

In diesem Artikel erfahren Sie:
- Ob synthetische Daten wirklich die Zukunft des KI- und ML-Trainings sind.
- Was echte Web-Daten sind, welche Haupttypen es gibt und wie man sie in großem Maßstab sammelt.
- Was synthetische Daten sind, wie sie kategorisiert werden können und wie sie erfolgreich generiert werden.
- Die Auswirkungen von synthetischen vs. echten Daten in Bezug auf Kosten, Datenschutz, Robustheit und Verteilungsqualität.
- Wie die Datenwahl die KI-Trainingspipeline und die Modellleistung beeinflusst.
- Warum ein hybrider Ansatz, der beide Datentypen kombiniert, oft die effektivste Strategie ist.
- Die Vor- und Nachteile jedes Ansatzes.
Legen wir los.
Sind synthetische Daten die Zukunft von KI/ML, oder sind Web-Daten noch relevant?
Die KI-Skalierungsgesetze zeigen, dass die Leistung tendenziell steigt, wenn Modelle mit mehr Parametern, mehr Rechenleistung und vor allem mehr Daten trainiert werden. Mit anderen Worten: Größere Modelle benötigen exponentiell größere Datensätze, um Leistungsgewinne aufrechtzuerhalten.
Historisch gesehen bildeten echte Web-Daten die Grundlage des modernen KI-Trainings, aber hochwertige Web-Daten sind endlich. Bekanntlich erklärte Elon Musk, dass KI-Unternehmen keine Trainingsdaten mehr haben und das gesamte verfügbare menschliche Wissen für das Modelltraining “ausgeschöpft” haben.
Darüber hinaus werden Web-Daten zunehmend dupliziert und sind teuer zu sammeln, bereinigen und rechtlich zu prüfen. Dies unterstreicht auch die Bedeutung der Auswahl von Web-Datensatz-Anbietern, die KI-optimierte, regelmäßig aktualisierte und datenschutzkonforme Datensätze liefern.
Dieser Druck beschleunigt das Interesse an alternativen Datenquellen, insbesondere an synthetischen Daten. Laut Gartner sollen synthetische Daten bis 2030 echte Daten im KI-Modelltraining übertreffen. Das Unternehmen führt diesen Wandel auf strengere Datenschutzanforderungen, die Knappheit realer Daten und den Wunsch nach kostengünstigeren Alternativen zurück.
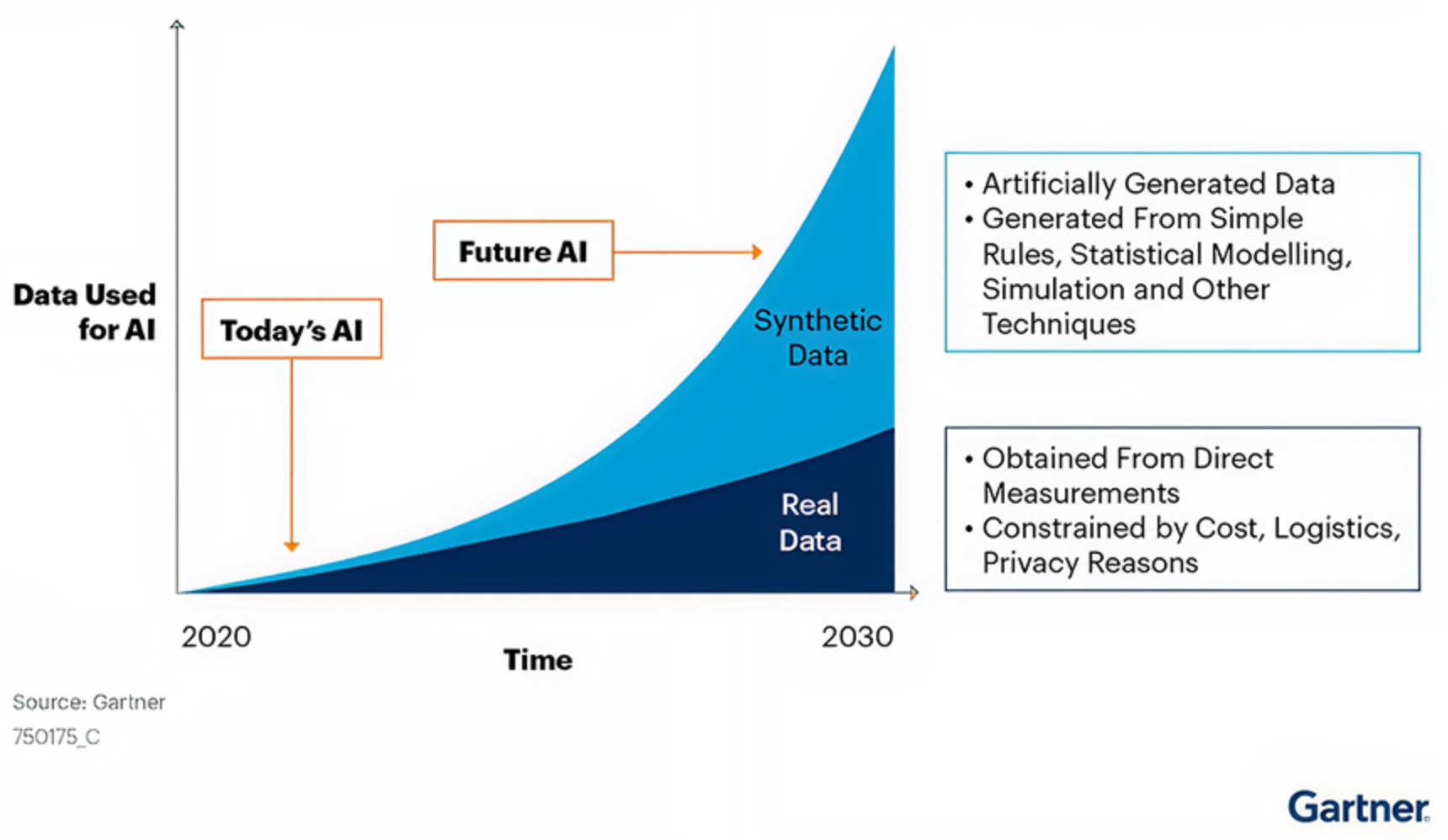
Gleichzeitig sollte diese Prognose eher als Schätzung denn als Gewissheit betrachtet werden. Das Internet erzeugt weiterhin enorme Mengen an Inhalten, mit etwa 402 Millionen Terabyte Web-Daten, die täglich erstellt werden!
Zum Vergleich: GPT-3 wurde auf rund 45 Terabyte Rohtext vor der Filterung trainiert. Dieser Vergleich zeigt, dass webbasierte, vom Menschen generierte Daten weiterhin umfangreich und für das KI-Training hochrelevant sind.
