Die Skalierung lokaler Scraping-Vorgänge von 1.000 auf 100.000 Seiten bedeutet in der Regel mehr Server, Proxys und Betriebsaufwand. Zielseiten werden schwieriger zu scrapen. Die Infrastrukturkosten steigen. Teams verbringen mehr Zeit mit der Reparatur von Scrapers als mit der Bereitstellung von Funktionen. In großem Maßstab ist Scraping kein Skript mehr, sondern wird zur Scraping-Infrastruktur.
Die Wahl zwischen lokalem und Cloud-Scraping wirkt sich auf drei Dinge aus: Kosten, Zuverlässigkeit und Liefergeschwindigkeit.
TL;DR
- Lokales Scraping läuft auf Ihren Rechnern. Sie haben die volle Kontrolle, müssen aber manuelle Wartungsarbeiten durchführen.
- Cloud-Scraping läuft auf einer Remote-Infrastruktur mit automatischer Skalierung und integrierter IP-Rotation.
- Wählen Sie lokales Scraping für weniger als 1.000 Seiten oder regulierte, nur intern verwendete Daten.
- Wählen Sie Cloud-Scraping für mehr als 10.000 Seiten, blockierte Websites oder eine Überwachung rund um die Uhr.
- IP-Blockierung ist der größte Engpass: 68 % der Teams nennen dies als ihre größte Herausforderung.
- In großem Maßstab kann Cloud-Scraping die Gesamtkosten um bis zu 70 % senken, indem es den DevOps-Overhead beseitigt.
- Bright Data bietet über 150 Millionen Residential-IPs, eine Verfügbarkeit von 99,9 % und eine wartungsfreie Ausführung.
Was ist lokales Scraping?
Lokales Scraping bedeutet, dass Sie den gesamten Stack besitzen – Code, IPs, Browser, aber auch Ausfälle und Ausfallzeiten. Sie führen Ihre Scraping-Skripte auf Ihrer Infrastruktur aus und verwalten die gesamte Pipeline selbst.
Es gibt keine verwaltete Infrastruktur-Ebene, sodass Sie bei Störungen selbst für die Behebung sorgen müssen.
So funktioniert lokales Scraping
Lokales Scraping folgt einer einfachen Ausführungsschleife. Ihr Skript sendet Anfragen, empfängt Antworten und extrahiert Daten aus HTML- oder gerenderten Seiten.
Anfragen stammen von Ihrer eigenen IP-Adresse oder von Proxys, die Sie konfigurieren. Wenn Websites den Traffic blockieren, müssen Sie die IPs rotieren und die Anfragen manuell wiederholen.
Für statische Seiten reicht ein einfacher HTTP-Client aus, aber für JavaScript-lastige Websites müssen Sie lokal Headless-Browser ausführen, um Inhalte vor der Extraktion zu rendern.
Darüber hinaus müssen Sie beim lokalen Scraping in der Regel CAPTCHAs und andere Anti-Bot-Maßnahmen manuell bearbeiten.
Dies funktioniert in kleinem Maßstab, aber mit zunehmendem Volumen wird das einfache Skript, mit dem Sie begonnen haben, schnell zu einem komplexen Infrastruktursystem, das Sie betreiben und warten müssen.
Vorteile des lokalen Scrapings
Da beim lokalen Scraping die Ausführung vollständig in Ihrer Umgebung bleibt, ist es ideal, wenn Sie Folgendes benötigen:
- Volle Kontrolle über die Ausführung: Sie verwalten den Zeitpunkt der Anfragen, die Header, die Logik des Parsings und die Speicherung.
- Keine Abhängigkeit von Dritten: Das Scraping läuft ohne externe Infrastruktur oder Anbieter.
- Schutz sensibler Daten: Die Daten bleiben in Ihrem Netzwerk.
- Hoher Lernwert: Sie arbeiten direkt mit Headern, Cookies, Ratenbeschränkungen und Fehlern.
- Geringe Einrichtungskosten für kleine Aufgaben: Ein Skript und ein Laptop reichen für das Scraping ungeschützter Websites mit geringem Volumen aus.
