

Der definitive Leitfaden zum Rust-Web-Scraping
In diesem Leitfaden erfahren Sie:
- Ob Rust eine gute Sprache für Web-Scraping ist.
- Was die besten Rust-Web-Scraping-Bibliotheken sind.
- Wie man einen Web-Scraper in Rust erstellt
- Wie Sie Ihre Scraping-Aktivitäten ethisch und respektvoll gestalten.
Lassen Sie uns loslegen!
Ist Rust eine gute Sprache für Web-Scraping?
Rust ist eine statisch typisierte Programmiersprache, die für ihren Fokus auf Sicherheit, Leistung und Parallelität bekannt ist. In den letzten Jahren hat sie aufgrund ihrer hohen Effizienz an Popularität gewonnen. Das macht sie zu einer ausgezeichneten Wahl für eine Vielzahl von Anwendungen, darunter auch Web-Scraping.
Rust bietet wertvolle Funktionen für Online-Datenscraping-Projekte. Insbesondere sein robustes Parallelitätsmodell erleichtert die gleichzeitige Ausführung mehrerer Webanfragen. Diese Eigenschaft macht es zu einer vielseitigen Sprache, die sich für die effiziente Extraktion großer Datenmengen aus verschiedenen Websites eignet.
Darüber hinaus umfasst das Rust-Ökosystem HTTP-Client- und HTML-Parsing-Bibliotheken, um die Prozesse des Abrufens von Webseiten und der Datenextraktion zu optimieren. Sehen wir uns einige der besten an!
Die besten Rust-Web-Scraping-Bibliotheken
Zu den beliebtesten und am weitesten verbreiteten Rust-Web-Scraping-Bibliotheken gehören:
- reqwest: Ein leistungsstarker HTTP-Client für Rust, der nahtlose Webanfragen und Interaktionen ermöglicht.
- Scraper: Eine flexible HTML-Parsing-Bibliothek in Rust, die die effiziente Extraktion von Daten aus HTML-Dokumenten ermöglicht.
- rust-headless-chrome: Bietet eine headless Chrome-Browser-Automatisierung mit Rust und damit eine robuste Lösung für dynamisches Web-Scraping.
- thirtyfour: Rust-Bindings für Selenium, die automatisierte Tests und Web-Scraping durch Interaktion mit Webbrowsern ermöglichen.
Voraussetzungen
Befolgen Sie die nachstehenden Anweisungen und machen Sie sich bereit, Rust-Code zu schreiben.
Einrichten der Umgebung
Bevor Sie beginnen, müssen Sie Rust auf Ihrem Computer installiert haben. Um zu überprüfen, ob Sie es bereits haben, öffnen Sie das Terminal und geben Sie den folgenden Befehl ein:
rustc --versionWenn das Ergebnis dem unten stehenden ähnelt, können Sie loslegen:
rustc 1.75.0 (82e1608df 2023-12-21)Aktualisieren Sie Rust auf die neueste Version mit:
rustup updateWenn dieser Befehl stattdessen einen Fehler zurückgibt, müssen Sie Rust installieren. Laden Sie das Installationsprogramm von der offiziellen Website herunter, starten Sie es und folgen Sie den Anweisungen des Assistenten. Dadurch wird Folgendes eingerichtet:
- rustup: Ein Installationsprogramm und Versionsmanager für die Programmiersprache Rust, der die einfache Installation und Verwaltung verschiedener Toolchains ermöglicht.
- cargo: Der offizielle Paketmanager und das Build-Tool für Rust. Es optimiert den Prozess der Verwaltung von Abhängigkeiten und der Erstellung von Rust-Projekten.
Schließen Sie alle geöffneten Terminalfenster und wiederholen Sie den Befehl am Anfang dieses Abschnitts. Dieses Mal erhalten Sie das gewünschte Ergebnis.
Großartig! Sie haben Rust nun installiert!
Erstellen Sie ein Rust-Projekt
Angenommen, Sie möchten ein neues Rust-Projekt namens simple_rust_web_scraper erstellen. Öffnen Sie das Terminal und führen Sie den folgenden Befehl cargo new aus:
cargo new simple_rust_web_scraperWenn alles wie vorgesehen funktioniert, erhalten Sie die folgende Meldung:
Binärdatei (Anwendung) „simple_rust_web_scraper“ erstelltDieser Befehl erstellt einen Ordner namens „simple_rust_web_scraper”. Öffnen Sie ihn und beachten Sie, dass er Folgendes enthält:
- Cargo.toml: Die Manifestdatei, in der die Abhängigkeiten des Projekts angegeben werden.
- src/: Der Ordner, in dem Sie Ihre Rust-Dateien ablegen. Standardmäßig wird eine Beispiel-Datei main.rs für Sie initialisiert.
Öffnen Sie simple_rust_web_scraper in Ihrer Rust-IDE. Visual Studio Code mit der Rust-Erweiterung ist beispielsweise ideal dafür geeignet:
Navigieren Sie in den Ordner src/, öffnen Sie die Datei main.rs und Sie sehen folgende Zeilen:
fn main() {
println!("Hello, world!");
}Das ist nichts weiter als ein einfaches Rust-Skript, das „Hello, world!” im Terminal ausgibt. Insbesondere stellt die Funktion main() den Einstiegspunkt jeder Rust-Anwendung dar und ist der Ort, an dem Sie die Scraping-Logik schreiben werden.