Daher wird die Zukunft des KI-Trainings voraussichtlich nicht ausschließlich von synthetischen Daten abhängen. Stattdessen erwarten viele ML-Experten einen hybriden Ansatz, auf den wir später in diesem Artikel eingehen werden.
Synthetische Daten vs. echte Web-Daten: Ein Vergleich der beiden Datenparadigmen
In den folgenden Kapiteln erfahren Sie, was synthetische Daten und echte Web-Daten sind, was sie bieten und wie sie sich in verschiedenen Aspekten des KI-Modelltrainings vergleichen. Wir beginnen mit echten Web-Daten, da diese intuitiver zu verstehen sind, und gehen dann zu synthetischen Daten über.
Für einen schnellen Überblick auf hoher Ebene werfen Sie einen Blick auf die folgende Tabelle zum Vergleich synthetischer und echter Web-Daten:
| Echte Web-Daten | Synthetische Daten | |
|---|---|---|
| Definition | Aus echten Web-Quellen gesammelte Daten | Künstlich generierte Daten, die reale Verteilungen mithilfe von Modellen oder Regeln imitieren |
| Beispiele | Webseiten, Foren, Nachrichtenartikel, Produktseiten, PDFs usw. | LLM-generierter Text, GAN-Bilder, simulierte Robotik-Umgebungen, regelbasierte Datensätze usw. |
| Primäres Ziel | Erfassung realer Komplexität und natürlichem Verhalten | Steigerung von Skalierung, Abdeckung und Steuerbarkeit |
| Datentypen | Unstrukturiert (Text, Bilder), halbstrukturiert (JSON, XML) | Strukturiert, halbstrukturiert, unstrukturiert (Text, Bild, Audio, Video) |
| Wie es gewonnen wird | Hauptsächlich Web-Scraping | LLM-Generierung, GANs, VAEs, regelbasierte Systeme, Simulationsmaschinen |
| Datenschutzrisiko | Höher (personenbezogene Daten, Compliance erforderlich) | Gering (keine echten Nutzerdaten bei korrekter Generierung) |
| Datenqualität | Verrauscht, inkonsistent, aber authentisch | Sauber, strukturiert, kann aber Artefakte oder Halluzinationen enthalten |
| Verteilung | Natürliche, reale Verteilung | Kontrolliert, kann jedoch synthetische Verzerrungen oder Verschiebungen einführen |
| Robustheit | Starke Generalisierung auf reale Eingaben | Stark für gezielte Szenarien, schwächere Generalisierung |
| Long-Tail-Abdeckung | Natürlich vorhanden, aber spärlich | Kann explizit generiert und überabgetastet werden |
| Verzerrungsrisiko | Spiegelt reale Verzerrungen wider | Kann neue Verzerrungen verstärken oder einführen |
| Typische Pipeline-Rolle | Vortraining, Feinabstimmung, Evaluierung | Vortraining, Augmentierung, Generierung von Grenzfällen |
| Risiken | Datenmangel, Compliance-Einschränkungen, Rauschen | Synthetisch-zu-real-Lücke, Modell-Kollaps, halluzinierte Muster |
Jetzt ist es an der Zeit, in die zwei zentralen Datenparadigmen einzutauchen, die das moderne KI-Training prägen!
