

In diesem Artikel erfahren Sie:
- Was Azure Synapse Analytics ist und was es bietet.
- Warum die Integration der SERP-API von Bright Data in Azure Synapse Analytics eine erfolgreiche Strategie ist.
- Wie Sie eine Azure Synapse-Pipeline erstellen, die Web-Suchdaten mithilfe der SERP-API von Bright Data sammelt, transformiert und analysiert.
Lassen Sie uns loslegen!
Was ist Azure Synapse Analytics?
Azure Synapse Analytics ist eine cloudbasierte Analyseplattform, die Datenintegration, Unternehmensdatenlagerung und Big-Data-Verarbeitung in einem einzigen Arbeitsbereich vereint. Sie bietet Pipeline-Orchestrierung, Apache Spark-Pools sowie dedizierte und serverlose SQL-Pools, sodass Sie Daten in großem Umfang aus einer einzigen einheitlichen Umgebung erfassen, transformieren und abfragen können.
Das Hauptziel besteht darin, Ihnen dabei zu helfen, aus Rohdaten geschäftliche Erkenntnisse zu gewinnen. Dies wird durch die Kombination einer Pipeline-Engine (basierend auf Azure Data Factory) für die Datenerfassung, Apache Spark-Notebooks für codebasierte Transformationen und SQL-Pools für die Abfrage und Bereitstellung von analysefähigen Datensätzen für Dashboards, ML-Modelle und nachgelagerte Anwendungen erreicht.
Azure Synapse Analytics vs. Azure KI Foundry: Was ist der Unterschied?
Wenn Sie bereits unseren Leitfaden zur Integration der SERP-API in Azure KI Foundry gelesen haben, fragen Sie sich vielleicht, wie sich Synapse Analytics davon unterscheidet. Die beiden dienen grundlegend unterschiedlichen Zwecken:
- Azure AI Foundry ist eine einheitliche KI-Entwicklungsplattform, die sich auf die Erstellung, Bereitstellung und Verwaltung von KI-Anwendungen, Agenten und Prompt-Flows konzentriert. Sie bietet Zugriff auf einen Katalog von LLMs (von Azure OpenAI, Meta, Mistral usw.) und ist für die KI-orientierte Entwicklung mit Prompt-Engineering, Modelloptimierung und RAG-Workflows konzipiert.
- Azure Synapse Analytics ist eine Datenanalyse- und Data-Warehousing-Plattform, die sich auf die Erfassung großer Datenmengen, die Durchführung komplexer Transformationen und die Bereitstellung strukturierter Analysen in großem Maßstab konzentriert. Sie eignet sich hervorragend für ETL/ELT-Pipelines, die Verarbeitung von Big Data mit Spark und SQL-basierte Business Intelligence.
Kurz gesagt: Mit Azure AI Foundry erstellen Sie KI-gestützte Anwendungen und Prompt-Flows, während Sie mit Azure Synapse Analytics Datenpipelines erstellen, die Daten für Analysen und Berichte sammeln, transformieren und speichern.
Die beiden Plattformen ergänzen sich perfekt. Mit Synapse können Sie die Datengrundlage aufbauen, Webdaten in großem Umfang sammeln und speichern und diese kuratierten Daten dann in AI Foundry für KI-gestützte Analysen einspeisen. In diesem Tutorial erfahren Sie, wie Synapse Analytics mit der SERP-API von Bright Data integriert werden kann, um eine vollständige Webdaten-Pipeline aufzubauen, die Suchergebnisse sammelt, sie mit Spark transformiert und Analysen über SQL bereitstellt.
Warum die SERP-API von Bright Data in Azure Synapse Analytics integrieren?
Azure Synapse Analytics bietet in seiner Pipeline-Engine einen leistungsstarken REST-Konnektor, mit dem Sie jede REST-API aufrufen und die Ergebnisse direkt in Azure Data Lake Storage speichern können. Dies eröffnet Ihnen die Möglichkeit, externe Datenquellen in Ihre Analyse-Workflows einzubinden. Um jedoch Echtzeit-Websuchdaten in Ihr Data Warehouse einzuspeisen, benötigen Sie eine zuverlässige, skalierbare und strukturierte Datenquelle.
Hier kommt die SERP-API von Bright Data ins Spiel. Mit der SERP-API können Sie programmgesteuert Suchanfragen in Suchmaschinen wie Google, Bing, DuckDuckGo, Yandex und anderen durchführen und den vollständigen SERP-Inhalt abrufen. Sie gibt Daten in verschiedenen Formaten zurück, darunter geparste JSON-Daten, rohe HTML-Daten und KI-fähige Markdown-Daten, und bietet Ihnen so eine zuverlässige Quelle für aktuelle, überprüfbare Daten.
Dieser Ansatz ist besonders nützlich für:
- SEO-Keyword-Tracking-Pipelines, um Ihre Suchrankings für Tausende von Keywords täglich zu überwachen und Trends im Zeitverlauf zu identifizieren.
- Wettbewerbsanalyse-Warehouses, um Daten zur Sichtbarkeit von Wettbewerbern zu sammeln und diese mit internen Metriken für strategische Analysen zu verbinden.
- Datensätze der Marktforschung, um Suchergebnis-Trends über Branchen, Regionen und Zeiträume hinweg für groß angelegte Berichte zu aggregieren.
- Content-Performance-Analysen, um zu verfolgen, wie Ihre Inhalte für Ziel-Keywords ranken, und um die Auswirkungen von SEO-Maßnahmen zu messen.
Durch die Kombination der Pipeline-Orchestrierungs- und Data-Warehousing-Funktionen von Azure Synapse mit der SERP-API von Bright Data können Sie Datenpipelines erstellen, die kontinuierlich Web-Suchdaten in großem Umfang sammeln, transformieren und analysieren, ohne dass Sie eine Scraping-Infrastruktur unterhalten müssen.
So erstellen Sie eine SERP-Datenpipeline in Azure Synapse mit Bright Data
In diesem Abschnitt erfahren Sie, wie Sie die SERP-API von Bright Data als Teil eines täglichen Keyword-Ranking-Trackers in eine Azure Synapse-Pipeline integrieren können. Diese Pipeline besteht aus fünf Hauptschritten:
- Einrichtung des Arbeitsbereichs: Sie erstellen einen Azure Synapse-Arbeitsbereich mit einem verknüpften Data Lake Storage-Konto.
- Konfiguration der Datenquelle: Sie erstellen einen mit REST verknüpften Dienst, der auf die SERP-API von Bright Data verweist, mit sicherer Speicherung der Anmeldedaten.
- Erfassungspipeline: Eine Synapse-Pipeline ruft die SERP-API für eine Reihe von verfolgten Keywords auf und speichert die rohen JSON-Ergebnisse in Ihrem Data Lake.
- Spark-Transformation: Ein Apache Spark-Notebook glättet und normalisiert die rohen SERP-Daten zu analysefähigen Delta-Tabellen.
- SQL-Analyse: Serverlose SQL-Abfragen analysieren Ranking-Trends, und es werden Ansichten für Power BI-Dashboards erstellt.
Hinweis: Dies ist nur ein Beispiel. Sie können die SERP-API in vielen anderen Szenarien und Anwendungsfällen nutzen. Sie könnten beispielsweise auch Pipelines für die Preisüberwachung wettbewerbsfähiger Preise erstellen oder SERP-Daten in Machine-Learning-Modelle einspeisen.
Befolgen Sie die nachstehenden Anweisungen, um eine Webdaten-Pipeline auf Basis der SERP-API von Bright Data in Azure Synapse Analytics zu erstellen!
Voraussetzungen
Um diesem Tutorial-Abschnitt folgen zu können, benötigen Sie Folgendes:
- Ein Microsoft-Konto.
- Ein Azure-Abonnement (auch die kostenlose Testversion ist ausreichend).
- Ein Bright Data-Konto mit einer aktiven SERP-API-Zone und einem API-Schlüssel (mit Administratorrechten).
Befolgen Sie die offizielle Bright Data-Dokumentation, um Ihre SERP-API-Zone einzurichten und Ihren API-Schlüssel zu erhalten. Bewahren Sie Ihren API-Schlüssel und den Zonennamen an einem sicheren Ort auf, da Sie sie in Kürze benötigen werden.
Schritt 1: Erstellen Sie einen Azure Synapse-Arbeitsbereich
Azure Synapse-Pipelines sind nur innerhalb eines Synapse-Arbeitsbereichs verfügbar, daher müssen Sie zunächst einen solchen erstellen.
