

Befolgen Sie diese Schritt-für-Schritt-Anleitung und lernen Sie, wie Sie ein Web-Scraping-Python-Skript für Indeed erstellen, um automatisch Daten zu Stellenangeboten abzurufen.
Dieser Leitfaden behandelt folgende Themen:
- Warum Jobdaten aus dem Internet scrapen?
- Bibliotheken und Tools zum Scraping von Indeed
- Scraping von Jobdaten aus Indeed mit Selenium
Warum Jobdaten aus dem Internet scrapen?
Das Web-Scraping von Jobdaten aus dem Internet ist aus mehreren Gründen nützlich, darunter:
- Marktforschung: Unternehmen und Arbeitsmarktanalysten können Informationen über Branchentrends sammeln. Dazu gehören beispielsweise die Frage, welche Fähigkeiten besonders gefragt sind oder in welchen geografischen Regionen das Beschäftigungswachstum am stärksten ist. Außerdem können Sie die Einstellungsaktivitäten Ihrer Mitbewerber beobachten.
- Optimierung der Jobsuche und -vermittlung: Hilft Arbeitssuchenden, Stellenanzeigen aus verschiedenen Quellen zu durchsuchen, um Positionen zu finden, die ihren Qualifikationen und Präferenzen entsprechen.
- Optimierung der Personalbeschaffung und des Personalwesens: Unterstützung des Einstellungsprozesses durch Erleichterung der Personalbeschaffung und Hilfe beim Verständnis der Gehaltsentwicklungen auf dem Markt und der von Bewerbern gewünschten Leistungen.
Somit sind Jobdaten sowohl für Arbeitgeber als auch für Arbeitssuchende nützlich.
Wenn es um Job-Listing-Scraper geht, muss ein wichtiger Aspekt hervorgehoben werden. Die Zielplattform muss öffentlich sein. Mit anderen Worten: Sie muss auch nicht angemeldeten Nutzern die Jobsuche ermöglichen. Denn das Scraping von Daten hinter einer Login-Barriere kann aus rechtlichen Gründen zu Problemen führen.
Das bedeutet, dass LinkedIn aus der Gleichung herausfällt. Welche anderen Jobplattformen bleiben übrig? Indeed, eine der führenden Online-Jobplattformen!
Bibliotheken und Tools für das Scraping von Indeed
Python gilt dank seiner Syntax, seiner Benutzerfreundlichkeit und seines reichhaltigen Ökosystems an Bibliotheken als eine der besten Sprachen für das Web-Scraping. Also, legen wir los. Schauen Sie sich unseren Leitfaden zum Web-Scraping mit Python an.
Nun müssen Sie aus den vielen verfügbaren Bibliotheken die richtigen für das Web-Scraping auswählen. Um eine fundierte Entscheidung zu treffen, erkunden Sie Indeed in Ihrem Browser. Sie werden feststellen, dass die meisten Daten auf der Website nach einer Interaktion abgerufen werden. Das bedeutet, dass die Website stark auf AJAX setzt, um Inhalte dynamisch zu laden und zu aktualisieren, ohne die Seite neu zu laden. Um Web-Scraping auf einer solchen Website durchzuführen, benötigen Sie ein Tool, das JavaScript ausführen kann. Dieses Tool ist Selenium!
Selenium ermöglicht das Web-Scraping dynamischer Websites in Python. Es rendert Websites in einem steuerbaren Webbrowser und führt die von Ihnen vorgegebenen Operationen aus. Dank Selenium können Sie Daten auch dann scrapen, wenn die Zielwebsite JavaScript für das Rendern oder Abrufen von Daten verwendet.
Erfahren Sie, wie Sie Stellenanzeigen von Websites wie Indeed scrapen können!
Scraping von Jobdaten aus Indeed mit Selenium
Folgen Sie dieser Schritt-für-Schritt-Anleitung und erfahren Sie, wie Sie ein Python-Skript zum Web-Scraping von Indeed erstellen.
Schritt 1: Projekt einrichten
Bevor Sie mit dem Web-Scraping beginnen, stellen Sie sicher, dass Sie die folgenden Voraussetzungen erfüllen:
- Python 3+ auf Ihrem Computer installiert: Laden Sie das Installationsprogramm herunter, doppelklicken Sie darauf und folgen Sie den Anweisungen des Installationsassistenten.
- Eine Python-IDE Ihrer Wahl: PyCharm Community Edition oder Visual Studio Code mit der Python-Erweiterung sind zwei gute Optionen.
Jetzt haben Sie alles, was Sie zum Einrichten eines Python-Projekts benötigen!
Öffnen Sie das Terminal und führen Sie die folgenden Befehle aus, um:
- Erstellen Sie einen Ordner „indeed-scraper“.
- Treten Sie ihn
- Initialisieren Sie ihn mit einer virtuellen Python-Umgebung
mkdir indeed-Scraper
cd indeed-Scraper
python -m venv envFühren Sie unter Linux oder macOS den folgenden Befehl aus, um die Umgebung zu aktivieren:
./env/bin/activate
Unter Windows führen Sie Folgendes aus:
envScriptsactivate.ps1
Initialisieren Sie anschließend eine Datei scraper.py mit der folgenden Zeile im Projektordner:
print("Hello, World!")
Derzeit wird nur „Hello, World!” ausgegeben, aber bald wird die Scraping-Logik von Indeed enthalten sein.
Starten Sie sie, um zu überprüfen, ob sie funktioniert, mit:
python Scraper.py
Wenn alles wie geplant funktioniert hat, sollte diese Meldung im Terminal angezeigt werden:
Hallo, Welt!
Nachdem Sie nun wissen, dass das Skript funktioniert, öffnen Sie den Projektordner in Ihrer Python-IDE.
Gut gemacht! Machen Sie sich bereit, Python-Code zu schreiben!
Schritt 2: Installieren Sie die Scraping-Bibliotheken
Wie bereits erwähnt, ist Selenium ein großartiges Tool beim Web-Scraping von Stellenanzeigen von Indeed. Führen Sie den folgenden Befehl in der aktivierten virtuellen Python-Umgebung aus, um es zu den Abhängigkeiten des Projekts hinzuzufügen:
pip install selenium
Dies kann eine Weile dauern, haben Sie also bitte etwas Geduld.
Bitte beachten Sie, dass sich dieses Tutorial auf Selenium 4.11.2 bezieht, das über automatische Treibererkennungsfunktionen verfügt. Wenn Sie eine ältere Version von Selenium auf Ihrem PC installiert haben, aktualisieren Sie diese mit:
pip install selenium -U
Löschen Sie nun scraper.py. Importieren Sie dann das Paket und initialisieren Sie einen Selenium-Scraper mit:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# set up a controllable Chrome instance
# in headless mode
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# Scraping-Logik...
# Schließen Sie den Browser und geben Sie die Ressourcen frei.
driver.quit()
Dieses Skript instanziiert eine Instanz von WebDriver, um eine Chrome-Instanz programmgesteuert zu steuern. Der Browser wird im Hintergrund im Headless-Modus geöffnet, d. h. ohne GUI. Dies ist eine gängige Konfiguration für die Produktion. Wenn Sie stattdessen lieber die vom Skript für Web-Scraping-Jobs auf der Seite ausgeführten Vorgänge verfolgen möchten, kommentieren Sie diese Option aus. Dies ist bei der Entwicklung nützlich.
Stellen Sie sicher, dass Ihre Python-IDE keine Fehler meldet. Ignorieren Sie die Warnungen, die Sie möglicherweise aufgrund der ungenutzten Importe erhalten. Sie sind dabei, die Bibliotheken zu verwenden, um Repository-Daten aus GitHub zu extrahieren!
Perfekt! Jetzt ist es an der Zeit, Ihren Indeed-Python-Web-Scraper zu erstellen.
Schritt 3: Verbinden Sie sich mit der Zielwebseite
Öffnen Sie Indded und suchen Sie nach Stellenangeboten, die Sie interessieren. In dieser Anleitung erfahren Sie, wie Sie Remote-Stellenangebote für Software-Ingenieure in New York scrapen können. Beachten Sie, dass jede andere Indeed-Stellensuche ebenfalls geeignet ist. Die Scraping-Logik ist dieselbe.
So sieht die Zielseite zum Zeitpunkt der Erstellung dieses Artikels im Browser aus:
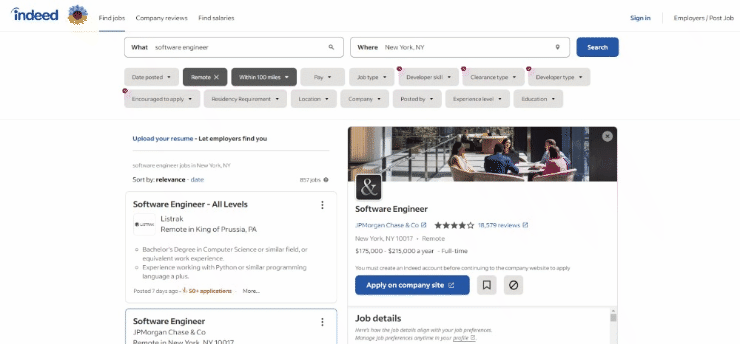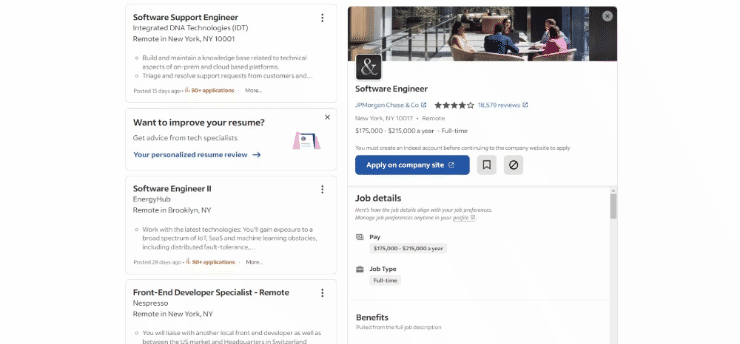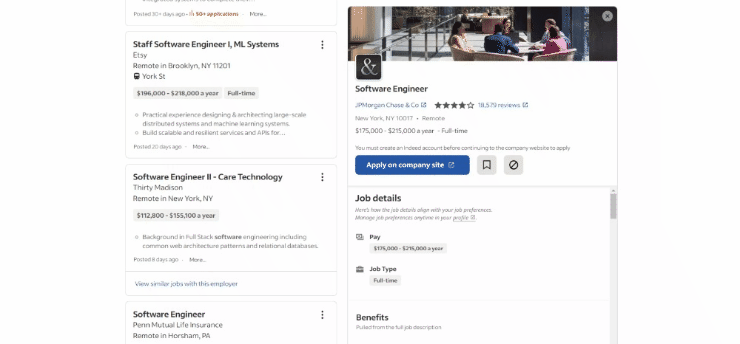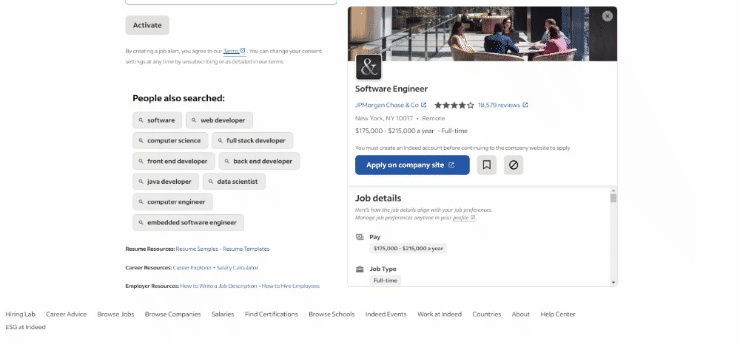
Die URL der Zielseite sieht konkret wie folgt aus:
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100
Wie Sie sehen können, handelt es sich um eine dynamische URL, die sich basierend auf einigen Abfrageparametern ändert.
