

In diesem Blogbeitrag erfahren Sie:
- Was Datensätze sind, welche Vorteile sie bieten, wie sie funktionieren, wann ihr Einsatz sinnvoll ist und wo Sie hochwertige, zuverlässige Datensätze finden.
- Was Web-Scraping-APIs sind, welche Vorteile sie bieten, wie sie funktionieren, wann man sie nutzen sollte und wo man skalierbare findet.
- Wie beide in ähnlichen Szenarien anhand von geführten Beispielen eingesetzt werden können.
- Wie Datensätze und Web-Scraping-APIs im Vergleich abschneiden und welche Option je nach Ihren Anforderungen besser geeignet ist.
- Ob es sinnvoll ist, beide gemeinsam zu verwenden.
Legen wir los!
Die Welt der Datensätze erkunden
Wir beginnen diesen Leitfaden zu Datensätzen vs. Web-Scraping-APIs mit einer Einführung in Datensätze.
Was ist ein Datensatz?
Ein Datensatz ist eine strukturierte Sammlung von Informationen, die für eine einfache Analyse, Verarbeitung und Wiederverwendung organisiert ist. Sie werden typischerweise in Formaten wie CSV, JSON oder SQL gespeichert und können Texte, Zahlen, Bilder, Videos und andere Datentypen enthalten.
Die meisten Datensätze konzentrieren sich auf ein bestimmtes Thema, eine Branche, einen Markt oder ein Interessengebiet, wie etwa B2B, Einzelhandel und andere. Dieser engere Fokus hilft Unternehmen und Forschern, Erkenntnisse zu gewinnen, Trends zu erkennen und datengestützte Entscheidungen zu treffen.
Datensätze gelten im Allgemeinen als statische Momentaufnahmen von Daten, die zu einem bestimmten Zeitpunkt erfasst wurden. Die meisten der besten Datensatzanbieter bieten jedoch Dienste an, um regelmäßig aktualisierte Datensätze zu erhalten, indem sie aktuelle Informationen aus den zugrunde liegenden Datenquellen abrufen.
Die drei wesentlichen Vorteile von Datensätzen sind:
- Sofort einsatzbereit: Vorgesammelte und strukturierte Daten, sofort nutzbar für Analysen, KI oder Geschäftsanwendungen. Kein technisches Wissen erforderlich.
- Kosteneffizienz: Reduziert den Bedarf an internen Datenerhebungs- und Engineering-Ressourcen.
- Skalierbarkeit: Bietet Zugang zu großen Datensätzen mit Millionen oder Milliarden von Datensätzen aus verschiedenen Branchen.
Wie Datensätze funktionieren
Die meisten modernen Datensätze stammen aus dem Web, der größten und aktuellsten Quelle öffentlicher Informationen der Welt. Schließlich werden kontinuierlich neue Daten auf Websites, Marktplätzen und Social-Media-Plattformen generiert.
Der Prozess der Datensatzerstellung umfasst folgende Schritte:
- Datenerhebung: Informationen werden aus einer oder mehreren Quellen gesammelt, am häufigsten von Websites über Web-Scraping, APIs oder öffentliche Feeds. Je nach Anwendungsfall kann dies Produktlisten, Preise, Bewertungen, Stellenangebote, Social-Media-Inhalte oder Unternehmensdaten umfassen.
- Datenbereinigung und -validierung: Rohdaten sind oft unübersichtlich, unvollständig oder doppelt vorhanden. In diesem Schritt werden Fehler beseitigt, Formate standardisiert und fehlende Werte behandelt. Die Daten werden validiert, um Genauigkeit und Konsistenz sicherzustellen.
- Datenstrukturierung: Die bereinigten Daten werden in einem einheitlichen Format wie CSV, JSON oder Parquet organisiert. Dies erleichtert die Speicherung in Datenbanken oder Data Warehouses für Abfragen sowie die Nutzung in Datenanalyse- oder KI-Workflows.
Obwohl diese Schritte technisch intern durchgeführt werden können, werden sie in der Regel an einen Datensatzanbieter delegiert. Dies liegt daran, dass das Sammeln und Verarbeiten von Daten im großen Maßstab spezialisierte Werkzeuge und Fachkenntnisse erfordert. Bedenken Sie, dass einige Datensätze mehrere Milliarden Datensätze umfassen können.
Nach der Verarbeitung verteilen Datensatzanbieter die Daten über verschiedene Liefermethoden. Dazu gehören direkte Downloads für kleinere Datensätze, S3-Integrationen und API-basierter Zugriff.
Hinweis: Nicht alle Datensätze stammen aus dem Web. Einige werden durch Umfragen, Forschungsstudien, Sensoren, interne Unternehmenssysteme oder durch die Kombination mehrerer Quellen erstellt. Sie können beispielsweise öffentliche Open-Data-Quellen mit proprietären oder privat erhobenen Informationen kombinieren.
Anwendungsfälle
Im Folgenden sind einige der relevantesten Szenarien für Datensätze in Unternehmen, kleinen Betrieben, bei Einzelpersonen und im öffentlichen Sektor aufgeführt:
- KI-Modelltraining: Datensätze stehen im Mittelpunkt von Machine-Learning- und KI-Trainingsprozessen. Durch die Einspeisung großer Mengen hochwertiger Daten in Modelle lernen diese Muster und entwickeln Fähigkeiten wie Sprachverständnis, Bilderkennung, Empfehlungen und Prognosen.
- Markttrend-Analyse: Analysieren Sie historische Marktdaten, um Branchentrends zu untersuchen und das Kundenverhalten zu verstehen. Validieren Sie Produktideen und unterstützen Sie strategische Entscheidungen auf Basis realer externer Daten statt Annahmen.
- Social-Media-Analyse: Gewinnen Sie Erkenntnisse über Nutzerverhalten, Engagement und Stimmung. Überwachen Sie Marken, analysieren Sie Zielgruppen, identifizieren Sie Influencer und bewerten Sie die Content-Performance auf Plattformen wie Reddit, Facebook und anderen.
- Business Intelligence und Entscheidungsfindung: Untersuchen Sie Preise, Wettbewerber und Marktsignale, um Chancen zu erkennen, die Ressourcenallokation zu optimieren und die strategische Entscheidungsfindung zu verbessern.
- Recruiting und Talent Intelligence: Analysieren Sie Arbeitsmarktdaten, um Kandidaten zu finden, Einstellungstrends zu verstehen, die Nachfrage nach Fähigkeiten zu bewerten und Belegschaftsstrukturen von Wettbewerbern zu kartieren, um Recruiting-Strategien zu verbessern.
- Produktentwicklung und Optimierung der Nutzererfahrung: Analysieren Sie Nutzerbewertungen, Feedback und Verhaltensdaten, um Produkte zu verbessern. Verfeinern Sie Funktionen, personalisieren Sie Erlebnisse und optimieren Sie User Journeys, um Zufriedenheit und Bindung zu steigern.
Wo Sie aktualisierte, strukturierte, KI-bereite Datensätze erhalten
Unter den führenden Datensatz-Marktplätzen belegt Bright Data den ersten Platz, da es eine groß angelegte Web-
Dateninfrastruktur mit sofort einsetzbaren, businesstauglichen Datensätzen kombiniert.
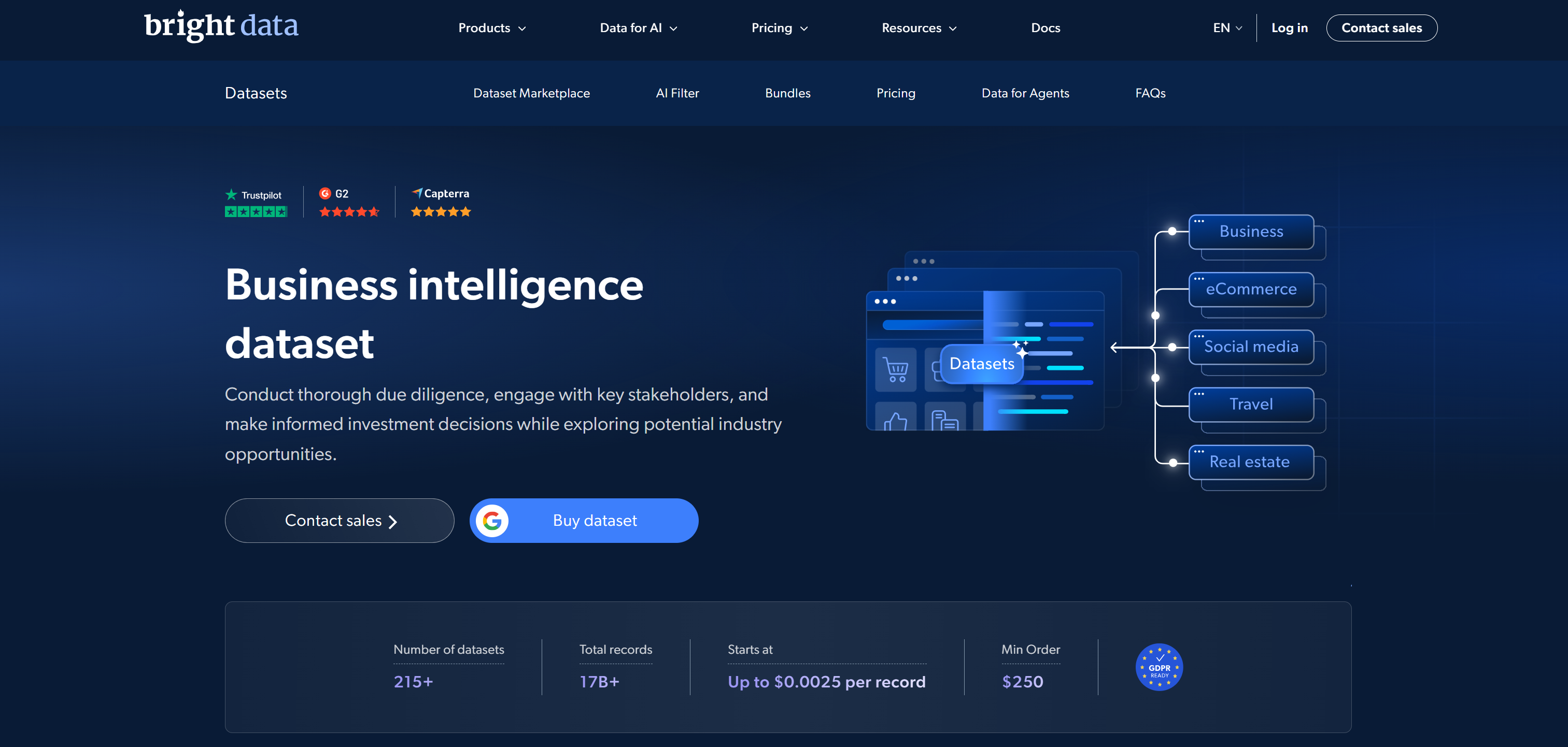
Der Datensatz-Marktplatz bietet vorgesammelte Datensätze aus über 350 Web-Domains mit insgesamt mehr als 17 Milliarden Datensätzen. Diese umfassen E-Commerce, Social Media, Immobilien, Finanzen, professionelle Netzwerke und viele weitere Branchen. Die Datensätze sind bereinigt, strukturiert, standardisiert und für KI und ML optimiert. Sie werden in Formaten wie JSON, CSV, Parquet und NDJSON geliefert.
