

Web-Scraping ist eine programmatische Methode zum Sammeln von Daten aus Websites, und es gibt unzählige Anwendungsfälle für Web-Scraping, darunter Marktforschung, Preisüberwachung, Datenanalyse und Lead-Generierung.
In diesem Tutorial sehen Sie sich einen praktischen Anwendungsfall an, der sich auf eine häufige Herausforderung für Eltern konzentriert: das Sammeln und Organisieren von Informationen, die von der Schule nach Hause geschickt werden. Hier konzentrieren Sie sich auf Hausaufgaben und Informationen zum Schulessen.
Im Folgenden finden Sie ein grobes Architekturdiagramm des endgültigen Projekts:
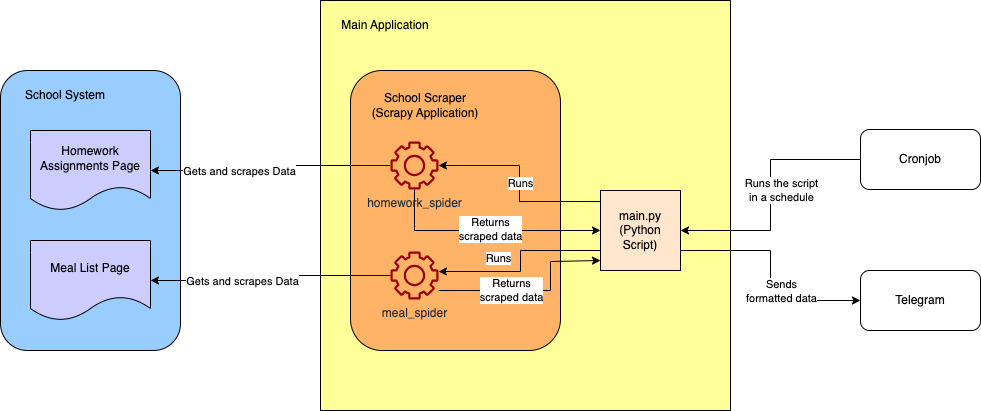
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie Folgendes:
- Python 3.10+
- aktivierte virtuelle Umgebung
- Scrapy CLI 2.11.1
- Visual Studio Code
Aus Datenschutzgründen verwenden Sie diese Dummy-Website eines Schulsystems: https://systemcraftsman.github.io/scrapy-demo/website/.
Erstellen Sie das Projekt
Erstellen Sie in Ihrem Terminal Ihr Basisprojektverzeichnis (Sie können es an einem beliebigen Ort ablegen):
mkdir school-scraper
Navigieren Sie in Ihren neu erstellten Ordner und erstellen Sie ein neues Scrapy-Projekt, indem Sie den folgenden Befehl ausführen:
cd Scraper &
scrapy startproject school_scraper
Die Projektstruktur sollte wie folgt aussehen:
school-scraper
└── school_scraper
├── school_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
Der vorherige Befehl erstellt zwei Ebenen von school_scraper-Verzeichnissen. Im inneren Verzeichnis befindet sich eine Reihe von automatisch generierten Dateien: middlewares.py, in der Sie Scrapy-Middlewares definieren können; pipelines.py, in der Sie benutzerdefinierte Pipelines zur Änderung Ihrer Daten definieren können; und settings.py, in der Sie die allgemeinen Einstellungen für Ihre Scraping-Anwendung definieren können.
Am wichtigsten ist jedoch der Ordner spiders, in dem sich Ihre Spiders befinden. Spiders sind Python-Klassen, mit denen Sie eine bestimmte Website auf eine bestimmte Weise scrapen können. Sie halten sich an das Prinzip der Trennung von Anliegen innerhalb des Scraping-Systems, sodass für jede Scraping-Aufgabe eine eigene Spider erstellt werden kann.
Da Sie noch keinen generierten Spider haben, ist dieser Ordner leer, aber im nächsten Schritt werden Sie Ihren ersten Spider generieren.