Melden Sie sich bei Ihrem Azure-Konto an und suchen Sie in der Suchleiste oben im Azure-Portal nach Azure Synapse Analytics:
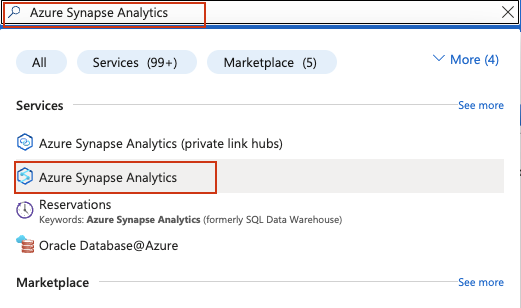
Klicken Sie auf der Verwaltungsseite von Synapse Analytics auf „Erstellen“. Füllen Sie das Erstellungsformular aus:
- Wählen Sie Ihr Azure-Abonnement aus.
- Wählen Sie eine vorhandene Ressourcengruppe aus oder erstellen Sie eine neue.
- Geben Sie Ihrem Arbeitsbereich einen Namen, z. B.
„bright-data-serp-pipeline“. - Wählen Sie eine Region in Ihrer Nähe aus.
- Wählen Sie für Data Lake Storage Gen2 „Neu erstellen “ und geben Sie einen Speicherkontennamen ein (muss vollständig in Kleinbuchstaben geschrieben sein, 3–24 Zeichen lang und weltweit eindeutig sein, z. B.
„serppipelinelake“). Erstellen Sie ein neues Dateisystem mit dem Namen„raw“.
Klicken Sie auf „Überprüfen + Erstellen“ und dann auf „Erstellen“, um die Bereitstellung zu starten.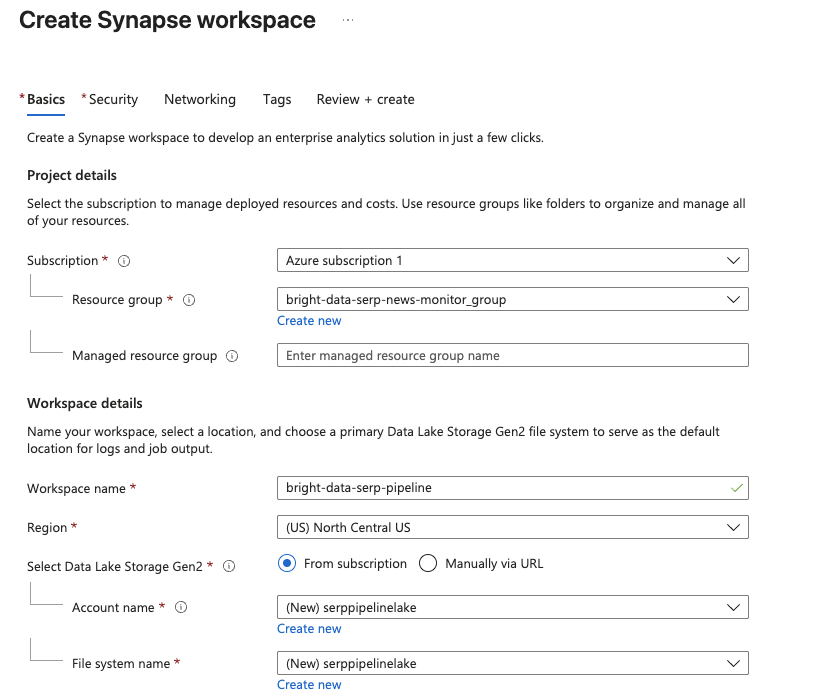
Der Initialisierungsprozess kann einige Minuten dauern. Nach Abschluss des Vorgangs sollte eine Bestätigungsseite angezeigt werden. Klicken Sie auf „Zur Ressource gehen“ und dann auf „Synapse Studio öffnen“, um die webbasierte Entwicklungsumgebung zu starten.
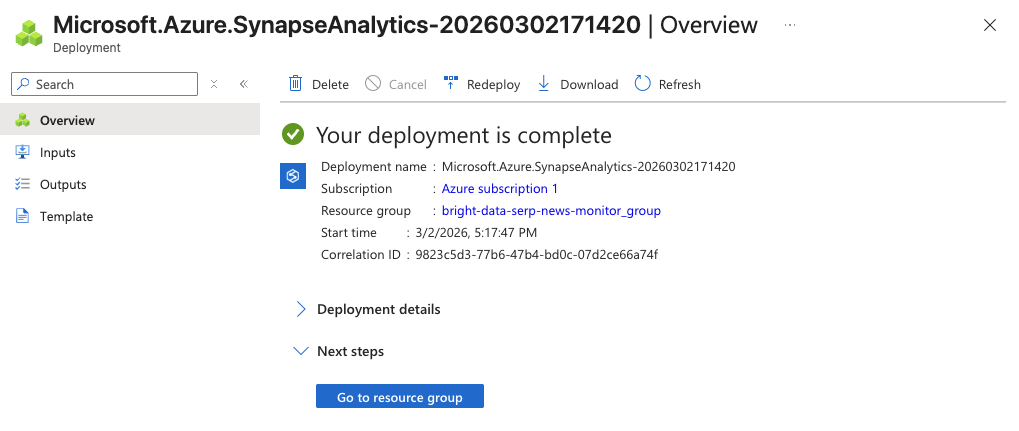
Sie verfügen nun über einen Synapse-Arbeitsbereich, in dem Sie Pipelines erstellen, Spark-Notebooks schreiben und SQL-Abfragen ausführen können.
Schritt 2: Erstellen eines Apache Spark-Pools
Um die Transformations-Notebooks später in diesem Tutorial ausführen zu können, benötigen Sie einen Apache Spark-Pool in Ihrem Arbeitsbereich.
- Gehen Sie in Synapse Studio zu „Verwalten“ > „Apache Spark-Pools “ > „Neu“.
- Geben Sie dem Pool einen Namen, z. B.
„sparkpool“. - Stellen Sie die Knotengröße auf „Klein“ (4 vCores / 32 GB) ein, dies ist für SERP-Datentransformationen ausreichend.
- Aktivieren Sie „Automatische Skalierung“ und legen Sie den Bereich auf 3–5 Knoten fest.
- Klicken Sie auf „Überprüfen + Erstellen“ und dann auf „Erstellen“.
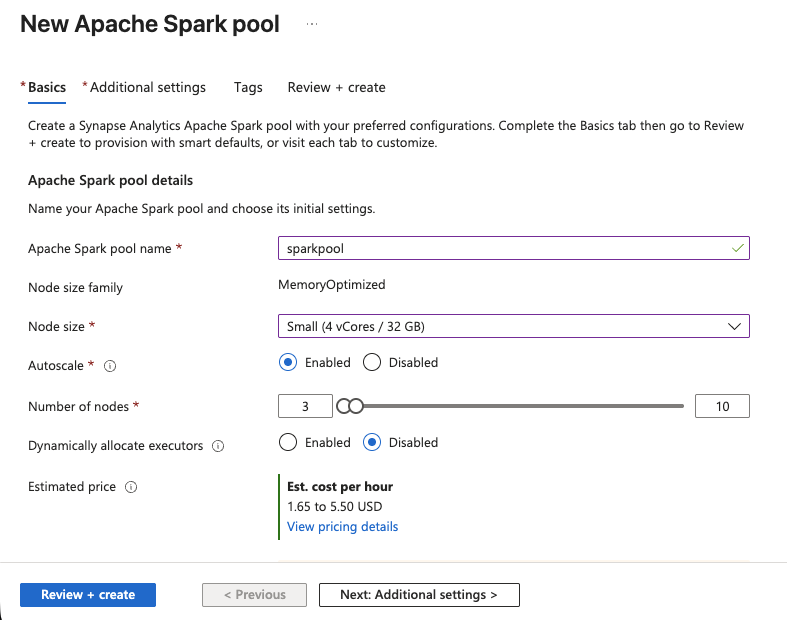
Der Spark-Pool ist in wenigen Augenblicken einsatzbereit. Sie verfügen nun über die Rechenleistung zum Ausführen von PySpark-Notebooks.
Schritt 3: Erstellen Sie die Erfassungspipeline
Jetzt erstellen Sie eine Synapse-Pipeline, die die SERP-API von Bright Data für eine Reihe von verfolgten Keywords aufruft und die Ergebnisse in Ihrem Data Lake speichert.
Erstellen Sie eine neue Pipeline
- Gehen Sie zu „Integrieren“ > „+“ > „Pipeline“.
