

In diesem Lernprogramm erfahren Sie:
- Warum Sie überhaupt eine benutzerdefinierte Lösung zur Markenüberwachung benötigen.
- Wie Sie eine solche mit dem Bright Data SDK, OpenAI und SendGrid erstellen.
- Wie man einen KI-Workflow zur Überwachung der Markenreputation in Python implementiert.
Sie können das GitHub-Repository für alle Projektdateien einsehen. Jetzt können wir eintauchen!
Warum eine maßgeschneiderte Lösung zur Markenüberwachung?
Die Markenüberwachung ist eine der wichtigsten Aufgaben im Marketing, und es gibt mehrere Online-Dienste, die dabei helfen. Das Problem bei diesen Lösungen ist, dass sie in der Regel teuer sind und möglicherweise nicht auf Ihre speziellen Bedürfnisse zugeschnitten sind.
Deshalb ist es sinnvoll, eine individuelle Lösung zur Überwachung der Markenreputation zu entwickeln. Auf den ersten Blick mag das einschüchternd klingen, da es als ein komplexes Ziel erscheinen mag. Mit den richtigen Tools (wie Sie gleich sehen werden) ist es jedoch durchaus machbar.
KI-Workflow für die Markenreputation – Erklärung des Workflows
Zuallererst können Sie kein effektives Markenüberwachungs-Tool ohne zuverlässige externe Informationen über Ihre Marke erstellen. Eine hervorragende Quelle hierfür ist Google News. Wenn Sie verstehen, was in den täglichen Nachrichtenartikeln über Ihre Marke gesagt wird und welche Stimmung dahinter steht, können Sie fundierte Entscheidungen treffen. Das Ziel ist es, zu reagieren, Ihre Marke zu schützen oder zu fördern.
Das Problem ist, dass das Auslesen von Nachrichtenartikeln eine Herausforderung darstellt. Insbesondere Google News ist durch mehrere Anti-Bot-Maßnahmen geschützt. Hinzu kommt, dass jede Nachrichtenquelle ihre eigene Website mit einzigartigen Schutzmaßnahmen hat, was eine konsistente programmatische Erfassung von Nachrichtendaten erschwert.
An dieser Stelle kommt Bright Data ins Spiel. Dank seiner Websuch- und Scraping-Fähigkeiten bietet es Ihnen zahlreiche Produkte und Integrationen für den programmatischen Zugriff auf KI-fähige öffentliche Webdaten von beliebigen Websites.
Mit dem neuen Bright Data SDK können Sie die nützlichsten Bright Data-Lösungen auf vereinfachte Weise mit nur wenigen Zeilen Python-Code nutzen!
Sobald Sie über die Nachrichtendaten verfügen, können Sie sich auf KI verlassen, um die relevantesten Artikel auszuwählen und sie im Hinblick auf Stimmungen und Markeneinblicke zu analysieren. Anschließend können Sie einen Dienst wie Twilio SendGrid nutzen, um den daraus resultierenden Bericht an Ihr gesamtes Marketingteam zu senden. Im Großen und Ganzen ist dies genau das, was ein benutzerdefinierter KI-Workflow zur Markenreputation leistet.
Lassen Sie uns nun einen genaueren Blick darauf werfen, wie man ihn aus technischer Sicht implementiert!
Technische Schritte
Die Schritte zur Implementierung des KI-Workflows zur Überwachung der Markenreputation sind:
- Laden der Umgebungsvariablen: Laden Sie die API-Schlüssel von Bright Data, OpenAI und SendGrid aus den Umgebungsvariablen. Diese Schlüssel werden benötigt, um eine Verbindung zu den Diensten von Drittanbietern herzustellen, die diesen Workflow betreiben.
- Laden Sie die Konfigurationsdatei: Lesen Sie eine JSON-Konfigurationsdatei (z. B.
config.json), die die anfänglichen Suchanfragen, die Anzahl der in den Bericht aufzunehmenden Nachrichtenartikel sowie die E-Mail-Adresse des Absenders und die E-Mail-Adressen der Empfänger enthält. - Abrufen von Google News-Seiten-URLs: Verwenden Sie das Bright Data SDK, um Suchmaschinenergebnisseiten (SERPs) für den konfigurierten Suchbegriff abzurufen. Greifen Sie von jeder dieser Seiten auf die URLs der Google News-Seiten zu.
- Scrapen Sie Google News-Seiten: Verwenden Sie das Bright Data SDK, um die vollständigen Google News-Seiten im Markdown-Format zu scrapen. Jede dieser Seiten enthält mehrere URLs von Nachrichtenartikeln.
- Lassen Sie die KI die wichtigsten Nachrichten identifizieren: Füttern Sie die gescrapten Google News-Seiten mit einem OpenAI-Modell und lassen Sie es die relevantesten Nachrichtenartikel für die Markenüberwachung auswählen.
- Scrapen Sie einzelne Nachrichtenartikel: Verwenden Sie das Bright Data SDK, um den Inhalt jedes von der KI zurückgegebenen Nachrichtenartikels abzurufen.
- Analysieren Sie Nachrichtenartikel auf Markenreputation: Füttern Sie die KI mit den einzelnen Nachrichtenartikeln und bitten Sie sie, eine Zusammenfassung, eine Stimmungsanalyse und wichtige Erkenntnisse zur Markenreputation zu liefern.
- Erstellen Sie einen abschließenden HTML-Bericht: Geben Sie die Ergebnisse der Nachrichtenanalyse an die KI weiter und bitten Sie sie, einen gut strukturierten HTML-Bericht zu erstellen.
