

In diesem Leitfaden erfahren Sie:
- Was ein Forschungsagent ist und warum traditionelle Methoden versagen
- Wie Sie Bright Data für eine zuverlässige Datenerfassung konfigurieren
- Wie Sie einen lokalen KI-gestützten Forschungsagenten mit Streamlit UI erstellen
- Wie Sie Bright Data APIs mit lokalen Modellen integrieren, um strukturierte Erkenntnisse zu gewinnen
Lassen Sie uns in die Entwicklung Ihres intelligenten Forschungsassistenten eintauchen. Wir empfehlen Ihnen auch Deep Lookup, die KI-gestützte Suchmaschine von Bright Data, mit der Sie das Web wie eine Datenbank durchsuchen können.
Branchenproblem
- Forscher sind mit zu vielen Informationen aus zahlreichen Quellen konfrontiert, was eine manuelle Überprüfung unpraktisch macht.
- Herkömmliche Recherchen erfordern eine langsame, manuelle Suche, Extraktion und Synthese.
- Die Ergebnisse sind oft unvollständig, unzusammenhängend und schlecht organisiert.
- Einfache Scraping-Tools liefern Rohdaten ohne Glaubwürdigkeit oder Kontext.
Die Lösung: Forschungsagent
Ein Deep Research Agent ist ein KI-System, das die Recherche von der Erfassung bis zur Berichterstattung automatisiert. Es kümmert sich um den Kontext, verwaltet Aufgaben und liefert gut strukturierte Erkenntnisse.
Schlüsselkomponenten:
- Planner Agent: unterteilt die Recherche in Aufgaben
- Research SubAgents: führt Recherchen durch und extrahiert Daten
- Writer Agent: stellt strukturierte Berichte zusammen
- Condition Agent: prüft die Qualität und stößt bei Bedarf tiefergehende Recherchen an
In diesem Handbuch wird gezeigt, wie ein lokales Recherchesystem mithilfe der APIs von Bright Data, einer Streamlit-Benutzeroberfläche und lokalen LLMs für Datenschutz und Kontrolle erstellt wird.
Voraussetzungen
- Bright Data-Konto mit API-Schlüssel.
- Python 3.10+
- Abhängigkeiten:
Anfragenfaissoderchromadbpython-dotenvstreamlitollama(für lokale Modelle)
Bright Data-Konfiguration
Bright Data-Konto erstellen
- Registrieren Sie sich bei Bright Data
- Navigieren Sie zum Abschnitt API-Anmeldeinformationen
- Erzeugen Sie Ihr API-Token
Speichern Sie Ihre API-Anmeldeinformationen sicher mithilfe von Umgebungsvariablen. Erstellen Sie eine .env-Datei, um Ihre Anmeldeinformationen zu speichern und sensible Informationen von Ihrem Code getrennt zu halten.
BRIGHT_DATA_API_KEY="ihr_bright_data_api_token_hier"Umgebung einrichten
# venv erstellen
python -m venv venv
Quelle venv/bin/activate
# Abhängigkeiten installieren
pip install anfragen openai chromadb python-dotenv streamlitImplementierung
Schritt 1: Forschung
Dies wird unsere Forschungsaufgabe sein.
query = "KI Anwendungsfälle im Gesundheitswesen"Schritt 2: Daten abrufen
In diesem Schritt wird demonstriert, wie mit der API für die Datensammlung von Bright Data programmatisch Daten aus dem Web abgerufen werden. Der Code sendet eine Forschungsabfrage und ruft relevante Daten ab, wobei die API-Anmeldeinformationen sicher gehandhabt werden.
importieren Sie requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f "Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())Schritt 3: Verarbeiten und Einbetten
In diesem Schritt werden die abgerufenen Forschungsdaten verarbeitet und in ChromaDB gespeichert, einer Vektordatenbank, die eine semantische Suche und einen Ähnlichkeitsabgleich ermöglicht. So entsteht eine durchsuchbare Wissensdatenbank aus Ihren Forschungsergebnissen, die für KI-Anwendungsfälle im Gesundheitswesen oder jedes andere Forschungsthema abgefragt werden kann.
