

In diesem Tutorial lernen Sie Folgendes:
- Warum das Scrapen von Bildern einer Website sinnvoll ist
- Wie man mit Python und Selenium Bilder von einer Website scrapen kann
Dann legen wir mal los!
Warum Bilder von Websites scrapen?
Beim Web-Scraping geht es nicht nur um das Extrahieren von Textdaten. Vielmehr kann damit jede Art von Daten erfasst werden, auch Multimedia-Dateien wie Bilder. Vor allem ist das Scraping von Bildern aus einer Website in verschiedenen Szenarien nützlich. Zu diesen gehören:
- Abrufen von Bildern für das Training von maschinellem Lernen und KI-Modellen: Trainieren Sie anhand von online heruntergeladenen Bildern ein Modell, um dessen Genauigkeit und Effektivität zu verbessern.
- Untersuchung der visuellen Kommunikation der Konkurrenz: Verstehen Sie Trends und Strategien, indem Sie Ihrem Marketingteam Zugriff auf Bilder gewähren, die Ihre Konkurrenten zur Vermittlung von wichtigen Botschaften an ihr Publikum verwenden.
- Automatischer Abruf visuell ansprechender Bilder von Online-Anbietern: Nutzen Sie qualitativ hochwertige Bilder, um auf Ihrer Website und auf sozialen Medienplattformen eine hohe Präsenz zu erzeugen und das Interesse des Publikums zu wecken und zu binden.
Bilder scrappen mit Python: Schritt-für-Schritt-Anleitung
Um Bilder von einer Webseite zu scrapen, führen Sie folgenden Vorgang durch:
- Verbinden Sie sich mit der Zielseite
- Wählen Sie alle relevanten HTML-Knoten für Bilder auf der Seite aus
- Extrahieren Sie die Bild-URLs aus jedem dieser Knoten
- Laden Sie die mit diesen URLs verbundenen Bilddateien herunter.
Eine gute Zielseite für eine solche Aufgabe ist Unsplash, einer der beliebtesten Bildanbieter des Internets. So sieht das Dashboard für das Suchwort „Hintergrund“ für kostenlose Bilder aus:
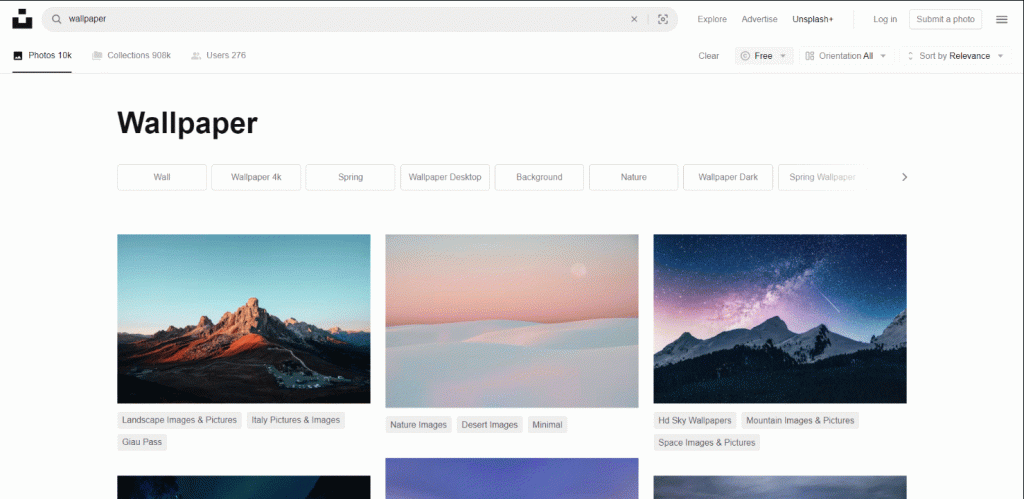
Wie Sie sehen können, lädt die Seite neue Bilder, sobald der Benutzer nach unten scrollt. Anders ausgedrückt: Es handelt sich um eine interaktive Website, die für das Scraping ein Browser-Automatisierungstool erfordert.
Die URL dieser Seite lautet:
https://unsplash.com/s/photos/wallpaper?license=freeSchauen wir uns nun an, wie man mit Python Bilder von dieser Website scrapen kann!
Schritt Nr. 1: Erste Schritte
Um diesem Tutorial folgen zu können, müssen Sie Python 3 auf Ihrem Rechner installiert haben. Ist dies nicht der Fall, laden Sie das Installationsprogramm herunter, doppelklicken Sie darauf und befolgen Sie die Anweisungen.
