

In diesem Artikel erfahren Sie:
- Welche Produkte Bright Data auf Databricks anbietet.
- Wie Sie ein Databricks-Konto einrichten und alle erforderlichen Anmeldedaten für die programmatische Datenabfrage und -exploration abrufen.
- Wie Sie einen Bright Data-Datensatz mit Databricks abfragen können:
- REST-API
- CLI
- SQL-Konnektor
Lassen Sie uns loslegen!
Datenprodukte von Bright Data auf Databricks
Databricks ist eine offene Analyseplattform für die Erstellung, Bereitstellung, Freigabe und Pflege von Daten, Analysen und KI-Lösungen für Unternehmen in großem Maßstab. Auf der Website finden Sie Datenprodukte von mehreren Anbietern, weshalb sie als einer der besten Datenmarktplätze gilt.
Bright Data ist seit kurzem als Datenproduktanbieterbei Databricks vertreten und bietet bereits über 40 Produkte an:
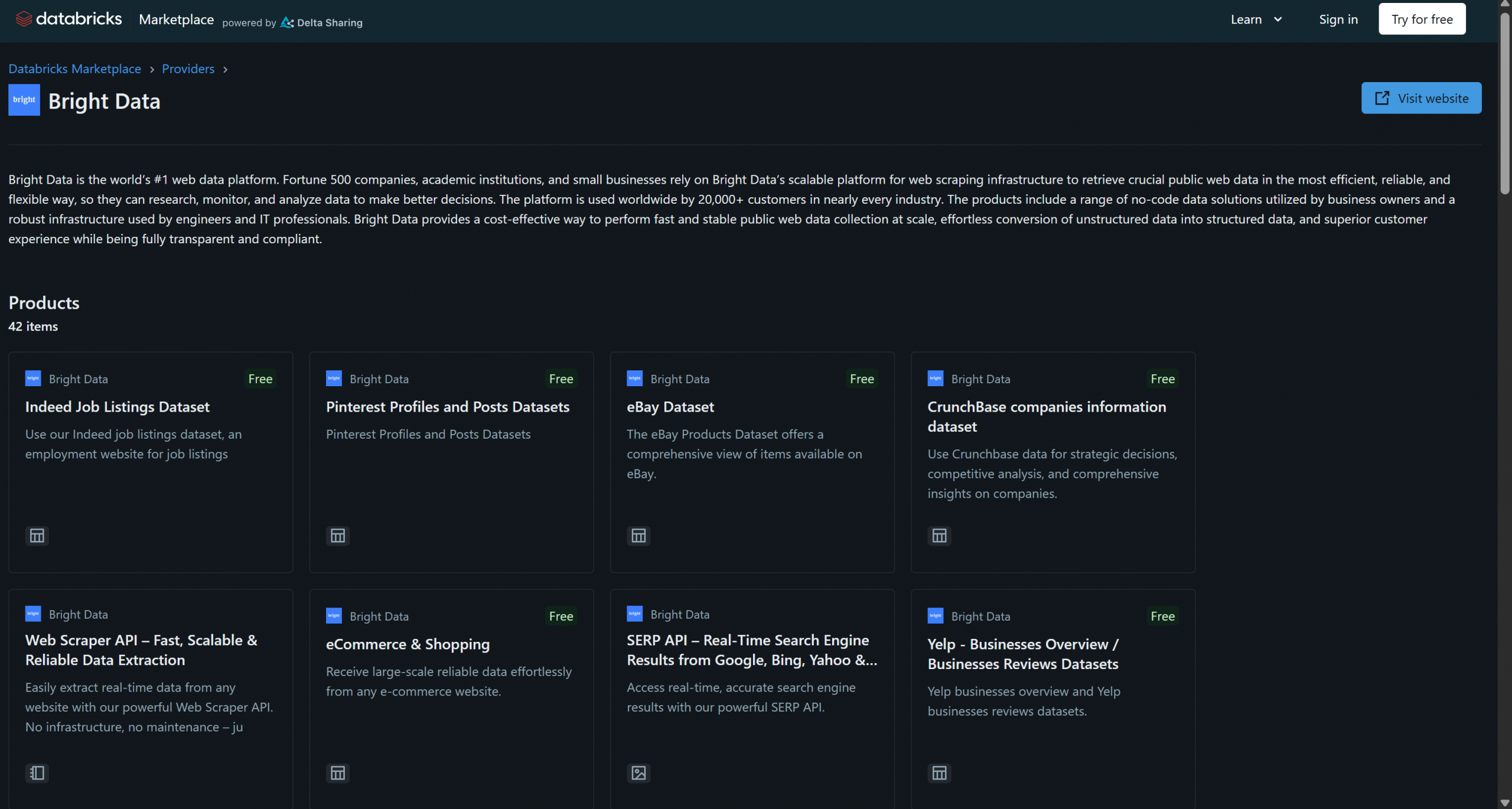
Zu diesen Lösungen gehören B2B-Datensätze, Unternehmensdatensätze, Finanzdatensätze, Immobiliendatensätze und viele andere. Darüber hinaus haben Sie über die Infrastruktur von Bright Data Zugriff auf allgemeinere Lösungen für die Abfrage von Webdaten und das Web-Scraping, wie z. B. der Scraping-Browser und die Web Scraper API.
In diesem Tutorial erfahren Sie, wie Sie Daten aus einem dieser Bright Data-Datensätze mithilfe der Databricks-API, der CLI und der dedizierten SQL Connector-Bibliothek programmgesteuert abfragen können. Legen wir los!
Erste Schritte mit Databricks
Um Bright Data-Datensätze aus Databricks über API oder CLI abzufragen, müssen Sie zunächst einige Einstellungen vornehmen. Befolgen Sie die folgenden Schritte, um Ihr Databricks-Konto zu konfigurieren und alle erforderlichen Anmeldedaten für den Zugriff auf und die Integration von Bright Data-Datensätzen abzurufen.
Am Ende dieses Abschnitts verfügen Sie über:
- Ein konfiguriertes Databricks-Konto
- Ein Databricks-Zugriffstoken
- Eine Databricks-Warehouse-ID
- Eine Databricks-Host-Zeichenfolge
- Zugriff auf einen oder mehrere Bright Data-Datensätze in Ihrem Databricks-Konto
Voraussetzungen
Stellen Sie zunächst sicher, dass Sie über ein Databricks-Konto verfügen (ein kostenloses Konto reicht aus). Wenn Sie noch kein Konto haben, erstellen Sie eines. Andernfalls melden Sie sich einfach an.
Konfigurieren Sie Ihren Databricks-Zugriffstoken
Um den Zugriff auf Databricks-Ressourcen zu autorisieren, benötigen Sie einen Zugriffstoken. Befolgen Sie die nachstehenden Anweisungen, um einen solchen einzurichten.