- Nennen Sie sie
„IngestSERPData“.
Fügen Sie Pipeline-Parameter hinzu
Klicken Sie auf den Hintergrund der Pipeline-Arbeitsfläche, um die Pipeline-Eigenschaften zu öffnen. Gehen Sie zur Registerkarte „Parameter“ und fügen Sie Folgendes hinzu:
| Name | Typ | Standardwert |
|---|---|---|
Schlüsselwörter |
Array | ["Web-Scraping-Tools", "Proxy-Dienst", "Daten-Extraktions-API"] |
Dies sind die Schlüsselwörter, für die Sie Rankings verfolgen möchten. Sie können diese Liste jederzeit ändern.
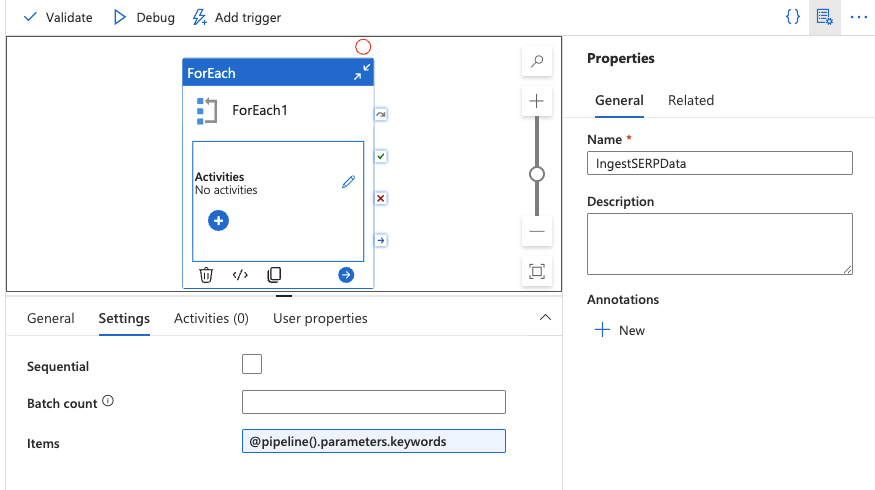
Fügen Sie eine ForEach-Aktivität hinzu
- Ziehen Sie eine ForEach -Aktivität aus dem Aktivitätenbereich auf die Arbeitsfläche.
- Legen Sie auf der Registerkarte „Einstellungen“ das Feld „Elemente“ wie folgt fest:
@pipeline().parameters.keywords
Dadurch werden alle Schlüsselwörter in Ihrem Array durchlaufen.
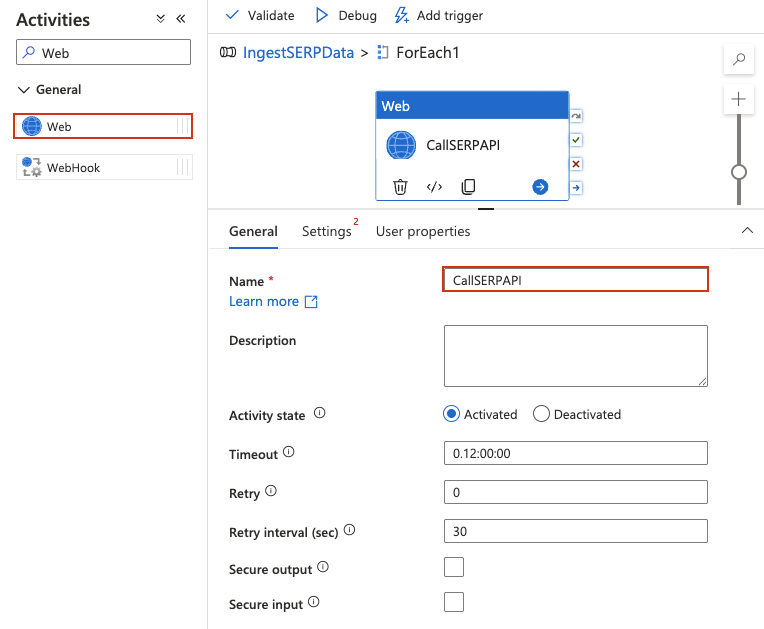
Fügen Sie eine Web-Aktivität innerhalb von „ForEach“ hinzu
Eine Web-Aktivität ruft eine REST-API direkt auf, ohne dass Datensätze oder verknüpfte Dienste für die Anfrage selbst erforderlich sind.
- Doppelklicken Sie auf die ForEach-Aktivität, um die innere Arbeitsfläche zu öffnen. Die Kopfzeile des Designers sollte sich ändern und anzeigen, dass Sie sich innerhalb des ForEach-Bereichs befinden (Breadcrumb-ähnlich:
IngestSERPData > ForEach1). - Erweitern Sie im Bereich „Aktivitäten“ auf der linken Seite den Eintrag „Allgemein“ und ziehen Sie eine Webaktivität auf die innere Arbeitsfläche.
- Geben Sie ihr einen Namen, z. B.
„CallSERPAPI“.
Konfigurieren Sie die Webaktivität
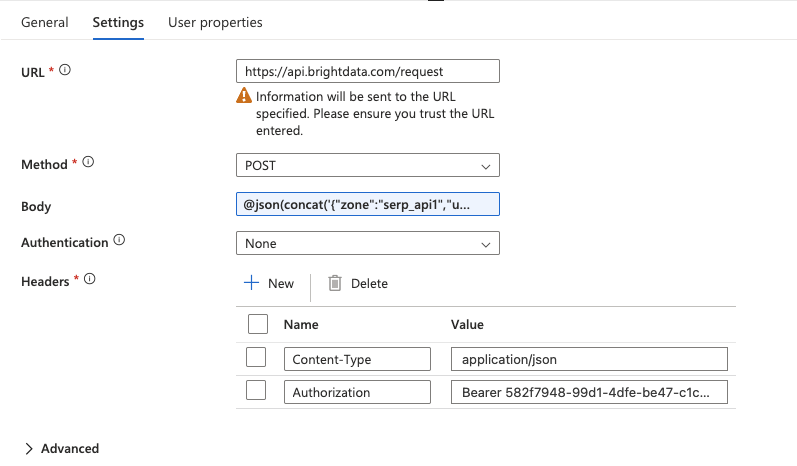
Klicken Sie auf die Webaktivität, um sie auszuwählen, und gehen Sie dann zur Registerkarte „Einstellungen“, um Folgendes zu konfigurieren:
- URL: Geben Sie den vollständigen API-Endpunkt direkt in das Feld ein:
https://api.brightdata.com/request- Methode: Wählen Sie
POSTaus der Dropdown-Liste aus. - Header: Klicken Sie zweimal auf „+ Header hinzufügen“, um Folgendes hinzuzufügen: Name Wert
Content-Typeapplication/jsonAuthorizationBearer YOUR_BRIGHT_DATA_API_KEY - Body: Hier übergeben Sie die SERP-API-Anfrage mit dem aktuellen Schlüsselwort aus der ForEach-Schleife. Geben Sie den folgenden Ausdruck direkt in das Feld „Body“ ein (verwenden Sie nicht das Popup-Fenster „Dynamischen Inhalt hinzufügen“):
@concat('{"Zone":"YOUR_SERP_API_Zone","url":"https://www.google.com/search?q=',replace(item(),' ','+'),'&hl=en&gl=us","format":"raw","data_format":"json"}')Ersetzen Sie YOUR_SERP_API_ZONE durch Ihren tatsächlichen Zonennamen aus dem Bright Data-Dashboard.
Wichtig: Das
@muss das allererste Zeichen im Feld sein, ohne führende Leerzeichen. Dadurch wird Synapse angewiesen, den Text als Ausdruck auszuwerten. Bei korrekter Eingabe wird der Ausdruck im Feld hervorgehoben. Wenn er als einfacher Text angezeigt wird, löschen Sie ihn und geben Sie ihn erneut ein, wobei Sie darauf achten müssen, dass@an der Position Null steht.Funktion: Die Funktion
item()gibt das aktuelle Schlüsselwort aus der ForEach-Schleife zurück (z. B.„Web-Scraping-Tools“). Die Funktionreplace()ersetzt Leerzeichen durch+-Zeichen, um einen gültigen URL-Abfrageparameter zu bilden. Die Funktionconcat()erstellt den vollständigen JSON-Anfragetext als einzelne Zeichenfolge.
- Authentifizierung: Auf
„Keine“setzen (die Authentifizierung wird bereits über den Authorization-Header abgewickelt).