Einschränkungen des lokalen Scrapings
Lokales Scraping wird mit steigenden Anforderungen an Volumen und Zuverlässigkeit immer schwieriger aufrechtzuerhalten:
- Geringe Skalierbarkeit: Bei höheren Volumina müssen zusätzliche Server und Bandbreite gekauft werden.
- IP-Blockierung: Sie müssen Proxys beschaffen, rotieren und ersetzen, da Websites den Traffic blockieren.
- CAPTCHA-Unterbrechungen: Manuelles Lösen unterbricht die Automatisierung; automatisierte Lösungsprogramme verursachen zusätzliche Kosten und Latenzzeiten.
- JavaScript-intensive Browserausführung: JavaScript-intensive Websites erfordern lokale Browser, die viel CPU-Leistung und Speicherplatz beanspruchen.
- Kontinuierliche Wartung: Änderungen an Websites und Aktualisierungen der Erkennung erfordern häufige Code-Korrekturen und Neuimplementierungen.
- Fragile Zuverlässigkeit: Ausfälle stoppen die Datenerfassung, bis Sie eingreifen.
Beispiel: Lokales Scraping in Python
So sieht lokales Scraping mit Python in kleinem Maßstab aus:
import requests
from bs4 import BeautifulSoup
def scrape_products(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
return [
{
"name": item.find("h3").text.strip(),
"price": item.find("span", class_="price").text.strip(),
}
for item in soup.select(".product-card")
]
products = scrape_products("https://example.com/products")Dieses Skript wird lokal ausgeführt und verwendet Ihre echte IP-Adresse. Es verarbeitet problemlos mehrere hundert Seiten auf ungeschützten Websites.
Beachten Sie jedoch, was fehlt: Es gibt keine Proxy-Rotation, CAPTCHA-Verarbeitung, Wiederholungslogik oder Überwachung. Das Hinzufügen dieser Funktionen kann das Skript leicht aufblähen und seine Ausführung und Wartung erschweren.
Was ist Cloud-Scraping?
Beim Cloud Scraping wird die Ausführung außerhalb Ihrer Anwendung durchgeführt. Sie senden Anfragen an die API eines Anbieters und erhalten als Antwort die extrahierten Daten. Der Anbieter kümmert sich um den Betrieb des Proxy-Netzwerks und die gesamte erforderliche Scraping-Infrastruktur.
Plattformen wie Bright Data betreiben diese Infrastruktur im Produktionsmaßstab.
So funktioniert Cloud Scraping
Cloud Scraping folgt einem Anfrage-Ausführung-Antwort-Modell:
- Sie senden eine Scraping-Anfrage über die API eines Anbieters.
- Der Anbieter leitet die Anfrage über sein Proxy-Netzwerk weiter, und zwar auf einer Remote-Infrastruktur, nicht auf Ihren Rechnern.
- Wenn eine Website JavaScript erfordert, wird die Anfrage in einem verwalteten Browser ausgeführt. Die gerenderte Seite wird vor der Datenextraktion verarbeitet.
- Fehlgeschlagene Anfragen lösen Wiederholungsversuche basierend auf der vom Anbieter definierten Logik aus.
- CAPTCHA-Herausforderungen werden innerhalb der Ausführungsebene erkannt und gelöst.
- Sie erhalten die extrahierten Daten als Antwort.
