
In diesem Artikel werden wir folgende Themen behandeln:
- Was ist eine Datenpipeline?
- Wie eine gute Datenpipeline-Architektur Unternehmen helfen kann
- Beispiele für Datenpipeline-Architekturen
- Datenpipeline vs. ETL-Pipeline
Was ist eine Datenpipeline?
Eine Datenpipeline ist der Prozess, den Daten durchlaufen. In der Regel findet ein vollständiger Zyklus zwischen einem „Zielort“ und einem „Datensee oder -pool“ statt, der ein Team bei seinem Entscheidungsprozess oder einen Algorithmus bei seinen Funktionen im Bereich der KI unterstützt. Ein typischer Ablauf sieht in etwa so aus:
- Erfassung
- Erfassung
- Aufbereitung
- Berechnung
- Präsentation
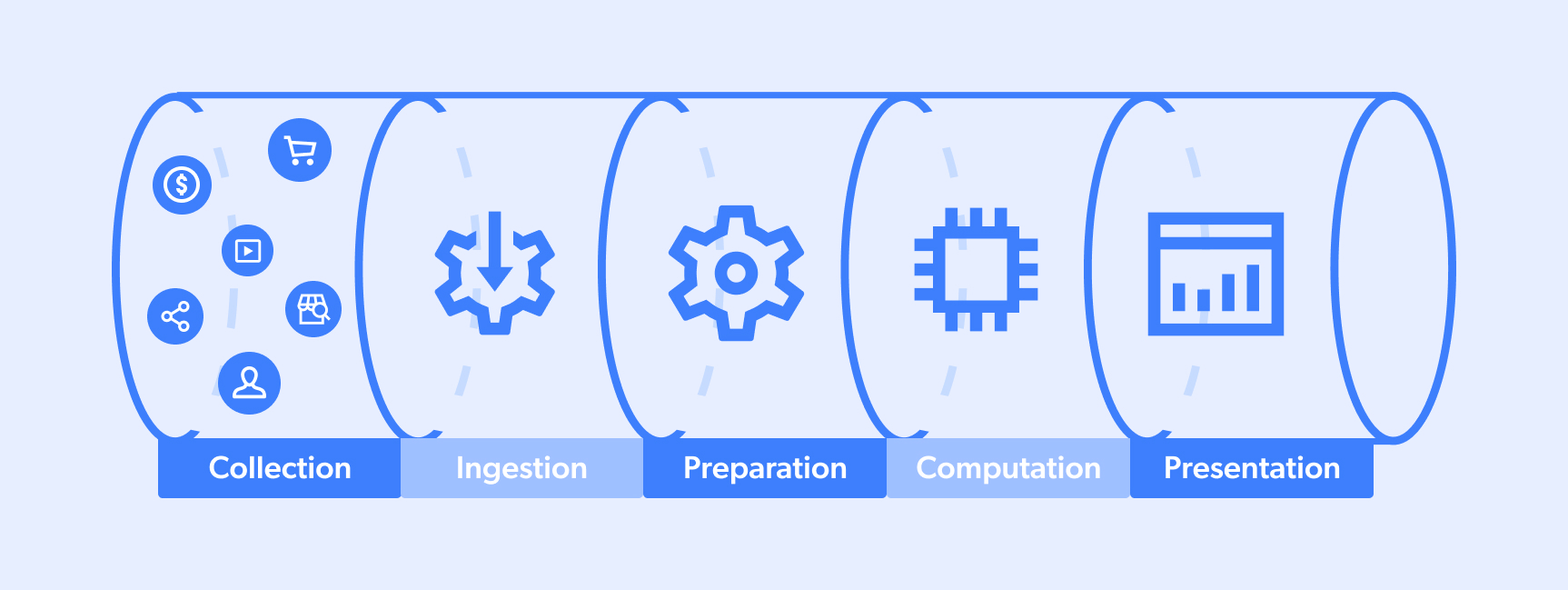
Beachten Sie jedoch, dass Datenpipelines mehrere Quellen/Ziele haben können und dass manchmal Schritte gleichzeitig stattfinden können. Außerdem können bestimmte Pipelines teilweise sein (z. B. Nummern 1-3 oder 3-5).
Was ist eine Big-Data-Pipeline?
