

In diesem Tutorial über Tricks zum Scraping von Next.js-Websites lernen Sie Folgendes:
- Was Next ist und warum es so beliebt ist
- Warum es dank der Funktionsweise von React Hydration einfach ist, Next.js-Webseiten zu scrapen
- Wie Sie React Hydration für das Web-Scraping nutzen können
Lassen Sie uns loslegen!
Was ist Next.js und wie funktioniert es?
Next.js ist ein JavaScript-Framework, das auf React aufbaut und zum Erstellen von serverseitig gerenderten und statisch generierten Websites dient. Es vereinfacht den Entwicklungsprozess durch eine umfangreiche API und einen strukturierten Ansatz zum Erstellen serverseitiger React-Anwendungen.
Next.js hat im Laufe der Jahre stark an Popularität gewonnen und ist laut Statista mittlerweile die fünftmeistgenutzte Webbibliothek. Dies ist auf seine Benutzerfreundlichkeit, seine hervorragende Leistung, seine Ähnlichkeiten mit React, seine umfangreiche Dokumentation und die Unterstützung durch die Community zurückzuführen. Kein Wunder, dass viele große Unternehmen und Startups Next.js für ihre Webentwicklungsanforderungen wählen.
Auf hoher Ebene funktioniert Next.js, indem es Daten auf dem Server abruft und an React-Komponenten weiterleitet, um vorgerenderte HTML-Dokumente zu erstellen. Dieser Prozess verbessert die Leistung, indem HTML-Inhalte auf dem Server generiert werden, die dann an den Client gesendet werden können, um das Laden der Startseite zu beschleunigen.
Wie Sie React Hydration für das Web-Scraping nutzen können
Hydration schließt die Lücke zwischen serverseitigem und clientseitigem Rendering. Genauer gesagt ist Next.js Hydration der Prozess, durch den das von Next.js generierte HTML-Dokument in eine voll funktionsfähige clientseitige React-Anwendung umgewandelt wird.
Während der Hydration – nachdem der Browser die vom Server zurückgegebene HTML-Seite geladen hat –fügt React der Seite Interaktivität hinzu. Konkret fügt es Ereignis-Listener hinzu und verarbeitet den Status in den DOM-Knoten, die den auf dem Server gerenderten React-Komponenten entsprechen.