- Versenden Sie den Bericht per E-Mail: Nutzen Sie das SendGrid SDK, um den von der KI erstellten HTML-Bericht an die angegebenen Empfänger zu senden und so einen umfassenden Überblick über die Markenreputation zu erhalten.

Sehen Sie, wie Sie diesen KI-Workflow in Python implementieren können!
Erstellen eines KI-gestützten Workflows zur Markenreputation mit dem Bright Data SDK
In diesem Tutorial erfahren Sie, wie Sie einen KI-Workflow zur Überwachung Ihrer Markenreputation erstellen können. Die erforderlichen Markennachrichtendaten werden von Bright Data über das Bright Data Python SDK bezogen. Die KI-Funktionen werden von OpenAI bereitgestellt, und die E-Mail-Zustellung wird über SendGrid abgewickelt.
Am Ende dieses Tutorials werden Sie über einen vollständigen Python-KI-Workflow verfügen, der die Ergebnisse direkt an Ihren Posteingang liefert. Der Ausgabebericht zeigt die wichtigsten Nachrichten auf, die Ihre Marke beachten sollte, und gibt Ihnen alles an die Hand, was Sie brauchen, um schnell zu reagieren und eine starke Markenpräsenz zu erhalten.
Lassen Sie uns einen KI-Workflow zur Markenreputation erstellen!
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen Sie über folgende Voraussetzungen verfügen:
- Lokal installiertes Python 3.8+.
- Einen Bright Data-API-Schlüssel.
- Einen OpenAI-API-Schlüssel.
- Einen Twilio SendGrid-API-Schlüssel.
Wenn Sie noch keinen Bright Data-API-Schlüssel haben, melden Sie sich bei Bright Data an, und folgen Sie der Einrichtungsanleitung. Befolgen Sie auch die offiziellen OpenAI-Anweisungen, um Ihren OpenAI-API-Schlüssel zu erhalten.
Für SendGrid erstellen Sie ein Konto, verifizieren es, verbinden eine E-Mail-Adresse und verifizieren Ihre Domäne. Erstellen Sie einen API-Schlüssel und überprüfen Sie, ob Sie programmatisch E-Mails über diesen Schlüssel versenden können.
Schritt #1: Erstellen Sie Ihr Python-Projekt
Öffnen Sie ein Terminal und erstellen Sie ein neues Verzeichnis für Ihren KI-Workflow zur Überwachung der Markenreputation:
mkdir brand-reputation-monitoring-workflowDer Ordner brand-reputation-monitoring-workflow/ wird den Python-Code für Ihren KI-Workflow enthalten.
Wechseln Sie nun in das Projektverzeichnis und richten Sie eine virtuelle Umgebung ein:
cd brand-reputation-monitoring-workflow
python -m venv .venvLaden Sie nun das Projekt in Ihre bevorzugte Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Fügen Sie innerhalb des Projektordners eine neue Datei namens workflow.py hinzu. Ihr Projekt sollte nun enthalten:
brand-reputation-monitoring-workflow/
├── .venv/
└── workflow.pyworkflow.py wird Ihre Haupt-Python-Datei sein.
Aktivieren Sie die virtuelle Umgebung. Unter Linux oder macOS führen Sie aus:
source .venv/bin/activateÄquivalent dazu führen Sie unter Windows aus:
.venv/Scripts/activateWenn die Umgebung aktiviert ist, installieren Sie die erforderlichen Abhängigkeiten mit:
pip install python-dotenv brightdata-sdk openai sendgrid pydanticDie Bibliotheken, die Sie gerade installiert haben, sind:
python-dotenv: Zum Laden von Umgebungsvariablen aus einer.env-Datei, wodurch die sichere Verwaltung von API-Schlüsseln erleichtert wird.brightdata-sdk: Für den Zugriff auf die Scraping-Tools und -Lösungen von Bright Data in Python.openai: Für die Interaktion mit den Sprachmodellen von OpenAI.sendgrid: Für den schnellen Versand von E-Mails mit der Twilio SendGrid Web API v3.pydantic: Zur Definition von Modellen für KI-Ausgaben und Ihrer Konfiguration.
Geschafft! Ihre Python-Entwicklungsumgebung ist nun bereit, einen KI-Workflow zur Überwachung der Markenreputation mit OpenAI, Bright Data SDK und SendGrid aufzubauen.
Schritt Nr. 2: Einrichten des Lesens von Umgebungsvariablen
Konfigurieren Sie Ihr Skript so, dass es Geheimnisse aus Umgebungsvariablen liest. Importieren Sie in Ihrer workflow.py-Datei python-dotenv und rufen Sie load_dotenv() auf, um Umgebungsvariablen automatisch zu laden:
from dotenv import load_dotenv
load_dotenv()Ihr Skript kann nun Variablen aus einer lokalen .env-Datei lesen. Erstellen Sie also eine .env-Datei im Stammverzeichnis Ihres Projekts:
brand-reputation-monitoring-workflow/
├── .venv/
├── .env # <-----------
└─── workflow.pyÖffnen Sie die .env-Datei und fügen Sie die envs OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN und SENDGRID_API_KEY hinzu:
OPENAI_API_KEY="<IHR_OPENAI_API_KEY>"
BRIGHT_DATA_API_TOKEN="<IHR_BRIGHT_DATA_API_TOKEN>"
SENDGRID_API_KEY="<IHR_SENDGRID_API_TOKEN>"Ersetzen Sie die Platzhalter durch Ihre tatsächlichen Anmeldedaten:
<YOUR_OPENAI_API_KEY>→ Ihr OpenAI-API-Schlüssel.<YOUR_BRIGHT_DATA_API_TOKEN>→ Ihr Bright Data-API-Token.<YOUR_SENDGRID_API_KEY>→ Ihr SendGrid-API-Schlüssel.
