
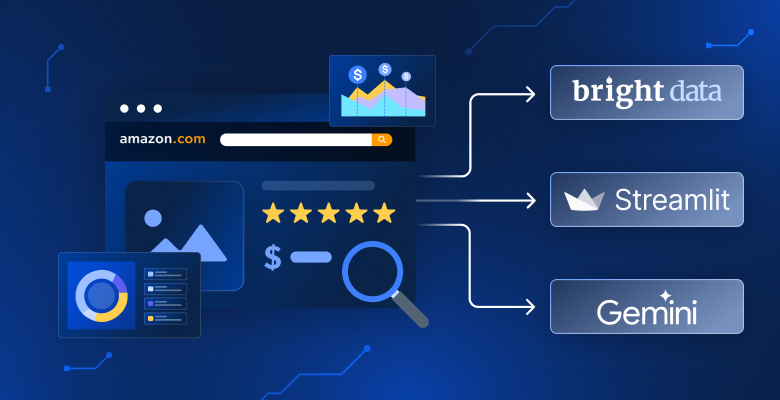
Sind Sie es leid, Produkte auf Amazon manuell zu vergleichen? Möchten Sie KI Fragen zu Ihren Suchergebnissen stellen? Benötigen Sie bessere Einblicke als nur die Sortierung nach Preis oder Bewertung? In diesem Tutorial erstellen Sie einen Amazon-Produktanalysator, der alle 23 Amazon-Marktplätze durchsucht, die Ergebnisse mit KI analysiert und Erkenntnisse über interaktive Dashboards präsentiert.
Was Sie erstellen werden
Am Ende dieses Leitfadens verfügen Sie über eine funktionsfähige Web-App, die Amazon-Produktdaten abruft und diese in einem übersichtlichen Dashboard mit KI-gestützten Einblicken organisiert.
Kernfunktionen und Benutzer-Workflow
So funktioniert es:
- Suche und Datenerfassung. Wählen Sie einen von 23 Amazon-Marktplätzen (Vereinigte Staaten, Deutschland, Japan usw.) aus und geben Sie ein Produkt-Schlüsselwort wie „drahtlose Kopfhörer” ein. Die App verwendet die Web Scraper API von Bright Data, um Produktinformationen zu sammeln.
- Übersichtliche Anzeige der Ergebnisse. Die Daten werden über eine übersichtliche, tabbasierte Oberfläche dargestellt:
- Empfehlungen. Zeigen Sie Produkte an, die nach einem benutzerdefinierten Bewertungsalgorithmus (kombiniert Bewertung, Anzahl der Bewertungen und Rabatte) in drei Kategorien sortiert sind: „Bestes Preis-Leistungs-Verhältnis“, „Höchste Bewertung“ und „Beste Angebote“.
- Marktanalyse. Entdecken Sie interaktive Diagramme, die Preisverteilungen und Bewertungsmuster zeigen, um die Produktlandschaft zu verstehen.
- KI-Assistent. Stellen Sie Fragen in einfachem Englisch, z. B. „Welche Produkte haben die höchsten Bewertungen unter 100 Dollar?”. Die KI analysiert Ihre aktuellen Suchergebnisse und liefert Antworten mit Produktzitaten.
- Produktergebnisse. Durchsuchen, sortieren und exportieren Sie den vollständigen Datensatz zur weiteren Analyse in eine CSV-Datei.
Nachdem wir nun gesehen haben, was die App leistet, wollen wir uns die Technologien ansehen, die dies ermöglichen.