Zeitplan-Trigger hinzufügen
- Zurück auf der Haupt-Pipeline-Leinwand klicken Sie auf „Trigger hinzufügen “ > „Neu/Bearbeiten“.
- Wählen Sie „Neu“ und legen Sie eine tägliche Wiederholung fest (z. B. 6:00 Uhr UTC).
- Klicken Sie auf „OK“ und dann auf „Alle veröffentlichen“, um die Pipeline zu speichern und bereitzustellen.
Um sie sofort zu testen, klicken Sie auf Jetzt auslösen > OK. Navigieren Sie zu Überwachen > Pipeline-Ausführungen, um die Ausführung zu beobachten. Sie sollten sehen, dass die Pipeline erfolgreich ist, und JSON-Dateien in Ihrem Data Lake unter dem Pfad raw/serp/ finden.
Zurück zur Haupt-Pipeline-Leinwand
Klicken Sie auf den Namen der Pipeline (IngestSERPData) in der Breadcrumb-Navigation oben im Designer, um zur Haupt-Canvas zurückzukehren. Sie sollten die ForEach-Aktivität mit einem Indikator sehen, der anzeigt, dass sie untergeordnete Aktivitäten enthält.
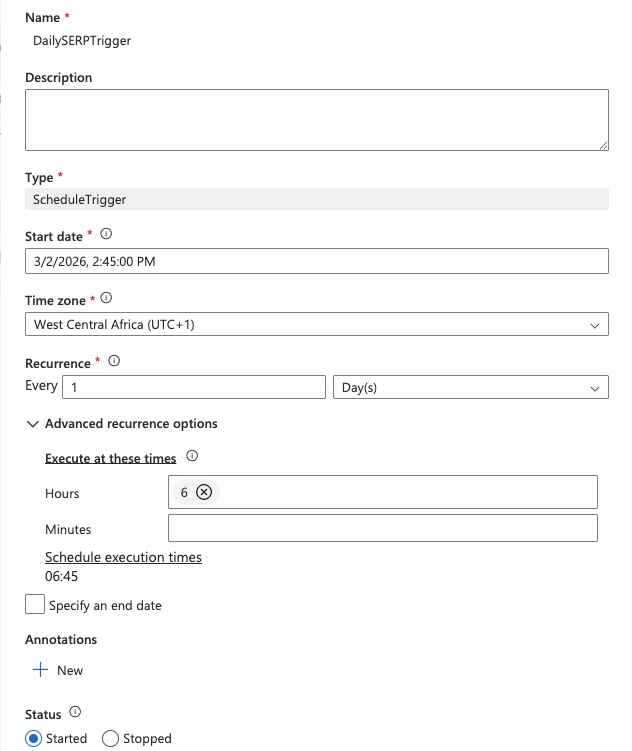
Fügen Sie einen Zeitplan-Trigger hinzu
- Klicken Sie oben im Pipeline-Designer auf „Trigger hinzufügen > Neu/Bearbeiten “.
- Wählen Sie in der Dropdown-Liste „Neu“ aus.
- Geben Sie dem Trigger einen Namen (z. B.
DailySERPTrigger), legen Sie den Typ auf „Zeitplan“ fest und konfigurieren Sie Folgendes:
- Startdatum: Das heutige Datum
- Wiederholung: Alle
1Tag - Zu diesen Uhrzeiten:
6(für 6:00 Uhr UTC)
- Klicken Sie auf „OK“ und bestätigen Sie die Trigger-Parameter.
- Klicken Sie oben in Synapse Studio auf „Alle veröffentlichen“, um alles zu speichern und bereitzustellen.
Testen Sie die Pipeline
So führen Sie die Pipeline sofort aus, ohne auf den geplanten Trigger zu warten:
- Klicken Sie oben im Pipeline-Designer auf Jetzt auslösen > OK.
- Navigieren Sie im linken Menü zu „Überwachen > Pipeline-Ausführungen “.
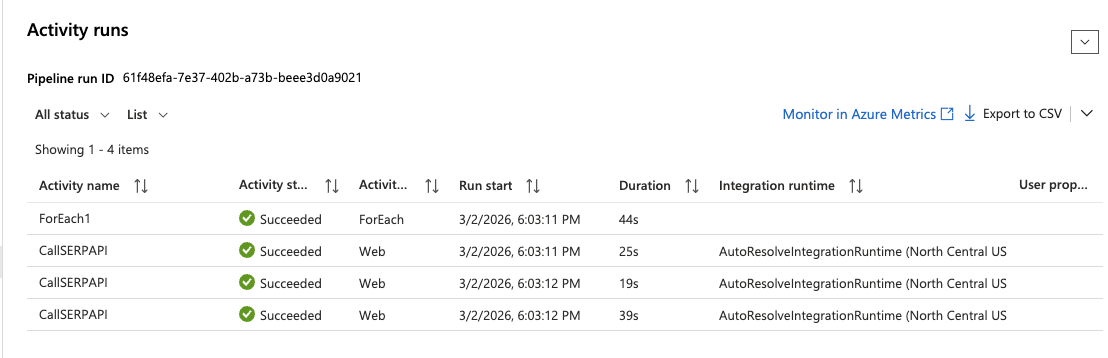
- Warten Sie, bis der Lauf abgeschlossen ist. Es sollte ein grüner Status „Erfolgreich“ angezeigt werden.
- Klicken Sie auf den Lauf und erweitern Sie die ForEach-Aktivität, um jede Ausführung der Webaktivität zu überprüfen. Klicken Sie auf eine beliebige
CallSERPAPI-Iteration, um die vollständige API-Antwort im Abschnitt „Ausgabe“ anzuzeigen.
Schritt 4: Daten mit Apache Spark sammeln und transformieren
Die Webaktivität in Schritt 3 hat bestätigt, dass die SERP-API-Integration funktioniert, und die Pipeline-Orchestrierung mit Zeitplanung demonstriert. Für den Schritt der Datenerfassung und -transformation verwenden Sie ein Apache Spark-Notebook, das die SERP-API direkt mit Python aufruft, die Rohantworten in Ihrem Data Lake speichert und sie in analysefähige Delta-Tabellen umwandelt.
Dieser Ansatz ist im Data Engineering Standard: Pipelines übernehmen die Orchestrierung und Planung, während Notebooks die eigentliche Datenverarbeitungslogik übernehmen.
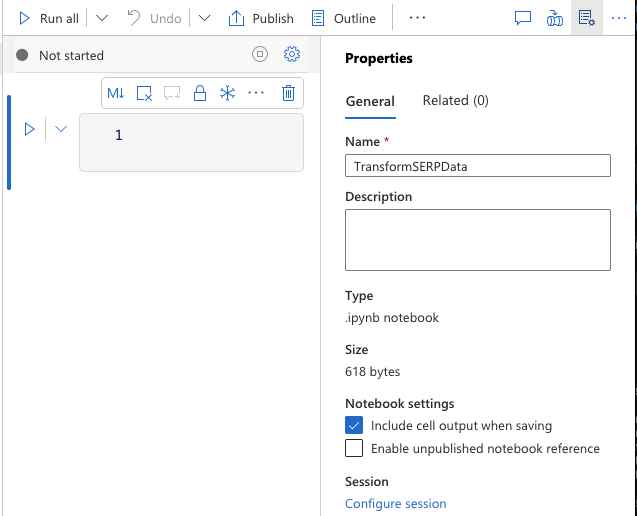
Erstellen Sie ein Spark-Notebook
- Navigieren Sie zu „Entwickeln“ > „+“ > „Notebook“.
- Nennen Sie es
„TransformSERPData“. - Fügen Sie es Ihrem
SparkpoolApache Spark-Pool hinzu. - Stellen Sie sicher, dass PySpark (Python) als Sprache ausgewählt ist.
