

Web-Scraping, eine Technik zur Datenerfassung, wird häufig durch verschiedene Hindernisse beeinträchtigt, darunter IP-Sperren, Geoblocking und Datenschutzbedenken. Zum Glück können Proxyserver Ihnen helfen, diese Herausforderungen zu meistern. Sie dienen als Vermittler zwischen Ihrem Computer und dem Internet und bearbeiten Anfragen mit ihren eigenen IP-Adressen. Diese Funktion hilft nicht nur dabei, IP-bezogene Einschränkungen und Verbote zu umgehen, sondern erleichtert auch den Zugriff auf geografisch eingeschränkte Inhalte. Darüber hinaus tragen Proxyserver maßgeblich dazu bei, die Anonymität beim Web-Scraping aufrechtzuerhalten und Ihre Privatsphäre zu schützen.
Die Verwendung von Proxyservern kann auch die Leistung und Zuverlässigkeit Ihrer Web-Scraping-Bemühungen verbessern. Indem sie Anfragen auf mehrere Server verteilen, stellen sie sicher, dass kein einzelner Server übermäßig belastet wird, und optimieren so den Prozess.
In diesem Tutorial erfahren Sie, wie Sie einen Proxyserver in Node.js für Ihre Web-Scraping-Projekte verwenden können.
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, sollten Sie sich mit JavaScript und Node.js vertraut machen. Wenn Node.js noch nicht auf Ihrem Computer installiert ist, müssen Sie es jetzt installieren.
Sie benötigen außerdem einen geeigneten Texteditor. Es stehen verschiedene Optionen zur Verfügung, z. B. Sublime Text. In diesem Tutorial wird Visual Studio Code (VS Code) verwendet. Er ist benutzerfreundlich und vollgepackt mit Funktionen, die das Programmieren erleichtern.
Erstellen Sie zunächst ein neues Verzeichnis mit dem Namen web-scraping-proxy und initialisieren Sie dann Ihr Node.js-Projekt. Öffnen Sie Ihr Terminal oder Ihre Shell und navigieren Sie mit den folgenden Befehlen zu Ihrem neuen Verzeichnis:
cd web-scraping-proxy
npm init -y
Als Nächstes müssen Sie einige Node.js-Pakete installieren, um HTTP-Anfragen zu verarbeiten und HTML zu analysieren.
Stellen Sie sicher, dass Sie sich in Ihrem Projektverzeichnis befinden, und führen Sie dann Folgendes aus:
npm install axios playwright puppeteer http-proxy-agent
npx playwright install
Axios wird verwendet, um HTTP-Anfragen zum Abrufen von Webinhalten zu stellen. Playwright und Puppeteer automatisieren Browserinteraktionen, was für das Scraping dynamischer Websites unerlässlich ist. Playwright unterstützt verschiedene Browser und Puppeteer konzentriert sich auf Chrome oder Chromium. Die http-proxy-agent-Bibliothek wird verwendet, um einen Proxy-Agenten für die HTTP-Anfragen zu erstellen.
npx playwright install ist erforderlich, um die notwendigen Treiber zu installieren, die die playwright-Bibliothek verwenden wird.
Sobald Sie diese Schritte abgeschlossen haben, können Sie mit Node.js in die Welt des Web-Scraping eintauchen.
Richten Sie einen lokalen Proxy für Web-Scraping ein
Ein wichtiger erster Schritt beim Web-Scraping ist die Einrichtung eines Proxyservers. Für dieses Tutorial verwenden Sie das Open-Source-Tool mitmproxy.
Gehen Sie zunächst zur mitmproxy-Downloadseite und laden Sie Version 10.1.6 herunter, die auf Ihr Betriebssystem zugeschnitten ist. Wenn Sie während der Installation Hilfe benötigen, ist die mitmproxy-Installationsanleitung eine hilfreiche Ressource.