Erstellen Sie den Hausaufgaben-Spider
Um Hausaufgabendaten aus einem Schulsystem zu scrapen, müssen Sie einen Spider erstellen, der sich zunächst beim System anmeldet und dann zur Seite mit den Hausaufgaben navigiert, um die Daten zu scrapen:
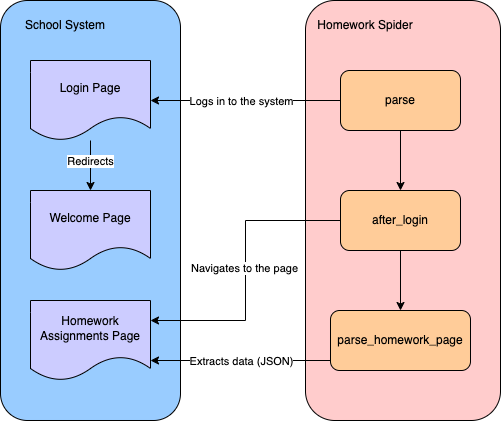
Sie verwenden die Scrapy-CLI, um einen Scraper für das Web-Scraping zu erstellen. Navigieren Sie zum Verzeichnis school-scraper/school_scraper Ihres Projekts und führen Sie den folgenden Befehl aus, um einen Scraper namens HomeworkSpider im Ordner spiders zu erstellen:
scrapy genspider homework_spider systemcraftsman.github.io/scrapy-demo/website/index.html
HINWEIS: Vergessen Sie nicht, alle Python- oder Scrapy-bezogenen Befehle in Ihrer aktivierten virtuellen Umgebung auszuführen.
Der Befehl scrapy genspider generiert den Spider. Der nächste Parameter ist der Name des Spiders (d. h. homework_spider) und der letzte Parameter definiert die Start-URL des Spiders. Auf diese Weise wird systemcraftsman.github.io von Scrapy als zulässige Domain erkannt.
Ihre Ausgabe sollte wie folgt aussehen:
Spider „homework_spider” mit Vorlage „basic” im Modul erstellt:
school_scraper.spiders.homework_spider
Eine Datei namens homework_spider.py muss im Verzeichnis school_scraper/spiders erstellt werden und sollte wie folgt aussehen:
class HomeworkSpiderSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
Benennen Sie die Klasse in „HomeworkSpider” um, um das überflüssige „Spider” im Klassennamen zu entfernen. Die Funktion „parse” ist die erste Funktion, die das Scraping startet. In diesem Fall ist das die Anmeldung im System.
HINWEIS: Das Anmeldeformular auf
https://systemcraftsman.github.io/scrapy-demo/index.htmlist ein Dummy-Anmeldeformular, das aus einigen JavaScript-Zeilen besteht. Da die Seite HTML ist, akzeptiert sie keine POST-Anfragen, stattdessen wird eine HTTP-GET-Anfrage verwendet, um die Anmeldung zu simulieren.
Aktualisieren Sie die parse -Funktion wie folgt:
...Code ausgelassen...
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
Hier erstellen Sie eine Formularanfrage, um das Anmeldeformular innerhalb der Seite index.html zu übermitteln. Das übermittelte Formular sollte zur definierten welcome_page_url weiterleiten und über eine Callback-Funktion verfügen, um den Scraping-Prozess fortzusetzen. Sie werden die Callback-Funktion after_login in Kürze hinzufügen.
Definieren Sie die welcome_page_url, indem Sie sie oben in der Klasse hinzufügen, wo auch andere Variablen definiert sind:
...Code ausgelassen...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
...Code ausgelassen...
Fügen Sie dann die Funktion after_login direkt nach der Funktion parse in der Klasse hinzu:
...Code ausgelassen...
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
...Code ausgelassen...
Die Funktion „after_login” überprüft, ob der Antwortstatus 200 ist, was bedeutet, dass die Anfrage erfolgreich war. Anschließend navigiert sie zur Hausaufgaben-Seite und ruft die Callback-Funktion „parse_homework_page” auf, die Sie im nächsten Schritt definieren werden.
Definieren Sie die homework_page_url, indem Sie sie oben in der Klasse hinzufügen, in der die anderen Variablen definiert sind:
...Code ausgelassen...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
...Code ausgelassen...
Fügen Sie die Funktion parse_homework_page nach der Funktion after_login in der Klasse hinzu:
...Code ausgelassen...
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
...Code ausgelassen...
Die Funktion parse_homework_page überprüft, ob der Antwortstatus 200 (d. h. erfolgreich) ist, und führt dann das Parsing der Hausaufgabendaten durch, die in einer HTML-Tabelle bereitgestellt werden.
