
Früher war die Datenfilterung ein einfacher Datenbanktrick. Heute ist sie eine zentrale Geschäftsfunktion, die KI unterstützt, die Einhaltung von Vorschriften sicherstellt und Ihnen hilft, die Konkurrenz auszustechen.
In diesem Leitfaden erfahren Sie:
- Was Datenfilterung ist.
- Warum Datenfilterung wichtig ist.
- Warum Sie automatisierte Datenfilterung verwenden sollten.
- Wie Deep Lookup die Datenfilterung einfach macht.
Tauchen Sie ein!
Was ist Datenfilterung?
Datenfilterung bedeutet, dass Sie sich nur die Daten anzeigen lassen, die Sie wirklich interessieren. Stellen Sie sich das wie einen Kaffeefilter vor, der Ihnen nur die guten Sachen zeigt, die Sie wollen, und nicht den Kaffeesatz. Die Funktionsweise ist einfach: Sie legen Regeln fest (z. B. zeigen Sie mir Kunden in Kalifornien), und das System schließt alles aus, was nicht den Regeln entspricht.
Wir alle nutzen die Datenfilterung in unserem täglichen Leben. Wenn Sie auf Amazon nach “kabellosen Kopfhörern unter 100 $” suchen, filtern Sie. Wenn Ihr Marketingteam eine Liste von Kunden erstellt, die in den letzten 6 Monaten nicht gekauft haben, wird gefiltert. Wenn Sie Ihren Posteingang nach Absender sortieren, filtern Sie.
Das Konzept ist zwar einfach, aber um die Datenfilterung in einem Unternehmen in großem Umfang zu nutzen, sind ein solides Verständnis Ihrer Daten und die richtigen Tools erforderlich. Heutzutage ist die Datenfilterung für den Erfolg eines jeden Unternehmens wichtig, und wir sagen Ihnen genau, warum.
Warum Datenfilterung wichtig ist
Filtern ist eine Notwendigkeit, um Big Data sinnvoll nutzen zu können.
Die meisten Unternehmen sitzen heute auf Goldminen von Daten, die sie nie nutzen werden. Nicht, weil die Daten nicht wertvoll wären, sondern weil sie sie nicht effizient durchforsten können, um das Wesentliche zu finden.
Stellen Sie sich das einmal so vor. Ihr Unternehmen sammelt wahrscheinlich Hunderte von Datenpunkten über jeden Kunden. Aber wenn es darauf ankommt und Sie Ihre wertvollsten Segmente identifizieren müssen, werden Sie dann wirklich 50.000 Kundendatensätze manuell durchforsten? Nein, natürlich nicht. Sie nehmen eine Stichprobe, stellen einige fundierte Vermutungen an und hoffen auf das Beste.
Das ist genau das Problem, das die Filterung löst. Im Folgenden erfahren Sie, warum eine effektive Datenfilterung so wichtig ist:
- Durchbrechen Sie das Rauschen: Ihre Analysten verschwenden keine Zeit mehr mit irrelevanten Daten und konzentrieren sich auf die Muster, die tatsächlich etwas bewirken.
- Beschleunigen Sie alles: KleinereDatensätze bedeuten schnellere Abfragen, schnellere Erkenntnisse und Entscheidungen, die in Tagen statt in Wochen getroffen werden.
- Verborgene Muster aufdecken: Wenn Sie das Durcheinander beseitigen, werden Trends, die vorher unsichtbar waren, plötzlich offensichtlich.
- Sparen Sie bares Geld: Weniger zu speichernde und zu verarbeitende Daten bedeuten geringere Infrastrukturkosten. Außerdem wird die Zeit Ihres Teams unendlich viel wertvoller.
- Bleiben Sie gesetzeskonform: Wenn Sie sensible Informationen automatisch herausfiltern, können Sie ruhiger schlafen, weil Sie wissen, dass Sie nicht versehentlich Kundendaten preisgeben.