Sie können dann Selenium verwenden, um eine Verbindung zur Zielseite herzustellen:
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
Die Funktion get() weist den Browser an, die Seite aufzurufen, die durch die als Parameter übergebene URL angegeben ist.
Nach dem Öffnen der Seite sollten Sie die Fenstergröße so einstellen, dass alle Elemente sichtbar sind:
driver.set_window_size(1920, 1080)
So sieht Ihr Skript zum Scraping von Indeed bisher aus:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Einrichten einer steuerbaren Chrome-Instanz
# im Headless-Modus
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# Fenstergröße festlegen, um sicherzustellen, dass Seiten
# nicht im responsiven Modus gerendert werden
driver.set_window_size(1920, 1080)
# Öffnen Sie die Zielseite im Browser.
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# Scraping-Logik...
# Browser schließen und Ressourcen freigeben
driver.quit()
Kommentieren Sie die Option zum Aktivieren des Headless-Modus aus und starten Sie das Skript. Es öffnet sich für den Bruchteil einer Sekunde das untenstehende Fenster, bevor es sich wieder schließt:
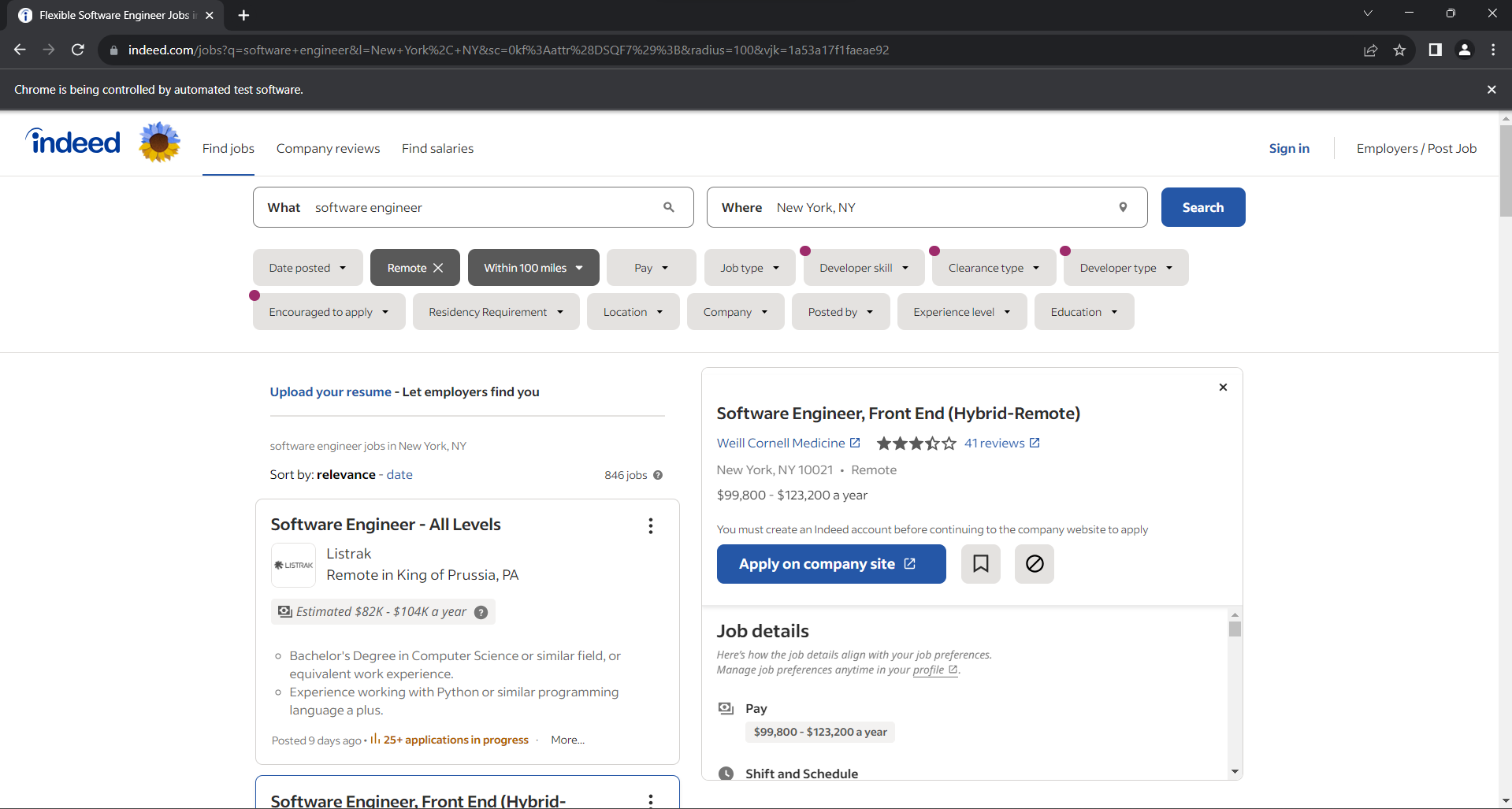
Beachten Sie den Haftungsausschluss „Chrome wird von automatisierter Software gesteuert“. Dieser stellt sicher, dass Selenium wie erwartet funktioniert.
Schritt 4: Machen Sie sich mit der Seitenstruktur vertraut
Bevor Sie mit dem Scraping beginnen, müssen Sie noch einen weiteren wichtigen Schritt durchführen. Das Scraping von Daten aus einer Website umfasst die Auswahl von HTML-Elementen und die Extraktion von Daten aus diesen Elementen. Es ist nicht immer einfach, einen Weg zu finden, um die gewünschten Knoten aus dem DOM zu erhalten. Aus diesem Grund sollten Sie sich etwas Zeit nehmen, um die Seitenstruktur zu analysieren und zu verstehen, wie Sie eine effektive Auswahlstrategie definieren können.
Öffnen Sie Ihren Browser und besuchen Sie die Indeed-Jobsuche-Seite. Klicken Sie mit der rechten Maustaste auf ein beliebiges Element und wählen Sie die Option „Untersuchen“, um die DevTools Ihres Browsers zu öffnen:
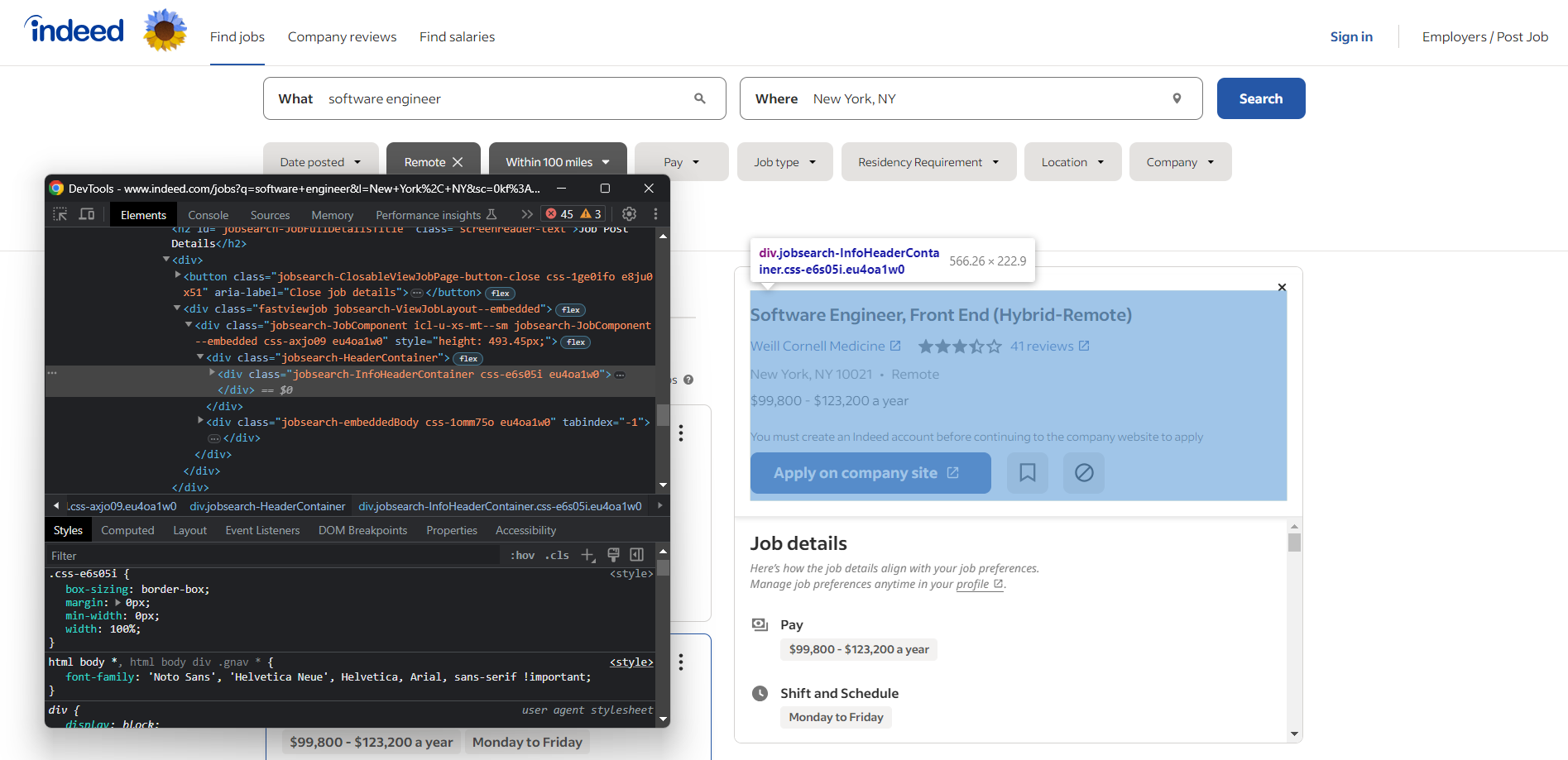
Hier sehen Sie, dass die meisten Elemente, die interessante Daten enthalten, CSS-Klassen wie die folgenden haben:
css-j45z4f,css-1m4cuuf, …e37uo190,eu4oa1w0, …job_f27ade40cc1a3686,job_1a53a17f1faeae92, …
Da diese offenbar zufällig zum Zeitpunkt der Kompilierung generiert werden, sollten Sie sich beim Scraping nicht auf sie verlassen. Stattdessen sollten Sie die Auswahllogik auf Klassen wie den folgenden basieren:
jobsearch-JobInfoHeader-titledatecardOutline
Oder IDs wie:
companyRatingsapplyButtonLinkContainerjobDetailsSection
Beachten Sie außerdem, dass einige Knoten eindeutige HTML-Attribute haben:
data-company-namedata-testid
Dies sind nützliche Informationen, die Sie für Web-Scraping-Jobs von Indeed beachten sollten. Interagieren Sie mit der Seite, um zu untersuchen, wie sie reagiert und welche Daten sie anzeigt. Sie werden feststellen, dass verschiedene Stellenangebote unterschiedliche Info-Attribute haben.
Untersuchen Sie die Zielseite weiter und machen Sie sich mit ihrer DOM-Struktur vertraut, bis Sie bereit sind, fortzufahren.
