

Python ist eine der beliebtesten Sprachen, wenn es um Web-Scraping geht. Was ist die größte Informationsquelle im Internet? Google! Deshalb ist das Scraping von Google mit Python so beliebt. Die Idee besteht darin, SERP-Daten automatisch abzurufen und sie für Marketing, Wettbewerbsbeobachtung und mehr zu verwenden.
Folgen Sie dieser Anleitung und lernen Sie, wie Sie mit Selenium Google-Scraping in Python durchführen. Legen wir los!
Welche Daten sollten von Google gescrapt werden?
Google ist eine der größten Quellen für öffentliche Daten im Internet. Es gibt unzählige interessante Informationen, die Sie daraus abrufen können, von Google Maps-Bewertungen bis hin zu Antworten auf „People also ask“ (Andere Nutzer fragen auch):
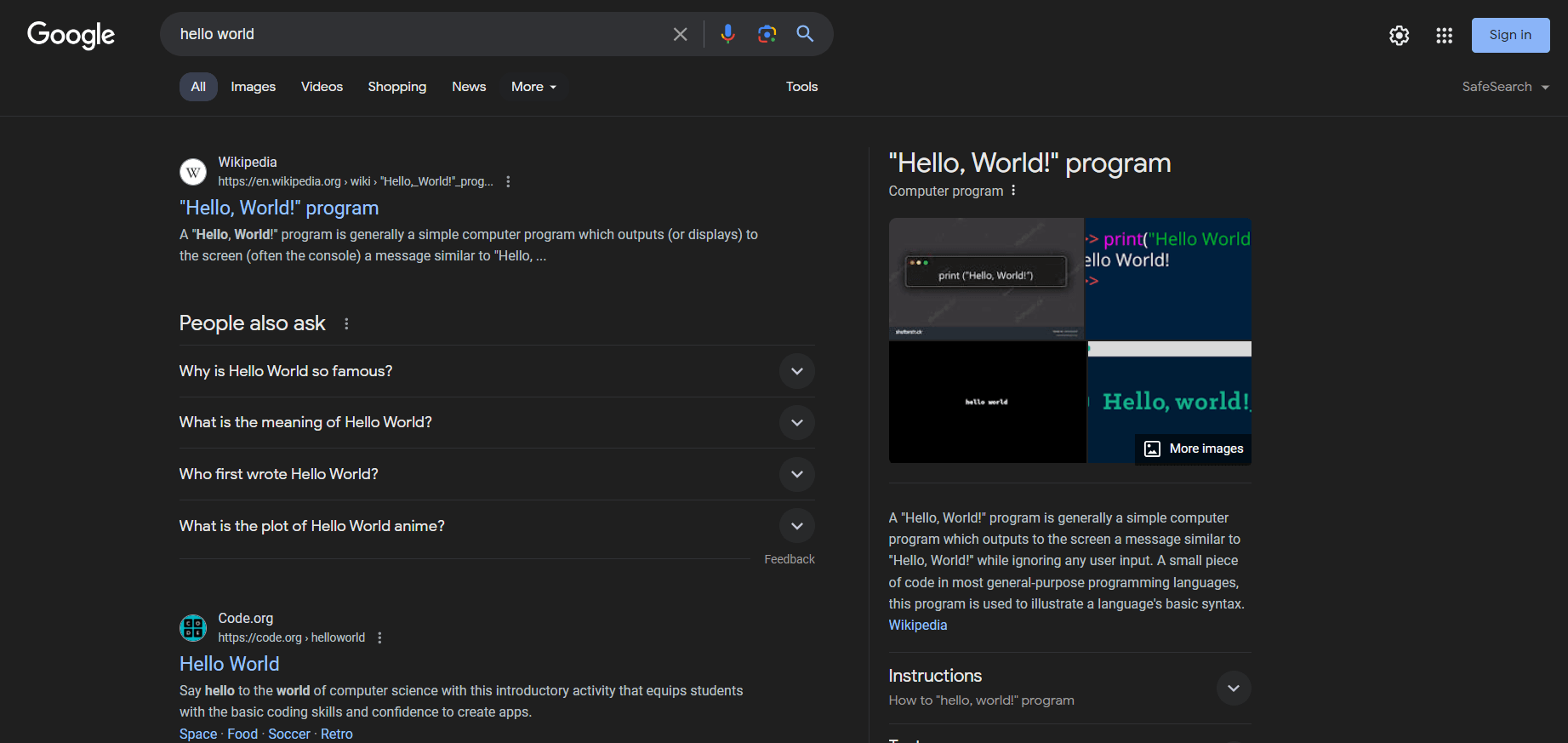
Was Nutzer und Unternehmen jedoch in der Regel interessiert, sind SERP-Daten. SERP ist die Abkürzung für„Search Engine Results Page“ ( Suchmaschinen-Ergebnisseite) und bezeichnet die Seite, die Suchmaschinen wie Google als Antwort auf eine Nutzeranfrage zurückgeben. In der Regel enthält sie eine Liste von Karten mit Links und Textbeschreibungen zu Webseiten, die von der Suchmaschine vorgeschlagen werden.
So sieht eine SERP-Seite aus:
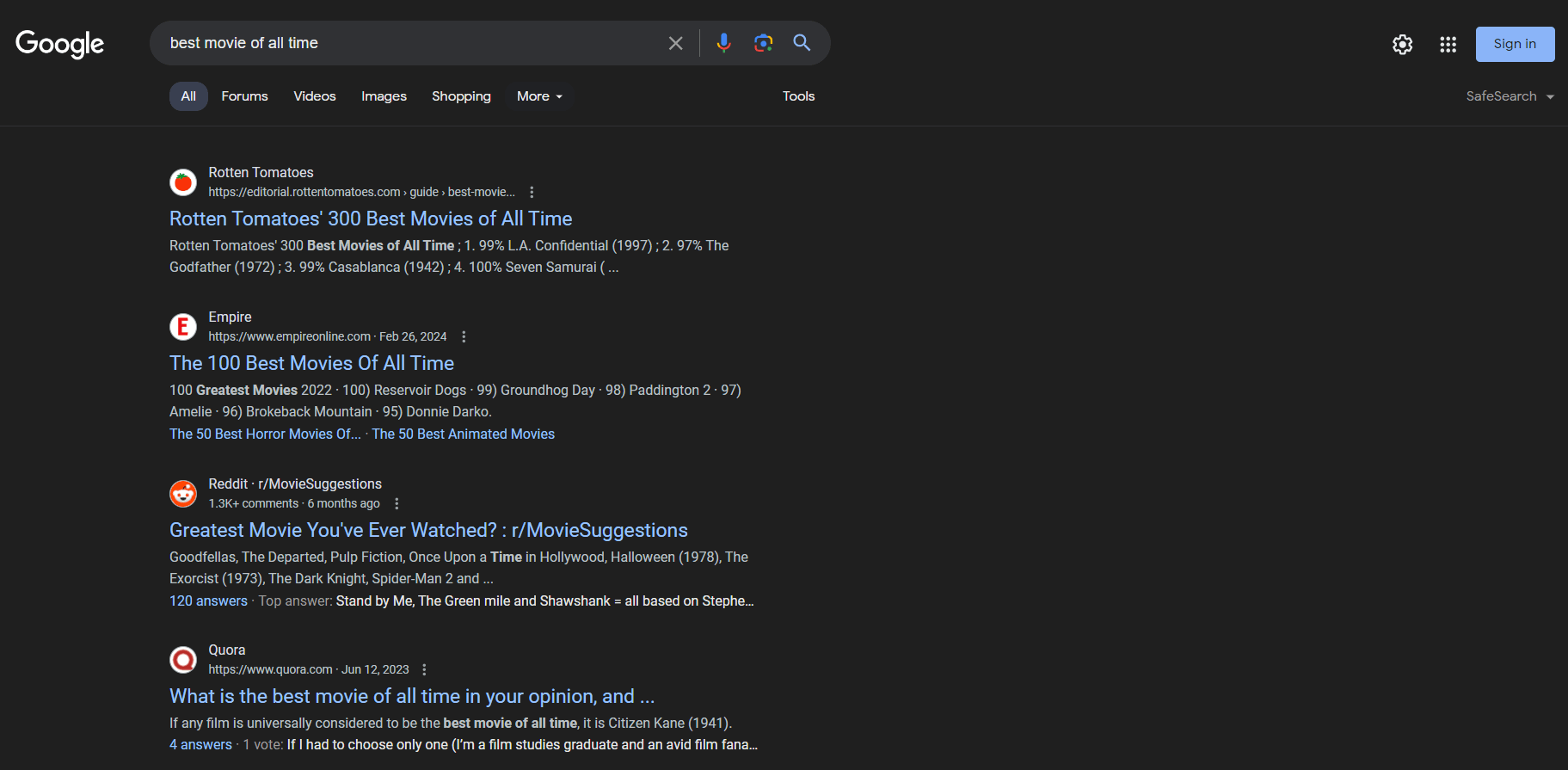
SERP-Daten sind für Unternehmen von entscheidender Bedeutung, um ihre Online-Sichtbarkeit zu verstehen und die Konkurrenz zu analysieren. Sie liefern Einblicke in Nutzerpräferenzen, Keyword-Performance und Strategien der Wettbewerber. Durch die Analyse von SERP-Daten können Unternehmen ihre Inhalte optimieren, ihre SEO-Rankings verbessern und ihre Marketingstrategien besser auf die Bedürfnisse der Nutzer abstimmen.