Der Technologie-Stack und die Projektarchitektur
Unsere App verwendet einen modernen, Python-basierten Stack, wobei jede Komponente aufgrund ihrer spezifischen Stärken in den Bereichen Datenverarbeitung, KI und Webentwicklung ausgewählt wurde.
| Komponente | Technologie | Zweck |
|---|---|---|
| Datenquelle | Bright Data Amazon Scraper API | Zuverlässige Amazon-Datenerfassung im Unternehmensmaßstab ohne lästige Proxy-Verwaltung oder CAPTCHA-Lösung. |
| Frontend | Streamlit | Erstellen Sie schnell ein interaktives und ansprechendes Web-Dashboard, indem Sie ausschließlich Python verwenden. |
| KI-Integration | Google Gemini | Einblicke in natürliche Sprache, Datenzusammenfassung und KI-Assistenzfunktionen. |
| Datenverarbeitung | Pandas | Die Grundlage für alle Datenbereinigungen, -transformationen und -analysen. |
| Mathematische Operationen | NumPy | Algorithmen zur Wertbewertung und statistische Berechnungen. |
| Visualisierungen | Plotly | Umfangreiche, interaktive Diagramme und Grafiken, die Benutzer erkunden können. |
| HTTP(S) & Wiederholungsversuche | Anfragen + Beharrlichkeit | Robuste und widerstandsfähige Kommunikation mit externen APIs. |
Projektarchitektur
Das Projekt ist modular aufgebaut, um eine klare Trennung der Aufgabenbereiche zu gewährleisten und die Wartung und Erweiterung des Codes zu vereinfachen.
├── streamlit_app.py # Hauptzugangspunkt der Streamlit-Anwendung
├── requirements.txt # Projektabhängigkeiten
├── .env # API-Schlüssel und Umgebungsvariablen (privat)
└── amazon_analytics/ # Kernmodul der Anwendungslogik
├── __init__.py # Paketinitialisierung
├── api.py # Bright Data API-Integration
├── data_processor.py # Datenbereinigung, Normalisierung und Feature Engineering
├── shopping_intelligence.py # Produktempfehlungs- und Bewertungs-Engine
├── gemini_ai_engine.py # KI-Analyse und Prompt Engineering mit Gemini
├── ai_engine_interface.py # Abstrakte KI-Engine-Schnittstelle
├── ai_response.py # Standardisierte KI-Antwortobjekte
└── config.py # KonfigurationsmanagementNachdem die Architektur nun klar ist, können wir Ihre Entwicklungsumgebung vorbereiten.
Voraussetzungen
Bevor wir mit dem Programmieren beginnen, stellen Sie bitte sicher, dass Sie über Folgendes verfügen:
- Python 3.8+. Wenn Sie es noch nicht installiert haben, laden Sie es von der offiziellen Python-Website herunter.
- Ein Bright Data-Konto. Sie benötigen einen API-Schlüssel, um auf die Amazon Scraper API zugreifen zu können. Melden Sie sich für eine kostenlose Testversion an, um loszulegen und Ihren API-Schlüssel zu generieren.
- Einen Google-API-Schlüssel. Dieser ist für die Verwendung des Gemini-KI-Modells erforderlich. Sie können einen solchen Schlüssel im Google AI Studio generieren.
- Grundkenntnisse. Kenntnisse in Python, Pandas und dem Konzept von Web-APIs sind hilfreich.
Sobald Sie diese Voraussetzungen erfüllen, können wir mit der Einrichtung des Projekts fortfahren.
Schritt 1 – Einrichten Ihrer Entwicklungsumgebung
Zuerst klonen wir das Projekt-Repository, erstellen eine virtuelle Umgebung, um unsere Abhängigkeiten zu isolieren, und installieren die erforderlichen Pakete.
Installation
Öffnen Sie Ihr Terminal und führen Sie die folgenden Befehle aus:
# Klonen Sie das Repository.
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# Erstellen und aktivieren Sie eine virtuelle Umgebung.
python -m venv venv
source venv/bin/activate # Unter Windows verwenden Sie: venvScriptsactivate
# Installieren Sie die erforderlichen Bibliotheken.
pip install -r requirements.txtAPI-Schlüssel-Konfiguration
Erstellen Sie als Nächstes eine .env -Datei im Stammverzeichnis des Projekts, um Ihre API-Schlüssel sicher zu speichern.