chromadb importieren
from chromadb.config import Einstellungen
# ChromaDB initialisieren
client = chromadb.PersistentClient(path="./research_db")
collection = client.get_or_create_collection("research_data")
# Forschungsergebnisse speichern
def store_research_data(results):
documents = []
metadatas = []
ids = []
for i, item in enumerate(results):
documents.append(item.get('content', ''))
metadatas.append({
'Quelle': item.get('Quelle', ''),
'query': query,
'zeitstempel': item.get('zeitstempel', '')
})
ids.append(f "doc_{i}")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)Schritt 4: Lokale Modellzusammenfassung
In diesem Schritt wird gezeigt, wie lokal ausgeführte große Sprachmodelle (LLMs) durch Ollama genutzt werden können, um prägnante Zusammenfassungen von Forschungsinhalten zu erstellen. Dieser Ansatz hält die Datenverarbeitung privat und ermöglicht Offline-Zusammenfassungsfunktionen.
importiere subprocess
json importieren
def summarize_with_ollama(content, model="llama2"):
"""Forschungsinhalte mit lokalem Ollama-Modell zusammenfassen""
try:
result = subprocess.run(
['ollama', 'run', model, f "Fassen Sie diesen Forschungsinhalt zusammen: {content[:2000]}"],
capture_output=True,
text=True,
timeout=120
)
return result.stdout.strip()
except Exception as e:
return f "Verdichtung fehlgeschlagen: {str(e)}"
# Beispiel für die Verwendung
research_data = res.json().get('results', [])
for item in research_data:
summary = summarize_with_ollama(item.get('content', ''))
print(f "Zusammenfassung: {Zusammenfassung}")ollama run llama2 "KI Anwendungsfälle im Gesundheitswesen zusammenfassen"Streamlit UI
Erstellen Sie schließlich eine vollständige Web-UI, die die Datensammlung von Bright Data mit der lokalen KI-Zusammenfassung durch Ollama kombiniert. Die Oberfläche ermöglicht es den Benutzern, über ein intuitives Dashboard Forschungsparameter zu konfigurieren, die Datenerfassung durchzuführen und KI-Zusammenfassungen zu generieren.
app.py erstellen
importiere streamlit as st
importiere Anfragen, os
from dotenv import load_dotenv
import subprocess
json importieren
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="🔎")
st.title("🔎 Lokaler Deep Research Agent mit hellen Daten")
# Konfiguration der Seitenleiste
mit st.sidebar:
st.header("Konfiguration")
api_key = st.text_input(
"Bright Data API-Schlüssel",
type="password",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Ollama Model",
["llama2", "mistral", "codellama"]
)
research_depth = st.slider("Forschungstiefe", 5, 50, 20)
# Hauptrecherche-Schnittstelle
query = st.text_input("Geben Sie das Forschungsthema ein:", "KI Anwendungsfälle im Gesundheitswesen")
col1, col2 = st.columns(2)
mit col1:
if st.button("🚀 Run Research", type="primary"):
if not api_key:
st.error("Bitte geben Sie Ihren Bright Data API-Schlüssel ein")
elif not query:
st.error("Bitte geben Sie ein Forschungsthema ein")
sonst:
with st.spinner("Collecting research data..."):
# Daten von Bright Data abrufen
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": abfrage, "limit": forschungstiefe}
headers = {"Authorization": f "Bearer {api_key}"}
res = requests.post(url, json=payload, headers=headers)
wenn res.status_code == 200:
st.success(f "Erfolgreich gesammelte {len(res.json().get('results', []))} Quellen!")
