

In diesem Blogbeitrag erfahren Sie:
- Was Amazon SageMaker ist und welchen Mehrwert es für maschinelles Lernen bietet.
- Warum Web-Daten für erfolgreiches Feature Engineering unverzichtbar sind.
- Wo Sie hochwertige Web-Daten für Feature Engineering und andere Machine-Learning-Szenarien abrufen können.
- Wie Sie Feature Engineering in Amazon SageMaker mit Datensätzen durchführen, die Web-Daten speichern.
Legen wir los!
Was ist Amazon SageMaker?
Amazon SageMaker ist ein vollständig verwalteter Dienst, der Ihnen hilft, Machine-Learning-Modelle und KI-Anwendungen in großem Maßstab zu erstellen, zu trainieren und bereitzustellen. Er bietet eine einheitliche End-to-End-Umgebung für Analysen und KI.
Er ermöglicht den Zugriff auf Daten aus mehreren Quellen, ob in Amazon-S3-Data-Lakes, Redshift-Data-Warehouses oder Drittanbieter- und Verbundsystemen gespeichert – und das bei garantierter Sicherheit und Governance auf Enterprise-Niveau.
Kurz gesagt vereinfacht SageMaker ML-Workflows und beschleunigt die Modellentwicklung, vom Feature Engineering bis zur Modellbereitstellung. Das sind die wichtigsten Funktionen und Möglichkeiten, die es Ihnen bietet:
- SageMaker Unified Studio: Eine einzige Entwicklungsumgebung zum Erstellen, Trainieren und Bereitstellen von ML- und generativen KI-Modellen mit vollständig verwalteter Infrastruktur und integrierten Tools.
- Modellentwicklung und MLOps: Umfasst vorgefertigte Templates, HyperPod und JumpStart für schnelles Prototyping, Training und die Operationalisierung von Modellen.
- Generative KI-Unterstützung: Erstellen und skalieren Sie Anwendungen mit Amazon Bedrock und nutzen Sie integrierte KI-Assistenten wie Amazon Q Developer.
- Datenverarbeitung und SQL-Analysen: Bereiten Sie Daten mit Open-Source-Frameworks auf Amazon Athena, EMR, Glue und Redshift vor, analysieren und integrieren Sie sie.
- Lakehouse-Architektur: Vereinheitlicht den Zugriff auf isolierte Daten über Speichersysteme hinweg zur Unterstützung umfassender Analysen und KI.
Eine Einführung in Feature Engineering mit Web-Daten
Feature Engineering ist der Prozess der Umwandlung von Rohdaten in aussagekräftige Variablen, sogenannte “Features”, die Machine-Learning-Modelle effektiver nutzen können. Anstatt einem Modell unverarbeitete Daten zuzuführen, geht es darum, abgeleitete Metriken zu erstellen, die Muster im Quelldatensatz besser erfassen.
Beispiele hierfür sind das Aggregieren von Werten, das Normalisieren von Scores, das Kombinieren verwandter Variablen oder das Erstellen von Verhältnissen, die Beziehungen zwischen verschiedenen Feldern hervorheben. Gutes Feature Engineering kann sogar einen größeren Einfluss auf die Modellleistung haben als die Wahl des Algorithmus selbst. Das liegt daran, dass gut gestaltete Features Modellen helfen, Signale zu erkennen, die sonst verborgen bleiben würden.
Web-Daten sind für Feature Engineering besonders wertvoll, da sie reale Aktivitäten in großem Maßstab widerspiegeln. Öffentliche Websites enthalten große Mengen an Informationen über Unternehmen, Produkte, Jobs, Bewertungen, Preise und Nutzerverhalten. Diese Signale können in Features wie Popularitätsindikatoren, Marktnachfragemetriken, Sentiment-Scores oder Einstellungstrends umgewandelt werden. Solche Features können die Leistung Ihrer Machine-Learning-Pipelines erheblich verbessern.
Die Arbeit mit Web-Daten bringt jedoch auch einige Herausforderungen mit sich. Die Daten können fehlerhaft, unvollständig oder inkonsistent sein. Dies kann die Qualität der Eingabedaten erheblich beeinträchtigen. Zudem setzen viele Websites Anti-Bot-Maßnahmen ein.
Daher ist der Einsatz von Web-Scraping für maschinelles Lernen eine knifflige Angelegenheit. Die gesammelten Daten müssen bereinigt, validiert und aufbereitet werden, bevor sie in einer ML-Pipeline verwendet werden können.
Wo Sie hochwertige Web-Daten in großen Mengen abrufen können
Wie Sie vielleicht verstanden haben, spielen Web-Daten eine zentrale Rolle beim Feature Engineering. Gleichzeitig ist es schwierig, sie zuverlässig und für den Enterprise-Einsatz zu beschaffen. Das Sammeln von Daten von einigen wenigen Seiten mag unkompliziert erscheinen, wenn Sie einer Web-Scraping-Roadmap folgen, aber dies konsistent über viele Domains oder eine große Website hinweg zu tun, ist weitaus komplexer.
Websites ändern häufig ihre Struktur, setzen Rate-Limits durch und implementieren Anti-Bot-Schutzmaßnahmen, die automatisierte Anfragen blockieren. Selbst wenn es Ihnen gelingt, die Daten zu sammeln, kann es schwierig sein, sicherzustellen, dass sie hochwertig, vollständig und aktuell sind.
Aus diesem Grund verlassen sich viele Organisationen auf Web-Datensatz-Unternehmen und Web-Datenanbieter wie Bright Data. Diese Plattformen geben Ihnen Zugang zu großen Mengen an Web-Daten, ohne dass Sie eine eigene Scraping-Infrastruktur aufbauen und pflegen müssen.
Bright Data bietet Hunderte von Datensätzen aus mehr als 215 beliebten Web-Domains mit insgesamt über 17 Milliarden Datensätzen. Diese Datensätze enthalten kontinuierlich aktualisierte Web-Daten, die strukturiert, sofort einsatzbereit und für ML- und KI-Anwendungen optimiert sind. Erkunden Sie den Datensatz-Marktplatz!
Falls vorgefertigte Datensätze Ihren Anforderungen nicht entsprechen, bietet Bright Data auch Web-Scraping-APIs und andere Datenerfassungstools. Diese helfen Ihnen, frische Daten von Websites auf Abruf zu erhalten, ohne sich selbst mit Scraping-Herausforderungen auseinandersetzen zu müssen.
Was Bright Data auszeichnet, ist seine Datenerfassungsinfrastruktur. Sie basiert auf einem globalen Proxy-Netzwerk mit über 150 Millionen IPs in mehr als 195 Ländern, mit einer Verfügbarkeit von 99,99 % und Erfolgsraten von 99,95 %. Diese Grundlage erleichtert die Entwicklung datengesteuerter Anwendungen und ML-Pipelines, die auf vertrauenswürdigen Web-Daten basieren.
Wie Sie Feature Engineering für Web-Daten in Amazon SageMaker durchführen
In diesem schrittweisen Abschnitt werden Sie durch den Prozess des Feature Engineerings in Amazon SageMaker geführt.
Sie beginnen mit einem Bright-Data-Glassdoor-Datensatz, laden ihn in Amazon S3 hoch, importieren ihn in ein SageMaker-Notebook und wenden Feature Engineering an, um aussagekräftige Metriken zu erstellen. Sobald die Features vorbereitet sind, verwenden Sie sie, um ein prädiktives Machine-Learning-Modell für hohe Mitarbeiterzufriedenheit zu trainieren.
Bedenken Sie, dass dies nur ein Beispiel ist und viele weitere Anwendungsfälle möglich sind.
Folgen Sie den Anweisungen!
Voraussetzungen
Um dieser Anleitung zu folgen, stellen Sie sicher, dass Sie Folgendes haben:
- Ein AWS-Konto (auch im Rahmen einer kostenlosen Testversion).
- Ein Bright-Data-Konto.
- Einen S3-Bucket, der in Ihrem AWS-Konto definiert ist.
- Grundlegende Python-Kenntnisse, insbesondere in Bezug auf Machine-Learning-Entwicklung und Data Science.
