Sie jedes ausgewählte HTML-Element. Bereiten Sie sich darauf vor, Ihre Scraping-Logik anzuwenden, um die DuckDuckGo-Suchergebnisse zu extrahieren und die Liste serp_results zu füllen:
for result_element in result_elements:
# Daten-Parsing-Logik...Großartig! Sie sind nun kurz davor, Ihr DuckDuckGo-Scraping-Ziel zu erreichen.
Schritt 5: Scrapen Sie die Ergebnisdaten
Überprüfen Sie erneut die HTML-Struktur eines SERP-Elements auf der Ergebnisseite:
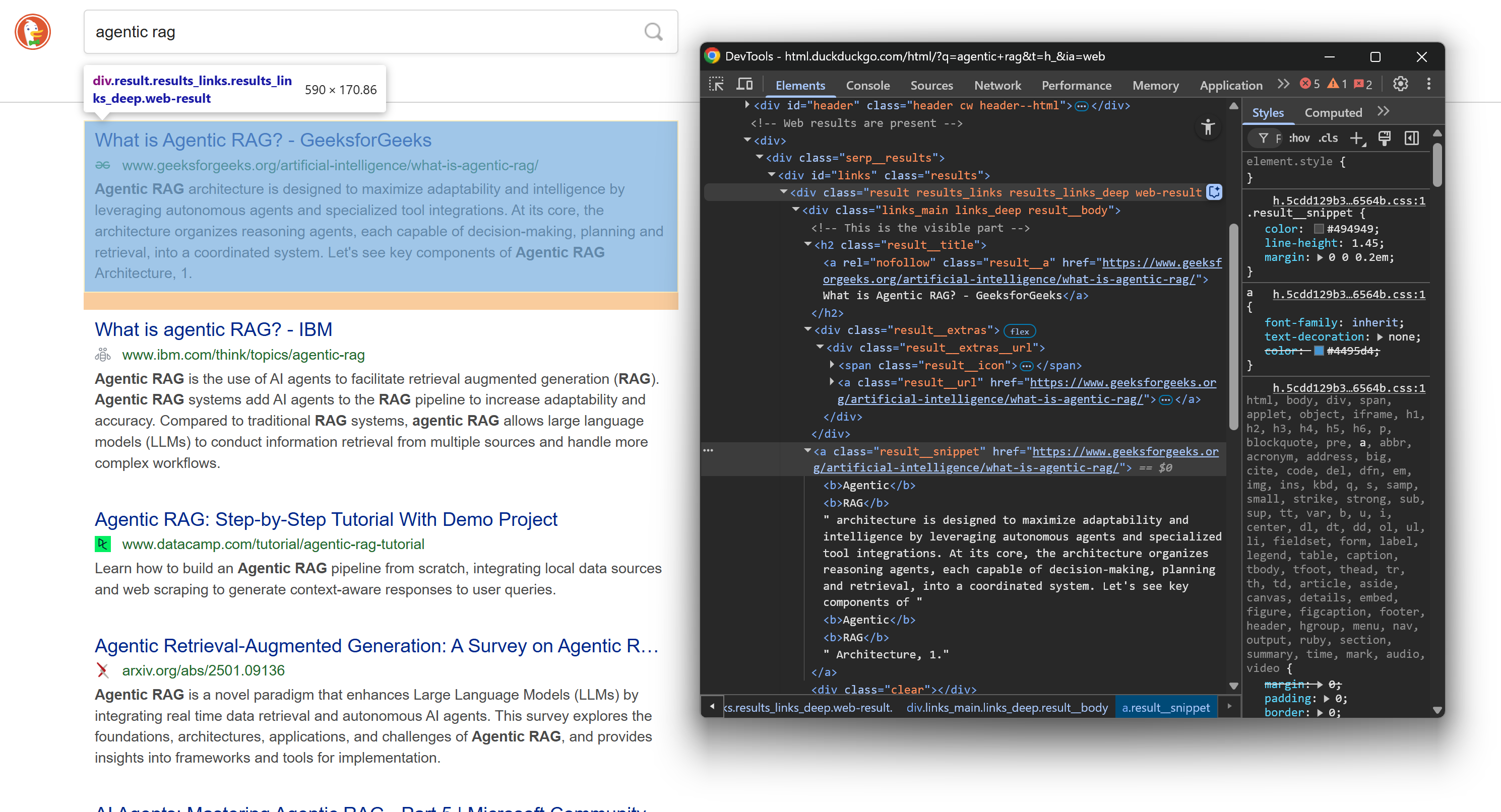
Konzentrieren Sie sich diesmal auf die verschachtelten HTML-Knoten. Wie Sie sehen können, können Sie aus diesen Elementen Folgendes scrapen:
- Ergebnis-Titel aus dem Text
.result__a - Ergebnis-URL aus dem
.result__ahref-Attribut - Die Anzeige-URL aus dem Text
.result__url - Ergebnis-Snippet/Beschreibung aus dem Text
.result__snippet
Wenden Sie die Methode select_one() von BeautifulSoup an, um den spezifischen Knoten auszuwählen, und verwenden Sie dann entweder .get_text(), um den Text zu extrahieren, oder [<attribute_name>], um auf ein HTML-Attribut zuzugreifen.
Implementieren Sie die Scraping-Logik mit:
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)Hinweis: strip=True ist nützlich, da es führende und nachfolgende Leerzeichen aus dem extrahierten Text entfernt.
Wenn Sie sich fragen, warum Sie „https:“ an title_element["href"] anhängen müssen, liegt das daran, dass sich der vom Server zurückgegebene HTML-Code geringfügig von dem in Ihrem Browser gerenderten unterscheidet. Der rohe HTML-Code, den Ihr Scraper tatsächlich parst, enthält URLs in einem Format wie diesem:
//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9Wie Sie sehen können, beginnt die URL mit // anstatt das Schema (https://) zu enthalten. Durch das Voranstellen von „https:“ stellen Sie sicher, dass die URL besser nutzbar wird (außerhalb von Browsern, die dieses Format ebenfalls unterstützen).