Hier ist eine vereinfachte Übersicht über die Funktionsweise von Cloud Scraping: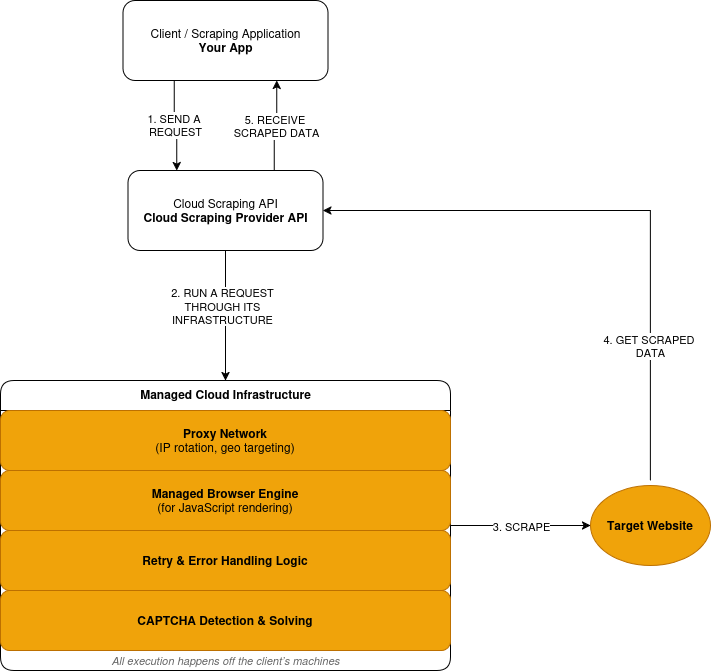
Vorteile von Cloud Scraping
Cloud Scraping begünstigt Skalierbarkeit, Zuverlässigkeit und reduzierten Betriebsaufwand:
- Verwaltete Ausführung: Anfragen werden auf der vom Anbieter betriebenen Infrastruktur ausgeführt.
- Integrierte Skalierbarkeit: Das Volumen steigt, ohne dass Sie neue Server kaufen müssen.
- Integrierte Anti-Bot-Behandlung: IP-Rotation und Wiederholungsversuche erfolgen automatisch.
- Browser-Infrastruktur enthalten: Der Scraping-Anbieter übernimmt das Rendern von JavaScript.
- Reduzierter Wartungsaufwand: Änderungen an der Website erfordern keine ständige Neuimplementierung mehr.
- Nutzungsbasierte Kosten: Die Preise richten sich nach dem Anfragevolumen.
Vor- und Nachteile von Cloud-Scraping
Cloud-Scraping reduziert den Betriebsaufwand, führt jedoch zu externen Abhängigkeiten. Ein Teil der Kontrolle verlagert sich außerhalb Ihrer Anwendungsgrenzen.
- Reduzierte Kontrolle auf niedriger Ebene: Timing, IP-Auswahl und Wiederholungsversuche folgen der Logik des Anbieters.
- Abhängigkeit von Dritten: Verfügbarkeit und Ausführung liegen außerhalb Ihres Systems.
- Kosten skalieren mit der Nutzung: Ein hohes Volumen erhöht die Ausgaben.
- Externe Fehlerbehebung: Bei Ausfällen sind die Transparenz und Unterstützung des Anbieters erforderlich.
- Compliance-Beschränkungen: Einige Daten dürfen kontrollierte Umgebungen nicht verlassen.
Beispiel: Web-Scraping mit hohem Volumen mit Bright Data Web Unlocker
Dies ist dieselbe Scraping-Aufgabe, die über eine cloudbasierte Ausführungsschicht ausgeführt wird.
import requests
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer API_KEY',
}
payload = {
'Zone': 'web_unlocker1',
'url': 'https://example.com/products',
'format': 'json'
}
response = requests.post('https://api.brightdata.com/request', json=payload, headers=headers)
print(response.json())Auf den ersten Blick ähnelt dies dem Beispiel für lokales Scraping. Es handelt sich weiterhin um eine einzelne HTTP-Anfrage. Der Unterschied besteht darin, wo die Anfrage ausgeführt wird.
Mit der Bright Data Web Unlocker API wird die Anfrage auf einer verwalteten Infrastruktur ausgeführt. IP-Rotation, Blockerkennung und Wiederholungsversuche finden außerhalb Ihrer Anwendung statt.