Dies sind die Schritte, die React benötigt, um eine vorgerenderte Seite zu hydrieren:
- Anfängliches Server-Rendering: Der Server generiert das HTML-Dokument mit der HTML-Darstellung der auf der Seite verwendeten React-Komponenten.
- Clientseitige JavaScript-Ausführung: Wenn der Client das HTML-Markup empfängt, führt er das JavaScript-Bundle aus, das den React-Code enthält.
- Abgleich: React vergleicht das vom Server zurückgegebene HTML mit der virtuellen DOM-Darstellung, die spontan generiert wurde. Weitere Informationen finden Sie in der offiziellen Dokumentation.
- Hydration: Wenn beide identisch sind, schließt React das Rendering ab, indem es Ereignisbehandler hinzufügt und den Status verarbeitet, während es so viel wie möglich vom vorhandenen DOM wiederverwendet.
Um diesen Vorgang auszuführen, benötigt React dieselben Daten, die vom Server zur Generierung des HTML-Dokuments verwendet werden. Aus diesem Grund fügt Next.js der generierten Seite einige spezielle DOM-Elemente hinzu, die die Props-Daten enthalten.
Auf einigen Next.js-Websites finden Sie diese Daten im <script> -Element mit der ID __NEXT_DATA__. Dieser spezielle DOM-Knoten enthält Daten im JSON-Format, die React für die Hydration verwendet, wie folgt:
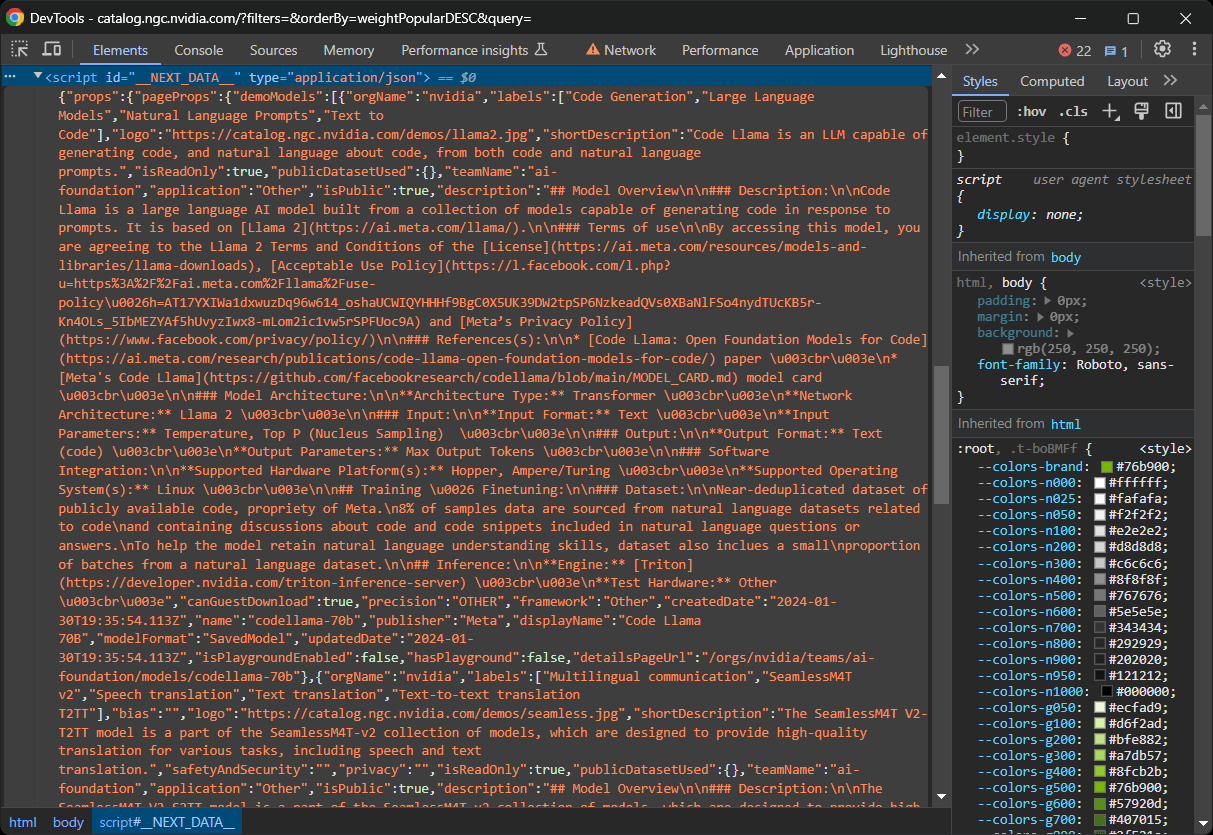
Auf neueren Next.js-Websites, die den neuen App Router verwenden, werden die Hydration-Daten stattdessen in den self.__next_f.push() -Funktionsaufrufen in mehreren <script> -Knoten gespeichert:
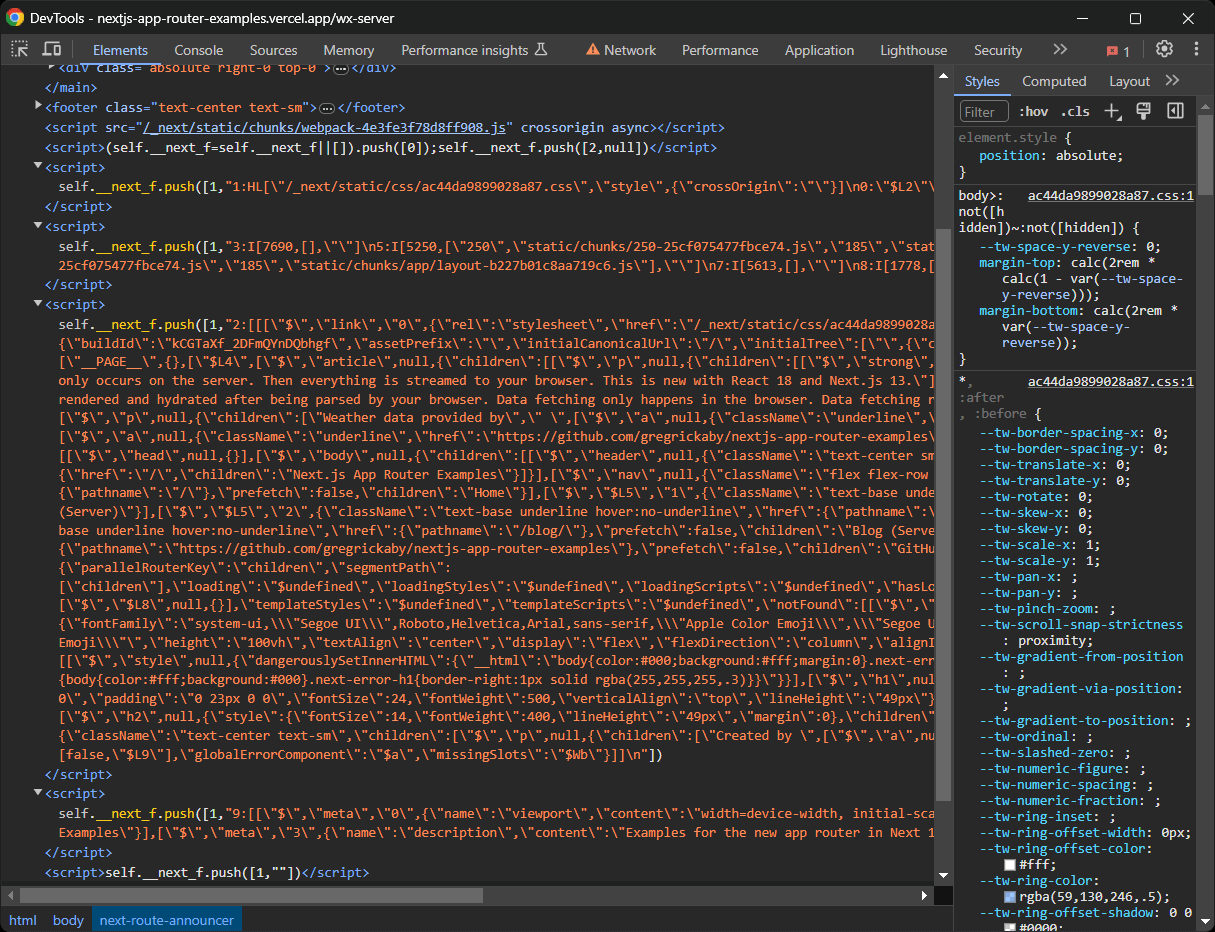
Beachten Sie, dass diese Knoten möglicherweise noch mehr Daten enthalten als auf der Website angezeigt werden. Wie ist das möglich? Weil diese Hydration-Elemente alle API- und Datenbankdaten speichern, die während der Seitengenerierung vom Server abgerufen und an React-Komponenten übergeben werden. Allerdings werden möglicherweise nicht alle Attribute dieser Objekte tatsächlich in den Komponenten abgerufen und verwendet.