Initialisieren Sie Ihr Python-Projekt zum Scrapen von Bildern mit den nachstehenden Befehlen:
mkdir image-scraper
cd image-scraper
python -m venv envDadurch wird ein image-scraper-Ordner angelegt und innerhalb desselben eine virtuelle Python-Umgebung eingefügt.
Öffnen Sie den Projektordner in einer Python-IDE Ihrer Wahl. PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung reichen völlig aus.
Erstellen Sie eine Datei scraper.py im Projektordner und initialisieren Sie diese wie folgt:
print('Hello, World!')Derzeit ist diese Datei ein einfaches Skript, das „Hallo, Welt!“ ausgibt, aber sie wird bald die Logik für das Scrapen von Bildern enthalten.
Prüfen Sie die Funktionsfähigkeit des Skripts, indem Sie auf die Schaltfläche „Ausführen“ in Ihrer IDE klicken oder den unten stehenden Befehl ausführen:
python scraper.pyIn Ihrem Terminal sollte nun die folgende Meldung erscheinen:
Hello, World!Großartig! Sie haben ein Python-Projekt erstellt. Implementieren Sie in den nächsten Schritten die Logik, die zum Scrapen von Bildern aus einer Website erforderlich ist.
Schritt Nr. 2: Installieren Sie Selenium
Selenium ist eine hervorragende Bibliothek zum Scrapen von Bildern, da sie sowohl Websites mit statischen als auch mit dynamischen Inhalten verarbeiten kann. Als Browser-Automatisierungstool kann es Seiten selbst dann rendern, wenn sie die Ausführung von JavaScript erfordern. Erfahren Sie mehr in unserem Leitfaden zu Selenium Web-Scraping.
Im Gegensatz zu einem HTML-Parser wie BeautifoulSoup kann Selenium mehr Websites erfassen und somit mehr Anwendungsbereiche abdecken. So funktioniert es beispielsweise auch mit Bildanbietern, die auf Benutzerinteraktionen angewiesen sind, um neue Bilder zu laden. Genau das gilt für Unsplash, die Zielsite dieses Leitfadens.
Ehe Sie Selenium installieren, müssen Sie die virtuelle Python-Umgebung aktivieren. Unter Windows führen Sie hierfür diesen Befehl aus:
envScriptsactivateFühren Sie unter macOS und Linux stattdessen folgenden Befehl aus:
source env/bin/activateInstallieren Sie im env-Terminal das Selenium WebDriver-Paket mit folgendem pip-Befehl:
pip install seleniumDer Installationsvorgang wird eine Weile in Anspruch nehmen, haben Sie also etwas Geduld.
Fantastisch! Nun haben Sie alles, was Sie zum Scrapen von Bildern in Python benötigen.
Schritt Nr. 3: Stellen Sie eine Verbindung zur Zielseite her,
importieren Sie Selenium und die zur Steuerung einer Chrome-Instanz erforderlichen Klassen, indem Sie die folgenden Zeilen in scraper.py einfügen
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import OptionsMit diesem Code können Sie nun eine Headless-Chrome-WebDriver-Instanz initialisieren:
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless") # comment while developing
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)Kommentieren Sie die Option --headless, wenn Sie möchten, dass Selenium ein Chrome-Fenster mit der GUI öffnet. Auf diese Weise können Sie in Echtzeit verfolgen, was das Skript auf der Seite leistet, was für die Fehlersuche äußerst nützlich ist. Lassen Sie in der Produktion die Option --headless aktiviert, um Ressourcen zu sparen.