Bright Datas Datensätze können auch angepasst werden, um hochspezifische Ziele zu erfüllen, indem sie nach mehreren Dimensionen gefiltert werden, einschließlich Kriterien für Datenfelder. Eine zusätzliche KI-gestützte Filterfunktion ermöglicht es Nutzern, große Datensätze mithilfe von Abfragen in natürlicher Sprache zu verfeinern, was die Datenauswahl zugänglicher macht.
Die Daten werden über mehrere Kanäle geliefert, darunter API-Zugriff, Amazon S3, Snowflake, Webhooks, Cloud-Storage-Integrationen und direkte Downloads. Diese Flexibilität macht es sowohl für leichtgewichtige Anwendungsfälle als auch für unternehmensweite Pipelines geeignet.
Bright Data-Datensätze entsprechen den GDPR- und CCPA-Konformitätsstandards. Sie werden zudem durch Validierungs-, Sicherheits- und Qualitätskontrollprozesse unterstützt, die Zuverlässigkeit und ethische Beschaffung öffentlich verfügbarer Daten gewährleisten.
Die Preise beginnen bei 250 $ pro Datensatz (100.000 Datensätze), abhängig von Volumen und Aktualisierungshäufigkeit (monatlich, vierteljährlich oder halbjährlich).
Ein Überblick über Web-Scraping-APIs
Nachdem Sie nun wissen, was Datensätze sind und wann Sie diese einsetzen sollten, sind Sie bereit, dieselben Aspekte bei Web-Scraping-APIs zu erkunden.
Was ist eine Web-Scraping-API?
Eine Web-Scraping-API ist ein Dienst, der es Ihnen ermöglicht, Daten von Websites zu extrahieren, ohne eine eigene Scraping-Infrastruktur zu verwalten. Sie übernimmt Aufgaben wie das Abrufen von Zielwebseiten, das Umgehen von Anti-Scraping- und Anti-Bot-Schutzmechanismen sowie das Parsing der Ergebnisse in strukturierte Formate.
Web-Scraping-APIs zielen in der Regel auf bestimmte Websites oder Datenquellen ab, wie E-Commerce-Plattformen, Suchmaschinen oder Social-Media-Seiten. Einige sind allgemeiner gehalten oder können per KI erweitert werden, um strukturierte Daten von beliebigen Websites zurückzugeben. Dies ermöglicht es Unternehmen und Entwicklern, Live- oder On-Demand-Daten aus relevanten Online-Quellen abzurufen.
Die drei wesentlichen Vorteile von Web-Scraping-APIs sind:
- Echtzeit-Datenzugriff: Rufen Sie bei Bedarf aktuelle Informationen direkt von Websites ab.
- Kein Infrastrukturmanagement: Kein Aufbau und keine Wartung von Scrapern, Proxys und Anti-Bot-Systemen erforderlich.
- Skalierbarkeit: Sammeln Sie zuverlässig und effizient Daten von Hunderten oder Tausenden von Seiten.
Wie Web-Scraping-APIs funktionieren
Technisch gesehen funktioniert eine Web-Scraping-API folgendermaßen:
- Anfragenverarbeitung: Ein Nutzer sendet eine Anfrage an die API mit der URL der Zielwebseite sowie optionalen Argumenten zur Anpassung des zugrunde liegenden Scraping-Verhaltens (z. B. JavaScript-Rendering, IP-Standort usw.).
- Seitenabruf und Zugriffsmanagement: Die API ruft die Zielwebseiten ab und kümmert sich dabei um technische Herausforderungen wie JavaScript-Rendering, Proxys, Rate Limits, CAPTCHAs und andere Anti-Bot-Schutzmechanismen.
- Datenextraktion und Parsing: Der rohe HTML-Code oder Antwortinhalt wird verarbeitet und in strukturierte Formate umgewandelt (z. B. JSON, CSV und andere). Einige APIs verwenden vordefinierte Vorlagen, während andere KI nutzen, um strukturierte Felder dynamisch aus beliebigen Webseiten zu extrahieren.
- Datenlieferung: Die endgültigen strukturierten Daten werden dem Nutzer über die API-Antwort zurückgegeben. Optional können sie auch in Speichersysteme wie S3, Webhooks oder Datenbanken zur weiteren Verarbeitung übertragen werden.
Anwendungsfälle
Hier sind die wichtigsten Szenarien, in denen Web-Scraping-APIs einen Unterschied machen:
- Marktforschung und Wettbewerbsbeobachtung: Überwachen Sie Websites von Wettbewerbern, Preisänderungen und Produktverfügbarkeit. Erkennen Sie Trends frühzeitig und passen Sie Geschäftsstrategien auf Basis sich ständig verändernder Marktsignale an.
- Finanzielle Entscheidungsfindung: Extrahieren Sie Live-Marktdaten wie Aktienkurse, Kryptobewegungen und Unternehmensnachrichten. Unterstützen Sie Handelsstrategien, Anlageanalysen und Risikomanagement durch kontinuierliche Echtzeit-Updates.
- E-Commerce-Monitoring und Preisoptimierung: Verfolgen Sie Produktlisten, Lagerbestände und Preisschwankungen auf mehreren Plattformen. Ermöglichen Sie dynamische Preisgestaltung, Angebotsfindung und Katalogoptimierung mit häufig aktualisierten Web-Daten.
- Nachrichten- und Ereignisüberwachung: Sammeln Sie aktuelle Nachrichten, regulatorische Updates und Branchenankündigungen aus mehreren Quellen. Verbessern Sie die Situationswahrnehmung und reagieren Sie schneller auf Markt- oder Politikänderungen.
- Lead-Generierung und Sales Intelligence: Extrahieren Sie aktuelle Unternehmens- und Kontaktdaten aus Verzeichnissen, Firmenwebsites und professionellen Plattformen. Identifizieren Sie neue Interessenten und reichern Sie Vertriebspipelines mit kontinuierlich aktualisierten Informationen an.
- Markenüberwachung und Reputationsverfolgung: Beobachten Sie Erwähnungen in KI-Chatbots und Suchmaschinen. Verfolgen Sie Stimmungen aus Bewertungen und Diskussionen in Foren, Social Media und Nachrichtenseiten. Erkennen Sie Stimmungsänderungen frühzeitig und reagieren Sie prompt auf Reputationsrisiken oder -chancen.
- KI-Agent-Grundierung und Web-Zugriff: Statten Sie KI-Agenten mit direktem Zugriff auf Web-Scraping-APIs aus, um auf Abruf kontextuelle, aktuelle externe Daten abzurufen. Dies ermöglicht fundiertes Reasoning, reduziert Halluzinationen und erlaubt Agenten, auf Basis der neuesten online verfügbaren Informationen zu handeln.
Web-Scraping-APIs: Welcher ist der beste Anbieter?
Bright Data erweist sich als bester Anbieter von Web-Scraping-APIs. Es kombiniert groß angelegte Proxy-Netzwerke mit einem umfassenden Web Scraper API-Ökosystem, das für zuverlässige, konforme und skalierbare Datenextraktion entwickelt wurde.
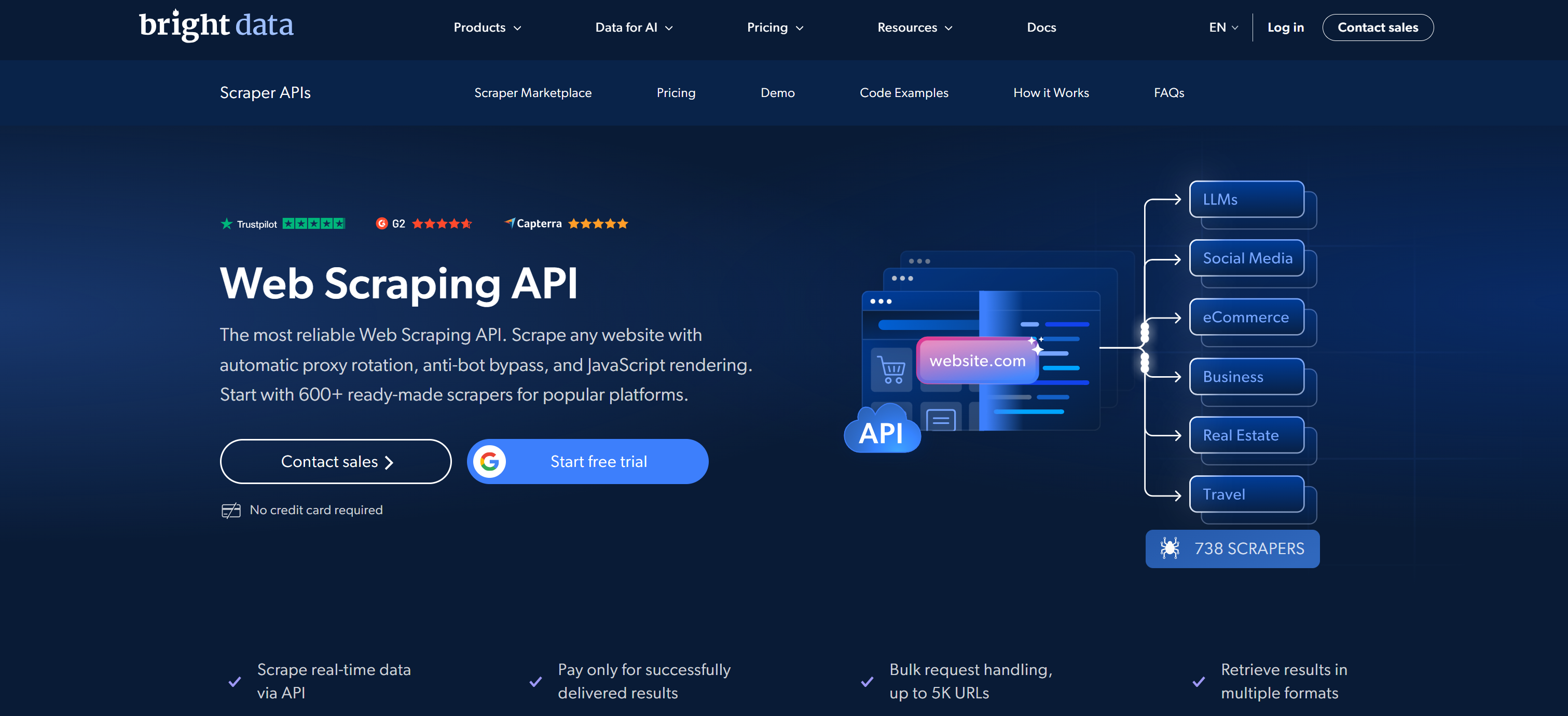
Die Web Scraper API-Bibliothek unterstützt über 600 vorgefertigte Scraper für wichtige Datenquellen. Dazu gehören Amazon, LinkedIn, X/Twitter, Instagram, TikTok, YouTube, Walmart, Zillow, Indeed, Glassdoor, Booking, Airbnb, Yelp, Yahoo Finance, Facebook und viele mehr. Diese Scraping-APIs ermöglichen die direkte Extraktion strukturierter, domänenspezifischer Daten in JSON, NDJSON oder CSV.
Was Bright Data auszeichnet, ist sein zugrunde liegendes globales Netzwerk von über 400 Millionen Residential-IPs in 195 Ländern. Dies ermöglicht eine groß angelegte, unternehmenstaugliche Architektur mit SLA-gesicherter 99,99 % Verfügbarkeit und einer Anfrageerfolgsrate von 99,95 %.