Überprüfen Sie dieses Verhalten selbst. Klicken Sie mit der rechten Maustaste auf die Seite und wählen Sie die Option „Seitenquelle anzeigen”. Dadurch wird Ihnen das vom Server zurückgegebene HTML-Dokument im Rohformat angezeigt (ohne Browser-Rendering). Sie sehen SERP-Links in diesem Format:
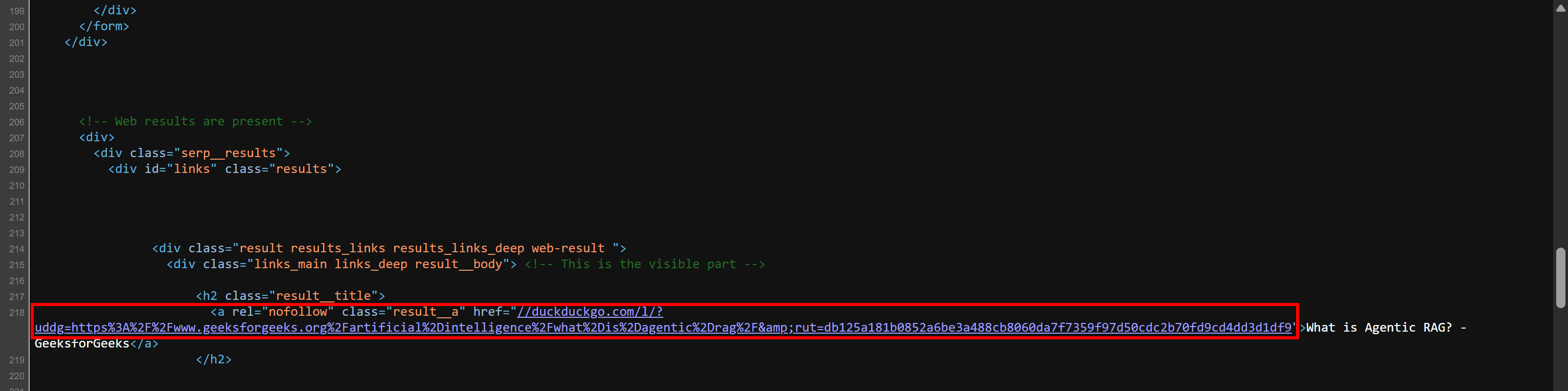
Erstellen Sie nun mit den gescrapten Datenfeldern ein Wörterbuch für jedes Suchergebnis und hängen Sie es an die Liste serp_results an:
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result) Perfekt! Ihre DuckDuckGo-Web-Scraping-Logik ist fertig. Jetzt müssen Sie nur noch die gescrapten Daten exportieren.
Schritt 6: Exportieren Sie die gescrapten Daten in eine CSV-Datei
Zu diesem Zeitpunkt haben Sie die DuckDuckGo-Suchergebnisse in einer Python-Liste gespeichert. Um diese Daten für andere Teams oder Tools nutzbar zu machen, exportieren Sie sie mit der in Python integrierten CSV-Bibliothek in eine CSV-Datei:
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Header schreiben
writer.writeheader()
# Alle Datenzeilen schreiben
writer.writerows(serp_results)Vergessen Sie nicht, csv zu importieren:
import csvAuf diese Weise erstellt Ihr DuckDuckGo-Scraper eine Ausgabedatei namens duckduckgo_results.csv, die alle gescrapten Ergebnisse im CSV-Format enthält. Mission erfüllt!
Schritt 7: Alles zusammenfügen
Der endgültige Code in scraper.py lautet:
import requests
from bs4 import BeautifulSoup
import csv
# Basis-URL der statischen Version von DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Beispiel für eine Suchanfrage
search_query = "agentic rag"
# Um eine Browseranfrage zu simulieren und 403-Fehler zu vermeiden
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Verbindung zur Ziel-SERP-Seite herstellen
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)
# HTML-Inhalt aus der Antwort abrufen
html = response.text
# HTML analysieren
soup = BeautifulSoup(html, "html.parser")
# Alle Ergebniscontainer finden
result_elements = soup.select("#links .result")
# Speicherort für die gescrapten Daten
serp_results = []
# Jedes SERP-Ergebnis durchlaufen und Daten daraus scrapen
for result_element in result_elements:
# Logik zum Parsing der Daten
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)
# Neues SERP-Ergebnisobjekt füllen und an die Liste anhängen
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)
# Exportieren Sie die gescrapten Daten in CSV
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Header schreiben
writer.writeheader()
# Alle Datenzeilen schreiben
writer.writerows(serp_results)Wow! Mit weniger als 65 Zeilen Code haben Sie gerade ein Skript zum Scrapen von DuckDuckGo-Daten erstellt.
Starten Sie es mit diesem Befehl:
python Scraper.pyDie Ausgabe ist eine Datei namens duckduckgo_results.csv, die in Ihrem Projektordner erscheint. Öffnen Sie sie, und Sie sollten die gescraped Daten wie folgt sehen:

Et voilà! Sie haben unstrukturierte Suchergebnisse einer DuckDuckGo-Webseite in eine strukturierte CSV-Datei umgewandelt.
[Extra] Integrieren Sie rotierende Proxys, um Blockierungen zu vermeiden
Der oben genannte Scraper funktioniert gut für kleine Läufe, ist jedoch nicht sehr skalierbar. Das liegt daran, dass DuckDuckGo Ihre Anfragen blockiert, wenn es zu viel Traffic von derselben IP-Adresse feststellt. In diesem Fall geben die Server eine 403-Fehlermeldung mit folgendem Text zurück:
Wenn dieses Problem weiterhin besteht, senden Sie uns bitte eine E-Mail an <a href="mailto:[email protected]?subject=Error getting results">mail to us</a>.<br />
Unsere Support-E-Mail-Adresse enthält einen anonymisierten Fehlercode, der uns hilft, den Kontext Ihrer Suche zu verstehen.Das bedeutet, dass der Server Ihre Anfrage als automatisiert identifiziert und blockiert hat, in der Regel aufgrund eines Problems mit der Ratenbegrenzung. Um Blockierungen zu vermeiden, müssen Sie Ihre IP-Adresse rotieren.
Die Lösung besteht darin, Anfragen über einen rotierenden Proxy zu senden. Wenn Sie mehr über diesen Mechanismus erfahren möchten, lesen Sie unseren Leitfaden zum Rotieren einer IP-Adresse.
Bright Data bietet rotierende Proxys, die von einem Netzwerk mit über 150 Millionen IPs unterstützt werden. Erfahren Sie, wie Sie diese in Ihren DuckDuckGo-Scraper integrieren können, um Blockierungen zu vermeiden!
