

Seit 30 Jahren ist Craigslist eine beliebte Anlaufstelle für alle Arten von Geschäften. Trotz seines sehr einfachen Designs aus den 1990er Jahren ist Craigslist möglicherweise der beste Ort der Welt, um Angebote „vom Eigentümer“ zu kaufen.
Heute werden wir miteinem Python-Scraper Fahrzeugdaten aus Craigslist extrahieren. Folgen Sie unseren Anweisungen und Sie werden Craigslist im Handumdrehen wie ein Profi scrapen. Sie suchen nach Skalierbarkeit? Sehen Sie sich unseren Vergleich der besten Scraping-Tools an.
Was Sie aus Craigslist extrahieren können
HTML durchforsten: Der schwierige Weg
Die wichtigste Fähigkeit beim Web-Scraping ist es, zu wissen, wo man suchen muss. Wir könnten einen überkomplizierten Parser schreiben, der einzelne Elemente aus dem HTML-Code extrahiert.
Wenn Sie sich den Lkw in der Abbildung unten ansehen, sind seine Daten in einem div-Element der Klasse cl-gallery verschachtelt. Wenn wir es auf die harte Tour machen wollen, können wir diesen Tag finden und dann weitere Elemente daraus parsen.
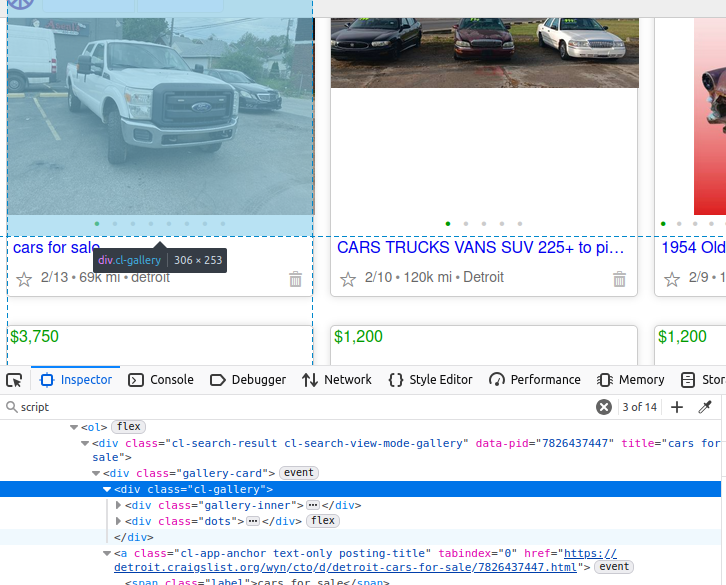
Das JSON finden: Wertvolle Zeit sparen
Es gibt jedoch einen besseren Weg. Viele Websites, darunter auch Craigslist, verwenden eingebettete JSON-Daten, um die gesamte Seite aufzubauen. Wenn Sie dieses JSON finden, reduziert sich Ihre Parsing-Arbeit auf fast null.
Auf einer Craigslist-Seite gibt es ein Skript-Objekt, das alle gewünschten Daten enthält. Wenn wir dieses eine Element extrahieren, erhalten wir die Daten der gesamten Seite. Wenn Sie genau hinschauen, sehen Sie, dass seine ID ld_searchpage_results lautet. Wir können dieses Element mit dem CSS-Selektor script[id='ld_searchpage_results'] finden.

Scraping von Craigslist mit Python
Jetzt, da wir wissen, wonach wir suchen, wird das Scraping von Craigslist viel einfacher. In den nächsten Abschnitten gehen wir den einzelnen Code durch und fügen ihn dann zu einem funktionsfähigen Scraper zusammen.
Parsing der Seite
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#if we receive a bad status code, throw an error
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#wir haben alle Einträge durchlaufen, setzen success = True und brechen die Schleife ab
success = True
except Exception as e:
print(f"Failed to scrape the listings, {e} at {url}")
return scraped_data
- Zunächst erstellen wir unsere Variablen
url,scraped_dataundsuccess.url: Die genaue URL der Suche, die wir durchführen möchten.scraped_data: Hier speichern wir alle unsere Suchergebnisse.success: Wir möchten, dass dieser Scraper persistent ist. In Kombination mit einerwhile-Schleifewird unser Scraper erst beendet, wenn der Auftrag abgeschlossen ist und wir success aufTruesetzen.
- Dann rufen wir die Seite auf und geben im Falle einer fehlerhaften Antwort eine Fehlermeldung aus.
soup = BeautifulSoup(response.text, "html.parser")erstellt einBeautifulSoup-Objekt, mit dem wir die Seite parsen können.- Wir finden unser eingebettetes JSON mit
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']"). - Anschließend konvertieren wir es mit
json.loads()in eindict. - Als Nächstes durchlaufen wir alle Elemente und bereinigen ihre Daten. Das
clean_itemwird an unserescraped_dataangehängt. - Schließlich setzen wir
successaufTrueund geben das Array der gescrapten Einträge zurück.
