
In diesem Artikel behandeln wir folgende Themen:
- ETL-Pipeline erklärt
- Vorteile von ETL-Pipelines
- Wie man eine ETL-Pipeline in einem Unternehmen implementiert
- Automatisierung einiger Schritte der ETL-Pipeline
- Häufig gestellte Fragen zu ETL-Pipelines
ETL-Pipeline erklärt
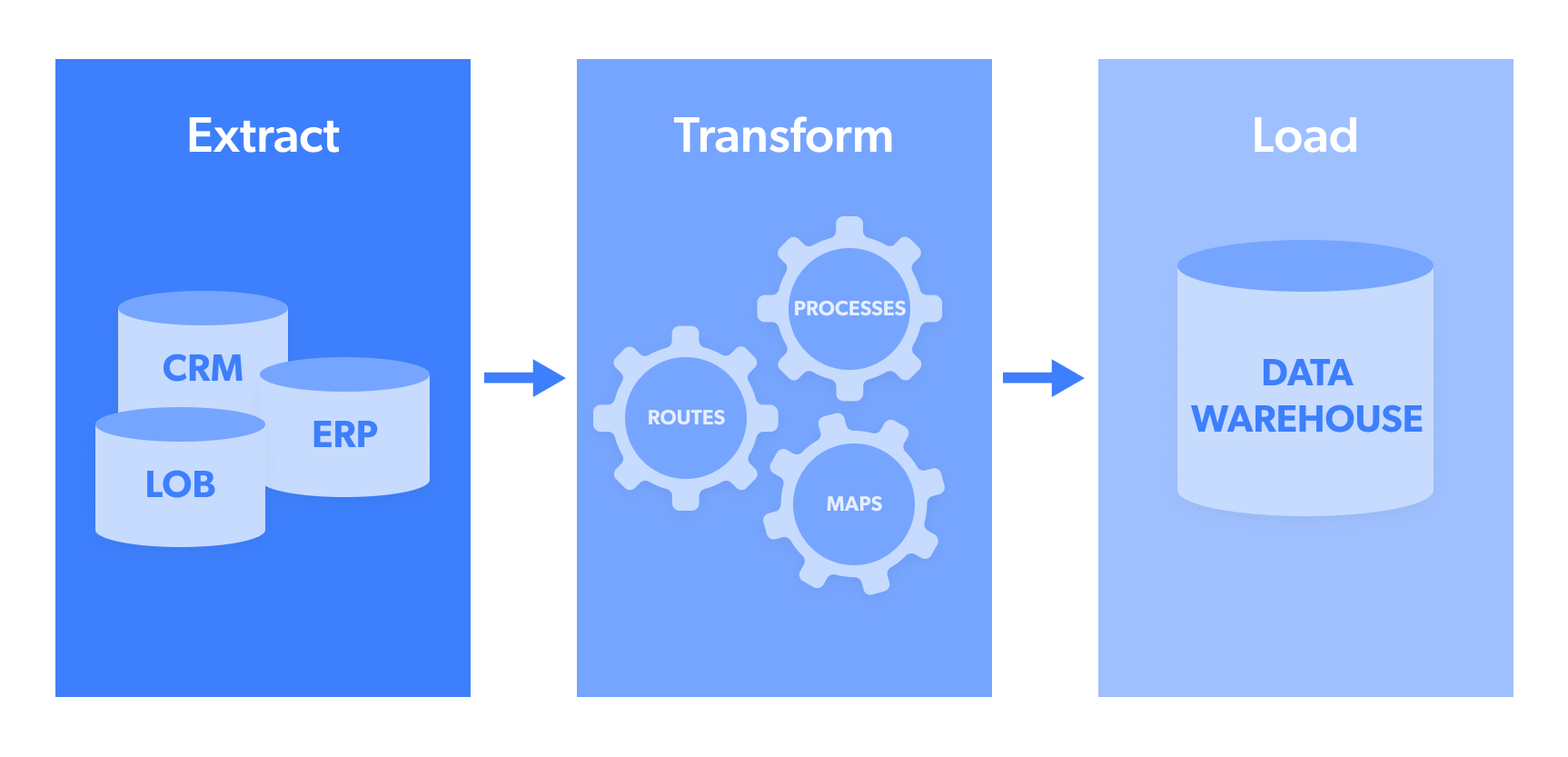
ETL steht für:
- Extrahieren: Dies ist die Phase der Datenextraktion aus einer Quelle oder einem Datenpool, z. B. einer NoSQL-Datenbank oder einer Open-Source-Zielwebsite wie Trendbeiträgen in sozialen Medien.