# Erstellen Sie die .env-Datei
touch .envÖffnen Sie nun die .env -Datei in einem Texteditor und fügen Sie Ihre Schlüssel hinzu:
BRIGHT_DATA_TOKEN=Ihr_Bright_Data_Token_hier
GOOGLE_API_KEY=Ihr_Google_API_Schlüssel_hierIhre Umgebung ist nun vollständig konfiguriert. Lassen Sie uns nun in die Kernlogik eintauchen, beginnend mit der Datenerfassung.
Schritt 2 – Scraping von Amazon-Produktdaten mit Bright Data
Die Grundlage unserer App sind hochwertige Daten. Das manuelle Scraping einer Website wie Amazon ist komplex – Sie müssen Proxys verwalten, mit unterschiedlichen Seitenlayouts umgehen und Wege finden, um die CAPTCHAs und Blockierungsmechanismen von Amazon zu umgehen.
Die Amazon Web Scraper API von Bright Data macht all diese Komplexität überflüssig. Sie bietet:
- Zuverlässigkeit auf Unternehmensniveau. Basierend auf einem Netzwerk von über 150 Millionen ethisch beschafften Residential-Proxys in 195 Ländern, die einen konsistenten und unterbrechungsfreien Zugriff gewährleisten.
- Keine Infrastrukturprobleme. Automatische IP-Rotation, CAPTCHA-Lösung und Proxy-Verwaltung werden für Sie im Hintergrund übernommen.
- Umfassende strukturierte Daten. Liefert saubere, strukturierte JSON-Daten mit mehr als 20 Datenpunkten pro Produkt, darunter ASIN, Preise, Bewertungen, Rezensionen, Verkäuferinformationen, Produktbeschreibungen, Bilder, Verfügbarkeit und vieles mehr.
- Kostengünstige Preise. Pay-as-you-go-Modell ab 0,001 $ pro Datensatz, wodurch es für Projekte jeder Größe skalierbar ist.
API-Integration (api.py)
Unsere BrightDataAPI-Klasse in api.py übernimmt alle Interaktionen mit der API. Sie verwendet einen Trigger-Poll-Download-Workflow, der sich ideal für potenziell lang andauernde Scraping-Jobs eignet.
Die Methode trigger_search initiiert den Scraping-Auftrag. Beachten Sie die Verwendung des Dekorators @retry aus der Tenacity- Bibliothek – dieser sorgt für mehr Ausfallsicherheit, indem er die Anfrage bei einem Fehlschlag automatisch mit exponentiellem Backoff wiederholt.
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/datensätze/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""Löst einen neuen Scraping-Job aus und gibt die Snapshot-ID zurück."""
payload = [{
"keyword": keyword,
"url": amazon_url,
"pages_to_search": pages_to_search
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]Nach dem Auslösen einer Suche fragt die Methode „wait_for_results“ die API so lange ab, bis der Auftrag abgeschlossen ist, und lädt dann die Daten herunter. Dadurch wird verhindert, dass die App während des Wartens hängen bleibt, und es wird eine Zeitüberschreitung eingebaut, um Endlosschleifen zu vermeiden.
Nachdem eine zuverlässige Datenerfassung eingerichtet ist, besteht der nächste Schritt darin, diese Rohdaten zu bereinigen und anzureichern.
Schritt 3 – Aufbau der Datenverarbeitungs-Pipeline
Rohdaten aus beliebigen Quellen haben selten das perfekte Format für die Analyse. Unsere DataProcessor-Klasse in data_processor.py ist für die Bereinigung, Normalisierung und Entwicklung neuer Funktionen aus den gescrapten Amazon-Daten verantwortlich, sodass diese für unsere KI- und Visualisierungsebenen bereit sind. Einen umfassenderen Überblick über die Datenverarbeitung finden Sie in unserem Leitfaden zur Datenanalyse mit Python.
Intelligentes Parsing von Preisen
Eine große Herausforderung bei E-Commerce-Daten ist der Umgang mit internationalen Formaten. Beispielsweise kann ein Preis in Deutschland „1.234,56” lauten, während er in den USA „1.234,56” lautet. Die Funktion parse_float_locale geht intelligent mit diesen Abweichungen um.