Super! Sie haben nun die Geheimnisse von Drittanbietern mithilfe von Umgebungsvariablen sicher konfiguriert.
Schritt Nr. 3: Initialisieren der SDKs
Beginnen Sie mit dem Hinzufügen der erforderlichen Importe:
from brightdata import bdclient
von openai importieren OpenAI
von sendgrid import SendGridAPIClientInitialisieren Sie dann die SDK-Clients:
brightdata_client = bdclient()
openai_client = OpenAI()
sendgrid_client = SendGridAPIClient()Die drei obigen Zeilen initialisieren die folgenden:
- Bright Data Python SDK
- OpenAI-Python-SDK
- SendGrid-Python-SDK
Beachten Sie, dass Sie die API-Schlüssel-Umgebungsvariablen nicht manuell in Ihren Code laden und an die Konstruktoren übergeben müssen. Das liegt daran, dass das OpenAI SDK, Bright Data SDK und SendGrid SDK automatisch nach OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN und SENDGRID_API_KEY in Ihrer Umgebung suchen. Mit anderen Worten: Sobald diese Umgebungsvariablen in .env gesetzt sind, übernehmen die SDKs das Laden für Sie.
Insbesondere verwenden die SDKs die konfigurierten API-Schlüssel, um die zugrundeliegenden API-Aufrufe an ihre Server mit Ihrem Konto zu authentifizieren.
Wichtig! Weitere Einzelheiten zur Funktionsweise des Bright Data-SDK und zur Verbindung mit den erforderlichen Zonen in Ihrem Bright Data-Konto finden Sie auf der offiziellen GitHub-Seite oder in der Dokumentation.
Perfekt! Die Bausteine für die Erstellung Ihres KI-Workflows zur Überwachung der Markenreputation sind nun fertig.
Schritt Nr. 4: Abrufen der Google News-URLs
Der erste Schritt in der Workflow-Logik besteht darin, die SERPs für die markenbezogenen Suchanfragen, die Sie überwachen möchten, abzurufen. Dies geschieht über die search() -Methode des Bright Data SDK, die im Hintergrund die SERP-API aufruft.
Analysieren Sie dann die JSON-Textantwort, die Sie von search() erhalten, um auf die URLs der Google News-Seiten zuzugreifen, die wie folgt aussehen:
https://www.google.com/search?sca_esv=7fb9df9863b39f3b&hl=en&q=nike&tbm=nws&source=lnms&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RrRWAIniWd7tzPwkE1KJWcRvaH01D-XIVr2cowAnfeRRP_dme4bG4a8V_AkFVl-SqROia4syDA2-hwysjgAT-v0BCNgzLBnrhEWcFR7F5dffabwXi9c9pDyztBxQc1yfKVagSlUz7tFb_e8cyIqHDK7O6ZomxoJkHRwfaIn-HHOcZcyM2n-MrnKKBHZg&sa=X&ved=2ahUKEwiX1vu4_KePAxVWm2oFHT6tKsAQ0pQJegQIPhABErreichen Sie all das mit dieser Funktion:
def get_google_news_page_urls(search_queries):
# Abrufen von SERPs für die angegebenen Suchanfragen
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Um das SERP-Ergebnis als geparsten JSON-String zu erhalten
)
news_page_urls = []
for serp_result in serp_results:
# Laden des JSON-Strings in ein Wörterbuch
serp_data = json.loads(serp_result)
# Extrahieren der Google News URL aus jeder geparsten SERP
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urlsWenn Sie ein Array von Abfragen an search() übergeben (wie in diesem Fall), gibt die Methode ein Array von SERPs zurück, jeweils eines für jede Abfrage. Da parse auf True gesetzt ist, wird jedes Ergebnis als JSON-String zurückgegeben, den Sie dann mit dem in Python integrierten json-Modul parsen müssen.
Denken Sie daran, json aus der Python-Standardbibliothek zu importieren:
import jsonGroßartig! Jetzt können Sie programmatisch eine Liste der URLs von Google News-Seiten abrufen, die mit Ihrer Marke in Verbindung stehen.