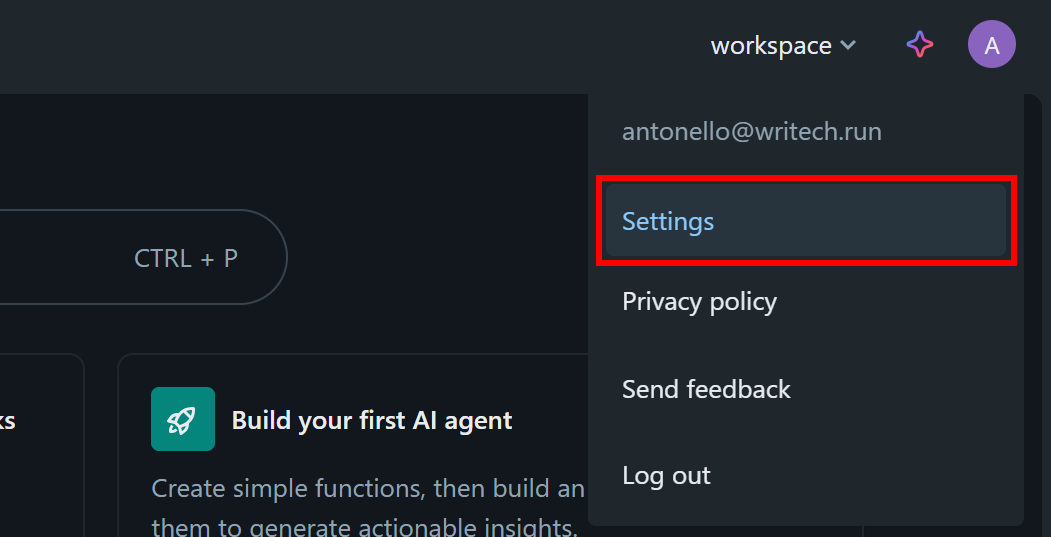
Klicken Sie in Ihrem Databricks-Dashboard auf Ihr Profilbild und wählen Sie die Option „Einstellungen“:
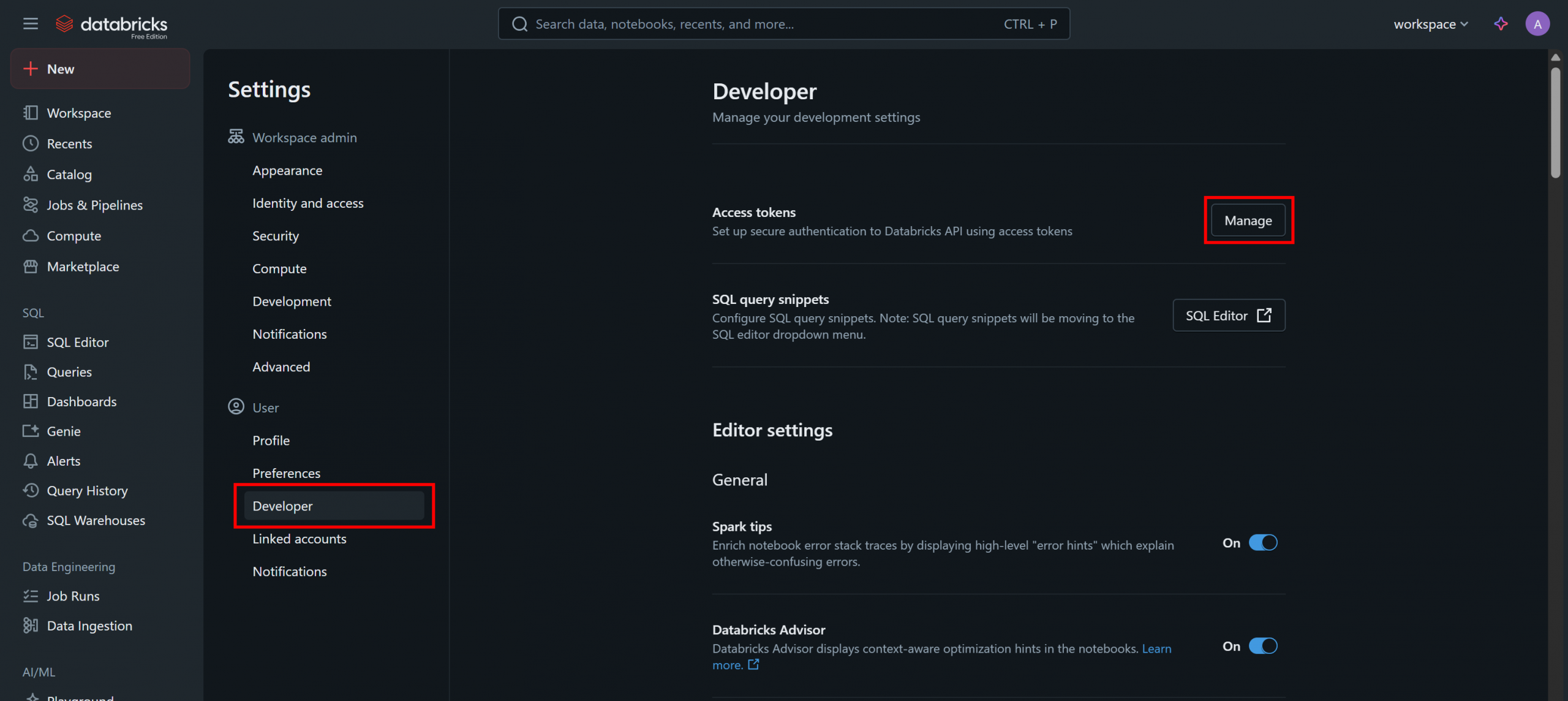
Wählen Sie auf der Seite „Einstellungen“ die Option „Entwickler“ und klicken Sie dann im Abschnitt „Zugriffstoken“ auf die Schaltfläche „Verwalten“:
Klicken Sie auf der Seite „Zugriffstoken“ auf „Neues Token generieren“ und befolgen Sie die Anweisungen im Modal:
Sie erhalten einen Databricks-API-Zugriffstoken. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn bald benötigen werden.
Rufen Sie Ihre Databricks-Warehouse-ID ab
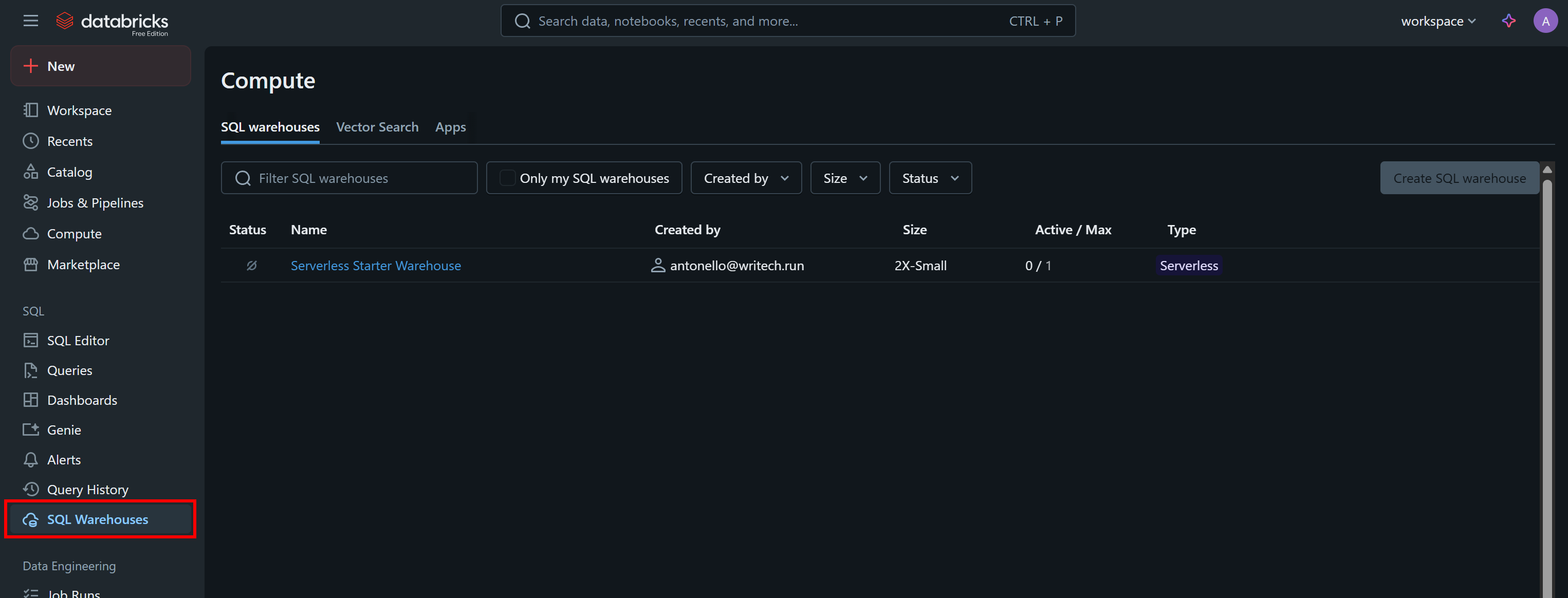
Eine weitere Information, die Sie benötigen, um die API programmgesteuert aufzurufen oder die Datensätze über die CLI abzufragen, ist Ihre Databricks-Warehouse-ID. Um diese abzurufen, wählen Sie im Menü die Option „SQL-Warehouses“:
Klicken Sie auf das verfügbare Warehouse (in diesem Beispiel „Serverless Starter Warehouse“) und rufen Sie die Registerkarte „Übersicht“ auf:
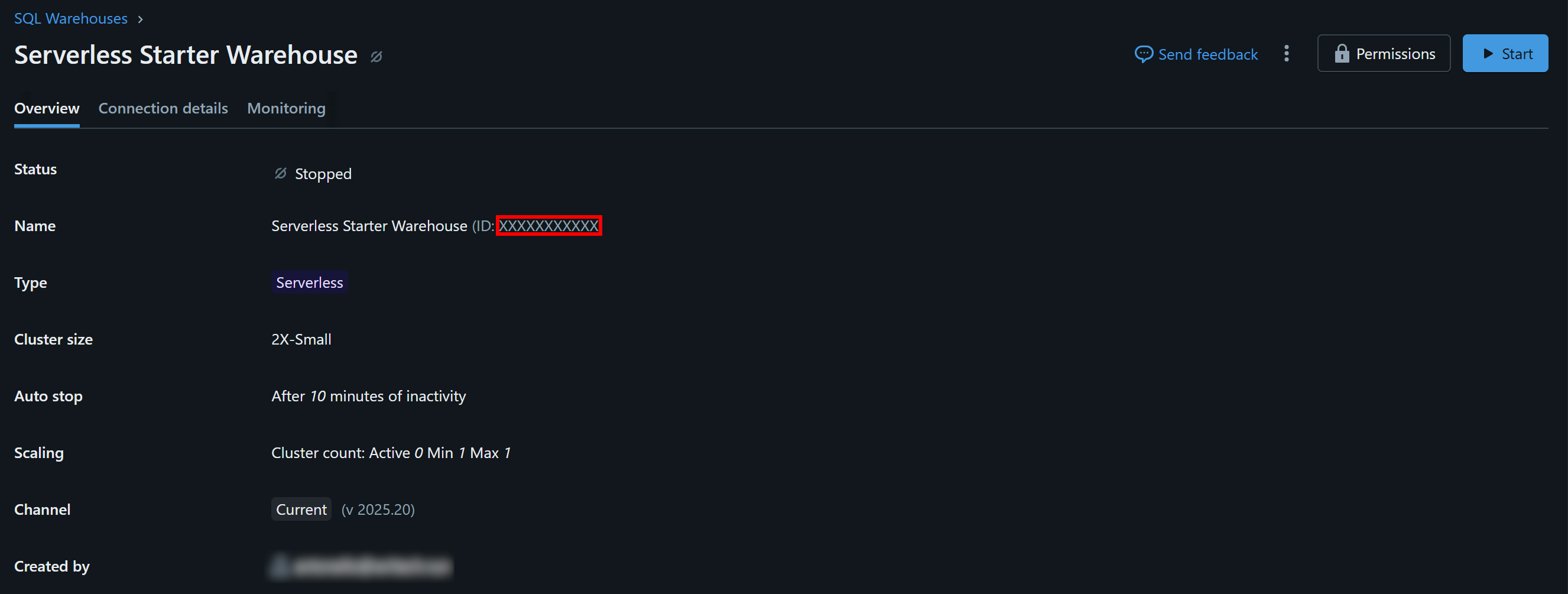