Schritt 5: Beginnen Sie mit der Extraktion der Jobdaten
Eine einzelne Indeed-Suchseite enthält mehrere Stellenangebote. Sie benötigen also ein Array, um die von der Seite gescrapten Stellenangebote zu verfolgen:
jobs = []Wie Sie im vorherigen Schritt sicher bemerkt haben, werden die Stellenangebote in .cardOutline -Karten angezeigt:
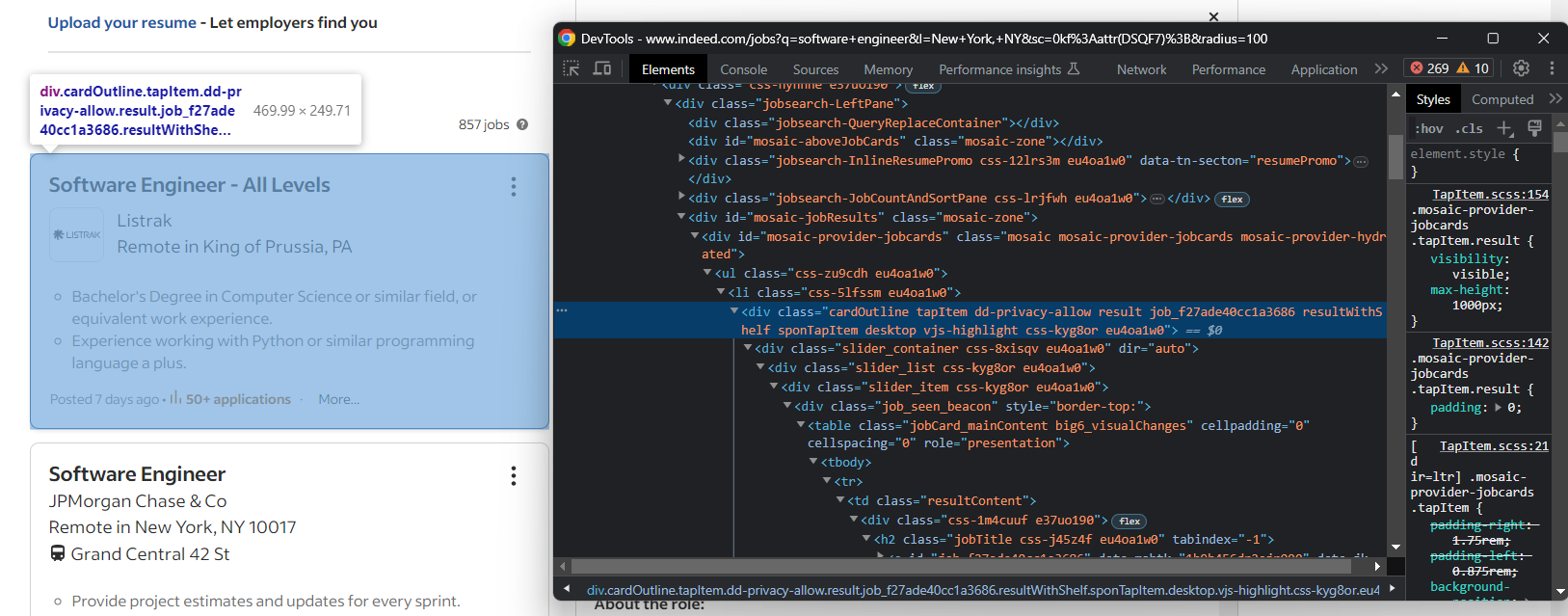
Wählen Sie sie alle mit folgendem Befehl aus:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
Mit der Methode find_elements() von Selenium können Sie Webelemente auf einer Webseite lokalisieren. In ähnlicher Weise gibt es auch die Methode find_element(), um den ersten Knoten zu erhalten, der der Auswahlabfrage entspricht.
By.CSS_SELECTOR weist den Treiber an, eine CSS-Selektor-Strategie zu verwenden. Selenium unterstützt auch:
By.ID: Zum Suchen eines Elements anhand des HTML-Attributs„id“By.TAG_NAME: Zum Suchen von Elementen anhand ihres HTML-TagsBy.XPATH: Zum Suchen von Elementen über einen XPath-Ausdruck
Importieren Sie By mit:
from selenium.webdriver.common.by import By
Durchlaufen Sie die Liste der Jobkarten und initialisieren Sie ein Python-Wörterbuch, in dem die Jobdetails gespeichert werden sollen:
for job_card in job_cards:
# Initialisieren Sie ein Wörterbuch, um die gescrapten Jobdaten zu speichern.
job = {}
# Logik zur Extraktion von Jobdaten...
Eine Stellenanzeige kann mehrere Attribute haben. Da nur ein kleiner Teil davon obligatorisch ist, initialisieren Sie sofort eine Liste von Variablen mit Standardwerten:
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
Nachdem Sie sich nun mit der Seite vertraut gemacht haben, wissen Sie, dass einige Details in der Übersicht der Stellenkarte zu finden sind. Andere befinden sich stattdessen in der Registerkarte „Details”, die bei Interaktion angezeigt wird.
Beispielsweise befinden sich das Erstellungsdatum und die Anzahl der Bewerbungen in der Registerkarte „Zusammenfassung“:
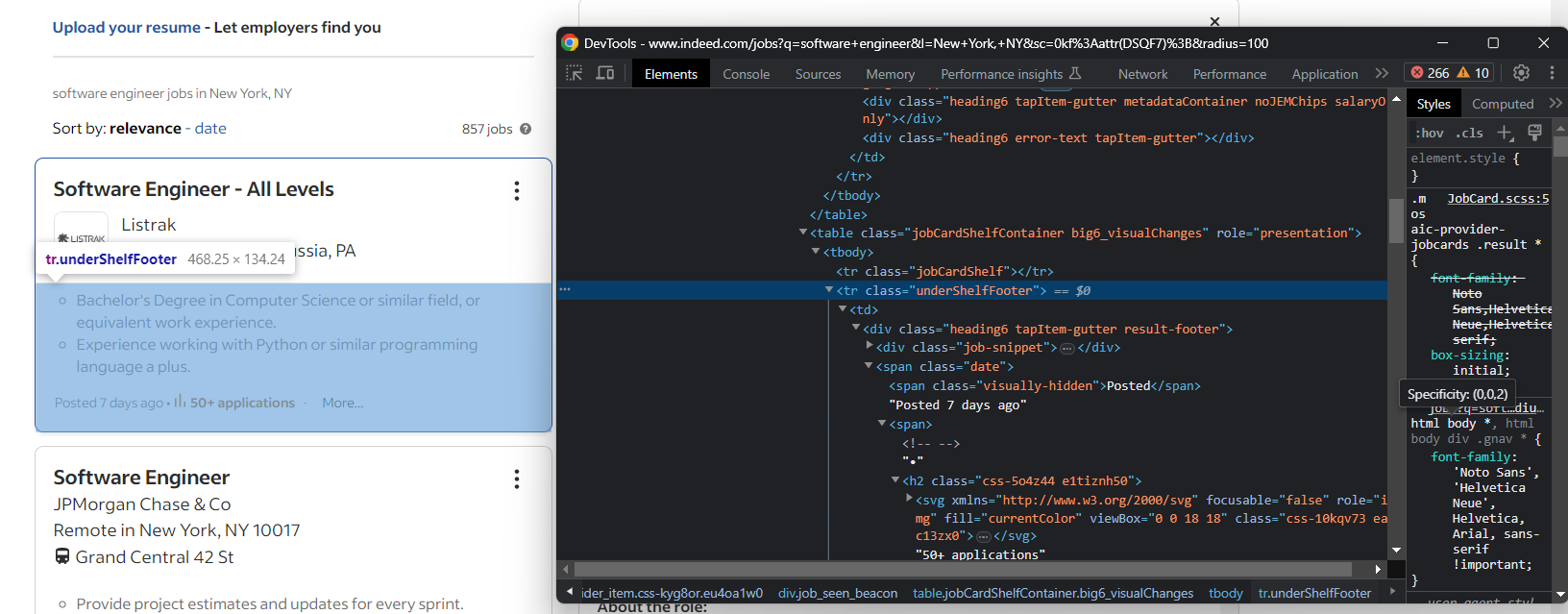
Extrahieren Sie beide mit:
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
except NoSuchElementException:
pass
Dieser Ausschnitt zeigt einige Muster, die für das Web-Scraping von Stellenanzeigen von Indeed entscheidend sind. Da die meisten Info-Elemente optional sind, müssen Sie sich vor dem folgenden Fehler schützen:
selenium.common.exceptions.NoSuchElementException: Meldung: kein solches Element
Selenium löst diesen Fehler aus, wenn versucht wird, ein HTML-Element auszuwählen, das derzeit nicht auf der Seite vorhanden ist.
Importieren Sie die Ausnahme mit:
from selenium.common import NoSuchElementException
Die Anweisung „try ... catch“ stellt sicher, dass das Skript ohne Fehler fortgesetzt wird, wenn das Zielelement nicht im DOM vorhanden ist.
Außerdem sind einige Jobinformationen in Zeichenfolgen enthalten, wie z. B.:
<info_1> • <info_2>
Wenn <info_2> fehlt, lautet das Zeichenfolgenformat stattdessen:
<info_1>
Daher müssen Sie die Logik zur Datenextraktion basierend auf dem Vorhandensein des Zeichens „``•``” ändern.
Bei einem HTML-Element können Sie mit dem Textattribut auf dessen Textinhalt zugreifen. Verwenden Sie die Python-Zeichenfolgen replace(), um die gesammelten Zeichenfolgen zu bereinigen.
Schritt 6: Umgang mit den Anti-Scraping-Maßnahmen von Indeed
Indeed setzt einige Techniken und Technologien ein, um Bots daran zu hindern, auf seine Daten zuzugreifen. Bei der Interaktion mit den Jobkarten öffnet sich beispielsweise von Zeit zu Zeit dieses Modalfenster:
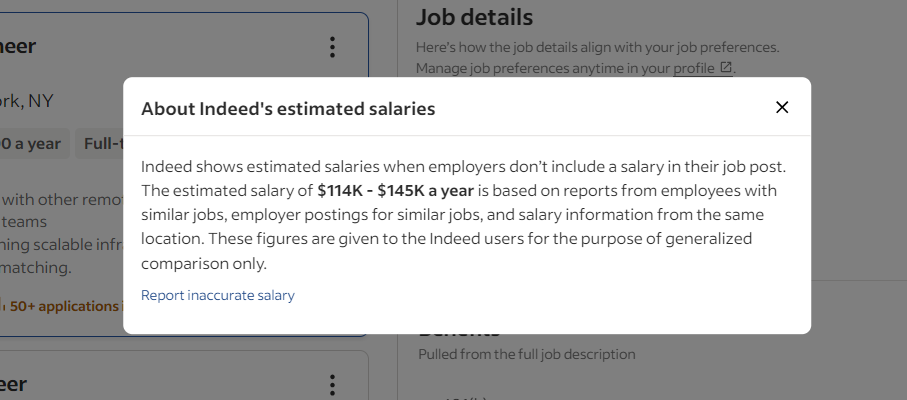
Dieses Popup blockiert die Interaktion. Wenn Sie nicht richtig darauf reagieren, wird Ihr Selenium-Indeed-Skript angehalten. Untersuchen Sie es in den DevTools und achten Sie besonders auf die Schaltfläche „Schließen”:
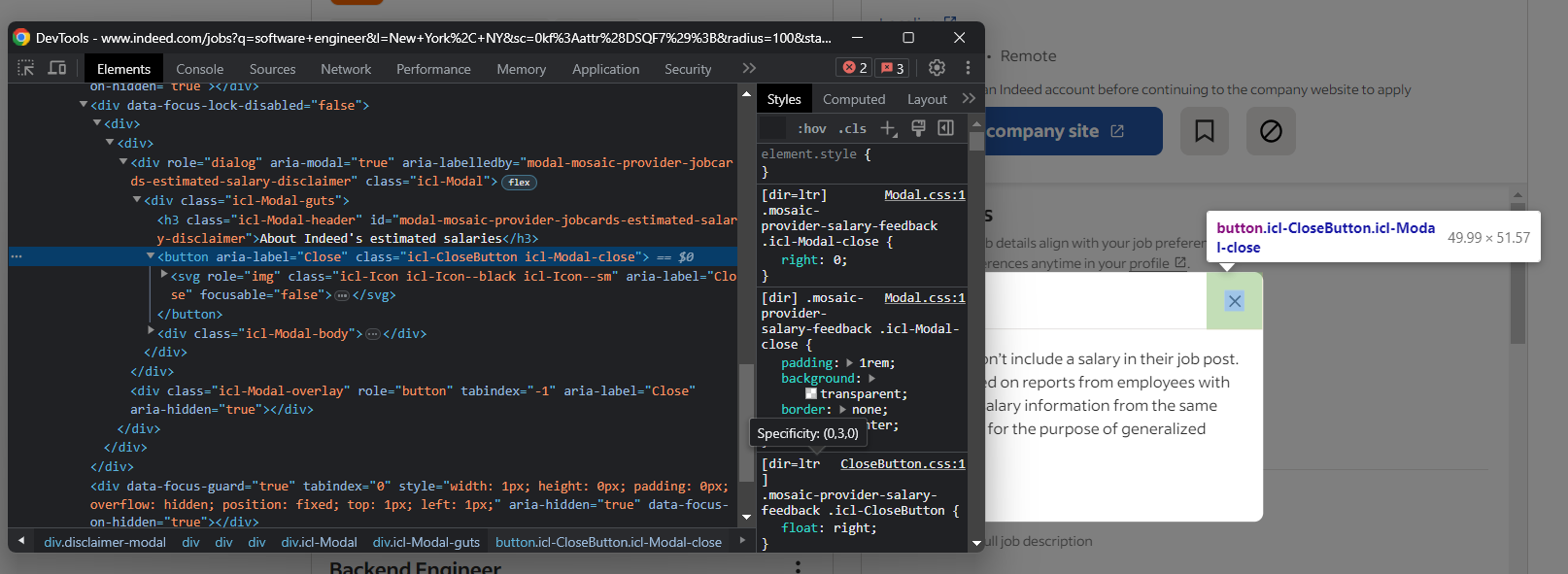
Schließen Sie dieses Modal in Selenium mit:
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
Mit der Methode click() von Selenium können Sie auf das ausgewählte Element im gesteuerten Browser klicken.