Nun spielt es keine Rolle, ob Sie tatsächlich verstanden haben, warum diese Daten vorhanden sein müssen, damit React funktioniert. Wichtig ist, dass die über Next.js generierten Webseiten die zu rendernden Daten im JSON-Format in speziellen DOM-Knoten enthalten. Wie Sie sich vorstellen können, hat dies enorme Auswirkungen auf das Web-Scraping mit Nex.js!
Scraping von Next.js-Websites durch die Hydration-Daten
Das Extrahieren von Daten aus einer mit Next.js erstellten Seite ist so einfach, dass Sie nicht einmal ein Scraping-Skript benötigen. Die DevTools Ihres Browsers reichen völlig aus.
Sehen wir uns nun an, wie Sie React Hydration nutzen können, um Next.js-Websites in Sekundenschnelle zu scrapen!
Extrahieren von Daten aus __NEXT_DATA__
Angenommen, Sie haben überprüft, dass die zu scrapend Zielseite mit Next.js erstellt wurde (wie das geht, erfahren Sie in der FAQ-Frage).
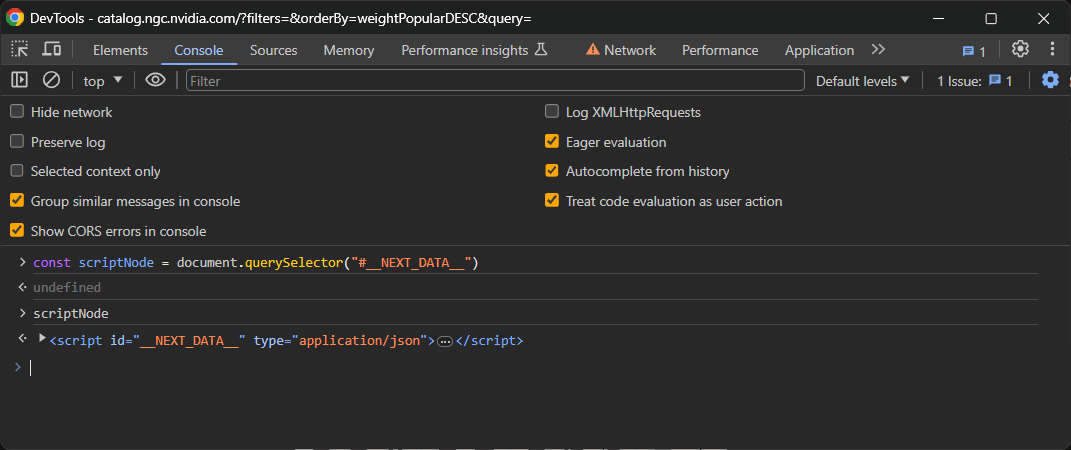
Rufen Sie nun die Seite in Ihrem Browser auf, klicken Sie mit der rechten Maustaste und wählen Sie „Untersuchen”, um zu den DevTools zu gelangen. Wechseln Sie zur Registerkarte „Konsole” und führen Sie die folgende JavaScript-Zeile aus, um das gewünschte <script> -Element auszuwählen:
const scriptNode = document.querySelector("#__NEXT_DATA__")Dadurch wird die Funktion querySelector() verwendet, um das Element im DOM mit der ID __NEXT_DATA__ auszuwählen und es der Variablen scriptNode zuzuweisen.