# amazon_analytics/data_processor.py (zur besseren Lesbarkeit vereinfacht)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""Robuster Float-Parser, der internationale Zahlenformate verarbeitet."""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# Dezimalzeichen anhand der letzten Position bestimmen
if s.rfind(',') > s.rfind('.'):
s = s.replace('.', '').replace(',', '.') # Europäisches Format
else:
s = s.replace(',', '') # US-Format
elif has_comma:
# Prüfen, ob Komma Tausender-Trennzeichen oder Dezimaltrennzeichen ist
if re.search(r",d{3}$", s):
s = s.replace(',', '') # Tausender-Trennzeichen
else:
s = s.replace(',', '.') # Dezimaltrennzeichen
return float(s)
return NoneBenutzerdefinierter Wertbewertungsalgorithmus
Um Benutzern zu helfen, schnell die besten Produkte zu finden, haben wir einen benutzerdefinierten Wert-Score erstellt. Diese zusammengesetzte Metrik kombiniert mehrere Faktoren zu einem einzigen, leicht verständlichen Score.
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10)
-> float:
"""Berechnet einen zusammengesetzten Wert-Score basierend auf Qualität, sozialer Bewährtheit und Deal-Wert."""
score = 0.0
# 40 % Gewichtung für Produktqualität (Bewertung)
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# 30 % Gewichtung für soziale Beweise (Anzahl der Bewertungen)
if num_ratings and num_ratings >= min_reviews:
# Logarithmische Skala, um zu verhindern, dass sehr beliebte Artikel dominieren
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# 30 % Gewichtung für den Wert des Angebots (Rabattprozentsatz)
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # Obergrenze bei 50 % Rabatt
score += discount_score * 0.3
return round(score, 2)Dieser Algorithmus gleicht Qualität (Bewertung), soziale Beweise (Anzahl der Bewertungen) und Deal-Wert (Rabatt) aus, um eine ganzheitliche Messung der Attraktivität eines Produkts zu ermöglichen.
Nachdem unsere Daten nun bereinigt und angereichert sind, können wir sie in unsere KI-Engine einspeisen, um tiefere Einblicke zu gewinnen.
Schritt 4 – Integration von KI für intelligente Analysen mit Gemini
Hier wird unsere App wirklich intelligent. Wir verwenden Googles Gemini KI, um die verarbeiteten Daten zu analysieren und Fragen der Nutzer zu beantworten. Eine große Herausforderung bei LLMs ist die Halluzination – das Erfinden von Fakten, die in den Quelldaten nicht vorhanden sind. Unsere GeminiAIEngine wurde entwickelt, um dies zu verhindern.
# amazon_analytics/gemini_ai_engine.py (zur Verdeutlichung des Tutorials erheblich vereinfacht)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""Erstellt eine halluzinationssichere Eingabeaufforderung, indem alle Datenkontexte einbezogen werden."""
# Hinweis: Die tatsächliche Implementierung umfasst detailliertes Feld-Mapping,
# Typkonvertierung und NaN-Behandlung für mehr als 20 Produktattribute.
products_data = []
for _, row in df.iterrows():
product = {
'name': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'final_price': float(row.get('final_price', 0)) if pd.notna(row.get('final_price')) else 0,
'rating': float(row.get('rating', 0)) if pd.notna(row.get('rating')) else 0,
'num_ratings': int(row.get('num_ratings', 0)) if pd.notna(row.get('num_ratings')) else 0,
# ... zusätzliche Felder mit korrekter Typbehandlung
}
products_data.append(product)
return f"""Sie sind ein erfahrener Amazon-Produktanalyst mit fortgeschrittenen Denkfähigkeiten.