Vergessen Sie nicht, das Browserfenster zu schließen, indem Sie folgende Zeile am Ende Ihres Skripts einfügen:
# close the browser and free up its resources
driver.quit() Auf manchen Seiten werden Bilder in Abhängigkeit von der Bildschirmgröße des Geräts des Benutzers auf unterschiedliche Weise dargestellt. Zur Vermeidung von Problemen mit responsiven Inhalten vergrößern Sie das Chrome-Fenster mit:
driver.maximize_window()Sie können Chrome jetzt anweisen, sich über Selenium mit der Zielseite zu verbinden, indem Sie die get()-Methode verwenden:
url = "https://unsplash.com/s/photos/wallpaper?license=free"
driver.get(url)Fügen Sie alles zusammen und Sie erhalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# close the browser and free up its resources
driver.quit()Starten Sie das Skript zum Scraping von Bildern im Headed-Modus. Daraufhin wird die folgende Seite für den Bruchteil eines Bereichs angezeigt, bevor Chrome geschlossen wird:
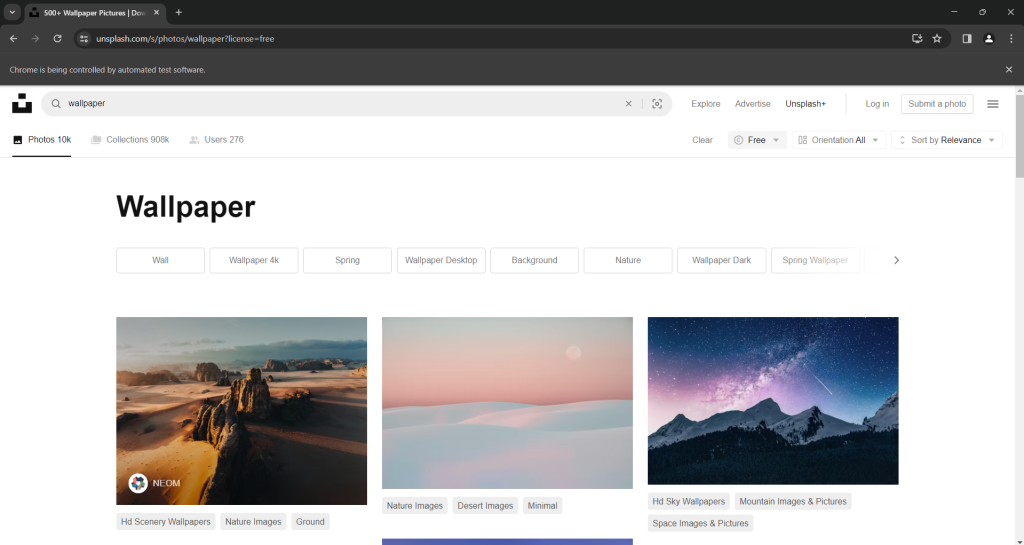
Die Meldung „Chrome wird von automatisierter Testsoftware gesteuert“ bedeutet, dass Selenium wie vorgesehen im Chrome-Fenster ausgeführt wird.
Ausgezeichnet! Schauen Sie sich den HTML-Code der Seite an, um zu erfahren, wie man Bilder daraus extrahiert.
Schritt Nr. 4: Inspizieren der Zielseite
Bevor Sie sich mit der Python-Logik für das Scrapen von Bildern befassen, müssen Sie den HTML-Quellcode Ihrer Zielseite untersuchen. Nur so verstehen Sie, wie man eine effektive Knotenauswahllogik festlegt und die gewünschten Daten extrahieren kann.
Besuchen Sie also die Zielseite in Ihrem Browser, klicken Sie mit der rechten Maustaste auf ein Bild und wählen Sie die Option „Inspizieren“, um die DevTools zu öffnen:
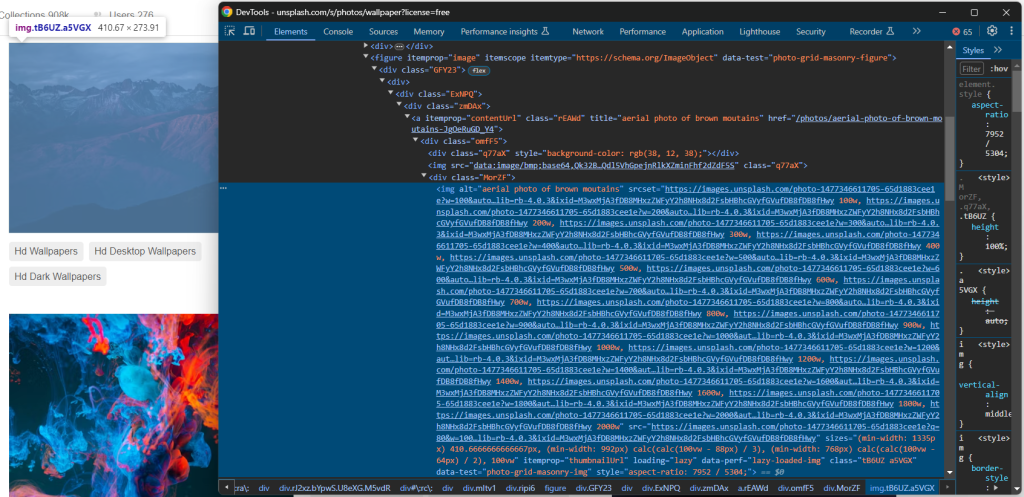
An dieser Stelle sind einige interessante Fakten zu erkennen.