Jetzt wissen Sie also, dass SERP-Daten zweifellos sehr wertvoll sind. Jetzt müssen Sie nur noch herausfinden, wie Sie das richtige Tool zum Abrufen dieser Daten auswählen. Python ist eine der besten Programmiersprachen für Web-Scraping und eignet sich perfekt für diesen Zweck. Bevor wir uns jedoch mit dem manuellen Scraping befassen, wollen wir uns die beste und schnellste Option für das Scraping von Google-Suchergebnissen ansehen: die SERP-API von Bright Data.
Vorstellung der SERP-API von Bright Data
Bevor Sie sich mit der Anleitung zum manuellen Scraping befassen, sollten Sie die SERP-API von Bright Data für eine effiziente und nahtlose Datenerfassung in Betracht ziehen. Die SERP-API bietet Echtzeit-Zugriff auf Suchmaschinenergebnisse aller großen Suchmaschinen, darunter Google, Bing, DuckDuckGo, Yandex, Baidu, Yahoo und Naver. Dieses leistungsstarke Tool basiert auf den branchenführenden Proxy-Diensten und fortschrittlichen Anti-Bot-Lösungen von Bright Data und gewährleistet eine zuverlässige und genaue Datenabfrage ohne die üblichen Herausforderungen, die mit Web-Scraping verbunden sind.
Warum sollten Sie die SERP-API von Bright Data dem manuellen Scraping vorziehen?
- Echtzeit-Ergebnisse und hohe Genauigkeit: Die SERP-API liefert Suchmaschinenergebnisse in Echtzeit und gewährleistet so, dass Sie genaue und aktuelle Daten erhalten. Mit einer Standortgenauigkeit bis auf Stadtebene sehen Sie genau das, was ein echter Nutzer überall auf der Welt sehen würde.
- Fortschrittliche Anti-Bot-Lösungen: Vergessen Sie Blockierungen oder CAPTCHA-Herausforderungen. Die SERP-API umfasst automatisierte CAPTCHA-Lösung, Browser-Fingerprinting und vollständige Proxy-Verwaltung, um eine reibungslose und unterbrechungsfreie Datenerfassung zu gewährleisten.
- Anpassbar und skalierbar: Die API unterstützt eine Vielzahl von maßgeschneiderten Suchparametern, sodass Sie Ihre Abfragen an Ihre spezifischen Bedürfnisse anpassen können. Sie ist auf Volumen ausgelegt und bewältigt wachsenden Traffic und Spitzenzeiten mit Leichtigkeit.
- Einfache Bedienung: Mit einfachen API-Aufrufen können Sie strukturierte SERP-Daten im JSON- oder HTML-Format abrufen, wodurch die Integration in Ihre bestehenden Systeme und Arbeitsabläufe vereinfacht wird. Die Antwortzeit ist außergewöhnlich kurz und liegt in der Regel unter 5 Sekunden.
- Kostengünstig: Sparen Sie Betriebskosten durch die Verwendung der SERP-API. Sie zahlen nur für erfolgreiche Anfragen und müssen nicht in die Wartung der Scraping-Infrastruktur oder die Behebung von Serverproblemen investieren.
Starten Sie noch heute und testen Sie die kostenlose Testversion und erleben Sie die Effizienz und Zuverlässigkeit der SERP-API von Bright Data!
Erstellen Sie einen Google SERP-Scraper in Python
Folgen Sie dieser Schritt-für-Schritt-Anleitung und erfahren Sie, wie Sie ein Google SERP-Scraping-Skript in Python erstellen.
Schritt 1: Projekt einrichten
Um dieser Anleitung zu folgen, muss Python 3 auf Ihrem Rechner installiert sein. Wenn Sie es installieren müssen, laden Sie das Installationsprogramm herunter, starten Sie es und folgen Sie den Anweisungen des Assistenten.
Jetzt haben Sie alles, was Sie zum Scrapen von Google in Python benötigen!
Verwenden Sie die folgenden Befehle, um ein Python-Projekt mit einer virtuellen Umgebung zu erstellen:
mkdir google-scraper
cd google-scraper
python -m venv envgoogle-scraper wird das Stammverzeichnis Ihres Projekts sein.
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE. PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung sind beide hervorragende Optionen.
Aktivieren Sie unter Linux oder macOS die virtuelle Umgebung mit dem folgenden Befehl:
./env/bin/activateUnter Windows führen Sie stattdessen Folgendes aus:
env/Scripts/activateBeachten Sie, dass einige IDEs die virtuelle Umgebung automatisch erkennen, sodass Sie sie nicht manuell aktivieren müssen.
Fügen Sie eine Datei namens scraper.py in den Ordner Ihres Projekts ein und initialisieren Sie sie wie folgt:
print("Hello, World!")Dies ist nur ein einfaches Skript, das die Meldung „Hello, World!” ausgibt, aber es wird bald die Google-Scraping-Logik enthalten.
Überprüfen Sie, ob Ihr Skript wie gewünscht funktioniert, indem Sie es über die Schaltfläche „Ausführen” in Ihrer IDE oder mit diesem Befehl starten:
python Scraper.pyDas Skript sollte Folgendes ausgeben:
Hallo, Welt!Gut gemacht! Sie verfügen nun über eine Python-Umgebung für das SERP-Scraping.
Bevor Sie mit Python Google scrapen, sollten Sie sich unseren Leitfaden zum Web-Scraping mit Python ansehen.
Schritt 2: Installieren Sie die Scraping-Bibliotheken
Es ist an der Zeit, die geeignete Python-Scraping-Bibliothek für das Scraping von Daten aus Google zu installieren. Es gibt mehrere Optionen, und um die beste Vorgehensweise zu wählen, muss die Zielwebsite analysiert werden. Gleichzeitig sprechen wir hier von Google, und wir alle wissen, wie Google funktioniert.
Es ist komplex, eine Google-Such-URL zu erstellen, die nicht die Aufmerksamkeit der Anti-Bot-Technologien auf sich zieht. Wir alle wissen, dass Google eine Benutzerinteraktion erfordert. Deshalb ist der einfachste und effektivste Weg, mit der Suchmaschine zu interagieren, ein Browser, der das Verhalten eines echten Benutzers simuliert.
Mit anderen Worten: Sie benötigen ein Headless-Browser-Tool, um Webseiten in einem steuerbaren Browser darzustellen. Selenium ist dafür perfekt geeignet!
Führen Sie in einer aktivierten virtuellen Python-Umgebung den folgenden Befehl aus, um das Selenium -Paket zu installieren:
pip install seleniumDer Einrichtungsprozess kann einige Zeit in Anspruch nehmen, haben Sie also bitte etwas Geduld.
Super! Sie haben gerade Selenium zu den Abhängigkeiten Ihres Projekts hinzugefügt.
Schritt 3: Selenium einrichten
Importieren Sie Selenium, indem Sie die folgenden Zeilen zu scraper.py hinzufügen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import OptionsInitialisieren Sie eine Chrome WebDriver -Instanz, um ein Chrome-Fenster im Headless-Modus wie folgt zu steuern:
# Optionen zum Starten von Chrome im Headless-Modus
options = Options()
options.add_argument('--headless') # während der lokalen Entwicklung auskommentieren
# Initialisieren Sie eine Webdriver-Instanz mit den
# angegebenen Optionen.
driver = webdriver.Chrome(
service=Service(),
options=options
)Hinweis: Das Flag --headless stellt sicher, dass Chrome ohne GUI gestartet wird. Wenn Sie die von Ihrem Skript auf der Google-Seite ausgeführten Vorgänge sehen möchten, kommentieren Sie diese Option aus. Deaktivieren Sie das Flag --headless im Allgemeinen während der lokalen Entwicklung, lassen Sie es jedoch in der Produktion aktiviert. Der Grund dafür ist, dass die Ausführung von Chrome mit der GUI viele Ressourcen beansprucht.
Vergessen Sie nicht, die Webtreiberinstanz als letzte Zeile Ihres Skripts zu schließen:
driver.quit()Ihre Datei scraper.py sollte nun Folgendes enthalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# Optionen zum Starten von Chrome im Headless-Modus
options = Options()
options.add_argument('--headless') # während der lokalen Entwicklung auskommentieren
# Initialisieren Sie eine Webtreiberinstanz mit den
# angegebenen Optionen
driver = webdriver.Chrome(
service=Service(),
options=options)
# Scraping-Logik...
# Schließen Sie den Browser und geben Sie seine Ressourcen frei
driver.quit()Großartig! Sie haben nun alles, was Sie zum Scrapen dynamischer Websites benötigen.