Schritt #5: Scrapen Sie die Google News-Seiten und holen Sie die besten News-URLs
Denken Sie daran, dass eine einzige Google News-Seite mehrere Nachrichtenartikel enthält:
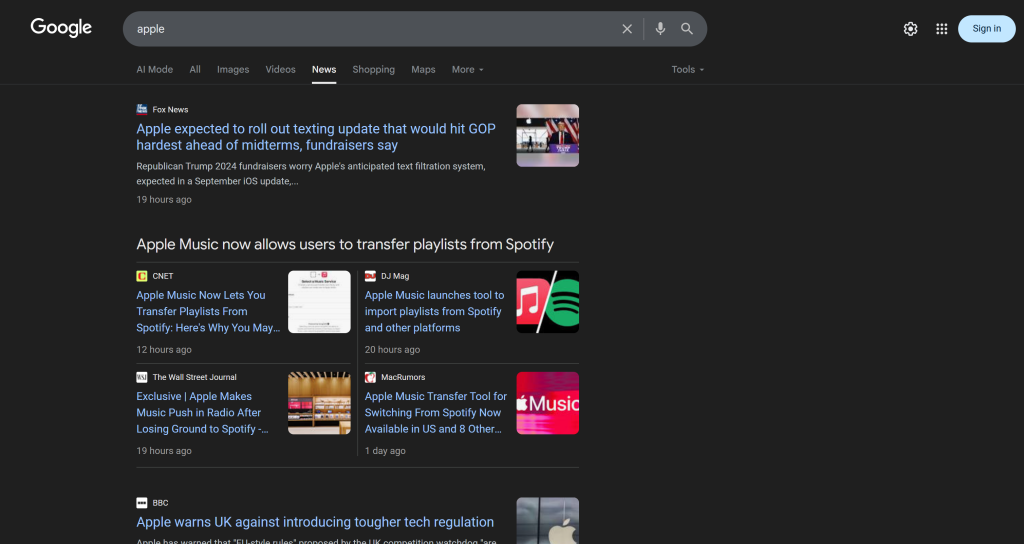
Die Idee ist also die folgende:
- Scrapen Sie den Inhalt von Google News-Seiten und erhalten Sie die Ergebnisse im Markdown-Format.
- Füttern Sie eine KI (in diesem Fall ein OpenAI-Modell) mit den Markdown-Inhalten und bitten Sie sie, die 5 wichtigsten Nachrichtenartikel für die Überwachung der Markenreputation auszuwählen.
Erreichen Sie den ersten Mikroschritt mit dieser Funktion:
def scrape_news_pages(news_page_urls):
# Scrape jede Nachrichtenseite parallel und liefere ihren Inhalt in Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
) Unter der Haube ruft die scrape() -Methode des Bright Data SDK die Web Unlocker-API auf. Wenn Sie ein Array von URLs übergeben, führt scrape() die Scraping-Aufgabe parallel aus und holt alle Seiten gleichzeitig ab. In diesem Fall ist die API so konfiguriert, dass sie Daten in Markdown zurückgibt, was ideal für die LLM-Ingestion ist (wie in unserem Datenformat-Benchmark auf Kaggle bewiesen).
Vervollständigen Sie dann den zweiten Mikroschritt mit:
def get_best_news_urls(news_pages, num_news):
# GPT verwenden, um die relevantesten Nachrichten-URLs zu extrahieren
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system",
"content": f "Extrahiert die {num_news} relevantesten Nachrichten für die Überwachung des Markenrufs aus dem Text und gibt sie als Liste von URL-Strings zurück."
},
{
"role": "Benutzer",
"content": "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urlsDiese Funktion verknüpft einfach die Markdown-Textausgaben aus der vorherigen Funktion und übergibt sie an das GPT-5-mini OpenAI-Modell mit der Bitte, die wichtigsten URLs zu extrahieren.
Es wird erwartet, dass die Ausgabe dem URLList-Modell folgt, das als Pydantic-Modell definiert ist:
class URLList(BaseModel):
urls: List[str]Dank der Optiontext_format in der parse() -Methode weisen Sie die OpenAI-API an, das Ergebnis als eine Instanz von URLList zurückzugeben. Im Grunde erhalten Sie eine Liste von Strings, wobei jeder String eine URL darstellt.
Importieren Sie die erforderlichen Klassen aus pydantic:
from pydantic import BaseModel
from typing import ListGroßartig! Sie haben nun eine strukturierte Liste von Nachrichten-URLs, die Sie auslesen und auf Markenreputation analysieren können.
Schritt #6: News-Seiten scrapen und für die Überwachung des Markenrufs analysieren
Nun, da Sie eine Liste der besten Nachrichten-URLs haben, verwenden Sie scrape(), um deren Inhalt in Markdown zu erhalten:
def scrape_news_articles(news_urls):
# Scrape jede News-URL und gib eine Liste von Dicts mit URL und Inhalt zurück
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
news_list = []
for url, content in zip(news_urls, news_content_list):
news_list.append({
"url": url,
"inhalt": inhalt
})
return news_listUnabhängig davon, auf welcher Domain diese News-Artikel gehostet werden oder welche Anti-Scraping-Maßnahmen vorhanden sind, kümmert sich die Web Unlocker API darum und gibt den Inhalt jedes Artikels in Markdown zurück. Im Einzelnen werden die Nachrichtenartikel parallel abgefragt. Um die Übersicht zu behalten, welche News-URL welcher Markdown-Ausgabe entspricht, verwenden Sie zip().
Als nächstes füttern Sie jeden Markdown-Nachrichteninhalt mit OpenAI, um ihn auf Markenreputation zu analysieren. Extrahieren Sie für jeden Artikel:
- den Titel
- die URL
- Eine kurze Zusammenfassung
- Ein kurzes Stimmungslabel (z. B. “positiv”, “negativ” oder “neutral”)
- 3-5 umsetzbare, kurze, leicht verständliche Erkenntnisse
Erreichen Sie dies mit der folgenden Funktion:
def process_news_list(news_list):
# Wo werden die analysierten Nachrichtenartikel gespeichert?
news_analysis_list = []
# Analysieren Sie jeden Nachrichtenartikel mit GPT, um Erkenntnisse über die Markenreputation zu erhalten
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system",
"content": f"""
Angesichts des Nachrichteninhalts:
1. Extrahiere den Titel.
2. Extrahiere die URL.
3. Schreiben Sie eine Zusammenfassung in höchstens 30 Wörtern.
4. Extrahieren Sie die Stimmung der Nachricht als eine der folgenden: "positiv", "negativ", oder "neutral".
5. Extrahieren Sie die 3 bis 5 wichtigsten Erkenntnisse (nicht mehr als 10/12 Wörter) über die Markenreputation aus den Nachrichten und präsentieren Sie diese in einer klaren, prägnanten und unkomplizierten Sprache.