Bright Datas Web Scraper API verwaltet den gesamten Scraping-Lebenszyklus automatisch, einschließlich Proxy-Rotation, CAPTCHA-Lösung, JavaScript-Rendering, Rate Limiting und Anti-Bot-Umgehung. Sie unterstützen auch Massenanfragen (bis zu 5.000 URLs pro Job), geplantes Scraping und flexible Lieferpipelines.
Die Preisgestaltung ist nutzungsbasiert, und Sie zahlen nur für erfolgreiche Anfragen. Das Pay-per-use-Modell beginnt bei 1,50 $ pro 1.000 Datensätze, mit verschiedenen abonnementbasierten Plänen für Unternehmen und Konzerne.
Datensätze und Web-Scraping-APIs in einem realen Szenario
Um zu verstehen, wie Daten mithilfe von Datensätzen oder Web-Scraping-APIs abgerufen werden, betrachten Sie denselben übergeordneten Anwendungsfall. Sie möchten Unternehmensdaten von Crunchbase extrahieren, einmal für die Kundenakquise und einmal für eine KI-gestützte Live-Unternehmensanalyse.
Der erste Anwendungsfall erfordert einen Crunchbase-Datensatz, während der zweite eine Crunchbase-Web-Scraping-API benötigt. In den nächsten zwei Kapiteln sehen Sie, wie Sie mit Bright Datas Lösungen auf beide Datentypen zugreifen können.
Hinweis: Voraussetzung für die geführten Abschnitte unten ist, dass Sie bereits ein Bright Data-Konto haben. Andernfalls erstellen Sie ein neues Konto.
Erste Schritte mit Bright Datas Datensätzen
In diesem schrittweisen Abschnitt erfahren Sie, wie Sie einen schlüsselfertigen Crunchbase-Datensatz von Bright Data abrufen.
Schritt #1: Zugriff auf den Crunchbase-Datensatz
Beginnen Sie damit, sich in Ihrem Bright Data-Konto anzumelden. Wählen Sie im Kontrollpanel die Option ‘Dataset Marketplace’ unter dem Menü ‘Datasets’.
Navigieren Sie auf der Seite ‘My datasets’ zum Tab ‘Dataset Marketplace’, und Sie gelangen zu dieser Seite:
Suchen Sie nach ‘crunchbase’ und wählen Sie den Datensatz ‘Crunchbase companies information’:
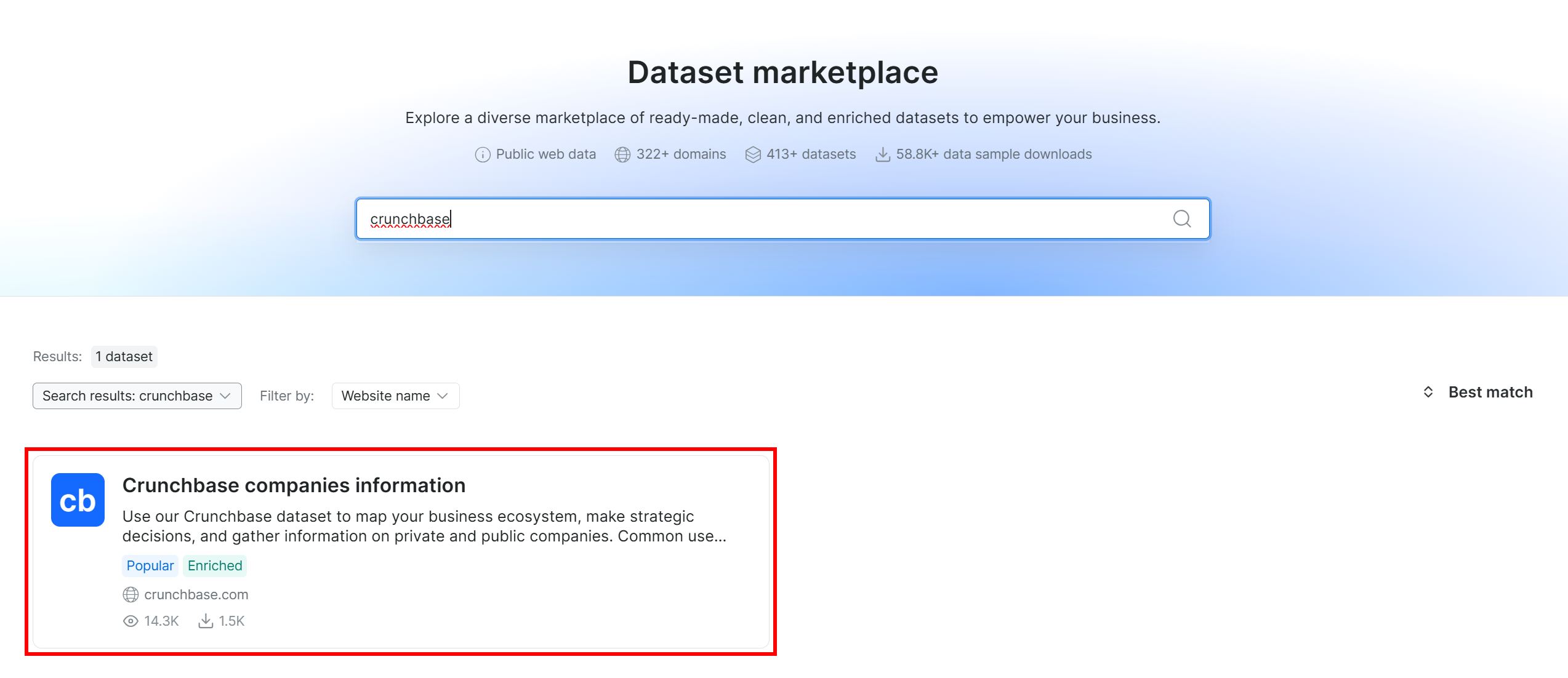
Sie werden dann zur Seite des Datensatzes ‘Crunchbase companies information’ weitergeleitet. Großartig!
Schritt #2: Den Datensatz kennenlernen
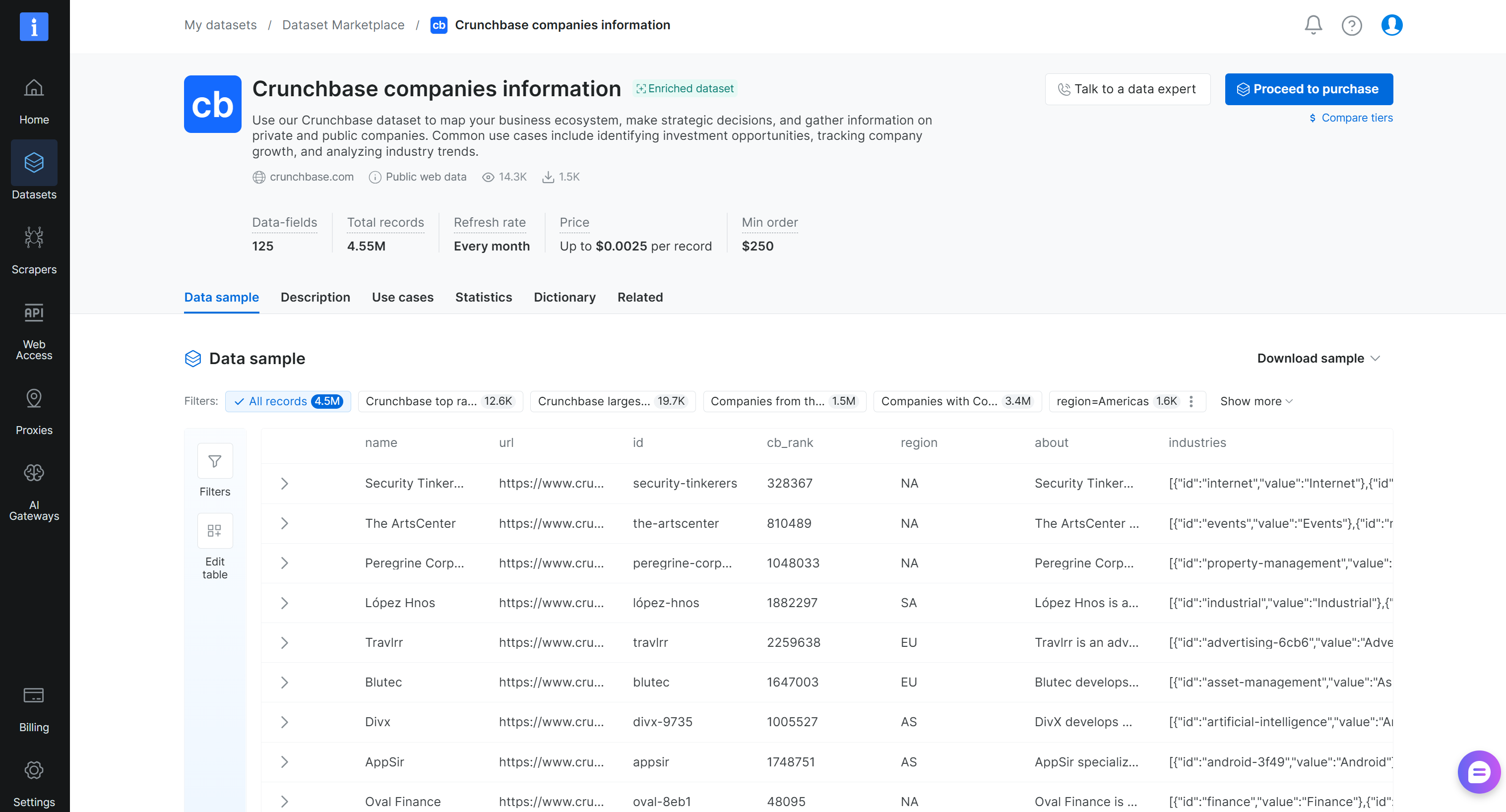
Auf der Seite des Datensatzes ‘Crunchbase companies information’ können Sie den Datensatz erkunden. Im Detail können Sie Musterdatensätze einsehen, vorgefertigte Teilmengen durchsuchen (zum Beispiel die am besten bewerteten Crunchbase-Unternehmen) und wichtige Statistiken wie Feldfüllraten überprüfen. Sie können auch das vollständige Datenwörterbuch mit Feldnamen, Typen und Beschreibungen einsehen und Filter anwenden, um den Datensatz zu verfeinern.