Fantastisch! Jetzt müssen Sie nur noch überprüfen, ob Ihr neues Rust-Projekt funktioniert!
Öffnen Sie das Terminal Ihrer IDE und führen Sie diesen Befehl aus, um Ihre Rust-Anwendung zu kompilieren:
cargo buildIm Stammverzeichnis Ihres Projekts wird ein Ordner „target/“ mit einigen Binärdateien angezeigt.
Führen Sie die kompilierte binäre ausführbare Datei, die mit Ihrem Code verknüpft ist, mit folgendem Befehl aus:
cargo runIm Terminal sollte nun Folgendes angezeigt werden:
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `targetdebugsimple_rust_web_scraper.exe`
Hello, world!Die ersten beiden Zeilen sind nur Protokollinformationen, die Sie ignorieren können. Konzentrieren Sie sich auf die letzte Zeile und sehen Sie, dass das Projekt wie erwartet die Meldung „Hello, World!” ausgegeben hat.
Perfekt! Sie haben nun ein Rust-Projekt. Es ist an der Zeit, eine Rust-Web-Scraping-Logik zu schreiben!
So erstellen Sie einen Web-Scraper in Rust
In diesem Schritt-für-Schritt-Tutorial lernen Sie, wie Sie mit Rust Web-Scraping durchführen. Im Einzelnen erstellen Sie einen Rust-Scraper, der automatisch Daten aus der Sandbox „Scrape This Site Country“ sammelt. So sieht die Zielseite aus:
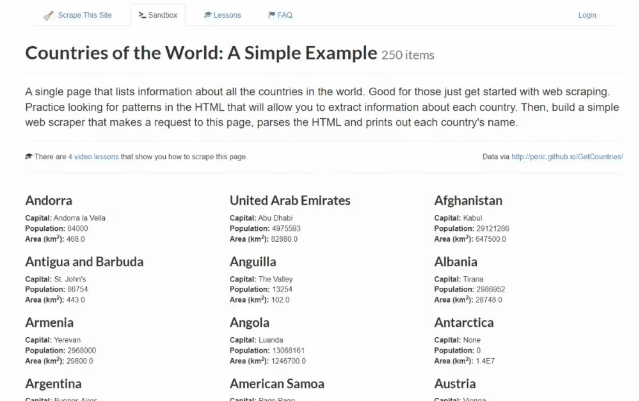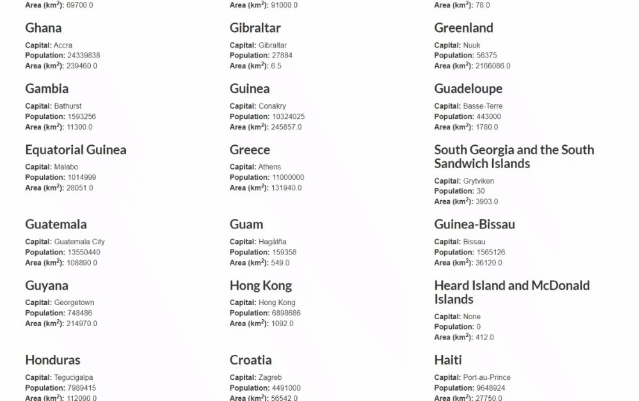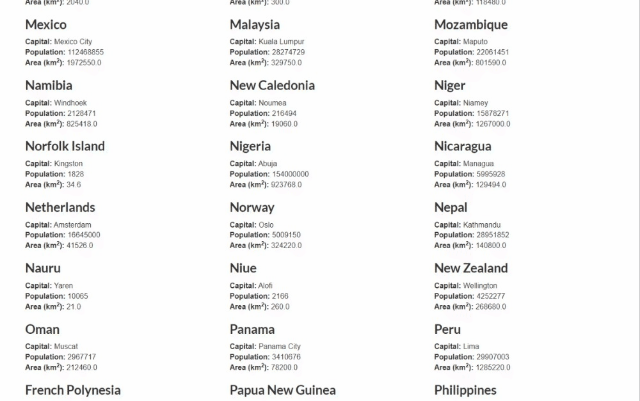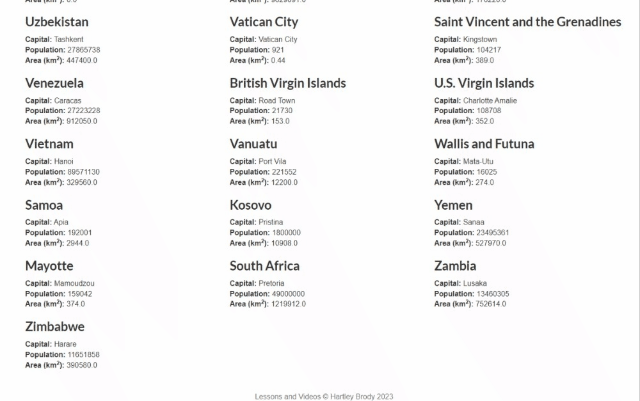
Wie Sie sehen können, enthält sie eine Liste aller Länder der Welt und einige interessante Informationen über sie.
Das Rust-Web-Scraping-Skript führt folgende Schritte aus:
- Verbindung zur Zielseite herstellen und deren HTML-Code parsen.
- Es wählt die HTML-Elemente der Länder aus der Seite aus.