Befolgen Sie die offizielle Anleitung zur Proxy-Einrichtung, und Sie erhalten eine Proxy-Verbindungszeichenfolge, die wie folgt aussieht:
<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335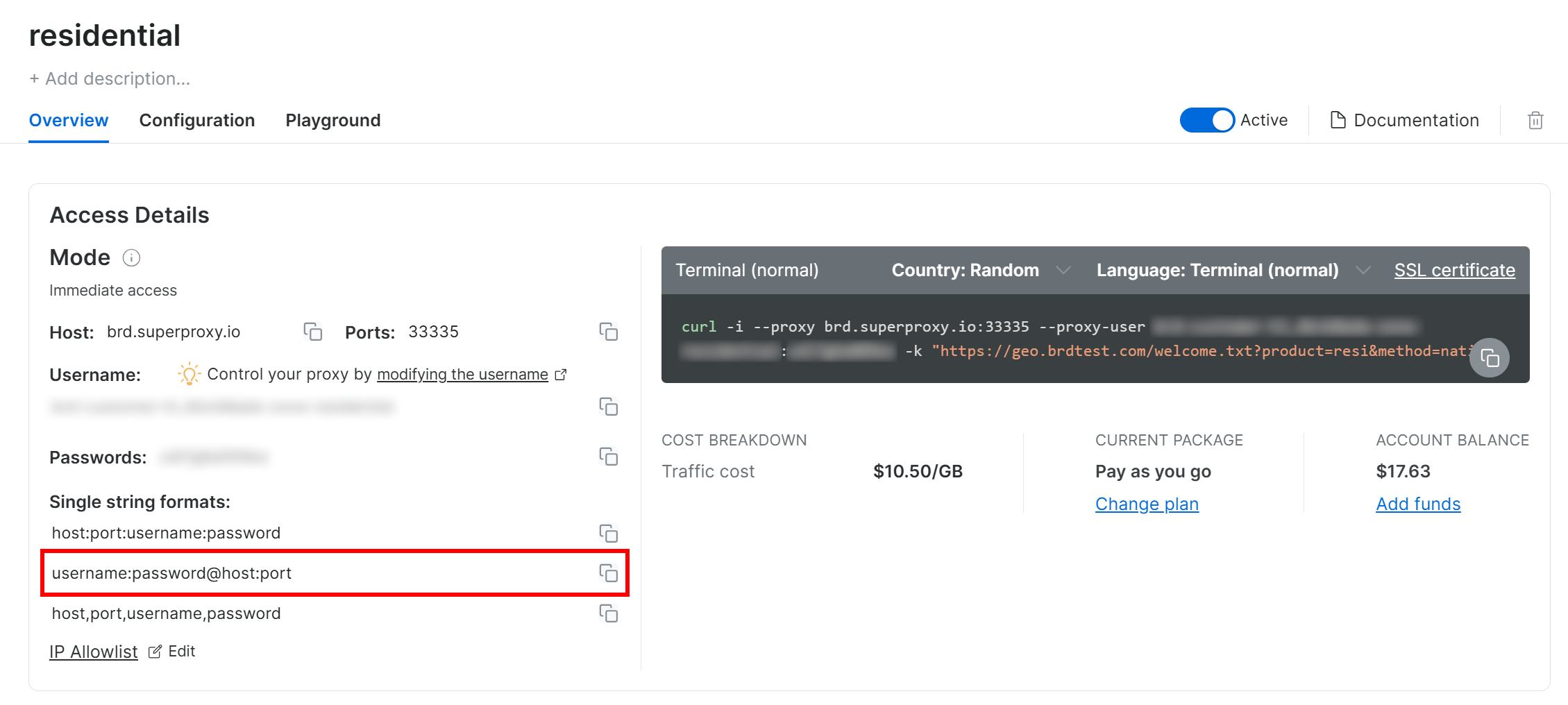
Stellen Sie den Proxy in Requests wie folgtein:
proxy_url = "http://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
# Definition von Parametern und Headern...
response = requests.get(
base_url,
params=params,
headers=headers,
proxies=proxies, # Weiterleitung der Anfrage über den Rotierenden Proxy
verify=False,
)Hinweis: verify=False deaktiviert die SSL-Zertifikatsüberprüfung. Dadurch werden Fehler im Zusammenhang mit der Validierung von Proxy-Zertifikaten vermieden, aber es ist unsicher. Eine produktionsreife Implementierung finden Sie auf unserer Dokumentationsseite zur SSL-Zertifikatsvalidierung.
Jetzt werden Ihre GET-Anfragen an DuckDuckGo über das 150 Millionen IP-Adressen umfassende Residential-Proxy-Netzwerk von Bright Data geleitet, wodurch jedes Mal eine neue IP-Adresse sichergestellt wird und Sie IP-bezogene Sperren vermeiden können.
Ansatz Nr. 2: Verwendung einer DuckDuckGo-Scraping-Bibliothek wie DDGS
In diesem Abschnitt erfahren Sie, wie Sie die DDGS-Bibliothek verwenden. Dieses Open-Source-Projekt mit über 1,8k Sternen auf GitHub war früher unter dem Namen duckduckgo-search bekannt, da es sich speziell auf DuckDuckGo konzentrierte. Vor kurzem wurde es in DDGS (Dux Distributed Global Search) umbenannt, da es nun auch andere Suchmaschinen unterstützt.
Hier sehen wir uns an, wie man es über die Befehlszeile verwendet, um DuckDuckGo-Suchergebnisse zu scrapen!