REGELN FÜR NULL HALLUZINATIONEN:
1. Erfinden Sie NIEMALS Produktinformationen.
2. Verwenden Sie NUR die unten ausdrücklich angegebenen Daten.
3. Wenn Informationen fehlen, geben Sie deutlich an: „Diese Informationen sind nicht verfügbar“.
4. Geben Sie zur Überprüfung immer die spezifischen ASINs der Produkte an.
5. Nutzen Sie Ihre Argumentationsfähigkeit, um wertvolle Erkenntnisse auf der Grundlage der tatsächlichen Daten zu liefern.
ARGUMENTATIONSFÄHIGKEITEN:
- Vergleichen Sie Produkte, indem Sie Preis, Bewertungen, Rezensionen und Funktionen analysieren.
- Identifizieren Sie Produkte mit dem besten Preis-Leistungs-Verhältnis, indem Sie das Verhältnis zwischen Preis und Bewertung berücksichtigen.
- Bewerten Sie die Vertrauenswürdigkeit eines Produkts, indem Sie die Qualität der Bewertungen und die Anzahl der Rezensionen bewerten.
- Erkennen Sie Schnäppchen, indem Sie den ursprünglichen Preis mit dem Endpreis vergleichen.
BENUTZERANFRAGE: {user_query}
VERFÜGBARE PRODUKTDATEN ({len(df)} Produkte):
{json.dumps(products_data, indent=2)}
Analysieren Sie diese Daten mit Hilfe Ihrer Argumentation und liefern Sie hilfreiche, genaue Erkenntnisse. Geben Sie zur Überprüfung spezifische ASINs und Zahlen an."""Wichtige Techniken zur Vermeidung von Halluzinationen:
- Vollständige Datenerfassung. Alle Produktinformationen werden der KI zur Verfügung gestellt, sodass keine Lücken für Spekulationen bleiben.
- Eindeutige Grenzen. Klare Regeln darüber, was die KI tun kann und was nicht.
- ASIN-Zitate. Zwingt die KI, zur Überprüfung auf bestimmte Produkte zu verweisen.
- Strukturiertes Datenformat. Das JSON-Format macht das Parsing der Daten für die KI zuverlässig.
Dieser Prompt-Engineering-Ansatz verwandelt die KI in einen zuverlässigen Datenanalysten, dessen Ergebnisse vertrauenswürdig und überprüfbar sind.
Nachdem die KI-Engine bereit ist, können wir das Empfehlungssystem aufbauen.
Schritt 5 – Erstellen der Shopping-Intelligence-Engine
Die ShoppingIntelligenceEngine in shopping_intelligence.py verwendet die verarbeiteten Daten, um drei Hauptempfehlungen zu generieren: „Best Overall Value“ (Bester Gesamtwert), „Highest Rated“ (Höchste Bewertung) und „Best Deal“ (Bestes Angebot). Die Engine wendet ausgefeilte Filterkriterien an, um qualitativ hochwertige Empfehlungen zu gewährleisten.
Das System arbeitet mit einer Liste von Produktwörterbüchern und verwendet separate Hilfsmethoden für jede Empfehlungskategorie, die jeweils spezifische Qualitätsschwellenwerte haben.
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Generate shopping intelligence from product data."""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Generieren Sie Top-Produktempfehlungen mit Begründung."""
try:
# Filtern Sie zunächst nur nach gültigen Produkten.
valid_products = []
for product in products:
rating = product.get('rating')
price = product.get('final_price')
if rating is not None and price is not None and rating > 0 and price > 0:
valid_products.append(product)
if not valid_products:
return []
picks = []
used_asins = set()
# Finde jede Kategorie mit speziellen Methoden.
best_value = self._find_best_value(valid_products)
if best_value and best_value.get('asin') not in used_asins:
picks.append({
'product': best_value,
'reason': 'Best Overall Value',
'explanation': 'Excellent balance of quality, price, and customer reviews'
})
used_asins.add(best_value['asin'])
highest_rated = self._find_highest_rated(valid_products)
if highest_rated and highest_rated.get('asin') not in used_asins:
picks.append({
'product': highest_rated,
'reason': 'Höchste Bewertung',
'explanation': 'Höchste Kundenzufriedenheit mit nachweislicher Erfolgsbilanz'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': 'Best Deal',
'explanation': 'Great value with significant savings and good quality'
})
used_asins.add(best_deal['asin'])