Wenn Sie scriptNode in die Konsole eingeben und die Eingabetaste drücken, erhalten Sie den gewünschten Knoten:
Greifen Sie auf den inneren HTML-Inhalt zu undführen Sie ein Parsing des Inhalts als JSON-Inhalt ausmit:
const jsonData = JSON.parse(scriptNode.innerHTML)
Et voilà! Das Objekt jsonData enthält nun alle Daten, die React zum Rendern der Komponenten auf der Seite verwendet hat:
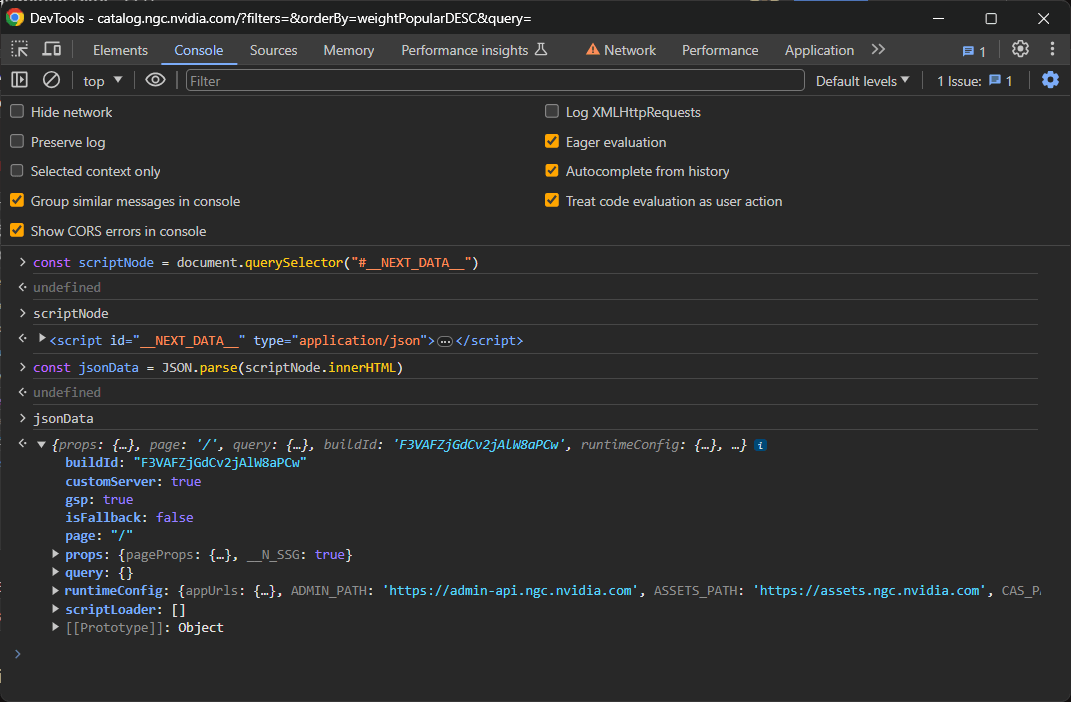
Konzentrieren Sie sich im Detail auf das Feld pageProps innerhalb von props:
jsonData.props.pageProps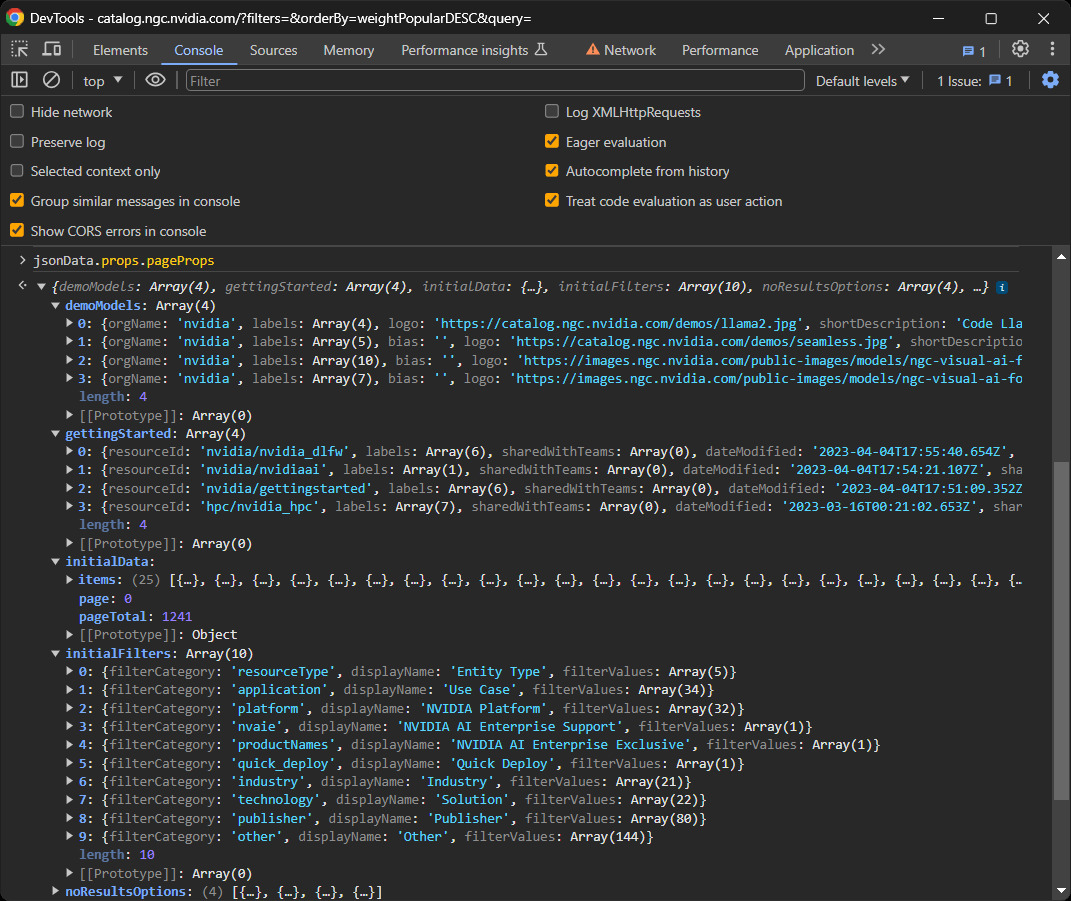
Klicken Sie anschließend mit der rechten Maustaste auf das Objekt und wählen Sie die Option „Objekt kopieren”:
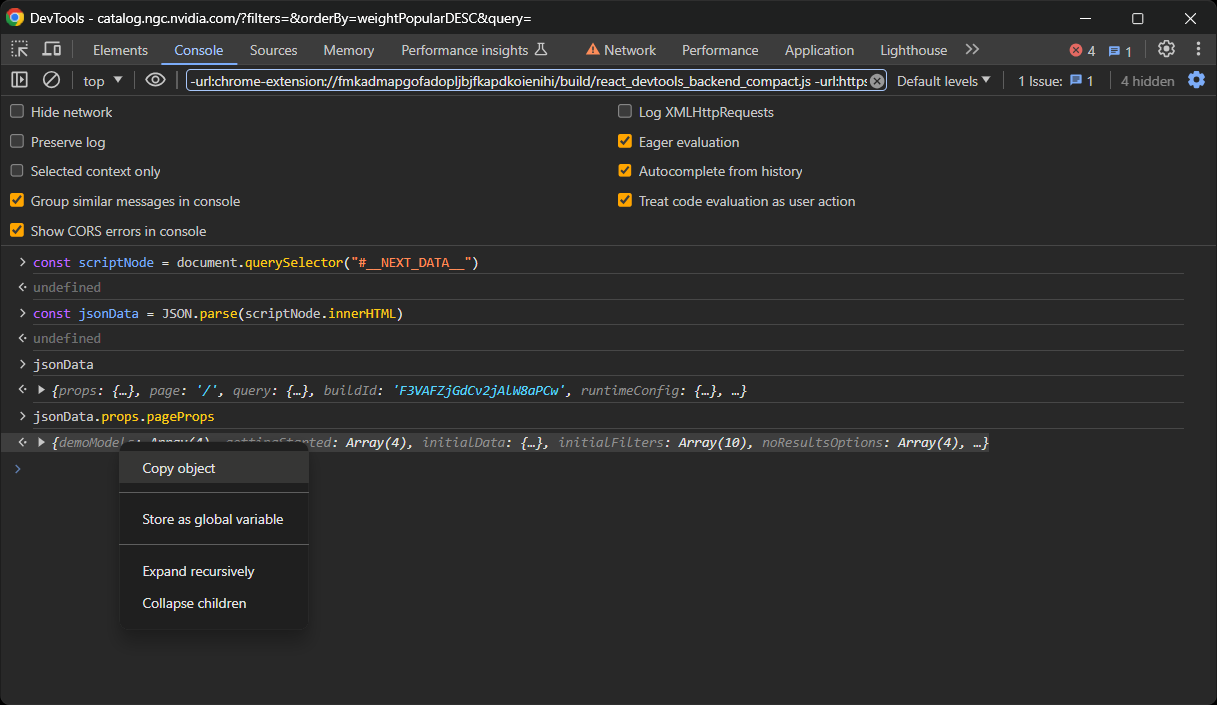
Erstellen Sie abschließend eine Datei „data.json“ und fügen Sie den gewünschten Inhalt ein!