Die Welt der echten Web-Daten erkunden
Hier erfahren Sie alles, was Sie über echte Web-Daten für das KI-Modelltraining wissen müssen.
Was sind Web-Daten?
Web-Daten sind Informationen, die von Webseiten und anderen öffentlichen Web-Quellen gesammelt werden, hauptsächlich durch Web-Scraping. Sie umfassen unstrukturierte Inhalte wie Text, Bilder, Code, Metadaten und Dokumente (z. B. PDFs) sowie halbstrukturierte Daten wie JSON und XML.
Arten von Web-Daten
Es gibt viele mögliche Kategorien von Web-Daten. Auf hoher Ebene, besonders im KI-Kontext, ist es sinnvoll, zwischen zwei Haupttypen zu unterscheiden:
- Historische Web-Daten: Typischerweise durch Web-Scraping-Pipelines gesammelt, dann bereinigt, angereichert, dedupliziert und in strukturierten Datensätzen in Formaten wie CSV, JSON und Parquet aggregiert. Diese Datensätze werden für das Vortraining und die Feinabstimmung von Modellen verwendet.
- Live-Web-Daten: In Echtzeit von Webseiten durch Scraping oder APIs abgerufen. Sie spiegeln die aktuellsten verfügbaren Informationen im Internet wider. Dies macht sie besonders nützlich für die Verankerung von KI-Antworten und für RAG-Systeme, bei denen Aktualität und sachliche Genauigkeit entscheidend sind.
Zusammen erfüllen diese beiden Formen von Web-Daten komplementäre Rollen in modernen KI-Systemen.
Wie man Web-Daten erhält
Um Web-Daten für das KI/ML-Training zu beschaffen, benötigen Sie eine skalierbare Web-Scraping-Pipeline. Der Aufbau einer solchen Infrastruktur im eigenen Haus erfordert erhebliches technisches Know-how.
Dabei müssen eine Vielzahl von Anti-Scraping-Herausforderungen wie IP-Sperren, CAPTCHA-Lösungen und Rate-Limiter bewältigt werden. Zudem sind starke Data-Engineering-Fähigkeiten für Bereinigung, Deduplizierung und Normalisierung erforderlich. Daher verlassen sich Unternehmen bevorzugt auf dedizierte Web-Daten-Plattformen wie Bright Data.
Bright Data bietet ein End-to-End-Ökosystem für die Sammlung und Bereitstellung von Web-Daten. Was es auszeichnet, ist sein Netzwerk von über 400 Millionen Residential-IPs in 195 Ländern, das eine hochskalierbare und gleichzeitige Web-Datenerfassung unterstützt. Diese Enterprise-Infrastruktur ist zudem GDPR- und CCPA-konform sowie mit anderen Datenschutz- und Sicherheitsstandards vereinbar.
Das Angebot von Bright Data für Web-Daten umfasst:
- Web-Daten-Marktplatz: Eine Sammlung von über 350 gebrauchsfertigen Datensätzen aus über 250 Domänen (darunter Reddit, Amazon, LinkedIn, Yahoo Finance und viele andere). Diese Datensätze umfassen über 17 Petabyte Web-Daten und sind für ML-Training und KI-Anwendungen optimiert. Sie werden in mehreren Formaten wie JSON, CSV und Parquet über Cloud-Lieferung und andere Vertriebswege bereitgestellt.