"""
},
{
"role": "Benutzer",
"content": f "NEWS URL: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NeuigkeitenAnalysen,
)
# Das analysierte Nachrichtenobjekt abrufen und an die Liste anhängen
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_listDiesmal ist das Pydantic-Modell in text_format eingestellt:
class NewsAnalysis(BaseModel):
title: str
url: str
Zusammenfassung: str
Stimmung_Analyse: str
insights: List[str]Das Ergebnis der Funktion process_news_list() wird also eine Liste von NewsAnalysis-Objekten sein.
Super! Die KI-gestützte Verarbeitung von Nachrichten für die Überwachung der Markenreputation ist abgeschlossen.
Schritt #7: Erzeugen Sie den E-Mail-Bericht und versenden Sie ihn
Haben Sie sich jemals gefragt, wie E-Mails strukturiert sind und im Posteingang Ihres Kunden erscheinen? Das liegt daran, dass die meisten E-Mail-Teile eigentlich nur strukturierte HTML-Seiten sind. Schließlich unterstützt das E-Mail-Protokoll den Versand von HTML-Dokumenten.
Konvertieren Sie die zuvor erstellte Objektliste der Nachrichtenanalyse in JSON, übergeben Sie sie an AI und bitten Sie es, ein HTML-Dokument zu erstellen, das per E-Mail versendet werden kann:
def create_html_email_body(news_analysis_list):
# Erzeugt einen strukturierten HTML-E-Mail-Text aus den analysierten Nachrichten
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
Generieren Sie aus dem unten stehenden Inhalt eine strukturierte HTML-E-Mail, die gut formatiert, ansprechend und versandfertig ist.
Achten Sie auf die korrekte Verwendung von Überschriften, Absätzen, farbigen Beschriftungen und Links, wo dies angebracht ist.
Fügen Sie keine Kopf- oder Fußzeilen ein und geben Sie nur diese Informationen an - sonst nichts.
INHALT:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_textSchließlich verwenden Sie das Twilio SendGrid SDK, um die E-Mail programmatisch zu versenden:
def send_email(sender, recipients, html_body):
# Senden Sie die HTML-E-Mail mit SendGrid
message = Mail(
from_email=Absender,
to_emails=recipients,
subject="Brand Monitoring Weekly Report",
html_content=html_body
)
sendgrid_client.send(Nachricht)Dazu ist der folgende Import erforderlich:
from sendgrid.helpers.mail import MailJetzt geht’s los! Alle Funktionen zur Implementierung dieses KI-Workflows zur Überwachung der Markenreputation sind nun implementiert.
Schritt Nr. 8: Laden Sie Ihre Einstellungen und Konfigurationen
Einige der in den vorherigen Schritten definierten Funktionen akzeptieren bestimmte Argumente (z. B. search_queries, num_news, sender, recipients). Diese Werte können sich von Lauf zu Lauf ändern, daher sollten Sie sie nicht in Ihrem Python-Skript fest einprogrammieren.
Lesen Sie sie stattdessen aus einer config.json-Datei, die die folgenden Felder enthält:
search_queries: Die Liste der Abfragen zur Markenreputation, für die Nachrichten abgerufen werden sollen.num_news: Die Anzahl der Nachrichtenartikel, die in den endgültigen Bericht aufgenommen werden sollen.Absender: Eine von SendGrid zugelassene E-Mail-Adresse, von der aus der Bericht versendet werden soll.empfänger: Die Liste der E-Mail-Adressen, an die der HTML-Bericht gesendet werden soll.
Modellieren Sie das Konfigurationsobjekt mit Hilfe der folgenden Pydantic-Klasse:
class Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Feld(..., gt=0)
Absender: str = Feld(..., min_length=1)
recipients: List[str] = Feld(..., min_items=1)Die Felddefinitionen geben Validierungsregeln an, um sicherzustellen, dass die Konfigurationen dem erwarteten Format entsprechen. Importieren Sie sie mit:
from pydantic import FeldAls Nächstes lesen Sie die Workflow-Konfigurationen aus einer lokalen config.json-Datei und analysieren sie in ein Config-Objekt:
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config) Fügen Sie eine config.json-Datei in das Verzeichnis Ihres Projekts ein:
brand-reputation-monitoring-workflow/
├── .venv/
├── .env
├─── config.json # <-----------
└─── workflow.pyUnd füllen Sie es mit etwas wie diesem:
{
"search_queries": ["apple", "iphone", "ipad"],
"absender": "[email protected]",
"empfänger": ["[email protected]", "[email protected]", "[email protected]"],
"num_news": 5
}Passen Sie die Werte an Ihre spezifischen Ziele an. Denken Sie auch daran, dass das Absenderfeld eine E-Mail-Adresse sein muss, die in Ihrem SendGrid-Konto verifiziert ist. Andernfalls wird die Funktion send_email() mit einem 403 Forbidden-Fehler fehlschlagen.
Sehr gut gemacht! Ein weiterer Schritt und der Workflow ist fertig.