Im Abschnitt „Name“ sehen Sie Ihre Databricks-Warehouse-ID (in Klammern, nach ID:). Kopieren Sie sie und bewahren Sie sie sicher auf, da Sie sie in Kürze benötigen werden.
Finden Sie Ihren Databricks-Host
Um eine Verbindung zu einer Databricks-Rechenressource herzustellen, müssen Sie Ihren Databricks-Hostnamen angeben. Dieser entspricht der Basis-URL Ihres Databricks-Kontos und hat folgendes Format:
https://<zufällige Zeichenfolge>.cloud.databricks.comSie finden diese Informationen direkt, indem Sie sie aus der URL Ihres Databricks-Dashboards kopieren:

Zugriff auf Bright Data-Datensätze erhalten
Jetzt müssen Sie Ihrem Databricks-Konto einen oder mehrere Bright Data-Datensätze hinzufügen, damit Sie diese über API, CLI oder SQL Connector abfragen können.
Gehen Sie zur Seite „Marketplace“, klicken Sie auf die Schaltfläche „Einstellungen“ auf der linken Seite und wählen Sie „Bright Data“ als einzigen Anbieter aus, der Sie interessiert:
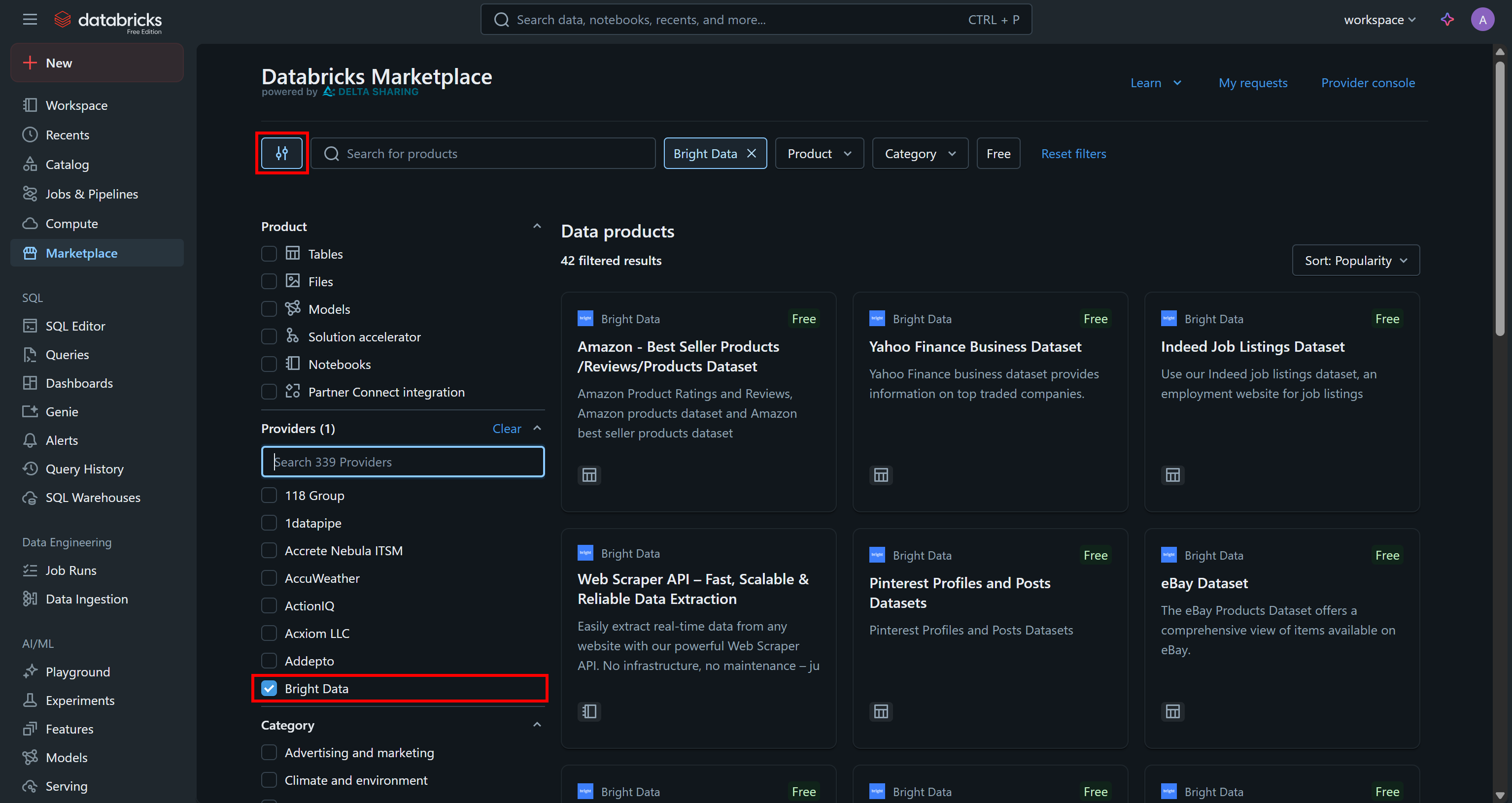
Dadurch werden die verfügbaren Datenprodukte so gefiltert, dass nur diejenigen angezeigt werden, die von Bright Data bereitgestellt werden und über Databricks zugänglich sind.