Schritt 4: Google besuchen
Der erste Schritt beim Scraping von Google mit Python besteht darin, eine Verbindung zur Zielwebsite herzustellen. Verwenden Sie die Funktion get() aus dem Treiberobjekt, um Chrome anzuweisen, die Google-Startseite aufzurufen:
driver.get("https://google.com/")So sollte Ihr Python-Skript zum Scraping von SERPs bisher aussehen:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# Optionen zum Starten von Chrome im Headless-Modus
options = Options()
options.add_argument('--headless') # während der lokalen Entwicklung auskommentieren
# Initialisieren Sie eine Webtreiberinstanz mit den
# angegebenen Optionen
driver = webdriver.Chrome(
service=Service(),
options=options)
# Verbinden Sie sich mit der Zielwebsite
driver.get("https://google.com/")
# Scraping-Logik...
# Schließen Sie den Browser und geben Sie seine Ressourcen frei
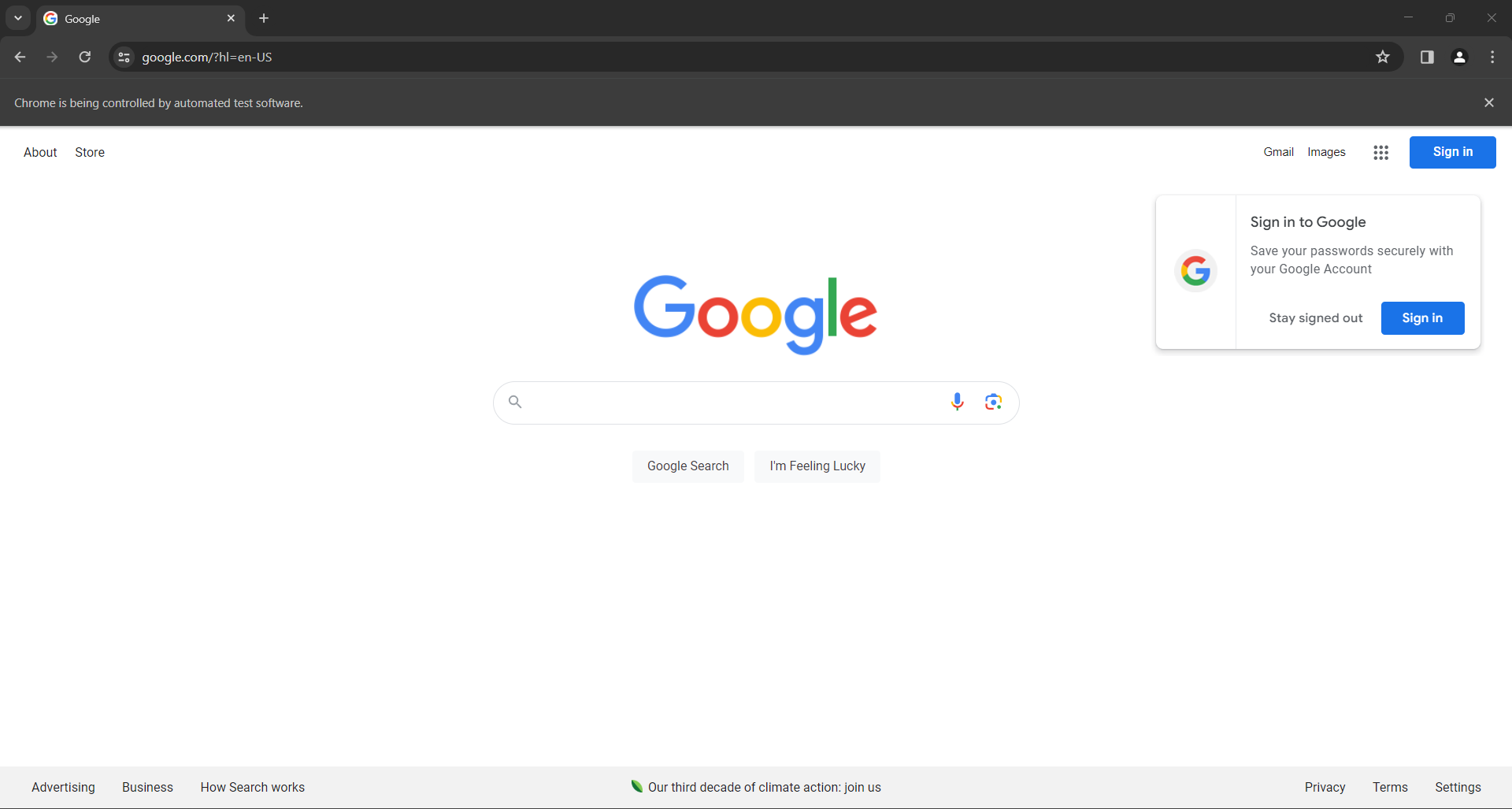
driver.quit()Starten Sie das Skript im Headless-Modus, und Sie sehen für den Bruchteil einer Sekunde das folgende Browserfenster, bevor die Anweisung quit() es beendet:
Wenn Sie ein Nutzer mit Sitz in der EU (Europäische Union) sind, enthält die Google-Startseite auch das folgende GDPR-Popup:
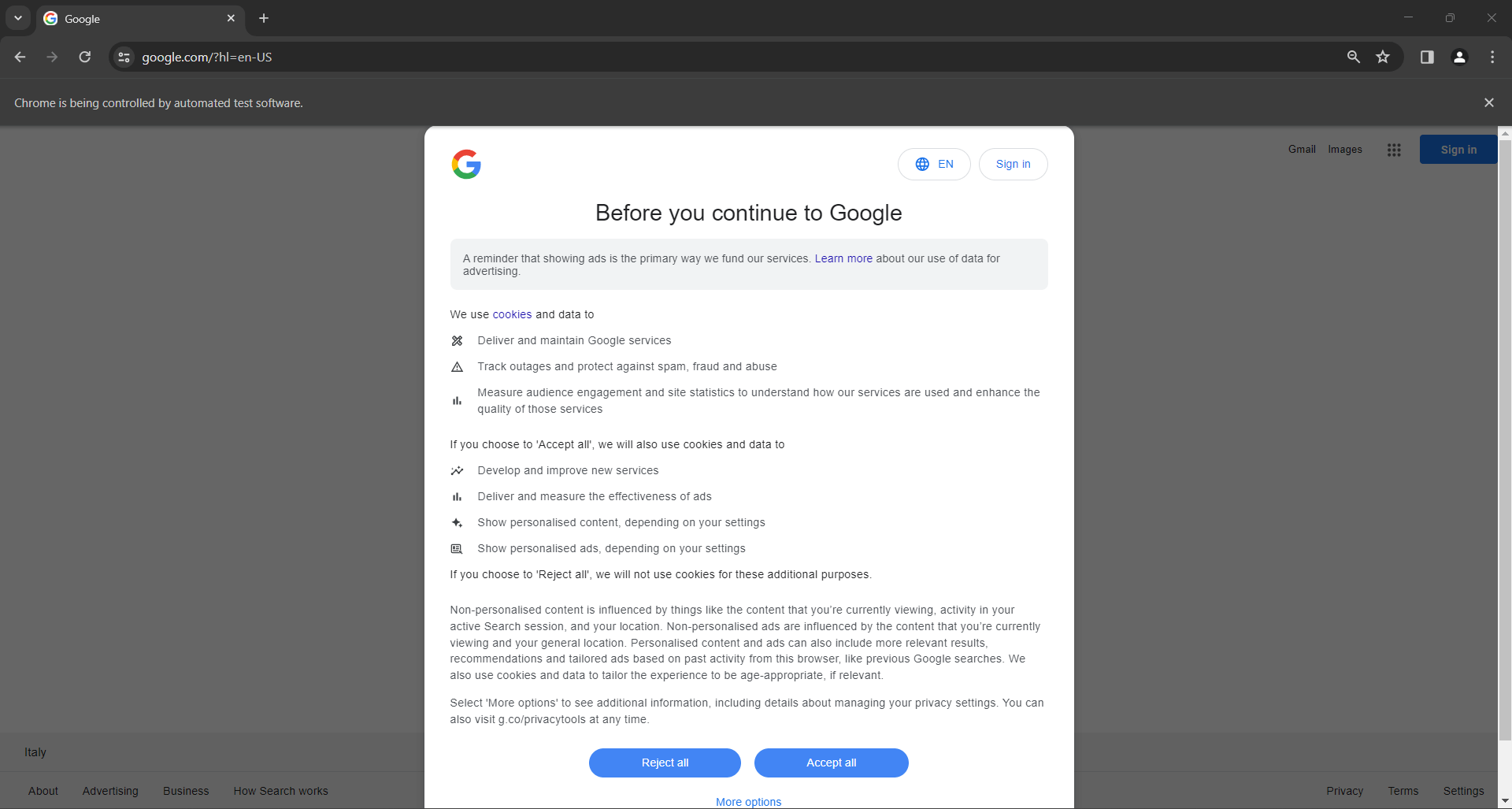
In beiden Fällen informiert Sie die Meldung „Chrome wird von einer automatisierten Testsoftware gesteuert“ darüber, dass Selenium Chrome wie gewünscht steuert.
Großartig! Selenium öffnet die Google-Seite wie gewünscht.
Hinweis: Wenn Google aus DSGVO-Gründen den Cookie-Richtlinien-Dialog angezeigt hat, führen Sie den nächsten Schritt aus. Andernfalls können Sie mit Schritt 6 fortfahren.
Schritt 5: Umgang mit dem DSGVO-Cookie-Dialogfeld
Der folgende Google-GDPR-Cookie-Dialog wird je nach Standort Ihrer IP angezeigt oder nicht. Integrieren Sie einen Proxy-Server in Selenium, um eine Exit-IP des von Ihnen bevorzugten Landes auszuwählen und dieses Problem zu vermeiden.