Schritt #9: Definieren Sie die Hauptfunktion
Zeit, alles zusammenzustellen. Rufen Sie jede vordefinierte Funktion in der richtigen Reihenfolge auf und geben Sie die richtigen Eingaben aus der Konfiguration ein:
search_queries = config.search_queries
print(f "Abrufen von Google News Seiten-URLs für die folgenden Suchanfragen: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} Google News Seiten URL(s) abgerufen!n")
print("Scraping-Inhalte von jeder Google News-Seite...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Google News-Seiten ausgewertet!n")
print("Extrahieren der relevantesten Nachrichten-URLs...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} newsartikel gefunden:n" + "n".join(f"- {news}" for news in news_urls) + "n")
print("Scraping der ausgewählten Nachrichtenartikel...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} newsartikel gecrappt!")
print("Analyse der einzelnen Nachrichten zur Überwachung des Markenrufs...")
news_analysis_list = process_news_list(news_list)
print("Nachrichtenanalyse abgeschlossen!n")
print("HTML-E-Mail-Text generieren...")
html = create_html_email_body(nachrichten_analyse_liste)
print("HTML-E-Mail-Text erzeugt!n")
print("Versenden der E-Mail mit dem HTML-Bericht zur Überwachung des Markenrufs...")
send_email(config.sender, config.recipients, html)
print("E-Mail gesendet!")Hinweis: Es kann eine Weile dauern, bis der Arbeitsablauf abgeschlossen ist, daher ist es hilfreich, Protokolle hinzuzufügen, um den Fortschritt im Terminal zu verfolgen. Auftrag erfüllt!
Schritt #10: Alles zusammenfügen
Der endgültige Code der Datei workflow.py lautet:
from dotenv import load_dotenv
from brightdata import bdclient
von openai importieren OpenAI
from sendgrid import SendGridAPIClient
from pydantic import BaseModel, Feld
von typing import List
importieren json
aus sendgrid.helpers.mail importieren Mail
# Laden von Umgebungsvariablen aus der .env-Datei
load_dotenv()
# Initialisieren des Bright Data SDK-Clients
brightdata_client = bdclient()
# Initialisierung des OpenAI-SDK-Clients
openai_client = OpenAI()
# Initialisieren des SendGrid-SDK-Clients
sendgrid_client = SendGridAPIClient()
# Pydantische Modelle
class Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Feld(..., gt=0)
Absender: str = Feld(..., min_length=1)
recipients: List[str] = Feld(..., min_items=1)
class URLList(BaseModel):
urls: List[str]
class NewsAnalysis(BaseModel):
title: str
url: str
Zusammenfassung: str
stimmung_analyse: str
insights: Liste[str]
def get_google_news_page_urls(search_queries):
# Abrufen von SERPs für die angegebenen Suchanfragen
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Um das SERP-Ergebnis als geparsten JSON-String zu erhalten
)
news_page_urls = []
for serp_result in serp_results:
# Laden des JSON-Strings in ein Wörterbuch
serp_data = json.loads(serp_result)
# Extrahieren der Google News URL aus jeder geparsten SERP
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urls
def scrape_news_pages(news_page_urls):
# Scrape jede Newsseite parallel und liefere ihren Inhalt in Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
)
def get_best_news_urls(news_pages, num_news):
# GPT verwenden, um die relevantesten News-URLs zu extrahieren
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system",
"content": f "Extrahiert die {num_news} relevantesten Nachrichten für die Überwachung der Markenreputation aus dem Text und gibt sie als Liste von URL-Strings zurück."
},
{
"role": "Benutzer",
"content": "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urls
def scrape_news_articles(news_urls):
# Scrape jede News-URL und gebe eine Liste von Dicts mit URL und Inhalt zurück
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
news_list = []
for url, content in zip(news_urls, news_content_list):
news_list.append({
"url": url,
"inhalt": inhalt
})
return news_list
def process_news_list(news_list):
# Wo werden die analysierten Nachrichtenartikel gespeichert?
news_analysis_list = []
# Analysieren Sie jeden Nachrichtenartikel mit GPT, um Erkenntnisse über die Markenreputation zu erhalten
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system",
"content": f"""
Angesichts des Nachrichteninhalts:
1. Extrahiere den Titel.
2. Extrahiere die URL.
3. Schreiben Sie eine Zusammenfassung in höchstens 30 Wörtern.
4. Extrahieren Sie die Stimmung der Nachricht als eine der folgenden: "positiv", "negativ", oder "neutral".
5. Extrahieren Sie die 3 bis 5 wichtigsten Erkenntnisse (nicht mehr als 10/12 Wörter) über die Markenreputation aus den Nachrichten und präsentieren Sie diese in einer klaren, prägnanten und unkomplizierten Sprache.
"""
},
{
"role": "Benutzer",
"content": f "NEWS URL: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NeuigkeitenAnalysen,
)
# Das analysierte Nachrichtenobjekt abrufen und an die Liste anhängen
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_list
def create_html_email_body(news_analysis_list):
# Erzeugt einen strukturierten HTML-E-Mail-Body aus den analysierten Nachrichten
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
Erzeugen Sie aus dem unten stehenden Inhalt eine strukturierte HTML-E-Mail, die gut formatiert, ansprechend und versandfertig ist.
Achten Sie auf die korrekte Verwendung von Überschriften, Absätzen, farbigen Beschriftungen und Links, wo dies angebracht ist.
Fügen Sie keine Kopf- oder Fußzeilen ein und geben Sie nur diese Informationen an - sonst nichts.