Nehmen wir für dieses Beispiel an, Sie interessieren sich für den„Zillow Properties Information Datensatz”:
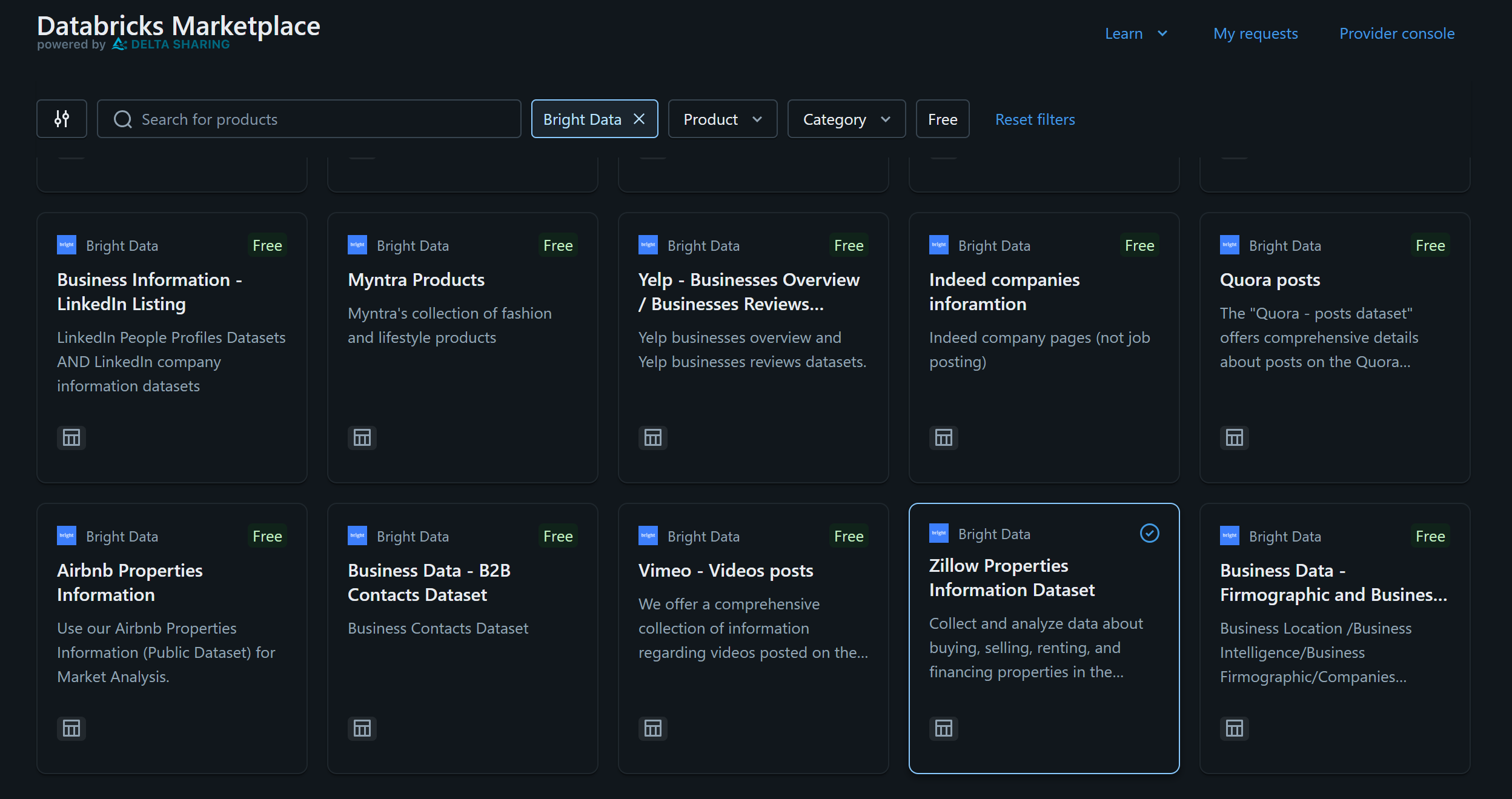
Klicken Sie auf die Datensatzkarte und drücken Sie auf der Seite „Zillow Properties Information Dataset“ auf „Get Instances Access“, um ihn Ihrem Databricks-Konto hinzuzufügen:
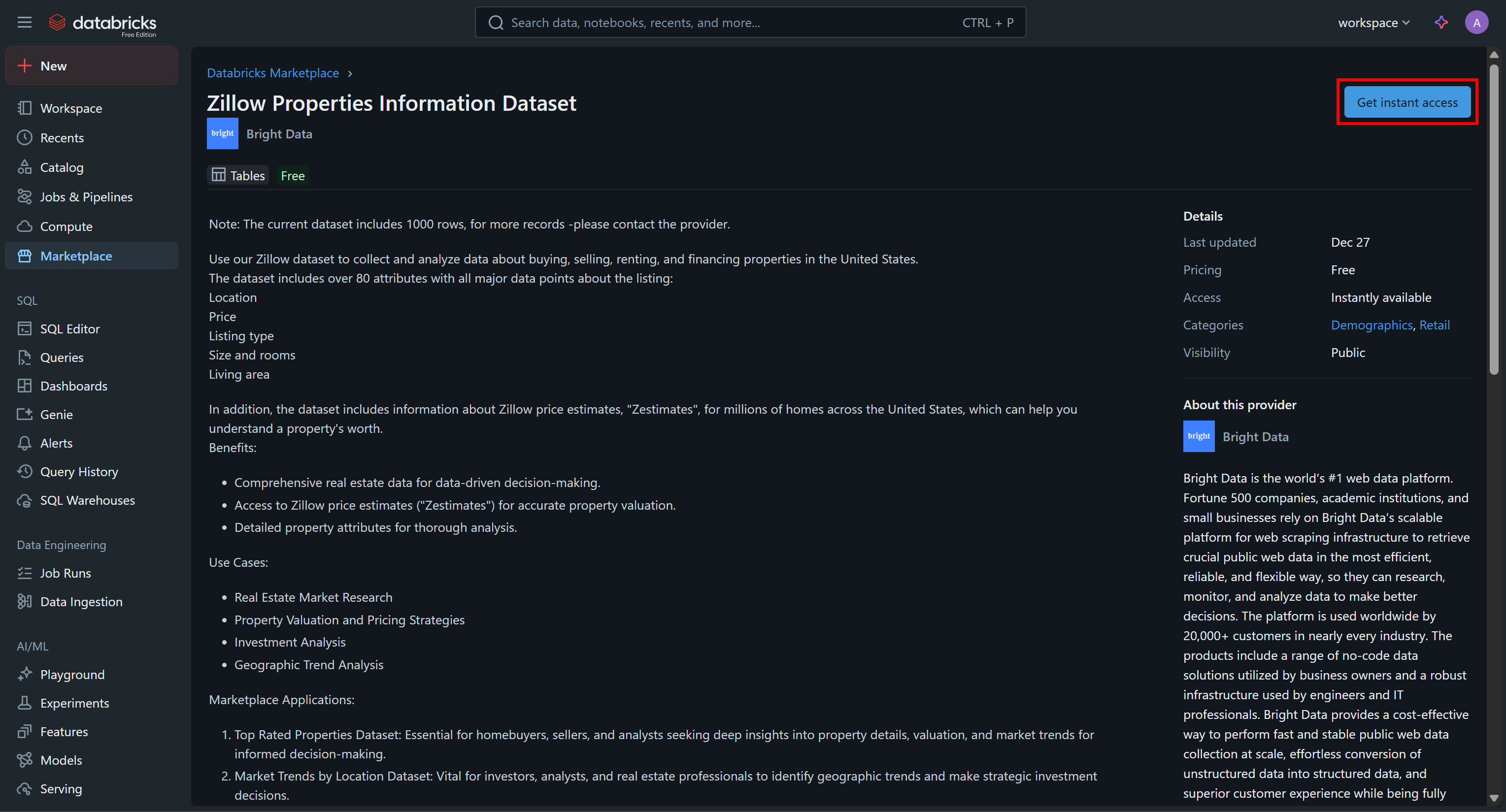
Der Datensatz wird Ihrem Konto hinzugefügt und Sie können ihn nun über Databricks SQL abfragen. Wenn Sie sich fragen, woher diese Daten stammen, lautet die Antwort: aus den Zillow-Datensätzen von Bright Data.