Überprüfen Sie das HTML-Element des Cookie-Dialogs mit den DevTools:
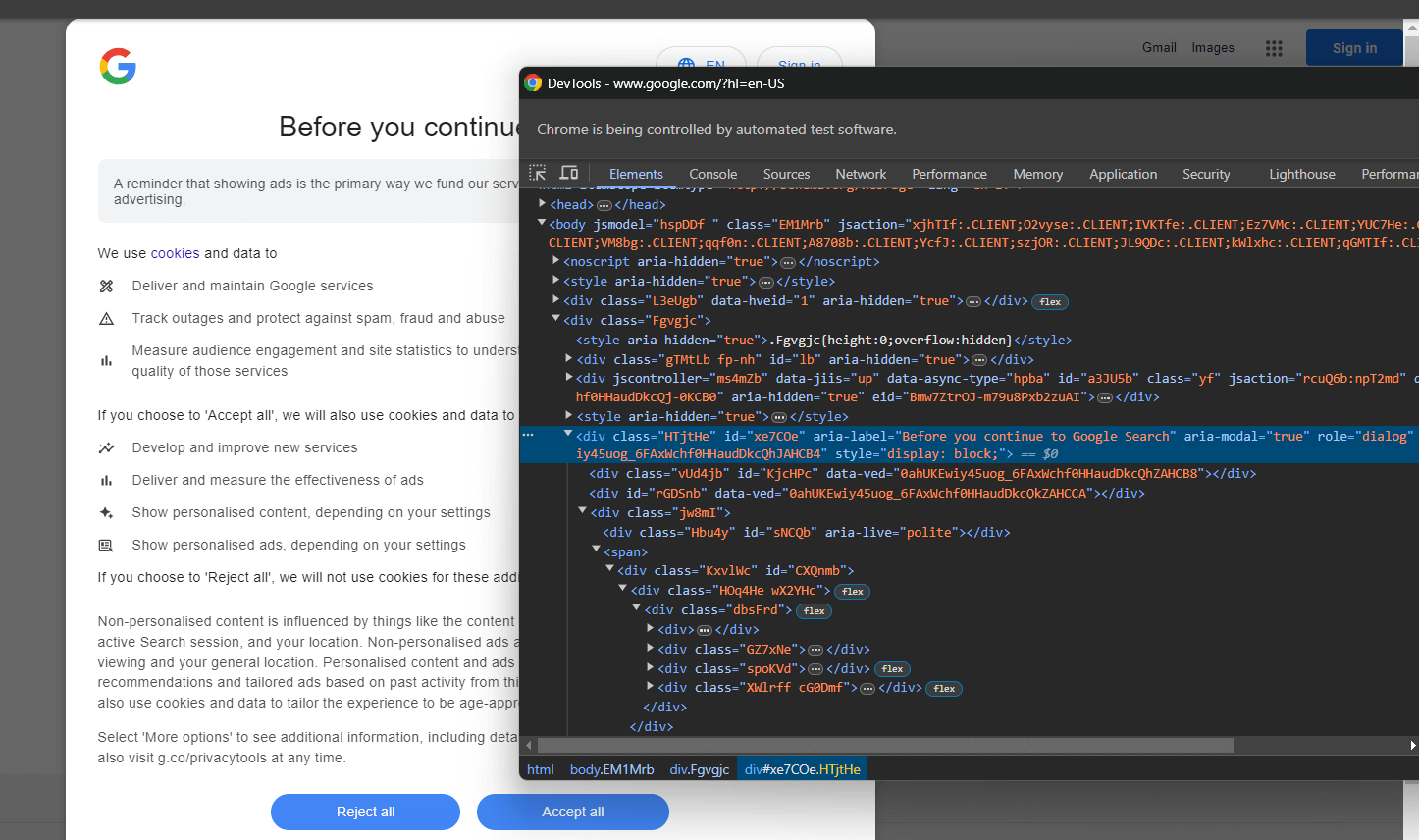
Erweitern Sie den Code und Sie werden feststellen, dass Sie dieses HTML-Element mit dem folgenden CSS-Selektor auswählen können:
[role='dialog']Wenn Sie die Schaltfläche „Alle akzeptieren“ überprüfen, werden Sie feststellen, dass es keine einfache CSS-Auswahlstrategie gibt, um sie auszuwählen:
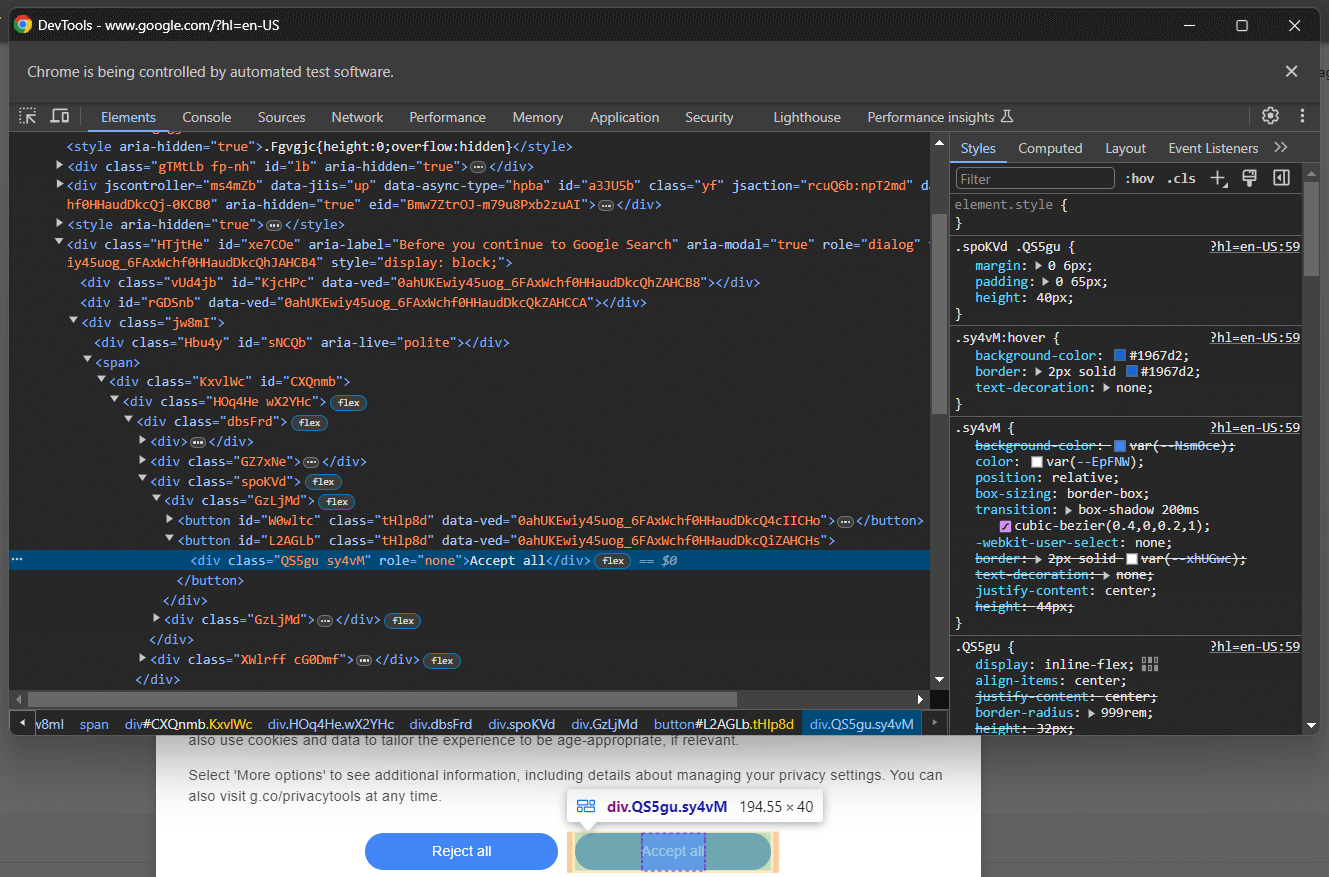
Im Detail scheinen die CSS-Klassen im HTML-Code zufällig generiert zu sein. Um die Schaltfläche auszuwählen, rufen Sie alle Schaltflächen im Cookie-Dialogelement ab und suchen Sie die Schaltfläche mit dem Text „Alle akzeptieren”. Der CSS-Selektor zum Abrufen aller Schaltflächen im Cookie-Dialog lautet:
[role='dialog'] buttonWenden Sie einen CSS-Selektor auf das DOM an, indem Sie ihn an die Selenium-Methode find_elements() übergeben. Dadurch werden HTML-Elemente auf der Seite basierend auf der angegebenen Strategie ausgewählt, in diesem Fall einem CSS-Selektor:
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")Damit die obige Zeile ordnungsgemäß funktioniert, ist der folgende Import erforderlich:
from selenium.webdriver.common.by import ByVerwenden Sie next(), um die Schaltfläche „Alle akzeptieren“ zu finden. Klicken Sie anschließend darauf:
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# Klicken Sie auf die Schaltfläche „Accept all”, falls vorhanden.
if accept_all_button is not None:
accept_all_button.click()Diese Anweisung sucht das <button>-Element im Dialogfeld, dessen Text die Zeichenfolge „Alle akzeptieren” enthält. Wenn vorhanden, wird es durch Aufrufen der Selenium-Methode click() angeklickt.
Fantastisch! Sie sind nun bereit, eine Google-Suche in Python zu simulieren, um einige SERP-Daten zu sammeln.