Cloud-Scraping vs. lokales Scraping: Direktvergleich
Hier sehen Sie einen Vergleich zwischen lokalem und Cloud-Scraping anhand der Faktoren, die sich tatsächlich auf Ihr Projekt auswirken.
| Faktor | Lokales Scraping | Cloud-Scraping | Vorteil von Bright Data |
|---|---|---|---|
| Infrastruktur | DIY-Einrichtung | Vollständig verwaltet | Globales Netzwerk in 195 Ländern |
| Skalierbarkeit | Begrenzt | Automatische Skalierung auf Milliarden/Monat | Milliarden Anfragen/Monat |
| IP-Blockierung | Hohes Risiko | Automatische Rotation | Über 150 Millionen Residential-IPs |
| Wartung | Manuell | Vom Anbieter verwaltet | 24/7-Überwachung |
| Kostenmodell | Fest + versteckt | Pay-as-you-go | Bis zu 70 % Kosteneinsparung |
| Anti-Bot | DIY | Integriert | 99,9 % CAPTCHA-Erfolg |
| Compliance | DIY | Variiert | SOC2, DSGVO, CCPA |
Kostenaufschlüsselung: Lokales Scraping vs. Cloud-Scraping
Lokales Scraping erscheint zunächst günstig, bis man alle Kosten berücksichtigt, die für den Betrieb erforderlich sind. Die größten Kosten entstehen hier nicht durch Server, sondern durch Ingenieure, die das Scraping warten, anstatt Funktionen zu entwickeln.
Beim Cloud-Scraping werden diese Kosten auf eine Preisgestaltung pro Anfrage umgelegt.
Kostenkomponenten des lokalen Scrapings
Lokales Scraping hat feste Kosten, die sich im Laufe der Zeit summieren.
- Server: Virtuelle Maschinen, Bandbreite, Speicherplatz.
- Proxys: Abonnements für private oder mobile IP-Adressen.
- CAPTCHA-Lösung: Lösungsdienste von Drittanbietern.
- Wartung: Arbeitszeit für Fehlerbehebungen und Updates.
- Ausfallzeiten: Verlorene Daten während Ausfällen.
Diese Kosten fallen unabhängig davon an, ob Sie Scraping betreiben oder nicht.
Kostenkomponenten beim Cloud-Scraping
Cloud-Scraping verwendet variable Preise, die an die Nutzung gebunden sind.
- Anfragen: Preise pro Anfrage oder pro Seite.
- Rendering: Höhere Kosten für die Ausführung von JavaScript.
- Datenübertragung: Gebühren basierend auf der Bandbreite.
Infrastruktur, Proxys und Wartung sind alle enthalten.
Kostenvergleich
| Kostenfaktor | Lokales Scraping | Cloud-Scraping | Bright Data |
|---|---|---|---|
| Serverkapazität | Feste monatliche Kosten | Enthalten | Enthalten |
| Proxy-Infrastruktur | Separates Abonnement | Inklusive | IP-Pool mit über 150 Millionen Adressen |
| CAPTCHA-Lösung | Separater Dienst | Enthalten | Enthalten |
| Wartungsaufwand | Laufende Entwicklungszeit | Vom Anbieter verwaltet | Keine Wartung |
| Ausfallzeiten | Von Ihrem Team übernommen | Reduziert durch den Anbieter | 99,9 % Verfügbarkeit SLA |
Beispiel für reale Kosten
Betrachten wir eine Arbeitslast , bei der monatlich 500.000 Seiten von geschützten Websites gescrapt werden.
Lokale Einrichtung:
- Server und Bandbreite: 300 $/Monat
- Residential-Proxys: 1.250 $/Monat
- CAPTCHA-Lösung: 150 $/Monat
- Technische Wartung: 3.000 $/Monat
- Gesamt: 4.700 $/Monat
Cloud-Einrichtung:
- Anfragen mit Rendering: 1.500 $/Monat
- Datenübertragung: 50 $/Monat
- Gesamt: 1.550 $/Monat
Der Cloud-Ansatz reduziert die monatlichen Kosten bei dieser Größenordnung um ~70 %.
Die Gewinnschwelle
- Unter 5.000 Seiten/Monat: lokale Lösungen sind oft vorteilhafter
- Zwischen 5.000 und 10.000 Seiten: Die Kosten gleichen sich an
- Über 10.000 Seiten: Cloud kostet in der Regel weniger
Oberhalb dieses Punktes steigen die lokalen Kosten linear an. Die Cloud-Kosten skalieren vorhersehbar mit der Nutzung.