Sobald Sie mitmproxy installiert haben, starten Sie es, indem Sie den folgenden Befehl in Ihrem Terminal eingeben:
mitmproxy
Dieser Befehl öffnet ein Fenster in Ihrem Terminal, das als Schnittstelle für mitmproxy dient:
Versuchen Sie, einen Test durchzuführen, um sicherzustellen, dass Ihr Proxy korrekt eingerichtet ist. Öffnen Sie ein neues Terminalfenster und führen Sie den folgenden Befehl aus:
curl --proxy http://localhost:8080 "http://wttr.in/Paris?0"
Dieser Befehl ruft den Wetterbericht für Paris ab. Ihre Ausgabe sollte so aussehen:
Weather report: Paris
Overcast
.--. -2(-6) °C
.-( ). ↙ 11 km/h
(___.__)__) 10 km
0.0 mm
Zurück im mitmproxy-Fenster werden Sie feststellen, dass die Anfrage erfasst wurde, was darauf hinweist, dass Ihr lokaler Proxy korrekt funktioniert:

Implementieren Sie einen Proxy in Node.js für Web-Scraping
Jetzt ist es an der Zeit, zu den praktischen Aspekten des Web-Scraping mit Node.js überzugehen. In diesem Abschnitt schreiben Sie ein Skript, das eine Website scrapst, indem es Anfragen über den lokalen Proxyserver sendet.
Scrapen Sie eine Website mit der Fetch-Methode
Erstellen Sie eine neue Datei mit dem Namen fetchScraping.js im Stammverzeichnis Ihres Projekts. Diese Datei enthält den Code zum Scrapen von Inhalten von einer Website, in diesem Fall https://toscrape.com/.
Geben Sie in fetchScraping.js den folgenden JavaScript-Code ein. Dieses Skript verwendet die Fetch-Methode, um Anfragen über Ihren Proxyserver zu senden:
const fetch = require("node-fetch");
const HttpProxyAgent = require("http-proxy-agent");
async function fetchData(url) {
try {
const proxyAgent = new HttpProxyAgent.HttpProxyAgent(
"http://localhost:8080"
);
const response = await fetch(url, { agent: proxyAgent });
const data = await response.text();
console.log(data); // Outputs the fetched data
} catch (error) {
console.error("Error fetching data:", error);
}
}
fetchData("http://toscrape.com/");
Dieser Codeausschnitt definiert eine asynchrone Funktion fetchData, die eine URL akzeptiert und mithilfe von Fetch eine Anfrage an diese URL sendet, während sie über den lokalen Proxy weitergeleitet wird. Dann druckt er die Antwortdaten aus.
Um Ihr Web-Scraping-Skript auszuführen, öffnen Sie Ihr Terminal oder Ihre Shell und navigieren Sie zum Stammverzeichnis Ihres Projekts, in dem sich Ihre fetchScraping.js-Datei befindet. Führen Sie das Skript mit diesem Befehl aus:
node fetchScraping.js
Sie sollten die folgende Meldung im Terminal sehen:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Diese Ausgabe ist der HTML-Inhalt der Webseite http://toscrape.com. Die erfolgreiche Anzeige dieser Daten zeigt an, dass Ihr Web-Scraping-Skript, das über den lokalen Proxy weitergeleitet wird, ordnungsgemäß funktioniert.
Navigieren Sie nun zurück zu Ihrem mitmproxy-Fenster und Sie sollten sehen, dass die Anfrage protokolliert wird, was bedeutet, dass Ihre Anfrage über Ihren lokalen Proxy gegangen ist:
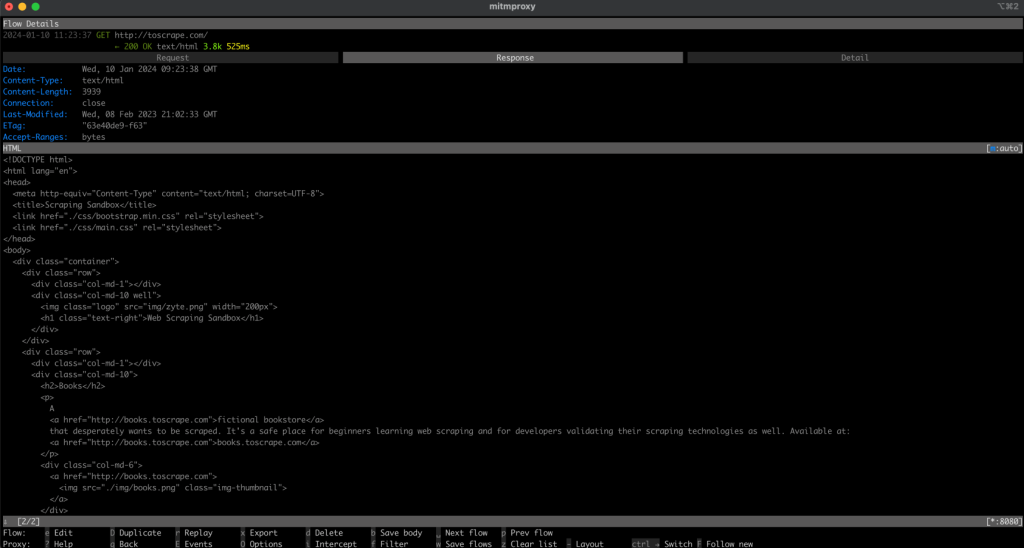
Scrapen Sie eine Website mit Playwright
Im Vergleich zu Fetch ist Playwright ein fortschrittliches Tool, das dynamischere Interaktionen mit Webseiten ermöglicht. Um es zu verwenden, müssen Sie in Ihrem Projekt eine neue Datei mit dem Namen playwrightScraping.js erstellen. Geben Sie in dieser Datei den folgenden JavaScript-Code ein:
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
proxy: {
server: "http://localhost:8080",
},
});
const page = await browser.newPage();
await page.goto("http://toscrape.com/");
// Extract and log the entire HTML content
const content = await page.content();
console.log(content);
await browser.close();
})();
Dieser Code verwendet Playwright, um eine Chromium-Browserinstanz zu starten, die für die Verwendung Ihres lokalen Proxyservers konfiguriert ist. Er öffnet dann eine neue Seite im Browser, navigiert zu http://toscrape.com und wartet darauf, dass die Seite geladen wird. Nach dem Abrufen der erforderlichen Daten wird der Browser geschlossen.
Um dieses Skript auszuführen, stellen Sie sicher, dass Sie sich in dem Verzeichnis befinden, das playwrightScraping.js enthält. Öffnen Sie Ihr Terminal oder Ihre Shell und führen Sie das Skript wie folgt aus:
node playwrightScraping.js
Wenn Sie das Skript ausführen, startet Playwright einen Chromium-Browser, navigiert zur angegebenen URL und führt alle zusätzlichen Scraping-Befehle aus, die Sie hinzugefügt haben. Dieser Prozess verwendet den lokalen Proxyserver, sodass Sie Ihre IP-Adresse nicht preisgeben und mögliche Einschränkungen umgehen können.
Die erwartete Ausgabe sollte der vorherigen ähnlich sein:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Wie zuvor sollte Ihre Anfrage im Fenster mitmproxy protokolliert werden.
Scrape eine Website mit Puppeteer
Scrapen Sie jetzt eine Website mit Puppeteer. Puppeteer ist ein leistungsstarkes Tool, das ein hohes Maß an Kontrolle über einen Headless-Chrome- oder -Chromium-Browser bietet. Diese Methode ist besonders nützlich für das Scraping dynamischer Websites, für die JavaScript-Rendering erforderlich ist.
Erstellen Sie zunächst eine neue Datei in Ihrem Projekt mit dem Namen puppeteerScraping.js. Diese Datei enthält den Puppeteer-Code zum Scrapen einer Website mithilfe des Proxyservers für Anfragen.
Öffnen Sie Ihre neu erstellte Datei puppeteerScraping.js und fügen Sie den folgenden JavaScript-Code ein:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
args: ['--proxy-server=http://localhost:8080']
});
const page = await browser.newPage();
await page.goto('http://toscrape.com/');
const content = await page.content();
console.log(content); // Outputs the page HTML
await browser.close();
})();
In diesem Code initialisieren Sie Puppeteer, um einen Headless-Browser zu starten, und geben an, dass er Ihren lokalen Proxyserver verwenden soll. Der Browser öffnet eine neue Seite, navigiert zu http://toscrape.comund ruft dann den HTML-Inhalt der Seite ab. Sobald der Inhalt in der Konsole angemeldet ist, wird die Browsersitzung geschlossen.
Um Ihr Skript auszuführen, navigieren Sie in Ihrem Terminal oder Ihrer Shell zu dem Ordner, der puppeteerScraping.js enthält. Führen Sie das Skript mit dem folgenden Befehl aus:
node puppeteerScraping.js
Nach dem Ausführen des Skripts öffnet Puppeteer die URL http://toscrape.com/ mithilfe des Proxyservers. Sie sollten den HTML-Inhalt der Seite in Ihrem Terminal gedruckt sehen. Dies zeigt an, dass Ihr Puppeteer-Skript die Webseite korrekt über den lokalen Proxy scrapt.