- Es extrahiert Daten aus diesen Elementen und speichert sie in einer Rust-Datenstruktur.
- Die gesammelten Daten in ein für Menschen lesbares Format wie CSV umwandeln.
Befolgen Sie die folgenden Schritte und erreichen Sie Ihr Scraping-Ziel!
Schritt 1: Überprüfen Sie die Zielseite
Sie müssen einige Bibliotheken installieren, um Web-Scraping in Rust durchzuführen, aber welche sind für Ihr spezifisches Szenario am besten geeignet? Um dies zu beantworten, müssen Sie herausfinden, ob die Zielwebsite statische oder dynamische Inhaltsseiten hat. Besuchen Sie daher die Website in Ihrem Browser.
Navigieren Sie zur Zielseite, klicken Sie mit der rechten Maustaste auf einen leeren Bereich und wählen Sie die Option „Untersuchen“, um die DevTools zu öffnen. Gehen Sie zur Registerkarte „Netzwerk“ und laden Sie die Seite neu. Konzentrieren Sie sich auf den Abschnitt „Fetch/XHR“:
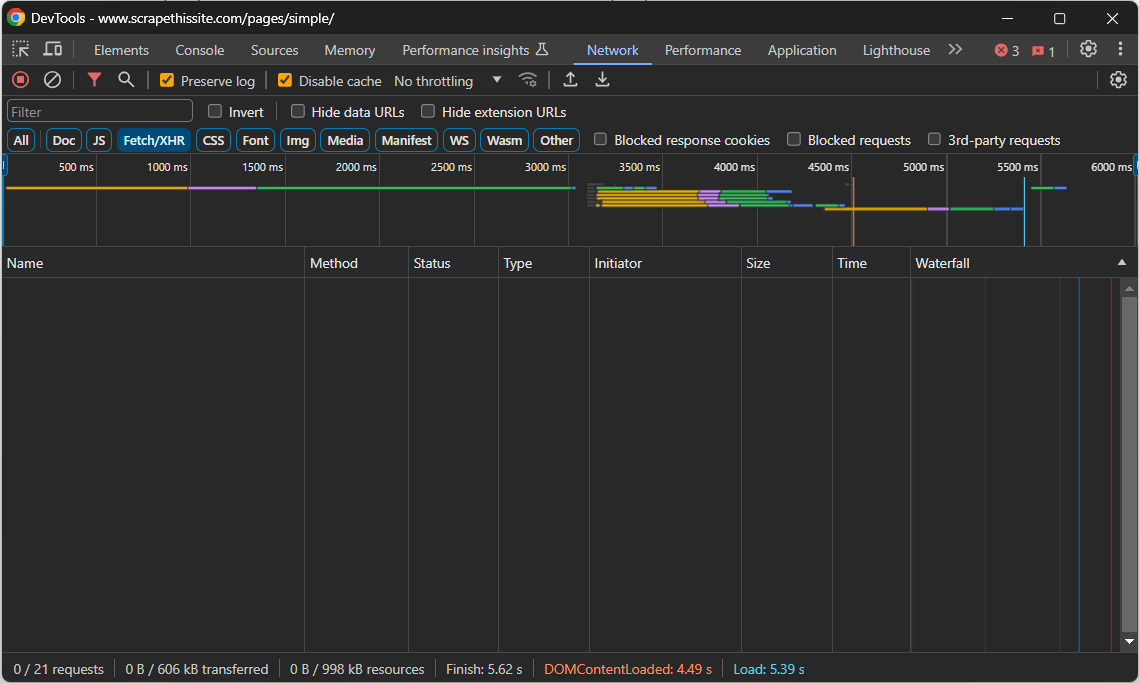
Während die Seite geladen und gerendert wird, bleibt dieser Abschnitt leer. Das bedeutet, dass die Webseite keine AJAX-Anfragen stellt. Mit anderen Worten: Sie ruft keine Daten dynamisch über JavaScript auf dem Client ab. Es handelt sich also um eine statische Inhaltsseite, deren HTML-Dokument bereits alle relevanten Daten enthält.