Ab jetzt gehen wir davon aus, dass Ihr S3-Bucket den Namen bright-data-sagemaker trägt:
Schritt 1: Den Eingabe-Datensatz von Bright Data abrufen
Der erste Schritt besteht darin, die Eingabe-Web-Daten zu beschaffen. Für Feature Engineering ist es am besten, mit einem großen, hochwertigen Datensatz zu beginnen. In diesem Beispiel nutzen wir die umfangreichen Datensatz-Sammlungen von Bright Data und konzentrieren uns dabei auf einen Glassdoor-Datensatz, wie zuvor geplant.
Alternative: Wenn Sie lieber neue Daten sammeln möchten, können Sie eine der Bright-Data-Web-Scraping-APIs verwenden, um frische, strukturierte, ML-fertige Datensätze zu erfassen. Diese APIs bieten eine Lieferoption, die Daten direkt an Ihr Amazon-S3-Konto senden kann, was die Integration mit SageMaker nahtlos macht.
Wenn Sie noch kein Bright-Data-Konto haben, erstellen Sie zunächst eines. Andernfalls melden Sie sich einfach an.
Wählen Sie im Bright-Data-Kontrollpanel die Menüoption “Web Datasets”. Navigieren Sie zur Registerkarte “Datensatz-Marktplatz“, um verfügbare Datensätze zu durchsuchen:
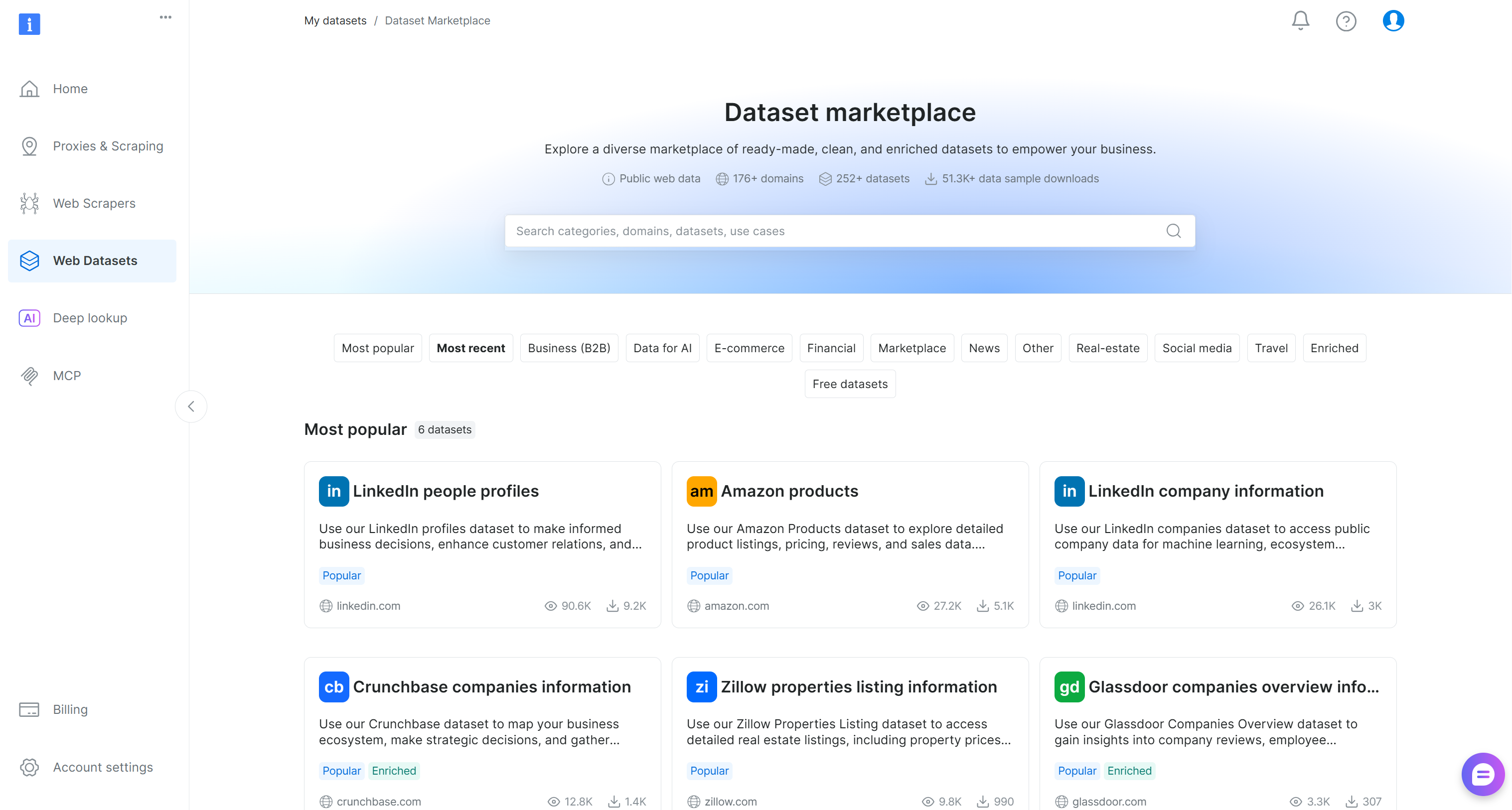
Hier können Sie über 200 gescrapte Datensätze aus mehr als 155 Domains mit Milliarden von Datensätzen erkunden.
