

In diesem Artikel werden wir folgende Themen behandeln:
- PhantomJS entmystifizieren
- Die Vor- und Nachteile der Verwendung von PhantomJS für das Crawling von Daten
- Eine Schritt-für-Schritt-Anleitung zur Datenerfassung mit PhantomJS
- Datenautomatisierung: Einfachere Alternativen zum manuellen Scraping
Entmystifizierung von PhantomJS
PhantomJS ist ein „headless Webbrowser”. Das bedeutet, dass es keine grafische Benutzeroberfläche (GUI) gibt, sondern dass es nur mit Skripten läuft (wodurch es schlanker, schneller und damit effizienter ist). Es kann verwendet werden, um verschiedene Aufgaben mit JavaScript (JS) zu automatisieren, wie z. B. das Testen von Code oder das Sammeln von Daten.
Anfängern würde ich empfehlen, PhantomJS zunächst mit „npm” in Ihrer CLI auf Ihrem Computer zu installieren. Dazu führen Sie den folgenden Befehl aus:
npm install phantomjs -g
Jetzt steht Ihnen der Befehl „phantomjs“ zur Verfügung.
Vor- und Nachteile der Verwendung von PhantomJS für das Crawling von Daten
PhantomJS hat viele Vorteile, darunter die „Headless”-Funktion, die, wie oben erläutert, das Programm schneller macht, da keine Grafiken geladen werden müssen, um Informationen zu testen oder abzurufen.
PhantomJS kann effizient eingesetzt werden, um Folgendes zu erreichen:
Bildschirmaufnahme
PhantomJS kann dabei helfen, das Erfassen und Speichern von PNG-, JPEG- und sogar GIF-Dateien zu automatisieren. Diese Funktion erleichtert die Durchführung von Front-End-Benutzeroberflächen-/Erfahrungsprüfungen erheblich. Sie können beispielsweise die Befehlszeile „Phantomjs amazon.js“ ausführen, um Bilder von Produktlisten von Mitbewerbern zu sammeln oder um sicherzustellen, dass die Produktlisten Ihres Unternehmens korrekt angezeigt werden.
Seitenautomatisierung
Dies ist ein großer Vorteil von PhantomJS, da es Entwicklern hilft, viel Zeit zu sparen. Durch Ausführen von Befehlszeilen wie Phantomjs userAgent.js können Entwickler JS-Code in Bezug auf eine bestimmte Webseite schreiben und überprüfen. Der größte Zeitvorteil besteht darin, dass dieser Prozess automatisiert und ohne Öffnen eines Browsers durchgeführt werden kann.
Testen
PhantomJS ist beim Testen von Websites von Vorteil, da es den Prozess rationalisiert, ähnlich wie andere beliebte Web-Scraping-Tools wie Selenium. Headless Browsing ohne GUI bedeutet, dass das Scannen nach Problemen schneller erfolgen kann, wobei Fehlercodes auf Befehlszeilenebene entdeckt und ausgegeben werden.
Entwickler integrieren PhantomJS auch in verschiedene Arten von Continuous-Integration-Systemen (CI), um Code zu testen, bevor er live geht. Dies hilft Entwicklern, fehlerhaften Code in Echtzeit zu beheben und sorgt für reibungslosere Live-Projekte.
Netzwerküberwachung / Datenerfassung
PhantomJS kann auch zur Überwachung des Netzwerktraffics/der Netzwerkaktivität verwendet werden. Viele Entwickler programmieren es so, dass es beim Sammeln von Zieldaten helfen kann, wie z. B.:
- Die Leistung einer bestimmten Webseite
- Wenn Codezeilen hinzugefügt/entfernt werden
- Daten zu Aktienkursschwankungen
- Influencer-/Engagement-Daten beim Scraping von Websites wie Instagram
Zu den Nachteilen der Verwendung von PhantomJS gehören:
- Es kann von böswilligen Akteuren für automatisierte Angriffe genutzt werden (hauptsächlich „dank” der Tatsache, dass es keine Benutzeroberfläche verwendet)
- Es kann sich manchmal als schwierig erweisen, wenn es um Full-Cycle-/End-to-End-Tests und Funktionstests geht.