Großartig! Sie haben gerade in weniger als einer Minute Web-Scraping auf einer Next.js-Website durchgeführt.
Wenn Sie alles zusammenfügen, erhalten Sie dieses Next.js-Scraping-Skript:
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pagePropsAbrufen von Daten aus self.__next_f.push -Funktionen
Next.js 13 hat den App Router eingeführt. Dadurch ändert sich die Art und Weise, wie Next.js die Daten zur Hydrierung an React übermittelt. In diesem Fall müssen Sie alle <script> -Knoten auswählen, die die Zeichenfolge self.__next_f.push enthalten.
Rufen Sie erneut die Zielseite im Browser auf und öffnen Sie die Konsole. Führen Sie den folgenden Befehl aus, um die <script> -Knoten auszuwählen:
const scriptNodes = document.querySelectorAll("script")querySelectorAll() gibt ein NodeList -Objekt zurück. Konvertieren Sie es mit Array.from() in ein Array, um die filter() -Methode anzuwenden und nur die gewünschten Knoten zu erhalten:
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))Jetzt enthält hydrationScriptNodes alle Hydration- <script> -Elemente auf der Seite:
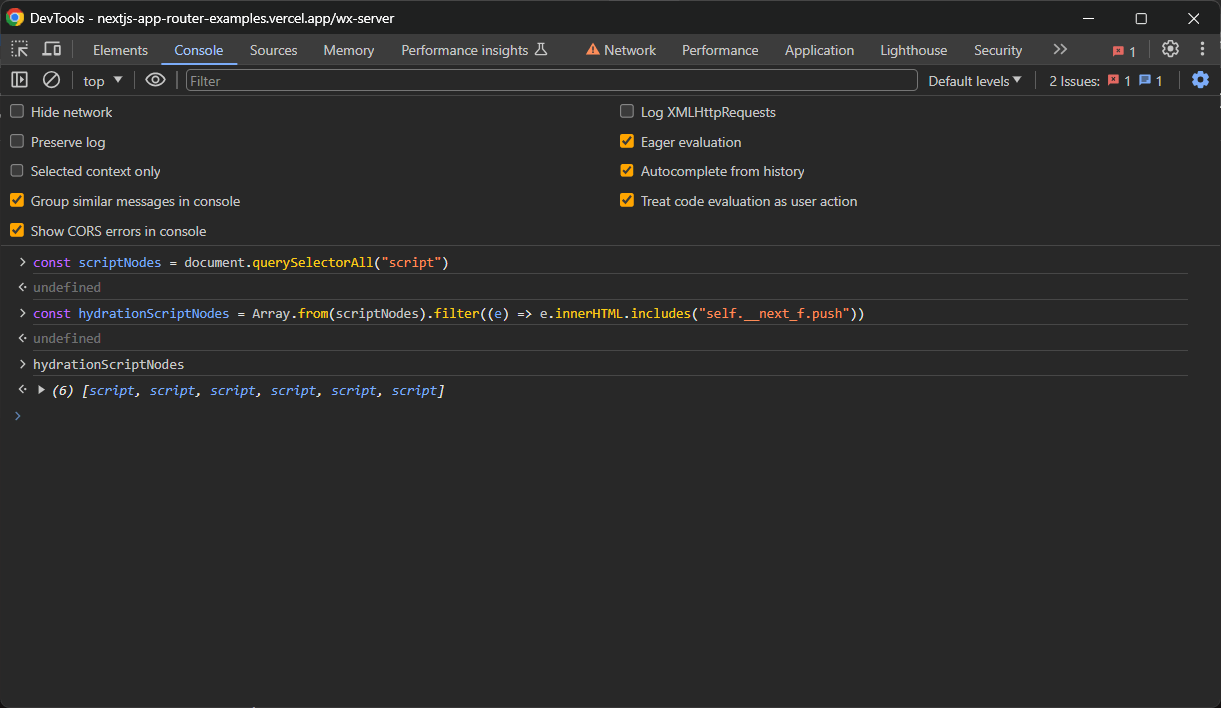
In der Regel möchten Sie jedoch nur den Knoten, der das Attribut initialTree hat. Hier sind alle interessanten Hydration-Daten gespeichert:
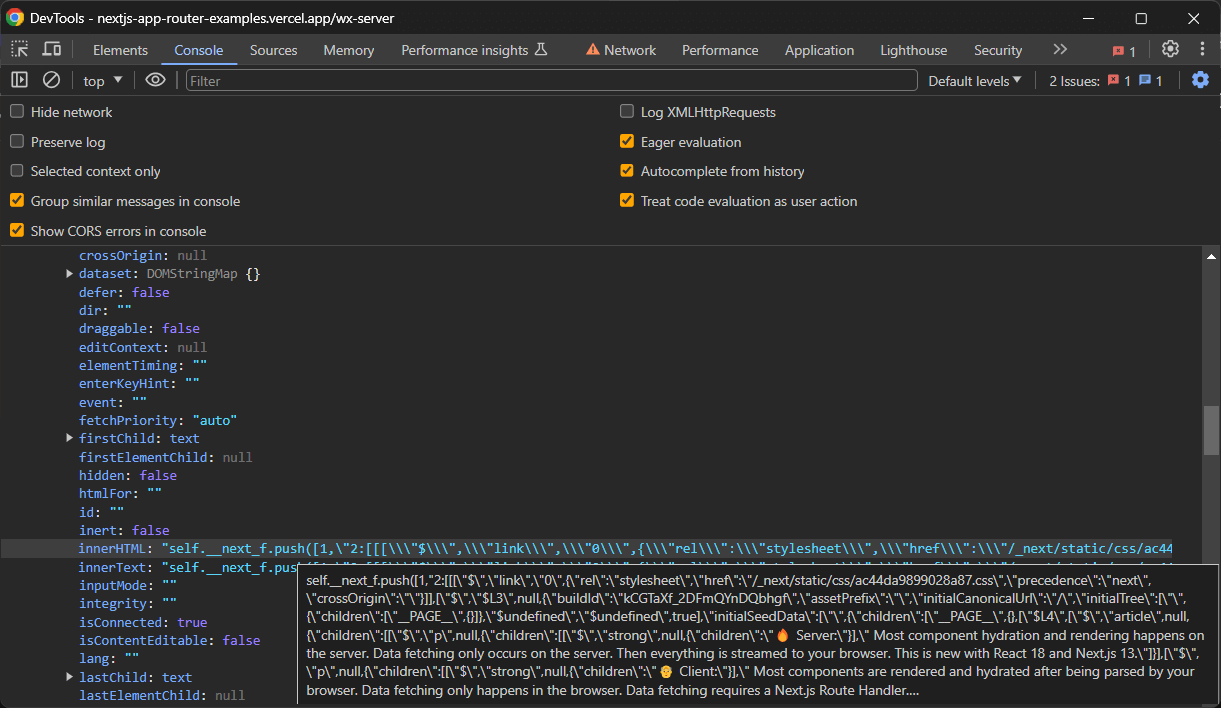
Wählen Sie ihn mit folgendem Befehl aus:
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))Extrahieren Sie dann die interessierenden Daten mit:
scriptNode.innerHTMLBeachten Sie, dass die abgerufenen Daten zwar die gewünschten Informationen enthalten, jedoch zusätzliches Parsing erforderlich ist. Mit ein paar zusätzlichen Zeilen können Sie sie in ein besser lesbares Format konvertieren.
