

In diesem Tutorial werden Sie lernen:
- Wie ein KI-gestützter LinkedIn-Assistent für die Jobsuche funktionieren könnte.
- Wie man ihn durch die Integration von LinkedIn-Stellendaten von Bright Data mit einem OpenAI-gesteuerten Workflow erstellt.
- Wie man diesen Workflow verbessert und zu einem robusten Assistenten für die Jobsuche erweitert.
Sie können die endgültigen Projektdateien hier einsehen.
Tauchen wir ein!
LinkedIn Job Hunting AI Assistant Workflow erklärt
Zunächst einmal können Sie keinen KI-Assistenten für die LinkedIn-Stellensuche ohne Zugang zu den Daten der LinkedIn-Stellenanzeigen erstellen. Und genau hier kommt Bright Data ins Spiel!
Mit dem LinkedIn Jobs Scraper können Sie über Web Scraping Daten zu öffentlichen Stellenangeboten von LinkedIn abrufen. Sie erhalten eine ähnliche Erfahrung wie bei der Suche auf dem LinkedIn-Jobportal. Aber statt einer Webseite erhalten Sie die strukturierten Jobdaten direkt im JSON- oder CSV-Format.
Mit diesen Daten können Sie dann eine KI bitten, jeden Job auf der Grundlage Ihrer Fähigkeiten und der von Ihnen gewünschten Position zu bewerten. Das ist im Großen und Ganzen das, was der LinkedIn Job AI Assistant für Sie tut.
Technische Schritte
Die folgenden Schritte sind erforderlich, um den LinkedIn Job AI Workflow zu implementieren:
- Laden der CLI-Argumente: Parsen der Befehlszeilenargumente, um Laufzeitparameter zu erhalten. Dies ermöglicht eine flexible Ausführung und eine einfache Anpassung ohne Änderung des Codes.
- Laden der Umgebungsvariablen: Laden Sie die OpenAI- und Bright Data-API-Schlüssel aus den Umgebungsvariablen. Diese sind erforderlich, um eine Verbindung zu den Integrationen von Drittanbietern herzustellen, die diesen KI-Workflow antreiben.
- Laden Sie die Konfigurationsdatei: Lesen Sie eine JSON-Konfigurationsdatei, die Parameter für die Stellensuche, Details zum Kandidatenprofil und die gewünschte Stellenbeschreibung enthält. Diese Konfigurationsinformationen steuern die Stellensuche und die KI-Bewertung.
- Scrapen der Jobs von LinkedIn: Abrufen von Stellenangeboten, die gemäß der Konfiguration gefiltert wurden, von der LinkedIn Jobs Scraper API.
- Bewertung der Stellen über KI: Senden Sie jeden Stapel von Stellenangeboten an OpenAI. Die KI bewertet sie auf der Grundlage Ihres Profils und der gewünschten Stelle auf einer Skala von
0bis100. Sie fügt auch einen kurzen Kommentar zu jeder Bewertung hinzu, damit Sie die Qualität der Übereinstimmung besser verstehen können. - Erweitern Sie die Stellenangebote mit KI-Bewertungen und Kommentaren: ****Fügen Sie die von der künstlichen Intelligenz generierten Bewertungen und Kommentare wieder in die ursprünglichen Stellenausschreibungen ein und bereichern Sie jeden Stelleneintrag mit diesen neuen, von der künstlichen Intelligenz generierten Feldern.
- Exportieren Sie die bewerteten Jobdaten: Exportieren Sie die angereicherten Jobdaten in eine CSV-Datei zur weiteren Analyse und Verarbeitung.
- Drucken Sie die besten Jobtreffer: Zeigen Sie die besten Job-Treffer direkt in der Konsole mit den wichtigsten Details an, um einen unmittelbaren Einblick in die wichtigsten Chancen zu erhalten.
Sehen Sie, wie Sie diesen KI-Workflow in Python implementieren können!
Wie man mit OpenAI und Bright Data einen KI-Workflow für die LinkedIn-Stellensuche erstellt
In diesem Tutorial lernen Sie, wie Sie einen KI-Workflow erstellen, der Sie bei der Jobsuche auf LinkedIn unterstützt. Die LinkedIn-Stellendaten werden von Bright Data bezogen, während die KI-Funktionen von OpenAI bereitgestellt werden. Beachten Sie, dass Sie auch jedes andere LLM verwenden können.
Am Ende dieses Abschnitts werden Sie einen vollständigen Python-KI-Workflow haben, den Sie über die Befehlszeile ausführen können. Er identifiziert die besten LinkedIn-Stellen und erspart Ihnen Zeit und Mühe bei der zermürbenden und kräftezehrenden Aufgabe der Jobsuche.
Lassen Sie uns einen KI-Assistenten für die LinkedIn-Jobsuche bauen!
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen Sie folgende Voraussetzungen erfüllen:
- Python 3.8 oder höher ist lokal installiert (wir empfehlen die Verwendung der neuesten Version).
- Einen Bright Data-API-Schlüssel.
- Einen OpenAI-API-Schlüssel.
Wenn Sie noch keinen Bright Data-API-Schlüssel haben, erstellen Sie ein Bright Data-Konto und folgen Sie der offiziellen Einrichtungsanleitung. Befolgen Sie auch die offiziellen OpenAI-Anweisungen, um Ihren OpenAI-API-Schlüssel zu erhalten.
Schritt Nr. 0: Einrichten des Python-Projekts
Öffnen Sie ein Terminal und erstellen Sie ein neues Verzeichnis für Ihren LinkedIn-KI-Assistenten für die Jobsuche:
mkdir linkedin-job-hunting-ai-assistant/Der Ordner linkedin-job-hunting-ai-assistant wird den gesamten Python-Code für Ihren KI-Workflow enthalten.
Navigieren Sie nun in das Projektverzeichnis und initialisieren Sie darin eine virtuelle Umgebung:
cd linkedin-job-hunting-ai-assistant/
python -m venv venvÖffnen Sie nun das Projekt in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie innerhalb des Projektordners eine neue Datei namens assistant.py. Ihre Verzeichnisstruktur sollte wie folgt aussehen:
linkedin-job-hunting-ai-assistant/
├── venv/
└── assistant.pyAktivieren Sie die virtuelle Umgebung in Ihrem Terminal. Unter Linux oder macOS, führen Sie aus:
source venv/bin/activateÄquivalent dazu starten Sie unter Windows diesen Befehl:
venv/Scripts/activateIn den nächsten Schritten werden Sie durch die Installation der erforderlichen Python-Pakete geführt. Wenn Sie es vorziehen, alle Pakete jetzt in der aktivierten virtuellen Umgebung zu installieren, führen Sie aus:
pip install python-dotenv requests openai pydanticInsbesondere sind folgende Bibliotheken erforderlich:
python-dotenv: Lädt Umgebungsvariablen aus einer.env-Dateiund erleichtert so die sichere Verwaltung von API-Schlüsseln.pydantic: Hilft beim Validieren und Parsen der Konfigurationsdatei in strukturierte Python-Objekte.Anfragen: Verarbeitet HTTP-Anforderungen zum Aufrufen von APIs wie Bright Data und zum Abrufen von Daten.openai: Stellt den OpenAI-Client für die Interaktion mit den Sprachmodellen von OpenAI zur Bewertung von KI-Aufträgen bereit.