Schritt 1: DDGS installieren
Installieren Sie DDGS global oder in einer virtuellen Umgebung über das ddgs PyPI-Paket:
pip install -U ddgsNach der Installation können Sie über das Befehlszeilentool ddgs darauf zugreifen. Überprüfen Sie die Installation, indem Sie Folgendes ausführen:
ddgs --helpDie Ausgabe sollte wie folgt aussehen:
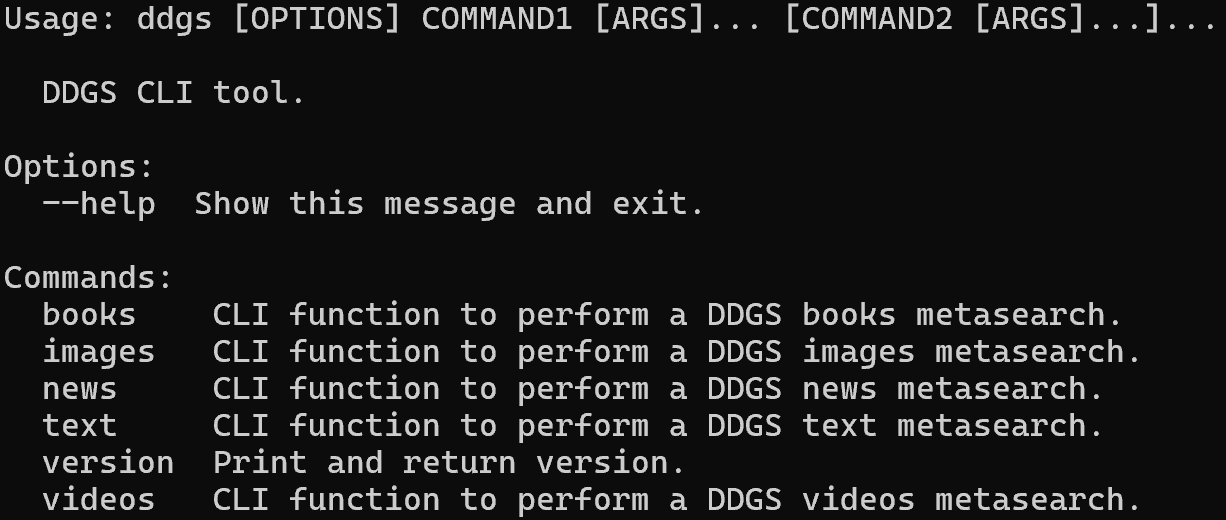
Wie Sie sehen können, unterstützt die Bibliothek mehrere Befehle zum Scraping verschiedener Datentypen (z. B. Text, Bilder, Nachrichten usw.). In diesem Fall verwenden Sie den Befehl „text“, der auf Suchergebnisse aus SERPs abzielt.
Hinweis: Sie können diese Befehle auch über die DDGS-API in Python-Code aufrufen, wie in der Dokumentation erläutert.
Schritt 2: Verwenden Sie DDGS über die CLI für das DuckDuckGo-Web-Scraping
Machen Sie sich zunächst mit dem Befehl „text” vertraut, indem Sie Folgendes ausführen:
ddgs text --helpDadurch werden alle unterstützten Flags und Optionen angezeigt:
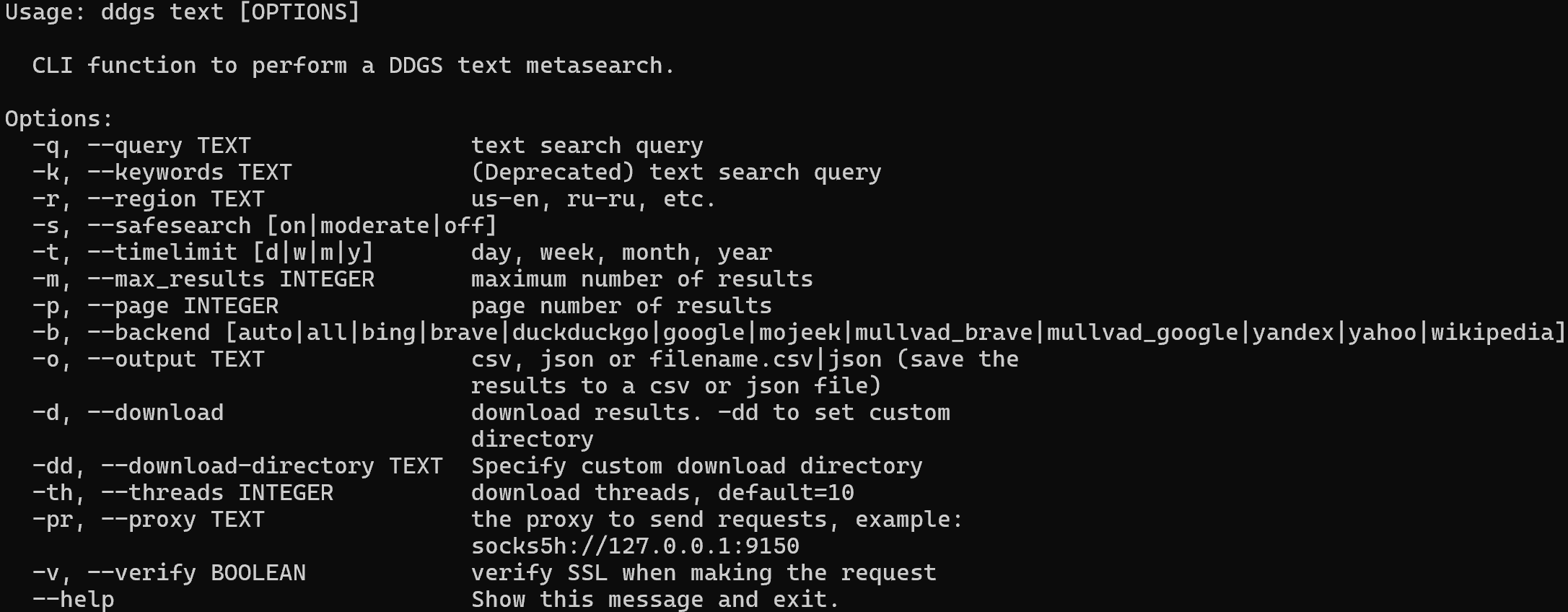
Um die DuckDuckGo-Suchergebnisse für „agentic rag” zu scrapen und in eine CSV-Datei zu exportieren, führen Sie Folgendes aus:
ddgs text -q „agentic rag” -b duckduckgo -o duckduckgo_results.csvDie Ausgabe ist eine Datei namens duckduckgo_results.csv. Öffnen Sie diese Datei, und Sie sollten etwa Folgendes sehen:

Erstaunlich! Sie haben die gleichen Suchergebnisse wie mit dem benutzerdefinierten Python-DuckDuckGo-Scraper erhalten, jedoch mit einem einzigen CLI-Befehl.
[Extra] Integrieren Sie einen rotierenden Proxy
Wie Sie gerade gesehen haben, ist DDGS ein äußerst leistungsfähiges SERP-Such- und Web-Scraping-Tool. Dennoch ist es keine Zauberei. Bei groß angelegten Scraping-Projekten stößt es auf die gleichen IP-Sperren und Blockierungen, die bereits erwähnt wurden.