- Web-Scraping-Produkte: Eine Reihe von API-basierten Lösungen für die Live-Web-Datenextraktion:
– Web Unlocker API: Umgeht Sperren und CAPTCHAs, um den Datenzugriff auf jeder Webseite sicherzustellen.
– SERP-API: Liefert strukturierte Echtzeit-Suchmaschinenergebnisse von Google, Bing, Yandex und anderen.
– Discover API: Gibt eine gerankte, aktuelle Menge von URLs aus dem öffentlichen Web zurück, bereit für die nachgelagerte Verarbeitung.
– Crawl API: Führt skalierbares Website-Crawling und strukturierte Datenextraktion durch.
– Scraper-APIs: Decken über 120 Websites für die direkte strukturierte Datenextraktion aus populären Domänen ab.
Bright Data bietet auch verwaltete Dienste für schlüsselfertige Datenakquisition an. Diese ermöglichen es Unternehmen, sich auf die Modellentwicklung statt auf Data-Engineering zu konzentrieren.
Eintauchen in die Welt der synthetischen Daten
In diesem Kapitel erkunden Sie die Verwendung synthetischer Daten für das KI/ML-Modelltraining.
Was sind synthetische Daten?
Synthetische Daten sind künstlich generierte Informationen, die die statistischen Muster und Eigenschaften realer Daten nachbilden. Anstatt aus echten Ereignissen gesammelt zu werden, werden sie künstlich erzeugt.
Arten synthetischer Daten
Synthetische Daten können kategorisiert werden:
- Nach Zusammensetzung und Datenschutzniveau:
– Vollständig synthetisch: Vollständig von Grund auf mit ML-Modellen generiert, die auf echten Daten trainiert wurden. Da keine originalen Datenpunkte enthalten sind, bietet dies das höchste Datenschutzniveau.
– Teilweise synthetisch: Nimmt einen vorhandenen echten Datensatz und ersetzt nur die sensiblen Attribute (wie Namen, Adressen oder Sozialversicherungsnummern) durch künstliche Werte. Dies bewahrt spezifische Datentrends, während personenbezogene Daten anonymisiert werden.
– Hybrid: Kombiniert echte, anonymisierte Datensätze mit künstlich generierten. Dies wird häufig verwendet, um Datensätze durch künstlich erzeugte seltene Ereignisse zu “upsampling” oder anzureichern (z. B. synthetische Betrugsfälle zu einem Bankdatensatz hinzuzufügen).
- Nach Datenstruktur:
– Strukturierte Daten: Hochorganisierte, quantitative Daten in tabellarischen Formaten.
– Unstrukturierte Daten: Qualitative oder medienlastige Datenformate. Dazu gehören synthetischer Text, künstlich generierte Bilder, Video und Audio.
Wie synthetische Daten erzeugt werden
Auf hoher Ebene können synthetische Daten mit drei vorherrschenden Ansätzen generiert werden:
- Vollständig KI-generiert: Erstellt mit Modellen wie GANs (Generative Adversarial Networks), VAEs (Variational Autoencoders) oder LLMs. Diese Systeme lernen die zugrunde liegende Verteilung realer Datensätze und generieren dann völlig neue Stichproben, die den Originaldaten ähneln, ohne sie direkt zu kopieren.
- Regelbasierte Generierung: Daten werden mithilfe vordefinierter, manuell erstellter Regeln, Einschränkungen oder Geschäftslogik erzeugt. Dies gewährleistet strikte Konsistenz, strukturelle Korrektheit und kontrolliertes Verhalten, was es für Systeme nützlich macht, die vorhersagbare Ausgaben erfordern.
- Simulierte oder Mock-Daten: Durch physikalische oder verhaltensbasierte Simulationen generiert. Dies wird häufig in Umgebungen wie autonomem Fahren oder Robotik eingesetzt, wo digitale Zwillinge und Physik-Engines realistische ‘Was-wäre-wenn’-Szenarien erstellen.
Auswirkungen synthetischer Daten vs. echter Web-Daten auf das KI/ML-Modelltraining
Vergleichen wir nun verschiedene Aspekte, um die Konsequenzen der Verwendung synthetischer vs. echter Web-Daten für das KI-Training zu verstehen.