Großartig! Dadurch wird das Popup-Fenster geschlossen und Sie können die Interaktion fortsetzen.
Eine weitere Datenschutztechnik, die Sie unbedingt berücksichtigen sollten, ist Cloudflare. Wenn Sie zu viel mit der Seite interagieren und zu viele Anfragen stellen, zeigt Indeed Ihnen diesen Anti-Bot-Bildschirm an:
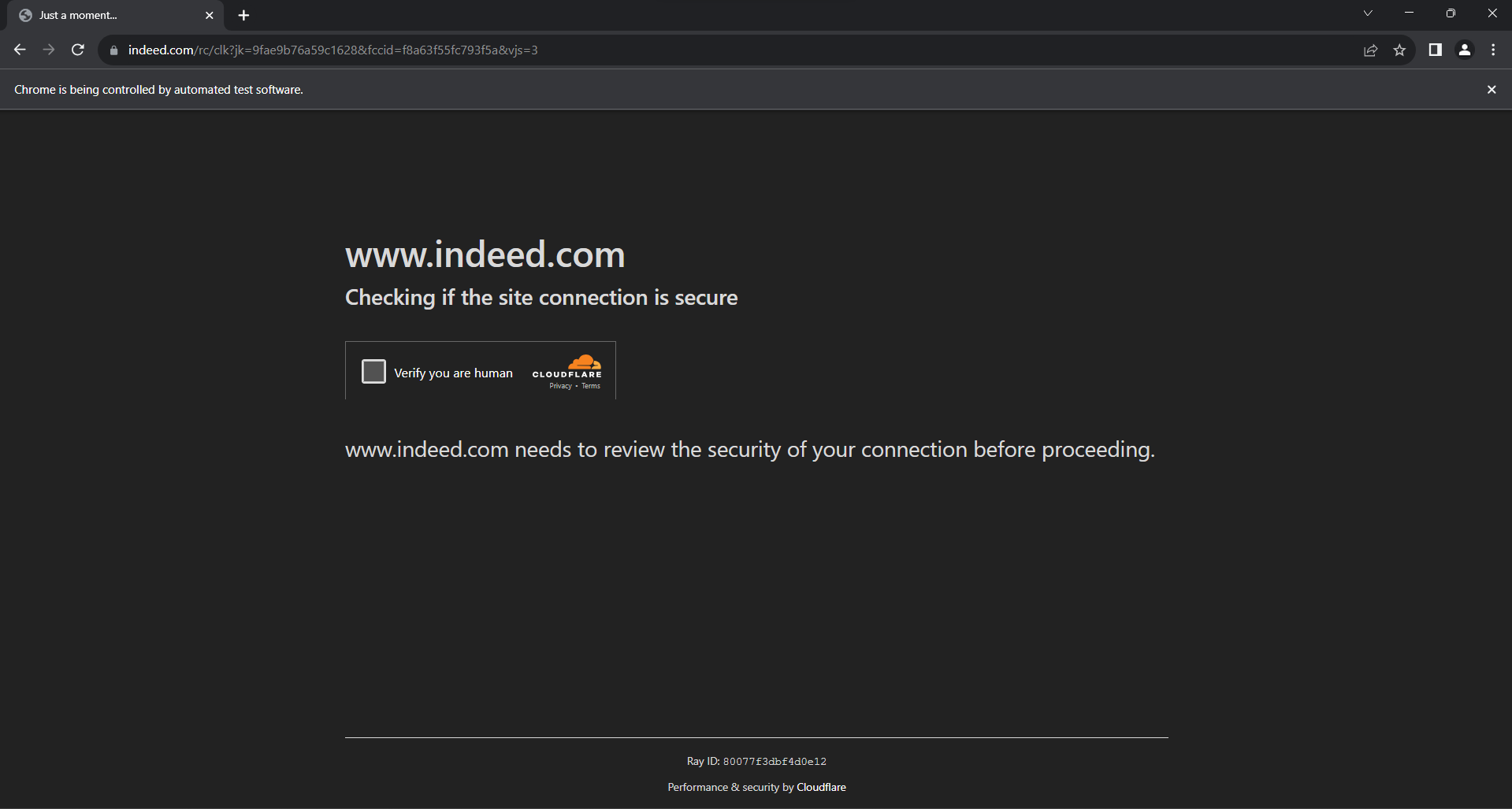
Die CAPTCHA-Lösung für Cloudflare aus Selenium ist eine sehr anspruchsvolle Aufgabe, die ein Premium-Produkt erfordert. Das Scraping von Indeed ist schließlich nicht so einfach. Glücklicherweise können Sie dies vermeiden, indem Sie einige zufällige Verzögerungen in Ihr Skript einbauen.
Stellen Sie sicher, dass die letzte Operation in Ihrer for- Schleife lautet:
time.sleep(random.uniform(1, 5))
Dadurch wird das Skript für eine zufällige Anzahl von Sekunden zwischen 1 und 5 angehalten.
Importieren Sie die erforderlichen Pakete aus der Python-Standardbibliothek mit:
import random
import time
Gut gemacht! Nichts kann Ihr automatisiertes Skript nun noch daran hindern, Indeed zu scrapen.
Schritt 7: Öffnen Sie die Karte mit den Jobdetails
Wenn Sie auf eine Stellenbeschreibung klicken, führt Indeed einen AJAX-Aufruf durch, um die Details sofort abzurufen. Während Sie auf diese Daten warten, zeigt die Seite einen animierten Platzhalter an:
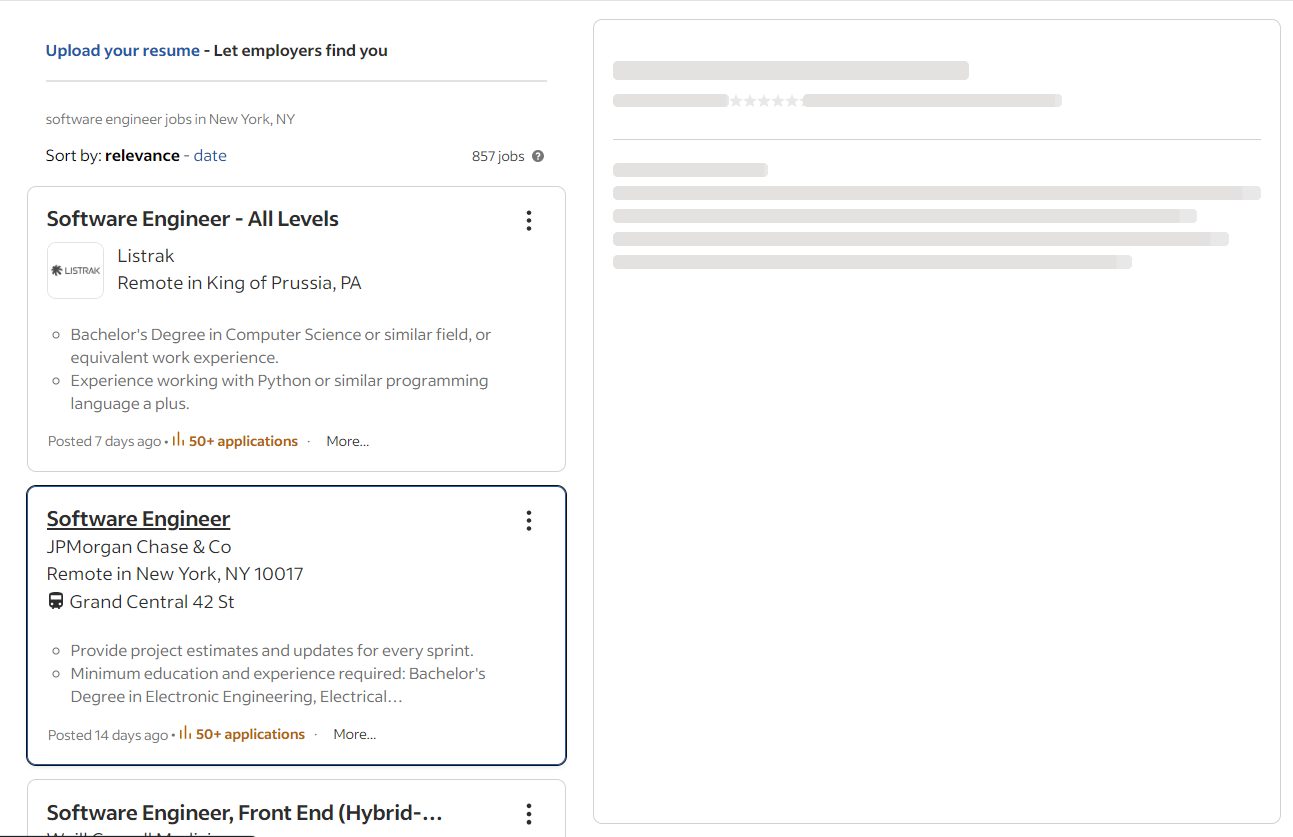
Sie können überprüfen, ob die Detailabschnitte geladen wurden, wenn das folgende Element auf der Seite angezeigt wird:
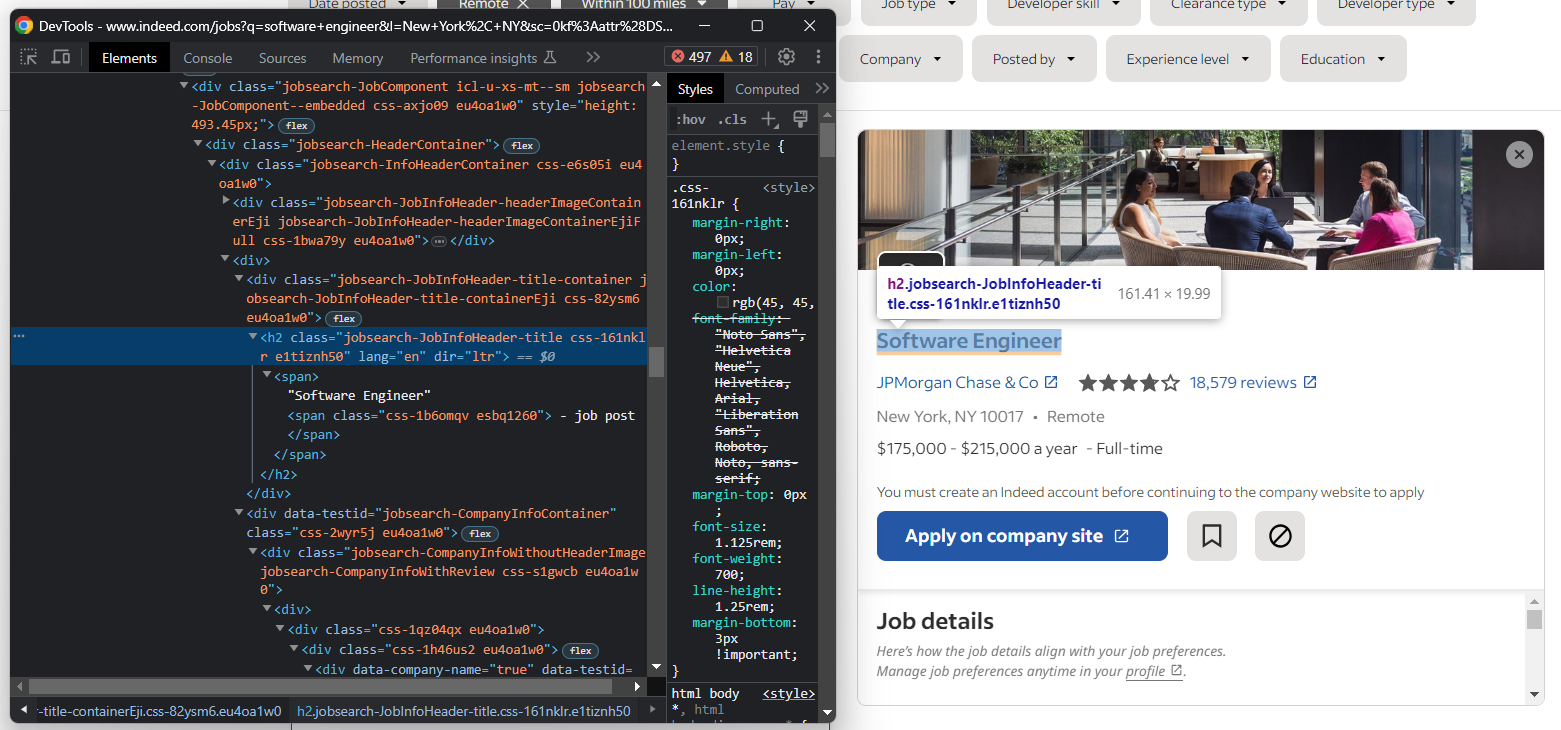
Um also in Selenium Zugriff auf die Job-Detail-Daten zu erhalten, müssen Sie:
- Führen Sie den Klickvorgang aus
- Warten, bis die Seite die gewünschten Daten enthält
Erreichen Sie dies mit:
job_card.click()
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
Mit dem WebDriverWait-Objekt von Selenium können Sie auf das Eintreten einer bestimmten Bedingung warten. In diesem Fall wartet das Skript bis zu 5 Sekunden, bis .jobsearch-JobInfoHeader-title auf der Seite angezeigt wird. Danach wird eine TimeoutException ausgelöst.