Um solche Probleme zu vermeiden, benötigen Sie wie zuvor einen rotierenden Proxy. Kein Wunder, dass DDGS native Unterstützung für die Proxy-Integration über das Flag -pr (oder --proxy) bietet.
Rufen Sie Ihre rotierende Proxy-URL von Bright Data ab und legen Sie sie in Ihrem ddgs -CLI-Befehl wie folgt fest:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv -pr <BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335Fertig! Die zugrunde liegenden Webanfragen der Bibliothek werden nun über das rotierende Proxy-Netzwerk von Bright Data geleitet. So können Sie sicher scrapen, ohne sich um IP-bezogene Sperren sorgen zu müssen.
Ansatz Nr. 3: Verwendung der SERP-API von Bright Data
In diesem Kapitel erfahren Sie, wie Sie die All-in-One-SERP-API von Bright Data verwenden, um Suchergebnisse aus der dynamischen Version von DuckDuckGo programmgesteuert abzurufen. Befolgen Sie die nachstehenden Anweisungen, um loszulegen!
Hinweis: Für eine vereinfachte und schnellere Einrichtung gehen wir davon aus, dass Sie bereits über ein Python-Projekt mit installierter Requests-Bibliothek verfügen.
Schritt 1: Richten Sie Ihre Bright Data SERP-API-Zone ein
Erstellen Sie zunächst ein Bright Data-Konto oder melden Sie sich an, wenn Sie bereits eines haben. Im Folgenden werden Sie durch den Prozess der Einrichtung des SERP-API-Produkts für das Scraping von DuckDuckGo geführt.
Für eine schnellere Einrichtung können Sie auch den offiziellen SERP-API-Leitfaden „Schnellstart“ zu Rate ziehen. Andernfalls fahren Sie mit den folgenden Schritten fort.
Nachdem Sie sich angemeldet haben, navigieren Sie zu Ihrem Bright Data-Konto und klicken Sie auf die Option „Proxies & Scraping”, um zu dieser Seite zu gelangen:
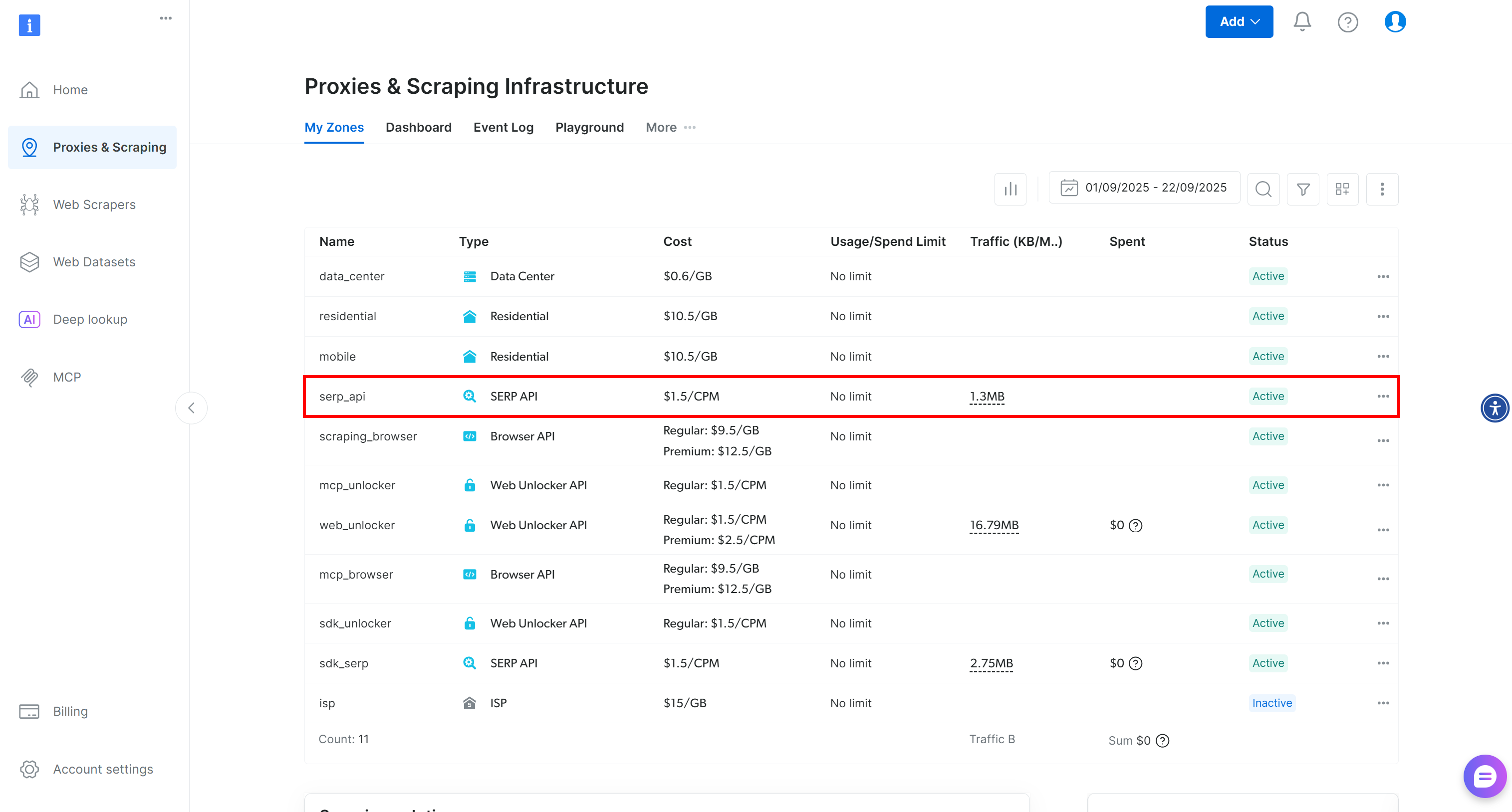
Überprüfen Sie die Tabelle „My Zones“, in der Ihre konfigurierten Bright Data-Produkte aufgelistet sind. Wenn bereits eine aktive SERP-API-Zone vorhanden ist, können Sie loslegen. Kopieren Sie einfach den Namen der Zone (in diesem Fallserp_api), da Sie ihn später benötigen werden.