Big-Data-Pipelines sind operative Abläufe, die sich mit der Erfassung, Verarbeitung und Implementierung von Daten in großem Umfang befassen. Dahinter steht die Idee, dass je größer die „Datenerfassung” ist, desto geringer die Fehlerquote bei wichtigen Geschäftsentscheidungen ist.
Zu den beliebten Anwendungen einer Big-Data-Pipeline gehören:
- Prädiktive Analysen: Algorithmen sind in der Lage, beispielsweise Vorhersagen zum Aktienmarkt oder zur Produktnachfrage zu treffen. Diese Fähigkeiten erfordern ein „Datentraining” unter Verwendung historischer Datensätze, die es den Systemen ermöglichen, menschliche Verhaltensmuster zu verstehen, um potenzielle zukünftige Ergebnisse vorherzusagen.
- Echtzeit-Markterfassung: Dieser Ansatz berücksichtigt, dass sich beispielsweise die aktuelle Verbraucherstimmung sporadisch ändern kann. Daher werden große Mengen an Informationen aus verschiedenen Quellen aggregiert, z. B. durch die Erfassung von Daten aus sozialen Medien, E-Commerce-Marktplätzen und Werbeanzeigen von Wettbewerbern in Suchmaschinen. Durch den Abgleich dieser einzigartigen Datenpunkte in großem Maßstab können bessere Entscheidungen getroffen werden, was zu einem höheren Marktanteil führt.
Durch die Nutzung einer Datenerfassungsplattform sind die operativen Abläufe der Big-Data-Pipeline in der Lage, Folgendes zu bewältigen:
- Skalierbarkeit – Datenmengen schwanken häufig, und Systeme müssen mit der Fähigkeit ausgestattet sein, Ressourcen auf Befehl zu aktivieren/deaktivieren.
- Fluidität – Bei der Erfassung großer Datenmengen aus mehreren Quellen müssen Big-Data-Verarbeitungsprozesse in der Lage sein, Daten in vielen verschiedenen Formaten (z. B. JSON, CSV, HTML) zu verarbeiten und über das Know-how verfügen, um unstrukturierte Daten von Zielwebsites zu bereinigen, abzugleichen, zu synthetisieren, zu verarbeiten und zu strukturieren.
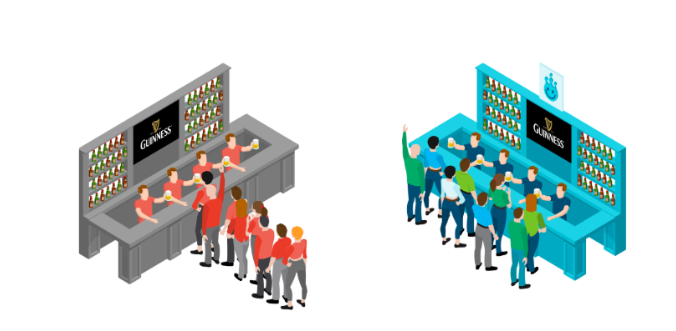
- Verwaltung gleichzeitiger Anfragen – Or Lenchner, CEO von Bright Data, drückt es gerne so aus: „Die Datenerfassung in großem Umfang ist wie das Warten auf Bier in einer Schlange bei einem Musikfestival. Gleichzeitige Anfragen sind kurze, schnelle Schlangen, in denen man schnell/gleichzeitig bedient wird. Die andere Schlange ist langsam/aufeinanderfolgend. Wenn Ihr Geschäftsbetrieb davon abhängt, in welcher Schlange würden Sie lieber stehen?“
Wie eine gute Datenpipeline-Architektur Unternehmen helfen kann
Hier sind einige der wichtigsten Möglichkeiten, wie eine gute Datenpipeline-Architektur zur Rationalisierung der täglichen Geschäftsprozesse beitragen kann:
Erstens: Datenkonsolidierung
Daten können aus vielen verschiedenen Quellen stammen, z. B. aus sozialen Medien, Suchmaschinen, Aktienmärkten, Nachrichtenagenturen, Verbraucheraktivitäten auf Marktplätzen usw. Datenpipelines fungieren als Trichter, der all diese Daten an einem einzigen Ort zusammenführt.