Zusammenfassend lässt sich sagen, dass die Datenfilterung die Brücke zwischen Rohdaten und fundierten Entscheidungen schlägt. Als Nächstes werden wir uns ansehen, wie Sie die Filterung in der Praxis angehen und einige Standardtechniken für eine effektive Filterung anwenden.
Manuelle Datenfilterung anhand von Amazon-Marktplatzdaten
Ich möchte Ihnen zeigen, wie die meisten Teams vorgehen, wenn sie Daten filtern müssen. Wir werden einen echten Amazon-Produktdatensatz (mit freundlicher Genehmigung von Bright Data Datasets) verwenden, um Ihnen genau zu zeigen, wie das abläuft. Dieser Datensatz enthält verschiedene Felder wie Produkttitel, Marken, Preise, Bewertungen und mehr aus verschiedenen Kategorien und Regionen.
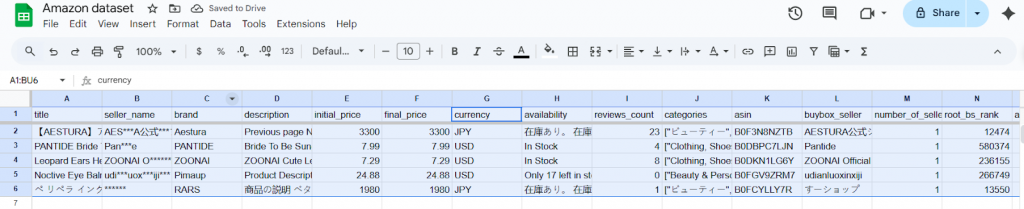
Angesichts einer so umfangreichen Liste müsste ein Datenexperte nur die für eine bestimmte Analyse relevanten Produkte herausfiltern, um sich auf nützliche Informationen zu konzentrieren. Dazu muss er die folgenden Schritte durchführen:
- Zunächst müssen alle Produkte herausgefiltert werden, die nicht den ursprünglichen Kriterien entsprechen. In der Praxis bedeutet dies oft, dass Sie Produkte außerhalb Ihrer Zielkategorie oder Ihres Zielbereichs ausschließen. Wenn wir uns zum Beispiel nur für Schönheitsprodukte interessieren, würden wir Einträge, die zu anderen Kategorien gehören, entfernen.
- Verwenden Sie ein Tool wie Google Sheets oder Excel, gehen Sie auf die Registerkarte Daten und klicken Sie auf Filter erstellen.

- Daraufhin wird in jeder Spalte ein Filter angezeigt, den Sie verwenden können, um den Datensatz so weit wie möglich anzupassen.
- Wenn Sie beispielsweise die Produkte nach Währung filtern und nur Produkte mit USD-Preisen anzeigen möchten, gehen Sie zur Spalte mit den Preisen und wenden diesen Filter an.

- Sobald Sie die Markierung für JPY entfernen, werden im Datensatz nur noch Produkte mit USD-Preisen angezeigt.
Wenn Sie dies zum ersten Mal tun, fühlt es sich ziemlich gut an. Sie haben die Kontrolle, Sie können genau sehen, was passiert, und Sie erkennen interessante Muster, während Sie arbeiten. “Oh, sieh mal, umweltfreundliche Produkte scheinen höhere Bewertungen zu haben!”
Aber in der Praxis sieht es folgendermaßen aus:
- Woche 1: Das ist großartig! Ich liebe es, diese Kontrolle zu haben.
- Woche 4: Okay, das wird langsam langweilig, aber ich finde immer noch gute Erkenntnisse.
- Woche 12: Ich habe gerade den ganzen Vormittag damit verbracht, die gleichen Filter wie gestern anzuwenden.
- Woche 24: Ich glaube, ich habe vergessen, den vorherigen Filter zu löschen… sind diese Zahlen überhaupt richtig?