Beachten Sie, dass der obige Ausschnitt auch den Titel der Stellenanzeige abruft.
Importieren Sie WebDriverWait und EC:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Von nun an ist das Element, auf das Sie sich konzentrieren sollten, diese Detailspalte:
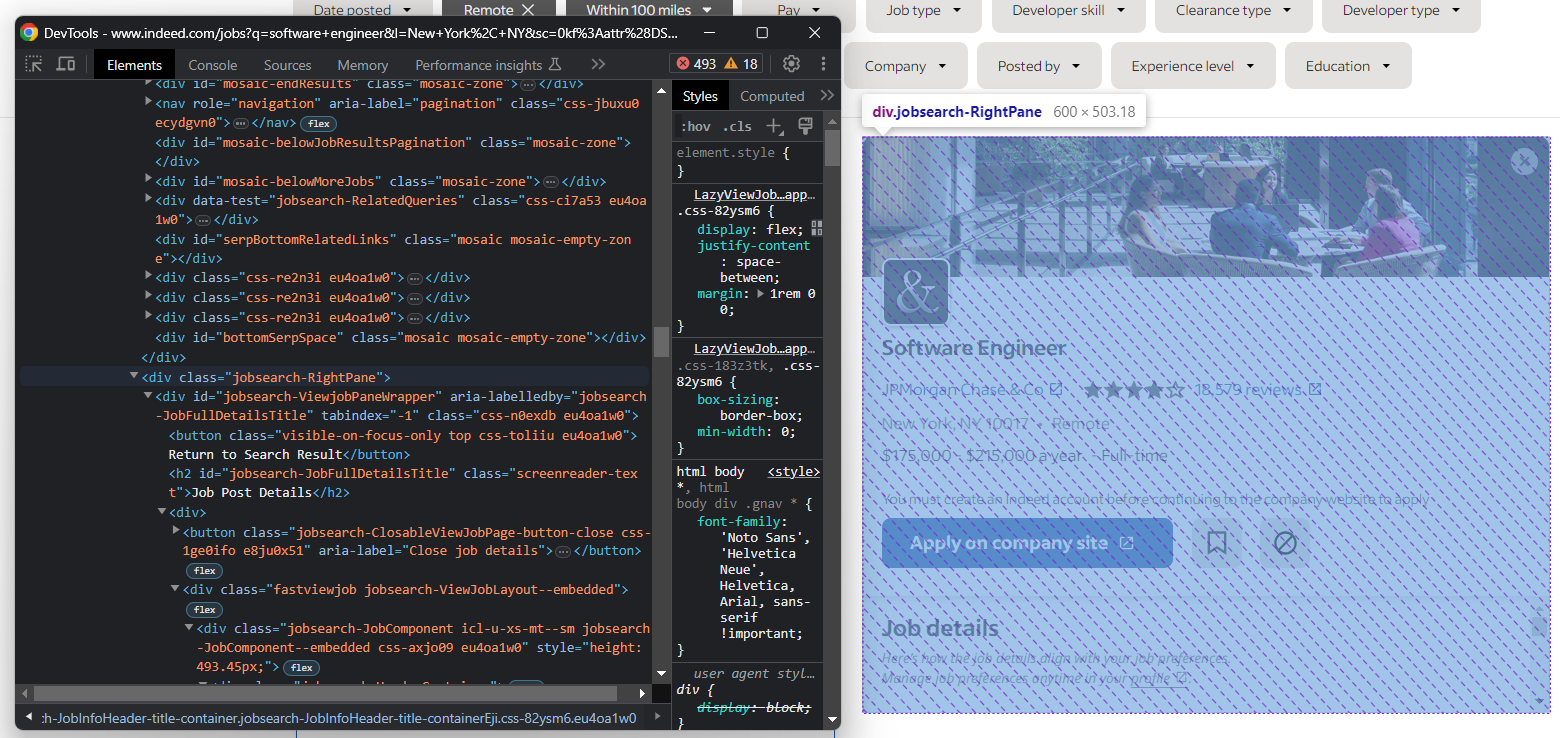
Wählen Sie es aus mit:
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
Fantastisch! Sie sind nun bereit, einige Jobdaten zu scrapen!
Schritt 8: Extrahieren Sie die Jobdetails
Jetzt ist es an der Zeit, die in Schritt 4 definierten Variablen mit einigen Jobdaten zu füllen.
Holen Sie sich den Namen des Unternehmens, das die Stelle ausgeschrieben hat:
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
Extrahieren Sie anschließend Informationen zu den Nutzerbewertungen und der Anzahl der Bewertungen des Unternehmens:
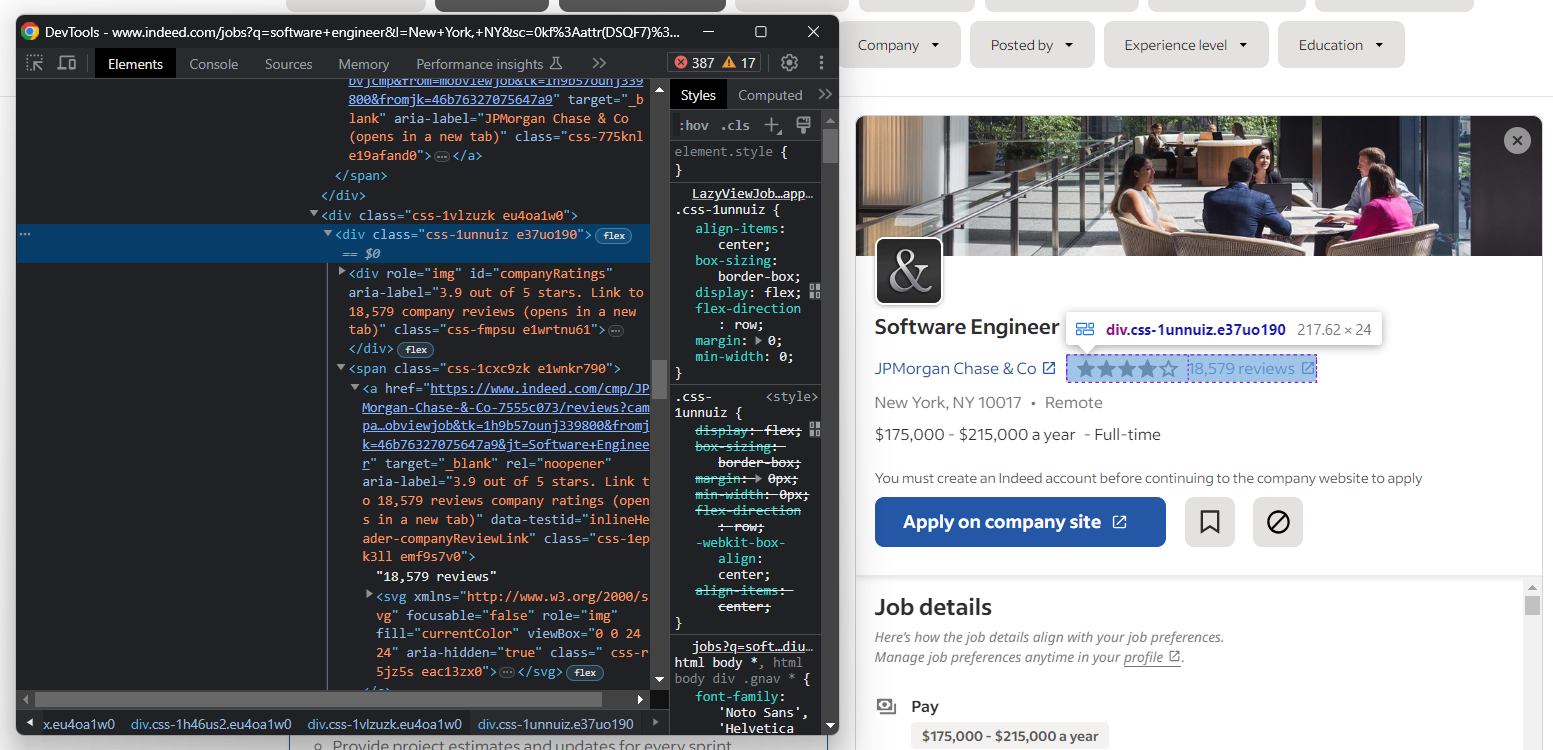
Wie Sie sehen, gibt es keine einfache Möglichkeit, auf das Element zuzugreifen, in dem die Anzahl der Bewertungen gespeichert ist.