Erstens: Das Bild ist in einem
[data-test="photo-grid-masonry-img"]Zweitens verfügen die Bildelemente sowohl über das traditionelle src-Attribut als auch über das srcset-Attribut. Sollten Sie mit dem letztgenannten Attribut nicht vertraut sein, gibt srcset mehrere Quellbilder zusammen mit Hinweisen an, die dem Browser bei der Auswahl des richtigen Bildes anhand von responsiven Haltepunkten helfen.
Konkret hat der Wert eines srcset- Attributs folgendes Format:
<image_source_1_url> <image_source_1_size>, <image_source_1_url> <image_source_2_size>, ...Wo:
200 W) oder Pixelverhältnisse (z. B.1,5).
Dieses Szenario eines Bildes mit beiden Attributen ist auf modernen responsiven Websites ziemlich häufig. Eine direkte Ausrichtung auf die Bild-URL in src ist nicht unbedingt der beste Ansatz, da srcset URLs zu Bildern mit höherer Qualität enthalten kann.
Aus dem obigen HTML können Sie zudem ersehen, dass alle Bild-URLs absolut sind. Folglich müssen Sie die Basis-URL der Website nicht mit ihnen verketten.
Im nächsten Schritt lernen Sie, mithilfe von Selenium die richtigen Bilder in Python zu extrahieren.
Schritt Nr. 5: Abruf aller Bild-URLs
Wählen Sie mit der Methode findElements() alle gewünschten HTML-Bildknoten auf der Seite aus:
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]") Damit diese Anweisung ausgeführt werden kann, ist folgender Import erforderlich:
from selenium.webdriver.common.by import ByAls Nächstes initialisieren Sie eine Liste, welche die aus den Bildelementen extrahierten URLs enthält:
image_urls = []Iterieren Sie über die Knoten in image_html_nodes, erfassen Sie die URL in src oder die URL des größten Bildes aus srcset (falls vorhanden) und fügen Sie diese zu image_urls hinzu:
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continueBedenken Sie, dass Unsplash eine recht dynamische Website ist und dass einige Bilder bei Ausführung dieser Schleife eventuell nicht mehr auf der Seite sind. Schützen Sie sich vor diesem Fehler und fangen Sie die StaleElementReferenceException ab.
Auch hier sollten Sie nicht vergessen, diesen Import hinzuzufügen:
from selenium.common.exceptions import StaleElementReferenceExceptionSie können jetzt die URLs der gescrapten Bilder ausgeben, und zwar mit:
print(image_urls)Die aktuelle DDie aktuelle Datei scraper.py sollte Folgendes enthalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# log in the terminal the scraped data
print(image_urls)
# close the browser and free up its resources
driver.quit()Führen Sie das Skript aus, um Bilder zu scrapen, wobei Sie eine mit der folgenden vergleichbaren Ausgabe erhalten:
[
'https://images.unsplash.com/photo-1707343843598-39755549ac9a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDF8MHxzZWFyY2h8MXx8d2FsbHBhcGVyfGVufDB8fDB8fHwy',
# omitted for brevity...
'https://images.unsplash.com/photo-1507090960745-b32f65d3113a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxzZWFyY2h8MjB8fHdhbGxwYXBlcnxlbnwwfHwwfHx8Mg%3D%3D'
]Also los geht’s! Das obige Array enthält die URLs der abzurufenden Bilder. Bleibt nur noch zu sehen, wie man Bilder in Python herunterlädt.
Schritt Nr. 6: Herunterladen der Bilder
Der einfachste Weg, ein Bild in Python herunterzuladen, ist die Verwendung der Methode urlretrieve() aus dem Paket url.request der Standardbibliothek. Diese Funktion kopiert ein durch eine URL angegebenes Netzwerkobjekt in eine lokale Datei.
Importieren Sie url.request , indem Sie die folgende Zeile am Anfang Ihrer scraper.py- Datei einfügen:
import urllib.requestErstellen Sie im Projektordner ein Bilderverzeichnis:
mkdir imagesIn dieses Verzeichnis schreibt das Skript die Bilddateien ein.