Wenn keine Zone vorhanden ist, scrollen Sie nach unten zum Abschnitt „Scraping-Lösungen“ und klicken Sie auf die Schaltfläche „Zone erstellen“ auf der Karte „SERP-API“:
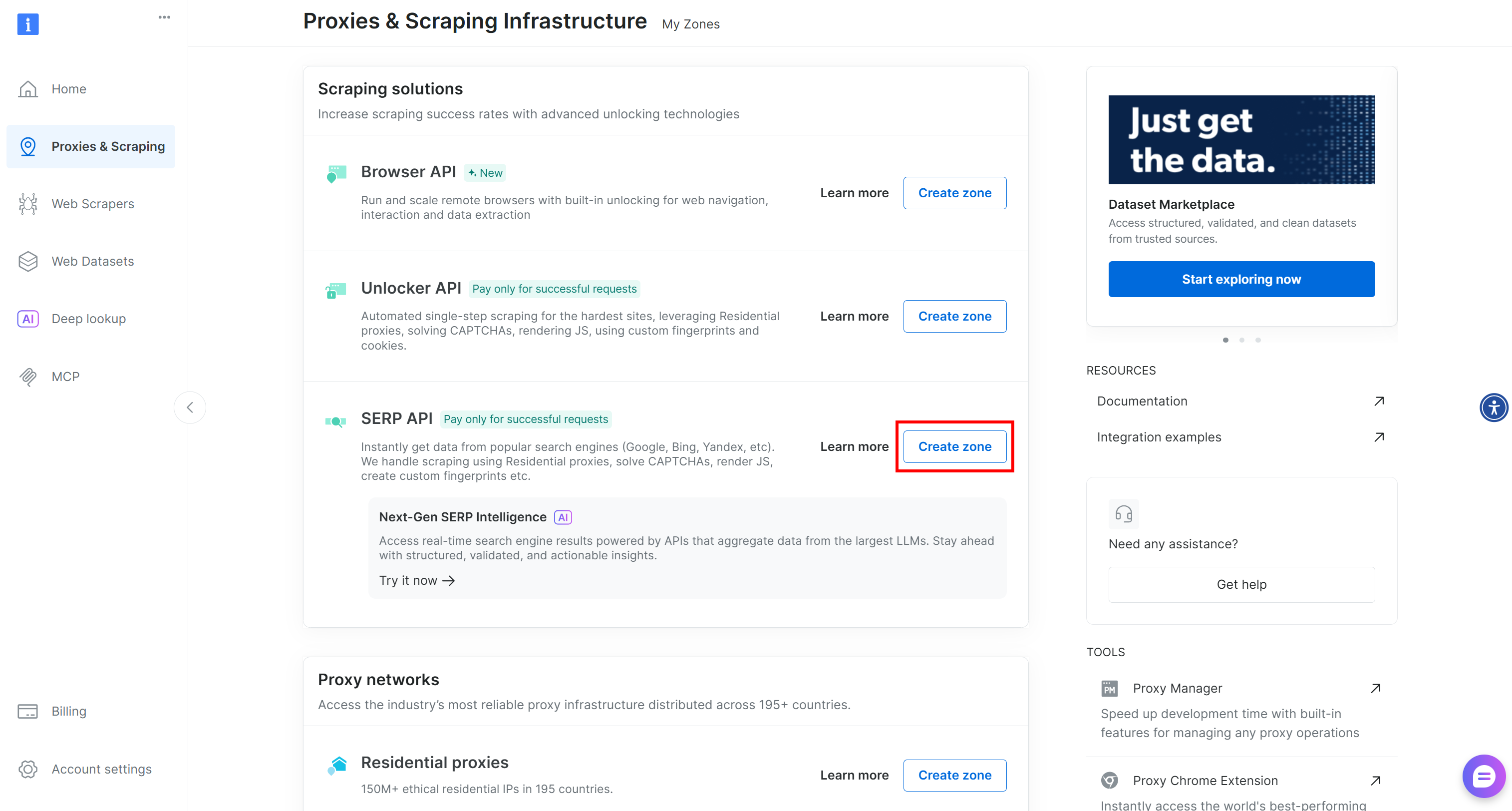
Geben Sie Ihrer Zone einen Namen (z. B. serp-api) und klicken Sie auf „Hinzufügen“:
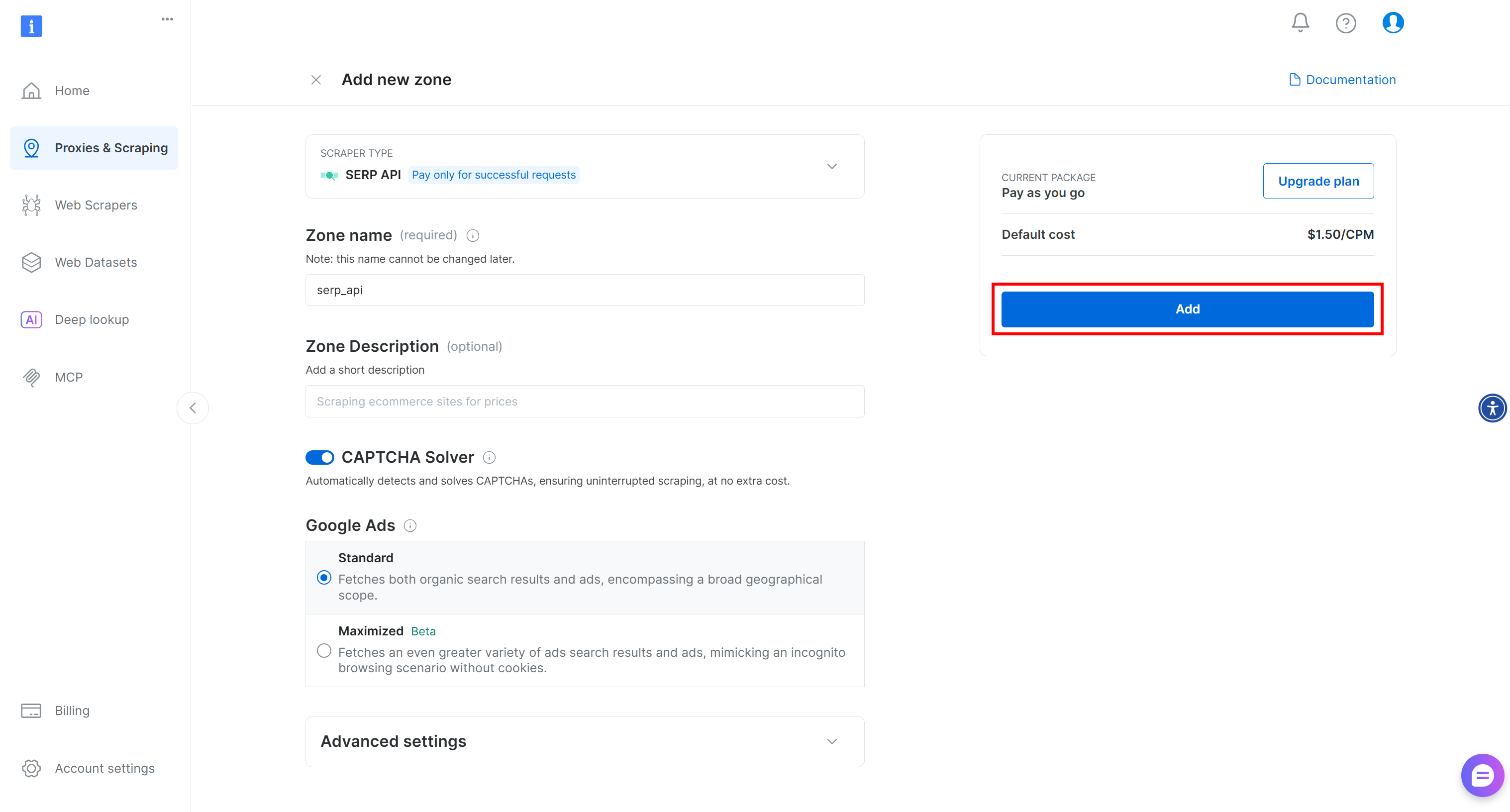
Gehen Sie als Nächstes zur Produktseite der Zone und stellen Sie sicher, dass sie aktiviert ist, indem Sie den Schalter auf „Active“ (Aktiv) stellen:
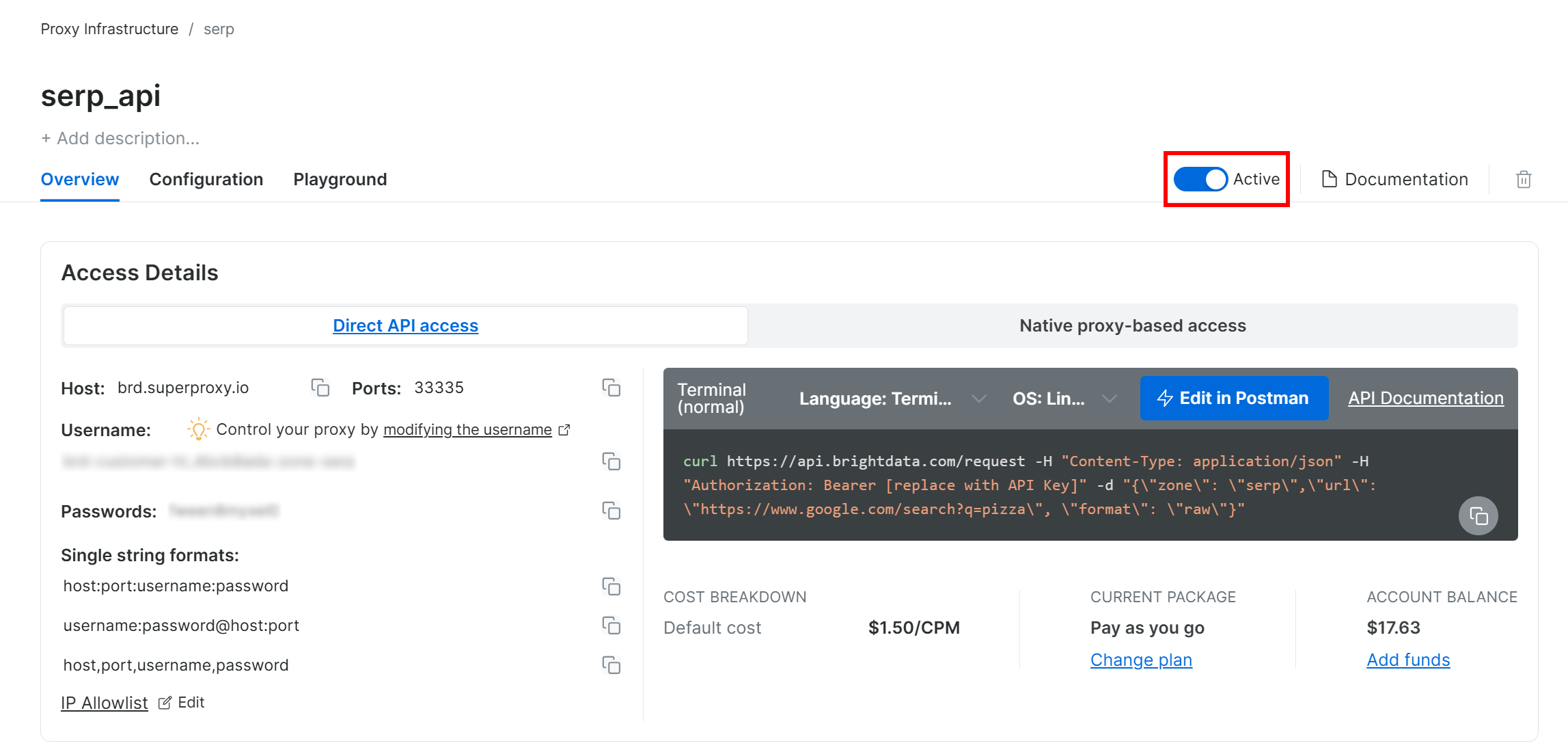
Großartig! Sie haben nun die SERP-API von Bright Data erfolgreich konfiguriert.
Schritt 2: Abrufen Ihres Bright Data API-Schlüssels
Die empfohlene Methode zur Authentifizierung von SERP-API-Anfragen ist die Verwendung Ihres Bright Data API-Schlüssels. Wenn Sie noch keinen generiert haben, befolgen Sie die offizielle Anleitung, um Ihren Schlüssel zu erhalten.
Wenn Sie eine POST-Anfrage an die SERP-API stellen, fügen Sie den API-Schlüssel zur Authentifizierung wie folgt in den Authorization -Header ein:
„Authorization: Bearer <BRIGHT_DATA_API_KEY>“Großartig! Sie verfügen nun über alle erforderlichen Bausteine, um die SERP-API von Bright Data in einem Python-Skript (oder über einen anderen HTTP-Client) aufzurufen.