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
Als Nächstes konzentrieren Sie sich auf den Standort des Unternehmens:
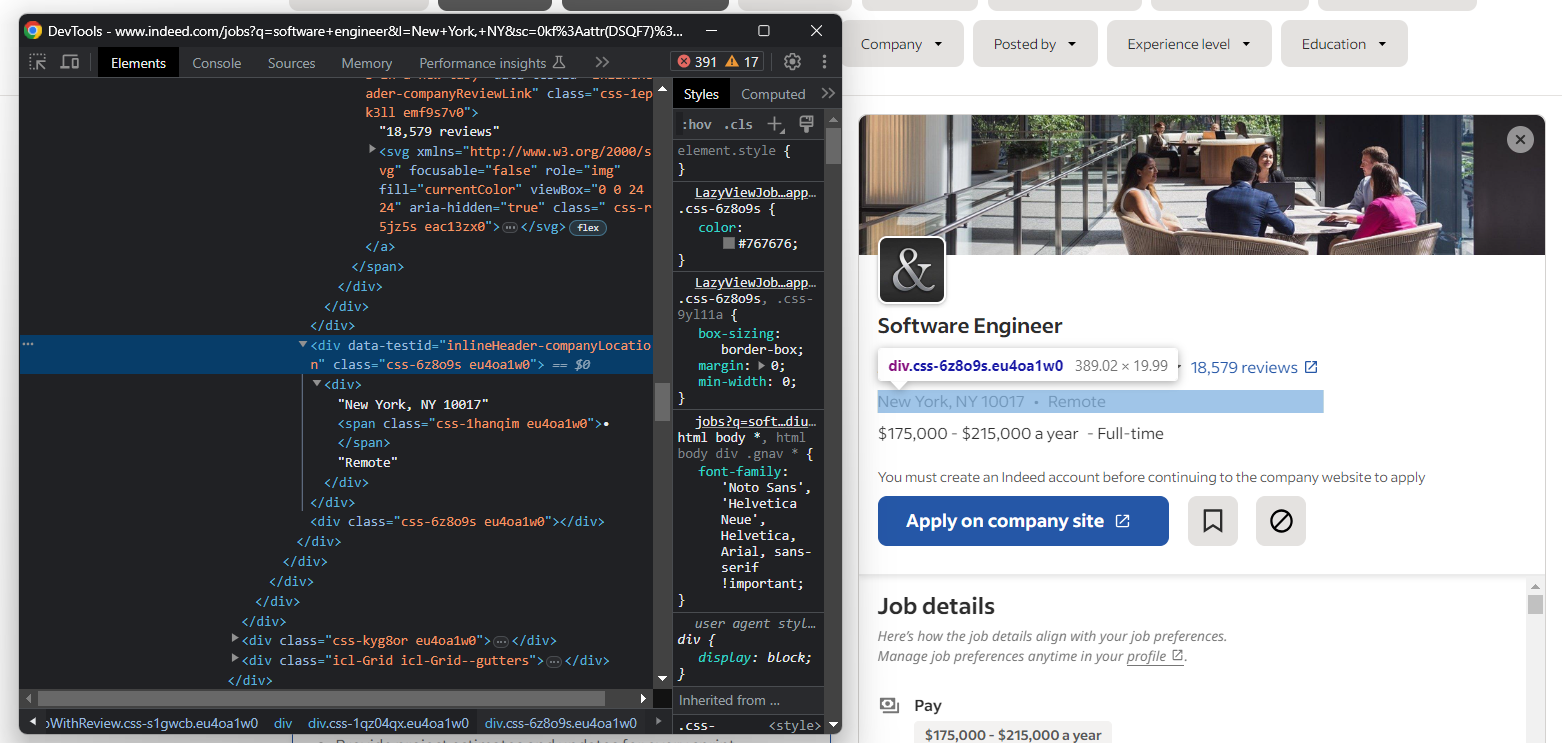
Auch hier müssen Sie das in Schritt 4 erwähnte Muster „``•``” anwenden:
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
Da Sie sich möglicherweise schnell auf die Stelle bewerben möchten, sehen Sie sich auch die Schaltfläche „Auf Unternehmenswebsite bewerben” von Indeed an:
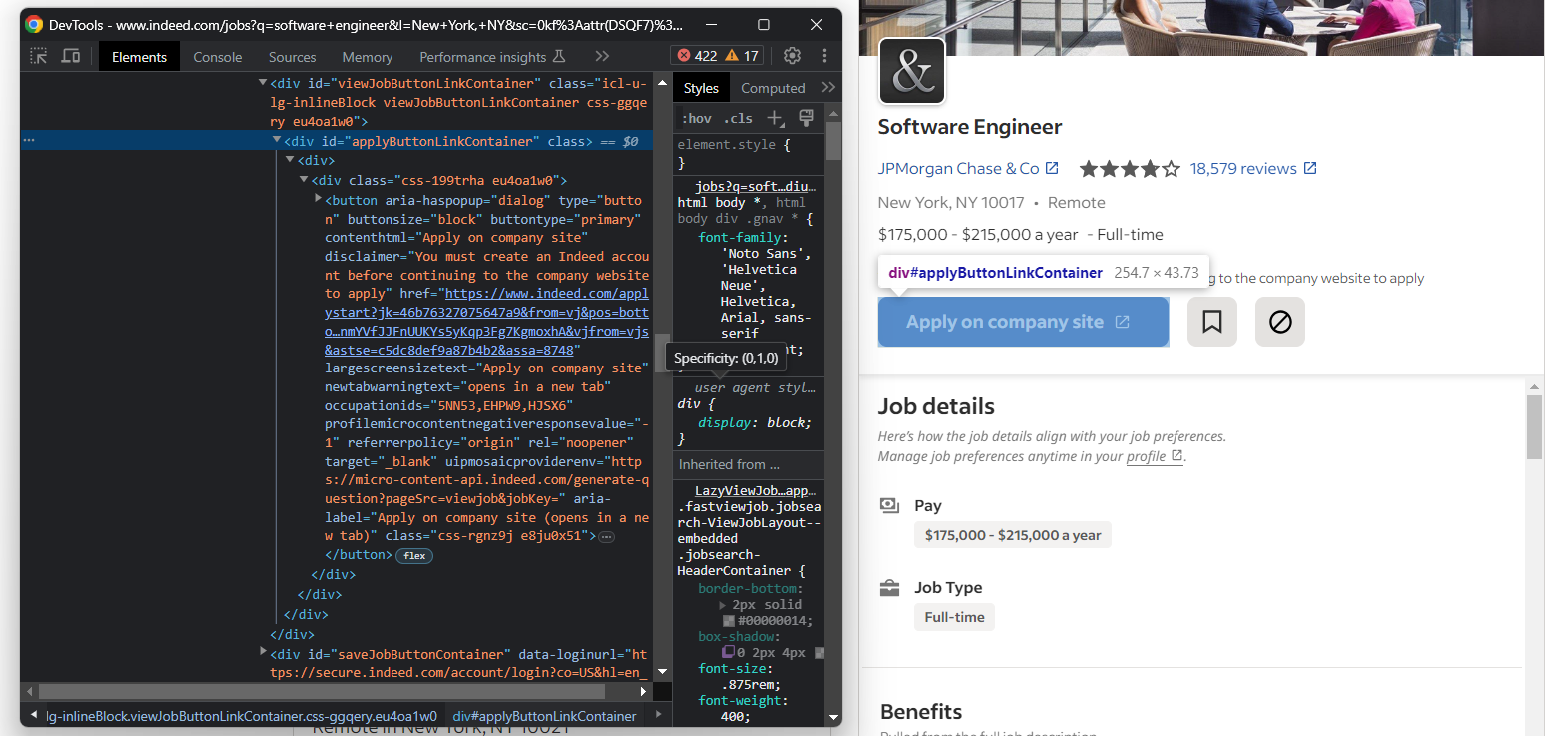
Rufen Sie die Ziel-URL der Schaltfläche mit folgendem Befehl ab:
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
Die Funktion get_attribute() von Selenium gibt den Wert des angegebenen HTML-Attributs zurück.
Jetzt beginnt der knifflige Teil.
Wenn Sie den Abschnitt „Jobdetails” untersuchen, werden Sie feststellen, dass es keine einfache Möglichkeit gibt, die Elemente für die Bezahlung und die Art der Stelle auszuwählen:
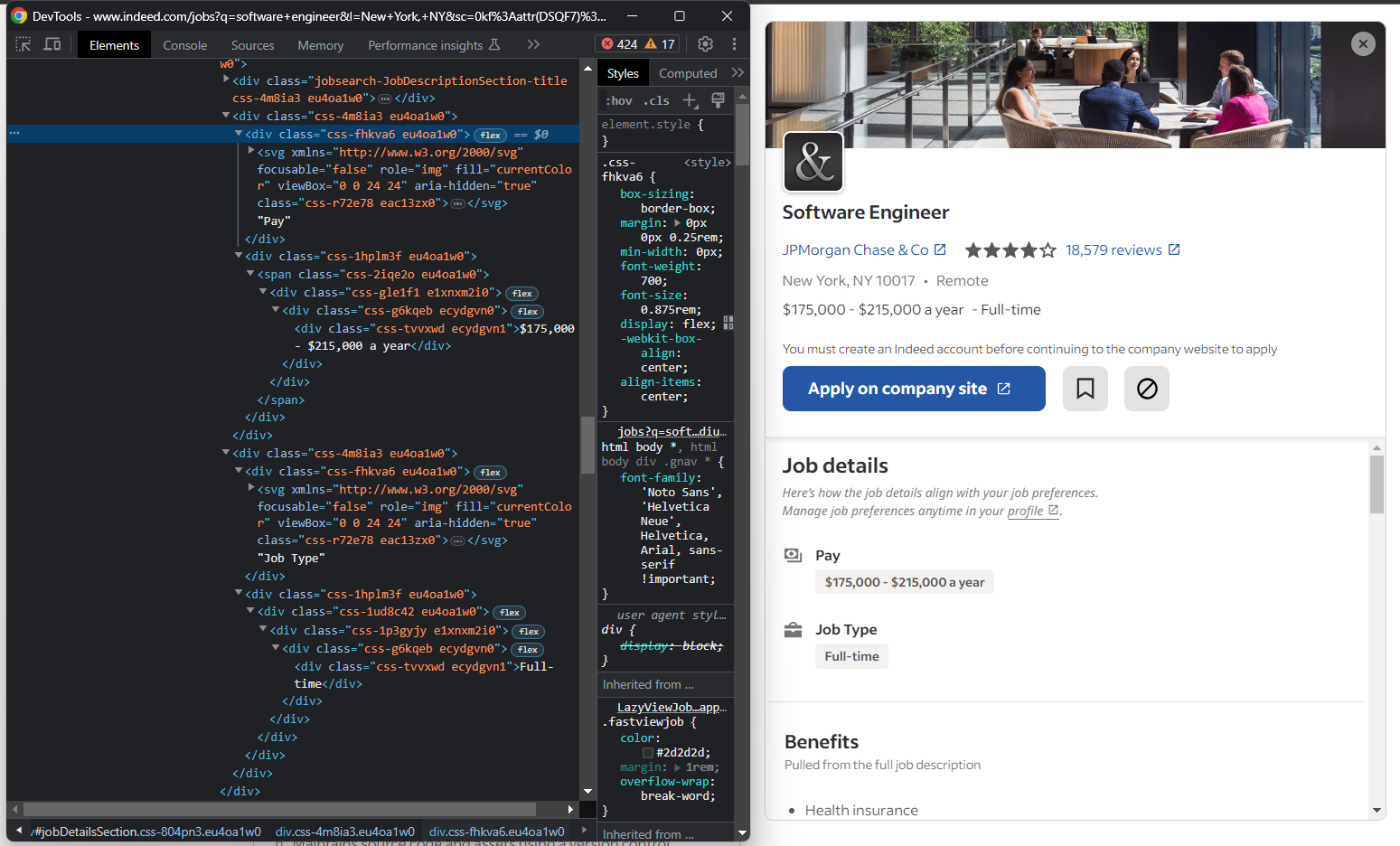
Sie können Folgendes tun:
- Alle
<div>-Elemente innerhalb des<div>-Elements „Jobdetails” abrufen - Durchlaufen Sie diese
- Wenn der Text des aktuellen
<div>-Elements „Bezahlung“ oder „Art der Stelle“ enthält, das nächste Geschwisterelement abrufen - Extrahieren Sie die gewünschten Daten
Mit anderen Worten, Sie müssen die folgende Logik implementieren:
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
Selenium bietet keine Hilfsmethode für den Zugriff auf die Geschwister eines Knotens. Stattdessen können Sie den Xpath-Ausdruck following-sibling::* verwenden.