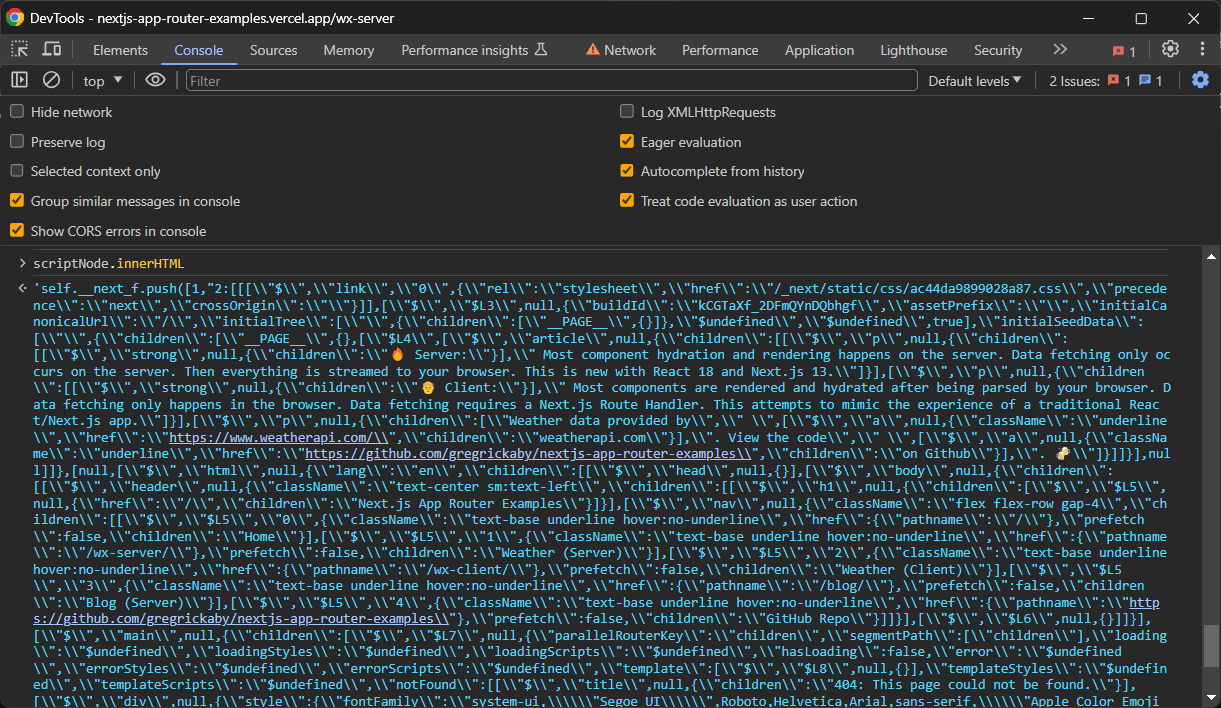
Diesmal lautet das Next.js-Skript zum Scraping:
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTMLHerzlichen Glückwunsch! Das Scraping von Next.js-Websites war noch nie so einfach!
Einschränkungen dieses Next.js-Scraping-Ansatzes
Dieser auf React-Hydration-Daten basierende Scraping-Ansatz ist zwar schnell und effektiv, unterliegt jedoch einigen Einschränkungen. Diese sind:
- Teilweise Daten: Die speziellen
<SCRIPT>-Knoten, die von Next.js hinzugefügt werden, enthalten nur die Daten, die vom Server abgerufen und während der Hydration an die React-Komponenten übergeben werden. Das sind möglicherweise nicht alle Daten, die auf der Seite enthalten sind. Der Grund dafür ist, dass React-Komponenten fest codierte Werte haben oder andere Daten dynamisch über AJAX abrufen können. In diesem Fall müssen Sie das Web-Scraping mit einem Browser-Automatisierungstool durchführen. - Zusätzliche Parsing erforderlich:
self.__next_f.pushbeinhaltet Daten in einem proprietären Format, und es ist nicht immer einfach, diese korrekt zu parsen. - Manuelle Vorgänge erforderlich: Sofern Sie die oben geschriebenen Skripte nicht in Scraping-Skripte in JavaScript, Python oder einer ähnlichen Sprache übersetzen und die Logik für den Datenexport integrieren, müssen Sie die Daten manuell in eine Textdatei exportieren. Weitere Informationen finden Sie in unserem Leitfaden zum Web-Scraping mit JavaScript und Node.js.
Fazit
In diesem Artikel haben Sie erfahren, was Next.js ist, warum es eine der weltweit am häufigsten verwendeten Technologien für die Erstellung von Websites ist und wie Sie Daten daraus scrapen können. Insbesondere haben Sie erkannt, dass es auf React Hydration basiert und was dies bedeutet. Aus diesem Grund enthalten die vom Server zurückgegebenen HTML-Seiten bereits alle Daten, die Sie benötigen (und das sogar im JSON-Format!). Dies macht das Web-Scraping von Next.js-Websites sehr einfach.
Das eigentliche Problem ist ein anderes: die Blockierung durch Anti-Bot-Technologien. Diese Systeme können Ihr automatisiertes Scraping-Skript erkennen und blockieren. Glücklicherweise hat Bright Data mehrere effektive Lösungen für Sie:
- Web Scraper IDE: Eine Cloud-IDE zum Erstellen von Web-Scrapern, die Blockierungen automatisch umgehen und vermeiden können.
- Web Scraper API: Einfacher programmgesteuerter Zugriff auf strukturierte Webdaten mit einer Verfügbarkeit von 99,99 % und unbegrenzter Skalierbarkeit.
- Scraping-Browser: Ein cloudbasierter, steuerbarer Browser, der JavaScript-Rendering-Funktionen bietet und gleichzeitig CAPTCHAs, Browser-Fingerprinting, automatische Wiederholungsversuche und vieles mehr für Sie übernimmt. Er lässt sich in die gängigsten Automatisierungs-Browser-Bibliotheken wie Playwright und Puppeteer integrieren.