# Füllen Sie bei Bedarf die verbleibenden Plätze mit Qualitätsprodukten.
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
for product in remaining_products[:3-len(picks)]:
picks.append({
'product': product,
'reason': 'Quality Choice',
'explanation': 'Good balance of quality and value'
})
return picks[:3]
except Exception:
return []Methoden zur Qualitätsfilterung
Jede Empfehlungskategorie hat bestimmte Qualitätsschwellenwerte, um zuverlässige Empfehlungen zu gewährleisten:
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Produkt mit der besten Wertungsnote finden – erfordert mindestens 10 Bewertungen."""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Finde das Produkt mit der höchsten Bewertung – erfordert eine Bewertung von 4,0+ und 50+ Bewertungen."""
candidates = [p for p in products if
p.get('rating', 0) >= 4.0 and
p.get('num_ratings', 0) >= 50]
if not candidates:
return None
return max(candidates, key=lambda p: (p.get('rating', 0), p.get('num_ratings', 0)))
def _find_best_deal(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Finde das beste Angebot – erfordert einen Rabatt von mindestens 10 % und eine Bewertung von mindestens 3,5."""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))Wichtige Designentscheidungen:
- Qualitätsschwellenwerte. Jede Kategorie hat Mindeststandards, um die Empfehlung minderwertiger Produkte zu verhindern.
- Keine Duplikate. Der Satz
„used_asins”stellt sicher, dass jedes Produkt nur einmal erscheint. - Fallback-Logik. Wenn weniger als 3 Empfehlungen gefunden werden, werden die nächstbesten Werte eingefügt.
- Fehlerbehandlung. Try/catch verhindert Abstürze bei fehlerhaften Daten.
Dieser Ansatz stellt sicher, dass Benutzer zuverlässige, hochwertige Empfehlungen erhalten und nicht nur die ersten gefundenen Produkte.
Jetzt haben wir alle Backend-Komponenten. Lassen Sie uns die Benutzeroberfläche erstellen, um alles zusammenzuführen.
Schritt 6 – Entwerfen des interaktiven Dashboards mit Streamlit
Das letzte Element ist die Benutzeroberfläche, die von streamlit_app.py verwaltet wird. Mit Streamlit können Sie mit minimalem Code ein reaktives, webbasiertes Dashboard erstellen. Die App verwendet ein ausgeklügeltes tabbasiertes Layout mit Echtzeit-Fortschrittsverfolgung und mehreren Diagrammtypen.
Sitzungsstatus und Komponenten-Caching
Die App verwendet spezifische Sitzungsstatusvariablen, um den Datenfluss zu verwalten, und speichert Backend-Komponenten für eine bessere Leistung im Cache:
# streamlit_app.py – Initialisierung des Sitzungsstatus
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""Initialisierung und Zwischenspeicherung von Backend-Komponenten."""
api = BrightDataAPI()
processor = DataProcessor()
intelligence = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processor, intelligence, ai_engineInline-Suchverarbeitung mit Fortschrittsverfolgung
Die Suchlogik ist direkt in den Hauptablauf der App eingebettet und verfügt über eine detaillierte Fortschrittsverfolgung und Datenpersistenz:
# streamlit_app.py – Suchverarbeitung (vereinfacht)
# Suchausführung mit Fortschrittsanzeige
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# Suche auslösen
status_text.text("Amazon-Suche wird gestartet...")
snapshot_id = API.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# Auf Ergebnisse warten mit intelligenten Fortschrittsaktualisierungen
status_text.text("Amazon verarbeitet Ihre Suche...")