Hinweis: Wir installieren hier die openai-Bibliothek, da sich dieses Tutorial auf OpenAI als Sprachmodellanbieter verlässt. Wenn Sie einen anderen LLM-Anbieter verwenden möchten, stellen Sie sicher, dass Sie das entsprechende SDK oder die entsprechenden Abhängigkeiten installieren.
Sie sind bereit! Ihre Python-Entwicklungsumgebung ist nun bereit für die Erstellung eines KI-Workflows mit OpenAI und Bright Data.
Schritt 1: Laden Sie die CLI-Argumente
Das KI-Skript für die LinkedIn-Jobsuche benötigt einige Argumente. Um es wiederverwendbar und anpassbar zu halten, ohne den Code zu ändern, sollten Sie diese über die CLI einlesen.
Im Einzelnen benötigen Sie die folgenden CLI-Argumente:
--config_file: Der Pfad zu der JSON-Konfigurationsdatei, die Ihre Parameter für die Stellensuche, die Details des Kandidatenprofils und die gewünschte Stellenbeschreibung enthält. Standard istconfig.json.--batch_size: Die Anzahl der Aufträge, die gleichzeitig zur Bewertung an die KI gesendet werden. Die Vorgabe ist5.--jobs_number: Die maximale Anzahl der Jobeinträge, die der Bright Data LinkedIn Jobs Scraper zurückgeben soll. Der Standardwert ist20.--output_csv: Der Name der CSV-Ausgabedatei, die die angereicherten Jobdaten mit KI-Bewertungen und Kommentaren enthält. Die Vorgabe istjobs_scored.csv.
Diese Argumente werden mit der folgenden Funktion aus der Befehlszeilenschnittstelle ausgelesen:
def parse_cli_args():
# Parsen der Kommandozeilenargumente für Konfigurations- und Laufzeitoptionen
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Pfad zur JSON-Datei der Konfiguration")
parser.add_argument("--jobs_number", type=int, default=20, help="Begrenzt die Anzahl der von der Bright Data Scraper API zurückgegebenen Aufträge")
parser.add_argument("--batch_size", type=int, default=5, help="Anzahl der Aufträge, die in jedem Batch bewertet werden")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="CSV-Dateiname der Ausgabe")
return parser.parse_args()Vergessen Sie nicht, argparse aus der Python Standard Library zu importieren:
import argparseGroßartig! Sie haben nun Zugriff auf Argumente aus der CLI.
Schritt #2: Laden Sie die Umgebungsvariablen
Konfigurieren Sie Ihr Skript so, dass es Geheimnisse aus Umgebungsvariablen liest. Um das Laden von Umgebungsvariablen zu vereinfachen, verwenden Sie das Paket python-dotenv. Wenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie es, indem Sie Folgendes ausführen:
pip install python-dotenvImportieren Sie dann in Ihrer Datei assistant.py die Bibliothek und rufen Sie load_dotenv() auf, um Ihre Umgebungsvariablen zu laden:
from dotenv import load_dotenv
load_dotenv()Ihr Assistent kann nun Variablen aus einer lokalen .env-Datei lesen. Fügen Sie also eine .env-Datei in das Stammverzeichnis Ihres Projekts ein:
linkedin-job-hunting-ai-assistant/
├── venv/
├── .env # <-----------
└── assistant.pyÖffnen Sie die .env-Datei und fügen Sie die envs OPENAI_API_KEY und BRIGHT_DATA_API_KEY hinzu:
OPENAI_API_KEY="<IHR_OPENAI_API_KEY>"
BRIGHT_DATA_API_KEY="<IHR_BRIGHT_DATA_API_KEY>"Ersetzen Sie den Platzhalter <YOUR_OPENAI_API_KEY> durch Ihren tatsächlichen OpenAI-API-Schlüssel. Ersetzen Sie in ähnlicher Weise den Platzhalter <YOUR_BRIGHT_DATA_API_KEY> durch Ihren Bright Data-API-Schlüssel.
Fügen Sie dann diese Funktion zu Ihrem Skript hinzu, um diese beiden Umgebungsvariablen zu laden:
def load_env_vars():
# Erforderliche API-Schlüssel aus der Umgebung lesen und das Vorhandensein überprüfen
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
wenn fehlend:
raise EnvironmentError(
f "Fehlende erforderliche Umgebungsvariablen: {', '.join(missing)}n"
"Bitte setzen Sie sie in Ihrer .env oder Umgebung."
)
return openai_api_key, brightdata_api_keyFügen Sie den erforderlichen Import aus der Python-Standardbibliothek hinzu:
import osWunderbar! Sie haben nun die Integrationsgeheimnisse von Drittanbietern mit Hilfe von Umgebungsvariablen sicher geladen.
Schritt #3: Laden Sie die Konfigurationsdatei
Jetzt brauchen Sie einen programmatischen Weg, um Ihrem Assistenten mitzuteilen, an welchen Stellen Sie interessiert sind. Damit die Ergebnisse korrekt sind, muss der Assistent auch Ihre Berufserfahrung kennen und wissen, welche Art von Job Sie suchen.