INHALT:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_text
def send_email(absender, empfänger, html_body):
# Senden der HTML-E-Mail mit SendGrid
message = Mail(
from_email=Absender,
to_emails=recipients,
subject="Brand Monitoring Weekly Report",
html_content=html_body
)
sendgrid_client.send(Nachricht)
def main():
# Einlesen der Konfigurationsdatei und Validierung
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config)
search_queries = config.search_queries
print(f "Abrufen der URLs von Google News-Seiten für die folgenden Suchanfragen: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} Google News Seiten URL(s) abgerufen!n")
print("Scraping-Inhalte von jeder Google News-Seite...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Google News-Seiten ausgewertet!n")
print("Extrahieren der relevantesten Nachrichten-URLs...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} newsartikel gefunden:n" + "n".join(f"- {news}" for news in news_urls) + "n")
print("Scraping der ausgewählten Nachrichtenartikel...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} newsartikel gecrappt!")
print("Analyse der einzelnen Nachrichten zur Überwachung des Markenrufs...")
news_analysis_list = process_news_list(news_list)
print("Nachrichtenanalyse abgeschlossen!n")
print("HTML-E-Mail-Text generieren...")
html = create_html_email_body(nachrichten_analyse_liste)
print("HTML-E-Mail-Text erzeugt!n")
print("Versenden der E-Mail mit dem HTML-Bericht zur Überwachung des Markenrufs...")
send_email(config.sender, config.recipients, html)
print("E-Mail gesendet!")
# Führen Sie die Hauptfunktion aus
if __name__ == "__main__":
main()Et voilà! Dank des Bright Data SDK, der OpenAI API und des Twilio SendGrid SDK konnten Sie einen KI-gestützten Workflow zur Überwachung der Markenreputation in weniger als 200 Zeilen Code erstellen.
Schritt Nr. 11: Testen Sie den Workflow
Nehmen wir an, Ihre search_queries sind "nike" und "nike shoes". num_news ist auf 5 eingestellt, und der Bericht ist so konfiguriert, dass er an Ihre persönliche E-Mail gesendet wird (beachten Sie, dass Sie dieselbe E-Mail-Adresse sowohl für den Absender als auch für das erste Element der Empfänger verwenden können ).
Starten Sie in Ihrer aktivierten virtuellen Umgebung Ihren Workflow mit:
python workflow.pyDas Ergebnis im Terminal wird in etwa so aussehen:
Abrufen von Google News Seiten-URLs für die folgenden Suchanfragen: nike, nike shoes
2 Google News Seiten-URL(s) abgerufen!
Scraping des Inhalts von jeder Google News-Seite...
Google News-Seiten abgerufen!
Extrahieren der relevantesten News-URLs...
5 Nachrichtenartikel gefunden:
- https://www.espn.com/wnba/story/_/id/46075454/caitlin-clark-becomes-nike-newest-signature-athlete
- https://wwd.com/footwear-news/sneaker-news/nike-acg-radical-airflow-ultrafly-release-dates-1238068936/
- https://www.runnersworld.com/news/a65881486/cooper-lutkenhaus-professional-contract-nike/
- https://hypebeast.com/2025/8/nike-kobe-3-protro-low-reveal-info
- https://wwd.com/footwear-news/sneaker-news/nike-air-diamond-turf-must-be-the-money-release-date-1238075256/
Scraping der ausgewählten Nachrichtenartikel...
5 Nachrichtenartikel gecrappt!
Analyse jedes Nachrichtenartikels zur Überwachung der Markenreputation...
Nachrichtenanalyse abgeschlossen!
HTML-E-Mail-Text generieren...
HTML-E-Mail-Text generiert!
Versenden der E-Mail mit dem HTML-Bericht zur Überwachung der Markenreputation...
E-Mail versendet!Hinweis: Die Ergebnisse werden sich je nach den verfügbaren Nachrichten ändern. Sie werden also nie dieselben sein wie die oben genannten, wenn Sie diese Anleitung lesen.
Nach der Meldung “E-Mail gesendet!” sollten Sie eine E-Mail mit dem Titel “Brand Monitoring Weekly Report” in Ihrem Posteingang finden:

Wenn Sie sie öffnen, wird sie etwa Folgendes enthalten:
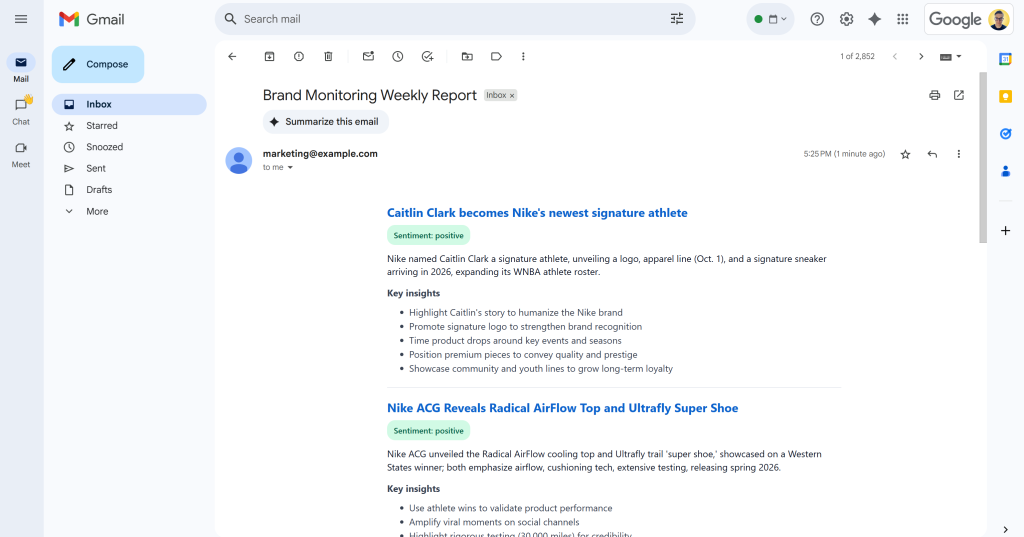
Wie Sie sehen können, war die KI in der Lage, einen visuell ansprechenden Markenüberwachungsbericht mit allen angeforderten Daten zu erstellen.