Überprüfen Sie dies, indem Sie die Seite „SQL Editor“ aufrufen und den Datensatz mit einer SQL-Abfrage wie dieser abfragen:
SELECT * FROM bright_data_zillow_properties_information_dataset.Datensätze.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;Das Ergebnis sollte in etwa so aussehen:
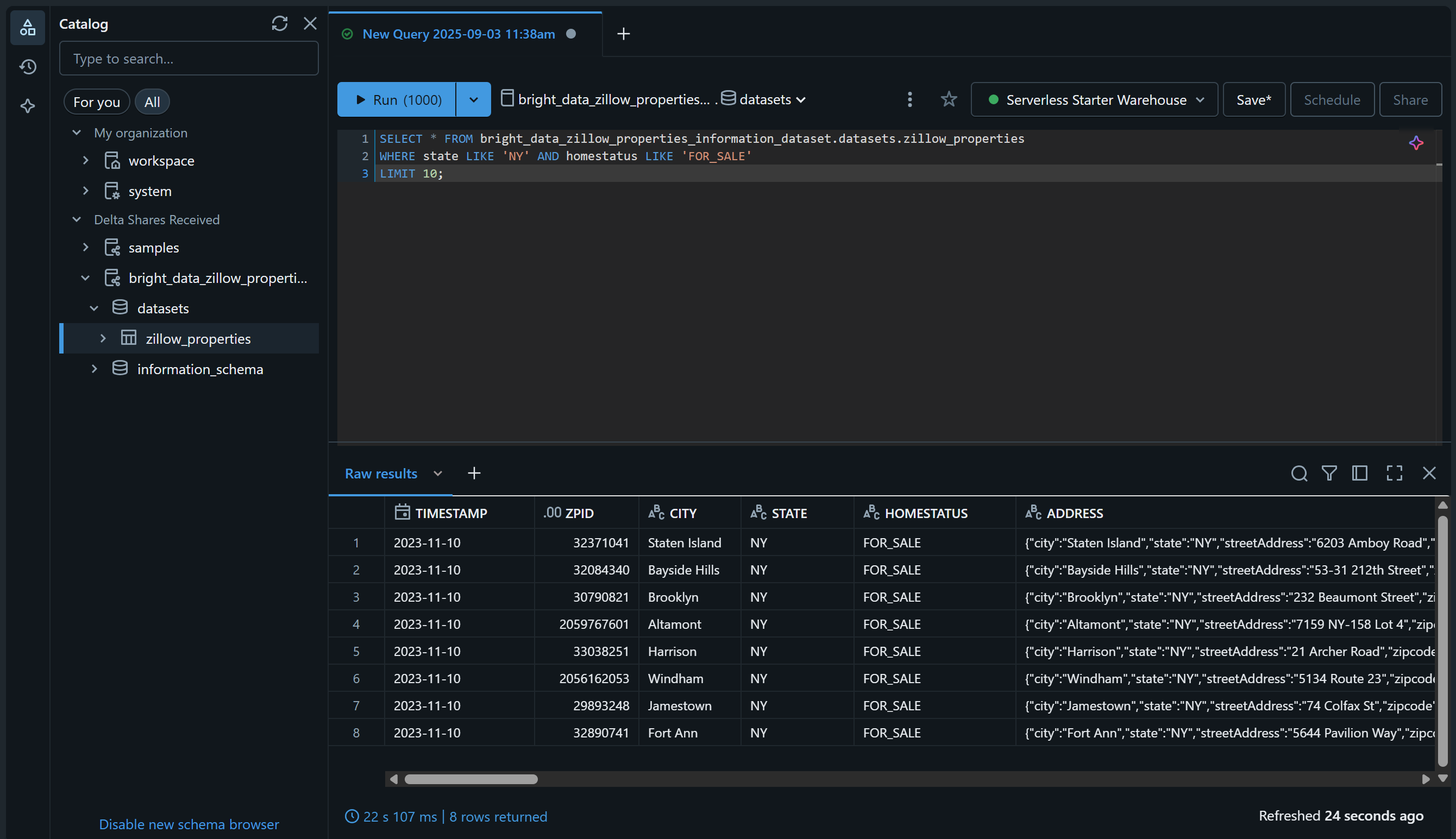
Großartig! Sie haben den ausgewählten Bright Data-Datensatz erfolgreich hinzugefügt und ihn über Databricks abfragbar gemacht. Sie können die gleichen Schritte ausführen, um weitere Bright Data-Datensätze hinzuzufügen.
In den nächsten Abschnitten erfahren Sie, wie Sie diesen Datensatz abfragen können:
- Über die Databricks-REST-API
- Mit dem Databricks SQL Connector für Python
- Über die Databricks-CLI
So fragen Sie einen Bright Data-Datensatz über die Databricks-REST-API ab
Databricks stellt einige seiner Funktionen über eine REST-API zur Verfügung, darunter die Möglichkeit, in Ihrem Konto verfügbare Datensätze abzufragen. Befolgen Sie die folgenden Schritte, um zu erfahren, wie Sie den von Bright Data bereitgestellten „Zillow Properties Information Dataset” programmgesteuert abfragen können.
Hinweis: Der folgende Code ist in Python geschrieben, kann jedoch leicht an andere Programmiersprachen angepasst oder direkt in Bash über cURL aufgerufen werden.
Schritt 1: Installieren Sie die erforderlichen Bibliotheken
Um SQL-Abfragen auf Remote-Databricks-Warehouses auszuführen, verwenden Sie die REST-API-Endpunkte /api/2.0/sql/statements. Sie können ihn über eine POST-Anfrage mit einem beliebigen HTTP-Client aufrufen. In diesem Beispiel verwenden wir die Python-Bibliothek „Requests”.
Installieren Sie sie mit:
pip install requestsImportieren Sie sie anschließend in Ihr Skript mit:
import requestsWeitere Informationen finden Sie in unserem speziellen Leitfaden zu Python Requests.
Schritt 2: Bereiten Sie Ihre Databricks-Anmeldedaten und -Geheimnisse vor
Um den Databricks-REST-API-Endpunkt /api/2.0/sql/statements mit einem HTTP-Client aufzurufen, müssen Sie Folgendes angeben:
- Ihr Databricks-Zugriffstoken: Zur Authentifizierung.
- Ihren Databricks-Host: Zum Erstellen der vollständigen API-URL.
- Ihre Databricks-Warehouse-ID: Um die richtige Tabelle im richtigen Warehouse abzufragen.
Fügen Sie die zuvor abgerufenen Geheimnisse wie folgt zu Ihrem Skript hinzu:
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"Tipp: Vermeiden Sie es in der Produktion, diese Geheimnisse fest in Ihrem Skript zu codieren. Speichern Sie diese Anmeldedaten stattdessen in Umgebungsvariablen und laden Sie sie mit python-dotenv, um die Sicherheit zu erhöhen.
Schritt 3: Aufruf der SQL-Anweisungsausführungs-API
Führen Sie einen POST-HTTP-Aufruf an den Endpunkt /api/2.0/sql/statements mit den entsprechenden Headern und dem entsprechenden Body unter Verwendung von Requests durch:
# Die parametrisierte SQL-Abfrage, die für den angegebenen Datensatz ausgeführt werden soll
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# Der Parameter zum Ausfüllen der SQL-Abfrage
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# POST-Anfrage erstellen und Datensatz abfragen
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Zur Authentifizierung in Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)Wie Sie sehen können, basiert der obige Ausschnitt auf einer vorbereiteten SQL-Anweisung. Wie in der Dokumentation betont, empfiehlt Databricks dringend die Verwendung parametrisierter Abfragen als Best Practice für Ihre SQL-Anweisungen.
Mit anderen Worten: Die Ausführung des obigen Skripts entspricht der Ausführung der folgenden Abfrage in der Tabelle „bright_data_zillow_properties_information_dataset.datasets.zillow_properties“, genau wie wir es zuvor getan haben:
SELECT * FROM bright_data_zillow_properties_information_dataset.Datensätze.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;Fantastisch! Jetzt müssen nur noch die Ausgabedaten verwaltet werden.
Schritt 4: Exportieren der Abfrageergebnisse
Verarbeiten Sie die Antwort und exportieren Sie die abgerufenen Daten mit dieser Python-Logik:
if response.status_code == 200:
# Zugriff auf die JSON-Ausgabedaten
result = response.json()
# Exportieren Sie die abgerufenen Daten in eine JSON-Datei
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Abfrage erfolgreich! Ergebnisse gespeichert in '{output_file}'")
else:
print(f"Fehler {response.status_code}: {response.text}")Wenn die Anfrage erfolgreich ist, erstellt der Snippet eine Datei namens zillow_properties.json, die die Abfrageergebnisse enthält.