Wenn Sie auf die Schaltfläche ‘Filters’ auf der linken Seite klicken, öffnet sich folgendes Modal:
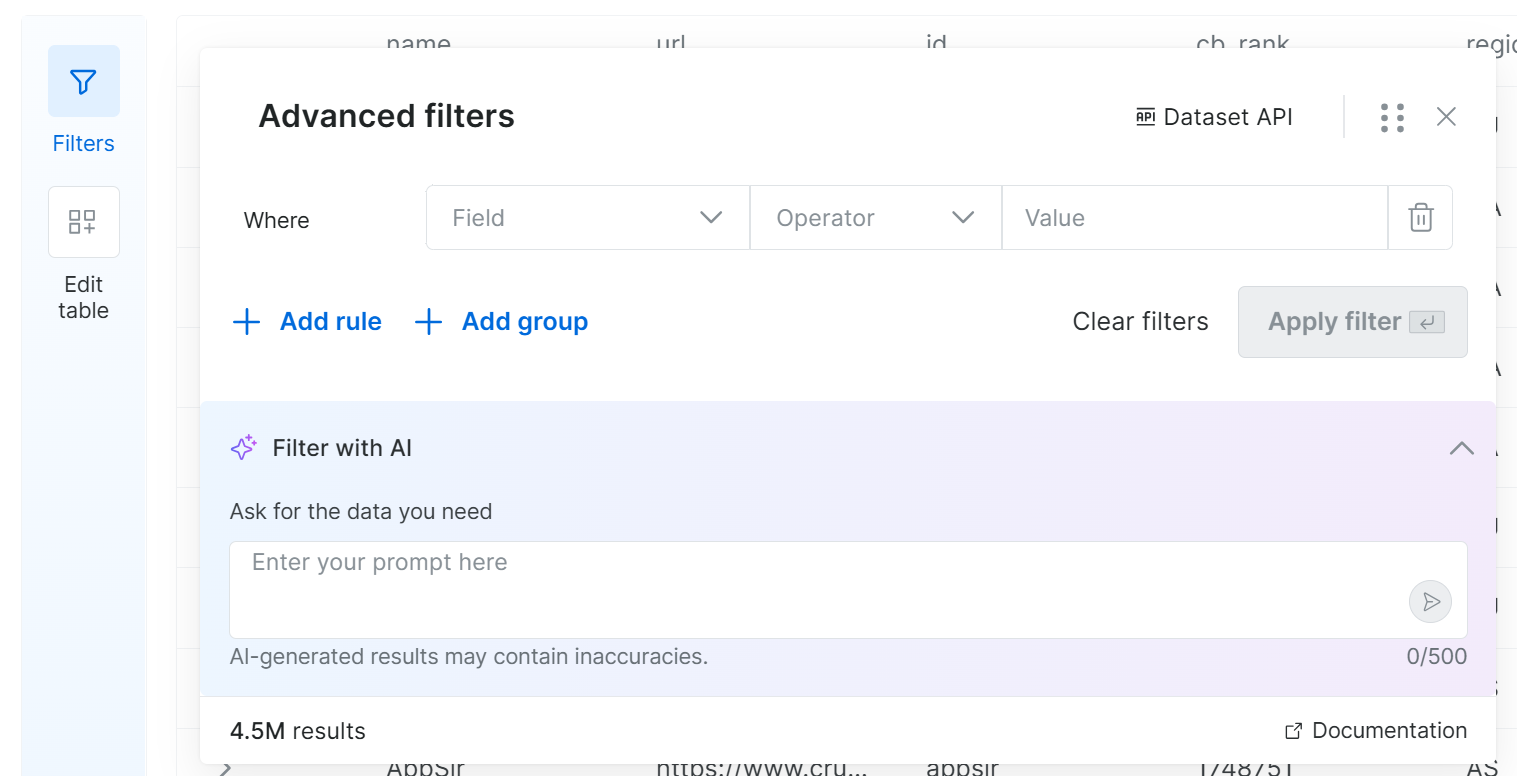
Dank dieser Funktion können Sie Filter definieren, indem Sie ein oder mehrere Kriterien für ausgewählte Felder festlegen. Alternativ schreiben Sie einfach eine Anfrage in natürlicher Sprache und lassen das System die Filter für Sie generieren. Fantastisch!
Schritt #3: Den Datensatz kaufen
Nachdem Sie die Daten für Ihren spezifischen Anwendungsfall gefiltert haben (oder sie unverändert gelassen haben), klicken Sie auf die Schaltfläche ‘Proceed to purchase’:

Definieren Sie anschließend die Größe des Datensatz-Snapshots und wählen Sie die Aktualisierungshäufigkeit:
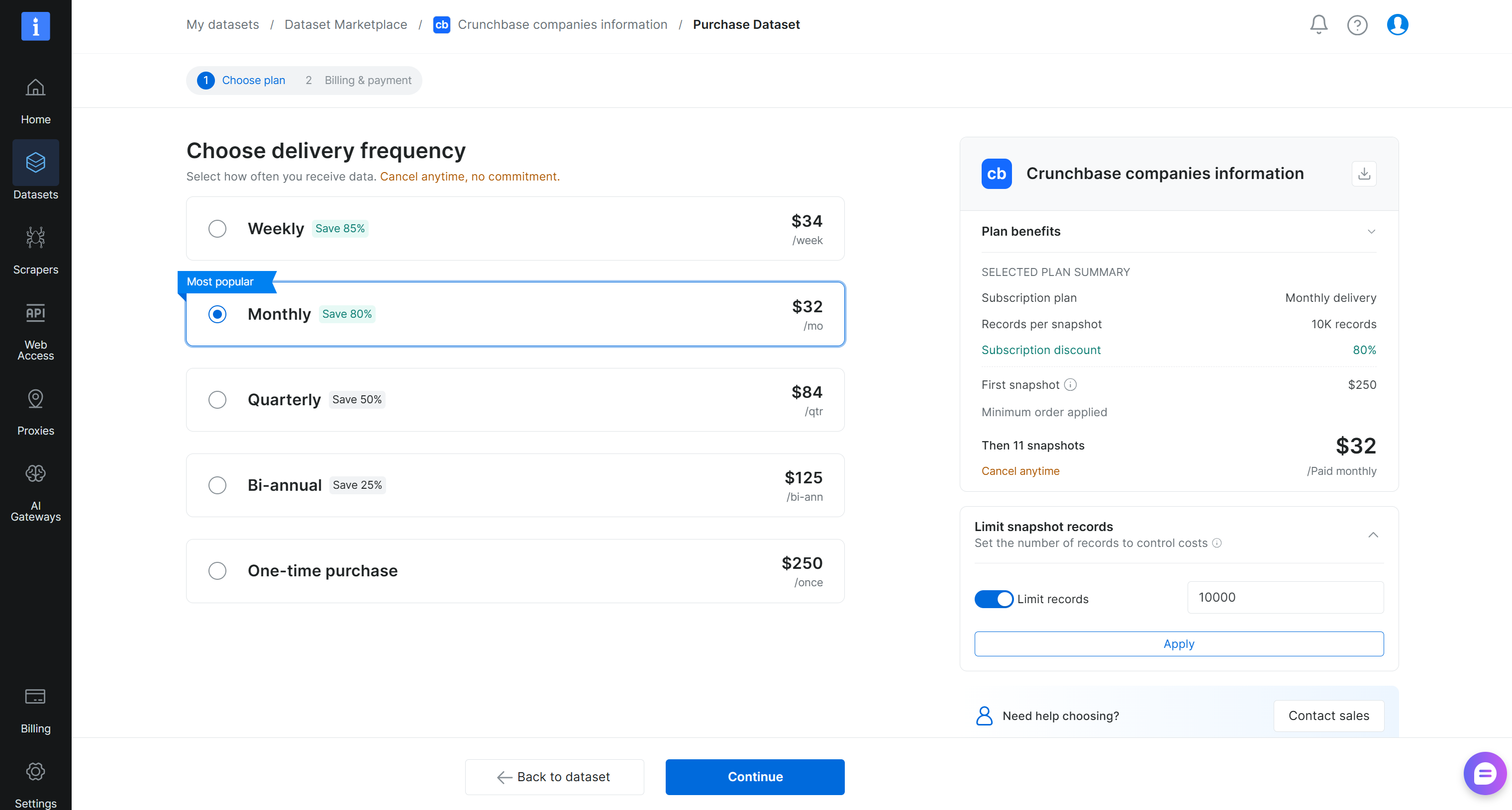
In diesem Beispiel haben wir die Lieferung so konfiguriert, dass sofort 10.000 Datensätze geliefert werden, gefolgt von 11 laufenden monatlichen Updates. Klicken Sie auf ‘Continue’ und schließen Sie den Checkout-Prozess ab, indem Sie Ihre Zahlungsdetails hinzufügen. Prima!
Schritt #4: Den erhaltenen Datensatz erkunden
Wenn der Datensatz fertig ist, erhalten Sie eine E-Mail-Benachrichtigung und können ihn aus dem Bright Data-Kontrollpanel herunterladen. Von dort aus können Sie festlegen, in welchem Format Sie den Datensatz herunterladen und Ihre bevorzugte Liefermethode einrichten möchten (Dateidownload, S3 usw.).
Bei einer Flat-File-Lieferung im CSV-Format erhalten Sie eine Datei wie diese:
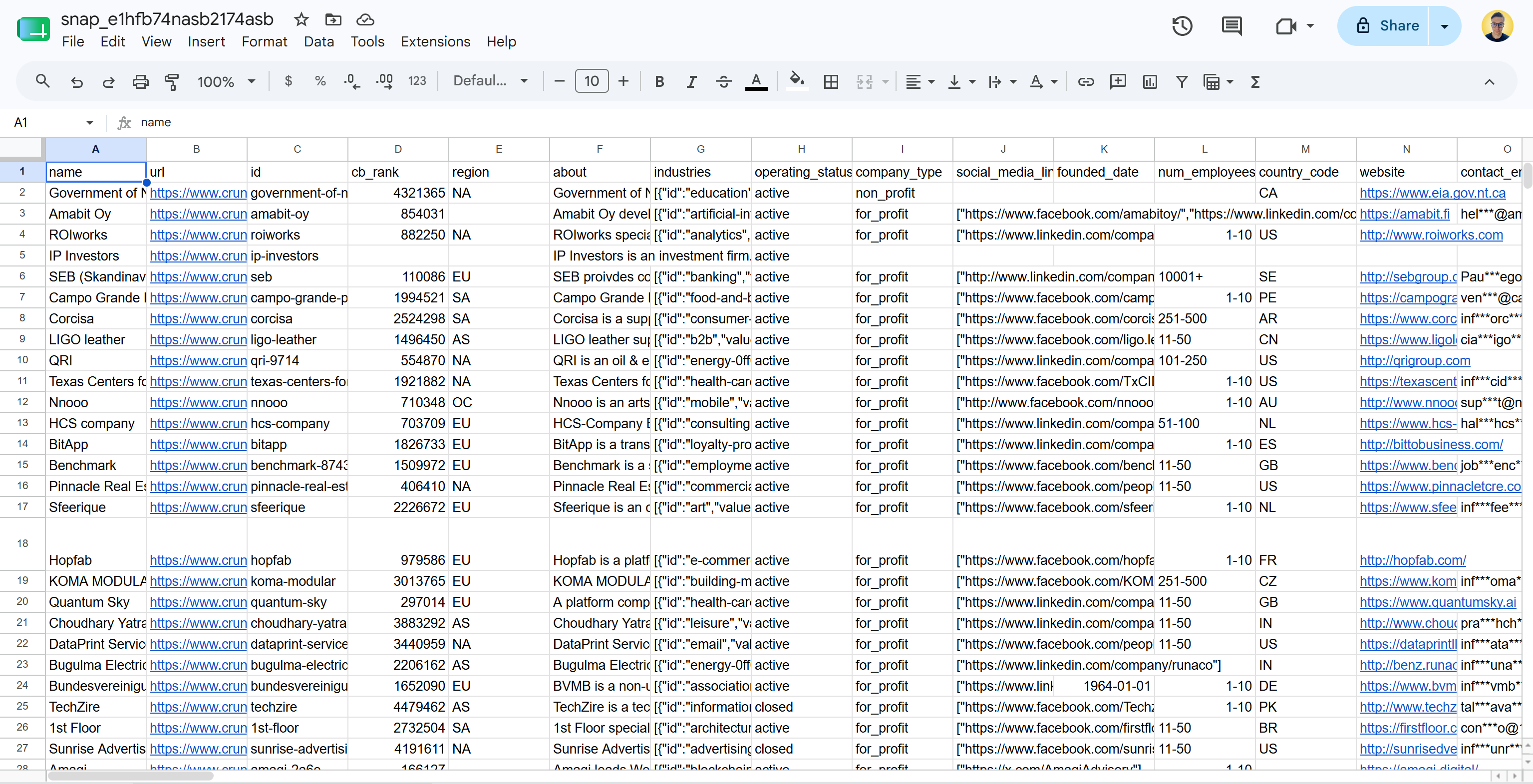
Beachten Sie, dass dies reale, sofort analysierbare Crunchbase-Daten in einem strukturierten Format enthält. Ziel erreicht!