Die erwartete Ausgabe sollte der vorherigen ähnlich sein, und Sie sollten sehen, dass Ihre Anfrage im Fenster mitmproxy protokolliert wird:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Eine bessere Alternative: Der Bright Data-Proxyserver
Wenn Sie Ihre Web-Scraping-Funktionen verbessern möchten, sollten Sie die Verwendung von Bright Data in Betracht ziehen. Der Bright Data-Proxyserver bietet eine fortschrittliche Lösung für die Verwaltung Ihrer Webanfragen.
Bright Data bietet verschiedene Proxyserver an, z. B. Proxys für Privathaushalte, ISP, Rechenzentren und mobile Geräte, mit denen Sie von verschiedenen geografischen Standorten aus auf jede Website zugreifen können. Auf diese Weise können Sie verschiedene Benutzeragenten emulieren und die Anonymität wahren.
Bright Data bietet auch eine Proxy-Rotation an, die die Effizienz und Anonymität Ihrer Web-Scraping-Aktivitäten verbessert, indem automatisch zwischen verschiedenen Proxys gewechselt wird, um zu verhindern, dass Ihre IP gesperrt wird.
Darüber hinaus können Sie den Scraping-Browser von Bright Data verwenden, einen automatisierten Browser, der über integrierte Entsperrfunktionen für Dinge wie CAPTCHA, Cookies und Browser-Fingerabdruck verfügt. Sie können auch den Web Unlocker von Bright Data nutzen, der mit Algorithmen für maschinelles Lernen ausgestattet ist, um jegliche Blockierung durch die Ziel-Websites zu umgehen und es Ihnen ermöglicht, Daten zu sammeln, ohne blockiert zu werden.
Implementieren Sie Bright Data-Proxy in einem Node.js-Projekt