Suchen Sie nun nach dem Datensatz “Glassdoor companies overview information” und öffnen Sie dessen Seite:
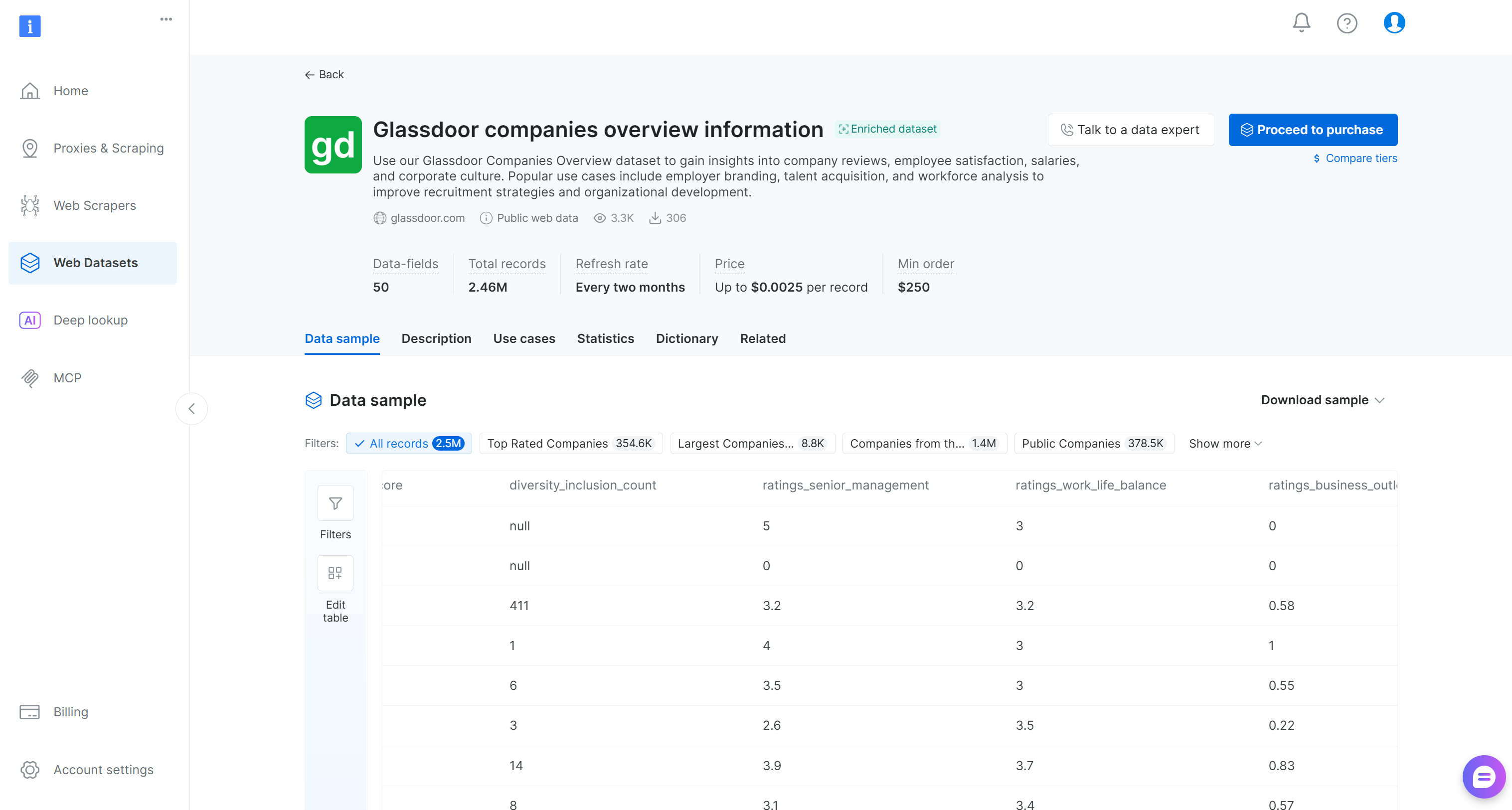
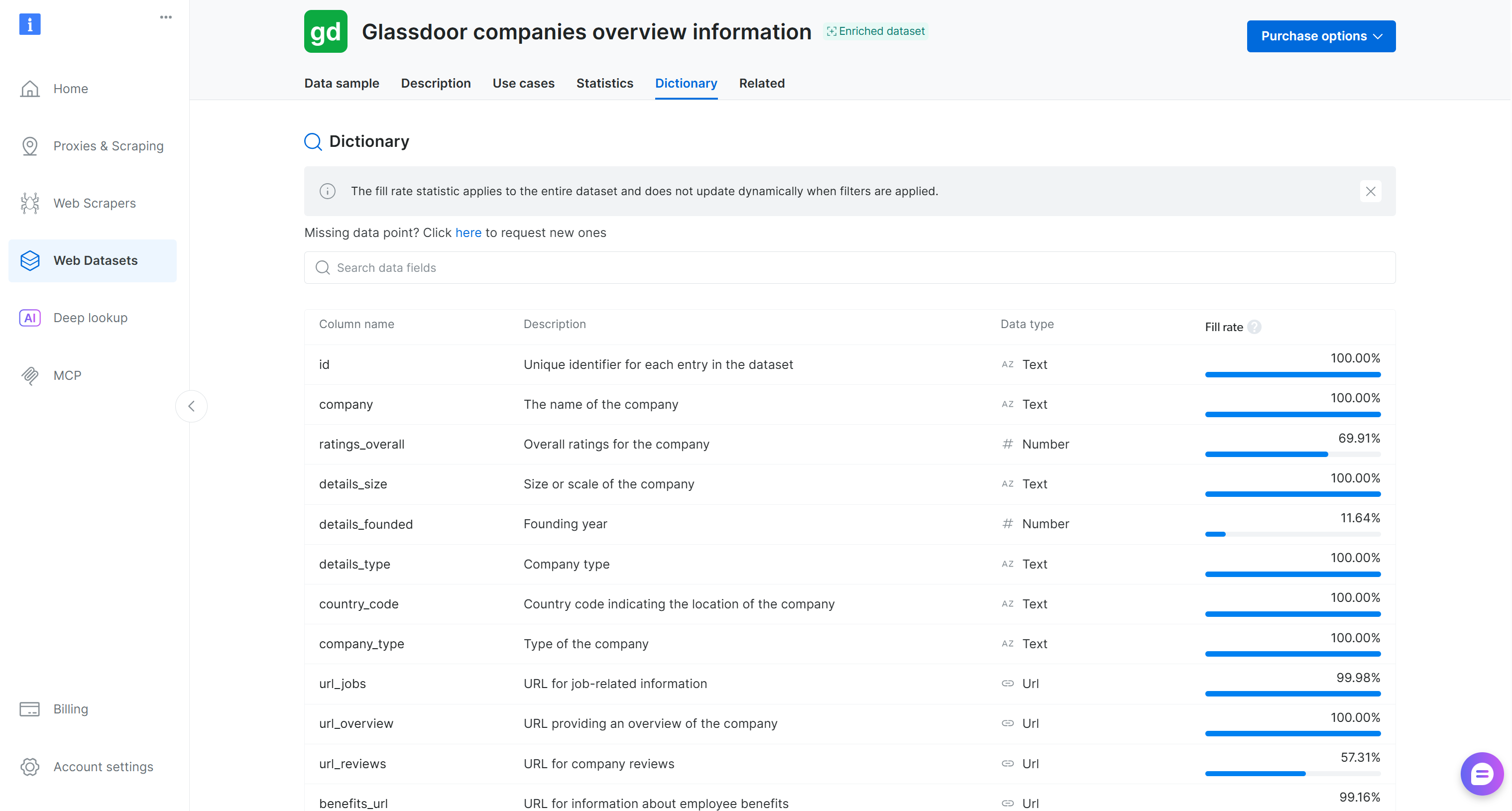
Dieser Datensatz enthält Unternehmensbewertungen, Mitarbeiterzufriedenheits-Scores, Gehälter und Informationen zur Unternehmenskultur. Beliebte Anwendungsfälle umfassen Employer Branding, Talentgewinnung und Belegschaftsanalyse. Er enthält über 2,46 Millionen Einträge mit 50 Datenfeldern.
Sie können entweder eine gefilterte Teilmenge kaufen oder eine kostenlose Probe herunterladen. In einem Produktionsszenario gilt: Je größer der Eingabe-Datensatz, desto zuverlässiger sind Ihre Feature-Engineering-Ergebnisse.
Da es sich bei diesem Tutorial nur um ein Beispiel handelt, verwenden wir die kostenlose Probe. Um diese zu erhalten, klicken Sie auf das Dropdown-Menü “Download sample” und wählen Sie die Option “Download as JSON”:
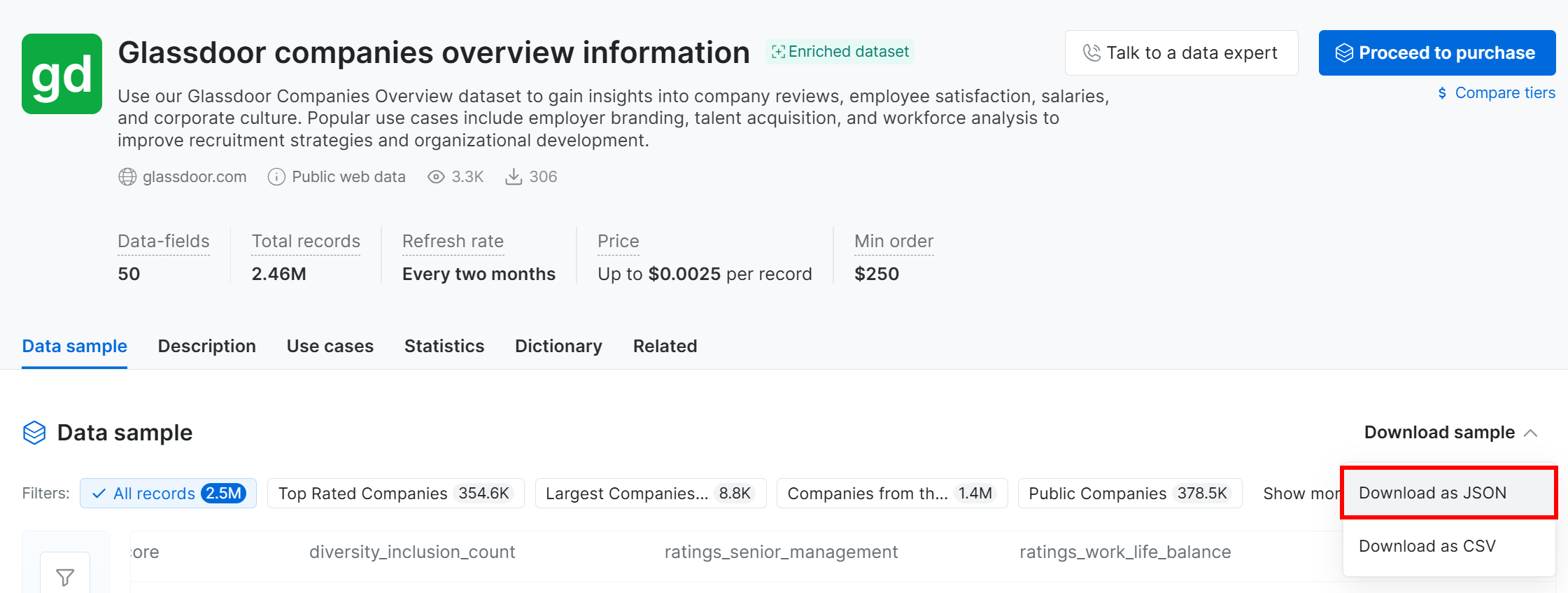
Sie erhalten eine Beispieldatei mit dem Namen Glassdoor companies overview information.json. Diese Datei enthält 1.000 Unternehmenseinträge mit jeweils 50 Feldern.