Schritt 3: Aufruf der SERP-API
Fügen Sie alles zusammen und rufen Sie die Bright Data SERP-API auf der DuckDuckGo-Suchseite „agentic rag“ mit diesem Python-Snippet auf:
# pip install requests
import requests
# Bright Data-Anmeldedaten (TODO: durch Ihre Werte ersetzen)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"
# Ihre DuckDuckGo-Zielsuchseite
duckduckgo_page_url = "https://duckduckgo.com/?q=agentic+rag"
# Anfrage an die SERP-API von Bright Data stellen
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zone": bright_data_serp_api_zone_name,
"url": duckduckgo_page_url,
"format": "raw"
})
# Zugriff auf den gerenderten HTML-Code aus der dynamischen Version von DuckDuckGo
html = response.text
# Parsing-Logik...Ein vollständigeres Beispiel finden Sie unter „Bright Data SERP-API Python Project” auf GitHub.
Beachten Sie, dass die Ziel-URL diesmal die dynamische DuckDuckGo-Version sein kann (z. B. https://duckduckgo.com/?q=agentic+rag). Die SERP-API übernimmt das JavaScript-Rendering, ist in das Bright Data-Proxy-Netzwerk für die IP-Rotation integriert und verwaltet andere Anti-Scraping-Maßnahmen wie Browser-Fingerprinting und CAPTCHAs. Daher gibt es keine Probleme beim Scraping dynamischer SERPs.
Die Variable „html” enthält den vollständig gerenderten HTML-Code der DuckDuckGo-Seite. Überprüfen Sie dies, indem Sie den HTML-Code mit folgendem Befehl ausgeben:
print(html)Sie erhalten etwa folgende Ausgabe:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agentic RAG bei DuckDuckGo</title>
<!-- Der Kürze halber ausgelassen ... -->
</head>
<body>
<div class="site-wrapper" style="min-height: 825px;">
<div id="content">
<div id="duckassist-answer" class="answer-container">
<DIV class="answer-content-block">
<P class="answer-text">
<SPAN class="highlight">Agentic RAG</SPAN> ist eine erweiterte Version von Retrieval-Augmented Generation (RAG), die es KI-Agenten ermöglicht, die Art und Weise, wie sie Informationen abrufen und verwenden, dynamisch zu verwalten, wodurch ihre Fähigkeit verbessert wird, auf Echtzeitabfragen zu reagieren und sich an veränderte Situationen anzupassen. Dieser Ansatz verbessert die Genauigkeit und Entscheidungsfähigkeit von KI-Systemen, indem er das Schlussfolgern mit dem Abrufen von Daten integriert.
</P>
<!-- Der Kürze halber ausgelassen ... -->
</DIV>
<!-- Der Kürze halber ausgelassen ... -->
</DIV>
<ul class="results-list">
<li class="result-item">
<article class="result-card">
<div <!-- Aus Gründen der Kürze ausgelassen ... -->
<div class="result-body">
<h2 class="result-title">
<a href="https://www.geeksforgeeks.org/artificial-intelligence/what-is-agentic-rag/" rel="noopener" target="_blank" class="result-link">
<span class="title-text">Was ist Agentic RAG? – GeeksforGeeks</span>
</a>
</h2>
<div class="result-snippet-container">
<div class="result-snippet">
<div>
<span class="snippet-text">
<span class="snippet-date">8. September 2026</span>
<span>
Die Architektur von <b>Agentic RAG</b> wurde entwickelt, um die Anpassungsfähigkeit und Intelligenz durch den Einsatz autonomer Agenten und spezialisierter Tool-Integrationen zu maximieren. Im Kern organisiert die Architektur schlussfolgernde Agenten, die jeweils in der Lage sind, Entscheidungen zu treffen, zu planen und Informationen abzurufen, zu einem koordinierten System. Sehen wir uns die wichtigsten Komponenten der <b>Agentic RAG</b>-Architektur an: 1.
</span>
</span>
</div>
</div>
</div>
</div>
</article>
</li>
<!-- Weitere Suchergebnisse ... -->
</ul>
<!-- Der Kürze halber weggelassen ... -->
</div>
<!-- Der Kürze halber weggelassen ... -->
</div>
</body>
</html>Hinweis: Die ausgegebene HTML-Datei kann auch die von der KI generierte Zusammenfassung „Search Assist” enthalten, da es sich um die dynamische Version der Seite handelt.
Nun führen Sie das Parsing dieses HTML-Codes wie im ersten Ansatz aus, um auf die benötigten DuckDuckGo-Daten zuzugreifen!
Ansatz Nr. 4: Integration eines DuckDuckGo-Scraping-Tools in einen KI-Agenten über MCP
Denken Sie daran, dass das SERP-API-Produkt auch über das Tool „search_engine” verfügbar ist, das im Bright Data Web MCP enthalten ist.
Dieser Open-Source-MCP-Server bietet KI-Zugriff auf die Webdatenabruf-Lösungen von Bright Data, einschließlich der DuckDuckGo-Scraping-Funktionen. Im Einzelnen ist das Tool „search_engine“ in der kostenlosen Version des Web MCP verfügbar, sodass Sie es ohne Kosten in Ihre KI-Agenten oder Workflows integrieren können.
Um das Web MCP in Ihre KI-Lösung zu integrieren, benötigen Sie in der Regel Node.js lokal installiert und eine Konfigurationsdatei wie diese:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}Diese Konfiguration funktioniert beispielsweise mit Claude Code. Weitere Integrationen finden Sie in der Dokumentation.
Dank dieser Integration können Sie SERP-Daten in natürlicher Sprache abrufen und in Ihren KI-gestützten Workflows oder Agenten verwenden.
Fazit
In diesem Tutorial haben Sie die vier empfohlenen Methoden zum Scraping von DuckDuckGo kennengelernt:
- Über einen benutzerdefinierten Scraper
- Mit DDGS
- Mit der DuckDuckGo-Such-API
- Dank Web MCP
Wie gezeigt, ist die einzige zuverlässige Methode, um DuckDuckGo in großem Umfang zu scrapen und dabei Blockierungen zu vermeiden, die Verwendung einer strukturierten Scraping-Lösung, die auf einer robusten Anti-Bot-Bypass-Technologie und einem großen Proxy-Netzwerk wie Bright Data basiert.
Erstellen Sie ein kostenloses Bright Data-Konto und entdecken Sie unsere Scraping-Lösungen!