Schritt 5: Alles zusammenfügen
Ihr endgültiges Skript sollte Folgendes enthalten:
import requests
import json
# Ihre Databricks-Anmeldedaten (ersetzen Sie diese durch die richtigen Werte)
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<IHR_DATABRICKS_HOST>"
# Die parametrisierte SQL-Abfrage, die für den angegebenen Datensatz ausgeführt werden soll
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.Datensätze.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# Der Parameter zum Ausfüllen der SQL-Abfrage
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# POST-Anfrage erstellen und Datensatz abfragen
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Zur Authentifizierung in Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# Behandeln der Antwort
if response.status_code == 200:
# Zugriff auf die ausgegebenen JSON-Daten
result = response.json()
# Exportieren der abgerufenen Daten in eine JSON-Datei
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Abfrage erfolgreich! Ergebnisse gespeichert in '{output_file}'")
else:
print(f"Fehler {response.status_code}: {response.text}")Führen Sie den Code aus, woraufhin eine Datei namens „zillow_properties.json” in Ihrem Projektverzeichnis erstellt werden sollte.
Die Ausgabe enthält zunächst die Spaltenstruktur, damit Sie die verfügbaren Spalten besser verstehen können. Anschließend sehen Sie im Feld „data_array” die resultierenden Abfragedaten als JSON-Zeichenfolge:
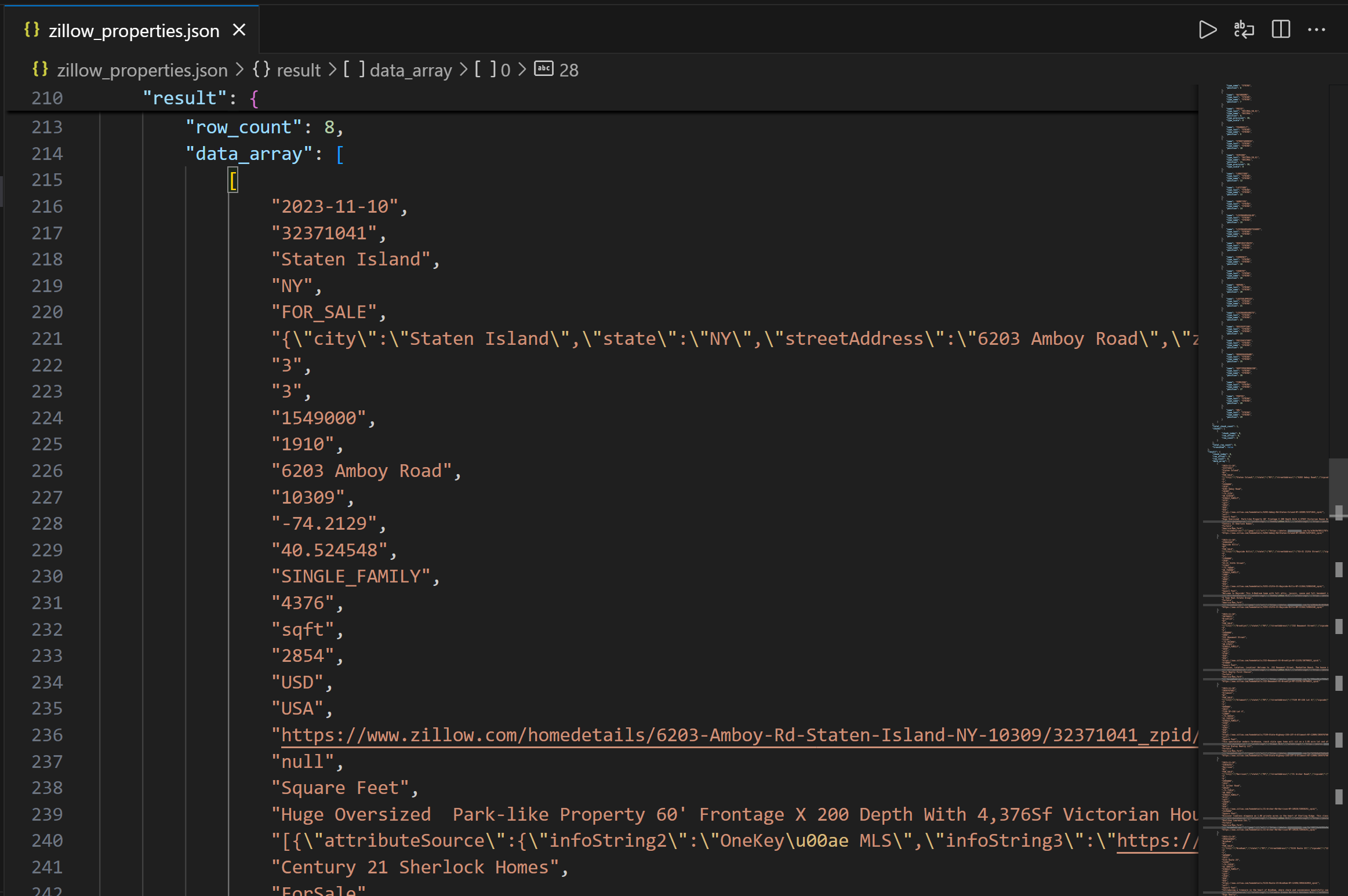
Mission erfüllt! Sie haben soeben Zillow-Immobiliendaten gesammelt, die von Bright Data über die Databricks-REST-API bereitgestellt wurden.
So greifen Sie mit der Databricks-CLI auf Bright Data-Datensätze zu
Mit Databricks können Sie auch Daten in einem Warehouse über die Databricks-CLI abfragen, die auf der REST-API basiert. Erfahren Sie, wie Sie sie verwenden!
Schritt 1: Installieren Sie die Databricks-CLI
Die Databricks-CLI ist ein Open-Source-Befehlszeilentool, mit dem Sie direkt von Ihrem Terminal aus mit der Databricks-Plattform interagieren können.
Befolgen Sie zur Installation die Installationsanleitung für Ihr Betriebssystem. Wenn alles korrekt eingerichtet ist, sollte die Ausführung des Befehls „databricks -v“ etwa folgende Ausgabe liefern:

Perfekt!
Schritt 2: Definieren Sie ein Konfigurationsprofil für die Authentifizierung
Verwenden Sie die Databricks-CLI, um ein Konfigurationsprofil mit dem Namen DEFAULT zu erstellen, das Sie mit Ihrem persönlichen Databricks-Zugriffstoken authentifiziert. Führen Sie dazu den folgenden Befehl aus:
databricks configure --profile DEFAULTSie werden dann aufgefordert, Folgendes anzugeben:
- Ihren Databricks-Host
- Ihr Databricks-Zugriffstoken
Fügen Sie beide Werte ein und drücken Sie die Eingabetaste, um die Konfiguration abzuschließen:

Sie können nun CLI -API -Befehle authentifizieren, indem Sie die Option --profile DEFAULT angeben.
Schritt 3: Abfrage Ihres Datensatzes
Verwenden Sie den folgenden CLI-Befehl, um eine parametrisierte Abfrage über den Befehl „api post“ auszuführen:
databricks API post "/api/2.0/sql/statements"
--profile DEFAULT
--json '{
"warehouse_id": "<YOUR_DATABRICKS_WAREHOUSE_ID>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataset.Datensätze.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
"parameters": [
{ "name": "state", "value": "NY", "type": "STRING" },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}'
> zillow_properties.jsonErsetzen Sie den Platzhalter <YOUR_DATABRICKS_WAREHOUSE_ID> durch die tatsächliche ID Ihres Databricks SQL-Warehouses.