Konzentrieren Sie sich nun auf die Vorteile des Jobs. In der Regel gibt es mehr als einen:
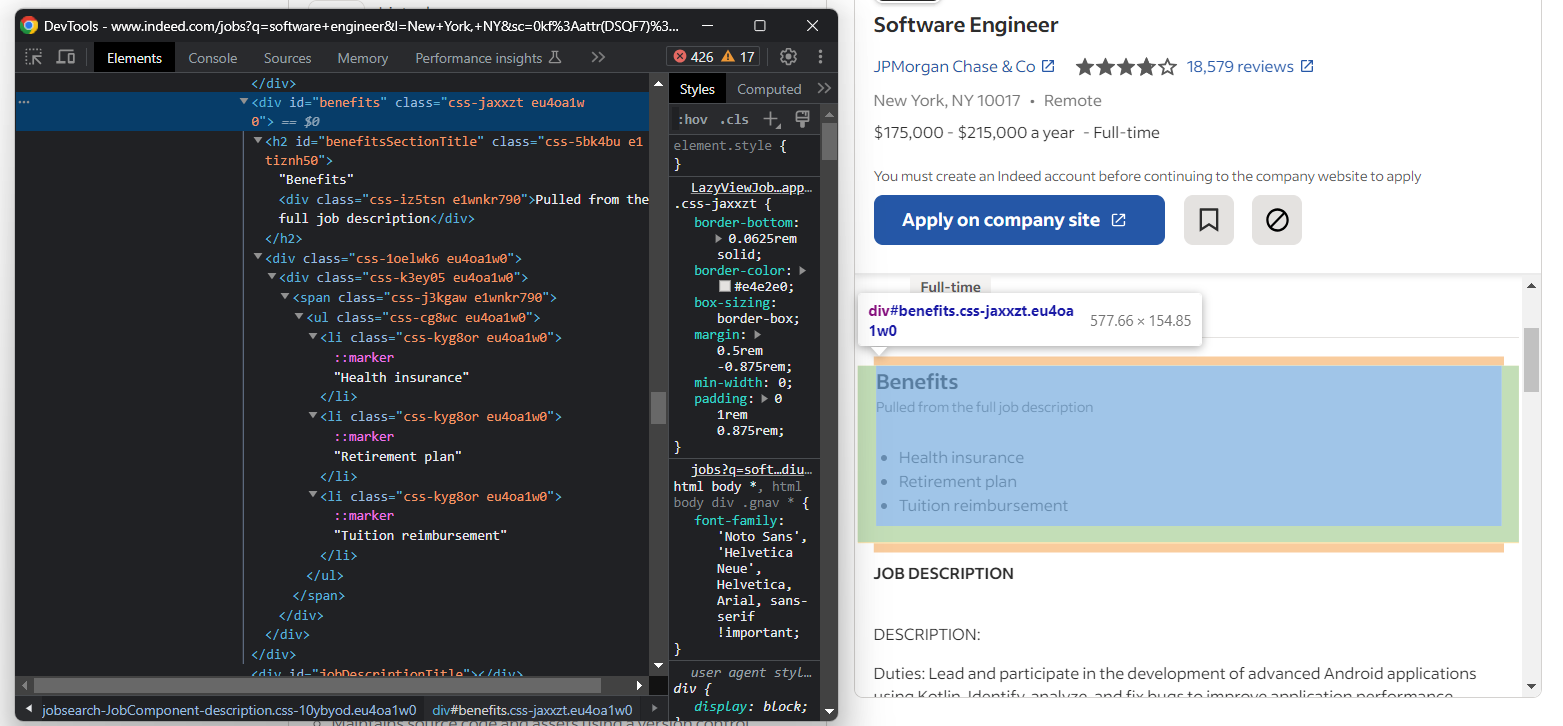
Um sie alle abzurufen, müssen Sie eine Liste initialisieren und mit folgenden Elementen füllen:
try:
benefits_element = job_details_element.find_element(By.ID, „benefits”)
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, „li”):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
Rufen Sie schließlich die Rohbeschreibung der Stelle ab:
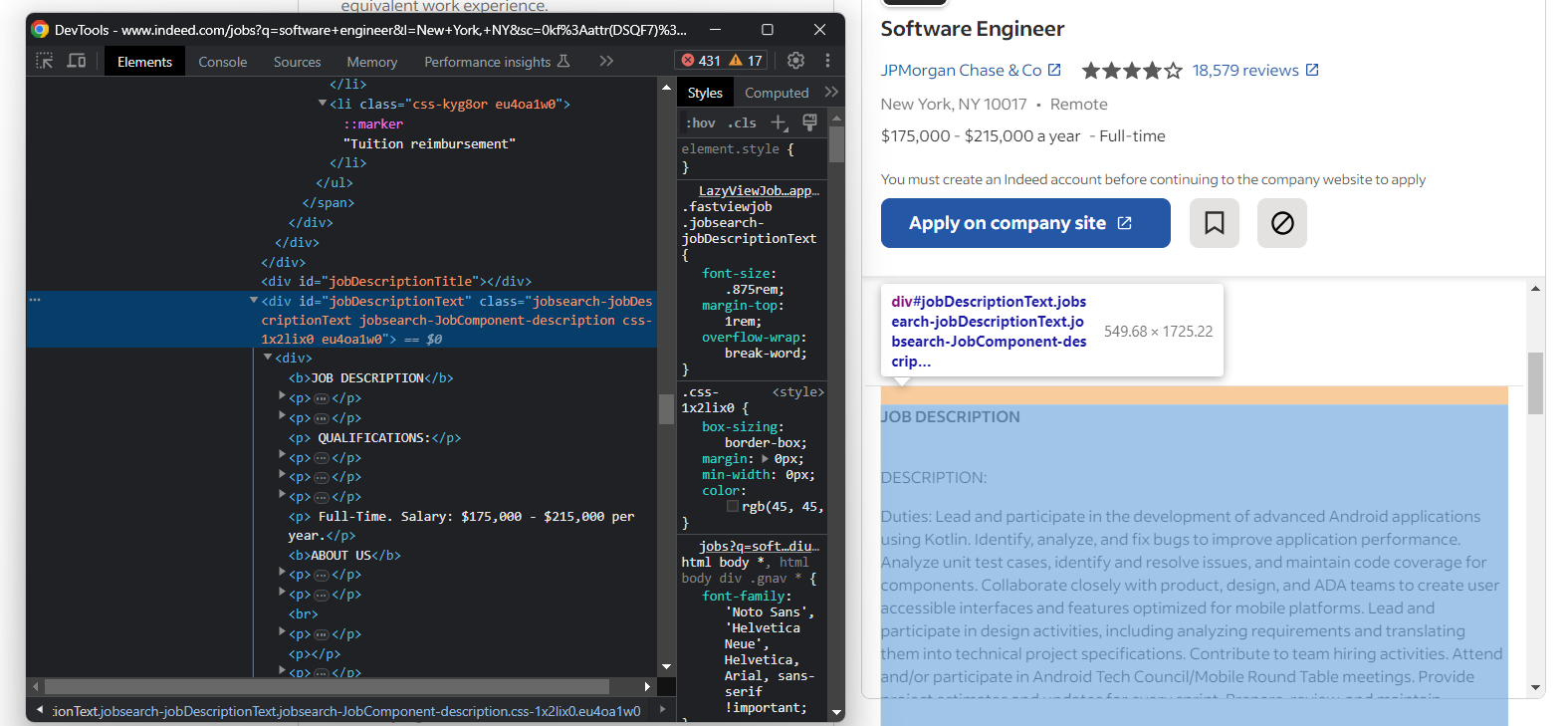
Extrahieren Sie den Text der Beschreibung mit:
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
Füllen Sie das Job -Wörterbuch und fügen Sie es zur Job -Liste hinzu:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
Sie können auch eine Protokollanweisung hinzufügen, um zu überprüfen, ob das Skript wie erwartet funktioniert:
print(job)
Führen Sie das Skript aus:
python Scraper.py
Dies erzeugt eine Ausgabe ähnlich wie:
{'posted_at': 'vor 17 Tagen', 'applications': '50+', 'title': 'Software Support Engineer', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3,5', 'company_reviews': '95', 'location': 'New York, NY 10001', 'location_type': 'Remote', 'apply_link': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '80.000 bis 100.000 Dollar pro Jahr', 'job_type': 'Vollzeit', 'benefits': ['401(k)', '401(k) matching', 'Zahnversicherung', 'Krankenversicherung', 'Bezahlter Elternurlaub', 'Bezahlter Urlaub', 'Elternurlaub', 'Augenversicherung'], 'description': „Integrated DNA Technologies (IDT) ist der führende Hersteller von kundenspezifischen Oligonukleotiden und proprietären Technologien für (der Kürze halber ausgelassen...)”}
Et voilà! Sie haben gerade gelernt, wie man Stellenanzeigen von Websites scrapt.
Schritt 9: Mehrere Stellenangebotsseiten scrapen
Eine typische Jobsuche auf Indeed liefert eine paginierte Liste mit Dutzenden von Ergebnissen. Sie haben gesehen, wie Sie jede Seite scrapen können!
Sehen Sie sich zunächst eine Seite an und beachten Sie, wie Indeed funktioniert. Im Detail zeigt es das folgende Element an, wenn eine nächste Seite verfügbar ist.