Zelle 1: SERP-Daten sammeln und im Data Lake speichern
Fügen Sie in der ersten Zelle den folgenden Code hinzu. Dadurch wird die Bright Data SERP-API für jedes Keyword aufgerufen und die rohen JSON-Antworten in Ihrem Data Lake gespeichert:
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# Konfiguration
API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
Zone = "YOUR_SERP_API_Zone"
STORAGE_ACCOUNT = "YOUR_STORAGE_ACCOUNT"
import requests
import json
from datetime import datetime
from notebookutils import mssparkutils
# SERP-Daten für jedes Keyword sammeln
today = datetime.utcnow().strftime("%Y/%m/%d")
for keyword in KEYWORDS:
# Aufruf der Bright Data SERP-API
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
},
json={
"zone": Zone,
"url": f"abfss://[email protected]/serp/{today}/{file_name}.json"
}
)
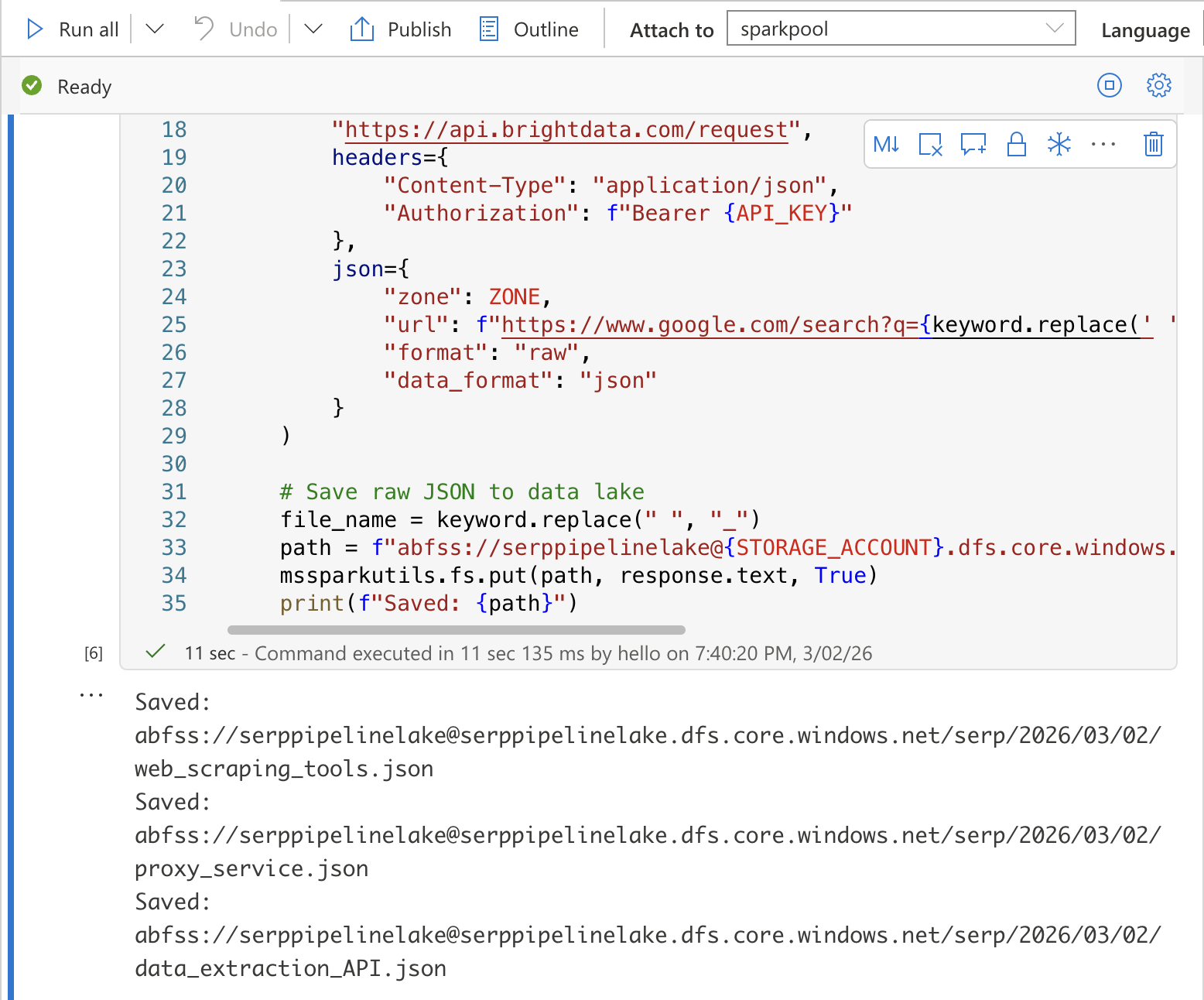
# Speichern Sie die rohen JSON-Daten im Data Lake.
file_name = keyword.replace(" ", "_")
path = f"abfss://raw@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/{file_name}.json"
mssparkutils.fs.put(path, response.text, True)
print(f"Gespeichert: {path}")Ersetzen Sie YOUR_BRIGHT_DATA_API_KEY, YOUR_SERP_API_ZONE und YOUR_STORAGE_ACCOUNT durch Ihre tatsächlichen Werte.
Sicherheitstipp: Speichern Sie Ihren API-Schlüssel in der Produktion in Azure Key Vault und rufen Sie ihn mit
mssparkutils.credentials.getSecret("your-keyvault-name", "BRIGHT_DATA_API_KEY")ab, anstatt ihn fest zu codieren.
Führen Sie die Zelle aus, indem Sie Umschalt + Eingabetaste drücken. Sie sollten eine Ausgabe sehen, die bestätigt, dass jede Datei im Data Lake gespeichert wurde.
Zelle 2: SERP-Daten transformieren und glätten
Fügen Sie in einer neuen Zelle den Transformationscode hinzu, der die rohen JSON-Daten liest und sie in eine strukturierte Tabelle abflacht:
from pyspark.sql.functions import explode, col, current_timestamp
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, ArrayType
# Lesen Sie die rohen SERP-Daten aus dem Data Lake
serp_raw = spark.read.option("multiline", "true").json(
f"abfss://serppipelinelake@{STORAGE_ACCOUNT}.dfs.core.windows.net/serp/{today}/*.json")
# Abflachen: Extrahieren Sie das Schlüsselwort aus general.query und explodieren Sie organische Ergebnisse
serp_flattened = serp_raw.select(
col("general.query").alias("keyword"),
col("general.language").alias("language"),
col("general.location").alias("location"),
explode(col("organic")).alias("result")
).select(
"keyword",
"language",
"location",
col("result.rank").cast("int").alias("rank"),
col("result.title").alias("title"),
col("result.link").alias("url"),
col("result.source").alias("source"),
col("result.description").alias("snippet"),
current_timestamp().alias("collected_at"))
# Vorschau anzeigen
display(serp_flattened)Führen Sie die Zelle aus. Sie sollten eine Vorschau-Tabelle mit den abgeflachten SERP-Ergebnissen sehen, mit Spalten für Keyword, Rang, Titel, URL, Snippet und Erfassungszeitstempel.