Schritt 6: Simulieren Sie eine Google-Suche
Öffnen Sie Google in Ihrem Browser und überprüfen Sie das Suchformular in den DevTools:
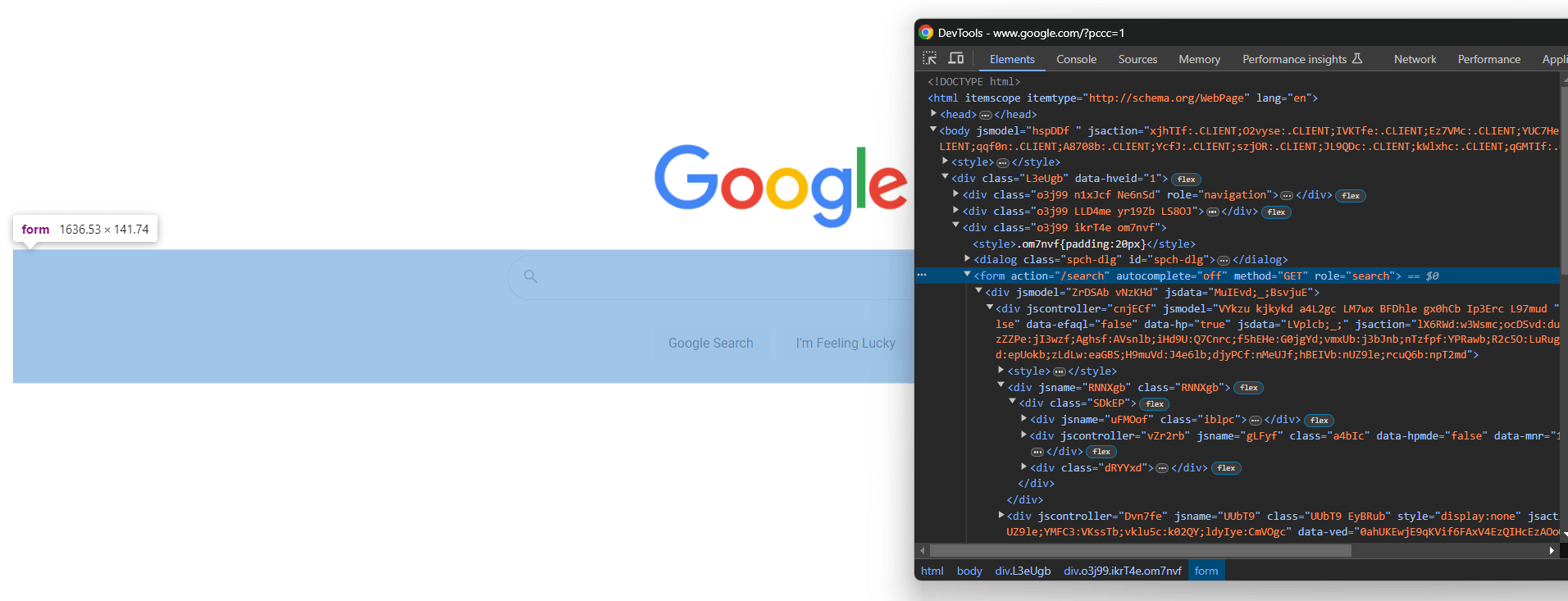
Die CSS-Klassen scheinen zufällig generiert zu sein, aber Sie können das Formular auswählen, indem Sie sein Aktionsattribut mit diesem CSS-Selektor anvisieren:
form[action='/search']Wenden Sie ihn in Selenium an, um das Formularelement über die Methode find_element() abzurufen:
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")Wenn Sie Schritt 5 übersprungen haben, müssen Sie den folgenden Import hinzufügen:
from selenium.webdriver.common.by import ByErweitern Sie den HTML-Code des Formulars und konzentrieren Sie sich auf den Suchtextbereich:
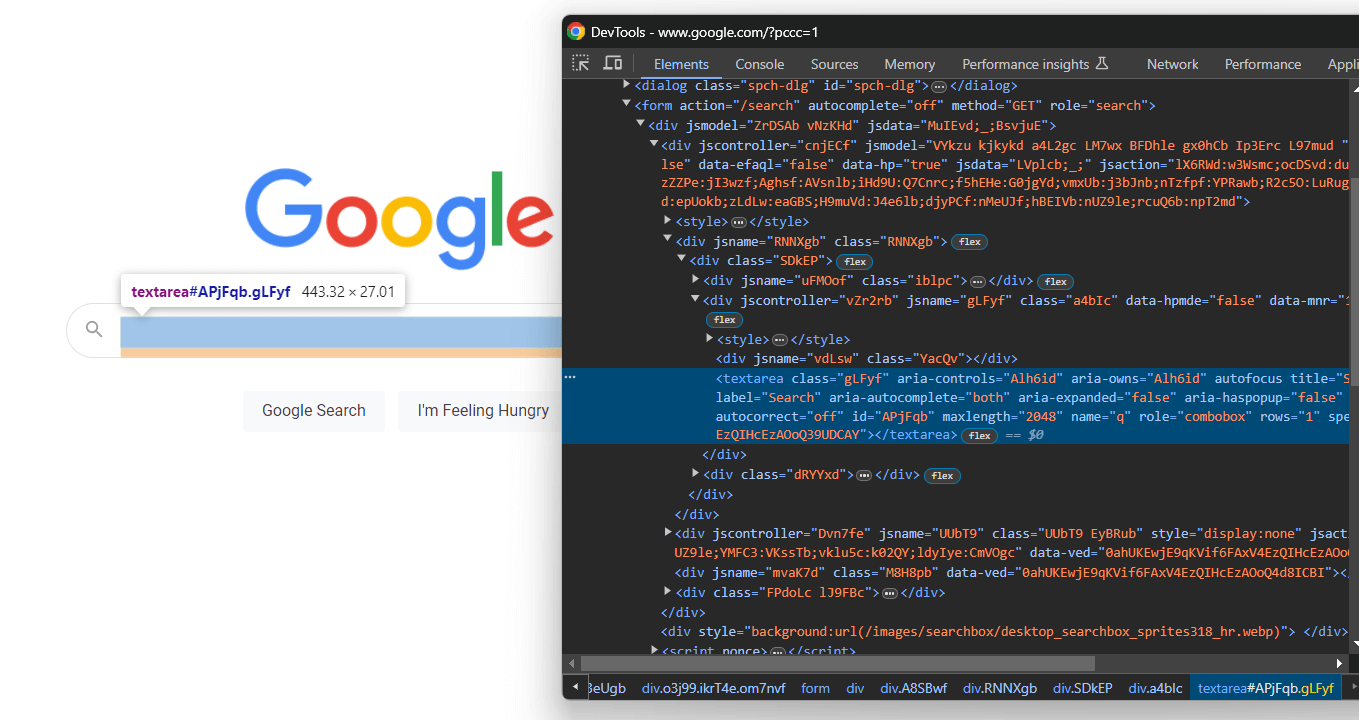
Auch hier wird die CSS-Klasse zufällig generiert, aber Sie können sie anhand ihres aria-label-Werts auswählen:
textarea[aria-label='Search']Suchen Sie also den Textbereich innerhalb des Formulars und geben Sie mit der Schaltfläche send_keys() die Google-Suchanfrage ein:
search_form_textarea= search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)In diesem Fall lautet die Google-Suchanfrage „bright data”. Beachten Sie, dass jede andere Suchanfrage ebenfalls möglich ist.