Zur weiteren Bestätigung klicken Sie mit der rechten Maustaste und wählen Sie die Option „Seitenquelle anzeigen“:
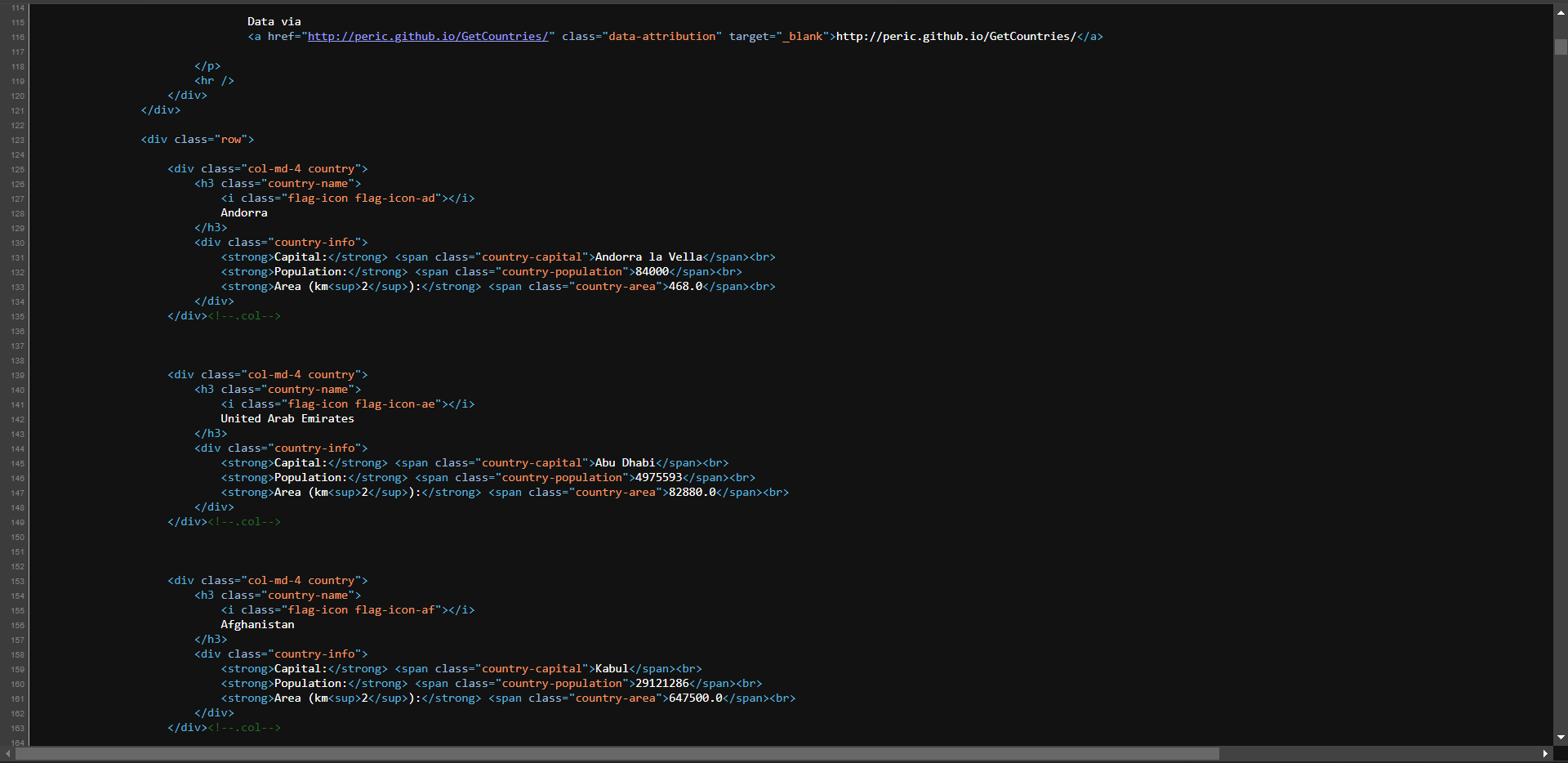
Sehen Sie sich den Code an und Sie werden feststellen, dass alle Daten der Seite in den vom Server zurückgegebenen HTML-Code eingebettet sind.
Wiederholen Sie diesen Vorgang auf einer Website mit mehreren Seiten auf allen Seiten, die Sie interessieren.
Da die Zielseiten kein JavaScript verwenden, benötigen Sie keine Browser-Automatisierungsbibliothek wie rust-headless-chrome. Sie könnten diese zwar trotzdem verwenden, aber die Ausführung von Chrome kostet Zeit und Ressourcen, sodass dies nur zu einem Leistungsaufwand führen würde, ohne einen wirklichen Nutzen zu haben.
Stattdessen sollten Sie eine HTTP-Client-Bibliothek verwenden, um das mit einer Seite verbundene HTML-Dokument abzurufen, und eine HTML-Parser-Bibliothek, um Daten daraus zu extrahieren. Daher sind reqwest und scraper die beiden Rust-Web-Scraping-Bibliotheken, die Sie benötigen!
Schritt 2: Installieren Sie die Scraping-Bibliotheken
Jetzt ist es an der Zeit, reqwest und Scraper zu installieren.
Öffnen Sie ein Terminal im Stammordner Ihres Projekts oder verwenden Sie das Terminal Ihrer IDE. Führen Sie den folgenden Befehl aus, um reqwest und Scraper zu den Abhängigkeiten Ihres Projekts hinzuzufügen:
cargo add Scraper reqwest --features "reqwest/blocking"Hinweis: Die Funktion reqwest/blocking ermöglicht es reqwest, synchrone HTTP-Aufrufe durchzuführen, die den aktuellen Thread blockieren. Weitere Informationen finden Sie in der Dokumentation.
Der Befehl cargo add aktualisiert die Datei Cargo.toml entsprechend und stellt sicher, dass sie Folgendes enthält:
[dependencies]
reqwest = { version = "0.11.23", features = ["blocking"] }
Scraper = "0.18.1"
Außerdem werden die beiden Bibliotheken und alle ihre Abhängigkeiten installiert.
Perfekt! Jetzt haben Sie alles, was Sie für das Web-Scraping mit Rust benötigen!
Schritt 3: Verbindung zur Zielseite herstellen
Verwenden Sie die Methode „get()“ aus „reqwest::blocking“, um eine GET-Anfrage an die angegebene URL zu senden und das zugehörige HTML-Dokument herunterzuladen:
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;Beachten Sie, dass diese Anweisung synchron ist, sodass die Ausführung des Skripts unterbrochen wird, bis der Server antwortet.