- Transformieren: Extrahierte Daten werden in der Regel in verschiedenen Formaten erfasst. „Transformieren” bezieht sich auf den Prozess der Strukturierung dieser Daten, sodass sie in einem einheitlichen Format vorliegen, das dann an das Zielsystem gesendet werden kann. Dazu können Formate wie JSON, CSV, HTML oder Microsoft Excel gehören.
- Load (Laden): Dies ist die eigentliche Übertragung/der eigentliche Upload der Daten in einen Datenpool/ein Data Warehouse, ein CRM oder eine Datenbank, damit sie anschließend analysiert und in umsetzbare Ergebnisse umgewandelt werden können. Zu den am häufigsten verwendeten Datenzielen gehören Webhook, E-Mail, Amazon S3, Google Cloud, Microsoft Azure, SFTP oder API.
Zu beachten:
- ETL-Pipelines eignen sich besonders für kleinere Datensätze mit höherer Komplexität.
- „ETL-Pipelines” werden oft mit„Datenpipelines”verwechselt – letzteres ist ein weiter gefasster Begriff für Architekturmodelle zur vollständigen Datenerfassung, während ersteres ein gezielteres Verfahren ist.
Vorteile von ETL-Pipelines
Zu den wichtigsten Vorteilen von ETL-Pipelines gehören:
Erstens: Rohdaten aus mehreren Quellen
Unternehmen, die schnell wachsen möchten, können von starken ETL-Pipeline-Architekturen profitieren, da sie damit ihren Blickwinkel erweitern können. Dies wird dadurch erreicht, dass ein guter ETL-Datenaufnahmefluss es Unternehmen ermöglicht, Rohdaten in verschiedenen Formaten aus mehreren Quellen zu sammeln und diese effizient zur Analyse in ihre Systeme einzugeben. Das bedeutet, dass die Entscheidungsfindung viel stärker an den aktuellen Trends bei Verbrauchern und Wettbewerbern ausgerichtet ist.
Zweitens: Verkürzung der „Zeit bis zur Erkenntnis“
Wie bei jedem operativen Ablauf kann die Zeit von der ersten Erfassung bis zur umsetzbaren Erkenntnis erheblich verkürzt werden, sobald dieser in Gang gesetzt wurde. Anstatt dass Datenexperten jeden Datensatz manuell überprüfen, in das gewünschte Format konvertieren und dann an den Zielort senden müssen, wird dieser Prozess rationalisiert, was schnellere Erkenntnisse ermöglicht.
Drittens: Freisetzung von Unternehmensressourcen
Anknüpfend an den letzten Punkt – gute ETL-Pipelines tragen dazu bei, Unternehmensressourcen auf vielen Ebenen freizusetzen, darunter auch Personal. Unternehmen verbringen tatsächlich
„verbringen über 80 % ihrer Zeit mit der Bereinigung von Daten zur Vorbereitung auf den Einsatz von KI”.
Datenbereinigung bezieht sich in diesem Fall unter anderem auf die „Datenformatierung”, um die sich solide ETL-Pipelines kümmern.
Wie man eine ETL-Pipeline in einem Unternehmen implementiert
Hier ist ein Anwendungsfall aus dem E-Commerce, der veranschaulicht, wie eine ETL-Pipeline in einem Unternehmen implementiert werden kann:
Ein digitales Einzelhandelsunternehmen muss viele verschiedene Datenpunkte aus unterschiedlichen Quellen aggregieren, um wettbewerbsfähig zu bleiben und für seine Zielkunden attraktiv zu sein. Beispiele für Datenquellen sind unter anderem:
- Bewertungen, die für konkurrierende Anbieter auf Marktplätzen hinterlassen wurden
- Google-Suchtrends für Artikel/Dienstleistungen
- Werbung (Texte + Bilder) von Konkurrenzunternehmen
All diese Datenpunkte können in verschiedenen Formaten wie (.txt), (.csv), (.tab), SQL, (.jpg) und anderen gesammelt werden. Zielinformationen in mehreren Formaten sind für die Geschäftsziele des Unternehmens nicht förderlich (d. h. Gewinnung von Erkenntnissen über Wettbewerber/Verbraucher in Echtzeit und Vornahme von Änderungen, um höhere Umsätze zu erzielen).