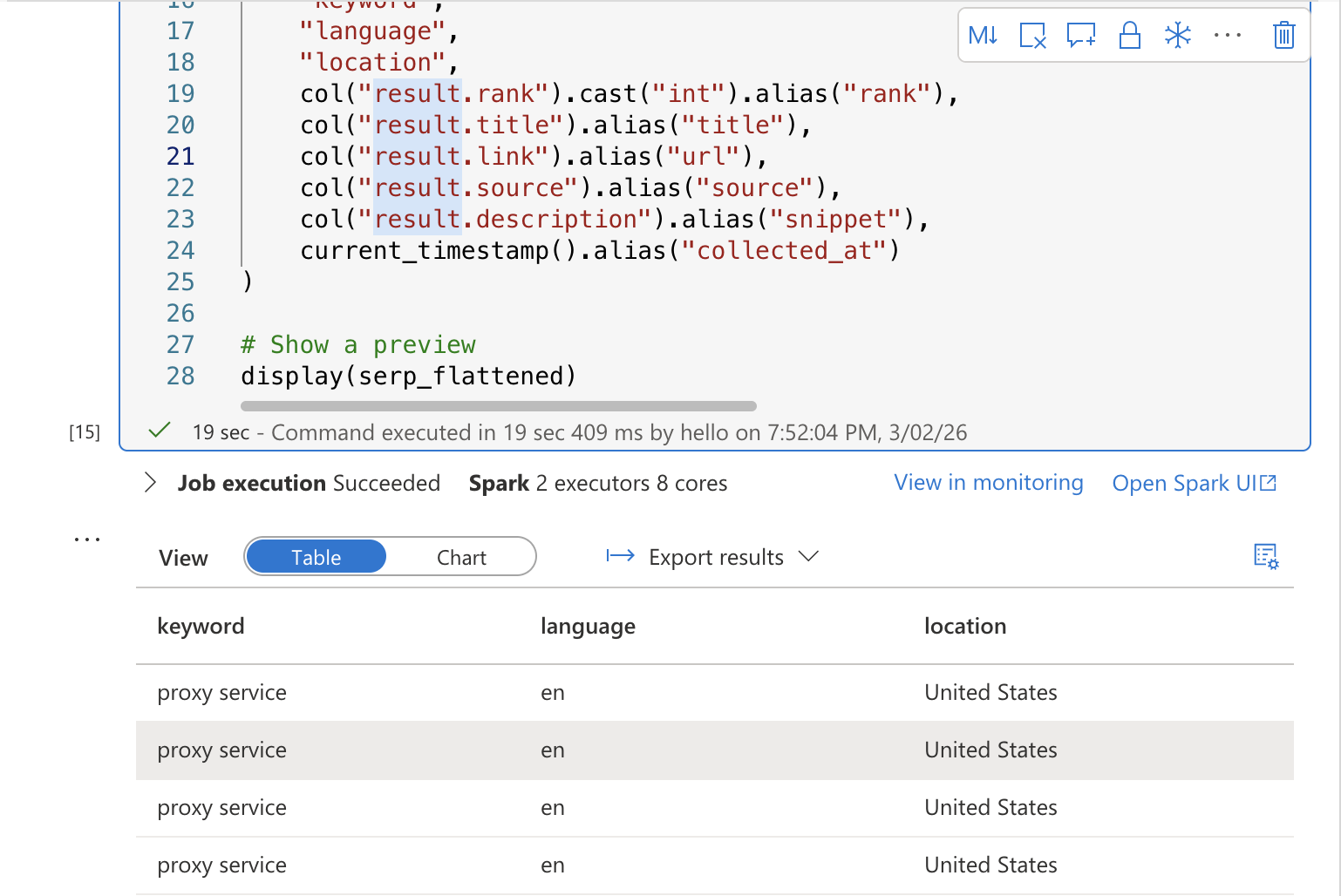
Zelle 3: In einer Delta-Tabelle speichern
Schreiben Sie in einer dritten Zelle die transformierten Daten in eine Delta-Tabelle für SQL-Analysen:
# Transformierte Daten als Delta-Tabelle in Ihren Data Lake schreiben
serp_flattened.write.format("delta").mode("append").save(
f"abfss://[email protected]/curated/serp_rankings"
)
print("Daten in curated/serp_rankings geschrieben") 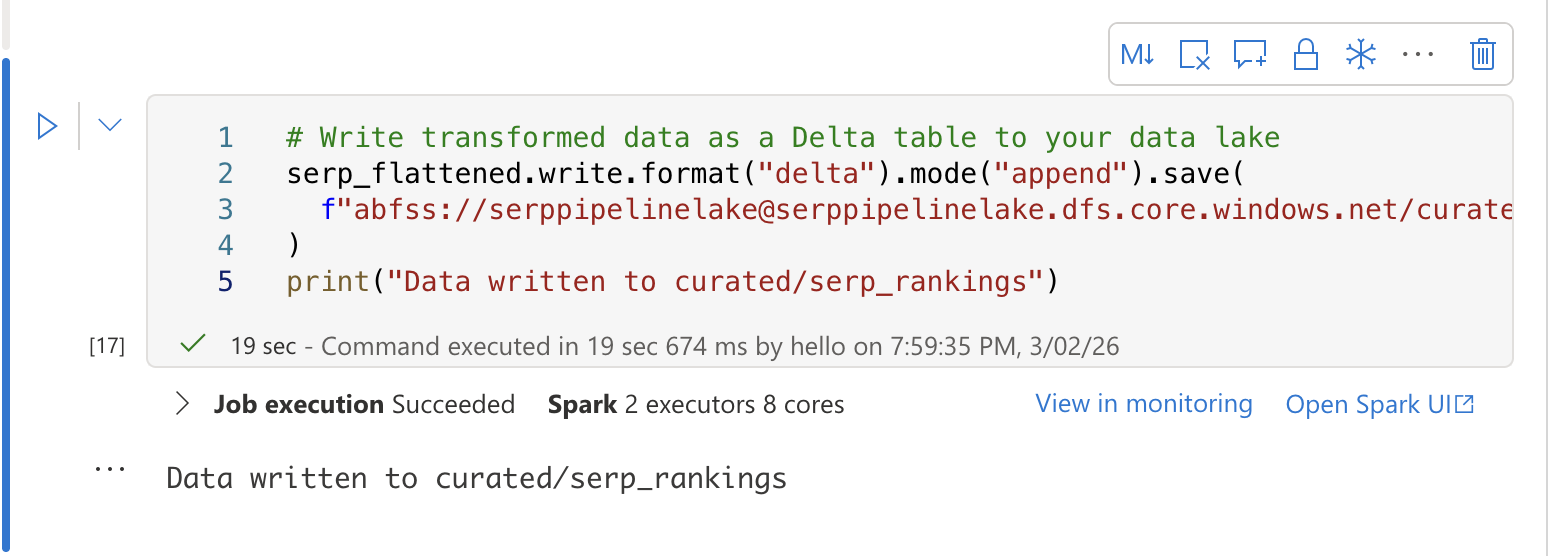
Fügen Sie das Notizbuch zu Ihrer Pipeline hinzu
- Kehren Sie zu Ihrer
IngestSERPData-Pipeline im Integrate Hub zurück. - Ziehen Sie eine Notebook -Aktivität auf die Arbeitsfläche, außerhalb und nach der ForEach-Aktivität.
- Wählen Sie auf der Registerkarte „Einstellungen“ Ihr
TransformSERPData-Notebookaus und fügen Sie es ansparkpoolan. - Verbinden Sie die ForEach-Aktivität mit der Notebook-Aktivität mit einer Success -Abhängigkeit (ziehen Sie den grünen Pfeil).
- Klicken Sie auf „Alle veröffentlichen“, um zu speichern.
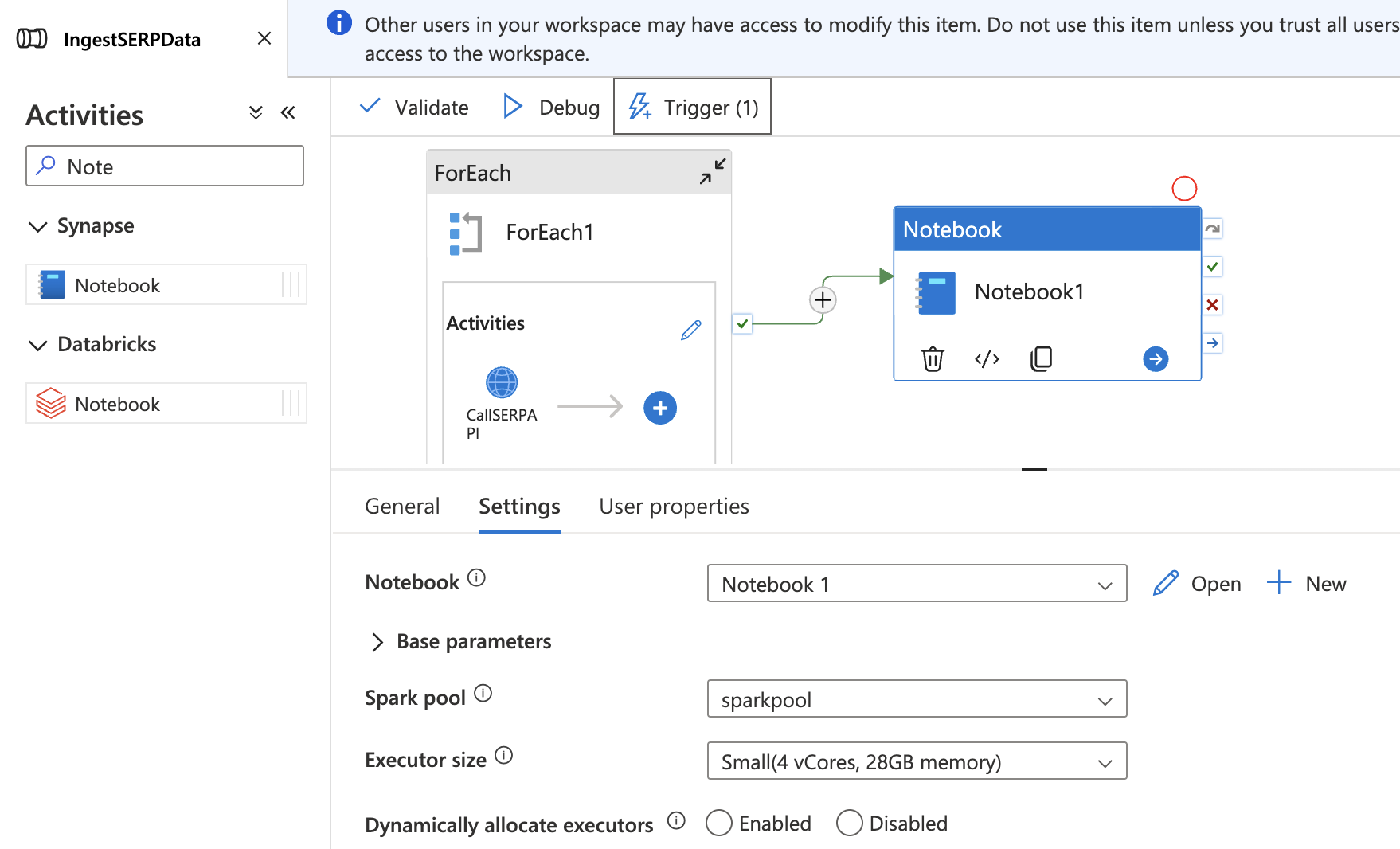
Jetzt läuft die gesamte Pipeline durchgängig: SERP-Daten sammeln → in Data Lake speichern → in eine Delta-Tabelle umwandeln.