Im Hintergrund wird damit dasselbe erreicht wie zuvor in Python. Genauer gesagt wird eine POST-Anfrage an die Databricks REST SQL API gestellt. Das Ergebnis ist eine Datei zillow_properties.json, die dieselben Daten wie zuvor enthält:
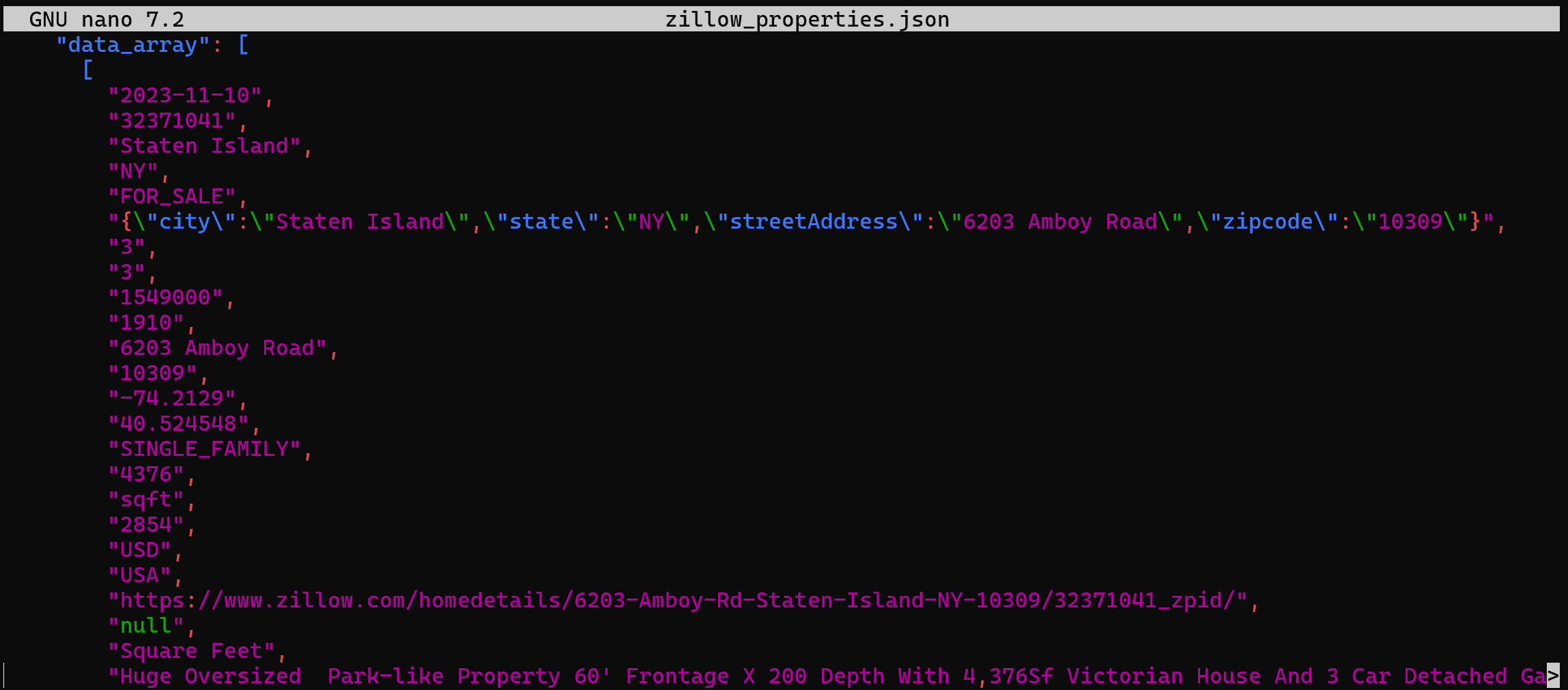
So fragen Sie einen Datensatz aus Bright Data über den Databricks SQL Connector ab
Der Databricks SQL Connector ist eine Python-Bibliothek, mit der Sie eine Verbindung zu Databricks-Clustern und SQL-Warehouses herstellen können. Insbesondere bietet er eine vereinfachte API für die Verbindung mit der Databricks-Infrastruktur und die Untersuchung Ihrer Daten.
In diesem Abschnitt des Leitfadens erfahren Sie, wie Sie damit den „Zillow Properties Information Datensatz” von Bright Data abfragen können.
Schritt 1: Installieren Sie den Databricks SQL Connector für Python
Der Databricks SQL Connector ist über die Python-Bibliothek databricks-sql-connector verfügbar. Installieren Sie ihn mit:
pip install databricks-sql-connectorImportieren Sie ihn anschließend in Ihr Skript mit:
from databricks import sqlSchritt 2: Erste Schritte mit dem Databricks SQL Connector
Der Databricks SQL Connector erfordert andere Anmeldedaten als die REST-API und die CLI. Im Einzelnen benötigt er:
server_hostname: Ihren Databricks-Hostnamen (ohne den Teil„https://“).http_path: Eine spezielle URL für die Verbindung zu Ihrem Warehouse.access_token: Ihr Databricks-Zugriffstoken.
Die erforderlichen Authentifizierungswerte sowie ein Beispiel-Starter-Snippet finden Sie auf der Registerkarte „Verbindungsdetails“ Ihres SQL-Warehouses:
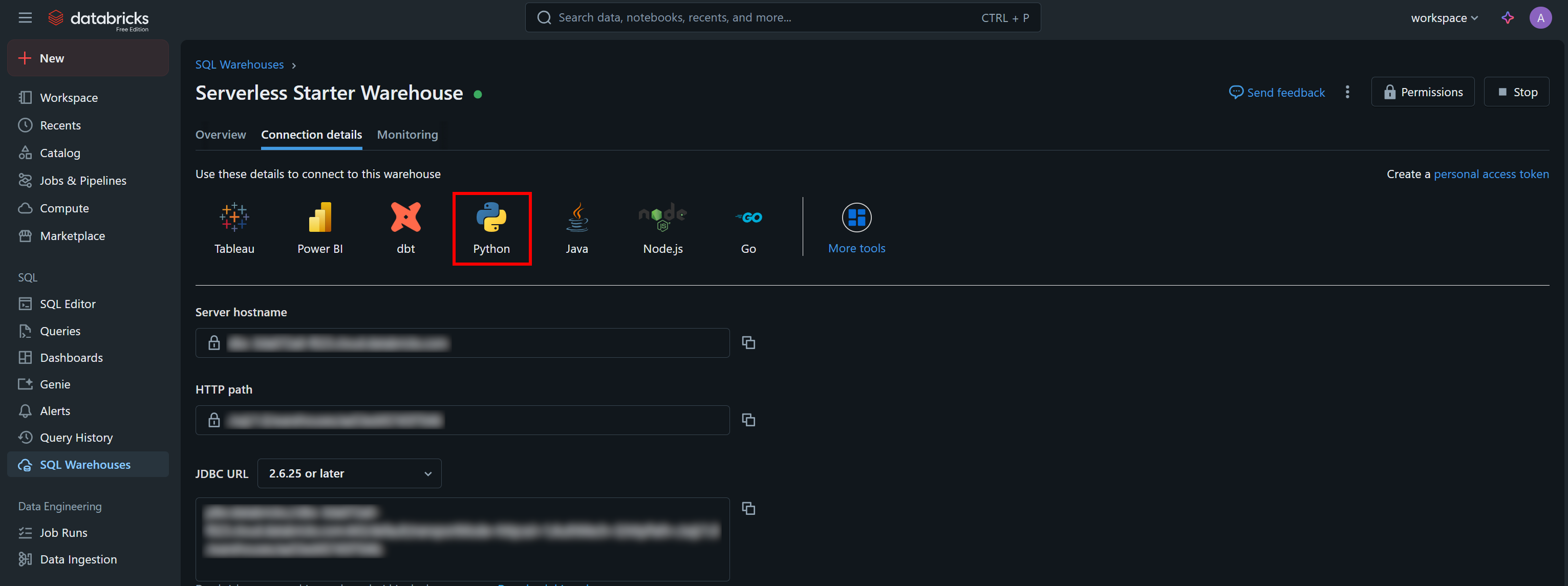
Klicken Sie auf die Schaltfläche „Python“, um Folgendes anzuzeigen:
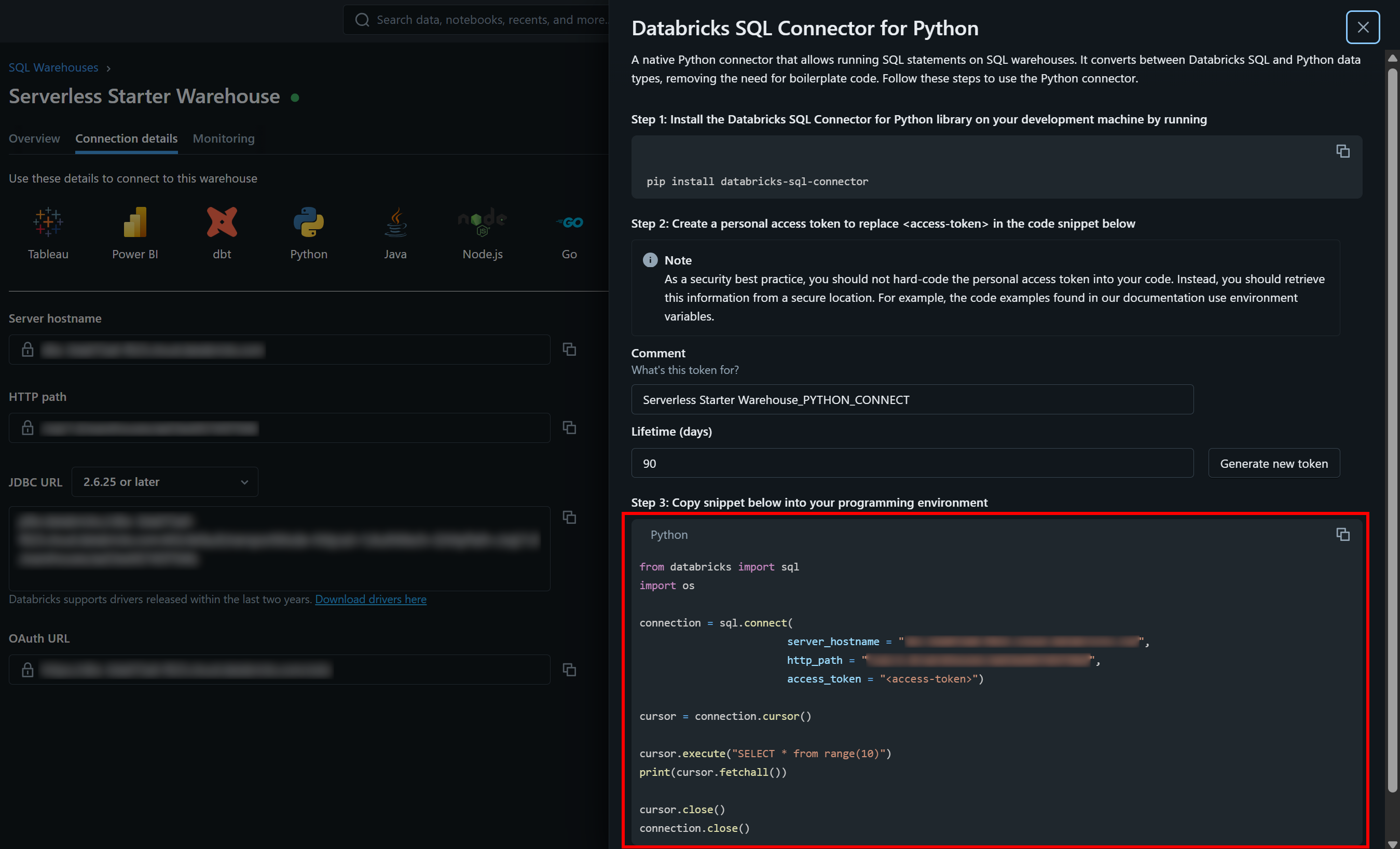
Das sind alle Anweisungen, die Sie benötigen, um mit dem databricks-sql-connector zu beginnen.
Schritt 3: Alles zusammenfügen
Passen Sie den Code aus dem Beispiel-Snippet im Abschnitt „Databricks SQL Connector für Python“ an Ihr Warehouse an, um die gewünschte parametrisierte Abfrage auszuführen. Am Ende sollten Sie ein Skript wie das folgende erhalten:
from databricks import sql
# Verbinden Sie sich mit Ihrem SQL-Warehouse in Databricks (ersetzen Sie die Anmeldedaten durch Ihre Werte)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUST_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# Führen Sie die parametrisierte SQL-Abfrage aus und rufen Sie die Ergebnisse in einem Cursor ab.
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.Datensätze.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# Führen Sie die Abfrage aus.
cursor.execute(sql_query, params)
result = cursor.fetchall()
# Drucken Sie alle Ergebnisse zeilenweise aus.
for row in result[:2]:
print(row)
# Schließen Sie den Cursor und die SQL-Warehouse-Verbindung.
cursor.close()
connection.close()Führen Sie das Skript aus, um eine Ausgabe wie die folgende zu erhalten:
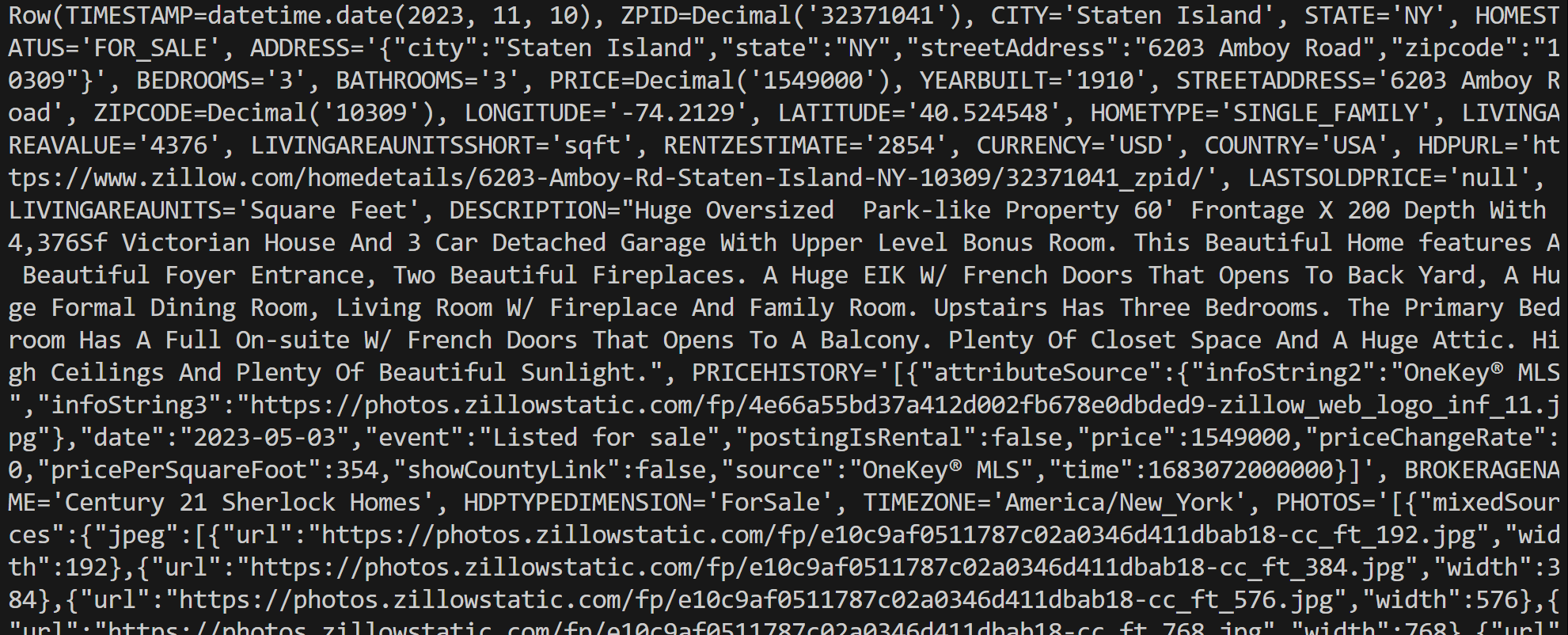
Beachten Sie, dass jedes Zeilenobjekt eine Row-Instanz ist, die einen einzelnen Datensatz aus den Abfrageergebnissen darstellt. Sie können diese Daten dann direkt in Ihrem Python-Skript verarbeiten.
Beachten Sie, dass Sie eine Row- Instanz mit der Methode asDict() in ein Python-Wörterbuch konvertieren können:
row_data = row.asDict()Et voilà! Jetzt wissen Sie, wie Sie Ihre Bright Data-Datensätze in Databricks auf verschiedene Weise abfragen und mit ihnen interagieren können.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie die Datensätze von Bright Data aus Databricks mithilfe der REST-API, der CLI oder der dedizierten SQL-Connector-Bibliothek abfragen können. Wie gezeigt, bietet Databricks mehrere Möglichkeiten zur Interaktion mit den Produkten seiner Datenanbieter, zu denen nun auch Bright Data gehört.
Mit über 40 verfügbaren Produkten können Sie die umfangreiche Vielfalt der Datensätze von Bright Data direkt in Databricks erkunden und auf verschiedene Weise auf deren Daten zugreifen.
Erstellen Sie kostenlos ein Bright Data-Konto und probieren Sie noch heute unsere Datenlösungen aus!