Datenverteilung und Realismus
Web-Daten approximieren eine natürliche Datenverteilung eng. Sie erfassen die inhärente Komplexität menschlicher Sprache und Verhaltensweisen, wie sie in der realen Welt vorkommen. Dies bringt wichtige Vorteile mit sich, darunter natürliche Korrelationen zwischen Merkmalen, authentische Grenzfälle, vielfältige sprachliche Stile und realistisches Rauschen wie menschliche Fehler, Mehrdeutigkeiten und Inkonsistenzen.
Reale Web-Daten sind jedoch auch von Natur aus unordentlich. Sie sind oft unausgewogen, dupliziert, schwer in großem Maßstab zu kuratieren und können minderwertige oder Spam-Inhalte enthalten, die aufwändige Filterung erfordern.
Im Gegensatz dazu repräsentieren synthetische Daten eine kontrollierte Verteilung. Sie werden absichtlich entworfen und generiert, sodass Praktiker Datensatz-Eigenschaften präzise gestalten können. Dies ermöglicht ausgewogene Klassenverteilungen, gezielte Abdeckung spezifischer Szenarien, Generierung seltener Ereignisse und strukturiertes Curriculum-Lernen.
Gleichzeitig bringen synthetische Daten wichtige Risiken mit sich, darunter Verteilungsverschiebungen, unrealistische Artefakte, Mode-Kollaps und Überregularisierung, wenn der Generator zu stark eingeschränkt ist.
Wichtig: Ein zentrales ML-Konzept in diesem Zusammenhang ist die synthetisch-zu-real-Lücke, ähnlich dem Sim-to-Real-Problem in der Robotik. Modelle, die stark auf synthetischen Daten trainiert wurden, können bei realistischen Eingaben schlechter abschneiden, da die generierte Verteilung die Realität nicht vollständig abbildet.
Long-Tail-Abdeckung
Echte Web-Daten enthalten von Natur aus ein breites Wissensspektrum. Dazu gehören obskure Fakten, seltene Ereignisse und unerwartete Grenzfälle, die organisch aus menschlicher Aktivität entstehen. Dennoch sind diese Long-Tail-Beispiele von Natur aus spärlich. Per Definition treten seltene Ereignisse selten auf, was es Modellen erschwert, robuste Muster daraus während des Trainings zu lernen.
Andererseits können synthetische Daten verwendet werden, um seltene oder unterrepräsentierte Szenarien explizit zu generieren. So können Sie gezielt Lücken in einem Datensatz schließen und die Abdeckung verbessern, wo echte Daten unzureichend sind. Beispiele hierfür sind seltene Coding-Bugs und ressourcenarme Sprachen.
Ein großer Vorteil der Verwendung synthetischer Daten für die Long-Tail-Abdeckung ist die Möglichkeit, seltene Ereignisse zu überabtasten. Dies kann helfen, Klassenungleichgewichte zu reduzieren und die Modellleistung bei seltenen, aber wichtigen Fällen zu verbessern. Werden seltene Szenarien jedoch künstlich überrepräsentiert, können die gelernten Priors des Modells verzerrt werden.
Wenn beispielsweise Cybersecurity-Exploit-Fälle in synthetischen Daten stark überabgetastet werden, könnte das Modell beginnen, deren Wahrscheinlichkeit in realen Umgebungen zu überschätzen. Daher ist eine sorgfältige Kalibrierung unerlässlich, um sicherzustellen, dass die synthetische Long-Tail-Generierung die Abdeckung verbessert, ohne unrealistische Verteilungen einzuführen.
Kosten- und Datenschutzaspekte
Wie bereits erwähnt, bauen Unternehmen selten ihre eigene Web-Scraping- und Datensatz-Infrastruktur auf. Stattdessen verlassen sie sich auf Drittanbieter wie Bright Data, die Crawling, Entsperrung, Bereinigung und Lieferung abstrahieren. Dies verändert grundlegend sowohl die Kostenstruktur als auch die Datenschutz-Kompromisse der Datenbeschaffung.
Nachfolgend finden Sie einen vereinfachten Überblick über das Preismodell von Bright Data für die Web-Datenerfassung:
| Preis | Individuelle Pläne für Unternehmen | GDPR-konform | CCPA-konform | Konform mit SEC-Vorschriften | |
|---|---|---|---|---|---|
| Datensätze | Von 0,001 bis 0,0025 USD pro Datensatz | ✔️ | ✔️ | ✔️ | ✔️ |
| Web-Scraping-APIs | 1–1,50 USD / 1.000 Ergebnisse | ✔️ | ✔️ | ✔️ | ✔️ |
Bright Data bietet auch Datenannotationsdienste an und hilft Unternehmen, die Abhängigkeit von internem Data-Engineering weiter zu reduzieren. Wichtig ist, dass seine Daten auf Datenschutz-Frameworks ausgerichtet sind, was rechtliche und regulatorische Risiken mindert.