Iterieren Sie nun die Liste mit den URLs der gescrapten Bilder. Erzeugen Sie für jedes Bild einen inkrementellen Dateinamen und laden Sie das Bild mit urlretrieve() herunter:
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1Das ist alles, was Sie zum Herunterladen von Bildern in Python benötigen. Die print()- Anweisungen sind zwar nicht erforderlich, aber dennoch zum Verständnis der Funktionsweise des Skripts von Vorteil.
Beeindruckend! Sie haben gerade gelernt, wie man in Python Bilder von einer Website abruft. Es ist an der Zeit, sich den vollständigen Code des Python-Skripts scrape images anzusehen.
Schritt Nr. 7: Das Ganze zusammensetzen
Hier der Code der endgültigen scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
import urllib.request
# to run Chrome in headless mode
options = Options()
options.add_argument("--headless")
# initialize a Chrome WerbDriver instance
# with the specified options
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# to avoid issues with responsive content
driver.maximize_window()
# the URL of the target page
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# visit the target page in the controlled browser
driver.get(url)
# select the node images on the page
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# where to store the scraped image url
image_urls = []
# extract the URLs from each image
for image_html_node in image_html_nodes:
try:
# use the URL in the "src" as the default behavior
image_url = image_html_node.get_attribute("src")
# extract the URL of the largest image from "srcset",
# if this attribute exists
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# get the last element from the "srcset" value
srcset_last_element = srcset.split(", ")[-1]
# get the first element of the value,
# which is the image URL
image_url = srcset_last_element.split(" ")[0]
# add the image URL to the list
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# to keep track of the images saved to disk
image_name_counter = 1
# download each image and add it
# to the "/images" local folder
for image_url in image_urls:
print(f"downloading image no. {image_name_counter} ...")
file_name = f"./images/{image_name_counter}.jpg"
# download the image
urllib.request.urlretrieve(image_url, file_name)
print(f"images downloaded successfully to "{file_name}"n")
# increment the image counter
image_name_counter += 1
# close the browser and free up its resources
driver.quit()Großartig! Mit weniger als 100 Zeilen Code lässt sich ein automatisiertes Skript zum Herunterladen von Bildern von einer Website in Python erstellen.
Führen Sie es mit folgendem Befehl aus:
python scraper.pyDas Python-Skript zum Scrapen von Bildern protokolliert die folgende Zeichenkette:
downloading image no. 1 ...
images downloaded successfully to "./images/1.jpg"
# omitted for brevity...
downloading image no. 20 ...
images downloaded successfully to "./images/20.jpg"Öffnen Sie den /Bilderordner und Sie werden die vom Skript automatisch heruntergeladenen Bilder finden:
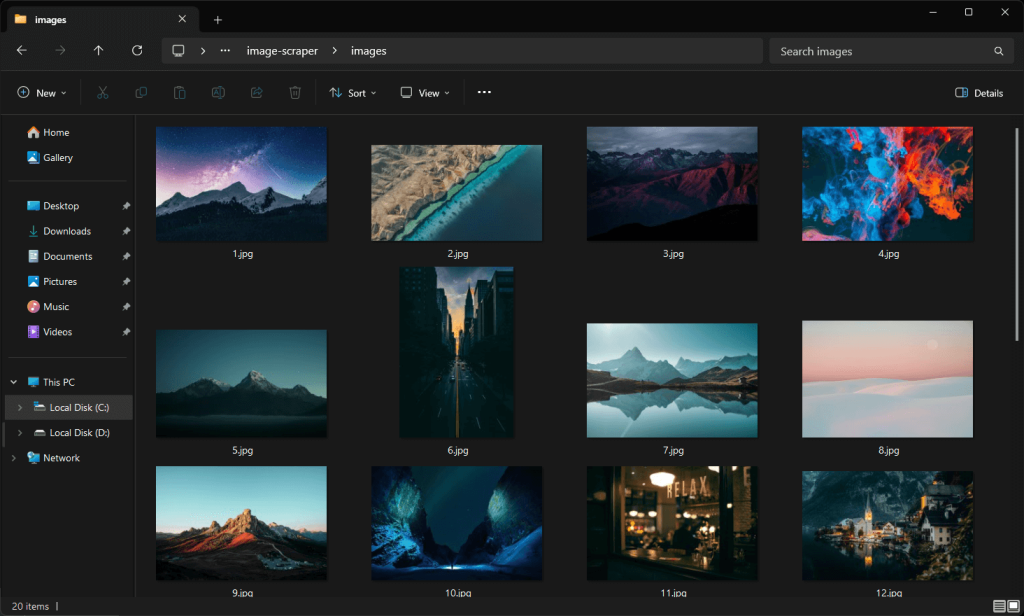
Beachten Sie, dass sich diese Bilder von denen auf dem Screenshot der Unsplash-Seite von eben unterscheiden, da die Website ständig aktualisierte Inhalte empfängt.