Zweitens: Reibungsreduzierung
Datenpipelines reduzieren Reibungsverluste und verkürzen die Zeit bis zur Erkenntnisgewinnung, indem sie den Aufwand für die Bereinigung und Aufbereitung der Daten für die erste Analyse verringern.
Drittens: Datenkompartimentierung
Eine intelligent implementierte Datenpipeline-Architektur stellt sicher, dass nur relevante Stakeholder Zugriff auf bestimmte Informationen erhalten, sodass jeder einzelne Akteur auf Kurs bleibt.
Viertens: Datenuniformität
Daten kommen in vielen verschiedenen Formaten aus einer Vielzahl von Quellen. Die Datenpipeline-Architektur sorgt für Einheitlichkeit und ermöglicht das Kopieren/Verschieben/Übertragen zwischen verschiedenen Speichern/Systemen.
Beispiele für Datenpipeline-Architekturen
Datenpipeline-Architekturen müssen Faktoren wie das voraussichtliche Erfassungsvolumen, die Herkunft und den Zielort der Daten sowie die Art der möglicherweise erforderlichen Verarbeitung berücksichtigen.
Hier sind drei archetypische Beispiele für Datenpipeline-Architekturen:
- Eine Streaming-Datenpipeline: Diese Datenpipeline ist für eher Echtzeit-Anwendungen gedacht. Ein Beispiel hierfür ist ein Online-Reisebüro (OTA), das Daten zu Preisen, Paketen und Werbekampagnen von Wettbewerbern sammelt. Diese Informationen werden verarbeitet/formatiert und dann an die entsprechenden Teams/Systeme zur weiteren Analyse und Entscheidungsfindung weitergeleitet (z. B. an einen Algorithmus, der für die Neufestsetzung von Ticketpreisen auf der Grundlage von Preissenkungen bei Wettbewerbern zuständig ist).
- Eine batchbasierte Datenpipeline: Hierbei handelt es sich um eine einfachere/geradlinigere Architektur. Sie besteht in der Regel aus einem System/einer Quelle, das/die eine große Menge an Datenpunkten generiert, die dann an einen Zielort (d. h. eine „Einrichtung” zur Datenspeicherung/Analyse) geliefert werden. Ein gutes Beispiel hierfür wäre ein Finanzinstitut, das große Datenmengen zu Käufen/Verkäufen/Volumen von Anlegern an der Nasdaq sammelt. Diese Informationen werden zur Analyse weitergeleitet und dann für das Portfoliomanagement verwendet.
- Eine hybride Datenpipeline: Diese Art von Ansatz ist bei sehr großen Unternehmen/Umgebungen beliebt, da er sowohl Echtzeit-Einblicke als auch Batch-Verarbeitung/Analyse ermöglicht. Viele Unternehmen, die sich für diesen Ansatz entscheiden, bevorzugen es, Daten im Rohformat zu speichern, um eine größere Vielseitigkeit in Bezug auf neue Abfragen/strukturelle Änderungen der Pipeline zu ermöglichen.
Datenpipeline vs. ETL-Pipeline
ETL-Pipelines (Extraction, Transformation, and Loading) dienen in der Regel der Speicherung und Integration. Sie fungieren in der Regel als Mittel, um Daten aus unterschiedlichen Quellen zu sammeln, in ein universelleres/zugänglicheres Format zu übertragen und in ein Zielsystem hochzuladen. ETL-Pipelines ermöglichen es uns in der Regel, Daten zu sammeln, zu speichern und für den schnellen Zugriff/die schnelle Analyse vorzubereiten.
Bei einer Datenpipeline geht es eher darum, einen systemischen Prozess zu schaffen, in dem Daten gesammelt, formatiert und an Zielsysteme übertragen/hochgeladen werden können. Datenpipelines sind eher ein Protokoll, das sicherstellt, dass alle Teile der „Maschine” wie vorgesehen funktionieren.
Fazit
Die Suche und Implementierung der für Ihr Unternehmen geeigneten Datenpipeline-Architektur ist für Ihren geschäftlichen Erfolg von entscheidender Bedeutung. Unabhängig davon, ob Sie sich für einen Streaming-, Batch- oder Hybrid-Ansatz entscheiden, sollten Sie Technologien einsetzen, die Ihnen helfen, Lösungen zu automatisieren und an Ihre spezifischen Anforderungen anzupassen.