Nächste Schritte
Sobald der Datensatz bereit ist, laden Sie ihn in Ihr Data Warehouse oder Ihre Datenbank für vereinfachte Abfragen. Sie können ihn auch in Ihre Datenanalyse- und Verarbeitungspipelines integrieren.
Zum Beispiel könnten Sie:
- Ihn verwenden, um ein KI-Modell fein abzustimmen.
- Ihn in ein KI-System für Analysen, Trenderkennung oder Prognosen einspeisen.
- Ihn in BI-Dashboards für Berichte und Monitoring integrieren.
- Ihn mit anderen Datensätzen kombinieren, um Ihre internen Daten anzureichern.
Dies sind nur einige Ideen, um Rohdaten in umsetzbare Erkenntnisse für Ihren spezifischen Anwendungsfall umzuwandeln.
Frische, strukturierte Daten über Bright Datas Web-Scraping-APIs sammeln
Hier erfahren Sie, wie Sie mit Web-Scraping-APIs starten. Sie sehen, wie Sie strukturierte, aktuelle Daten von Crunchbase mithilfe der Crunchbase Scraper API von Bright Data abrufen.
Hinweis: Voraussetzung für diesen Abschnitt ist, dass Sie bereits einen Bright Data API-Schlüssel haben. Falls nicht, folgen Sie der offiziellen Anleitung zur Generierung Ihres Bright Data API-Schlüssels.
Schritt #1: Die Crunchbase Web Scraper API aufrufen
Beginnen Sie damit, sich in Ihrem Bright Data-Konto anzumelden. Wählen Sie anschließend die Seite ‘Scrapers Library’ aus dem Menü:
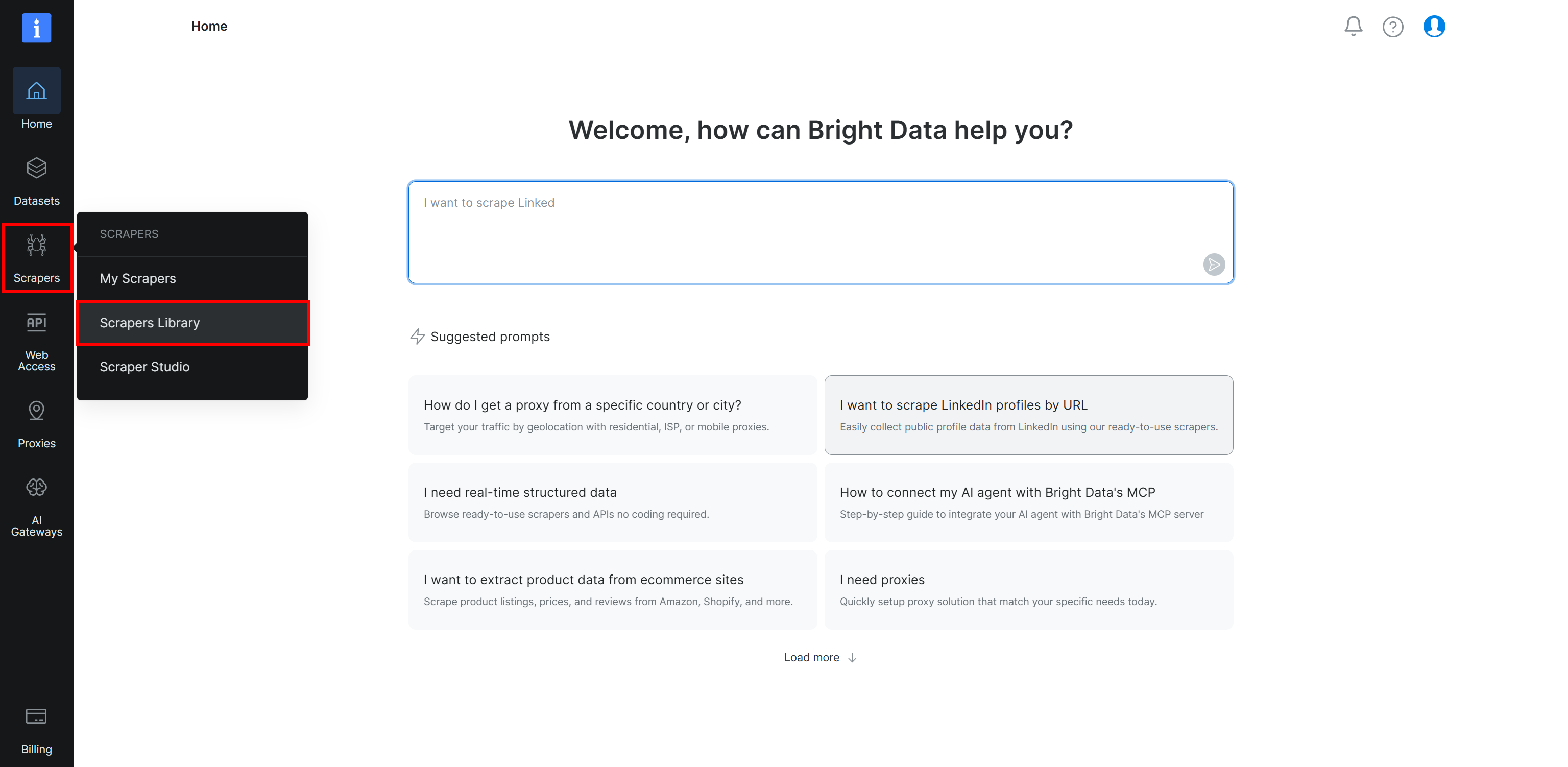
Sie gelangen zur Seite ‘Scrapers Library’, auf der Sie alle verfügbaren Bright Data Web Scraper APIs erkunden können:
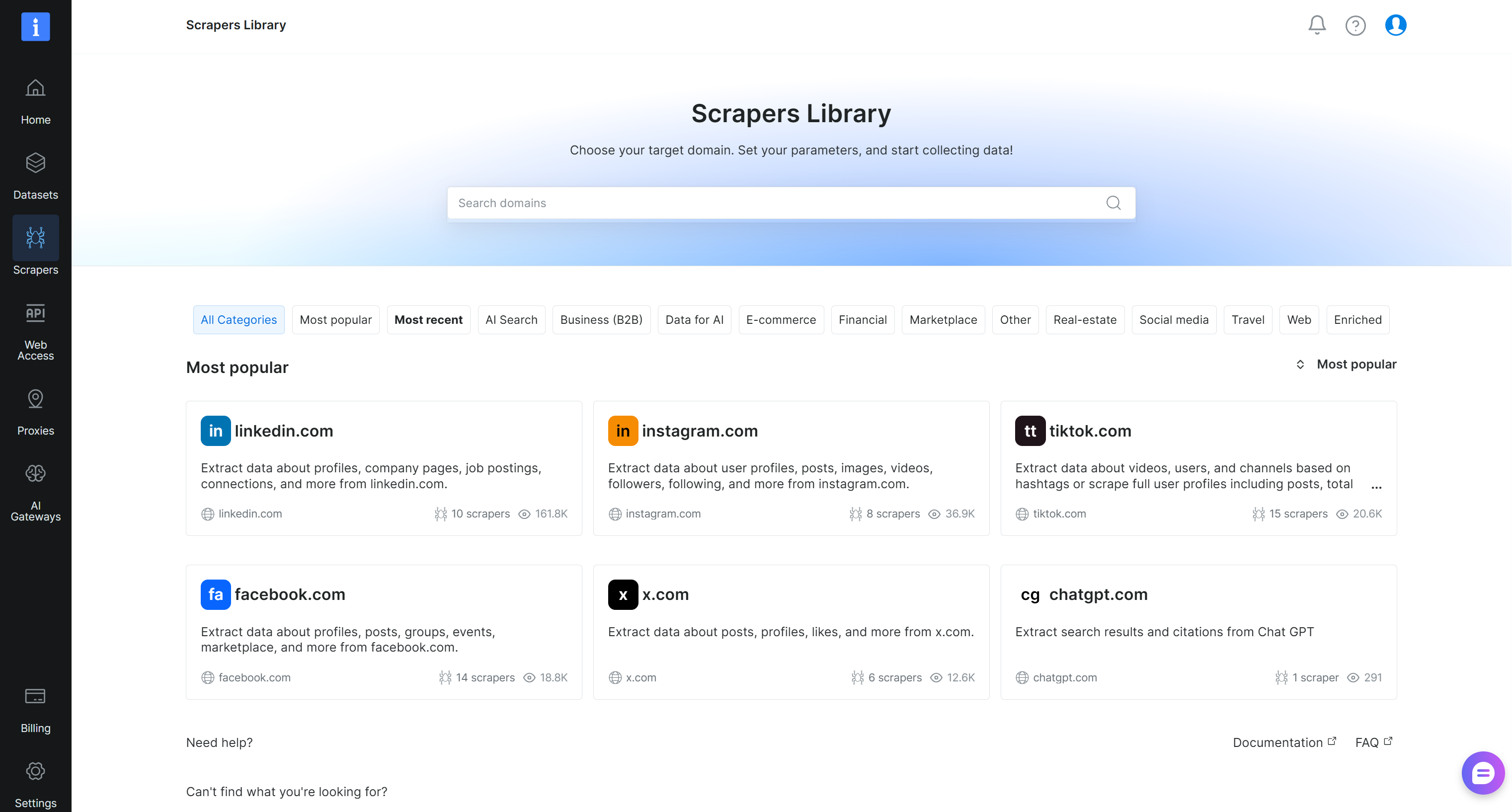
Suchen Sie nach ‘crunchbase.com’ und wählen Sie den Scraper ‘crunchbase.com’:
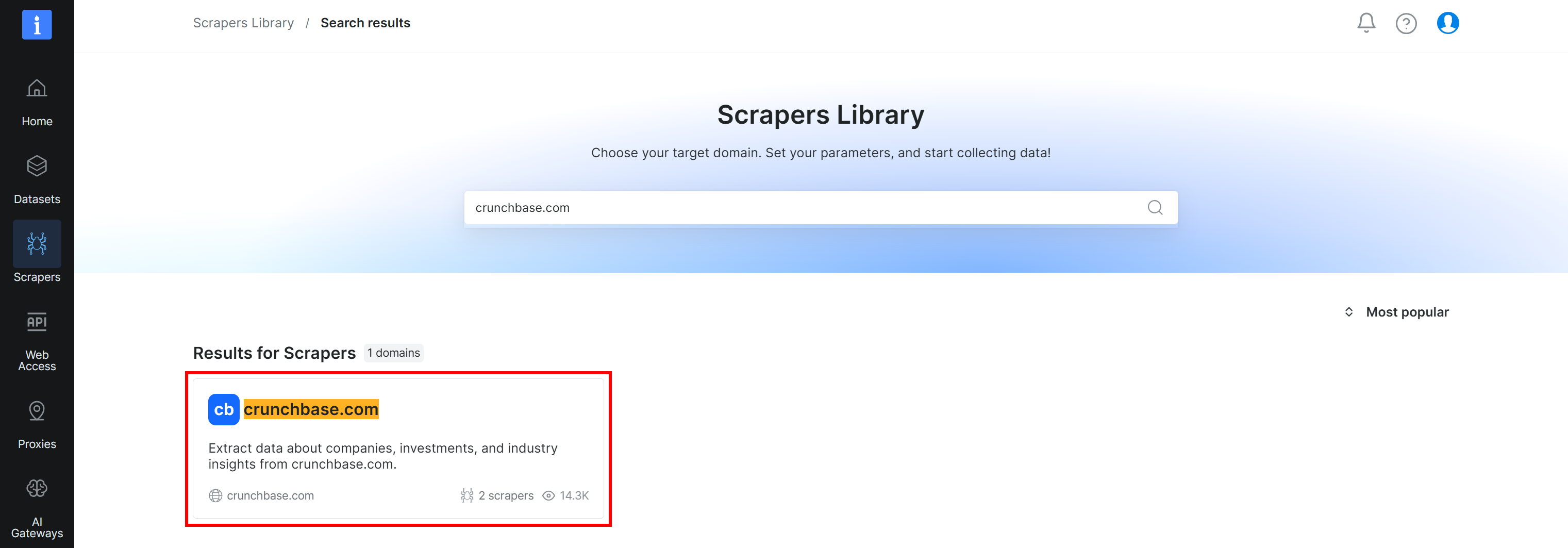
Sie gelangen dann zur Seite der ‘crunchbase.com Scraper API’ im Kontrollpanel. Ausgezeichnet!