Schritt 5: Rankings mit SQL analysieren
Sobald sich Ihre Daten in einer Delta-Tabelle befinden, können Sie sie direkt über den serverlosen SQL-Pool von Synapse abfragen – ohne zusätzliche Bereitstellung. Der serverlose SQL-Pool liest Delta-Dateien mithilfe der OPENROWSET-Funktion direkt aus Ihrem Data Lake.
Erstellen Sie eine Datenbank
Navigieren Sie zu „Entwickeln“ > „+“ > „SQL-Skript“. Stellen Sie sicher, dass „Integriert (serverlos)“ als SQL-Pool oben im Skript-Editor ausgewählt ist. Führen Sie Folgendes aus, um eine dedizierte Datenbank für Ihre SERP-Analysen zu erstellen:
CREATE DATABASE serp_analytics;Nachdem die Datenbank erstellt wurde, wechseln Sie zu ihr, indem Sie serp_analytics aus der Datenbank-Dropdown-Liste oben im Skript-Editor auswählen.
Verfolgen Sie Ranking-Änderungen im Zeitverlauf
Erstellen Sie ein neues SQL-Skript (oder löschen Sie das vorherige) und führen Sie die folgende Abfrage aus. Diese liest die Delta-Tabelle mithilfe von OPENROWSET direkt aus Ihrem Data Lake:
-- Sehen Sie, wie sich die Rankings für jedes Keyword und jede URL von Tag zu Tag verändern
SELECT
keyword,
url,
rank,
collected_at,
rank - LAG(rank) OVER (PARTITION BY keyword, url ORDER BY collected_at) AS rank_change
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
WHERE keyword = 'Web-Scraping tools'
ORDER BY collected_at DESC, rank ASC;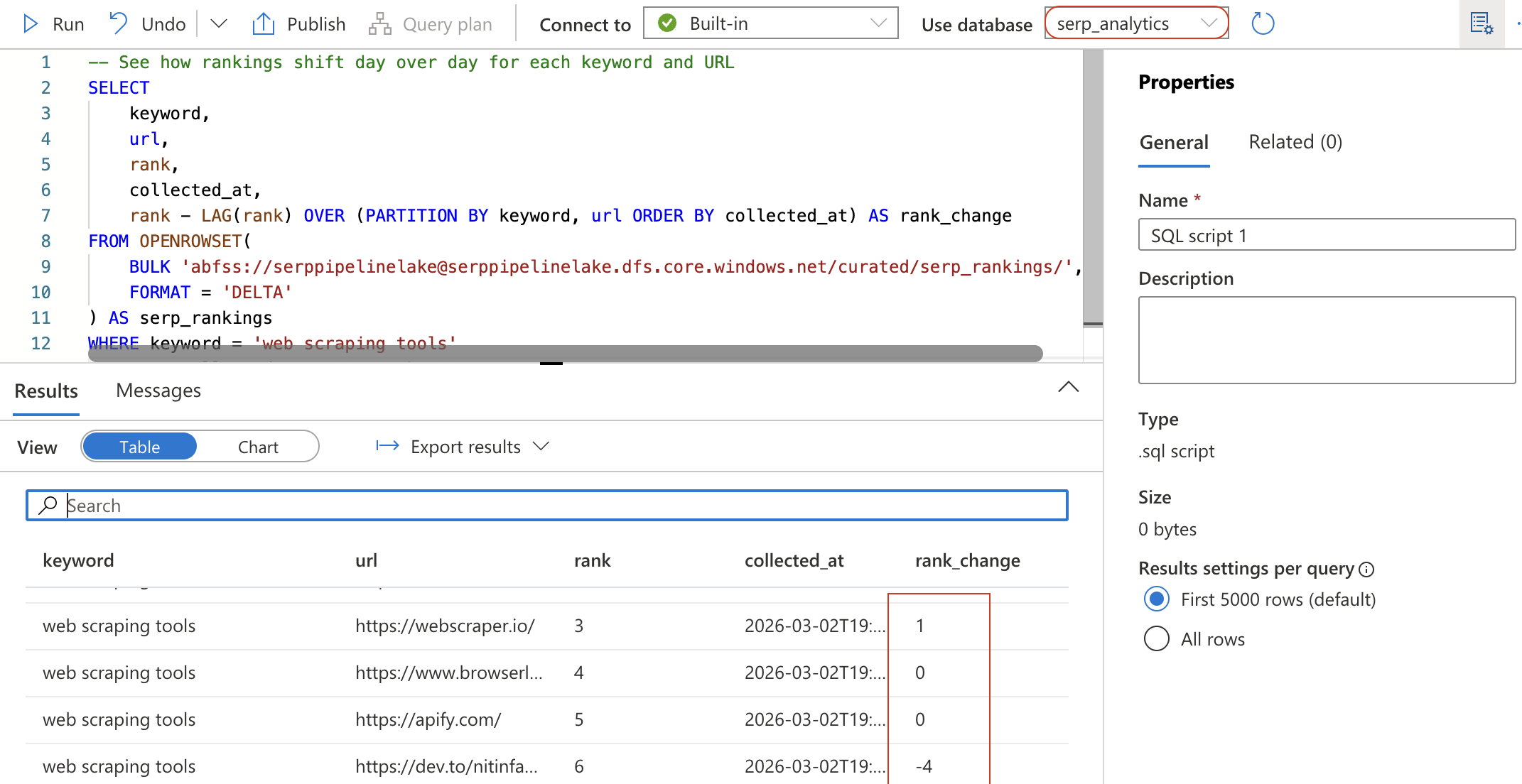
Diese Abfrage verwendet die LAG-Fensterfunktion, um zu berechnen, wie sich die Position jeder URL seit der letzten Erfassung verändert hat. Ein negativer Wert für rank_change bedeutet, dass die URL im Ranking nach oben geklettert ist.