Wann sollte lokales Scraping verwendet werden?
Lokales Scraping ist die richtige Wahl, wenn alle folgenden Bedingungen zutreffen:
- Sie scrapen weniger als 1.000 Seiten pro Durchlauf
- Die Zielseiten verfügen über einen minimalen Bot-Schutz
- Die Daten dürfen Ihre Umgebung nicht verlassen
- Sie akzeptieren manuelle Wartung
- Scraping ist nicht geschäftskritisch
Außerhalb dieser Bedingungen steigen Kosten und Risiken schnell an.
Wann sollte Cloud-Scraping verwendet werden?
Cloud-Scraping eignet sich, wenn eine der folgenden Bedingungen zutrifft:
- Das Volumen übersteigt 10.000 Seiten pro Monat
- Websites setzen aggressive Anti-Bot-Schutzmaßnahmen ein
- JavaScript-Rendering ist erforderlich
- Die Daten müssen kontinuierlich aktualisiert werden
- Zuverlässigkeit ist wichtiger als die Kontrolle über die Ausführung
An diesem Punkt wird der Besitz der Infrastruktur zu einer Belastung.
Wie Bright Data das Cloud-Scraping vereinfacht
Bright Data legt fest, wo das Scraping ausgeführt wird und welche Ebenen Sie nicht mehr betreiben. Es kümmert sich um die Infrastruktur, die das Scraping teuer in der Ausführung und Wartung macht:
- Netzwerkzugang: Weiterleitung von Anfragen über eine verwaltete Proxy-Infrastruktur
- Browser-Ausführung: Remote-Browser für JavaScript-intensive Websites.
- Anti-Bot-Maßnahmen: IP-Rotation, Blockerkennung und Wiederholungsversuche.
- Fehlerbehandlung: Ausführungskontrolle und Wiederholungslogik.
- Wartung: Laufende Updates bei Änderungen an Websites und Abwehrmaßnahmen.
- Sitzungssteuerung: Aufrechterhaltung von Sticky-Sessions über mehrere Anfragen hinweg.
- Geografische Präzision: Ziel-Land, Stadt, Netzbetreiber oder ASN.
- Fingerabdruck-Management: Reduzierung der Erkennung durch Fingerabdrücke auf Browser-Ebene.
- Verkehrskontrolle: Sichere Drosselung, Bursting oder Verteilung der Last.
Ausführungspfade und Tools
Bright Data stellt diese Infrastruktur über verschiedene Tools zur Verfügung, je nach Ihren Anforderungen.
Scraping-Browser-API
Verwenden Sie den Scraping-Browser, wenn Websites JavaScript-Rendering oder benutzerähnliche Interaktionen erfordern. Ihre bestehende Selenium- oder Playwright-Logik läuft auf von Bright Data gehosteten Browsern statt auf lokalen Instanzen.
Bright Data ersetzt lokale Browser-Cluster, Lebenszyklusmanagement und Ressourcenoptimierung.
Web Unlocker API
Verwenden Sie Web Unlocker für HTTP-basiertes Web-Scraping auf geschützten Websites. Bright Data leitet Anfragen über eine adaptive Proxy-Infrastruktur weiter und wendet die integrierte Blockbehandlung an.
Dadurch entfällt die Notwendigkeit, Proxys zu beschaffen, IPs zu rotieren oder Wiederholungslogik in Ihren Code zu schreiben.
Web Scraper APIs (vorgefertigte Datensätze)
Verwenden Sie Web Scraper APIs für standardisierte Plattformen wie Amazon, Google, LinkedIn und viele mehr. Es bietet über 150 vorgefertigte Scraper für alle wichtigen E-Commerce- und Social-Media-Plattformen.
Bright Data gibt strukturierte Daten ohne Browser-Automatisierung oder benutzerdefinierte Parser zurück. Dadurch entfällt die wartungsintensive Pflege von Scrapern für gängige Datenquellen.