Um zu vermeiden, dass diese Informationen direkt in Ihren Code einfließen, ist es sinnvoll, sie aus einer JSON-Konfigurationsdatei zu lesen. Konkret sollte diese Datei Folgendes enthalten:
Ort: Der geografische Ort, an dem Sie nach Stellen suchen möchten. Damit wird das Hauptgebiet definiert, in dem Stellenanzeigen gesammelt werden sollen.keyword: Spezifische Wörter oder Phrasen, die sich auf die gesuchte Stellenbezeichnung oder Rolle beziehen, z. B. “Python Developer”. Verwenden Sie Anführungszeichen, um exakte Übereinstimmungen zu erzwingen.Land: Ein aus zwei Buchstaben bestehender Ländercode (z. B.USfür die Vereinigten Staaten,FRfür Frankreich), um die Stellensuche auf ein bestimmtes Land zu beschränken.Zeitbereich: Der Zeitraum, in dem die Stellenausschreibungen veröffentlicht wurden, um nach aktuellen oder relevanten Stellenangeboten zu filtern (z. B.letzte Woche,letzter Monatusw.).job_art: Die Art der Beschäftigung, nach der gefiltert werden soll, z. B.Vollzeit,Teilzeit, usw.erfahrung_level: Das erforderliche Maß an Berufserfahrung, z. B.Einstieg,Associateusw.entfernt: Filtern Sie Stellen nach dem Arbeitsort (z. B.Remote,Vor-OrtoderHybrid).Unternehmen: Fokussieren Sie die Suche auf offene Stellen eines bestimmten Unternehmens oder Arbeitgebers.selective_search: Wenn diese Option aktiviert ist, werden Stellenangebote, deren Titel die angegebenen Schlüsselwörter nicht enthalten, ausgeschlossen, um gezieltere Ergebnisse zu erzielen.jobs_nicht_einbeziehen: Eine Liste spezifischer Job-IDs, die von den Suchergebnissen ausgeschlossen werden sollen, nützlich zum Entfernen von Duplikaten oder unerwünschten Stellenangeboten.ort_radius: Legt fest, wie weit sich die Suche um den angegebenen Ort herum erstrecken soll, einschließlich der umliegenden Gebiete.profile_summary: Eine Zusammenfassung Ihres beruflichen Profils. Diese Informationen werden von der KI verwendet, um zu beurteilen, wie gut die einzelnen Stellen zu Ihnen passen.desired_job_summary: Eine kurze Beschreibung der Art der Stelle, die Sie suchen, um der KI zu helfen, die Stellenanzeigen nach ihrer Eignung zu bewerten.
Diese Angaben entsprechen genau den Argumenten, die von der Bright Data LinkedIn Job Listings “discover by keyword” API (die Teil der LinkedIn Jobs Scraper Lösung ist) benötigt werden:
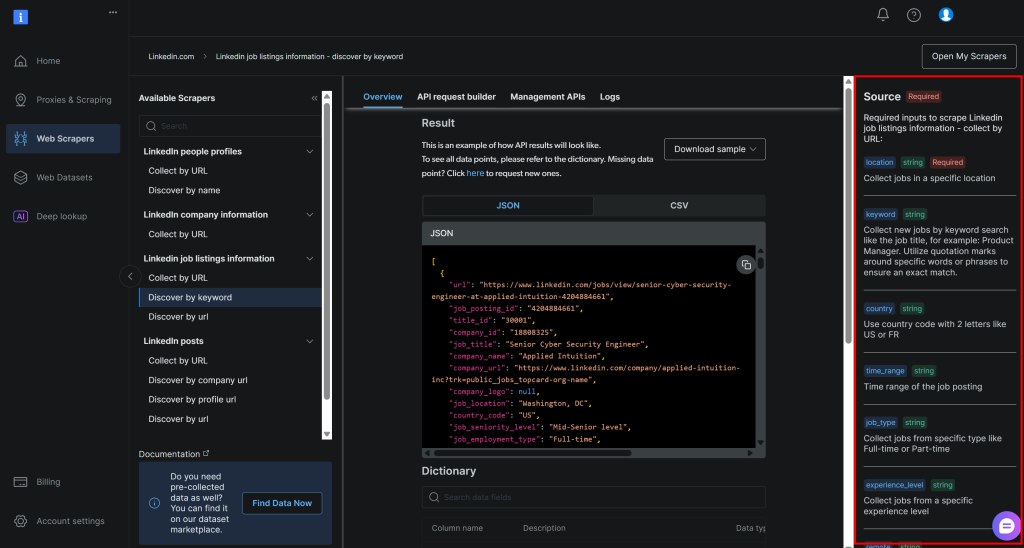
Weitere Informationen zu diesen Feldern und welche Werte sie annehmen können, finden Sie in den offiziellen Dokumenten.
Die letzten beiden Felder(profile_summary und desired_job_summary) beschreiben, wer Sie beruflich sind und wonach Sie suchen. Diese werden an die KI weitergegeben, um jede von Bright Data zurückgegebene Stellenausschreibung zu bewerten.
Um die Handhabung der Konfigurationsdatei im Code zu vereinfachen, empfiehlt es sich, sie auf ein Pydantic-Modell abzubilden. Installieren Sie zunächst Pydantic in Ihrer virtuellen Umgebung:
pip install pydanticDann definieren Sie das Pydantic-Modell, das die JSON-Konfigurationsdatei wie folgt abbildet:
class JobSearchConfig(BaseModel):
location: str
keyword: Optional[str] = None
country: Optional[str] = None
Zeitbereich: Optional[str] = Keine
job_type: Optional[str] = Keine
erfahrung_level: Optional[str] = Keine
entfernt: Optional[str] = Keine
Unternehmen: Optional[str] = Keine
selective_search: Optional[bool] = Feld (Standard=False)
jobs_to_not_include: Optional[Liste[str]] = Feld(default_factory=list)
ort_radius: Optional[str] = None
# Zusätzliche Felder
profile_summary: str # Profilzusammenfassung des Bewerbers für die AI-Bewertung
desired_job_summary: str # Beschreibung des gewünschten Jobs für die AI-BewertungBeachten Sie, dass nur die ersten und letzten beiden Konfigurationsfelder erforderlich sind.
Als Nächstes erstellen Sie eine Funktion zum Lesen der JSON-Konfigurationen aus dem Dateipfad --config_file. Deserialisieren Sie sie in eine JobSearchConfig-Instanz:
def load_and_validate_config(filename: str) -> JobSearchConfig:
# JSON-Konfigurationsdatei laden
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Konfigurationsdatei '{Dateiname}' nicht gefunden.")
try:
# Deserialisiere die eingegebenen JSON-Daten in eine JobSearchConfig-Instanz
config = JobSearchConfig(**Daten)
except ValidationError as e:
raise ValueError(f "Config deserialization error:n{e}")
return configDieses Mal benötigen Sie diese Importe:
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, Liste
importiere jsonGroßartig! Jetzt wird Ihre Konfigurationsdatei ordnungsgemäß gelesen und wie vorgesehen deserialisiert.
Schritt #4: Scrapen Sie die Jobs von LinkedIn
Es ist an der Zeit, die zuvor geladene Konfiguration zu verwenden, um die Bright Data LinkedIn Jobs Scraper-API aufzurufen.
Wenn Sie mit der Funktionsweise der Web Scraper-APIs von Bright Data nicht vertraut sind, sollten Sie zunächst einen Blick in die Dokumentation werfen.