Eine Schritt-für-Schritt-Anleitung zur Datenerfassung mit PhantomJS
PhantomJS ist unter NodeJS-Entwicklern sehr beliebt, daher zeigen wir Ihnen ein Beispiel für die Verwendung in einer NodeJS-Umgebung. Das Beispiel zeigt, wie Sie den HTML-Inhalt von der URL abrufen können.
Schritt 1: package.json einrichten und npm-Pakete installieren
Erstellen Sie einen Projektordner und darin eine Datei „package.json“.
{
"name": "phantomjs-example",
"version": "1.0.0",
"title": "PhantomJS Example",
"description": "PhantomJS Example",
"keywords": [
"phantom example"
],
"main": "./index.js",
"scripts": {
„inst”: „rm -rf node_modules && rm package-lock.json && npm install”,
„dev”: „nodemon index.js”
},
„dependencies”: {
„phantom”: „^6.3.0”
}
}
Führen Sie dann diesen Befehl in Ihrem Terminal aus: $ npm install. Dadurch wird Phantom in Ihrem lokalen Projektordner „node_modules” installiert.
Schritt 2: Erstellen Sie ein Phantom-JS-Skript
Erstellen Sie ein JS-Skript und nennen Sie es „index.js”
const phantom = require('phantom');
const main = async () => {
const instance = await phantom.create();
const page = await instance.createPage();
await page.on('onResourceRequested', function(requestData) {
console.info('Requesting', requestData.url);
});
const url = 'https://example.com/';
console.log('URL::', url);
const status = await page.open(url);
console.log('STATUS::', status);
const content = await page.property('content');
console.log('CONTENT::', content);
await instance.exit();
};
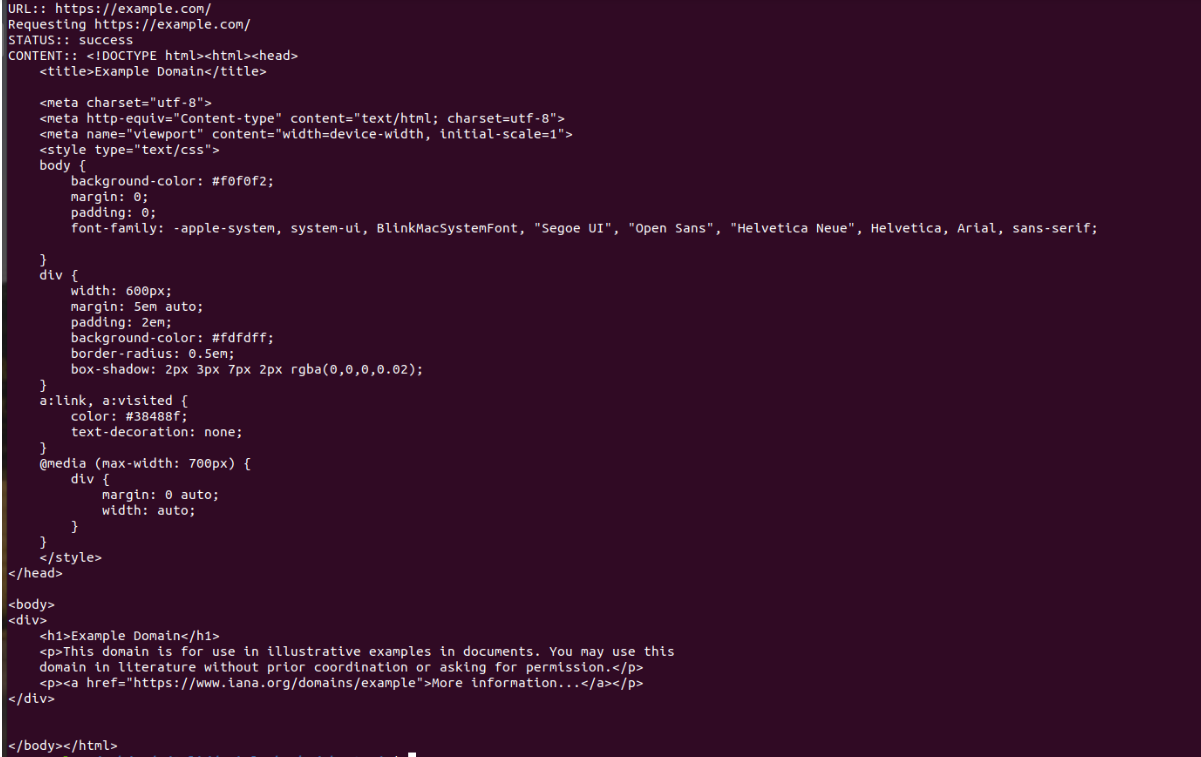
main().catch(console.log);Schritt 3: Führen Sie das JS-Skript aus
Um das Skript zu starten, führen Sie in Ihrem Terminal folgenden Befehl aus: $ node index.js. Das Ergebnis ist HTML-Inhalt.
Datenautomatisierung: Einfachere Alternativen zum manuellen Scraping
Wenn es um das Scraping von Daten in großem Umfang geht, ziehen es einige Unternehmen möglicherweise vor, Alternativen zu PhantomJS zu verwenden.