Schritt #2: Die Optionen der Scraper API verstehen
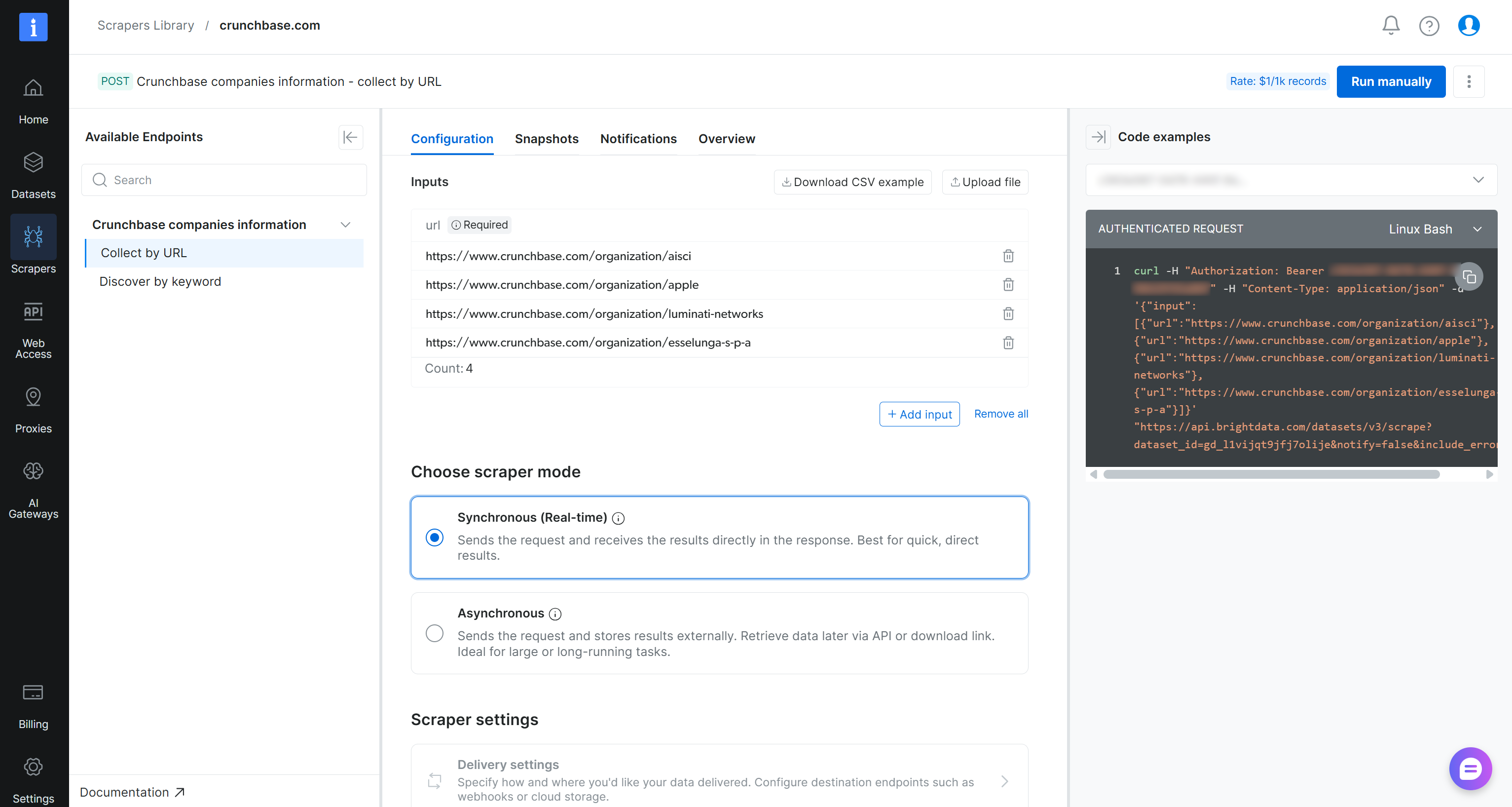
Auf der Seite der ‘crunchbase.com’ Scraper API können Sie im linken Panel alle verfügbaren Scraping-Endpunkte aufrufen. Für jeden Endpunkt können Sie einen API-Aufruf konfigurieren, indem Sie die Ziel-URLs hinzufügen. Sie können auch den Scraping-Modus (synchron oder asynchron) wählen und Datenlieferungsoptionen einrichten.
Wichtig: Führen Sie die API direkt aus, indem Sie auf die Schaltfläche ‘Run manually’ klicken. Sobald sie fertig ist, können Sie die extrahierten Daten über den Tab ‘Snapshots’ aufrufen. Dieser Workflow macht die API auch für nicht-technische Nutzer zugänglich.
Hervorragend! Zeit, einen spezifischen API-Aufruf zu konfigurieren, um frische Crunchbase-Daten zu erhalten.
Schritt #3: Den API-Aufruf konfigurieren
Auf der rechten Seite der Seite können Sie auf vordefinierte Code-Snippets zugreifen, um die Web-Scraping-API aufzurufen. Diese sind automatisch mit Ihrem Bright Data API-Schlüssel konfiguriert.
Wenn Sie beispielsweise Crunchbase-Unternehmensdaten für Anthropic mit Python abrufen möchten, fügen Sie die Ziel-URL in den Abschnitt ‘Inputs’ ein (d. h. https://www.crunchbase.com/organization/anthropic). Wählen Sie den Modus ‘Synchronous (Real-time)’ und dann das Snippet ‘Python (requests)’ aus den verfügbaren Optionen:
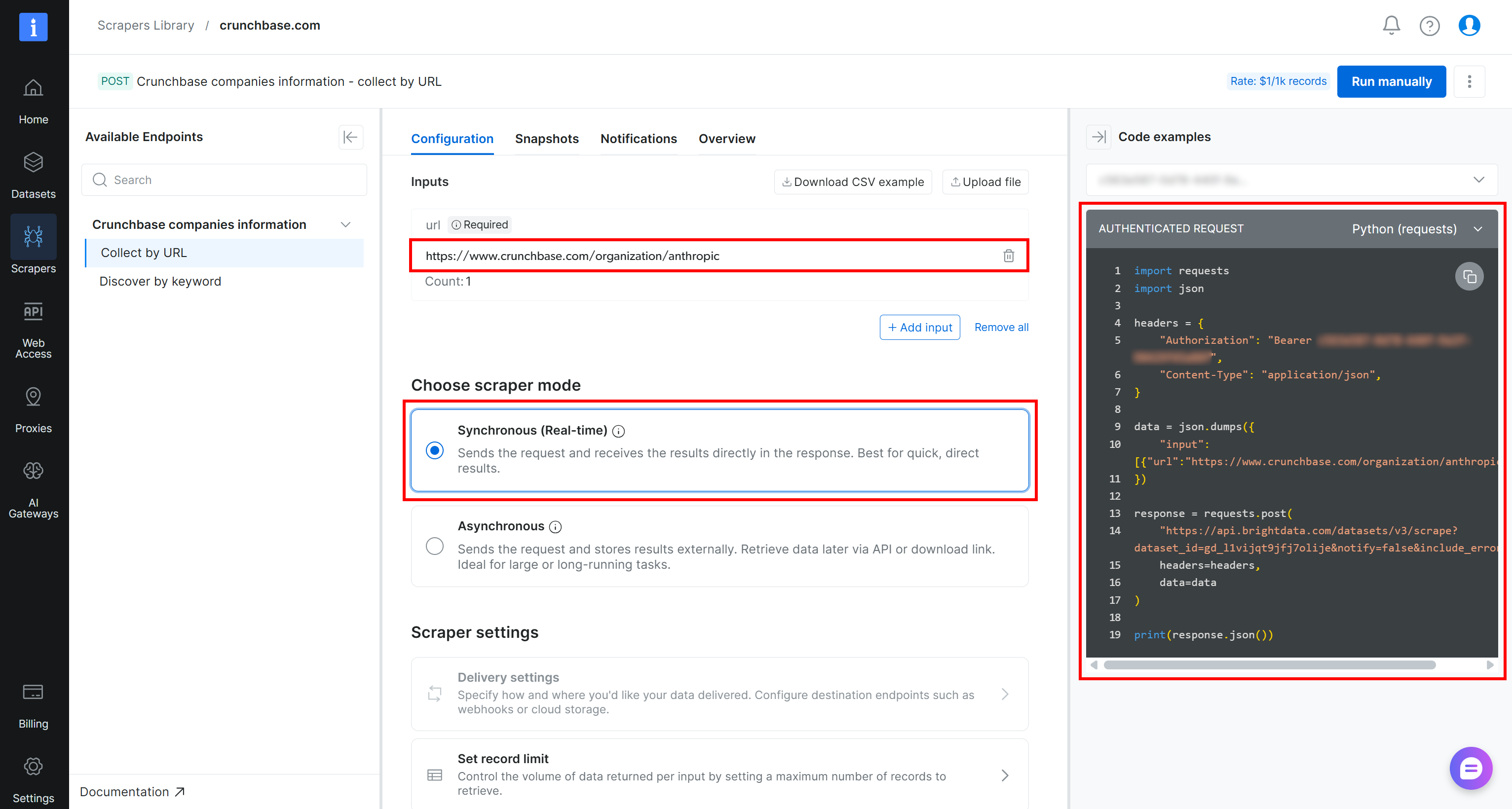
Dies ist das Skript, das Sie erhalten:
import requests
import json
headers = {
"Authorization": "Bearer ",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://www.crunchbase.com/organization/anthropic"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_l1vijqt9jfj7olije¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json()) Zeit, es auszuführen, um die Ergebnisse zu erhalten!
Schritt #4: Die Ergebnisse erkunden
Speichern Sie das Snippet aus dem Bright Data-Kontrollpanel lokal in einer Datei wie script.py.