Kurz gesagt: Web Scraper-APIs bieten API-Endpunkte, mit denen Sie öffentliche Daten von bestimmten Domänen abrufen können. Hinter den Kulissen initialisiert Bright Data eine vorgefertigte Scraping-Aufgabe auf seinen Servern und führt sie aus. Diese APIs handhaben IP-Rotation, CAPTCHA und andere Maßnahmen zur effektiven und ethischen Erfassung öffentlicher Daten von Webseiten. Sobald die Aufgabe abgeschlossen ist, werden die gesammelten Daten in ein strukturiertes Format umgewandelt und Ihnen als Schnappschuss zur Verfügung gestellt.
Der allgemeine Arbeitsablauf ist also wie folgt:
- Lösen Sie den API-Aufruf aus, um eine Web-Scraping-Aufgabe zu starten.
- Regelmäßige Überprüfung, ob der Snapshot mit den gescrapten Daten bereit ist.
- Abrufen der Daten aus dem Snapshot, sobald dieser verfügbar ist.
Sie können die obige Logik mit nur wenigen Zeilen Code implementieren:
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Auslösen der Bright Data LinkedIn-Jobsuche
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Vorbereiten der Nutzdaten für die Bright Data-API auf der Grundlage der Benutzerkonfiguration
data = [{
"Standort": config.location,
"keyword": config.keyword oder "",
"land": config.country oder "",
"zeit_bereich": config.time_range oder "",
"job_type": config.job_type oder "",
"experience_level": config.experience_level oder "",
"remote": config.remote oder "", "remote": config.remote oder "",
"Firma": config.company oder "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include oder "",
"standort_radius": config.standort_radius oder "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Keine snapshot_id von Bright Data Trigger zurückgegeben.")
print(f "LinkedIn-Jobsuche ausgelöst! Snapshot-ID: {snapshot_id}")
# Abfrage des Snapshot-Endpunkts, bis die Daten bereit sind oder ein Timeout auftritt
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Abruf des Snapshots für ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Snapshot ist bereit: Rückgabe der JSON-Daten der Stellenausschreibungen
print("Snapshot ist bereit")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Snapshot ist noch nicht bereit: warten und erneut versuchen
print(f "Snapshot ist noch nicht bereit: Erneuter Versuch in {polling_timeout} Sekunden...")
time.sleep(abfrage_timeout)
sonst:
raise RuntimeError(f "Snapshot-Abfrage fehlgeschlagen: {snap_resp.status_code} - {snap_resp.text}")Diese Funktion löst den LinkedIn Jobs Scraper von Bright Data anhand von Suchparametern aus der Konfigurationsdatei aus und stellt sicher, dass Sie nur Angebote erhalten, die Ihren Kriterien entsprechen. Sie fragt dann ab, bis der Daten-Snapshot bereit ist, und gibt, sobald er verfügbar ist, die Stellenanzeigen im JSON-Format zurück. Beachten Sie, dass die Authentifizierung über den Bright Data-API-Schlüssel erfolgt, der zuvor aus Ihren Umgebungsvariablen geladen wurde.
Der Snapshot, der mit dem LinkedIn Jobs Scraper abgerufen wird, enthält Stellenanzeigen im JSON-Format wie folgt:
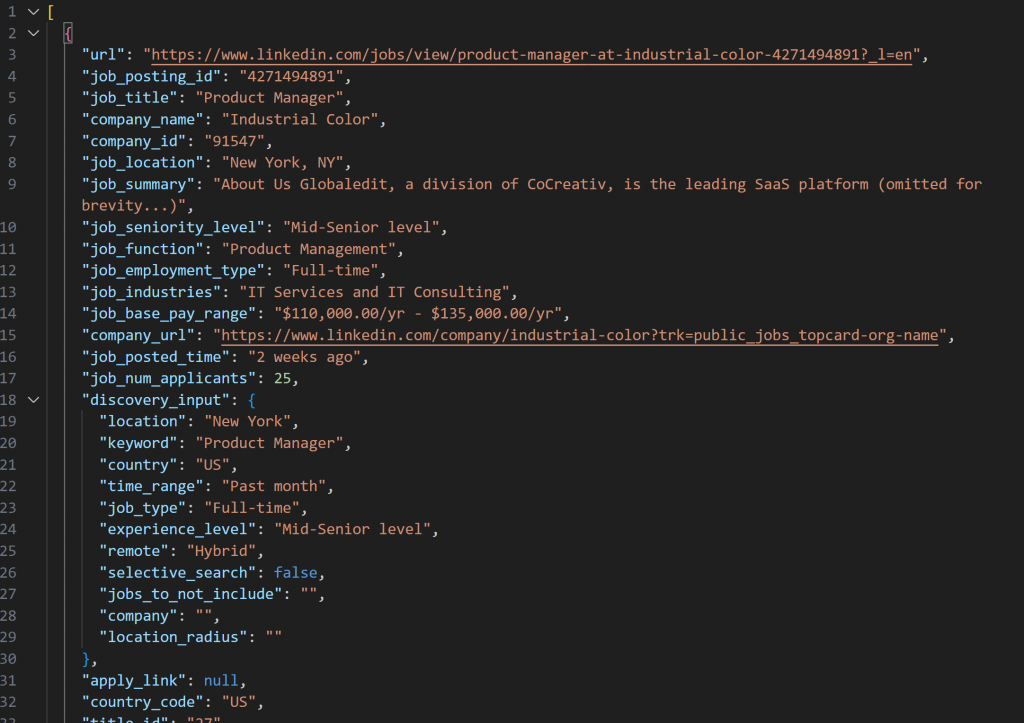
Hinweis: Der erzeugte JSON-Snapshot enthält genau bis zu --jobs_number Jobs. In diesem Fall enthält er 20 Stellen.
Damit die obige Funktion funktioniert, müssen Sie requests installieren:
pip install requestsWeitere Informationen zur Funktionsweise finden Sie in unserem Leitfaden für Fortgeschrittene zu Python HTTP Requests.
Vergessen Sie nicht, die Funktion zusammen mit time aus der Python-Standardbibliothek zu importieren:
import requests
importiere ZeitGroßartig! Sie haben soeben eine Integration mit Bright Data vorgenommen, um frische, spezifische LinkedIn-Stellenanzeigen-Daten zu sammeln.
Schritt #5: Bewerten Sie die Jobs mit KI
Nun ist es an der Zeit, ein LLM (wie die Modelle von OpenAI) zu bitten, jede gescrapte Stellenanzeige zu bewerten.
Das Ziel ist es, eine Punktzahl von 0 bis 100 zusammen mit einem kurzen Kommentar zu vergeben, je nachdem, wie gut die Stelle passt:
- Ihre Berufserfahrung
(profile_summary) - Ihre gewünschte Position
(desired_job_summary)
Um API-Roundtrips zu reduzieren und die Abläufe zu beschleunigen, ist es sinnvoll, Jobs in Batches zu verarbeiten. Insbesondere werden Sie eine Anzahl --batch_size von Jobs auf einmal auswerten.