Viele brillante Analysten brennen bei genau dieser Vorgehensweise aus. Nicht, weil die Arbeit nicht wertvoll wäre, sondern weil sie 80 % ihrer Zeit mit mechanischen Aufgaben verbringen, statt mit der eigentlichen Analyse.
Da Sie nun wissen, wie man Daten manuell filtert, lassen Sie uns die Vor- und Nachteile dieser Methode betrachten.
Vorteile der manuellen Filterung
- Die manuelle Filterung gibt Ihnen ein unmittelbares visuelles Feedback, so dass Sie die Ergebnisse sofort sehen und die Filter iterativ anpassen können. Sie können während der Arbeit unerwartete Muster oder Probleme mit der Datenqualität erkennen.
- Außerdem erhalten Sie eine Integration des Geschäftskontexts, die differenzierte Entscheidungen ermöglicht. Beim Filtern von “customers_say”- oder “top_review”-Feldern identifiziert das menschliche Urteilsvermögen Stimmungen und Bedenken, die automatisierte Systeme möglicherweise übersehen.
- Dies ermöglicht eine flexible Exploration, die eine auf Entdeckung ausgerichtete Analyse unterstützt. Sie könnten feststellen, dass Produkte mit ‘climate_pledge_friendly’ = TRUE höhere Bewertungen haben, was zu neuen strategischen Erkenntnissen führt.
- Die Einstiegshürde ist niedrig, d. h. jedes Teammitglied, das mit Tabellenkalkulationen vertraut ist, kann ohne technische Schulung oder spezielle Tools Analysen durchführen.
- Durch Filteransichten erhalten Sie Einblick in die Audit-Trails, und dokumentierte Kriterien gewährleisten die Reproduzierbarkeit der Analyse und die Zusammenarbeit im Team.
Nachteile der manuellen Filterung
- Die Grenzen des Umfangs werden schnell deutlich. Das Filtern durch mehr als 10.000 Zeilen in Google Sheets führt zu einer spürbaren Leistungsverschlechterung. Bei Millionen von Amazon-Produkten sehen Sie nur eine winzige Stichprobe.
- Die Zeitintensität nimmt mit der Komplexität zu. Die Anwendung des oben beschriebenen 8-stufigen Filterungsprozesses dauert 15-20 Minuten für eine Analyse. Eine tägliche Wiederholung oder eine Wiederholung für mehrere Kategorien ist nicht mehr tragbar.
- Die Wahrscheinlichkeit menschlicher Fehler steigt mit der Anzahl der Wiederholungen. Die versehentliche Auswahl falscher Operatoren (größer als vs. kleiner als) oder das Vergessen, vorherige Filter zu löschen, führt zu falschen Analysen.
- Inkonsistenz zwischen den Benutzern führt zu widersprüchlichen Erkenntnissen. Zwei Analysten könnten “hochwertige Verkäufer” unterschiedlich interpretieren, indem sie “Verkäufername” oder “Bewertung” mit unterschiedlichen Schwellenwerten filtern.
- Die begrenzte Reproduzierbarkeit macht eine Automatisierung unmöglich. Jede manuelle Filtersitzung erfordert einen menschlichen Eingriff, was geplante Berichte oder Echtzeit-Dashboards verhindert.
- Die Opportunitätskosten sind erheblich. Während Analysten Stunden mit dem Filtern von Daten verbringen, handeln Wettbewerber, die automatisierte Lösungen verwenden, bereits auf der Grundlage von Erkenntnissen. Die Zeit, die für die mechanische Filterung aufgewendet wird, könnte in strategische Analysen und Entscheidungsfindung investiert werden.
Insgesamt bietet die manuelle Datenfilterung ein hohes Maß an Kontrolle und Klarheit für den Analysten und eignet sich daher gut für explorative Analysen oder kleine Datensätze, bei denen das Verständnis von Nuancen wichtig ist. Aufgrund ihrer Ineffizienz und des Fehlerrisikos bei großen Datenmengen ist sie jedoch für Big Data oder Routineabläufe weniger geeignet.