Rufen Sie nun die Funktion submit() für das Formularelement auf, um das Formular zu senden und eine Google-Suche zu simulieren:
search_form.submit()Google führt die Suche anhand der angegebenen Abfrage durch und leitet Sie zur gewünschten SERP-Seite weiter:
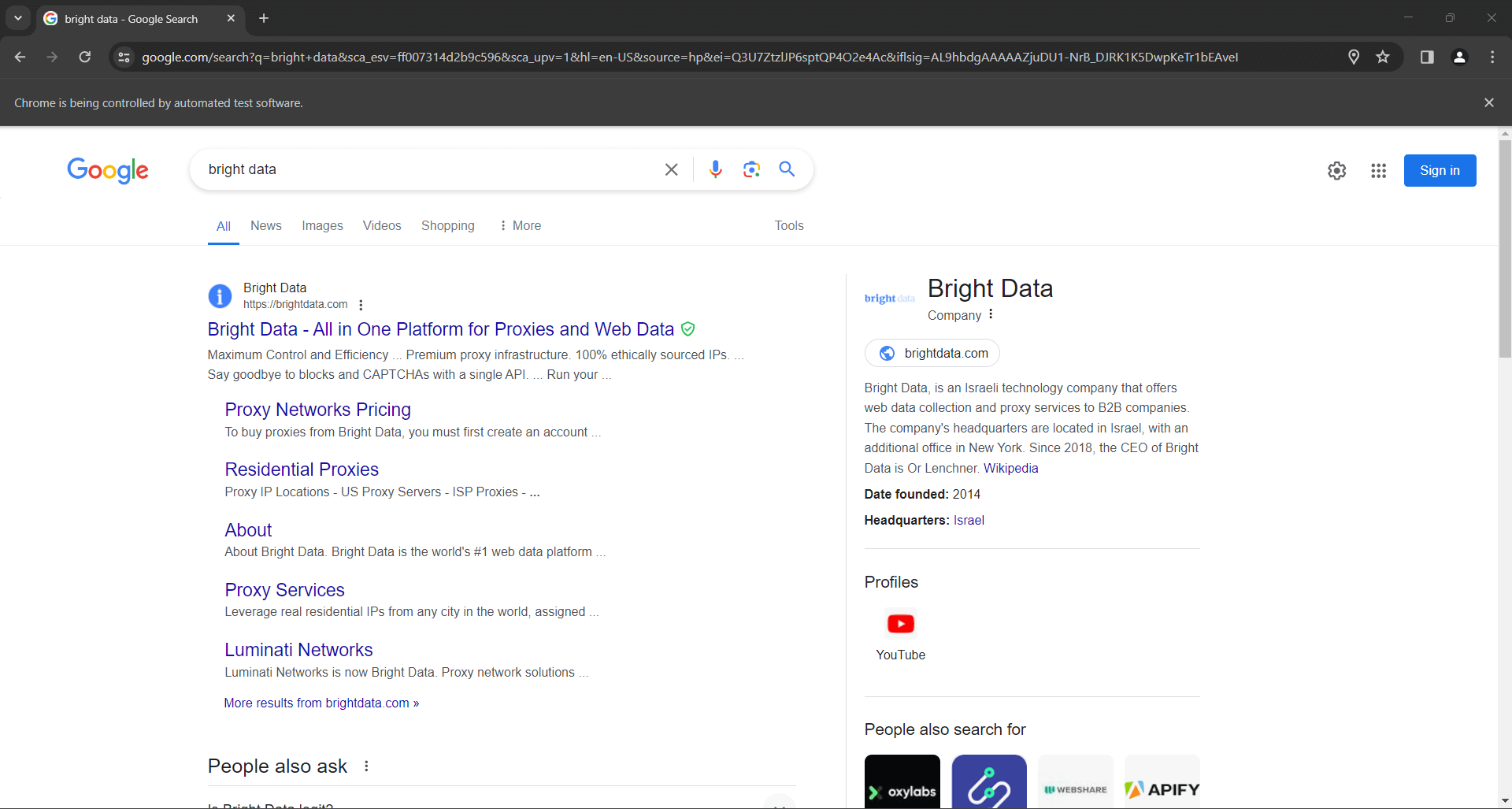
Die Zeilen zur Simulation einer Google-Suche in Python mit Selenium lauten:
# Wählen Sie das Google-Suchformular aus.
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# Wählen Sie den Textbereich innerhalb des Formulars aus.
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# Füllen Sie den Textbereich mit einer bestimmten Suchanfrage aus.
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# Senden Sie das Formular und führen Sie die Google-Suche durch.
search_form.submit()Los geht’s! Machen Sie sich bereit, SERP-Daten durch Scraping von Google in Python abzurufen.
Schritt 7: Wählen Sie die Suchergebniselemente aus
Untersuchen Sie die rechte Spalte im Ergebnisbereich:
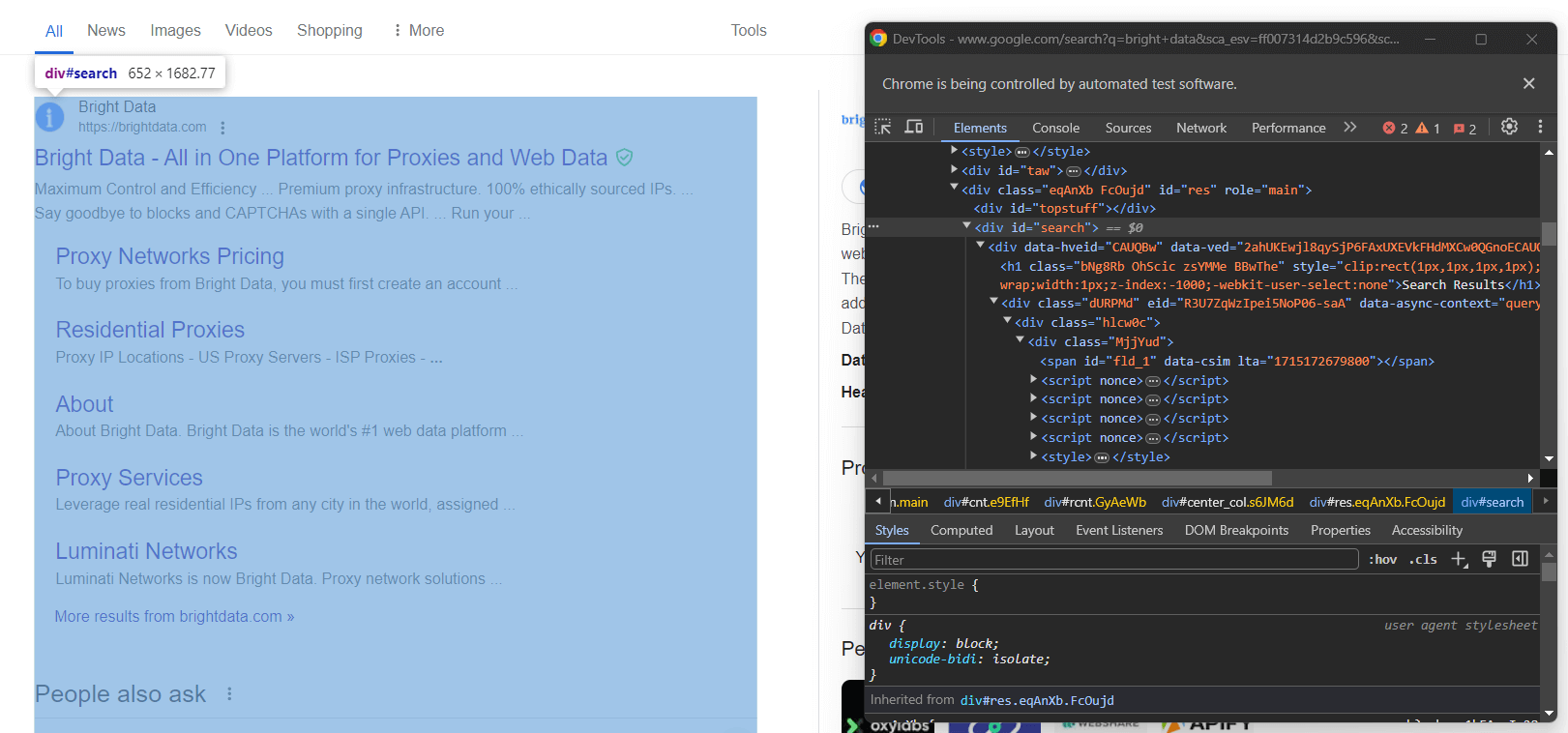
Wie Sie sehen können, handelt es sich um ein <div> -Element, das Sie mit dem folgenden CSS-Selektor auswählen können:
#searchVergessen Sie nicht, dass Google-Seiten dynamisch sind. Daher sollten Sie warten, bis dieses Element auf der Seite vorhanden ist, bevor Sie damit interagieren. Erreichen Sie dies mit der folgenden Zeile:
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))WebDriverWait ist eine spezielle Klasse, die von Selenium angeboten wird, um explizite Wartezeiten zu implementieren. Insbesondere ermöglicht sie es Ihnen, auf das Eintreten eines bestimmten Ereignisses auf der Seite zu warten.
In diesem Fall wartet das Skript bis zu 10 Sekunden, bis der HTML-Knoten #search auf dem Knoten vorhanden ist. Auf diese Weise können Sie sicherstellen, dass die Google-SERP wie gewünscht geladen wurde.