st.session_state.research_data = res.json()
# Ergebnisse anzeigen
for i, item in enumerate(res.json().get('results', [])):
with st.expander(f "Quelle {i+1}: {item.get('title', 'Kein Titel')}"):
st.write(item.get('content', 'Kein Inhalt vorhanden'))
sonst:
st.error(f "Failed to fetch data: {res.status_code}")
mit col2:
if st.button("🤖 Zusammenfassen mit Ollama"):
if 'research_data' in st.session_state:
with st.spinner("KI-Zusammenfassungen generieren..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('content', '')[:1500] # Länge des Inhalts begrenzen
try:
result = subprocess.run(
['ollama', 'run', model_choice, f "Fassen Sie diesen Inhalt zusammen: {content}"],
capture_output=True,
text=True,
timeout=60
)
Zusammenfassung = result.stdout.strip()
mit st.expander(f "KI Zusammenfassung {i+1}"):
st.write(summary)
except Exception as e:
st.error(f "Summarization failed for source {i+1}: {str(e)}")
else:
st.warning("Bitte führen Sie zuerst eine Recherche durch, um Daten zu sammeln")
# Rohdaten anzeigen, falls vorhanden
if 'research_data' in st.session_state:
with st.expander("Forschungsrohdaten anzeigen"):
st.json(st.session_state.research_data)Führen Sie die Anwendung aus:
streamlit run app.pyWenn Sie die Anwendung ausführen und Port 8501 besuchen, sollte dies die Benutzeroberfläche sein:
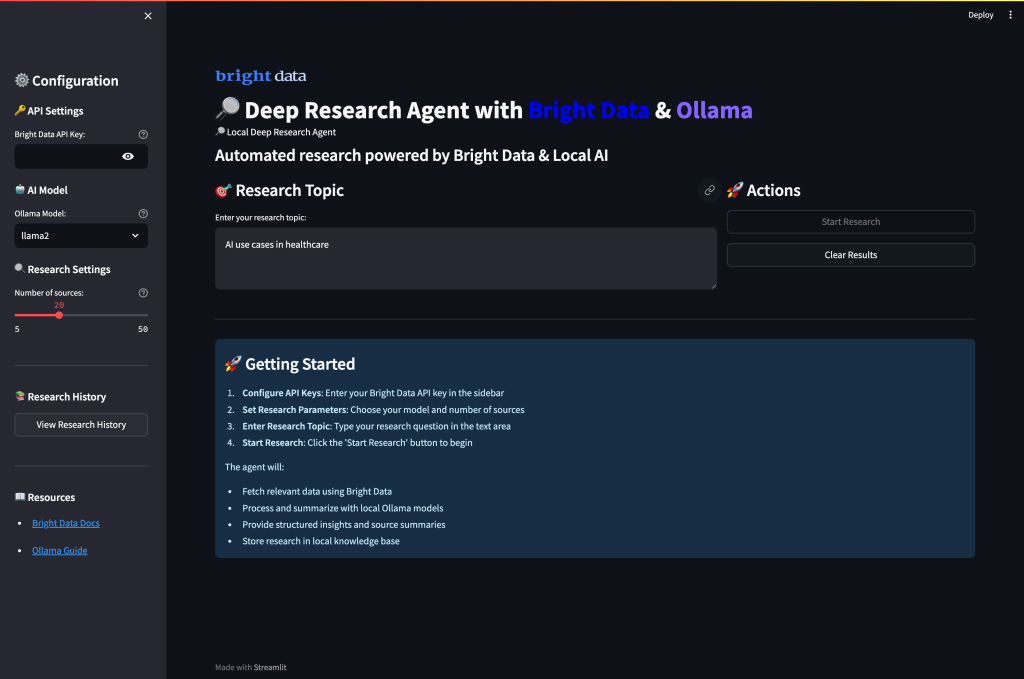
Ausführen Ihres Deep Research Agent
Führen Sie die Anwendung aus, um eine umfassende Forschung mit KI-gestützter Analyse durchzuführen. Öffnen Sie Ihr Terminal und navigieren Sie zu Ihrem Projektverzeichnis.
streamlit run app.pySie werden den intelligenten Multi-Agenten-Workflow des Systems sehen, während es Ihre Forschungsanfragen verarbeitet:
- Datenerfassungsphase: Der Agent holt über die zuverlässigen APIs von Bright Data umfassende Forschungsdaten aus verschiedenen Webquellen und filtert sie automatisch nach Relevanz und Glaubwürdigkeit.
- Verarbeitung der Inhalte: Jede Quelle wird einer intelligenten Analyse unterzogen, bei der das System Schlüsselinformationen extrahiert, Hauptthemen identifiziert und die Qualität des Inhalts mithilfe von semantischem Verständnis bewertet.