Sobald Sie eine Antwort erhalten haben, können Sie mit folgendem Befehl auf den HTML-Code der Zielseite zugreifen:
let html = response.text()?;Schreiben Sie diese beiden Zeilen in die Funktion main() von min.rs:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Verbindung zur Zielseite herstellen
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extrahiere den rohen HTML-Code und drucke ihn aus
let html = response.text()?;
println!("{html}");
Ok(())
}Wenn Sie sich fragen, was Result<(), Box<dyn std::error::Error>> ist, weil wir Residuals verwenden werden. Sehen Sie sich auch die Funktion println() am Ende an, die den abgerufenen HTML-Code protokolliert.
Führen Sie das Skript aus, und es wird im Terminal ausgegeben:
<!doctype html>
<HTML lang="en">
<HEAD>
<META charset="utf-8">
<TITLE>Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learning Web-Scraping</TITLE>
<!-- omitted for brevity... -->Gut gemacht! Das ist genau der HTML-Code der Zielseite!
Schritt 4: Parsing des HTML-Dokuments
Sie haben nun den HTML-Quellcode der gewünschten Seite in einer String-Variablen gespeichert. Übergeben Sie ihn an die Funktion parse_document() von Scraper, um ihn zu analysieren:
let document = Scraper::Html::parse_document(&html);Das zurückgegebene Dokumentobjekt stellt die DOM-Exploration-API bereit, die Sie für das Web-Scraping mit Rust benötigen.
So sollte Ihre Datei main.rs bis jetzt aussehen:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Verbindung zur Zielseite herstellen
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// Roh-HTML extrahieren und ausgeben
let html = response.text()?;
// HTML-Dokument parsen
let document = Scraper::Html::parse_document(&html);
Ok(())
}Sie sind nun bereit, die Logik für das Parsing der Daten zu schreiben. Aber zuerst müssen Sie die Struktur der Zielseite studieren!
Schritt 5: Untersuchen Sie die Seite
Beim Web-Scraping werden HTML-Knoten auf einer Seite ausgewählt und Daten daraus extrahiert. CSS-Selektoren gehören zu den beliebtesten Methoden zur Auswahl von HTML-Knoten. Wenn Sie Webentwickler sind, sind Sie wahrscheinlich bereits mit ihnen vertraut. Wenn nicht, lesen Sie die Dokumentation.
Die einzige Möglichkeit, effektive CSS-Selektoren zu definieren, besteht darin, den HTML-Code der Zielseite zu überprüfen. Öffnen Sie daher die Sandbox „Scrape This Site Country“ im Browser, klicken Sie mit der rechten Maustaste auf ein Länderelement und wählen Sie „Inspect:“
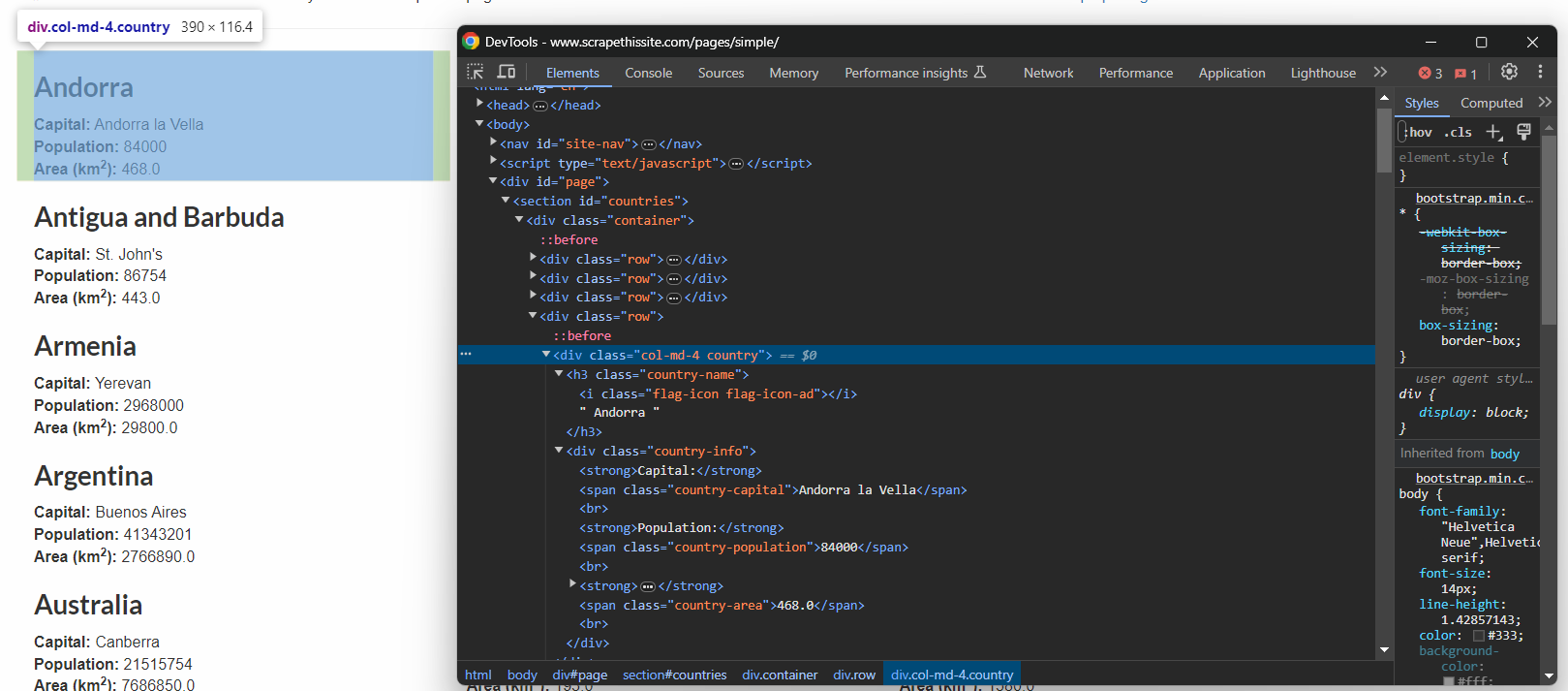
Dort sehen Sie, dass jedes Länder-Infofeld ein .country-HTML-Knoten ist, der Folgendes enthält:
- Den Namen des Landes in einem .country-name-Element.