Ohne solche Web-Daten-Anbieter müssten Sie Infrastrukturentwicklung, laufende Wartung und die komplexe Governance personenbezogener Daten, urheberrechtlich geschützter Materialien und sensibler Verhaltensdaten intern verwalten.
Bei synthetischen Daten entstehen die primären Kosten durch Inferenz-Computing und den Zugang zu Teacher-Modellen oder APIs. Aus Datenschutzsicht bieten künstlich generierte Daten einen inhärenten Vorteil. Da sie generiert und nicht von echten Personen gesammelt werden, eliminieren synthetische Daten von Natur aus die Exposition gegenüber personenbezogenen Daten.
Die richtige Wahl zwischen synthetischen und echten Web-Daten hängt von Qualitätsanforderungen, Skalierung, Datenschutzbeschränkungen und dem Ziel-Anwendungsfall ab. Je nach diesen Faktoren kann jeder Ansatz kosteneffizienter oder teurer als der andere sein.
Datenqualitätsfaktoren
Web-Daten bieten im Allgemeinen schwache Supervision. Modelle lernen aus natürlich vorkommenden Signalen wie Next-Token-Vorhersage, Metadaten und menschlich generierten Inhalten. Das Problem ist, dass echte Daten verrauscht sind und Fehlinformationen, Widersprüche, Spam, voreingenommene Meinungen und inkonsistente Formatierungen enthalten können.
Im Gegensatz dazu bieten synthetische Daten eine größere Kontrolle über Qualität und Supervision. Sie können perfekt formatierte Labels, strukturierte Ausgaben, schrittweise Begründungen und automatisch verifizierte Beispiele liefern. Synthetische Datensätze können beispielsweise mathematisch verifizierte Antworten oder durch Unit-Tests validierte Code-Snippets enthalten. Dies verbessert die Konsistenz und erleichtert gezieltes Training.
Das Hauptrisiko bei synthetischen Daten besteht darin, dass ihre Qualität grundlegend durch die Qualität des generierenden Modells, Algorithmus oder zugrunde liegenden Ansatzes begrenzt ist. Generierte Halluzinationen oder sachliche Fehler können sich in den endgültigen Datensatz einschleichen und dazu führen, dass Modelle mit Zuversicht falsche Muster lernen. Ebenso können versteckte Verzerrungen in Generierungssystemen von nachgelagerten Modellen übernommen werden. Auf der positiven Seite unterstützt synthetische Daten ein stärkeres Alignment- und Safety-Tuning.
Generalisierung und Robustheit
Eine der wichtigsten Fragen im maschinellen Lernen ist, wie gut ein Modell auf unbekannte Eingaben generalisiert. Mit anderen Worten: Welche Datenquelle führt zu besserer Robustheit bei Verteilungsverschiebungen: echte Web-Daten oder synthetische Daten?
Web-Daten neigen dazu, starke Robustheit zu erreichen, da sie natürlich vorkommendes menschliches Verhalten, Sprache und Rauschen widerspiegeln. Dies verbessert die Leistung bei Out-of-Distribution-Eingaben und verbessert den Domain-Transfer, insbesondere wenn Modelle in unvorhersehbaren Umgebungen eingesetzt werden.
Synthetische Daten hingegen eignen sich besser für gezielte Optimierung. Sie ermöglichen es, Trainingsbeispiele für spezifische Fähigkeiten, Grenzfälle oder seltene Szenarien präzise zu gestalten.
Wichtige Überlegungen beim KI-Training mit synthetischen oder echten Web-Daten
Nachdem Sie die Unterschiede zwischen synthetischen und Web-Daten kennen, sind Sie bereit, die praktischen Implikationen der Verwendung jedes Ansatzes im KI-Modelltraining zu sehen.
Daten-Trainingspipelines
Bei der Verwendung von Web-Daten folgt die Pipeline typischerweise diesen Schritten:
- Crawling: Rohdaten von Websites mithilfe groß angelegter Scraping-Systeme oder benutzerdefinierter Web-Scraping-Bots über mehrere Domänen hinweg sammeln.