Vorausgesetzt, Sie haben Python lokal installiert, installieren Sie die erforderliche Abhängigkeit:
pip install requestsFühren Sie anschließend das Skript aus mit:
python script.pyDas Ergebnis sieht folgendermaßen aus:
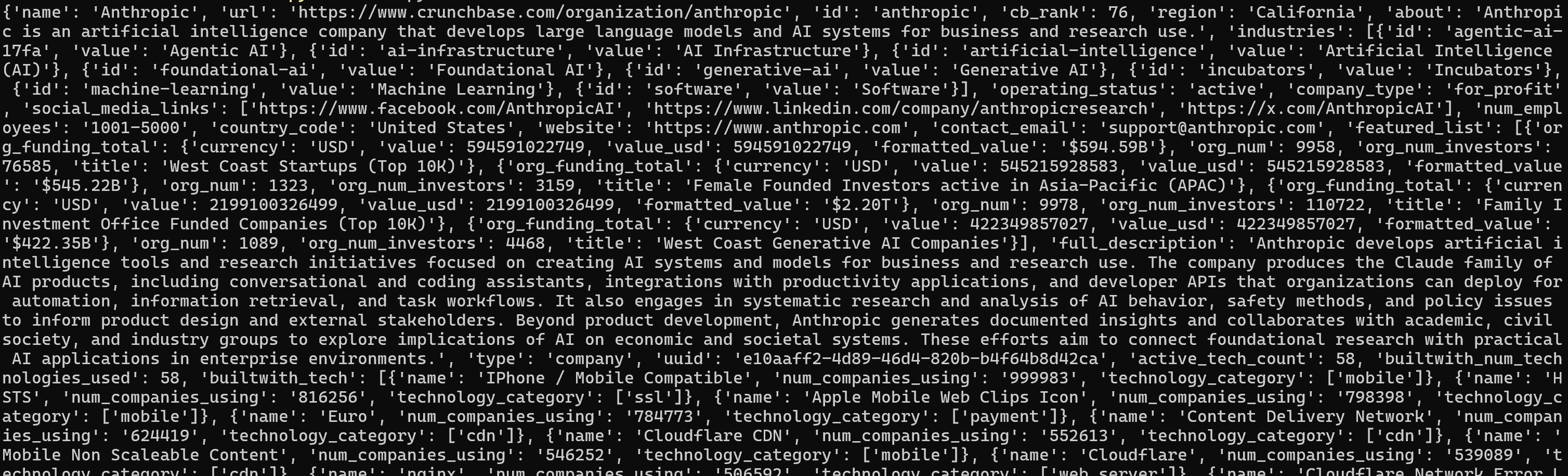
Für eine bessere Ansicht fügen Sie die Ausgabe in einen JSON-Viewer ein:
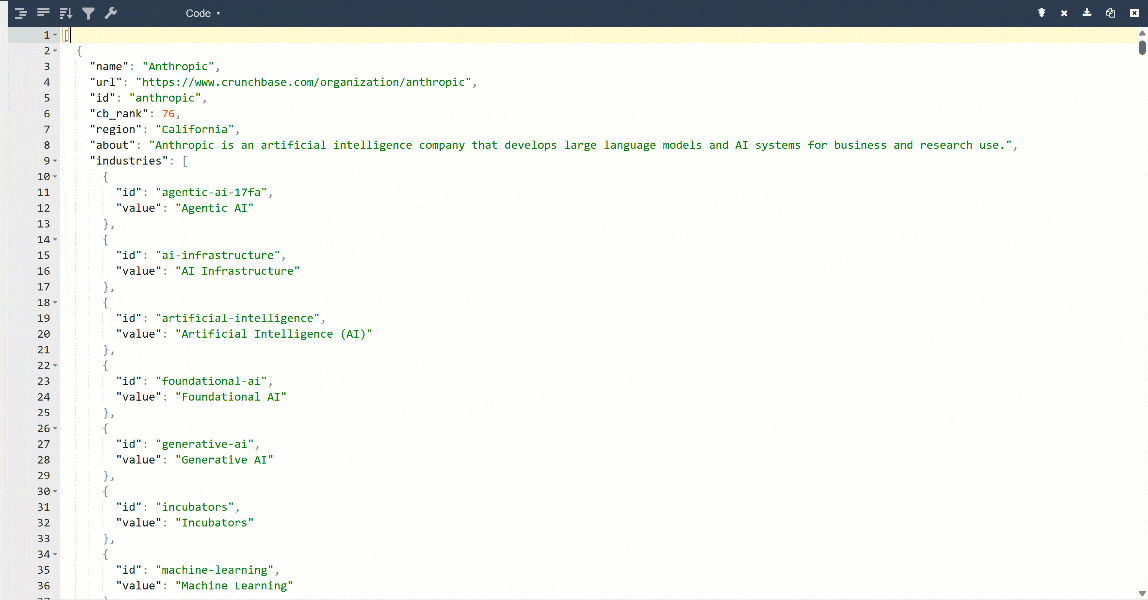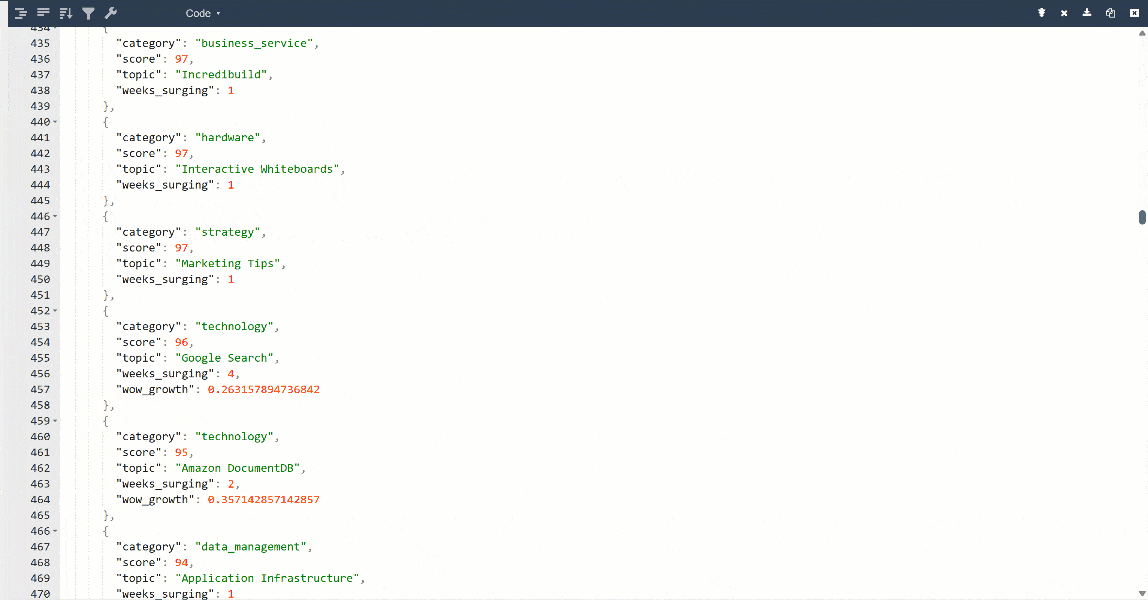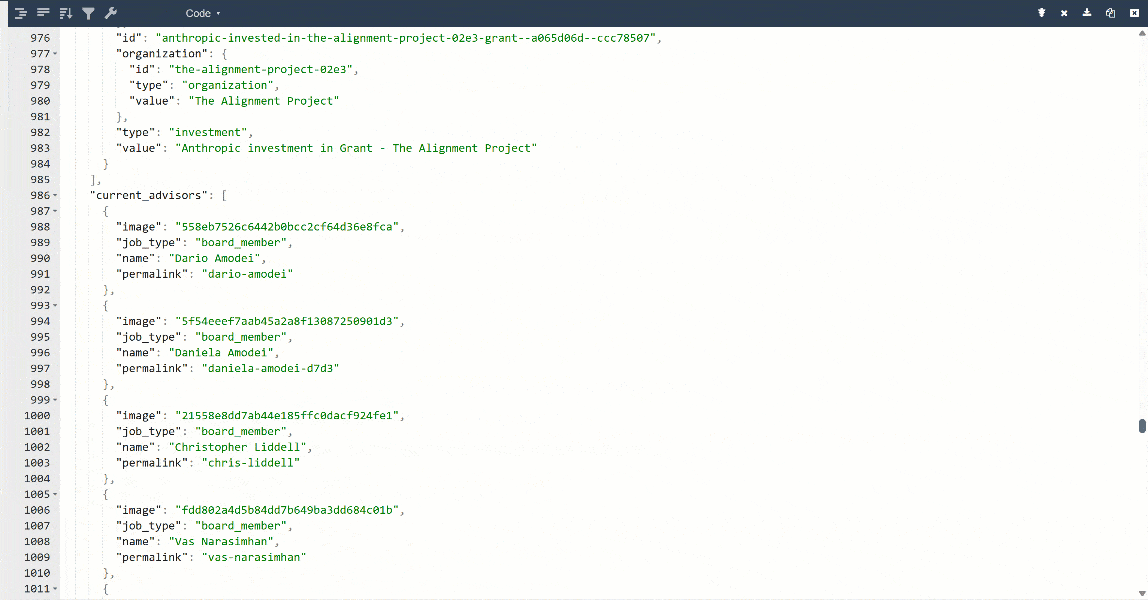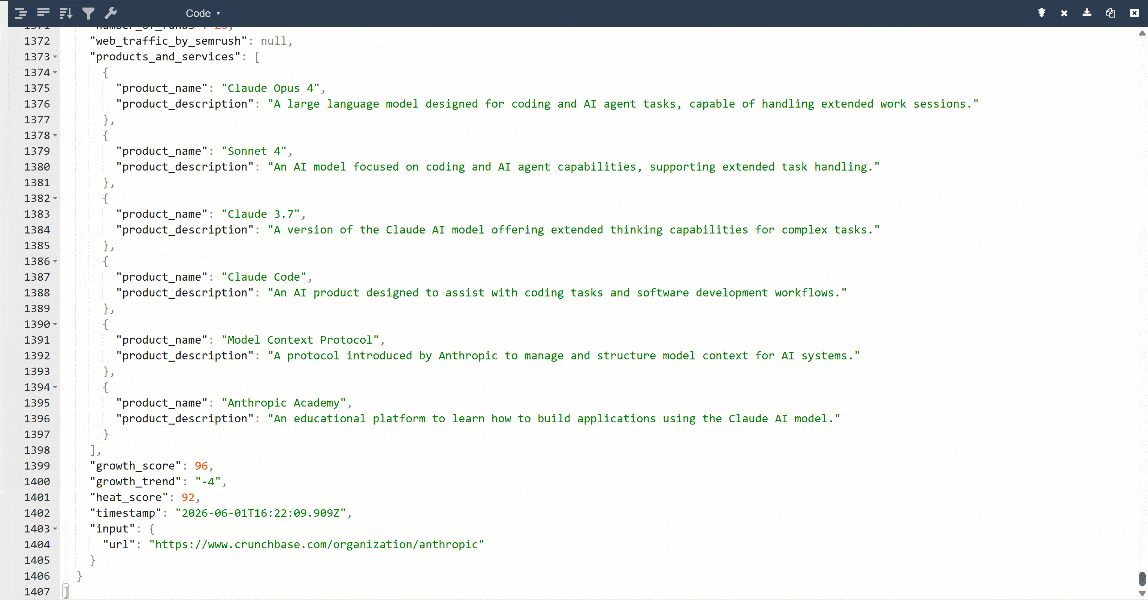
Dies sind dieselben Daten, die von der Zielseite extrahiert wurden, jedoch in einem strukturierten Format:
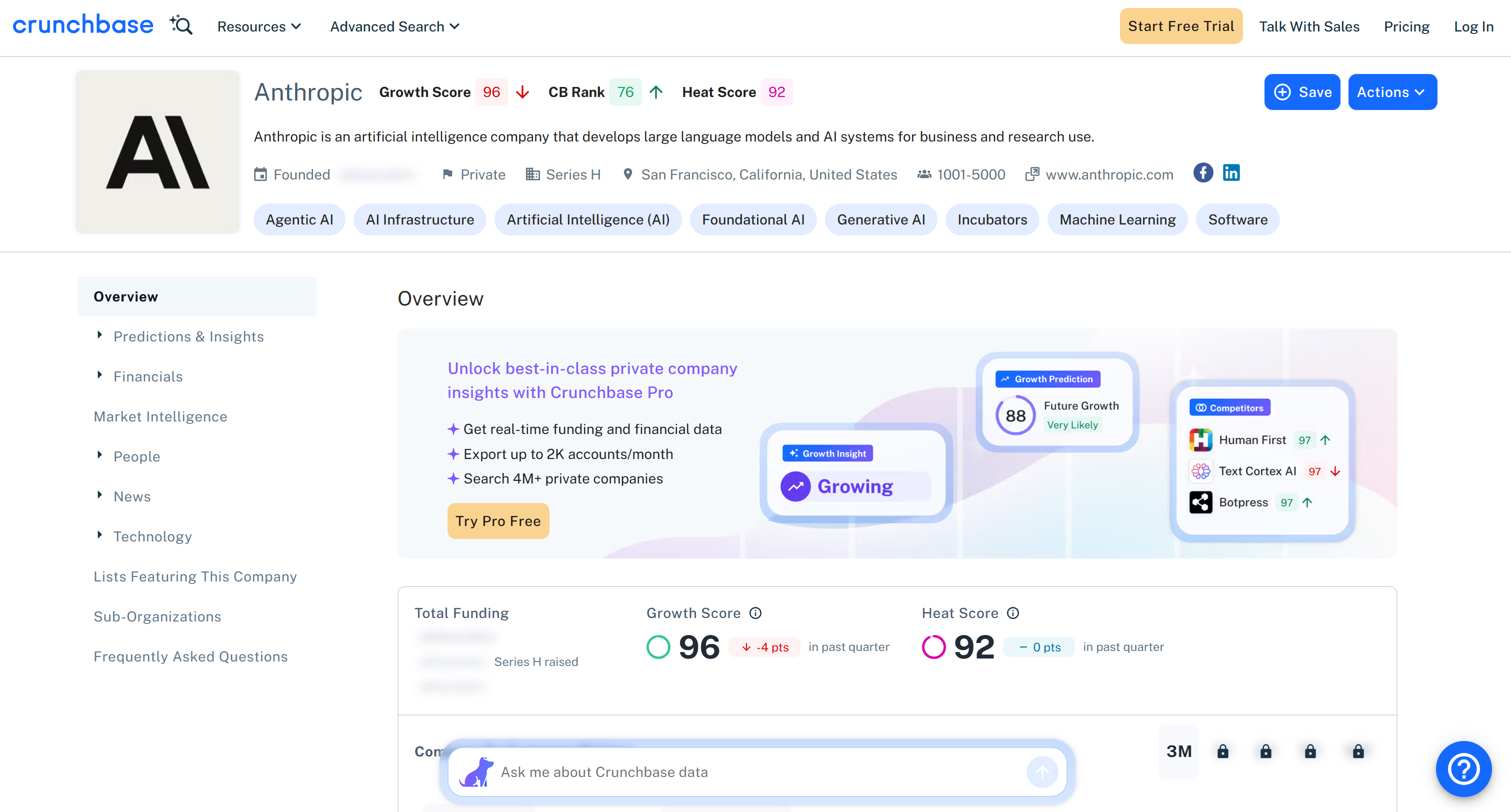
Beachten Sie, dass alle von der Bright Data Crunchbase Scraper API zurückgegebenen Informationen mit dem Inhalt der Zielseite übereinstimmen. Dies liegt daran, dass die Daten durch Web-Scraping in Echtzeit abgerufen werden und daher immer aktuell sind.
Et voilà! Sie haben erfolgreich Daten mithilfe der Bright Data Web-Scraping-API abgerufen.
Nächste Schritte
Das obige Kapitel zeigte ein einfaches Beispiel, wie man eine Bright Data Web-Scraping-API in Python aufruft. Web-Scraping-APIs können jedoch noch viel mehr. Dank ihnen können Sie strukturierte, aktuelle Daten direkt in Ihre Anwendungen, Systeme oder KI-Workflows streamen.
Für KI-Agent-Anwendungsfälle insbesondere fungieren diese APIs als Live-Grundierungsschicht, die kontinuierlich frischen externen Kontext in Ihre Systeme einspeist. Zum Beispiel können Sie:
- KI-Agenten mit realen, aktuellen Web-Daten für Retrieval und Reasoning ausstatten (zum Beispiel über Bright Datas Web MCP).
- LLM-Ausgaben mit Live-Informationen aus Quellen wie Crunchbase, E-Commerce-Plattformen oder Social Media verankern.
- Echtzeit-RAG-Pipelines aufbauen, bei denen gescrapte Web-Daten in Prompts oder Vektordatenbanken injiziert werden.
- Finanz- oder Business-Agenten unterstützen, die auf aktuelle Preise, Unternehmensupdates, Marktsignale usw. angewiesen sind.
Im Allgemeinen sind Bright Data Web-Scraping-APIs eine zentrale Infrastrukturschicht für den Aufbau dynamischer, datenbewusster Systeme, die auf frischer Web-Intelligenz basieren.
Datensätze oder Web-Scraping-APIs: Abschließende Vergleichstabelle
Vergleichen Sie die beiden Ansätze zur Datenbeschaffung auf einen Blick in der folgenden Vergleichstabelle für Datensätze vs. Web-Scraping-APIs:
| Datensätze | Web-Scraping-APIs | |
|---|---|---|
| Beschreibung | Vorgesammelte, strukturierte Datensammlungen | APIs, die auf Anfrage Live-Web-Daten von Zielwebsites extrahieren und zurückgeben |
| Datenformate | CSV, JSON, Excel, Parquet, NDJSON usw. | JSON, CSV |
| Datenaktualität | Statische oder periodisch aktualisierte Snapshots | Echtzeit |
| Aktualisierungsmodell | Tägliche, monatliche, vierteljährliche Aktualisierungszyklen | Echtzeit |
| Skalierbarkeit | Milliarden von Datensätzen | Hoch, abhängig von den Rate Limits und der Infrastruktur des API-Anbieters |
| Erforderliche Infrastruktur | Keine (vom Anbieter verwaltet) | Keine (vom Anbieter verwaltet) |
| Abdeckung | Breit, aber durch den Datensatzumfang begrenzt | Potenziell jede Website oder Domain |
| Komplexität für den Nutzer | Sehr gering | Gering bis mittel (API-Integration erforderlich) |
| KI-Nutzung | Hauptsächlich für Training | Echtzeit-Grundierung und mehr (unterstützt via Web MCP) |