Benennen Sie die Datei in glassdoor-companies.json um und bereiten Sie sich darauf vor, sie in Ihren S3-Bucket hochzuladen. Diese wird als Eingabe für Ihr SageMaker-Feature-Engineering-Notebook verwendet. Gut gemacht!
Schritt 2: Die Web-Daten in Ihren S3-Bucket hochladen
Rufen Sie Ihre Amazon-S3-Bucket-Seite auf und klicken Sie auf die Schaltfläche “Upload”, um die Datei glassdoor-companies.json hinzuzufügen. Nach dem Hochladen erscheint sie in Ihrem Bucket wie folgt:

Alternativ können Sie einen der vielen Amazon-S3-Clients verwenden, um die Datei hochzuladen.
Denken Sie daran: Mit den Bright-Data-Web-Scraping-APIs können Sie gescrapte Daten direkt an Amazon S3 senden.
Ausgezeichnet! Sie haben jetzt einige Eingabe-Web-Daten für Feature Engineering in Amazon SageMaker.
Schritt 3: Mit Amazon SageMaker beginnen
Melden Sie sich bei der AWS-Konsole an und suchen Sie nach “SageMaker”. Wählen Sie den Dienst aus, um seine Hauptseite zu öffnen:
Klicken Sie auf die Schaltfläche “Get started”, um Ihre Amazon-SageMaker-Erfahrung zu starten.
Stellen Sie auf der Setup-Seite für eine automatische IAM-Einrichtung sicher, dass “Auto-create a new role with admin permissions” ausgewählt ist. Fahren Sie fort, indem Sie auf die Schaltfläche “Set up” drücken:
Der Initialisierungsprozess kann einige Minuten dauern, also haben Sie Geduld. Während er läuft, sehen Sie eine Meldung “Setting up Amazon SageMaker Unified Studio…”.
Sobald das Setup abgeschlossen ist, gelangen Sie zur folgenden Seite:
Klicken Sie auf “Open”, um Amazon SageMaker Unified Studio zu starten:
Von hier aus können Sie Ihre SageMaker-Umgebung erkunden und verwalten, einschließlich der Entwicklung und Ausführung von Notebooks. Toll!
Schritt 4: Ein neues Notebook erstellen
Klicken Sie in Amazon SageMaker Unified Studio auf die Schaltfläche “Build in the notebook”, um ein neues Notebook zu erstellen:

So sollte Ihr neues SageMaker-Notebook aussehen:
Geben Sie Ihrem Notebook einen beschreibenden Namen, beispielsweise “Company Data Feature Engineering”.
Ein Amazon-SageMaker-Notebook ist eine verwaltete Machine-Learning-Compute-Instanz, die Jupyter Notebook ausführt. Es bietet alles, was Sie benötigen, um Daten vorzubereiten und zu verarbeiten, Trainingscode zu schreiben und zu testen, Modelle im SageMaker-Hosting bereitzustellen und Ihre Modelle zu validieren.
Wunderbar! Sie haben jetzt alle Bausteine, um die SageMaker-Feature-Engineering-Logik zu implementieren.
Schritt 5: Die Eingabe-Web-Daten laden
Der erste Schritt besteht darin, Ihre Glassdoor-Eingabe-Web-Daten von Bright Data in Ihr SageMaker-Notebook zu laden.
Erweitern Sie im Panel “Data Explorer” auf der linken Seite das Dropdown-Menü “Buckets”. Suchen Sie Ihren S3-Bucket und finden Sie die Datei glassdoor-companies.json. Klicken Sie auf das Burger-Menü neben der Datei und wählen Sie die Option “Read as dataframe”:
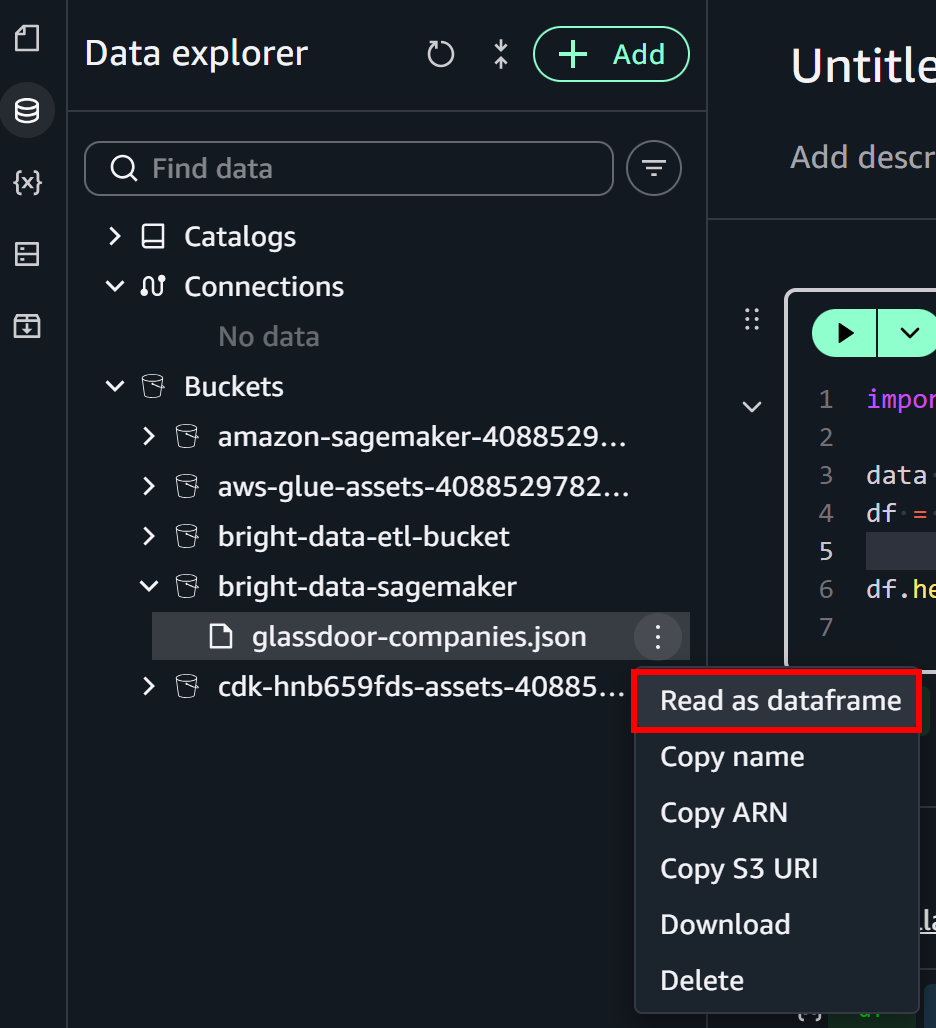
Dadurch wird die erste Notebook-Zelle mit Logik zum Laden der Datei aus S3 befüllt:
import pandas as pd
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")Hinweis: Ersetzen Sie bright-data-sagemaker durch den Namen Ihres S3-Buckets.
Vervollständigen Sie die Datenimport-Logik in der ersten Zelle wie folgt:
import pandas as pd
# Load the input data from the S3 bucket
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")
# Normalize the structured JSON fields
df = pd.json_normalize(data.to_dict(orient="records"))
# Print the first 10 lines
df.head(10)Dieses Code-Snippet lädt und verarbeitet einen JSON-Datensatz aus einem S3-Bucket für die Analyse in Python vor. Es verwendet pd.read_json() zum Lesen der Datei, dann pd.json_normalize(), um verschachtelte JSON-Felder in einen tabellarischen DataFrame zu glätten. Schließlich zeigt df.head(10) die ersten 10 Zeilen an und gibt eine schnelle Vorschau der strukturierten Daten.