- Den Namen der Hauptstadt in einem .country-capital-Element.
- Die Bevölkerungsdaten in einem .country-population-Element.
- Die Fläche des Landes in km² im Element .country-area.
Im obigen Absatz finden Sie alle CSS-Selektoren, die zum Auswählen der gewünschten HTML-Knoten erforderlich sind. Testen Sie die Selektoren zunächst an einem Länderinformationsfeld, bevor Sie sie auf alle Elemente der Seite anwenden!
Schritt 6: Daten aus einem einzelnen Element abrufen
Die Funktion parse() aus scraper::Selector akzeptiert eine Zeichenfolge, die einen CSS-Selektor darstellt, und gibt ein Selektorobjekt zurück. Verwenden Sie sie wie folgt:
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;Anschließend können Sie den Selektor an die Methode select() übergeben, die von document bereitgestellt wird:
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("Country info box element not found!")?;Dadurch wird der CSS-Selektor auf die Seite angewendet und das ausgewählte HTML-Element zurückgegeben. Da select() immer einen Iterator zurückgibt, ist der Aufruf von .next() erforderlich, um den ersten Knoten der Länderinformationsbox zu erhalten.
Beachten Sie, dass das von select() zurückgegebene Objekt ebenfalls die Funktion select() bereitstellt. In diesem Fall wird nur in den untergeordneten Elementen des aktuellen Knotens nach Knoten gesucht. Sie können also die gesamte Rust-Web-Scraping-Logik wie folgt implementieren:
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Landeshauptstadt nicht gefunden")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Bevölkerung des Landes nicht gefunden")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Landesfläche nicht gefunden")?;Mit der Methode text() können Sie auf den Text zugreifen, der im ausgewählten HTML-Knoten enthalten ist. Weitere Ansätze zur Datenextraktion finden Sie in der Dokumentation. Da der extrahierte Text unerwünschte Leerzeichen enthalten kann, entfernen Sie diese mit trim().
Geben Sie die gescrapten Daten aus, um zu überprüfen, ob die Scraping-Logik wie erwartet funktioniert:
println!("Ländername: {name}");
println!("Landeshauptstadt: {capital}");
println!("Ländername: {population}");
println!("Länderfläche: {area}");
Das würde folgendes Ergebnis liefern:
Ländername: Andorra
Landeshauptstadt: Andorra la Vella
Bevölkerung des Landes: 84000
Fläche des Landes: 468,0Ja! Sie haben gerade Web-Scraping in Rust durchgeführt!
Schritt 7: Alle Elemente auf der Seite scrapen
Dieses Mal erweitern Sie den oben gezeigten Code, um alle Knoten der Länderinformationsbox auf der Seite zu durchlaufen.
Zunächst müssen Sie eine benutzerdefinierte Datenstruktur definieren, in der die gesammelten Daten gespeichert werden sollen. Um eine neue, dafür maßgeschneiderte Struktur zu definieren, fügen Sie die folgenden Zeilen oben in Ihrer Datei main.rs ein:
struct Country {
name: String,
capital: String,
population: String,
area: String,
}Als Nächstes instanziieren Sie ein Vec von Country-Objekten in main():
let mut countries: Vec<Country> = Vec::new();Dieser Vektor enthält alle Ihre gesammelten Daten.
Entfernen Sie als Nächstes den Aufruf .next(), um alle Länderinformationsfelder abzurufen, durchlaufen Sie diese und füllen Sie die Länder:
// wo die gescrapten Daten gespeichert werden sollen
let mut countries: Vec<COUNTRY> = Vec::new();
// die HTML-Elemente der Länderinfoboxen auswählen
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// die HTML-Elemente der Länder durchlaufen
// und alle scrapen
for html_country_info_box_element in html_country_info_box_elements {
// Scraping-Logik für ein einzelnes HTML-Element der Länderinformationsbox...