Dazu gehören:
- Proxys: Das Web- Scraping mit Proxys kann insofern von Vorteil sein, als es Benutzern ermöglicht, Daten in großem Umfang zu sammeln und eine unbegrenzte Anzahl gleichzeitiger Anfragen zu senden. Proxys können auch dabei helfen, Blockaden der Zielwebsite wie Ratenbeschränkungen oder geolokalisierungsbasierte Sperren zu umgehen. In diesem Fall können Unternehmen länderspezifische/städtenspezifische Mobile-Proxys und Residential-IPs/Geräte nutzen, um Datenanfragen weiterzuleiten, wodurch sie genauere benutzerspezifische Daten abrufen können (z. B. Preise von Mitbewerbern, Werbekampagnen und Google-Suchergebnisse).
- Gebrauchsfertige Datensätze: Datensätze sind im Wesentlichen „Informationspakete”, die bereits gesammelt wurden und zur sofortigen Verwendung an Algorithmen/Teams übermittelt werden können. Sie enthalten in der Regel Informationen von einer Zielwebsite und werden durch relevante Websites aus dem gesamten Internet angereichert (z. B. Informationen zu Produkten in einer relevanten Kategorie bei mehreren Anbietern und einer Vielzahl von E-Commerce-Marktplätzen). Datensätze können auch regelmäßig aktualisiert werden, um sicherzustellen, dass alle Datenpunkte auf dem neuesten Stand sind. Der große Vorteil hierbei ist, dass keine Zeit und keine Ressourcen in die Datenerfassung investiert werden müssen, sodass mehr Zeit für die Datenanalyse und die Schaffung von Mehrwert für die Kunden zur Verfügung steht.
- Vollautomatisierte Web-Scraper-APIs: Die Web-Scraper-API ist eine benutzerfreundliche, code- und infrastrukturfreie, anpassbare Lösung zur Datenerfassung. Sie ermöglicht es Unternehmen, strukturierte Webdaten mühelos zu erfassen, ohne sich um die Entwicklung und Wartung von Software oder Hardware kümmern zu müssen.
Sprechen Sie mit einem der Datenexperten von Bright Data, um herauszufinden, welche Produkte Ihren Anforderungen im Bereich Web-Scraping am besten entsprechen.