Die Funktion überprüft den HTTP-Code 200 und extrahiert dann mit XPath jede Datenzeile. Nach dem Extrahieren jeder Zeile durchläuft die Funktion die Daten und extrahiert die spezifischen Elemente mit der privaten Funktion _get_item, die Sie Ihrer Spider-Klasse hinzufügen müssen.
Die Funktion „_get_item“ sollte wie folgt aussehen:
...Code ausgelassen...
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
Die Funktion _get_item ruft den Inhalt jeder Zelle mithilfe von XPath zusammen mit den Zeilen- und Spaltennummern ab. Wenn eine Zelle mehr als einen Absatz enthält, durchläuft die Funktion diese und hängt jeden Absatz an.
Die Funktion parse_homework_page erfordert außerdem die Definition einer date_str, die Sie als 12.03.2024 definieren sollten, da dies das Datum ist, das Sie in Ihrer statischen Website haben.
HINWEIS: In einem realen Szenario sollten Sie das Datum dynamisch definieren, da die Website-Daten dynamisch sind.
Definieren Sie date_str, indem Sie es oben in der Klasse hinzufügen, wo auch andere Variablen definiert sind:
...Code ausgelassen...
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
...Code ausgelassen...
Die endgültige Datei homework_spider.py sieht wie folgt aus:
import scrapy
from scrapy import FormRequest, Request
class HomeworkSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
Führen Sie in Ihrem Verzeichnis „school-scraper/school_scraper” den folgenden Befehl aus, um zu überprüfen, ob die Hausaufgaben-Daten erfolgreich gescrapt wurden:
scrapy crawl homework_spider
Sie sollten die gescrapten Ergebnisse zwischen den anderen Protokollen sehen:
...Ausgabe ausgelassen...
2024-03-20 01:36:05 [scrapy.core.scraper] DEBUG: Aus <200 https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html> extrahiert
{'MATHS': "Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.n", 'ENGLISH': 'Lesen Sie die Geschichte „Manny and His Monster Manners” auf den Seiten 100–107 in Ihrem Leseprotokoll und führen Sie die Aufgaben auf den Seiten 108 und 109 entsprechend der Geschichte durch.nnLeseprotokoll kitabınızın 100–107 sayfalarındaki „Manny and His Monster Manners“ auf den Seiten 100–107 in Ihrem Lesetagebuch und bearbeiten Sie die Aufgaben auf den Seiten 108 und 109 entsprechend der Geschichte.n'}
2024-03-20 01:36:05 [scrapy.core.engine] INFO: Spider wird geschlossen (abgeschlossen)
...Ausgabe ausgelassen...
Herzlichen Glückwunsch! Sie haben Ihren ersten Spider implementiert. Lassen Sie uns den nächsten erstellen!
Erstellen Sie den Meal List Spider
Um einen Spider zu erstellen, der die Speisekarte-Seite crawlt, führen Sie den folgenden Befehl in Ihrem Verzeichnis school-scraper/school_scraper aus:
scrapy genspider meal_spider systemcraftsman.github.io/scrapy-demo/website/index.html
Die generierte Spider-Klasse sollte wie folgt aussehen:
class MealSpiderSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
Der Erstellungsprozess des Meal-Spiders ist dem der Hausaufgaben-Spiders sehr ähnlich. Der einzige Unterschied besteht in der HTML-Scraping-Seite.
Um Zeit zu sparen, ersetzen Sie den gesamten Inhalt in meal_spider.py durch Folgendes:
import scrapy
from datetime import datetime
from scrapy import FormRequest, Request
class MealSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
meal_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html"
date_str = "13.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.meal_page_url,
callback=self.parse_meal_page
)
def parse_meal_page(self, response):
if response.status == 200:
data = {"BREAKFAST": "", "LUNCH": "", "SALAD/DESSERT": "", "FRUIT TIME": ""}
week_no = datetime.strptime(self.date_str, '%d.%m.%Y').isoweekday()
rows = response.xpath('//*[@class="table table-condensed table-yemek-listesi"]//tr')
key = ""
try:
for row in rows[1:]:
if self._get_item(row, week_no) in data.keys():
key = self._get_item(row, week_no)
else:
data[key] = self._get_item(row, week_no, "n")
finally:
return data
def _get_item(self, row, col_number, seperator=""):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for i, content in enumerate(contents):
item_str = item_str + content + seperator
return item_str
Beachten Sie, dass die Funktionen parse und after_login fast identisch sind. Der einzige Unterschied besteht im Namen der Callback-Funktion parse_meal_page, die den HTML-Code der Mahlzeitseite mit einer anderen XPath-Logik parst. Die Funktion wird außerdem von einer privaten Funktion namens _get_item unterstützt, die ähnlich wie die für Hausaufgaben erstellte Funktion funktioniert.