Was aus Ihrem Stack verschwindet
Wenn Sie Bright Data verwenden, müssen Sie Folgendes nicht mehr betreiben:
- Proxy-Pools oder IP-Rotationslogik
- Lokale oder selbstverwaltete Browser-Cluster
- CAPTCHA-Lösung
- Benutzerdefinierten Code für Wiederholungsversuche und Blockerkennung
- Kontinuierliche Korrekturen für Website- und Erkennungsänderungen
Diese Betriebskosten summieren sich schnell bei lokalen und selbst erstellten Cloud-Konfigurationen.
Bright Data im Vergleich zu anderen Cloud-Scraping-Tools
Cloud-Scraping-Plattformen sind nicht austauschbar. Die richtige Wahl hängt davon ab, wie viel Scraping Sie durchführen, wie geschützt die Ziele sind und wie viel Infrastruktur Sie bereit sind zu betreiben.
Direkter Vergleich
| Anbieter | Größe | IP-Pool | Compliance | Am besten geeignet für |
|---|---|---|---|---|
| Bright Data | Unternehmen (Milliarden) | 150 Mio. | SOC2, DSGVO, CCPA | Groß angelegte Produktion |
| ScrapingBee | Klein- und mittelständische Unternehmen | Begrenzt | Teilweise | Einfache Projekte |
| Octoparse | GUI-basiert | Kleiner Pool | Begrenzt | Nicht-technische Benutzer |
Wo Bright Data zum Einsatz kommt
Bright Data eignet sich für Workloads, bei denen das Scraping kontinuierlich und betrieblich wichtig ist.
Dazu gehören Fälle, in denen:
- Das Volumen 10.000 Seiten pro Monat übersteigt
- Ziele moderne Anti-Bot-Abwehrmaßnahmen einsetzen
- JavaScript-Rendering erforderlich ist
- Daten in nachgelagerte Systeme oder Analysen eingespeist werden
- Scraping-Fehler geschäftliche Auswirkungen haben
In diesen Fällen sind die Kosten und Risiken der Infrastrukturbesitzerschaft wichtiger als die Einfachheit der API.
Wenn andere Tools ausreichen
Leichtere Cloud-Tools funktionieren, wenn die Einschränkungen geringer sind.
API-basierte Dienste eignen sich für:
- Kleine oder periodische Scraping-Aufgaben
- Websites mit begrenztem Schutz
- Workloads, bei denen gelegentliche Ausfälle akzeptabel sind
GUI-basierte Tools eignen sich für:
- Nicht-technische Benutzer
- Einmalige oder manuelle Datenerfassung
- Explorative oder Ad-hoc-Aufgaben
Diese Tools reduzieren den Einrichtungsaufwand, beseitigen jedoch nicht die betrieblichen Einschränkungen bei großem Umfang.
So treffen Sie die richtige Wahl
Die Entscheidung spiegelt die zuvor genannten Kosten- und Nutzungsschwellen wider:
- Wenn das Scraping geringfügig, selten oder nicht kritisch ist , reichen oft einfachere Tools aus .
- Wenn das Scraping kontinuierlich, geschützt oder geschäftskritisch ist, ist eine verwaltete Infrastruktur wichtig.
Fazit
Beginnen Sie mit lokalem Scraping, um zu lernen. Wenn Sie einen Scraper auf Ihrem eigenen Rechner ausführen, lernen Sie, wie Anfragen, Parsing und Fehler funktionieren. Für kleine Aufträge mit weniger als 1.000 Seiten ist dieser Ansatz oft ausreichend.
Wechseln Sie zu Cloud-Scraping, wenn sich die Kosten aufgrund von Umfang oder Schutz ändern. Sobald das Volumen 10.000 Seiten pro Monat überschreitet, Ziele moderne Anti-Bot-Abwehrmaßnahmen einsetzen oder Daten kontinuierlich aktualisiert werden müssen, wird der Besitz der Infrastruktur zum Hindernis.
Lokales Scraping gibt Ihnen Kontrolle und Verantwortung. Cloud-Scraping tauscht einen Teil der Kontrolle gegen vorhersehbare Ausführung, geringeres Betriebsrisiko und skalierbare Kosten ein.