Installieren Sie zunächst das openai-Paket:
pip install openaiDann importieren Sie OpenAI und initialisieren den Client:
from openai import OpenAI
# ...
# OpenAI-Client initialisieren
client = OpenAI()Beachten Sie, dass Sie Ihren API-Schlüssel nicht manuell an den OpenAI-Konstruktor übergeben müssen. Die Bibliothek liest ihn automatisch aus der Umgebungsvariablen OPENAI_API_KEY, die Sie bereits gesetzt haben.
Fahren Sie mit der Erstellung der KI-gesteuerten Jobbewertungsfunktion fort:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Prompt für KI konstruieren, um Job-Matches basierend auf dem Kandidatenprofil zu bewerten
prompt = f"""
"Sie sind ein Experte für Personalbeschaffung. Given the following candidate profile:n"
"{profile_summary}nn"
"Gewünschte Stellenbeschreibung:n{desired_job_summary}nn"
"Bewerten Sie jede Stellenausschreibung genau von 0 bis 100 danach, wie gut sie dem Profil und der gewünschten Stelle entspricht.n"
"Fügen Sie für jede Stelle einen kurzen Kommentar (max. 50 Wörter) hinzu, der die Bewertung und die Qualität der Übereinstimmung erklärt.n"
"Geben Sie ein Array von Objekten mit den Schlüsseln 'job_posting_id', 'score' und 'comment' zurück.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
messages = [
{"role": "system", "content": "Sie sind ein hilfreicher Assistent bei der Jobbewertung"},
{"role": "Benutzer", "Inhalt": "Eingabeaufforderung"},
]
# OpenAI API verwenden, um die strukturierte Antwort in das JobScoresResponse-Modell zu parsen
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Liste der bewerteten Aufträge zurückgeben
return response.output_parsed.scoresHier wird das neue gpt-5-mini-Modell verwendet, damit OpenAI jede gescrapte Stellenausschreibung auf einer Skala von 0 bis 100 bewertet, zusammen mit einem kurzen erklärenden Kommentar.
Um sicherzustellen, dass die Antwort immer in genau dem Format zurückgegeben wird, das Sie benötigen, wird die Methode parse() aufgerufen. Diese Methode erzwingt ein strukturiertes Ausgabemodell, das hier mit den folgenden Pydantic-Modellen definiert ist:
class JobScore(BaseModel):
job_posting_id: str
score: int = Feld(..., ge=0, le=100)
Kommentar: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]Grundsätzlich wird die KI strukturierte JSON-Daten wie folgt zurückgeben:
{
"scores": [
{
"job_posting_id": "4271494891",
"score": 80,
"comment": "Starker SaaS-Produkt-Fit mit End-to-End-Eigentum, APIs und funktionsübergreifender Arbeit - passt zu Ihrem Startup-PM und Ihrer Erfahrung mit Kundenorientierung. Role targets 2-4 yrs, so it's slightly junior for your 7 years."
},
// der Kürze halber weggelassen...
{
"job_posting_id": "4273328527",
"score": 65,
"comment": "Produktrolle mit starkem Daten-/Technik-Schwerpunkt; agile und funktionsübergreifende Verantwortlichkeiten stimmen überein, aber es bevorzugt quantitative/technische Domänenerfahrung (Finanzen/Stat-Modellierung), was eine schwächere Passung sein kann."
}
]
}Die parse() -Methode wandelt dann die JSON-Antwort in eine JobScoresResponse-Instanz um. Anschließend können Sie in Ihrem Code programmatisch auf die Bewertungen und Kommentare zugreifen.
Hinweis: Wenn Sie einen anderen LLM-Anbieter bevorzugen, müssen Sie den obigen Code entsprechend anpassen, damit er mit dem gewählten Anbieter funktioniert.
Jetzt geht’s los! Die AI-Job-Bewertung ist abgeschlossen.
Schritt #6: Erweitern Sie die Jobs mit AI-Acores und Kommentaren
Werfen Sie einen Blick auf die rohe JSON-Ausgabe, die von der KI zurückgegeben wurde, wie oben gezeigt. Sie können sehen, dass jede Jobbewertung ein job_posting_id-Feld enthält. Dies entspricht der ID, die LinkedIn zur Identifizierung von Stellenangeboten verwendet.
Da diese IDs auch in den vom Bright Data LinkedIn Jobs Scraper erzeugten Snapshot-Daten erscheinen, können Sie sie verwenden, um:
- Finden Sie die ursprünglichen Stellenausschreibungsobjekte aus dem Array der gescrapten Stellen.
- Anreichern dieses Stellenausschreibungsobjekts durch Hinzufügen der KI-generierten Bewertung und des Kommentars.
Erreichen Sie dies mit der folgenden Funktion:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Wo werden die angereicherten Daten gespeichert?
extended_jobs = []
# Kombinieren Sie die ursprünglichen Jobs mit AI-Bewertungen und Kommentaren
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_mit_Punktzahl = dict(matched_job)
job_mit_punktzahl["ai_punktzahl"] = punktzahl_obj.punktzahl
job_mit_punktzahl["ai_kommentar"] = punktzahl_obj.kommentar
extended_jobs.append(job_mit_score)
# Erweiterte Jobs nach AI-Punktzahl sortieren (höchste zuerst)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobsWie Sie sehen, reichen ein paar for-Schleifen aus, um die Aufgabe zu bewältigen. Bevor Sie die angereicherten Daten zurückgeben, sortieren Sie die Liste in absteigender Reihenfolge nach ai_score. Auf diese Weise erscheinen die am besten übereinstimmenden Jobs ganz oben, so dass sie schnell und einfach zu erkennen sind.
Super! Ihr LinkedIn KI-Assistent für die Jobsuche ist jetzt fast einsatzbereit!
Schritt #7: Exportieren Sie die Daten der bewerteten Stellen
Verwenden Sie das in Python integrierte csv-Paket, um die gescrapten und angereicherten Jobdaten in eine CSV-Datei zu exportieren.
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Dynamisch die Feldnamen aus dem ersten Element des Arrays holen
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Erweiterte Auftragsdaten mit AI-Bewertungen in CSV schreiben
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writeow(job)
print(f "Exportierte {len(extended_jobs)} Jobs nach {output_csv}") Die obige Funktion wird aufgerufen, indem output_csv durch das CLI-Argument --output_csv ersetzt wird.
Vergessen Sie nicht, csv zu importieren:
import csvPerfekt! Der LinkedIn-Assistent für die Jobsuche exportiert nun die mit KI angereicherten Daten in eine CSV-Datei.