WebDriverWait erfordert einige zusätzliche Importe, fügen Sie diese also zu scraper.py hinzu:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECUntersuchen Sie nun die Google-Suchelemente:
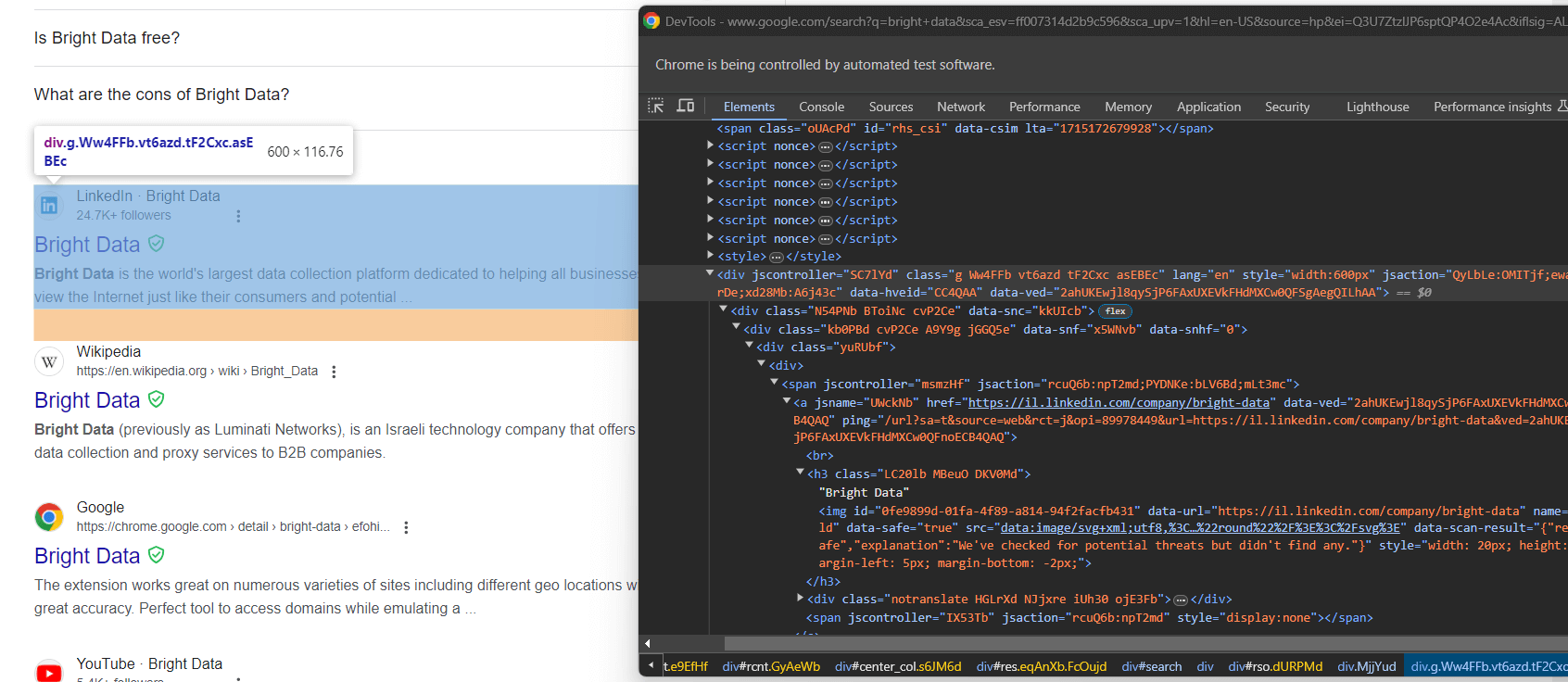
Auch hier ist die Auswahl über CSS-Klassen kein guter Ansatz. Konzentrieren Sie sich stattdessen auf ihre ungewöhnlichen HTML-Attribute. Ein geeigneter CSS-Selektor, um die Google-Suchelemente zu erhalten, ist:
div[jscontroller][lang][jsaction][data-hveid][data-ved]Dieser identifiziert alle <div> -Elemente, die die Attribute jscontroller, lang, jsaction, data-hveid und data-ved haben.
Übergeben Sie ihn an find_elements(), um alle Google-Suchelemente in Python über Selenium auszuwählen:
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")Die gesamte Logik lautet:
# bis zu 10 Sekunden warten, bis das Such-Div auf der Seite angezeigt wird
# und es auswählen
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# wähle die Google-Suchelemente in der SERP aus
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")Großartig! Sie sind nur noch einen Schritt davon entfernt, SERP-Daten in Python zu scrapen.
Schritt 8: Extrahieren Sie die SERP-Daten
Nicht alle Google-SERPs sind gleich aufgebaut. In einigen Fällen hat das erste Suchergebnis auf der Seite einen anderen HTML-Code als die anderen Suchelemente:
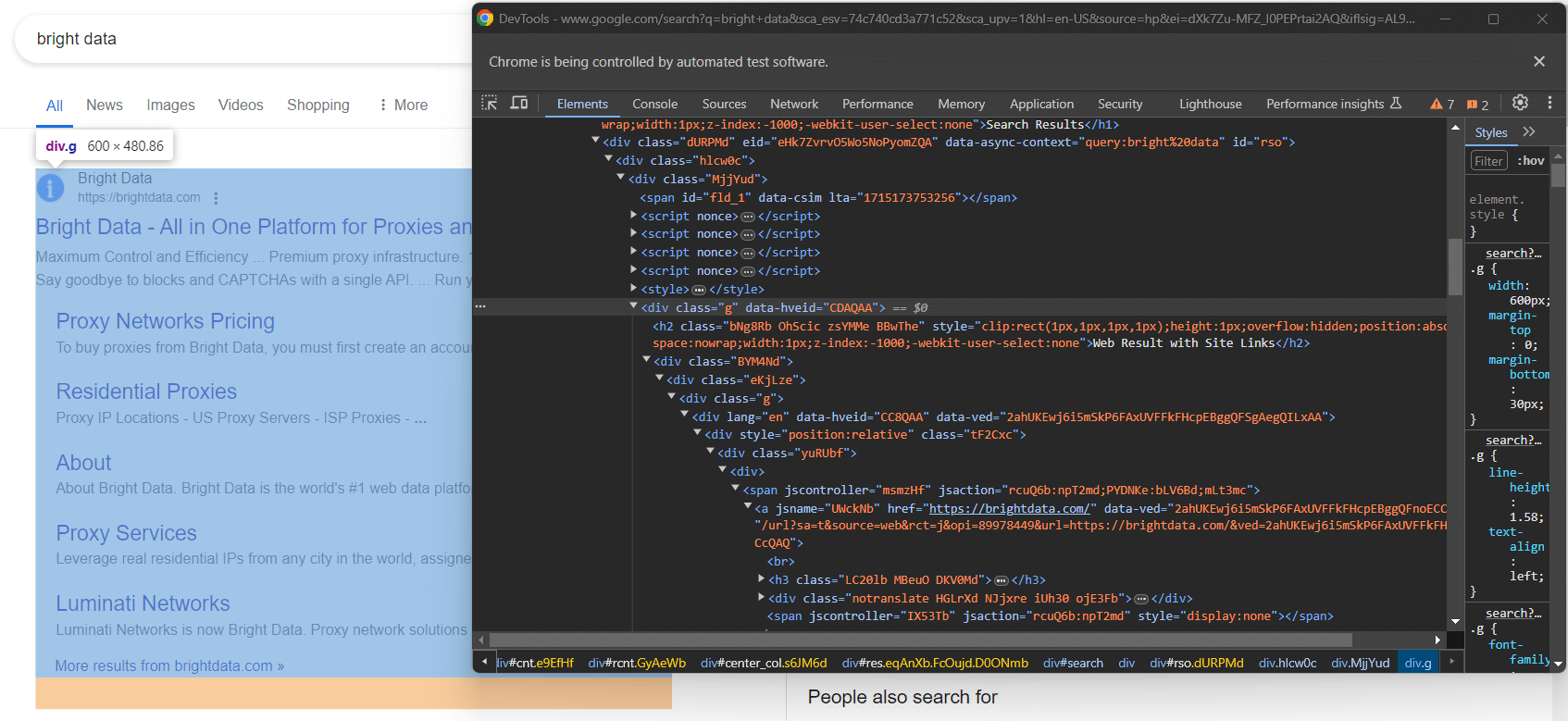
In diesem Fall kann das erste Suchergebniselement beispielsweise mit diesem CSS-Selektor abgerufen werden:
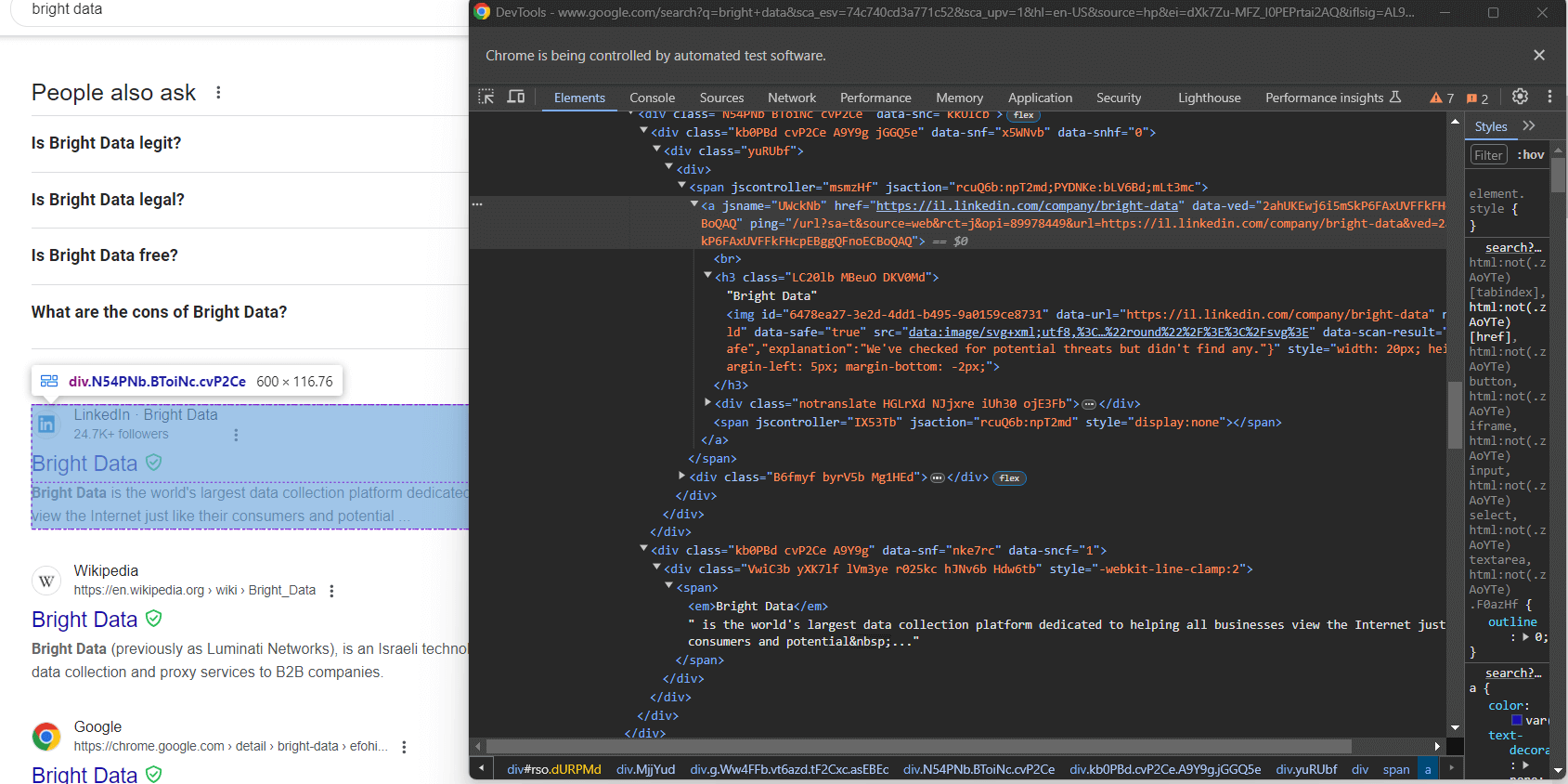
div.g[data-hveid]Abgesehen davon ist der Inhalt eines Google-Suchergebnisses weitgehend identisch. Dazu gehören:
- Den Seitentitel in einem
<h3>-Knoten. - Eine URL zu der spezifischen Seite in einem
<a>-Element, das das übergeordnete Element des oben genannten<h3>-Elements ist. - Eine Beschreibung im
[data-sncf='1'] <div>.