Wählen Sie Datensätze, wenn…
- Sie saubere, strukturierte Daten benötigen, die sofort für Analysen oder ML-Training bereit sind.
- Ihr Anwendungsfall auf historischen oder aggregierten Informationen beruht, ohne Bedarf an Echtzeit-Updates.
- Sie jegliche Datentechnik- oder Scraping-Komplexität vermeiden möchten.
- Sie kostengünstigen Zugang zu groß angelegten, kuratierten Daten wünschen.
- Sie einen batch-orientierten Workflow bevorzugen (Download → Speichern → Abfragen).
Bevorzugen Sie Web-Scraping-APIs, wenn…
- Sie frische, Echtzeit-Daten aus dem Web benötigen.
- Ihr System auf Live-Änderungen oder Ereignisse reagieren muss (Preise, Nachrichten, Unternehmensupdates usw.).
- Sie KI-Agenten entwickeln, die externe Grundierung benötigen.
- Sie Web-Daten ohne interne Scraping-Infrastruktur wünschen.
- Sie eine kontinuierliche oder wiederholte Extraktion sich verändernder Daten benötigen.
Datensätze + Web-Scraping-APIs: Ist das möglich?
Datensätze zusammen mit Web-Scraping-APIs zu verwenden ist nicht nur möglich, sondern oft die praktischste Lösung für moderne Daten- und KI-Systeme.
Datensätze liefern Ihnen saubere, strukturierte und sofort einsatzbereit historische Snapshots. Sie sind ideal, wenn Sie Konsistenz, Wiederholbarkeit und groß angelegte Analysen ohne Infrastruktursorgen benötigen.
Web-Scraping-APIs hingegen liefern frische, on-demand-Daten direkt aus dem Web. Sie sind besser geeignet für Echtzeit-Anwendungen und sich schnell verändernde Quellen.
In der Praxis ergänzen sich die beiden Ansätze hervorragend. Ein gängiges Muster ist, mit einem Datensatz zu beginnen, um den Ausgangszustand einer Domain zu definieren. Dann werden Web-Scraping-APIs verwendet, um bestimmte Teile davon anzureichern oder zu aktualisieren. Diese Kombination ist besonders nützlich in Szenarien, in denen sowohl stabiles Hintergrundwissen als auch Live-Kontext erforderlich sind.
Für ein reales Beispiel zu Crunchbase lesen Sie unseren Artikel ‘Filter a Crunchbase Dataset and Process It with AI for Prospecting New Clients‘. Er erklärt, wie man einen KI-gestützten Kundenakquise-Workflow aufbaut, indem man zunächst einen Crunchbase-Datensatz filtert und dann Web-Scraping-APIs verwendet, um Live-Unternehmenswebsites abzurufen und potenzielle Kunden mit KI zu bewerten.
Fazit
In diesem Blogbeitrag haben Sie verstanden, was Datensätze und Web-Scraping-APIs zu bieten haben. Sie haben gelernt, dass Datensätze ideal für Szenarien sind, in denen Sie große Mengen statischer, strukturierter Daten benötigen. Web-Scraping-APIs hingegen sind besser geeignet, wenn Sie frische Daten direkt aus dem Web benötigen.
In beiden Fällen benötigen Sie, unabhängig vom gewählten Ansatz, einen zuverlässigen Web-Datenanbieter. Bright Data unterstützt Sie mit:
- Datensatz-Marktplatz: Vorgefertigte, gefilterte öffentliche Web-Daten aus über 350 Domains in JSON, CSV, Parquet und anderen Formaten. Er bietet Zugang zu einer Sammlung von über 17 Milliarden Datensätzen.
- Web-Scraping-APIs: Eine Sammlung von über 600 Scraping-Endpunkten, die die Echtzeit-Web-Datenextraktion auf über 250 Domains automatisieren. Sie verwalten IP-Rotation, CAPTCHAs und Anti-Bot-Systeme und liefern strukturierte Daten ohne Infrastrukturaufwand.
Erstellen Sie noch heute ein Bright Data-Konto und testen Sie unsere Web-Datenlösungen kostenlos!