Führen Sie die Zelle aus, indem Sie auf die Schaltfläche “▶” drücken. Sie sollten eine Vorschau wie diese sehen:
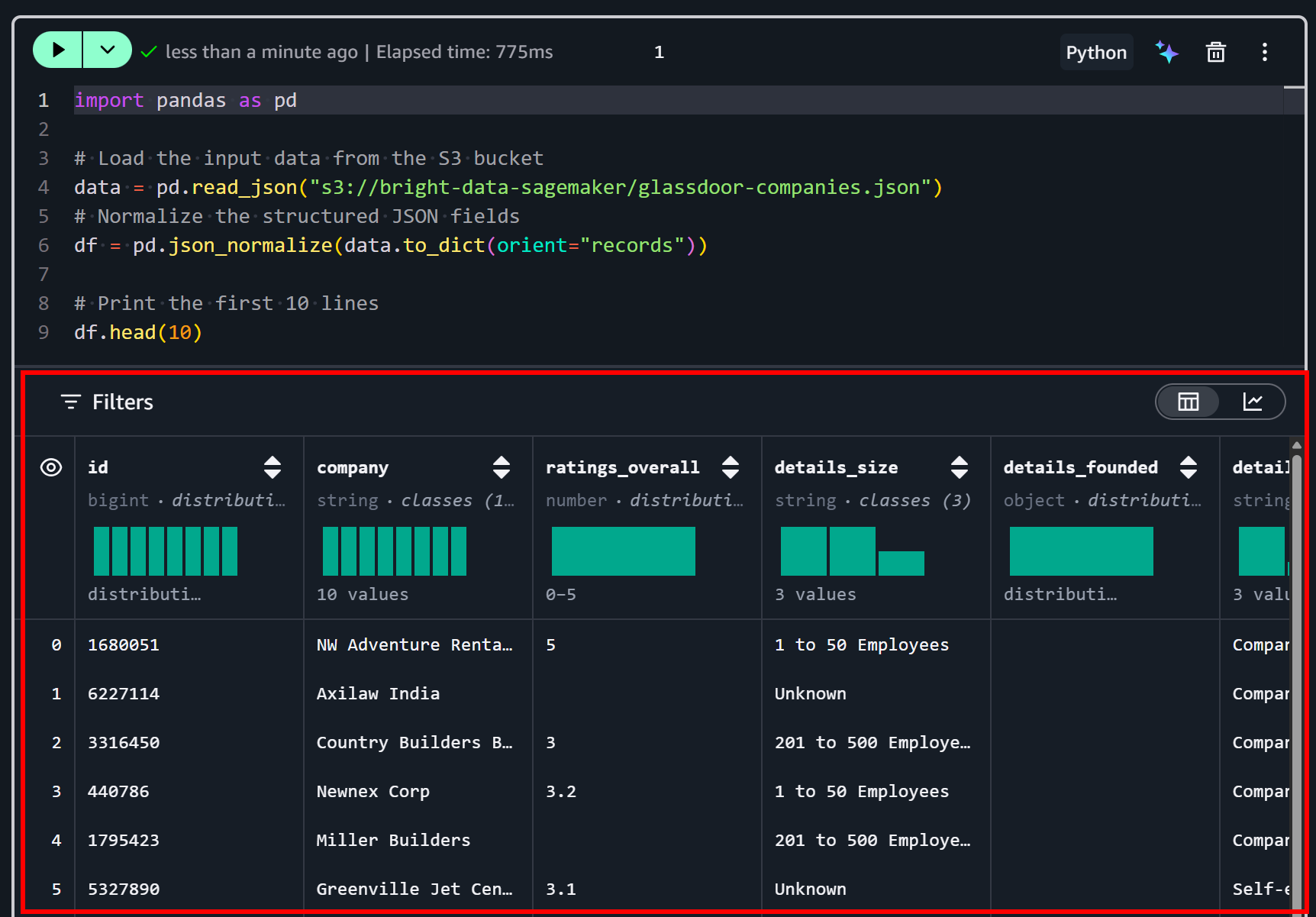
Wie Sie sehen können, wurde der Datensatz korrekt geladen. Er enthält 50 Datenfelder, wie auf der Registerkarte “Dictionary” auf der Bright-Data-Datensatz-Seite aufgeführt:
Sie haben Eingabe-Web-Daten, die für Feature Engineering bereit sind. Fantastisch!
Schritt 6: Die Eingabedaten vorverarbeiten
Nachdem Sie Ihren Datensatz in das Notebook importiert haben, besteht der nächste Schritt darin, ihn für das Feature Engineering zu bereinigen und vorzubereiten.
Fügen Sie eine neue Zelle in Ihr SageMaker-Notebook ein und geben Sie den folgenden Code ein:
# Select only the columns of interest
columns = [
"company",
"ratings_overall",
"ratings_work_life_balance",
"ratings_culture_values",
"ratings_compensation_benefits",
"ratings_career_opportunities",
"ratings_senior_management",
"ratings_ceo_approval",
"reviews_count",
"jobs_count",
"salaries_count",
"benefits_count",
"details_size",
"region"
]
df = df[columns]
# Remove all rows containing missing values
df = df.dropna()Dieses Snippet wählt nur die relevanten Spalten aus und hält Ihren Datensatz auf relevante Metriken und Bezeichner fokussiert. Anschließend wird df.dropna() verwendet, um alle Zeilen zu entfernen, die in den ausgewählten Spalten fehlende Werte enthalten. Dies stellt sicher, dass Ihre Daten für das Feature Engineering sauber und konsistent sind.
Ihre neue Zelle wird wie folgt aussehen:
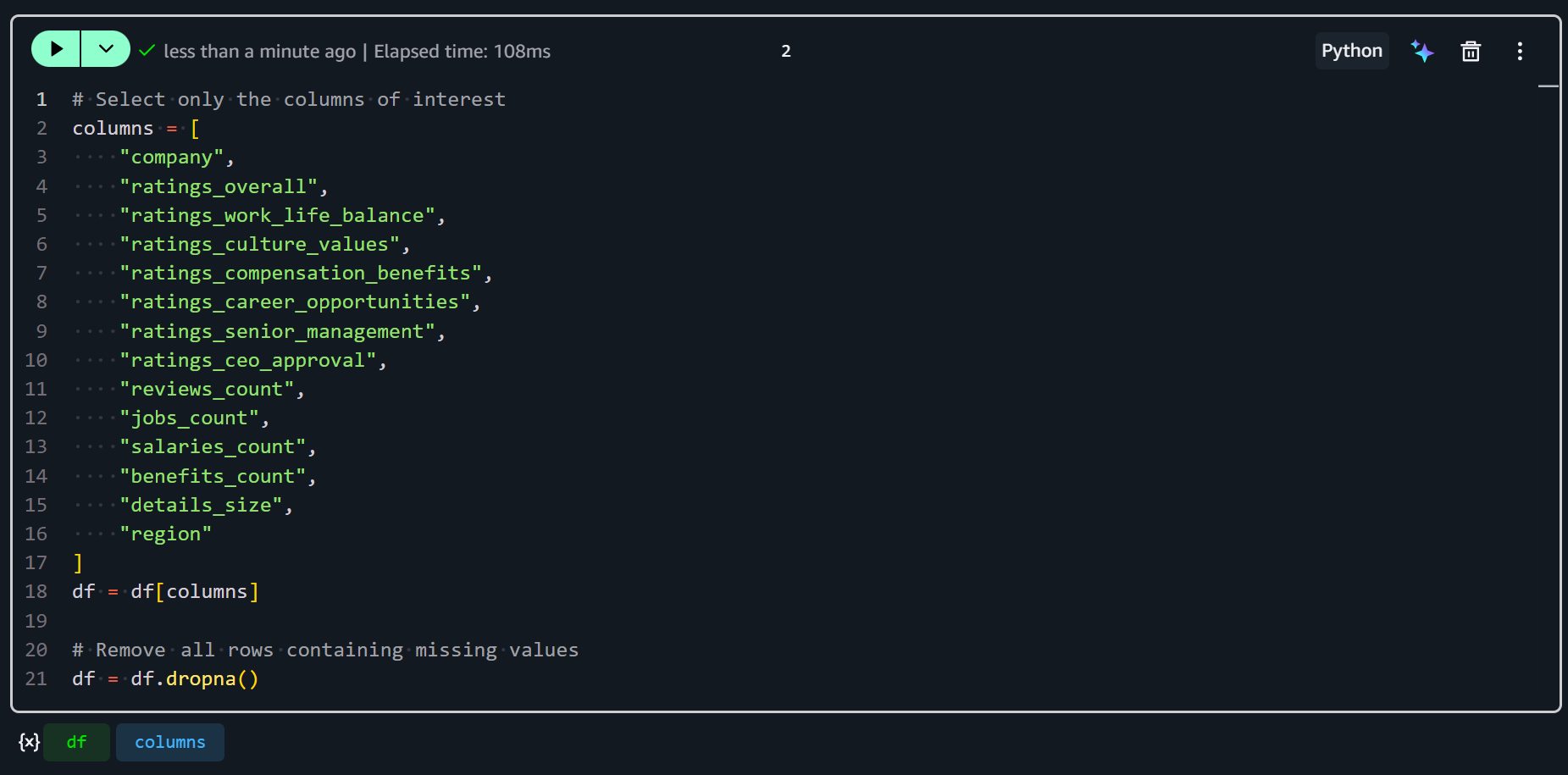
Gut! Ihr Eingabe-Datensatz ist jetzt für Feature Engineering in SageMaker bereit.