- Web Unlocker: Eine Entsperr-API, die nahtlos den rohen HTML-Code jeder Seite zurückgeben kann und dabei alle Anti-Scraping-Maßnahmen umgeht.
Sie möchten sich überhaupt nicht mit Web-Scraping beschäftigen, sind aber dennoch an Online-Daten interessiert? Entdecken Sie die gebrauchsfertigen Datensätze von Bright Data!
FAQ
Ist es möglich, __NEXT_DATA__ aus dem DOM in Next.jszu verbergen oder zu entfernen ?
Nein, das können Sie nicht entfernen oder ausblenden. Wenn Sie sich entscheiden, das _NEXT_DATA_ <script> -Element aus dem DOM zu entfernen, kann React nicht mehr hydrieren. Da die Daten in diesem Skript für die ordnungsgemäße Funktion von React erforderlich sind, können Sie sie nicht entfernen, ohne mit Fehlfunktionen oder einer Beeinträchtigung der Funktionalität zu rechnen. Lesen Sie die GitHub-Diskussion zu diesem Thema.
Ist es möglich, self.__next_f.push -Aufrufe aus dem DOMzu entfernen ?
Nein, Sie können die self.__next_f.push-Aufrufe in den von Next.js hinzugefügten <script> -Knoten nicht entfernen. Diese DOM-Elemente werden vom Server hinzugefügt, damit die clientseitige React-Anwendung hydrieren und wie erwartet funktionieren kann. Weitere Informationen finden Sie in der GitHub-Diskussion zu diesem Thema.
Wie kann man feststellen, ob eine Website mit Next.js erstellt wurde?
Es gibt mehrere Möglichkeiten, um festzustellen, ob eine Website mit Next.js erstellt wurde. Suchen Sie zunächst nach dem X-Powered-By-Header, der von einigen Versionen von Next.js standardmäßig gesetzt wird:
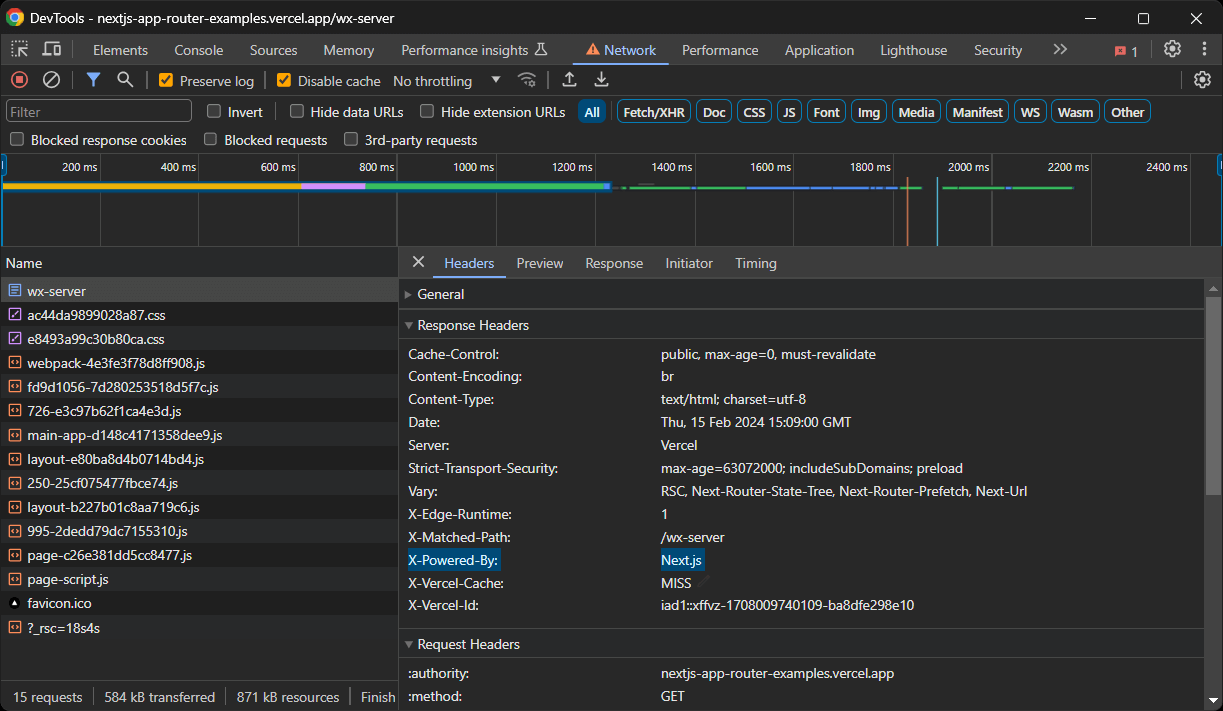
Andernfalls überprüfen Sie, ob das DOM einen <script id="__NEXT_DATA__" ... > -Knoten oder einige <script>self.__next_f.push(...)</script> -Knoten enthält.
Ist Next.js die einzige Technologie, die auf React Hydration basiert?
Nein, Next.js ist nicht die einzige Technologie, die auf React Hydration basiert. Andere Server-Side-Rendering-Generatoren (SSR) wie Gatsby nutzen ebenfalls React Hydration, um server-gerenderte HTML-Dateien in interaktive React-Anwendungen auf der Client-Seite umzuwandeln. Dieser Prozess ist ein gängiger Ansatz bei SSR mit React und nicht auf Next.js beschränkt.