Um einen Bright Data-Proxy in Ihr Node.js Projekt zu integrieren, müssen Sie sich für eine kostenlose Testversion registrieren. Sobald Ihr Konto aktiv ist, melden Sie sich an, navigieren Sie zu Proxys & Scraping, Infrastruktur und fügen Sie einen neuen Proxy hinzu, indem Sie Private Proxys auswählen:
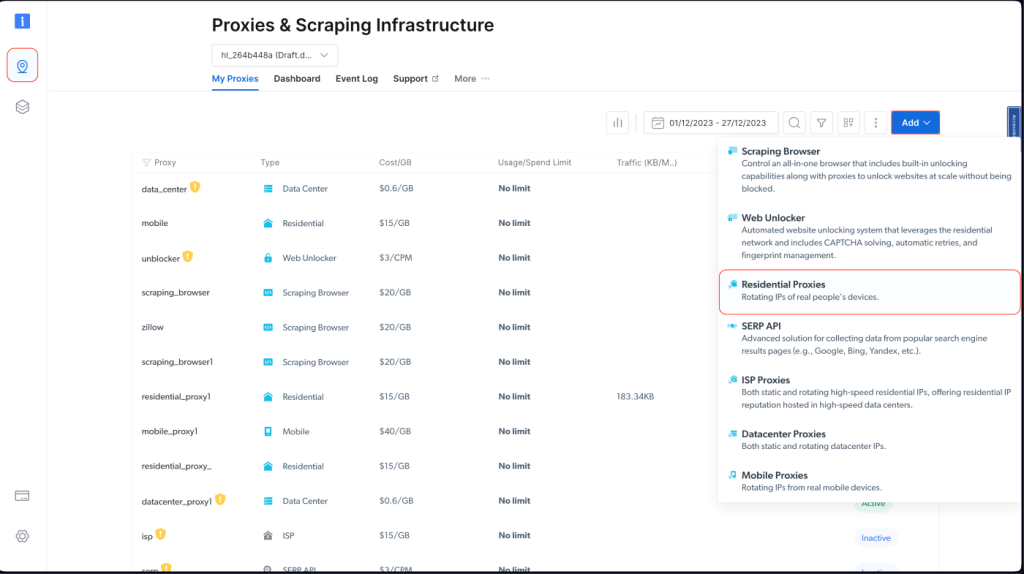
Behalten Sie die Standardeinstellungen bei und schließen Sie die Erstellung Ihres privaten Proxys ab:
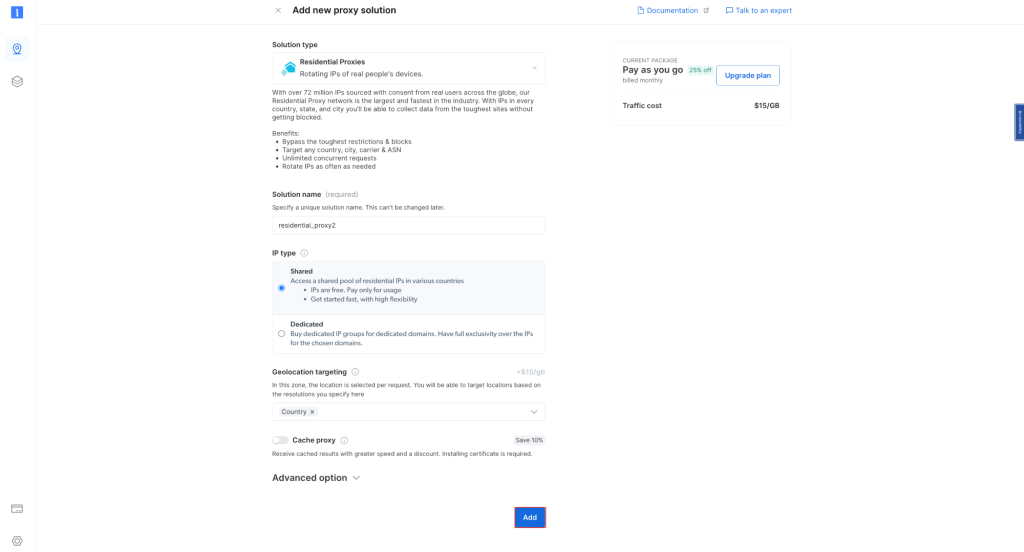
Notieren Sie sich nach der Erstellung die Proxy-Anmeldeinformationen, einschließlich Host, Port, Benutzername und Passwort. Diese benötigen Sie im nächsten Schritt:
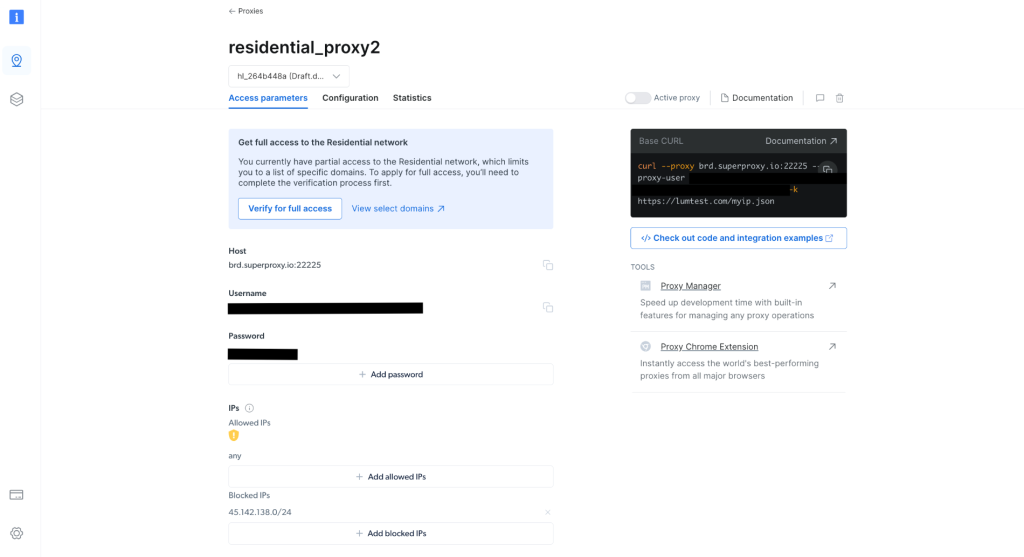
Erstellen Sie in Ihrem Projekt eine scrapingWithBrightData.js-Datei und fügen Sie das folgende Snippet hinzu. Achten Sie darauf, dass Sie den Platzhaltertext durch Ihre Bright Data-Proxy-Anmeldeinformationen ersetzen:
const axios = require('axios');
async function fetchDataWithBrightData(url) {
const proxyOptions = {
proxy: {
host: 'YOUR_BRIGHTDATA_PROXY_HOST',
port: YOUR_BRIGHTDATA_PROXY_PORT,
auth: {
username: 'YOUR_BRIGHTDATA_USERNAME',
password: 'YOUR_BRIGHTDATA_PASSWORD'
}
}
};
try {
const response = await axios.get(url, proxyOptions);
console.log(response.data); // Outputs the fetched data
} catch (error) {
console.error('Error:', error);
}
}
fetchDataWithBrightData('http://lumtest.com/myip.json');
Dieses Skript konfiguriert axios so, dass HTTP-Anfragen über Ihren Bright Data-Proxy weitergeleitet werden. Mithilfe dieser Proxykonfiguration werden Daten von einer angegebenen URL abgerufen. In diesem Beispiel nehmen Sie http://lumtest.com/myip.json, sodass Sie die verschiedenen Proxy-Server-Quellen basierend auf Ihrer Bright Data-Konfiguration sehen können.