Erstellen Sie eine Zusammenfassungsansicht für Power BI
Um die Daten für Power BI leicht nutzbar zu machen, erstellen Sie eine Ansicht, die die täglichen Rankings pro Keyword zusammenfasst:
CREATE VIEW daily_serp_summary AS
SELECT
keyword,
CAST(collected_at AS DATE) AS report_date,
COUNT(*) AS total_results,
AVG(CAST(rank AS FLOAT)) AS avg_rank,
MIN(rank) AS best_rank
FROM OPENROWSET(
BULK 'abfss://[email protected]/curated/serp_rankings/',
FORMAT = 'DELTA')
AS serp_rankings
GROUP BY keyword, CAST(collected_at AS DATE);Klicken Sie auf „Ausführen“. Dadurch wird eine Ansicht erstellt – eine gespeicherte Abfrage, auf die anhand ihres Namens verwiesen werden kann. Überprüfen Sie die Funktion, indem Sie Folgendes ausführen:
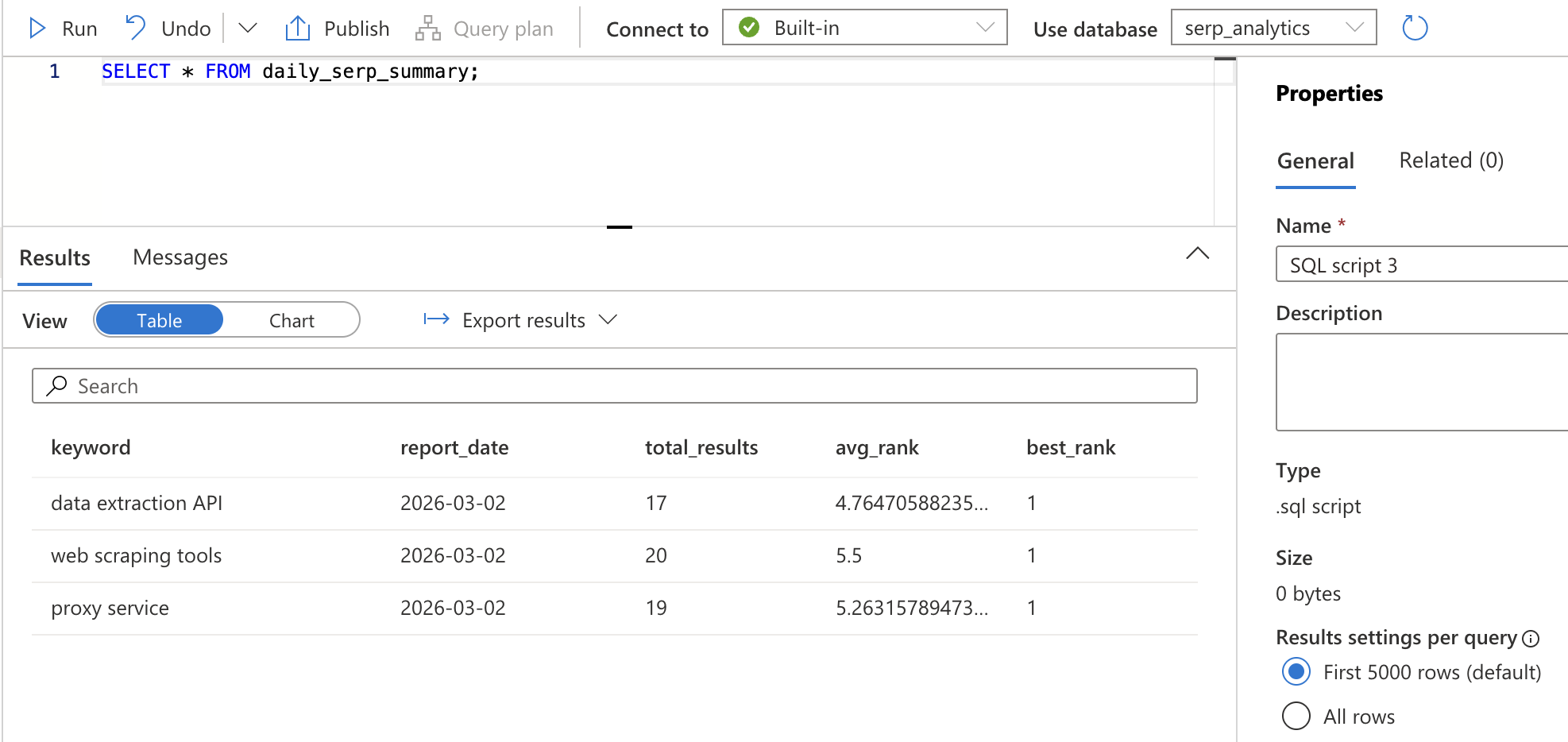
SELECT * FROM daily_serp_summary;Sie sollten pro Keyword und Tag eine Zeile mit der Gesamtzahl der Ergebnisse, dem durchschnittlichen Rang und dem besten Rang sehen.
Schritt 6: Überprüfen Sie die Ergebnisse
Nachdem die gesamte Pipeline ausgeführt wurde, können Sie jede Phase in Synapse Studio überprüfen.
Navigieren Sie zu „Monitor > Pipeline-Ausführungen“ und klicken Sie auf die letzte Ausführung, um sie zu überprüfen. Sie sehen eine visuelle Darstellung jedes Schritts, die Folgendes anzeigt:
- Die ForEach -Aktivität mit jeder Keyword-Iteration und den Ergebnissen der Web-Aktivität.
- Die Notebook -Aktivität mit den Details zur Ausführung des Spark-Jobs.
Erweitern Sie die ForEach-Aktivität, um zu überprüfen, ob die SERP-Daten für jedes Schlüsselwort erfolgreich abgerufen wurden. Klicken Sie auf einen beliebigen CallSERPAPI-Webaktivitätslauf, um die Details der Anfrage/Antwort in den Abschnitten „Input“ und „Output“ anzuzeigen.
Navigieren Sie zu „Data > Linked > Ihr Speicherkonto“, um die JSON-Rohdateien im Ordner „raw/serp/“ zu durchsuchen. Sie sollten nach Datum partitionierte Ordner mit einer JSON-Datei pro Schlüsselwort sehen.
Öffnen Sie abschließend den Develop -Hub, gehen Sie zu Ihrem TransformSERPData -Notebook und überprüfen Sie die Delta-Tabelle, indem Sie Folgendes ausführen:
SELECT * FROM curated.serp_rankings ORDER BY collected_at DESC LIMIT 20;Sie sollten strukturierte Zeilen mit Schlüsselwort, Rang, Titel, URL, Snippet und Sammelzeitstempel sehen, also saubere, analysefähige Daten, die aus den rohen SERP-Ergebnissen erstellt wurden. Die SERP-API von Bright Data hat den schwierigen Teil übernommen: das zuverlässige Abrufen von Google-Suchergebnissen in großem Umfang, das Umgehen von Anti-Bot-Maßnahmen und Ratenbegrenzern und die Rückgabe strukturierter Daten, die für Ihre Pipeline bereit sind.
Weiterführende Informationen
Dieses Beispiel zeigt einen Keyword-Ranking-Tracker, aber Sie können Ihre Synapse-Pipeline in viele Richtungen erweitern:
- Ersetzen Sie den SERP-API-Aufruf durch die Web Scraper API von Bright Data, um Produktpreise, Bewertungen oder Stellenanzeigen zu sammeln und Dashboards mit wettbewerbsfähigen Informationen zur Wettbewerbsanalyse zu erstellen.
- Fügen Sie ein zweites Spark-Notebook hinzu, um eine Stimmungsanalyse für SERP-Snippets durchzuführen und jedes Ergebnis hinsichtlich positiver oder negativer Formulierungen zu bewerten.
- Verbinden Sie die kuratierten Delta-Tabellen mit Azure Machine Learning für prädiktive Analysen, wie z. B. die Prognose von Ranking-Änderungen oder die Identifizierung neuer Suchtrends.
- Erstellen Sie eine Hybrid-Cloud-Architektur, in der SERP-Daten in Azure Data Lake landen, während sensible interne Daten vor Ort bleiben, wobei Synapse beide über föderierte Abfragen abfragt.
- Leiten Sie die transformierten Daten an einen Azure AI Foundry -Prompt-Flow für LLM-gestützte Analysen weiter, wobei Sie die Datenverarbeitung von Synapse mit den KI-Fähigkeiten von AI Foundry kombinieren.
- Integrieren Sie Tools wie LangChain oder CrewAI, um agentenbasierte Workflows zu erstellen, die Ihre kuratierten SERP-Daten nutzen.
Die Möglichkeiten sind praktisch unbegrenzt!
Fazit
In diesem Blogbeitrag haben Sie gelernt, wie Sie mit der SERP-API von Bright Data aktuelle Suchergebnisse von Google abrufen und in eine vollständige Datenpipeline in Azure Synapse Analytics integrieren können.
Die hier vorgestellte Pipeline ist ideal für alle, die einen automatisierten Keyword-Ranking-Tracker erstellen möchten, der kontinuierlich SERP-Daten sammelt, diese in analysefähige Tabellen umwandelt und Erkenntnisse über SQL-Abfragen und Power BI-Dashboards liefert. Im Gegensatz zum Azure AI Foundry-Ansatz, der sich ideal für KI-first-Prompt-Engineering und RAG-Workflows eignet, zeichnet sich Azure Synapse Analytics durch die groß angelegte Datenerfassung, -umwandlung und -speicherung für Business Intelligence und Analysen aus.
Um komplexere Datenpipelines zu erstellen, entdecken Sie die vollständige Suite von Web-Scraping-Tools von Bright Data zum Abrufen, Validieren und Transformieren von Live-Webdaten. Für einen tieferen Einblick in die Architekturmuster von Datenpipelines finden Sie die Grundlagen im Bright Data-Blog.
Registrieren Sie sich noch heute für ein kostenloses Bright Data-Konto und probieren Sie unsere KI-fähigen Webdatenlösungen aus!