- KI-Zusammenfassung: Lokale Ollama-Modelle verarbeiten die gesammelten Daten und erstellen prägnante Zusammenfassungen, wobei wichtige Erkenntnisse erhalten bleiben und die kontextuelle Genauigkeit über alle Quellen hinweg gewahrt wird.
- Wissenssynthese: Das System identifiziert wiederkehrende Muster, verbindet verwandte Konzepte und erkennt aufkommende Trends durch die gleichzeitige Analyse von Informationen aus mehreren Quellen.
- Strukturierte Berichterstattung: Abschließend fasst der Agent alle Ergebnisse in einem umfassenden Forschungsbericht zusammen, der eine gute Organisation, klare Zitate und eine professionelle Formatierung aufweist und die wichtigsten Entdeckungen und Erkenntnisse hervorhebt.
Verbesserte Recherche-Pipeline
Erweitern Sie die Implementierung für fortgeschrittene Recherchefunktionen.
Mit dieser erweiterten Pipeline wird ein vollständiger Recherche-Workflow erstellt, der über eine einfache Zusammenfassung hinausgeht und strukturierte Analysen, wichtige Erkenntnisse und umsetzbare Ergebnisse aus den gesammelten Recherchedaten liefert. Die Pipeline integriert Bright Data für die Informationsbeschaffung und lokale Ollama-Modelle für die intelligente Analyse.
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""Komplette Forschungspipeline mit Datensammlung und KI-Analyse"""
# Schritt 1: Abrufen von Daten von Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f "Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
if response.status_code != 200:
return {"error": "Datenerfassung fehlgeschlagen"}
research_data = response.json()
# Schritt 2: Verarbeiten und Analysieren mit Ollama
insights = []
for item in research_data.get('results', []):
content = item.get('content', '')
# Erzeugen von Erkenntnissen für jede Quelle
analysis_prompt = f"""
Analysieren Sie diesen Inhalt und liefern Sie wichtige Erkenntnisse:
{content[:2000]}
Fokus auf:
- Hauptpunkte und Ergebnisse
- Schlüsseldaten und Statistiken
- Mögliche Anwendungen
- Erwähnte Beschränkungen
"""
try:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=True,
timeout=90
)
insights.append({
'Quelle': item.get('Quelle', ''),
Analyse': result.stdout.strip(),
title': item.get('title', '')
})
except Exception as e:
insights.append({
'source': item.get('source', ''),
analysis': f "Analyse fehlgeschlagen: {str(e)}",
'title': item.get('title', '')
})
return {
'research_data': research_data,
ai_insights': einblicke,
'query': query
}Schlussfolgerung
Dieser Local Deep Research Agent zeigt, wie ein automatisiertes Forschungssystem aufgebaut werden kann, das die zuverlässige Webdatenerfassung von Bright Data mit der lokalen KI-Verarbeitung mit Ollama kombiniert. Die Implementierung bietet:
- Privacy First-Ansatz: Die gesamte KI-Verarbeitung erfolgt lokal mit Ollama
- Zuverlässige Datenerfassung: Bright Data gewährleistet qualitativ hochwertige, strukturierte Webdaten
- Benutzerfreundliches Interface: Streamlit UI macht komplexe Forschung zugänglich
- Anpassbarer Workflow: Anpassbar an verschiedene Forschungsbereiche und Anforderungen
Das System löst die wichtigsten Herausforderungen der Branche, indem es die Datenerfassung, -verarbeitung und -analyse automatisiert und so stundenlange manuelle Recherchen in Minuten automatisierter Erkenntnisse verwandelt.
Um Ihre Forschungsmöglichkeiten weiter zu verbessern, sollten Sie die Datensatzlösungen von Bright Data für branchenspezifische Daten erkunden und die Verwendung von Deep Lookup für die Abfrage und Suche in der weltweit größten Datenbank für Webdaten in Betracht ziehen.
Sind Sie bereit, Ihren eigenen Forschungsagenten zu erstellen? Erstellen Sie ein kostenloses Bright Data-Konto, um mit der zuverlässigen Webdatenerfassung zu beginnen und Ihre Forschungsabläufe noch heute zu verändern.