Die Art und Weise, wie die Tabelle in den Hausaufgaben- und Speisekarten-Seiten verwendet wird, unterscheidet sich, daher unterscheiden sich auch das Parsing und die Verarbeitung der Daten.
Um den meal_spider zu überprüfen, führen Sie den folgenden Befehl in Ihrem Verzeichnis school-scraper/school_scraper aus:
scrapy crawl meal_spider
Ihre Ausgabe sollte wie folgt aussehen:
...Ausgabe ausgelassen...
2024-03-20 02:44:42 [scrapy.core.scraper] DEBUG: Scraped from <200 https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html>
{'BREAKFAST': 'PANCAKE n KREM PEYNİR n SÜZME PEYNİR nnKAKAOLU FINDIK KREMASI n SÜTn', 'LUNCH': 'TARHANA ÇORBAnEKŞİLİ KÖFTEnERİŞTEn', 'SALAD/DESSERT': 'AYRANnKIRMIZILAHANA SALATAnROKALI GÖBEK SALATAn', 'FRUIT TIME': 'FINDIK& KURU ÜZÜMn'}
2024-03-20 02:44:42 [scrapy.core.engine] INFO: Closing spider (finished)
...Ausgabe ausgelassen...
HINWEIS: Da die Daten von einer Original-Website stammen, wurden sie nicht übersetzt, um ihr ursprüngliches Format beizubehalten.
Formatieren der Daten
Die Scraper, die Sie für die Hausaufgaben und die Seite mit den Mahlzeitenlisten erstellt haben, sind bereit, die Daten im JSON-Format zu scrapen. Möglicherweise möchten Sie die Daten jedoch formatieren, indem Sie die Spider programmgesteuert auslösen.
In Python-Anwendungen dient die Datei main.py in der Regel als Einstiegspunkt, an dem Sie Ihre Anwendung durch Aufrufen ihrer Schlüsselkomponenten initialisieren. In diesem Scrapy-Projekt haben Sie jedoch keinen Einstiegspunkt erstellt, da die Scrapy-CLI ein vorgefertigtes Framework für die Implementierung der Spider bereitstellt und Sie die Spider über dieselbe CLI ausführen können.
Um die Daten in diesem Szenario zu formatieren, erstellen Sie ein einfaches Python-Befehlszeilenprogramm, das Argumente entgegennimmt und entsprechend scrapt.
Erstellen Sie eine Datei namens main.py im Stammverzeichnis Ihres school-scraper-Projekts mit folgendem Inhalt:
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from school_scraper.school_scraper.spiders.homework_spider import HomeworkSpider
from school_scraper.school_scraper.spiders.meal_spider import MealSpider
results = []
class ResultsPipeline(object):
def process_item(self, item, spider):
results.append(item)
def _prepare_message(title, data_dict):
if len(data_dict.items()) == 0:
return None
message = f"===={title}====n----------------n"
for key, value in data_dict.items():
message = message + f"==={key}===n{value}n----------------n"
return message
def main(args=None):
if args is None:
args = sys.argv
settings = get_project_settings()
settings.set("ITEM_PIPELINES", {'__main__.ResultsPipeline': 1})
process = CrawlerProcess(settings)
if args[1] == "homework":
process.crawl(HomeworkSpider)
process.start()
print(_prepare_message("HOMEWORK ASSIGNMENTS", results[0]))
elif args[1] == "meal":
process.crawl(MealSpider)
process.start()
print(_prepare_message("MEAL LIST", results[0]))
if __name__ == "__main__":
main()
Die Datei main.py enthält eine Hauptfunktion und ist die Einstiegsfunktion für Ihre Anwendung. Wenn Sie main.py ausführen, wird die Hauptmethode aufgerufen. Die Hauptmethode verwendet ein Array-Argument namens args, mit dem Sie Argumente an das Programm senden können.