- Deduplizierung: Doppelte oder nahezu doppelte Inhalte entfernen, um Redundanz zu reduzieren und die Vielfalt und Effizienz des Datensatzes zu verbessern.
- Spracherkennung: Die Sprache jeder Stichprobe identifizieren und den Datensatz basierend auf Zielsprachanforderungen filtern oder segmentieren.
- Qualitätsbewertung: Inhalte mithilfe von Heuristiken oder Modellen bewerten und einordnen, um minderwertige oder irrelevante Informationen herauszufiltern.
- Toxizitätsfilterung: Schädliche, unsichere oder unangemessene Inhalte erkennen und entfernen, um Trainingssicherheit und Compliance zu gewährleisten.
- Entfernung personenbezogener Daten und Dekontaminierung: Personenbezogene Informationen entfernen und Kontaminationen aus sensiblen oder unerwünschten Quellen eliminieren.
Bei synthetischen Datenpipelines sind die Schritte stärker generierungsorientiert:
- Prompt-Generierung: Prompts oder Vorlagen entwerfen, die die Struktur, Aufgabe oder das Szenario für die synthetische Datenerstellung definieren.
- Modell-Sampling: Kandidaten-Ausgaben mit generativen Modellen wie LLMs, GANs oder anderen Systemen generieren.
- Verifikation: Ausgaben mithilfe automatisierter Prüfungen, Regeln oder externer Tools validieren, um Korrektheit und Konsistenz sicherzustellen.
- Filterung: Minderwertige, inkonsistente oder halluzinierte Stichproben entfernen, die vordefinierten Standards nicht entsprechen.
- Reward-Scoring: Qualitäts- oder Präferenz-Scores zuweisen, um die besten synthetischen Beispiele zu bewerten und auszuwählen.
- Iterative Verfeinerung: Datenqualität verbessern durch wiederholte Zyklen aus Generierung, Filterung und Re-Sampling, um die Robustheit zu steigern.
Wie Sie sehen, konzentrieren sich echte Web-Daten-Pipelines auf die Bereinigung verrauschter realer Eingaben. Synthetische Pipelines hingegen drehen sich mehr um die Steuerung und Validierung generierter Ausgaben. Sobald der Trainingsdatensatz erstellt wurde, können Sie mit dem Training des KI-Modells fortfahren.
Leistungsvergleich
Die abschließende Frage ist, ob synthetische Daten echte Web-Daten übertreffen können.
Ein aktuelles Paper zu KI für Requirements Engineering (AI4RE) legt nahe, dass LLM-generierte Datensätze eine starke Alternative sein können, wenn echte Daten knapp oder schwer zugänglich sind. Empirische Ergebnisse zeigen, dass Modelle, die ausschließlich auf synthetischen Daten trainiert wurden, jene übertreffen können, die nur auf menschlich erstellten Datensätzen trainiert wurden. Im Detail wurden Verbesserungen von bis zu +37% bei der Präzision und +30% beim Recall im Vergleich zu reinen Echtdaten-Baselines beobachtet.
Das ist jedoch keine binäre oder absolute Schlussfolgerung. Die Erkenntnisse legen nicht nahe, dass synthetische Daten echte Daten vollständig ersetzen sollten, sondern dass die beste Leistung oft durch einen hybriden Ansatz erzielt wird. Erfahren Sie mehr darüber!
Synthetische Daten + echte Web-Daten: Warum ein hybrider Ansatz am besten funktioniert
Die Debatte zwischen synthetischen und echten Web-Daten geht nicht mehr darum, sich für eine Seite zu entscheiden, sondern darum, wie man sie kombiniert.
Aktuelle Erkenntnisse zeigen, dass hybride Konfigurationen, die synthetische und echte Daten kombinieren, Verbesserungen von bis zu +85% bei der Präzision und eine Verdopplung des Recalls im Vergleich zur ausschließlichen Verwendung echter Web-Daten erzielen.
Gleichzeitig heben mehrere Studien und Branchenberichte hervor, dass das naive Mischen synthetischer und echter Stichproben die Leistung tatsächlich verschlechtern kann, aufgrund von Verteilungsunstimmigkeiten, Redundanz oder Bias-Verstärkung. Dies macht deutlich, dass Leistungsgewinne von sorgfältigem Datensatz-Design abhängen und nicht von bloßer Datenakkumulation.