results = smart_wait_for_results(API, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# Ergebnisse verarbeiten
status_text.text("Produkte werden analysiert...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# Umfassende Ergebnisse im Sitzungsstatus speichern
st.session_state.search_results = processed_results
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = results
st.session_state.search_metadata = {
'keyword': keyword,
'country': countries[selected_country],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"Found {len(processed_results)} products in {elapsed_time:.1f}s!")
progress_bar.progress(100)
except Exception as e:
st.error(f"Search failed: {str(e)}")Mehrere interaktive Visualisierungen
Die Registerkarte „Marktanalyse” erstellt verschiedene Diagrammtypen inline, jeweils mit spezifischen Stilen und Anmerkungen:
# streamlit_app.py – Preisverteilung mit Medianlinie
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="Preisspanne",
labels={'x': f'Preis ({currencies.get(current_country_code, "USD")})', 'y': 'Anzahl der Produkte'},
color_discrete_sequence=['#667eea']
)
# Medianlinie für Kontext hinzufügen
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="Median")
st.plotly_chart(fig_price, use_container_width=True)
# Streuung von Bewertung und Preis mit Größen- und Farbcodierung
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="Qualität vs. Preis",
labels={'final_price': f'Preis ({currencies.get(current_country_code, "USD")})', 'rating': 'Bewertung (Sterne)'},
color='rating',
color_continuous_scale='Viridis')
st.plotly_chart(fig_scatter, use_container_width=True)
# Verteilung der Wertungsergebnisse mit Prozentmarkierungen
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="Produkte mit bestem Preis-Leistungs-Verhältnis",
labels={'x': 'Wert-Score (0,0-1,0)', 'y': 'Anzahl der Produkte'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="Median")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75. Perzentil")
st.plotly_chart(fig_value, use_container_width=True)Erweiterte Diagrammfunktionen
Das Dashboard enthält anspruchsvolle Visualisierungen mit Business Intelligence:
- Preis-Histogramme. Mit Median- und Quartilsmarkierungen für die Marktpositionierung.
- Bewertungsstreudiagramme. Die Größe steht für das Bewertungsvolumen, die Farbe für die Bewertungsqualität.
- Positions-Kreisdiagramme. Zeigen die Verteilung der Suchrankings (1–5, 6–10, 11–20, 21+).
- Preis-Kategorie-Balkendiagramme. Segmentiert Produkte in die Kategorien Budget/Wert/Premium/Luxus.
- Rabattanalyse. Identifiziert echte Angebote im Gegensatz zu überhöhten Preisen.
Dieser umfassende Ansatz schafft ein professionelles Analyse-Dashboard, das umsetzbare Markteinblicke liefert.
Fazit
Sie haben erfolgreich einen Amazon-Produktanalysator erstellt, der sich auf Datenerfassung auf Unternehmensniveau, fortschrittliche KI und interaktive Datenvisualisierung stützt. Der vollständige Quellcode für dieses Projekt steht Ihnen auf GitHub zur Verfügung, damit Sie ihn erkunden und anpassen können.
Sie haben gelernt, wie Sie:
- die Web Scraper API von Bright Data verwenden, um Amazon-Daten zuverlässig und in großem Umfang zu scrapen.
- eine robuste Datenverarbeitungs-Pipeline implementieren, um komplexe, reale Datenherausforderungen zu bewältigen.
- einen halluzinationssicheren KI-Assistenten mit Google Gemini für vertrauenswürdige Analysen entwickeln
- Erstellen Sie mit Streamlit und Plotly eine intuitive und interaktive Benutzeroberfläche.
Dieses Projekt dient als leistungsstarke Vorlage für jede App, die große Mengen an Webdaten in verwertbare Business Intelligence umwandeln muss. Von hier aus können Sie es erweitern, um einen dedizierten Amazon-Preis-Tracker zu erstellen oder andere Datenquellen zu integrieren.
Die Welt der E-Commerce-Daten ist riesig. Wenn Sie vorab gesammelte, gebrauchsfertige Datensätze benötigen, finden Sie auf dem Marktplatz von Bright Data eine große Auswahl an Optionen.