Um Ihr Skript auszuführen, navigieren Sie in Ihrem Terminal oder Ihrer Shell zu dem Ordner, der scrapingWithBrightData.js enthält. Führen Sie dann das Skript mit dem folgenden Befehl aus:
node scrapingWithBrightData.js
Sobald Sie den Befehl ausgeführt haben, sollten Sie den Standort Ihrer IP-Adresse auf Ihrer Konsole ausgeben lassen, was hauptsächlich mit dem Proxyserver von Bright Data zusammenhängt.
Die erwartete Ausgabe ähnelt der folgenden:
{
ip: '108.53.191.230',
country: 'US',
asn: { asnum: 701, org_name: 'UUNET' },
geo: {
city: 'Jersey City',
region: 'NJ',
region_name: 'New Jersey',
postal_code: '07302',
latitude: 40.7182,
longitude: -74.0476,
tz: 'America/New_York',
lum_city: 'jerseycity',
lum_region: 'nj'
}
}
Wenn Sie das Skript nun erneut mit Node scrapingWithBrightData.js ausführen, werden Sie feststellen, dass der Bright Data-Proxyserver eine andere IP-Adresse verwendet. Dies bestätigt, dass Bright Data jedes Mal, wenn Sie Ihr Scraping-Skript ausführen, unterschiedliche Standorte und IP-Adressen verwendet, wodurch Sie Blockaden oder IP-Sperren von den Ziel-Websites umgehen können.
Ihre Ausgabe würde so aussehen:
{
ip: '93.85.111.202',
country: 'BY',
asn: {
asnum: 6697,
org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'
},
geo: {
city: 'Orsha',
region: 'VI',
region_name: 'Vitebsk',
postal_code: '211030',
latitude: 54.5081,
longitude: 30.4172,
tz: 'Europe/Minsk',
lum_city: 'orsha',
lum_region: 'vi'
}
}
Die übersichtliche Oberfläche und die Einstellungen von Bright Data machen es jedem, auch Anfängern, leicht, die leistungsstarken Proxy-Management-Funktionen effektiv zu nutzen.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie Proxys mit Node.js verwenden. Ohne geeignete Proxy-Management-Lösungen wie Bright Data können Sie auf Herausforderungen wie IP-Sperren und eingeschränkten Zugriff auf Ziel-Websites stoßen, was Ihre Scraping-Bemühungen behindern kann. Sie haben auch gelernt, wie einfach es ist, die Bright Data-Proxys zu verwenden, um Ihre Web-Scraping-Bemühungen zu verbessern. Diese Server tragen nicht nur zu Robustheit und Effizienz zu Ihrem Datenerfassungsprozess bei, sondern bieten auch die Vielseitigkeit, die für verschiedene Scraping-Szenarien erforderlich ist.
Wenn Sie diese Fähigkeiten in die Praxis umsetzen, denken Sie daran, wie wichtig es ist, sich an die Bedingungen der Website und die Datenschutzgesetze zu halten. Es ist wichtig, verantwortungsbewusst zu scrapen und dabei die von Websites festgelegten Regeln zu beachten. Mit dem Wissen, das Sie erworben haben, insbesondere mit den Funktionen, die die Bright Data-Proxys bieten, sind Sie gut auf erfolgreiches und ethisches Web-Scraping vorbereitet. Viel Spaß beim Scraping!
Der gesamte Code für dieses Tutorial ist in diesem GitHub-Repository verfügbar.