Schritt 7: Die Features definieren
Es ist Zeit, die Features zu definieren, die Sie für maschinelles Lernen verwenden werden. Denken Sie daran, dass Features abgeleitete Spalten sind, die Rohdaten zusammenfassen oder in aussagekräftige Metriken umwandeln, die zugrunde liegende Muster besser repräsentieren.
In diesem Beispiel fügen Sie Features hinzu, die Unternehmenskultur, Vergütung, Popularität und Wachstumsaktivität erfassen.
Zunächst kombiniert das Feature culture_score mehrere verwandte Bewertungen zu einer einzigen Metrik, die das allgemeine kulturelle Umfeld eines Unternehmens darstellt:
df["culture_score"] = (
df["ratings_culture_values"] +
df["ratings_work_life_balance"] +
df["ratings_senior_management"]
) / 3Es mittelt drei Bewertungsspalten:
ratings_culture_values: Beschreibt, wie gut das Unternehmen seine erklärten Werte verkörpert.ratings_work_life_balance: Bewertet die Wahrnehmung der Mitarbeiter zur Work-Life-Balance.ratings_senior_management: Erfasst die Wahrnehmung von Führung und Management.
Das Summieren der drei Bewertungen und Dividieren durch 3 ergibt einen normalisierten Score. Der resultierende Score behält denselben Maßstab wie die ursprünglichen Bewertungen bei und gewichtet jeden Kulturaspekt gleich.
Zweitens stellt das Feature compensation_score eine kombinierte Sicht auf die Mitarbeiterzufriedenheit mit Vergütung und Karrierewachstum dar:
df["compensation_score"] = (
df["ratings_compensation_benefits"] +
df["ratings_career_opportunities"]
) / 2Es umfasst:
ratings_compensation_benefits: Bewertet die Zufriedenheit der Mitarbeiter mit Gehalt und Leistungen.ratings_career_opportunities: Erfasst die Zufriedenheit der Mitarbeiter mit Karriereentwicklungsmöglichkeiten.
Durch die Mittelwertbildung wird das Feature konsistent mit anderen Scores skaliert, um beide Aspekte gleichgewichtig zu berücksichtigen.
Drittens misst das Feature review_popularity, wie häufig ein Unternehmen auf Glassdoor bewertet wird:
df["review_popularity"] = df["reviews_count"].apply(lambda x: x ** 0.5)Dies wird durch Anwenden einer Quadratwurzeltransformation auf die Anzahl der Bewertungen ermittelt. Warum die Quadratwurzel? Weil Bewertungszahlen oft stark verzerrt sind (einige Unternehmen haben Tausende von Bewertungen, viele haben sehr wenige). Die Quadratwurzel reduziert den Einfluss extrem hoher Werte und stabilisiert die Varianz, was die Verarbeitung und Analyse erleichtert.
Viertens schätzt das Feature hiring_intensity, wie aktiv ein Unternehmen im Verhältnis zu seiner Bewertungsaktivität einstellt:
df["hiring_intensity"] = df["jobs_count"] / (df["reviews_count"] + 1)Es wird berechnet, indem die Anzahl der offenen Stellenangebote (jobs_count) durch die Anzahl der Bewertungen plus 1 dividiert wird (um eine Division durch null bei Unternehmen ohne Bewertungen zu vermeiden).
Höhere Werte deuten auf Unternehmen hin, die aktiv einstellen, verglichen damit, wie viele Mitarbeiter Bewertungen hinterlassen. Dies kann ein Indikator für Wachstums- oder Expansionsaktivitäten sein.
Alles zusammengenommen ergibt sich:
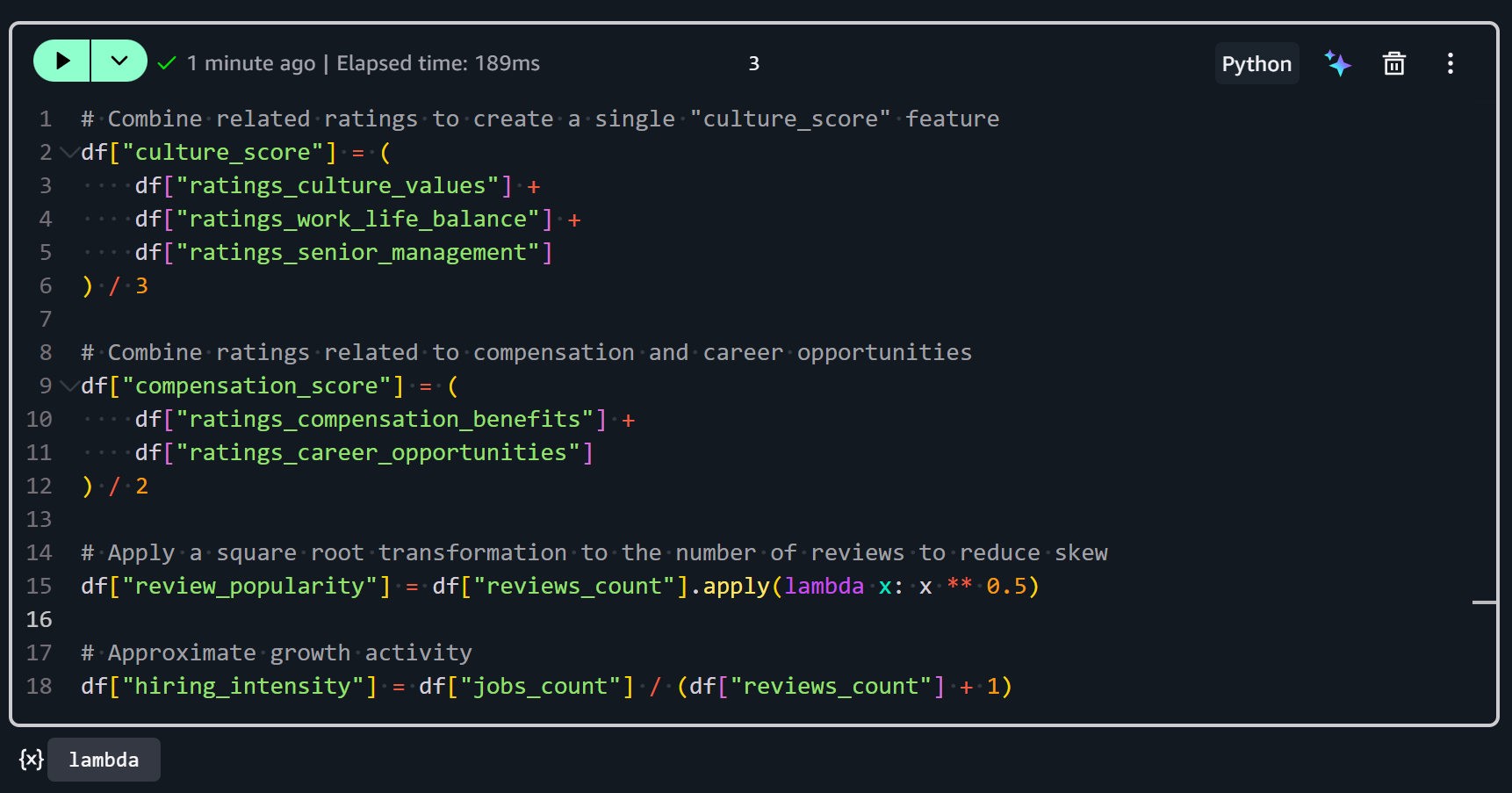
Nach diesen Transformationen enthält Ihr Datensatz nun abgeleitete Features, die Rohdaten und Zählungen in aussagekräftigere Metriken umwandeln. Toll!