Da eine einzelne SERP mehrere Suchergebnisse enthält, initialisieren Sie ein Array, in dem Sie Ihre gescrapten Daten speichern können:
serp_elements = []Sie benötigen außerdem eine Rang -Ganzzahl, um deren Rang auf der Seite zu verfolgen:
rank = 1Definieren Sie eine Funktion zum Scrapen von Google-Suchergebnissen in Python wie folgt:
def scrape_search_element(search_element, rank):
# select the elements of interest inside the
# search element, ignoring the missing ones, and apply
# the data extraction logic
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# das „a”-Element mit einem „h3”-Kind abrufen
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# return a new SERP data element
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}Google neigt dazu, seine SERP-Seiten häufig zu ändern. Knoten innerhalb der Suchelemente können verschwinden, daher sollten Sie sich mit try ... catch-Anweisungen dagegen schützen. Wenn ein Element nicht im DOM vorhanden ist, löst find_element() eine NoSuchElementException-Ausnahme aus.
Importieren Sie die Ausnahme:
from selenium.common import NoSuchElementExceptionBeachten Sie die Verwendung des CSS-Operators has(), um einen Knoten mit einem bestimmten untergeordneten Element auszuwählen. Weitere Informationen hierzu finden Sie in der offiziellen Dokumentation.
Übergeben Sie nun das erste Suchelement und die übrigen Elemente an die Funktion scrape_search_element(). Fügen Sie dann die zurückgegebenen Objekte zum Array serp_elements hinzu:
# Daten aus dem ersten Element auf der SERP scrapen
# (falls vorhanden)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# Daten aus allen Suchelementen auf der SERP scrapen
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1Am Ende dieser Anweisungen speichert serp_elements alle relevanten SERP-Daten. Überprüfen Sie dies, indem Sie es im Terminal ausgeben:
print(serp_elements)Das Ergebnis sieht in etwa so aus:
[
{'rank': 1, 'url': 'https://brightdata.com/', 'title': 'Bright Data – All-in-One-Plattform für Proxys und Webdaten', 'description': None},
{'rank': 2, 'url': 'https://il.linkedin.com/company/bright-data', 'title': 'Bright Data', 'description': "Bright Data ist die weltweit größte Plattform zur Datenerfassung, die allen Unternehmen dabei hilft, das Internet genauso zu sehen wie ihre Kunden und potenziellen..."},
# der Kürze halber ausgelassen...
{'rank': 6, 'url': 'https://aws.amazon.com/marketplace/seller-profile?id=bf9b4324-6ee3-4eb3-9ca4-083e558d04c4', 'title': 'Bright Data – AWS Marketplace', 'description': 'Bright Data ist eine führende Datenerfassungsplattform, die es unseren Kunden ermöglicht, strukturierte und unstrukturierte Datensätze von Millionen von Websites zu erfassen ...'},
{'rank': 7, 'url': 'https://techcrunch.com/2024/02/26/meta-zieht-Klage-gegen-Web-Scraping-Unternehmen-Bright Data-zurück-...', 'title': 'Meta zieht Klage gegen Web-Scraping-Unternehmen Bright Data zurück ...', 'description': '26. Februar 2024 – Meta hat seine Klage gegen das israelische Web-Scraping-Unternehmen Bright Data fallen gelassen, nachdem es vor einigen Wochen einen wichtigen Prozesspunkt verloren hatte.'}
]Unglaublich! Jetzt müssen Sie nur noch die gescrapten Daten in CSV exportieren.
Schritt 9: Exportieren Sie die gescrapten Daten in eine CSV-Datei
Nachdem Sie nun wissen, wie Sie Google mit Python scrapen können, erfahren Sie, wie Sie die abgerufenen Daten in eine CSV-Datei exportieren können.
Importieren Sie zunächst das CSV -Paket aus der Python-Standardbibliothek:
import csvVerwenden Sie anschließend das csv -Paket, um die Ausgabedatei serp_data.csv mit Ihren SERP-Daten zu füllen:
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)Et voilà! Ihr Google Python-Scraping-Skript ist fertig.
Schritt 10: Alles zusammenfügen
Dies ist der endgültige Code Ihres Skripts scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import NoSuchElementException
import csv
def scrape_search_element(search_element, rank):
# Wähle die interessanten Elemente innerhalb des
# Suchelements aus, ignoriere die fehlenden und wende
# die Logik zur Datenextraktion an.
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# das „a”-Element mit einem „h3”-Kind abrufen
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# return a new SERP data element
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}
# options to launch Chrome in headless mode
options = Options()
options.add_argument('--headless') # während der lokalen Entwicklung auskommentieren
# Initialisieren einer Webdriver-Instanz mit den
# angegebenen Optionen
driver = webdriver.Chrome(
service=Service(),
options=options)
# Verbindung zur Zielwebsite herstellen
driver.get("https://google.com/?hl=en-US")
# Wählen Sie die Schaltflächen im Cookie-Dialogfeld aus.
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# auf die Schaltfläche „Alle akzeptieren” klicken, falls vorhanden
if accept_all_button is not None:
accept_all_button.click()
# Google-Suchformular auswählen
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# Wählen Sie das Textfeld innerhalb des Formulars aus.
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# Füllen Sie das Textfeld mit einer bestimmten Suchanfrage aus.
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# Formular absenden und Google-Suche durchführen
search_form.submit()
# bis zu 10 Sekunden warten, bis das Such-Div auf der Seite angezeigt wird
# und es auswählen
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# Google-Suchelemente in der SERP auswählen
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")
# Speicherort für die gescrapten Daten
serp_elements = []
# um das aktuelle Ranking zu verfolgen
rank = 1
# Daten aus dem ersten Element auf der SERP scrapen
# (falls vorhanden)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# Daten aus allen Suchelementen auf der SERP scrapen
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1
# Die gescrapten Daten in CSV exportieren
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)
# Browser schließen und Ressourcen freigeben
driver.quit()Wow! Mit nur etwas mehr als 100 Zeilen Code können Sie einen Google-SERP-Scraper in Python erstellen.
Überprüfen Sie, ob er die erwarteten Ergebnisse liefert, indem Sie ihn in Ihrer IDE ausführen oder diesen Befehl verwenden:
python Scraper.pyWarten Sie, bis die Ausführung des Scrapers abgeschlossen ist. Anschließend wird die Datei serp_results.csv im Stammverzeichnis des Projekts angezeigt. Öffnen Sie sie, um Folgendes anzuzeigen:

Herzlichen Glückwunsch! Sie haben gerade ein Google-Scraping in Python durchgeführt.
Fazit
In diesem Tutorial haben Sie gesehen, welche Daten von Google gesammelt werden können und warum SERP-Daten am interessantesten sind. Insbesondere haben Sie gelernt, wie Sie mit Hilfe von Browser-Automatisierung einen SERP-Scraper in Python mit Selenium erstellen können.
Das funktioniert bei einfachen Beispielen, aber es gibt drei wesentliche Herausforderungen beim Scraping von Google mit Python:
- Google ändert ständig die Seitenstruktur der SERPs.
- Google verfügt über einige der fortschrittlichsten Anti-Bot-Lösungen auf dem Markt.
- Die Entwicklung eines effektiven Scraping-Prozesses, der parallel große Mengen an SERP-Daten abrufen kann, ist komplex und kostspielig.
Mit der SERP-API von Bright Data gehören diese Herausforderungen der Vergangenheit an. Diese API der nächsten Generation bietet eine Reihe von Endpunkten, die SERP-Daten aller wichtigen Suchmaschinen in Echtzeit bereitstellen. Die SERP-API basiert aufden erstklassigenProxy-Diensten und Anti-Bot-Bypass-Lösungen von Bright Data und zielt mühelos auf mehrere Suchmaschinen ab.
Führen Sie einen einfachen API-Aufruf durch und erhalten Sie Ihre SERP-Daten dank der SERP-API im JSON- oder HTML-Format. Testen Sie noch heute kostenlos!