Aus diesem Grund entscheidet sich dieser E-Commerce-Anbieter möglicherweise für die Einrichtung einer ETL-Pipeline, die alle oben genannten Formate in eines der folgenden Formate konvertiert (basierend auf den Algorithmus-/Eingabesystempräferenzen):
- JSON
- CSV
- HTML
- Microsoft Excel
Angenommen, er wählt Microsoft Excel als bevorzugtes Ausgabeformat für die Anzeige der Produktkataloge von Mitbewerbern. Ein Vertriebszyklus- und Produktionsmanager kann diese dann schnell überprüfen und neue Produkte identifizieren, die von Mitbewerbern verkauft werden und die er möglicherweise in seinen eigenen digitalen Katalog aufnehmen möchte.
Automatisierung einiger Schritte der ETL-Pipeline
Viele Unternehmen verfügen einfach nicht über die Zeit, die Ressourcen und das Personal, um Datenerfassungsvorgänge sowie die ETL-Pipeline manuell einzurichten. In solchen Fällen entscheiden sie sich für ein vollautomatisches Tool zur Extraktion von Webdaten.
Diese Art von Technologie ermöglicht es Unternehmen, sich auf ihre eigenen Geschäftsabläufe zu konzentrieren und gleichzeitig autonome ETL-Pipeline-Architekturen zu nutzen, die von einem Drittanbieter entwickelt und betrieben werden. Zu den wichtigsten Vorteilen dieser Option gehören:
- Webdatenextraktion ohne Infrastruktur/Code
- Kein zusätzlicher technischer Personalaufwand erforderlich
- Die Daten werden automatisch bereinigt, durch Parsing verarbeitet und synthetisiert und in einem einheitlichen Format Ihrer Wahl (JSON, CSV, HTML oder Microsoft Excel) bereitgestellt. Dieser Schritt ersetzt die ETL-Pipeline und wird automatisch ausgeführt.
- Die Daten werden dann an den Verbraucher auf Unternehmensseite (z. B. ein Team, einen Algorithmus oder ein System) geliefert. Dazu gehören Webhook, E-Mail, Amazon S3, Google Cloud, Microsoft Azure, SFTP oder API.
Neben automatisierten Datenextraktions-Tools gibt es auch eine effiziente und nützliche Abkürzung, die nicht viele Menschen kennen. Viele Unternehmen beschleunigen die „Zeit bis zur Datenauswertung“, indem sie die Notwendigkeit der Datenerfassung und ETL-Pipelines vollständig beseitigen. Dazu nutzen sie die Leistungsfähigkeit von gebrauchsfertigen Datensätzen, die bereits einheitlich formatiert sind und direkt an interne Datenverbraucher geliefert werden.
Fazit
ETL-Pipelines sind eine effektive Möglichkeit, die Datenerfassung aus mehreren Quellen zu optimieren, den Zeitaufwand für die Gewinnung verwertbarer Erkenntnisse aus Daten zu verringern und geschäftskritische Arbeitskräfte und Ressourcen freizusetzen. Doch trotz der Effizienzvorteile, die ETL-Pipelines bieten, erfordern sie immer noch einen erheblichen Zeit- und Arbeitsaufwand für die Entwicklung und den Betrieb. Aus diesem Grund entscheiden sich viele Unternehmen dafür, ihre Datenerfassung und ihren ETL-Pipeline-Flow mit Tools wie dem Web-Scraping-Tool von Bright Data auszulagern und zu automatisieren. Kontaktieren Sie uns, um die ultimative Lösung für Ihr Datenprojekt zu finden.
Häufig gestellte Fragen zu ETL-Pipelines
ETL steht für „Extract, Transform, Load” (Extrahieren, Transformieren, Laden). Es handelt sich um einen Prozess, mit dem Daten aus mehreren Quellen erfasst und einheitlich formatiert werden, damit sie von einem Zielsystem oder einer Zielanwendung verarbeitet werden können.
Das Laden ist der letzte Schritt im ETL-Prozess, bei dem die Daten in einem einheitlichen Format in einen Datenpool oder ein Data Warehouse hochgeladen werden, damit sie verarbeitet/analysiert/ausgewertet werden können. Die drei wichtigsten Arten des Ladens sind 1. Erstladungen 2. Inkrementelle Ladungen 3. Vollständige Aktualisierungen
Ja, es ist durchaus möglich, eine ETL-Pipeline mit Python zu erstellen. Dazu sind verschiedene Tools erforderlich, darunter „Luigi” zur Verwaltung des Workflows und „Pandas” für die Datenverarbeitung und -bewegung.