Schritt #8: Drucken Sie die Top Job Matches
Um eine sofortige Rückmeldung im Terminal zu erhalten, ohne die CSV-Ausgabedatei zu öffnen, schreiben Sie eine Funktion, die die wichtigsten Details der 3 besten Jobtreffer ausgibt:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL: {job.get('url', 'N/A')}")
print(f "Titel: {job.get('job_title', 'N/A')}")
print(f "AI Score: {job.get('ai_score')}")
print(f "AI Kommentar: {job.get('ai_comment', 'N/A')}")
print("-" * 40)Schritt #9: Alles zusammenfügen
Kombinieren Sie alle Funktionen aus den vorangegangenen Schritten in der Hauptlogik des LinkedIn-Stellensuchassistenten:
# Laufzeitparameter von der CLI abrufen
args = parse_cli_args()
try:
# API-Schlüssel aus der Umgebung laden
_, brightdata_api_key = load_env_vars()
# Konfigurationsdatei für die Auftragssuche laden
config = load_and_validate_config(args.config_file)
# Jobs abrufen
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs gefunden!")
except Exception as e:
print(f"[Fehler] {e}")
return
all_scores = []
# Jobs in Batches verarbeiten, um eine Überlastung der API zu vermeiden und große Datensätze zu verarbeiten
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f "Scoring batch {i // args.batch_size + 1} with {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Um das Auslösen von API-Ratenlimits zu vermeiden
# Punkte in die ausgewerteten Aufträge einfügen
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Ergebnisse in CSV speichern
export_extended_jobs(extended_jobs, args.output_csv)
# Die besten Jobübereinstimmungen mit Schlüsselinformationen zur schnellen Überprüfung ausgeben
print_top_jobs(extended_jobs)Unglaublich! Es bleibt nur noch, den kompletten Code des Assistenten zu überprüfen und sicherzustellen, dass er wie erwartet funktioniert.
Schritt #10: Vollständiger Code und erster Durchlauf
Ihre endgültige assistant.py-Datei sollte Folgendes enthalten:
# pip install python-dotenv requests openai pydantic
import argparse
von dotenv importieren load_dotenv
importieren os
von pydantic importieren BaseModel, Feld, ValidationError
from typing import Optional, Liste
importiere json
importiere Anfragen
importiere Zeit
von openai importieren OpenAI
csv importieren
# Umgebungsvariablen aus .env-Datei laden
load_dotenv()
# Pydantische Modelle zur Unterstützung des Projekts
class JobSearchConfig(BaseModel):
# Quelle: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
Standort: str
keyword: Optional[str] = None
country: Optional[str] = Keine
Zeitbereich: Optional[str] = Keine
job_type: Optional[str] = Keine
erfahrung_level: Optional[str] = Keine
entfernt: Optional[str] = Keine
Unternehmen: Optional[str] = Keine
selective_search: Optional[bool] = Feld (Standard=False)
jobs_to_not_include: Optional[Liste[str]] = Feld(default_factory=list)
ort_radius: Optional[str] = None
# Zusätzliche Felder
profile_summary: str # Profilzusammenfassung des Bewerbers für die AI-Bewertung
desired_job_summary: str # Beschreibung des gewünschten Jobs für die AI-Bewertung
class JobScore(BaseModel):
job_posting_id: str
score: int = Feld(..., ge=0, le=100)
kommentar: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]
def parse_cli_args():
# Parsen von Kommandozeilenargumenten für Konfigurations- und Laufzeitoptionen
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Pfad zur JSON-Datei der Konfiguration")
parser.add_argument("--jobs_number", type=int, default=20, help="Begrenzt die Anzahl der von der Bright Data Scraper API zurückgegebenen Aufträge")
parser.add_argument("--batch_size", type=int, default=5, help="Anzahl der Aufträge, die in jedem Batch bewertet werden")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="CSV-Dateiname der Ausgabe")
return parser.parse_args()
def load_env_vars():
# Erforderliche API-Schlüssel aus der Umgebung auslesen und das Vorhandensein überprüfen
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
wenn fehlend:
raise EnvironmentError(
f "Fehlende erforderliche Umgebungsvariablen: {', '.join(missing)}n"
"Bitte setzen Sie sie in Ihrer .env oder Umgebung."
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# JSON-Konfigurationsdatei laden
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Konfigurationsdatei '{Dateiname}' nicht gefunden.")
try:
# Deserielisieren der JSON-Eingabedaten zu einer JobSearchConfig-Instanz
config = JobSearchConfig(**Daten)
except ValidationError as e:
raise ValueError(f "Config deserialization error:n{e}")
return config
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Auslösen der Bright Data LinkedIn-Jobsuche
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Vorbereiten der Nutzdaten für die Bright Data-API auf der Grundlage der Benutzerkonfiguration
data = [{
"Standort": config.location,
"keyword": config.keyword oder "",
"land": config.country oder "",
"zeit_bereich": config.time_range oder "",
"job_type": config.job_type oder "",
"experience_level": config.experience_level oder "",
"remote": config.remote oder "",
"unternehmen": config.unternehmen oder "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include oder "",
"standort_radius": config.standort_radius oder "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Keine snapshot_id von Bright Data Trigger zurückgegeben.")
print(f "LinkedIn-Jobsuche ausgelöst! Snapshot-ID: {snapshot_id}")
# Snapshot-Endpunkt abfragen, bis die Daten bereit sind oder ein Timeout auftritt
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Abruf des Snapshots für ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Snapshot ist bereit: Rückgabe der JSON-Daten der Stellenausschreibungen
print("Snapshot ist bereit")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Snapshot ist noch nicht bereit: warten und erneut versuchen
print(f "Snapshot ist noch nicht bereit: Erneuter Versuch in {polling_timeout} Sekunden...")
time.sleep(abfrage_timeout)
sonst:
raise RuntimeError(f "Snapshot-Abfrage fehlgeschlagen: {snap_resp.status_code} - {snap_resp.text}")
# OpenAI-Client initialisieren
client = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Prompt für KI konstruieren, um Job-Matches basierend auf dem Kandidatenprofil zu bewerten
prompt = f"""
"Sie sind ein Experte für Personalbeschaffung. Given the following candidate profile:n"
"{profile_summary}nn"
"Gewünschte Stellenbeschreibung:n{desired_job_summary}nn"
"Bewerten Sie jede Stellenausschreibung genau von 0 bis 100 danach, wie gut sie dem Profil und der gewünschten Stelle entspricht.n"
"Fügen Sie für jede Stelle einen kurzen Kommentar (max. 50 Wörter) hinzu, der die Bewertung und die Qualität der Übereinstimmung erklärt.n"
"Geben Sie ein Array von Objekten mit den Schlüsseln 'job_posting_id', 'score' und 'comment' zurück.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
messages = [
{"role": "system", "content": "Sie sind ein hilfreicher Assistent bei der Jobbewertung"},
{"role": "Benutzer", "Inhalt": "Eingabeaufforderung"},
]
# OpenAI API verwenden, um die strukturierte Antwort in das JobScoresResponse-Modell zu parsen
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Liste der bewerteten Aufträge zurückgeben
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Wo werden die angereicherten Daten gespeichert?