Und voilà! Mission erfüllt.
Schritt Nr. 8: Weitere Schritte
Obwohl wir das Ziel bereits erreicht haben, gibt es einige mögliche Implementierungen zur Verbesserung Ihres Python-Skripts. Zu den wichtigsten zählen:
- Export von Bild-URLs nach CSV oder Speicherung der Bilder in einer Datenbank: Auf diese Weise können Sie sie in der Folgezeit herunterladen oder verwenden.
- Vermeidung des Herunterladens von bereits im
/Bilderordnerbefindlichen Bildern: Durch diese Verbesserung werden Netzwerkressourcen geschont, da bereits heruntergeladene Bilder übersprungen werden. - Scrappen auch der Metadaten-Informationen: Das Abrufen von Tags und Autoreninformationen kann hilfreich sein, um vollständige Informationen über heruntergeladene Bilder zu erhalten. Lernen Sie, wie das funktioniert, in unserem Leitfaden zum Web-Scraping mit Python.
- Mehr Bilder scrapen: Simulieren Sie die Interaktion des endlosen Scrollens, laden Sie mehr Bilder und laden Sie sie allesamt herunter.
Fazit
In diesem Leitfaden haben Sie gelernt, warum es sinnvoll ist, Bilder von einer Website zu scrapen und wie man das in Python durchführt. Außerdem haben Sie eine Schritt-für-Schritt-Anleitung zur Erstellung eines Python-Skripts zum Scrapen von Bildern gesehen, mit dem Sie automatisch Bilder von einer Website herunterladen können. Wie hier bewiesen, ist es nicht komplex und benötigt nur wenige Codezeilen.
Dabei müssen Sie die Anti-Bot-Systeme nicht übersehen. Selenium ist zwar ein ausgezeichnetes Tool, aber gegen solch fortschrittliche Technologien kann es nichts ausrichten. Diese können Ihr Skript als Bot identifizieren und den Zugriff auf die Bilder der Website verhindern.
Um diese Situation zu vermeiden, benötigen Sie ein Tool, das JavaScript rendern kann und zudem in der Lage ist, Fingerprinting, CAPTCHAs und Anti-Scraping für Sie auszuführen. Und genau das leistet der Scraping-Browser von Bright Data!
Sprechen Sie mit einem unserer Datenexperten über unsere Scraping-Lösungen.
FAQ
Ist es legal, Bilder von einer Website zu scrapen?
Das Scraping von Bildern einer Website ist an sich keine illegale Aktivität. Es ist jedoch wichtig, nur öffentliche Bilder herunterzuladen, die robots.txt- Datei für Scrapingzu respektieren und die Allgemeinen Geschäftsbedingungen der Website einzuhalten. Viele Menschen glauben, dass Web-Scraping nicht legal ist, doch das ist ein Mythos. Erfahren Sie mehr in unserem Artikel über die Mythen über Web-Scraping.
Welche Bibliotheken sind am besten, um Bilder mit Python herunterzuladen?
Bei statischen Inhalten reichen ein HTTP-Client wie requests und ein HTML-Parser wie beautifulsoup4 aus. Für Websites mit dynamischen Inhalten oder hochgradig interaktiven Seiten sind Sie auf ein Browser-Automatisierungstool wie Selenium oder Playwright angewiesen. Sehen Sie sich die Liste der besten Headless-Browser-Tools für Web-Scraping an.
Wie kann man den „HTTP-Fehler 403: Forbidden“ in urllib.request beheben?
Der HTTP-Fehler 403 wird ausgelöst, weil die Zielseite die mit urllib.request gestellte Anfrage als die eines automatisierten Skripts identifiziert. Dieses Problem lässt sich wirksam vermeiden, indem Sie den User-Agent- Header auf einen realen Wert setzen. Wenn Sie die Methode urlretrieve() verwenden, können Sie dies folgendermaßen tun:
opener = urllib.request.build_opener()
user_agent_string = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
opener.addheaders = [("User-Agent", user_agent_header)]
urllib.request.install_opener(opener)
# urllib.request.urlretrieve(...)