Die Datei main.py beginnt mit der Überprüfung des args-Werts und konfiguriert die Scrapy-Crawler-Einstellungen, indem sie eine Pipeline namens ResultsPipeline definiert. Wie Sie sehen können, ist die ResultsPipeline in dieser Datei definiert, aber Sie definieren die Pipelines unter dem Pipelines-Paket.
Die ResultsPipeline ruft einfach die Ergebnisse ab und hängt sie an ein Array namens results an. Das bedeutet, dass das Array results als Eingabe für die private Funktion _prepare_message verwendet werden kann, die zur Vorbereitung der formatierten Nachricht dient. Dies geschieht pro Spider in der Hauptfunktion, und die Unterscheidung wird durch das zweite Argument des Arrays args möglich, das für den Spider-Typ steht. Wenn der Spider-Typ homework ist, ruft der Crawler-Prozess den HomeworkSpider auf und startet ihn. Wenn der Spider-Typ meal ist, ruft der Crawler-Prozess den MealSpider auf und startet ihn.
Wenn ein Spider startet, hängt die injizierte ResultsPipeline die Daten an das Ergebnisse-Array an, und die Hauptfunktion kann sie für jeden Spider verwenden, indem sie _prepare_message aufruft, was bei der Formatierung der Datenausgabe hilft.
Führen Sie in Ihrem Hauptprojektverzeichnis die neu implementierte Datei main.py mit dem folgenden Befehl aus, um die Hausaufgaben abzurufen:
python main.py homework
Ihre Ausgabe sollte wie folgt aussehen:
...Ausgabe ausgelassen...
====HAUSAUFGABEN====
----------------
===MATHE===
Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.
----------------
===ENGLISCH===
Lesen Sie die Geschichte „Manny and His Monster Manners” auf den Seiten 100–107 in Ihrem Lesetagebuch und bearbeiten Sie die Aufgaben auf den Seiten 108 und 109 entsprechend der Geschichte.
Lesetagebuch kitabınızın 100-107 sayfalarındaki „Manny and His Monster Manners” adlı hikayeyi okuyunuz ve 108 ve 109'uncu sayfalarındaki aktiviteleri hikayeye göre tamamlayınız.
----------------
...Ausgabe ausgelassen...
Um die Mahlzeitenliste für den Tag zu erhalten, führen Sie den Python-Be fehl main.py meal aus. Ihre Ausgabe sieht wie folgt aus:
...Ausgabe ausgelassen...
====ESSENSLEISTE====
----------------
===FRÜHSTÜCK===
PANCAKE
KREM PEYNİR
SÜZME PEYNİR
KAKAOLU FINDIK KREMASI
SÜT
----------------
===MITTAGESSEN===
TARHANA ÇORBA
EKŞİLİ KÖFTE
ERİŞTE
----------------
===SALAT/DESSERT===
AYRAN
KIRMIZILAHANA SALATA
ROKALI GÖBEK SALATA
----------------
===OBSTZEIT===
FINDIK& KURU ÜZÜM
----------------
...Ausgabe ausgelassen...
Tipps zur Überwindung häufiger Hindernisse beim Web-Scraping
Herzlichen Glückwunsch! Wenn Sie es bis hierher geschafft haben, haben Sie offiziell einen Scrapy-Scraper erstellt.
Die Erstellung eines Web-Scrapers mit Scrapy ist zwar einfach, aber bei der Implementierung können einige Hindernisse auftreten, wie z. B. CAPTCHAs, IP-Sperren, Sitzungs- oder Cookie-Verwaltung und dynamische Websites. Werfen wir einen Blick auf einige Tipps für den Umgang mit diesen verschiedenen Szenarien:
Dynamische Websites
Dynamische Websites bieten Besuchern unterschiedliche Inhalte, die von Faktoren wie Systemkonfiguration, Standort, Alter und Geschlecht abhängen. So können beispielsweise zwei Personen, die dieselbe dynamische Website besuchen, unterschiedliche, auf sie zugeschnittene Inhalte sehen.