extended_jobs = []
# Kombinieren Sie die ursprünglichen Jobs mit AI-Bewertungen und Kommentaren
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_mit_Punktzahl = dict(matched_job)
job_mit_punktzahl["ai_punktzahl"] = punktzahl_obj.punktzahl
job_mit_punktzahl["ai_kommentar"] = punktzahl_obj.kommentar
extended_jobs.append(job_mit_score)
# Erweiterte Jobs nach AI-Punktzahl sortieren (höchste zuerst)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Dynamische Ermittlung der Feldnamen aus dem ersten Element des Arrays
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Erweiterte Auftragsdaten mit AI-Bewertungen in CSV schreiben
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writeow(job)
print(f "Exportierte {len(extended_jobs)} Jobs nach {output_csv}")
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL: {job.get('url', 'N/A')}")
print(f "Titel: {job.get('job_title', 'N/A')}")
print(f "AI Score: {job.get('ai_score')}")
print(f "AI Kommentar: {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# Laufzeitparameter von CLI holen
args = parse_cli_args()
try:
# API-Schlüssel aus der Umgebung laden
_, brightdata_api_key = load_env_vars()
# Konfigurationsdatei für die Auftragssuche laden
config = load_and_validate_config(args.config_file)
# Jobs abrufen
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs gefunden!")
except Exception as e:
print(f"[Fehler] {e}")
return
all_scores = []
# Jobs in Batches verarbeiten, um eine Überlastung der API zu vermeiden und große Datensätze zu verarbeiten
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f "Scoring batch {i // args.batch_size + 1} with {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Um das Auslösen von API-Ratenlimits zu vermeiden
# Punkte in die ausgewerteten Aufträge einfügen
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Ergebnisse in CSV speichern
export_extended_jobs(extended_jobs, args.output_csv)
# Die besten Jobübereinstimmungen mit Schlüsselinformationen zur schnellen Überprüfung ausgeben
print_top_jobs(extended_jobs)
if __name__ == "__main__":
main()Nehmen wir an, Sie sind ein Produktmanager mit 7 Jahren Erfahrung, der nach einer Hybrid-Stelle in New York sucht. Konfigurieren Sie Ihre config.json-Datei wie folgt:
{
"location": "New York",
"keyword": "Produktmanager",
"Land": "US",
"zeit_bereich": "Vergangener Monat",
"job_type": "Vollzeit",
"experience_level": "Mittleres-Senior-Level",
"remote": "Hybrid",
"profile_summary": "Erfahrener Produktmanager mit 7 Jahren Erfahrung in Tech-Startups, spezialisiert auf agile Methoden und funktionsübergreifende Teamführung.",
"desired_job_summary": "Ich suche eine Vollzeitstelle als Produktmanager mit Schwerpunkt auf SaaS-Produkten und kundenorientierter Entwicklung."
}Dann können Sie den LinkedIn-Assistenten für die Stellensuche mit ausführen:
python assistant.pyOptional: Für einen benutzerdefinierten Lauf, schreiben Sie etwas wie:
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvMit diesem Befehl wird der Assistent unter Verwendung der von Ihnen angegebenen config.json-Datei ausgeführt. Er verarbeitet Aufträge in Stapeln von 10 Aufträgen, ruft bis zu 40 Auftragslisten von Bright Data ab und speichert die angereicherten Ergebnisse mit KI-Bewertungen und Kommentaren in results.csv.
Wenn Sie nun den Assistenten mit den Standard-CLI-Argumenten ausführen, sollten Sie im Terminal etwa Folgendes sehen:
LinkedIn-Stellensuche ausgelöst! Schnappschuss-ID: s_me6x0s3qldm9zz0wv
Abruf des Snapshots für ID: s_me6x0s3qldm9zz0wv
Snapshot noch nicht bereit. Erneuter Versuch in 10 Sekunden...
# Der Kürze halber ausgelassen...
Snapshot noch nicht fertig. Erneuter Versuch in 10 Sekunden...
Schnappschuss ist bereit
20 Aufträge gefunden!
Stapel 1 mit 5 Aufträgen wird ausgewertet...
Auswertung Batch 2 mit 5 Aufträgen...
Auswertung Batch 3 mit 5 Aufträgen...
Auswertung Batch 4 mit 5 Aufträgen...
20 Aufträge in jobs.csv exportiertDie Ausgabe mit den Top-3-Jobs sieht dann etwa so aus:
*** Top 3 Jobübereinstimmungen ***
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
Titel: Produktmanager, Wachstum
AI-Wertung: 92
AI-Kommentar: Passt hervorragend: SaaS-fokussierter Wachstums-PM mit kundenzentrierten Zielen, produktgesteuertem Wachstum, Experimenten und funktionsübergreifender Zusammenarbeit - direkte Übereinstimmung mit der Erfahrung des Kandidaten und der gewünschten Rolle.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
Titel: Produktmanager
AI-Wertung: 90
KI-Kommentar: Starke Übereinstimmung: SaaS-Produkt, API/Integrationen, agile und funktionsübergreifende Führung hervorgehoben. Die einzige kleine Unstimmigkeit ist das angegebene Ziel von 2-4 Jahren (Sie haben 7), was Sie wahrscheinlich überqualifiziert, aber sehr geeignet macht.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
Titel: Produktmanager
AI-Wertung: 88
KI-Kommentar: Sehr ähnliche Rolle im Bereich SaaS/Integration mit agilen Praktiken und kundenorientierter Iteration. Der Personalvermittler gibt 2-4 Jahre an, aber Ihre 7 Jahre Erfahrung als PM in einem Startup und Ihre funktionsübergreifende Führungsrolle passen gut.