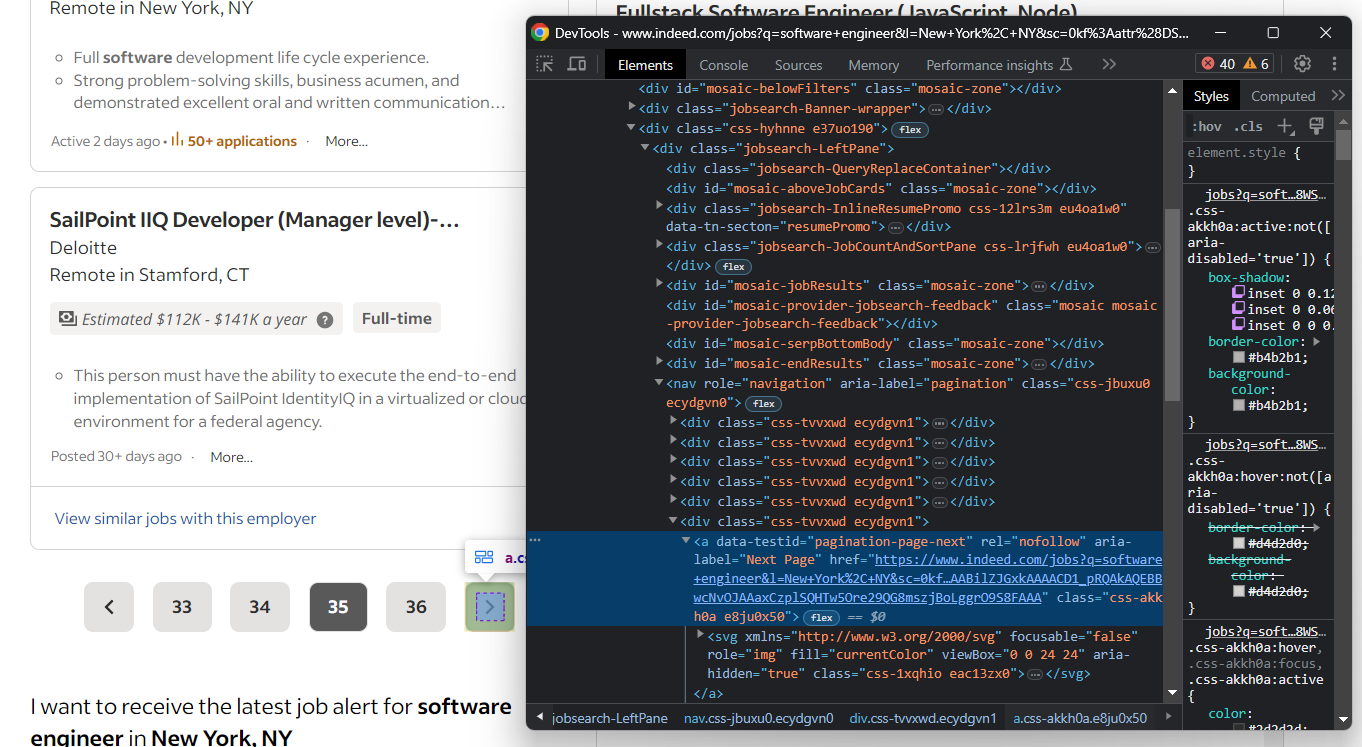
Andernfalls fehlt das Element für die nächste Seite:
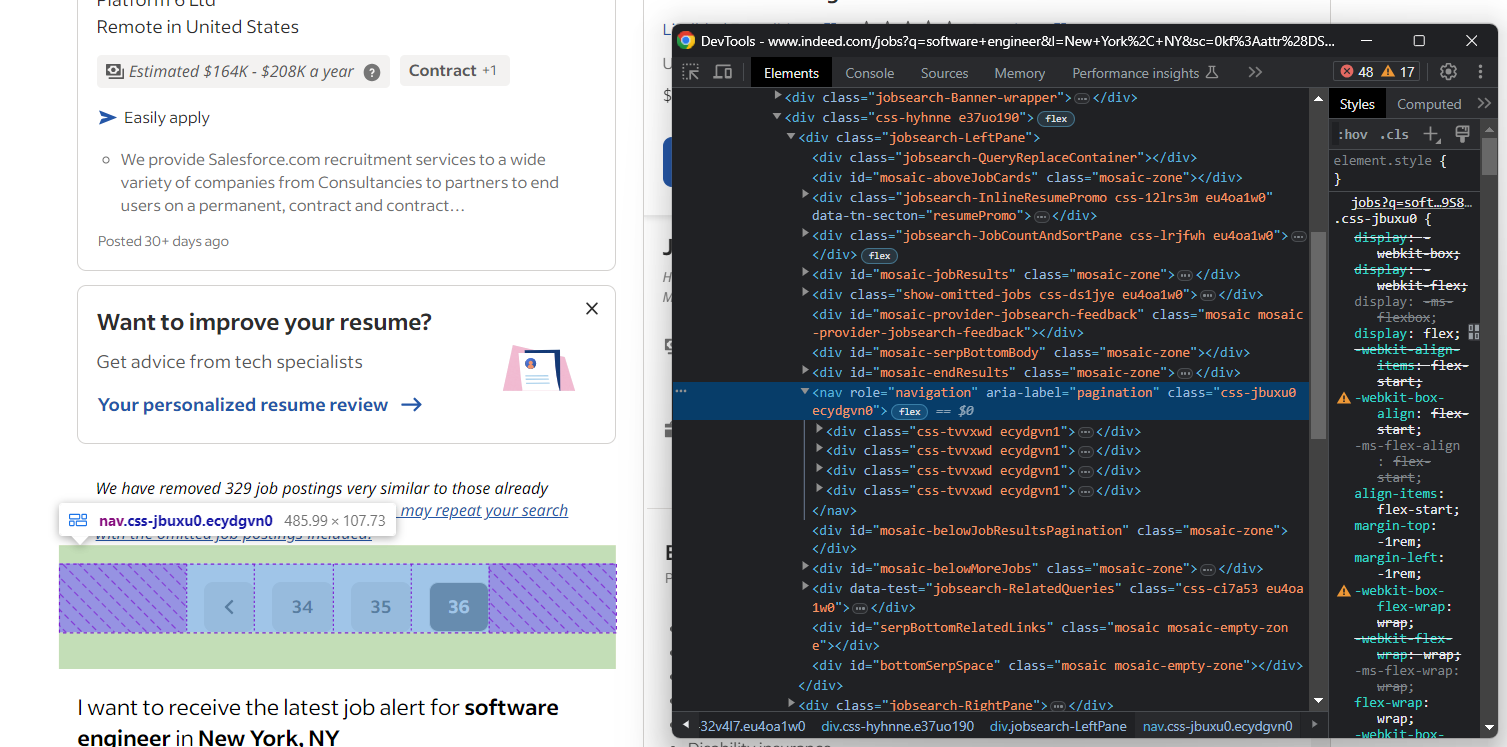
Beachten Sie, dass Indeed eine Liste mit Hunderten von Stellenangeboten zurückgeben kann. Da Sie nicht möchten, dass Ihr Skript endlos läuft, sollten Sie eine Begrenzung für die Anzahl der extrahierten Seiten hinzufügen.
Implementieren Sie das Web-Crawling auf Indeed in Selenium mit:
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# Scraping-Logik...
pages_scraped += 1
# wenn dies nicht die letzte Seite ist, zur nächsten Seite gehen
# andernfalls die while-Schleife unterbrechen
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
Der Indeed-Scraper wiederholt nun die Schleife, bis er die letzte Seite erreicht oder 5 Seiten durchlaufen hat.
Schritt 10: Exportieren der gescrapten Daten nach JSON
Derzeit werden die gescrapten Daten in einer Liste von Python-Dictionaries gespeichert. Exportieren Sie sie in JSON, um sie leichter teilen und lesen zu können.
Erstellen Sie zunächst ein Ausgabeobjekt:
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
Das Attribut „date” ist erforderlich, da die Veröffentlichungsdaten der Stellenangebote im Format „vor <X> Tagen” angegeben sind. Ohne einen Kontext zum Tag, an dem die Jobdaten gescrapt wurden, wäre es schwierig, sie zu verstehen.
Denken Sie daran, datetime zu importieren:
from datetime import datetime
Exportieren Sie es dann mit:
import json
# Scraping-Logik...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
Der obige Ausschnitt initialisiert eine jobs.json-Ausgabedatei mit open() und füllt sie mit JSON-Daten über json.dump(). In unserem Artikel erfahren Sie mehr darüber, wie Sie Daten in Python in JSON parsen und serialisieren können.
Das json-Paket stammt aus der Python-Standardbibliothek, sodass Sie keine zusätzlichen Abhängigkeiten installieren müssen, um das Ziel zu erreichen.
Wow! Sie haben mit rohen Jobdaten aus einer Webseite begonnen und verfügen nun über semistrukturierte JSON-Daten. Sie sind nun bereit, sich das gesamte Python-Skript zum Web-Scraping von Indeed anzusehen.
Schritt 11: Alles zusammenfügen
Hier ist die vollständige Datei scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# eine steuerbare Chrome-Instanz einrichten
# im Headless-Modus
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# Zielseite im Browser öffnen
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# Fenstergröße festlegen, um sicherzustellen, dass Seiten
# nicht im responsiven Modus gerendert werden
driver.set_window_size(1920, 1080)
# Datenstruktur zum Speichern der Stellenangebote,
# die von der Seite gescrapt wurden
jobs = []
pages_scraped = 0
pages_to_scrape = 3
while pages_scraped < pages_to_scrape:
# Wählen Sie die Stellenanzeigen-Karten auf der Seite aus.
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# Initialisieren Sie ein Wörterbuch, um die gescraped Stellenanzeigen-Daten zu speichern.
job = {}
# Initialisiere die zu scrapend Jobattribute
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# allgemeine Jobdaten aus der Übersichtskarte abrufen
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in Bearbeitung", "")
.strip()
posted_at = posted_at_text
.replace("Veröffentlicht", "")
.replace("Arbeitgeber", "")
.replace("Aktiv", "")
.strip()
except NoSuchElementException:
pass
# Anti-Scraping-Modal schließen
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
# Lade die Karte mit den Jobdetails.
job_card.click()
# Warte, bis der Abschnitt mit den Jobdetails nach dem Klick geladen ist.
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
# Extrahieren der Jobdetails
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
# speichere die gescrapten Daten
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# warte eine zufällige Anzahl von Sekunden zwischen 1 und 5,
# um Rate-Limiting-Blöcke zu vermeiden
time.sleep(random.uniform(1, 5))
# erhöhe den Scraping-Zähler
pages_scraped += 1
# wenn dies nicht die letzte Seite ist, gehe zur nächsten Seite
# andernfalls die while-Schleife unterbrechen
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
# Browser schließen und Ressourcen freigeben
driver.quit()
# Erstelle das Ausgabeobjekt
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
# Exportiere es nach JSON
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
Mit weniger als 200 Zeilen Code haben Sie gerade einen voll funktionsfähigen Scraper für Web-Scraping erstellt, um Jobdaten von Indeed zu scrapen.
Starten Sie ihn mit:
python Scraper.py
Warten Sie einige Minuten, bis das Skript fertig ist
Am Ende des Scraping-Prozesses erscheint eine Datei namens jobs.json im Stammverzeichnis Ihres Projekts. Öffnen Sie sie und Sie sehen:
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "vor 7 Tagen",
"applications": "50+",
"title": "Software Engineer - All Levels",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remote",
„apply_link”: „https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"Fitnessstudio-Mitgliedschaft",
"Bezahlter Urlaub"
],
"description": "Über Listrak:nWir sind ein SaaS-Unternehmen, das eine integrierte digitale Marketingplattform anbietet, der mehr als 1.000 führende Einzelhändler und Marken für E-Mail-, SMS-Marketing, Identitätsauflösung, Verhaltensauslöser und kanalübergreifende Orchestrierung vertrauen. Unser Hauptsitz befindet sich in (der Kürze halber weggelassen...)"
},
// der Kürze halber weggelassen...
{
„posted_at“: „vor 9 Tagen“,
„applications“: null,
„title“: „Softwareentwickler, Front End (Hybrid-Remote)“,
„company_name“: „Weill Cornell Medicine“,
„company_rating“: „3,4“,
„company_reviews”: „41”,
„location”: „New York, NY 10021”,
„location_type”: „Remote”,
„apply_link”: „https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615",
„pay”: „99.800 $ – 123.200 $ pro Jahr”,
„job_type”: null,
„benefits”: null,
„description”: „Titel: Softwareentwickler, Frontend (Hybrid-Remote)nTitel: Softwareentwickler, Frontend (Hybrid-Remote)nStandort: Upper East SidenOrganisationseinheit: Olivier Elemento LabnArbeitstage: Montag bis FreitagnAusnahmestatus: AusgenommennGehaltsspanne: 99.800,00 $ – 123.200,00 $nAs (der Kürze halber weggelassen...)"
}
}
Herzlichen Glückwunsch! Sie haben gerade gelernt, wie man Indeed mit Python scrapt!
Fazit
In diesem Tutorial haben Sie verstanden, warum Indeed eines der besten Jobportale im Internet ist und wie Sie Daten daraus extrahieren können. Insbesondere haben Sie gesehen, wie Sie einen Python-Scraper erstellen können, der Daten zu offenen Stellen daraus abrufen kann.
Wie hier gezeigt, ist das Scraping von Indeed keine leichte Aufgabe. Die Website verfügt über einen raffinierten Anti-Scraping-Schutz, der Ihr Skript blockieren könnte. Wenn Sie mit solchen Websites arbeiten, benötigen Sie einen steuerbaren Browser, der automatisch CAPTCHAs, Fingerprinting, automatische Wiederholungsversuche und vieles mehr für Sie erledigt. Genau das ist die Aufgabe unserer neuen Scraping-Browser-Lösung!
Sie möchten sich gar nicht mit Web-Scraping beschäftigen, sind aber an Jobdaten interessiert? Entdecken Sie unsere Indeed-Datensätze und unseren Datensatz mit Stellenanzeigen. Registrieren Sie sich jetzt und testen Sie gratis.
Hinweis: Dieser Leitfaden wurde zum Zeitpunkt der Erstellung von unserem Team gründlich getestet, aber da Websites ihren Code und ihre Struktur häufig aktualisieren, funktionieren einige Schritte möglicherweise nicht mehr wie erwartet.