In diesen Fällen ist es besser, auf automatisierte Filtermethoden oder Tools umzusteigen, und wir werden Ihnen genau sagen, warum.
Warum automatisierte Datenfilterung intelligenter, schneller und skalierbar ist
Bei der automatisierten Filterung geht es nicht nur um Geschwindigkeit. Die Automatisierung macht nicht nur schneller, was Sie vorher gemacht haben, sondern auch Dinge, die Sie buchstäblich nicht manuell machen konnten.
Erinnern Sie sich an den Amazon-Datensatz mit 73 verschiedenen Feldern? Manuell könnten Sie 5-10 Kombinationen dieser Felder untersuchen. Mit der Automatisierung können Sie Tausende von Kombinationen parallel testen. Sie könnten herausfinden, dass Produkte mit klimafreundlichen Plaketten tatsächlich eine um 23 % höhere Kundenbindung haben, aber nur in bestimmten Preisklassen und nur, wenn sie von bestimmten Verkäufern verkauft werden.
Das sind keine Erkenntnisse, über die man zufällig stolpert. Es sind Erkenntnisse, die sich ergeben, wenn man systematisch jeden Blickwinkel erforscht, und das kann man nur durch automatisierte Datenfilterung.
Die automatisierte Filterung verändert die Möglichkeiten eines Analysten oder eines Unternehmens grundlegend, indem sie Millionen von Datensätzen in Sekundenschnelle verarbeitet und dabei Hunderte von Filterkombinationen gleichzeitig anwendet. Dazu werden Ihre Kriterien als maschinell ausführbare Regeln kodiert und kontinuierlich in großem Maßstab ausgeführt.
Anstatt sich durch Spalten zu klicken, können Sie deklarative Filter definieren, diese Filter so nah wie möglich an die Quelle bringen und so schnelle, wiederverwendbare Daten erhalten. Mit der automatisierten Datenfilterung können Sie Tausende von Feldinteraktionen parallel untersuchen und dabei Muster aufdecken, die niemals in das begrenzte Untersuchungsbudget eines Menschen passen würden, und diese dann beliebig oft reproduzieren.
| Dimension | Manuell | Automatisiert |
|---|---|---|
| Geschwindigkeit/Latenzzeit | Menschliches Tempo; Minuten bis Stunden pro Durchlauf | Maschinengesteuert; Sekunden bis Minuten bei Skalierung |
| Skalierbarkeit | Begrenzt durch UI und Speicher | Horizontale Skalierung (verteilte Datenverarbeitung, Pushdown) |
| Verlässlichkeit | Anfällig für menschliche Fehler | Deterministisch, prüfbar, idempotent |
| Frische | Batch, ad hoc | Geplant oder Streaming; nahezu in Echtzeit möglich |
| Konsistenz | Variiert je nach Betreiber | Versionskontrollierte Logik; reproduzierbare Ausgaben |
| Kosten | Versteckte Arbeitskosten; Nacharbeit | Rechenoptimiert; Cache & Prädikat Pushdown |
| Verwaltung | Schwer zu überprüfen | Abstammung, Protokollierung, Genehmigungen, Zugriffskontrollen |
Eines der besten Tools, die Sie für die automatisierte Datenfilterung verwenden können, ist Deep Lookup von Brightdata, auf das wir im Folgenden eingehen werden.
Einführung in Deep Lookup: Daten mit einfachem Englisch filtern
Deep Lookup ist ein KI-gestütztes Recherchetool von Bright Data, das einfachsprachige Aufforderungen in strukturierte, genaue Datensätze umwandelt. Mit Deep Lookup können Sie genau das abfragen, was Sie benötigen, und erhalten es in Form einer Tabelle zurück, die Sie verwenden können.