// ein neues Country-Objekt erstellen und zum Vektor hinzufügen
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}Anschließend können Sie alle gescrapten Länder mit folgendem Befehl ausgeben:
// Ergebnisse protokollieren
for country in countries {
println!("Ländername: {}", country.name);
println!("Hauptstadt des Landes: {}", country.capital);
println!("Landesname: {}", country.population);
println!("Landesfläche: {}", country.area);
println!();
}
Die neue Rust-Web-Scraping-Datei main.rs enthält:
// benutzerdefinierte Struktur zum Speichern der Scraping-Daten
struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Verbindung zur Zielseite herstellen
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// Roh-HTML extrahieren und ausgeben
let html = response.text()?;
// HTML-Dokument parsen
let document = scraper::Html::parse_document(&html);
// wo die gescrapten Daten gespeichert werden sollen
let mut countries: Vec<COUNTRY> = Vec::new();
// HTML-Elemente der Länderinformationsbox auswählen
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// die HTML-Elemente des Landes durchlaufen
// und alle scrapen
for html_country_info_box_element in html_country_info_box_elements {
// Scraping-Logik für ein einzelnes HTML-Element des Länderinformationsfeldes
let country_name_selector = Scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Ländername nicht gefunden")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Landeshauptstadt nicht gefunden")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Bevölkerung des Landes nicht gefunden")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;
// Erstelle ein neues Country-Objekt und füge es zum Vektor hinzu
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// Ergebnisse protokollieren
for country in countries {
println!("Country name: {}", country.name);
println!("Hauptstadt des Landes: {}", country.capital);
println!("Bevölkerung des Landes: {}", country.population);
println!("Fläche des Landes: {}", country.area);
println!();
}
Ok(())
}
Starten Sie das Programm, um folgende Ausgabe zu erhalten:
Ländername: Andorra
Landeshauptstadt: Andorra la Vella
Bevölkerung des Landes: 84000
Fläche des Landes: 468,0
# der Kürze halber ausgelassen...
Ländername: Simbabwe
Landeshauptstadt: Harare
Bevölkerung des Landes: 11651858
Fläche des Landes: 390580,0Mission erfüllt! Sie haben soeben alle Länder von der Zielseite gescrapt!
Schritt 8: Exportieren Sie die extrahierten Daten in eine CSV-Datei
Die gesammelten Daten sind nun in einem Rust-Vektor gespeichert, was nicht das beste Format ist, wenn Sie sie mit anderen Personen teilen möchten. Deshalb müssen Sie sie in leicht zu durchsuchende Formate wie CSV exportieren.
Um Daten in eine CSV-Datei zu exportieren, sollten Sie die csv-Bibliothek verwenden. Installieren Sie sie mit diesem Befehl:
cargo add csvAnschließend können Sie damit eine CSV-Exportdatei erstellen mit:
// Initialisieren Sie die CSV-Ausgabedatei.
let mut writer = csv::Writer::from_path("countries.csv")?;
// Schreiben Sie den CSV-Header.
writer.write_record(&["name", "capital", "population", "area"])?;
// Datei mit jedem Land füllen
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}Dieser Ausschnitt erstellt eine CSV-Datei, initialisiert sie mit der Kopfzeile und füllt sie schließlich durch Iteration über den Länder-Vektor.
Schritt 9: Alles zusammenfügen
Hier ist der vollständige Code Ihres Rust-Skripts für das Web-Scraping:
// benutzerdefinierte Struktur zum Speichern der Scraping-Daten
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Verbindung zur Zielseite herstellen
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// Roh-HTML extrahieren und ausgeben
let html = response.text()?;
// HTML-Dokument parsen
let document = Scraper::Html::parse_document(&html);
// Speicherort für die gescrapten Daten
let mut countries: Vec<COUNTRY> = Vec::new();
// HTML-Elemente der Länderinformationsbox auswählen
let html_country_info_box_selector = Scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// HTML-Elemente der Länder durchlaufen
// und alle scrapen
for html_country_info_box_element in html_country_info_box_elements {
// Scraping-Logik für ein einzelnes HTML-Element der Länderinformationsbox
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = Scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Landeshauptstadt nicht gefunden")?;
let country_population_selector = Scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = Scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("Landesfläche nicht gefunden")?;
// Neues Länderobjekt erstellen und zum Vektor hinzufügen
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// Initialisiere die CSV-Ausgabedatei
let mut writer = csv::Writer::from_path("countries.csv")?;
// Schreibe den CSV-Header
writer.write_record(&["name", "capital", "population", "area"])?;
// Datei mit jedem Land füllen
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}
Ok(())
}Kaum zu glauben, oder? Mit weniger als 100 Zeilen Code können Sie einen Rust-Scraper erstellen.