Eine zentrale offene Frage ist das optimale Verhältnis zwischen synthetischen und echten Daten. Es gibt keine universelle Antwort. Einige Praktiker verwenden eine Pareto-ähnliche 80/20-Aufteilung (hauptsächlich echte Daten mit synthetischer Augmentierung), während andere ausgeglichenere Mischungen wie 60/40 bevorzugen, je nach Aufgabenkomplexität, Domain-Risiko und Datenverfügbarkeit.
Ebenso ist die Platzierung synthetischer Daten in der Pipeline entscheidend. Die Branchenpraxis empfiehlt eine gestufte Strategie: synthetisch-lastiges Vortraining für die Abdeckung, gefolgt von echtem Daten-Finetuning für Verankerung und Evaluierung.
Letztendlich funktionieren hybride Pipelines am besten, weil sie komplementäre Stärken kombinieren. Synthetische Daten bieten Skalierung und Grenzfall-Abdeckung, während echte Web-Daten Treue, Realismus und zuverlässige Evaluierung in Produktionsumgebungen gewährleisten.
Echte Web-Daten vs. synthetische Daten: Vor- und Nachteile
Als Zusammenfassungsabschnitt sehen Sie die Vor- und Nachteile der beiden Datenparadigmen.
Echte Web-Daten
👍 Vorteile:
- Erfasst authentische reale Muster und Rauschen
- Starker Benchmark für Evaluierung und Validierung
- Reduziert das Risiko synthetischer Verzerrungen oder Artefakte
👎 Nachteile:
- Teuer und zeitaufwändig zu sammeln und zu beschriften
- Kann durch Datenschutz- und regulatorische Einschränkungen begrenzt sein
- Kann unausgewogen oder unvollständig sein
Synthetische Daten
👍 Vorteile:
- Hochskalierbar und schnell zu generieren
- Kann seltene Ereignisse und Grenzfälle simulieren
- Unterstützt datenschutzerhaltende Trainingspipelines
👎 Nachteile:
- Risiko einer Domain-Lücke gegenüber realen Daten
- Erfordert sorgfältige Validierung und Qualitätskontrolle
- Kann im Vergleich zu echten Daten an Vielfalt mangeln, was zu Overfitting auf synthetische Artefakte führt
Echte Web-Daten + synthetische Daten
👍 Vorteile:
- Kombiniert Skalierung (synthetisch) mit Realismus (echte Daten)
- Erzielt in der Praxis oft die beste Leistung
- Stärkere Robustheit bei Grenzfällen und Normalfällen
👎 Nachteile:
- Erfordert sorgfältige Abstimmung und Anpassung der Verhältnisse
- Risiko von Leistungsverschlechterungen bei schlechter Mischung
- Komplexeres Pipeline-Design und aufwändigere Wartung
Fazit
In diesem Blogbeitrag zu synthetischen Daten vs. echten Web-Daten haben Sie die Auswirkungen der Verwendung realer oder künstlich generierter Daten für das KI/ML-Modelltraining kennengelernt. Wie immer in solchen Situationen gibt es keinen eindeutigen Gewinner. Der richtige Ansatz hängt von Ihrem spezifischen Budget, Ihren technischen Fähigkeiten und Ihren Leistungszielen ab.
Unabhängig vom Setup spielen Web-Daten weiterhin eine zentrale Rolle im KI-Modelltraining, sei es für das Vortraining oder das abschließende Finetuning. Ihre breite Abdeckung und reale Verankerung machen sie unverzichtbar. Einige Unternehmen bevorzugen jedoch stärker synthetisch-orientierte Ansätze. Der Hauptgrund ist die Komplexität des Aufbaus und der Pflege von Web-Daten-Abruf-Pipelines im eigenen Haus.
Hier kann Bright Data helfen. Mit einer Enterprise-tauglichen, hochskalierbaren und konformen Infrastruktur bietet es:
- Web-Datensätze: Über 350 fertige Datensätze mit Milliarden von Datensätzen, bereits gesammelt, kuratiert und für KI-Trainingszwecke optimiert.
- Web-Scraping-Produkte: API-basierte Lösungen für den Zugriff auf aktuelle Web-Daten von vielen Websites in großem Maßstab.
Darüber hinaus bietet Bright Data Datenannotationsdienste an. Es bietet skalierbare, genaue und anpassbare Beschriftungslösungen für NLP-, Computer-Vision- und Spracherkennungs-Anwendungsfälle.
Entdecken Sie alle Bright-Data-Lösungen für KI!
Erstellen Sie kostenlos ein Bright-Data-Konto und erkunden Sie unsere Web-Daten-Lösungen!