----------------------------------------Öffnen Sie die generierte Datei jobs_scored.csv. In den Hauptspalten werden Sie sehen:
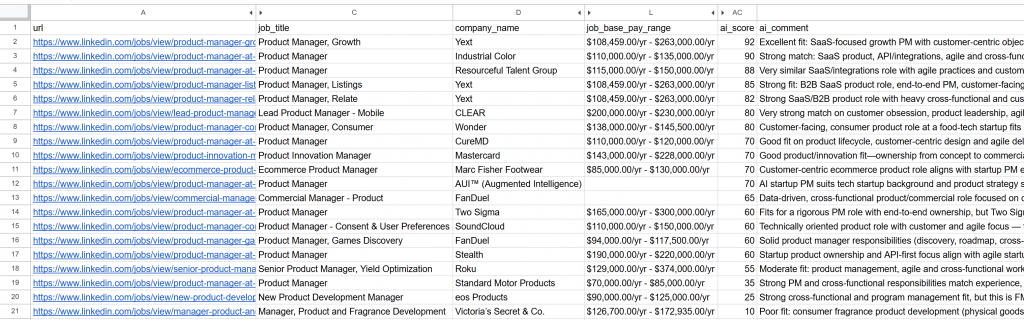
Beachten Sie, wie jede Stelle von der KI bewertet und kommentiert wurde. Dies hilft Ihnen, sich nur auf die Stellen zu konzentrieren, bei denen Sie eine echte Chance auf Erfolg haben!
Et voilà! Dank dieses KI-gestützten LinkedIn-Jobjagd-Workflows war es noch nie so einfach, Ihren nächsten Job zu finden.
Nächste Schritte
Der hier vorgestellte LinkedIn-Assistent für die Stellensuche funktioniert wie ein Chat, aber es gibt noch einige Verbesserungen, die es zu entdecken gilt:
- Vermeiden Sie es, dieselben Stellen wiederholt zu bewerten: Um jedes Mal, wenn Sie das Skript ausführen, andere Jobs zu bewerten, setzen Sie das Array
jobs_to_not_includein Ihrerconfig.json-Datei. Dieses sollte diejob_posting_idsvon Aufträgen enthalten, die der Assistent bereits analysiert hat. Um zum Beispiel die aktuell ausgewerteten Jobs auszuschließen, könnte Ihre Konfiguration wie folgt aussehen:
{
"location": "New York",
"keyword": "Produktmanager",
"Land": "US",
"zeit_bereich": "Vergangener Monat",
"job_type": "Vollzeit",
"experience_level": "Mittleres-Senior-Level",
"remote": "Hybrid",
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4252894407"], // <--- HINWEIS: Die IDs der Jobs, die ausgeschlossen werden sollen
"profile_summary": "Erfahrener Produktmanager mit 7 Jahren Erfahrung in Tech-Startups, spezialisiert auf agile Methoden und funktionsübergreifende Teamführung.",
"desired_job_summary": "Ich suche eine Vollzeitstelle als Produktmanager mit Schwerpunkt auf SaaS-Produkten und kundenorientierter Entwicklung."
}- Automatisieren Sie regelmäßige Skriptläufe: Planen Sie das Skript so, dass es regelmäßig (z. B. täglich) mit Tools wie Cron ausgeführt wird. Denken Sie in diesem Fall daran, das richtige
time_range-Argumentzu setzen (z. B. “Past 24 hours”) und diejobs_to_not_include-Listezu aktualisieren, um Jobs auszuschließen, die Sie bereits bewertet haben. So können Sie sich auf neue Stellenausschreibungen konzentrieren. - Verwenden Sie ein spezielles KI-Beurteilungsmodell: Ziehen Sie in Erwägung, anstelle eines allgemeinen GPT-5-Modells ein spezielles KI-Modell zu verwenden , das genau auf den Abgleich und die Bewertung von Stellenangeboten abgestimmt ist. Diese einfache Änderung kann die Genauigkeit und Relevanz der Stellenbewertungen erheblich verbessern.
Fazit
In diesem Artikel haben Sie erfahren, wie Sie die Funktionen von Bright Data zum Scannen von LinkedIn-Stellen nutzen können, um einen KI-gestützten Assistenten für die Stellensuche zu erstellen.
Der hier entwickelte KI-Workflow ist perfekt für alle, die einen neuen Job suchen und ihre Chancen maximieren möchten, indem sie sich nur auf die besten Möglichkeiten konzentrieren. Er hilft Ihnen, Zeit und Energie zu sparen, indem Sie sich auf Stellen bewerben, die wirklich ihren Karrierezielen entsprechen und eine höhere Chance auf eine Einstellung haben.
Um fortschrittlichere Workflows zu erstellen, erkunden Sie das gesamte Spektrum an Lösungen zum Abrufen, Validieren und Umwandeln von Live-Webdaten in der Bright Data AI-Infrastruktur.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren KI-fähigen Datentools!
FAQs
Das obige Beispiel verwendet LinkedIn als Datenquelle, aber Sie können das Skript leicht erweitern, um mit Indeed oder anderen über Bright Data verfügbaren Quellen für Stellenanzeigen zu arbeiten. Weitere Einzelheiten zur Integration mit Indeed finden Sie im Indeed Jobs Scraper.
Dieser KI-Workflow stützt sich auf OpenAI, weil es weit verbreitet und beliebt ist. Sie können den Workflow jedoch leicht anpassen, um mit anderen LLM-Anbietern wie Gemini, Anthropic, Cohere oder jedem anderen über die API verfügbaren großen Sprachmodell zu arbeiten.
Die vom LinkedIn Jobs Scraper zurückgegebenen Daten sind so hochwertig und gut strukturiert, dass Sie sie direkt mit einem LLM für das Scoring verarbeiten können. Aus diesem Grund benötigen Sie nicht unbedingt die Komplexität eines autonomen Agenten mit Argumentations- und Entscheidungsfähigkeiten.
Wenn Sie jedoch einen fortschrittlicheren KI-Agenten für die LinkedIn-Stellensuche entwickeln möchten, können Sie die folgende Multi-Agenten-Architektur in Betracht ziehen:
Job fetcher agent: Ein in die Bright Data-Infrastruktur integrierter KI-Agent (über Tooling oder MCP), der die LinkedIn Jobs Scraper API aufruft, um fortlaufend Stellenanzeigen abzurufen und zu aktualisieren.
Job Scorer Agent: Ein Agent, der darauf spezialisiert ist, Jobs auf der Grundlage des Profils und der Präferenzen des Bewerbers mit Hilfe eines LLM zu bewerten und einzustufen.
Orchestrator-Agent: Ein übergeordneter Agent, der die beiden anderen Agenten koordiniert und wiederholt Datenabrufe und Bewertungszyklen auslöst, bis die gewünschte Anzahl relevanter Stellenangebote mit hoher Punktzahl erreicht ist.
Sie könnten den Agenten sogar so programmieren, dass er sich automatisch auf diese Stellenangebote für Sie bewirbt. Wenn Sie erwägen, ein solches LinkedIn-Stellensuchsystem aufzubauen, empfehlen wir die Verwendung einer Multi-Agenten-Plattform wie CrewAI.