Schritt 8: Die Zielvariable festlegen
Nachdem Ihre Features definiert sind, besteht der nächste Schritt darin, die Zielvariable für Ihre Machine-Learning-Aufgabe festzulegen. Die Zielvariable stellt das Ergebnis dar, das Ihr Modell vorhersagen soll. In diesem Fall sagen Sie vorher, ob ein Unternehmen eine hohe Mitarbeiterzufriedenheit aufweist.
Um das Ziel festzulegen, fügen Sie eine neue Zelle in Ihr Notebook ein und fügen Sie diesen Code hinzu:
# Define the target variable
df["high_satisfaction"] = (df["ratings_overall"] >= 4).astype(int)Dadurch wird ein boolesches Feld erstellt, in dem Unternehmen mit einer Gesamtbewertung von 4 oder höher als True (hohe Zufriedenheit) und andere als False (niedrige Zufriedenheit) markiert werden.

Viele Machine-Learning-Algorithmen erfordern eine numerische Zielvariable. Durch die Umwandlung der Zufriedenheitsbewertungen in ein binäres 0/1-Boolean-Label können Sie Modelle für Klassifizierungsaufgaben trainieren. Dies hilft Ihnen vorherzusagen, ob ein Unternehmen wahrscheinlich hochzufriedene Mitarbeiter haben wird, basierend auf den von Ihnen erstellten Features. Erreichen Sie das im nächsten Schritt!
Schritt 9: Das ML-Modell für die Zufriedenheitsvorhersage trainieren
Mit Ihren definierten Features und der Zielvariable können Sie jetzt ein Machine-Learning-Modell trainieren, um hohe Mitarbeiterzufriedenheit vorherzusagen.
Das gewählte ML-Modell ist XGBoost, ein Gradient-Boosting-Algorithmus, der bei tabellarischen Daten und Klassifizierungsaufgaben außergewöhnlich gut abschneidet. Er eignet sich gut zur Vorhersage der Variablen high_satisfaction auf der Grundlage einer Mischung aus numerischen und abgeleiteten Features.
Fügen Sie eine neue Zelle in Ihr Notebook ein und ergänzen Sie die Logik zum Trainieren Ihres Modells:
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
# Define the features to use for prediction
features = [
"culture_score",
"compensation_score",
"ratings_ceo_approval",
"review_popularity",
"hiring_intensity"
]
# Separate input features (X) and target variable (y)
X = df[features]
y = df["high_satisfaction"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Initialize the XGBoost classifier with some reasonable hyperparameters
model = XGBClassifier(
n_estimators=500,
max_depth=5,
learning_rate=0.05,
eval_metric="logloss"
)
# Train the model on the training data
model.fit(X_train, y_train)Das obige Snippet bereitet ein Machine-Learning-Modell zur Vorhersage hoher Mitarbeiterzufriedenheit vor und trainiert es. Es wählt die konstruierten Features aus und teilt die Daten in Trainings- und Testsets auf. Anschließend initialisiert es einen XGBoost-Klassifikator mit optimierten Hyperparametern. Schließlich passt es das Modell an die Trainingsdaten an.
Führen Sie die Zelle aus, um das prädiktive Modell tatsächlich zu trainieren:
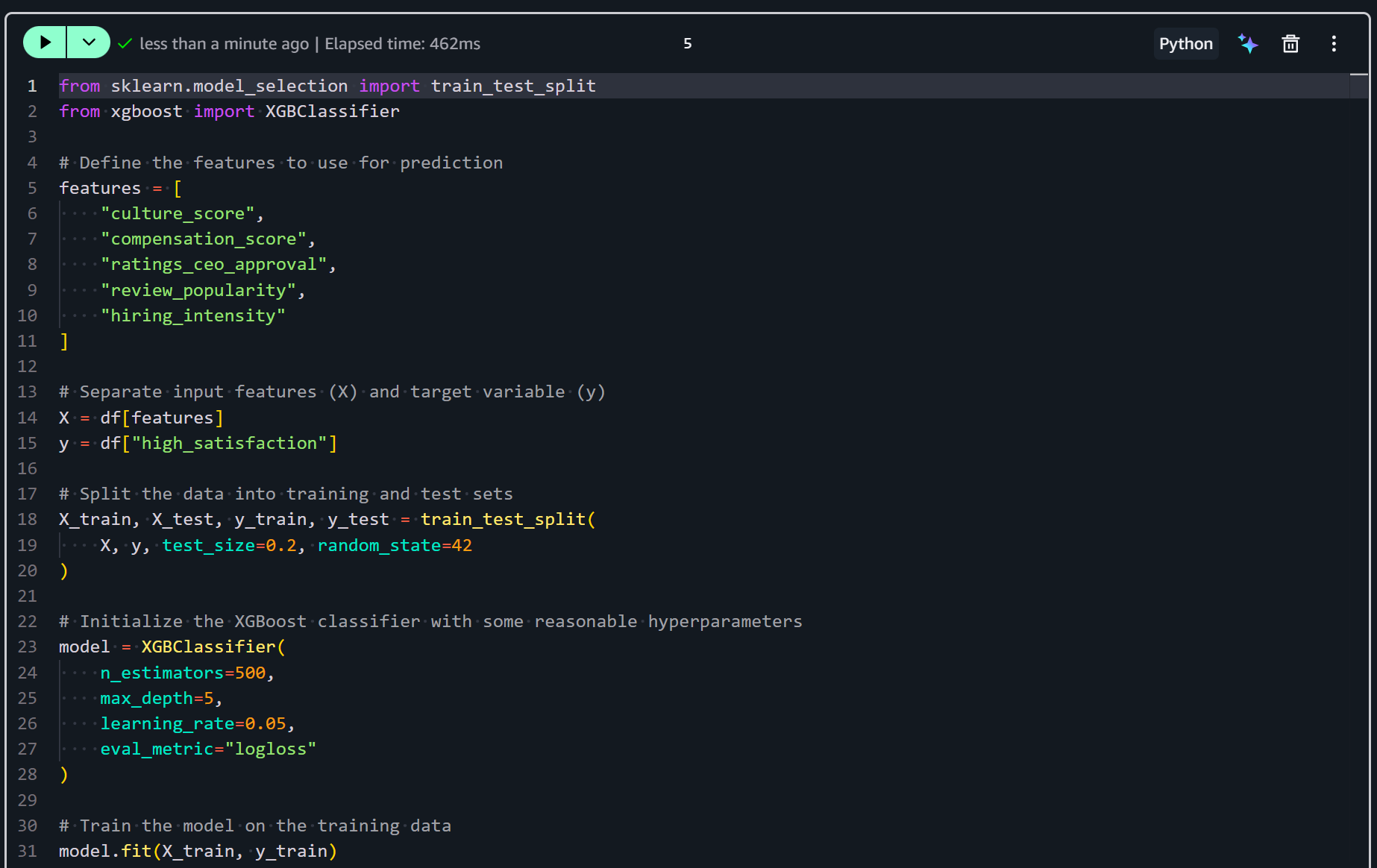
Nach diesem Schritt ist Ihr XGBoost-Klassifikator trainiert und bereit für Evaluierung und Vorhersage. Der nächste Schritt ist die Bewertung seiner Leistung!