Kompilieren Sie die Anwendung mit dem folgenden Befehl:
cargo buildStarten Sie sie dann mit:
cargo runWenn das Skript beendet ist, erscheint eine Datei namens countries.csv im Stammverzeichnis Ihres Projekts. Öffnen Sie diese Datei, um die folgenden Daten anzuzeigen:
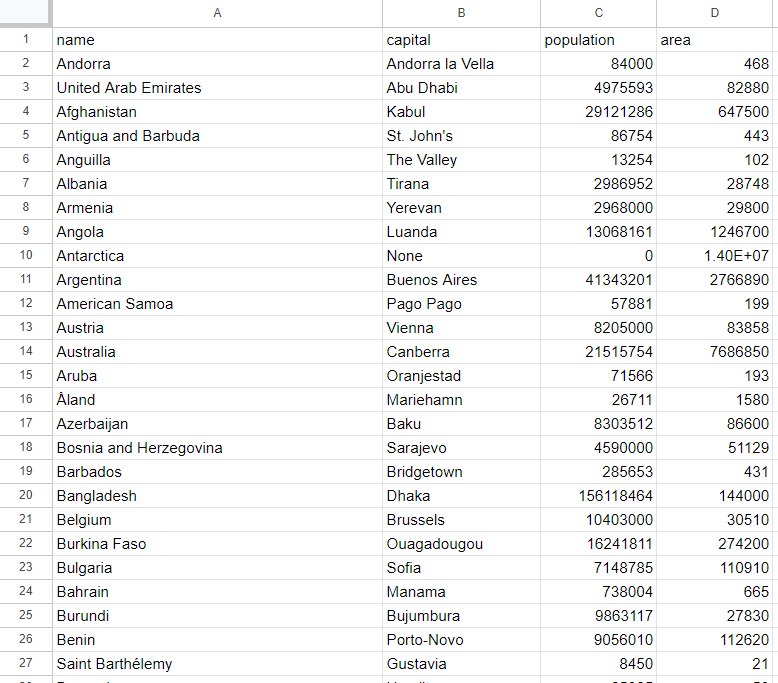
Et voilà! Jetzt kennen Sie die Grundlagen des Web-Scrapings mit Rust!
Halten Sie Ihre Web-Scraping-Aktivitäten ethisch und respektvoll
Das automatische Abrufen von Daten aus dem Internet ist eine effektive Methode, um nützliche Informationen zu erhalten. Dabei sollten Sie jedoch darauf achten, der Zielwebsite keinen Schaden zuzufügen. Daher müssen Sie bei dieser Vorgehensweise die richtigen Vorsichtsmaßnahmen treffen.
Beachten Sie die folgenden Tipps, um verantwortungsbewusstes Web-Scraping zu betreiben:
- Halten Sie sich an die robots.txt-Datei: Jede Website verfügt über eine robots.txt-Datei, in der die Regeln für den Zugriff automatisierter Crawler auf ihre Seiten festgelegt sind. Um ethische Scraping-Praktiken zu wahren, müssen Sie sich an diese Richtlinien halten. Weitere Informationen finden Sie in unserem Leitfaden zu robots.txt für Web-Scraping.
- Begrenzen Sie die Häufigkeit Ihrer Anfragen: Zu viele Anfragen in kurzer Zeitführen zu einer Überlastung des Servers und beeinträchtigen die Leistung der Website für alle Benutzer. Dies kann auch zu Maßnahmen zur Begrenzung der Anfragerate führen und dazu, dass Sie gesperrt werden. Fügen Sie daher Ihren Anfragen zufällige Verzögerungen hinzu, um eine Überlastung des Zielservers zu vermeiden.
- Überprüfen und beachten Sie die Nutzungsbedingungen der Website: Bevor Sie eine Website scrapen, lesen Sie deren Nutzungsbedingungen und halten Sie sich daran. Diese können Informationen zum Urheberrecht, zu geistigen Eigentumsrechten und Richtlinien zur Verwendung der Daten enthalten.
- Scrapen Sie nur öffentlich zugängliche Informationen: Konzentrieren Sie sich auf die Extraktion von Daten, die auf der Website öffentlich zugänglich sind und nicht durch Anmeldedaten oder andere Formen der Autorisierung geschützt sind. Das Scrapen privater oder sensibler Daten ohne entsprechende Berechtigung ist unethisch und kann rechtliche Konsequenzen nach sich ziehen.
- Verlassen Sie sich auf vertrauenswürdige und aktuelle Scraping-Tools: Wählen Sie seriöse Anbieter und entscheiden Sie sich für Bibliotheken und Tools, die gut gepflegt und regelmäßig aktualisiert werden. Nur so können Sie sicherstellen, dass sie den neuesten ethischen Scraping-Grundsätzen und Best Practices entsprechen. Wenn Sie Zweifel haben, lesen Sie unseren Artikel darüber , wie Sie den besten Web-Scraping-Dienst auswählen.
Fazit
In diesem Tutorial haben Sie gesehen, warum Rust eine gute Option für das Web-Scraping ist und welche Bibliotheken Sie dafür verwenden sollten. Hier haben Sie gelernt, wie Sie mit reqwest und scraper einen Rust-Scraper erstellen können, der Daten aus einer realen Website extrahieren kann. Das erfordert nur wenige Zeilen Code!
Beachten Sie jedoch, dass Web-Scraping nicht immer so einfach ist. Der Grund dafür ist, dass Anti-Scraping- und Anti-Bot-Lösungen immer häufiger zum Einsatz kommen. Diese Technologien können die Selbstliebe Ihres Skripts erkennen und es blockieren, was eine ernsthafte Herausforderung für Ihren Scraping-Vorgang darstellt.
Vermeiden Sie diese Probleme mit dem fortschrittlichen Web-Scraping-Tool der nächsten Generation von Bright Data. Wenn Sie mehr darüber erfahren möchten, wie Sie eine Blockierung vermeiden können, nutzen Sie einen Proxy von einem der zahlreichen verfügbaren Proxy-Dienste oder verwenden Sie den fortschrittlichen Web Unlocker.
Sie möchten sich nicht mit Web-Scraping beschäftigen? Entdecken Sie unsere Datensätze.
Sie sind sich nicht sicher, welches Produkt Sie wählen sollen? Melden Sie sich jetzt an und finden Sie die richtige Lösung für Ihr Unternehmen.