Anstatt Quellen zusammenzufügen oder komplexe Abfragen zu schreiben, beschreiben Sie die gewünschten Entitäten (Unternehmen, Produkte, Personen, Nachrichten, Eigenschaften), die Filter, die sie erfüllen müssen, und die Spalten, die Sie sehen möchten. Deep Lookup übernimmt die Filterung, Anreicherung und Strukturierung im Hintergrund, um analysefertige Ergebnisse zu liefern.
Wie Deep Lookup funktioniert
Deep Lookup unterstützt ein zweizeiliges Eingabeaufforderungsformat, etwa so:
- Finde alle … <Entitäten und Bedingungen>
- Anzeigen: <Spalten, die Sie wünschen>
Ein Deep-Lookup-Beispiel würde zum Beispiel so aussehen:
***Finde alle Amazon Beauty & Personal Care Produkte mit einem Preis ≤ $25 mit einer Bewertung ≥ 4 und auf Lager.***
***Anzeigen: Produktname, Marke, aktueller Preis, Bewertung, Anzahl der Rezensionen, Produkt-URL***
Deep Lookup nimmt diese Beschreibung und:
- Identifiziert die benötigten Datenquellen
- wendet Ihre Filter auf Datenbankebene an (nicht erst, nachdem alles heruntergeladen wurde)
- reichert die Ergebnisse mit zusätzlichem Kontext an
- liefert einen sauberen, strukturierten Datensatz, den Sie sofort verwenden können
Für komplexere Abfragen können Sie einen stärker strukturierten Ansatz verwenden:
FIND ALL: [Entitätstypen]
FILTERN:
- Bedingung #1
- Bedingung #2
ZEIGEN:
- Spalte #1 [Anreicherung oder Einschränkung]
- Spalte #2 [Bereicherung oder Einschränkung]
Der Hauptunterschied besteht darin, dass Sie die Geschäftslogik und nicht die technische Implementierung beschreiben. Sie müssen nicht wissen, auf welche API-Endpunkte Sie zugreifen müssen, wie Sie die Paginierung handhaben oder wo Sie Preisdaten von Wettbewerbern finden.
Die Datensätze, die Sie von Deep Lookup zurückerhalten, sind kuratiert, strukturiert und werden als Websets bereitgestellt. Websets sind verifiziert und vollständig zitiert, anpassbar (wählen Sie die genauen Felder) und so konzipiert, dass sie auf dem neuesten Stand bleiben, wenn Deep Lookup neue Quellen durchsucht.
In der Praxis sieht der Ablauf so aus:
- Stellen Sie Ihre Frage
- Crawl & Grund
- Erhalten Sie verwertbare Ergebnisse.
Sie können Websets nach Entität, Sektor, Geografie und Datenfeldern auf Ihren Anwendungsfall zuschneiden.
Schlusswort
Inzwischen haben Sie gesehen, dass Sie durch Datenfilterung unübersichtliche, überwältigende Informationen in klare Entscheidungen umwandeln können. Manuelles Filtern fördert die Intuition, aber Automatisierung sorgt für Schnelligkeit, Konsistenz und die Möglichkeit, Muster zu erkennen, die man in einer einzelnen Spalte nicht finden kann.
Genau hier setzt Bright Data an. Mit Deep Lookup geben Sie Ihre Kriterien in einfachem Englisch an und erhalten einen sauberen, strukturierten und stets aktuellen Datensatz, den Sie in Dashboards, Notebooks oder Modelle einfügen können. In Kombination mit den Bright Data-Datensätzen (wie dem Amazon-Datensatz in diesem Leitfaden) gelangen Sie von der Idee zur Erkenntnis bis zur Produktion, ohne brüchige Pipelines zu pflegen.
Sind Sie bereit zu sehen, was automatisierte Filterung für Ihre Daten leisten kann? Testen Sie Deep Lookup mit einem kostenlosen Bright Data-Konto. Nehmen Sie die Filterregeln, die Sie bisher manuell angewendet haben, und sehen Sie, welche Erkenntnisse Ihnen entgangen sind.