Scrapy kann zwar dynamische Webinhalte scrapen, ist jedoch nicht dafür ausgelegt. Um dynamische Inhalte zu scrapen, müssen Sie Scrapy so einstellen, dass es regelmäßig ausgeführt wird, und die Ergebnisse speichern und vergleichen, um Änderungen auf Webseiten im Laufe der Zeit zu verfolgen.
In bestimmten Fällen können dynamische Inhalte auf Webseiten als statisch behandelt werden, insbesondere wenn diese Seiten nur gelegentlich aktualisiert werden.
CAPTCHAs
Im Allgemeinen sind CAPTCHAs dynamische Bilder mit alphanumerischen Zeichen. Besucher der Seite müssen die übereinstimmenden Werte aus dem CAPTCHA-Bild eingeben, um den Validierungsprozess zu bestehen.
CAPTCHAs werden auf Webseiten verwendet, um sicherzustellen, dass der Besucher der Seite ein Mensch ist (im Gegensatz zu einem Spider oder Bot) und oft auch, um Web-Scraping zu verhindern.
Das hier verwendete Dummy-Schulsystem verwendet kein CAPTCHA-System, aber wenn Sie auf eines stoßen, können Sie eine Scrapy-Middleware erstellen, die das CAPTCHA herunterlädt und es mithilfe einer OCR-Bibliothek in Text umwandelt.
Manipulation von Sitzungen und Cookies
Wenn Sie eine Webseite öffnen, treten Sie in eine Sitzung innerhalb des Systems dieser Seite ein. Diese Sitzung speichert Ihre Anmeldedaten und andere relevante Daten, um Sie im gesamten System zu erkennen.
Ebenso können Sie Informationen über einen Besucher einer Webseite mithilfe eines Cookies verfolgen. Im Gegensatz zu Sitzungsdaten werden Cookies jedoch auf dem Computer des Besuchers und nicht auf dem Server der Website gespeichert, und Benutzer können sie bei Bedarf löschen. Daher können Sie Cookies nicht zum Aufrechterhalten einer Sitzung verwenden, aber Sie können sie für verschiedene unterstützende Aufgaben einsetzen, bei denen Datenverlust nicht kritisch ist.
Es kann Situationen geben, in denen Sie die Sitzung eines Benutzers manipulieren oder dessen Cookies aktualisieren müssen. Scrapy kann beide Situationen bewältigen, entweder durch seine integrierten Funktionen oder durch kompatible Bibliotheken von Drittanbietern.
IP-Sperre
IP-Sperre, auch bekannt als IP-Adressblockierung, ist eine Sicherheitstechnik, bei der eine Website bestimmte eingehende IP-Adressen blockiert. Diese Technik wird in der Regel eingesetzt, um Bots oder Spider daran zu hindern, auf sensible Informationen zuzugreifen, und um sicherzustellen, dass nur menschliche Benutzer auf die Daten zugreifen und diese verarbeiten können. Neben CAPTCHAs nutzen Unternehmen IP-Sperren, um Web-Scraping-Aktivitäten zu verhindern.
In diesem Szenario verwendet das Schulsystem keinen IP-Sperrmechanismus. Hätten sie jedoch einen implementiert, müssten Sie Strategien wie die Verwendung einer dynamischen IP-Adresse oder das Verbergen Ihrer IP-Adresse hinter einer Proxy-Wand anwenden, um weiterhin ihre Website zu scrapen.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie Spiders zum Einloggen und für das Parsing von Tabellen mit XPath in Scrapy erstellen. Außerdem haben Sie gelernt, wie Sie die Spiders programmgesteuert auslösen können, um die Datenkontrolle zu verbessern.
Den vollständigen Code für dieses Tutorial finden Sie in diesem GitHub-Repository.
Für diejenigen, die die Funktionen von Scrapy erweitern und Scraping-Hindernisse überwinden möchten, bietet Bright Data maßgeschneiderte Lösungen für öffentliche Webdaten. Die Integration von Bright Data in Scrapy verbessert die Scraping-Funktionen, die Proxy-Dienste helfen, IP-Sperren zu vermeiden, und Web Unlocker vereinfacht die Handhabung von CAPTCHAs und dynamischen Inhalten, wodurch die Datenerfassung mit Scrapy effizienter wird.
Registrieren Sie sich jetzt und sprechen Sie mit einem unserer Datenexperten über unsere Scraping-Lösungen.