Für Produktions-Workloads ist Cloud-Scraping eine Infrastruktur. Sie würden auch keine eigenen CDN- oder E-Mail-Server in großem Umfang betreiben. Die Scraping-Infrastruktur folgt derselben Logik.
Wenn Ihr Anwendungsfall diesem Profil entspricht, können Sie mit Plattformen wie Bright Data die Extraktionslogik beibehalten und gleichzeitig die Ausführung und Wartung aus Ihrem Stack auslagern.
FAQs: Cloud-Scraping vs. lokales Scraping
Was ist lokales Scraping?
Lokales Scraping läuft auf Maschinen, die Sie kontrollieren. Sie verwalten Anfragen, Proxys, Browser, Wiederholungsversuche und Fehler selbst. Es eignet sich am besten für kleine, seltene Aufgaben auf leicht geschützten Websites.
Was ist Cloud-Scraping?
Cloud-Scraping läuft auf einer von einem Drittanbieter betriebenen Infrastruktur. Sie senden Anfragen an eine API und erhalten als Antwort die extrahierten Daten. Der Scraping-Anbieter kümmert sich um die Ausführung, Skalierung, IP-Rotation, CAPTCHA-Lösung, Überwindung von Anti-Bot-Maßnahmen und vieles mehr.
Wann sollte ich von lokalem zu Cloud-Scraping wechseln?
Wechseln Sie, wenn einer der folgenden Fälle eintritt:
- IP-Sperren nach begrenztem Anfragevolumen
- CAPTCHAs unterbrechen die Automatisierung
- Das Volumen übersteigt 10.000 Seiten pro Monat
- JavaScript-Rendering wird erforderlich
- Scraping-Fehler beeinträchtigen nachgelagerte Systeme
An diesem Punkt wird der Besitz der Infrastruktur zu einer Belastung.
Ist Cloud-Scraping teurer als lokales Scraping?
Lokale Setups verursachen Kosten für Server, Proxy, Wartung und Ausfallzeiten. Die Cloud-Preise skalieren mit der Nutzung und eliminieren feste Infrastrukturkosten.
- In kleinem Maßstab ist lokales Scraping oft günstiger
- In großem Maßstab kostet Cloud-Scraping in der Regel weniger
Kann Cloud-Scraping JavaScript-lastige Websites verarbeiten?
Ja. Cloud-Plattformen betreiben verwaltete Browser, die JavaScript remote ausführen.
Beim lokalen Scraping müssen Sie selbst Headless-Browser ausführen, was die Parallelität einschränkt und den Wartungsaufwand erhöht.
Wie reduziert Cloud-Scraping die IP-Blockierung?
Cloud-Anbieter betreiben große Proxy-Netzwerke und verwalten das Request-Routing. IP-Rotation und Wiederholungslogik finden auf Infrastruktur-Ebene statt.
Ist Cloud-Scraping für sensible oder regulierte Daten geeignet?
Nicht immer. Einige Workloads können aufgrund von Richtlinien oder Vorschriften kontrollierte Umgebungen nicht verlassen. Bright Data bietet jedoch Scraping-Lösungen , die vollständig SOC2-, DSGVO- und CCPA-konform sind .
Kann ich lokales und Cloud-Scraping kombinieren?
Ja, aber die Komplexität steigt.
Einige Teams entwickeln und testen Scraper lokal und führen dann Produktions-Workloads in der Cloud aus. Dies erfordert die Pflege von zwei Ausführungsumgebungen und die Bewältigung der Unterschiede zwischen ihnen.
Die meisten Teams wählen einen Ansatz, der auf ihren primären Einschränkungen basiert.
Welche Teams profitieren am meisten von Cloud-Scraping-Plattformen wie Bright Data?
Teams, die Scraping als kontinuierliches oder geschäftskritisches System betreiben. Dazu gehören Workloads mit hohem Volumen, geschützten Zielen, JavaScript-Rendering oder begrenzter Bandbreite.