Schritt 10: Die Modellleistung bewerten
Der letzte Schritt besteht darin, zu beurteilen, wie gut Ihr Modell bei unbekannten Daten abschneidet. Fügen Sie eine neue Zelle in Ihr Notebook mit diesem Code ein:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, roc_auc_score, accuracy_score
# Use the trained model to predict labels on the test set
pred = model.predict(X_test)
print(classification_report(y_test, pred))
# Confusion matrix
cm = confusion_matrix(y_test, pred)
print("\nConfusion Matrix:\n", cm)
# ROC-AUC score
roc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
print("\nROC-AUC:", roc)Drücken Sie die Schaltfläche “Run All”, um alle Schritte auszuführen und die Metriken zu berechnen:

Nachdem die letzte Zelle ausgeführt wurde, sollten Sie eine Ausgabe ähnlich dieser sehen:
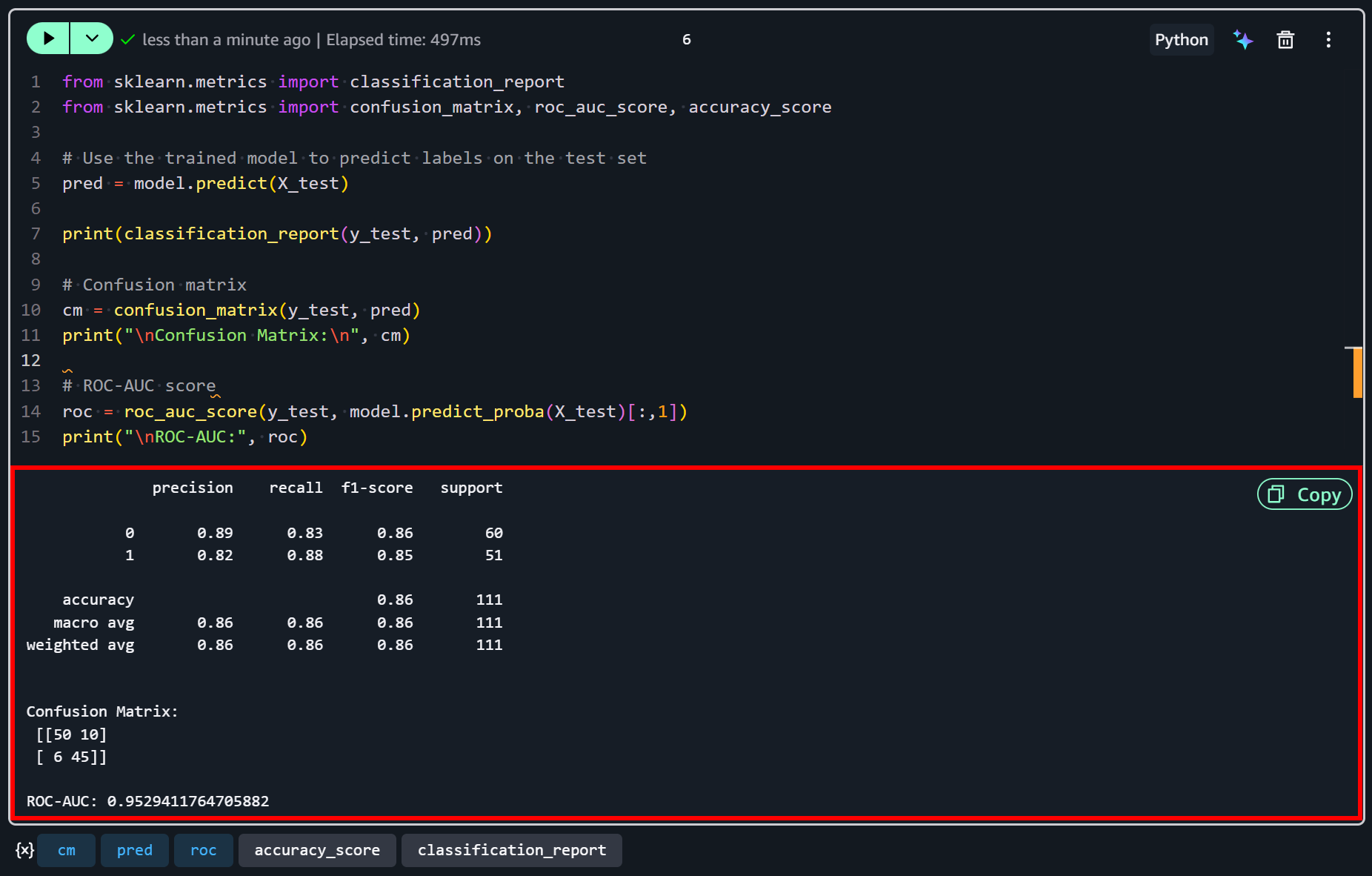
Diese Ergebnisse legen nahe, dass das Modell für diesen Beispieldatensatz angemessen gut abschneidet. Mit einer Genauigkeit von 86 % und einem ROC-AUC von 0,95 zeigt es eine starke Fähigkeit, zwischen Unternehmen mit hoher und niedriger Zufriedenheit zu unterscheiden.
Beide Klassen zeigen ausgeglichene Präzision und Recall, was bedeutet, dass das Modell ähnlich effektiv darin ist, Unternehmen mit hoher Zufriedenheit (1) und solche mit niedrigerer Zufriedenheit (0) korrekt zu identifizieren.
Dennoch verbleiben einige Fehlklassifikationen… Wie in der Konfusionsmatrix widergespiegelt, wurden 10 Unternehmen mit niedriger Zufriedenheit fälschlicherweise als hochzufrieden vorhergesagt, und 6 Unternehmen mit hoher Zufriedenheit wurden fälschlicherweise als niedrig zufrieden eingestuft.
Dies deutet darauf hin, dass das Modell zwar die Hauptmuster in den Daten erfasst, aber nicht perfekt ist und durch zusätzliche Features (oder mehr Daten) weiter verbessert werden könnte.
Et voilà! Dank des Bright-Data-Eingabe-Web-Datensatzes konnten Sie Feature Engineering durchführen und ein prädiktives Modell in Amazon SageMaker trainieren. Dies ist nur einer von vielen Anwendungsfällen, die Sie dank der breiten Vielfalt strukturierter Web-Datensätze von Bright Data erkunden könnten.
Nächste Schritte
Das aktuelle Modell, das hohe Mitarbeiterzufriedenheit anhand von durch Feature Engineering abgeleiteten Feldern vorhersagt, erzielt anständige Ergebnisse. Dennoch gibt es Verbesserungspotenzial. Es gibt mehrere Möglichkeiten, seine Leistung zu verbessern, darunter:
- Mehr abgeleitete Features erstellen: Kombinieren Sie bestehende Bewertungen auf neue Weise. Zum Beispiel könnten Sie einen
leadership_scoreausratings_senior_managementundratings_ceo_approvalberechnen oder einwork_life_compensation_ratio, um Kompromisse zwischen Vergütung und Work-Life-Balance zu erfassen. Erkunden Sie Verhältnisse, Differenzen oder Interaktionen zwischen Features, die verborgene Muster aufdecken können. - Schiefe Verteilungen transformieren: Features wie
reviews_countoderjobs_countsind oft verzerrt. Wir haben bereits eine Quadratwurzeltransformation angewendet, aber erwägen Sie logarithmische oder Box-Cox-Transformationen, um die Varianz weiter zu stabilisieren. - Kategoriale Features einbeziehen: Derzeit sind
regionunddetails_sizenicht numerisch. Ihre Kodierung mit One-Hot-Encoding oder Target-Encoding könnte zusätzliche Vorhersagesignale liefern. - Mehrere Datenpunkte aggregieren: Wenn Sie historische Bewertungs- oder Einstellungstrends erhalten können, könnten Features wie das durchschnittliche Wachstum von
jobs_countüber die Zeit oder Änderungen imculture_scoredynamisches Unternehmensverhalten erfassen. - Feature-Selektion und Wichtigkeitsanalyse: Prüfen Sie nach dem Training die XGBoost-Feature-Wichtigkeit, um zu ermitteln, welche Features am meisten zu den Vorhersagen beitragen. Sie können neue Features inspiriert von den prädiktivsten entwickeln.
- Externe Datenerweiterung: Erwägen Sie, andere Bright-Data-Datensätze zusammenzuführen, um reichhaltigere, kontextbezogene Features zu erstellen.
Fazit
In diesem Tutorial haben Sie gesehen, was Amazon SageMaker für Machine-Learning-Szenarien zu bieten hat. Insbesondere haben Sie erfahren, warum gescrapte Datensätze ausgezeichnete Quellen für Feature Engineering sind und wie sie zum Training prädiktiver ML-Modelle eingesetzt werden können.
Wie gezeigt, bietet Bright Data einen umfangreichen Datensatz-Marktplatz, der Hunderte von Domains und Milliarden von Web-Datensätzen abdeckt. Diese Datensätze werden kontinuierlich durch Web-Scraping aktualisiert, was sie ideal für die Unterstützung von Machine-Learning- und KI-Workflows macht. Wichtig ist, dass sie sich nahtlos in Amazon SageMaker integrieren lassen, wie in diesem Leitfaden veranschaulicht.
Erstellen Sie noch heute ein kostenloses Bright-Data-Konto und erkunden Sie unsere Web-Datenlösungen!