Scrollen Sie durch den Bericht, und Sie werden sehen:
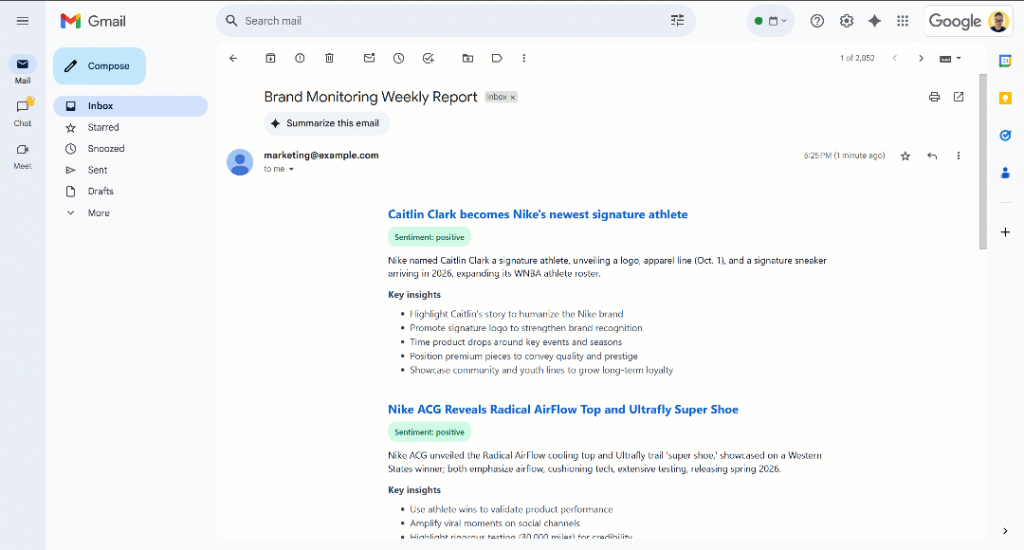
Beachten Sie, dass die Stimmungsbezeichnungen farblich kodiert sind, damit Sie die Stimmung schnell erkennen können. Außerdem sind die Titel der Nachrichten in blau gehalten, da es sich um Links zu den Originalartikeln handelt.
Et voilà! Sie haben mit ein paar Suchanfragen begonnen und am Ende eine E-Mail mit einem gut strukturierten Bericht zur Markenüberwachung erhalten.
Das alles war möglich dank der leistungsstarken Lösungen für das Scraping von Webdaten, die im Bright Data SDK verfügbar sind. Denken Sie daran, dass die gescrapten Seiten in LLM-optimierten Markdown-Formaten zurückgegeben werden, sodass jedes KI-Modell sie für Ihre Bedürfnisse analysieren kann. Erkunden Sie weitere unterstützte Anwendungsfälle für Agenten und KI-Workflows!
Nächste Schritte
Der aktuelle KI-Workflow zur Überwachung der Markenreputation ist bereits recht ausgeklügelt, aber Sie könnten ihn mit diesen Ideen noch weiter verbessern:
- Fügen Sie eine Speicherebene für bereits berichtete Nachrichten hinzu: Um zu vermeiden, dass dieselben Artikel mehrmals analysiert werden, um die Genauigkeit der Berichte zu verbessern und gleichzeitig Doppelarbeit zu vermeiden.
- Einführung von SendGrid-Vorlagen zur Standardisierung: Die KI kann bei jedem Durchlauf leicht unterschiedliche HTML-Berichte mit unterschiedlichen Strukturen erzeugen. Um das Layout einheitlich zu gestalten, können Sie eine SendGrid-Vorlage definieren, sie mit den generierten Nachrichtenanalysedaten füllen und sie über das SendGrid SDK versenden. Weitere Informationen finden Sie in den offiziellen Dokumenten.
- Speichern Sie den generierten HTML-Bericht in der Cloud: Speichern Sie den Bericht in S3, um sicherzustellen, dass er archiviert wird und für historische Analysen zur Markenüberwachung zur Verfügung steht.
Fazit
In diesem Artikel haben Sie erfahren, wie Sie die Websuch- und Scraping-Funktionen von Bright Data nutzen können, um einen KI-gestützten Workflow für die Markenreputation zu erstellen. Dieser Prozess wurde dank des neuen Bright Data SDK, das den Zugriff auf Bright Data-Produkte mit einfachen Methodenaufrufen ermöglicht, noch einfacher.
Der hier vorgestellte KI-Workflow ist ideal für Marketingteams, die ihre Marke überwachen und kostengünstig verwertbare Erkenntnisse gewinnen möchten. Er hilft dabei, Zeit und Aufwand zu sparen, indem er kontextbezogene Anweisungen liefert, die den Markenschutz und die Entscheidungsfindung unterstützen.
Um fortgeschrittenere Workflows zu erstellen, können Sie die gesamte Palette der Lösungen in der KI-Infrastruktur von Bright Data zum Abrufen, Validieren und Umwandeln von Live-Webdaten erkunden.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren KI-fähigen Webdatenlösungen!