Speichern unserer Daten
Die beiden gängigsten Speichermethoden beim Web-Scraping sind CSV und JSON. Wir zeigen Ihnen, wie Sie unsere Listings in beiden Formaten speichern können.
Speichern in einer JSON-Datei
Dieser grundlegende Ausschnitt enthält unsere JSON-Speicherlogik. Wir öffnen eine Datei und übergeben sie zusammen mit unseren Daten an json.dump(). Wir verwenden indent=4, um die JSON-Datei lesbar zu machen.
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save the results: {e}")
Speichern in einer CSV-Datei
Das Speichern in einer CSV-Datei erfordert etwas mehr Aufwand. CSV kann mit Arrays nicht besonders gut umgehen. Aus diesem Grund haben wir beim Bereinigen der Daten nur ein Bild extrahiert.
Wenn keine Einträge vorhanden sind, wird die Funktion beendet. Wenn Einträge vorhanden sind, schreiben wir die CSV-Kopfzeilen mit den Schlüsseln () aus dem ersten Element des Arrays. Dann verwenden wir csv.DictWriter(), um die Kopfzeilen und die Einträge zu schreiben.
def write_listings_to_csv(listings, filename):
if not listings:
print("Keine Einträge gefunden. CSV-Schreiben wird übersprungen.")
return
# CSV-Spaltenüberschriften definieren
fieldnames = listings[0].keys()
# Daten in CSV schreiben
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
Alles zusammenfügen
Jetzt können wir alle Teile zusammenfügen. Dieser Code enthält unseren voll funktionsfähigen Scraper.
import requests
from bs4 import BeautifulSoup
import json
import csv
def write_listings_to_csv(listings, filename):
if not listings:
print("Keine Einträge gefunden. CSV-Schreiben wird übersprungen.")
return
# CSV-Spaltenüberschriften definieren
fieldnames = listings[0].keys()
# Daten in CSV schreiben
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#if we receive a bad status code, throw an error
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#wir haben alle Einträge durchgesehen, setzen success = True und brechen die Schleife ab
success = True
except Exception as e:
print(f"Failed to scrape the listings, {e} at {url}")
return scraped_data
if __name__ == "__main__":
LOCATION = "detroit"
QUERY = "cars"
OUTPUT = "csv"
listings = scrape_listings(LOCATION, QUERY)
if OUTPUT == "json":
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Speichern der Ergebnisse fehlgeschlagen: {e}")
elif OUTPUT == "csv":
try:
write_listings_to_csv(listings, f"{QUERY}-{LOCATION}.csv")
print(f"{len(listings)} Einträge in {QUERY}-{LOCATION}.csv gespeichert")
except Exception as e:
print(f"CSV-Ausgabe konnte nicht geschrieben werden: {e}")
else:
print("Ausgabemethode wird nicht unterstützt")
Innerhalb des Hauptblocks können Sie Speichermethoden mit der Variablen OUTPUT verarbeiten. Wenn Sie in einer JSON-Datei speichern möchten, setzen Sie diese auf json. Wenn Sie eine CSV-Datei wünschen, setzen Sie diese Variable auf csv. Bei der Datenerfassung werden Sie beide Speichermethoden ständig verwenden.
JSON-Ausgabe
Wie Sie in der Abbildung unten sehen können, wird jedes Auto durch ein lesbares JSON-Objekt mit einer übersichtlichen, klaren Struktur dargestellt.
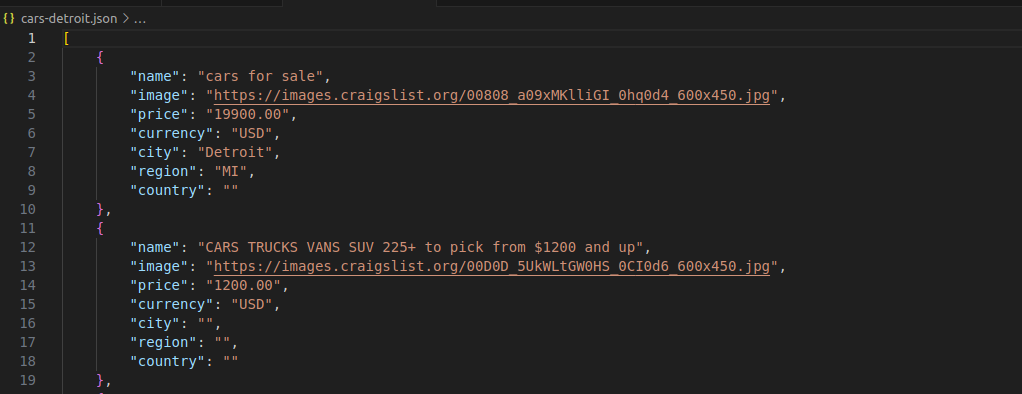
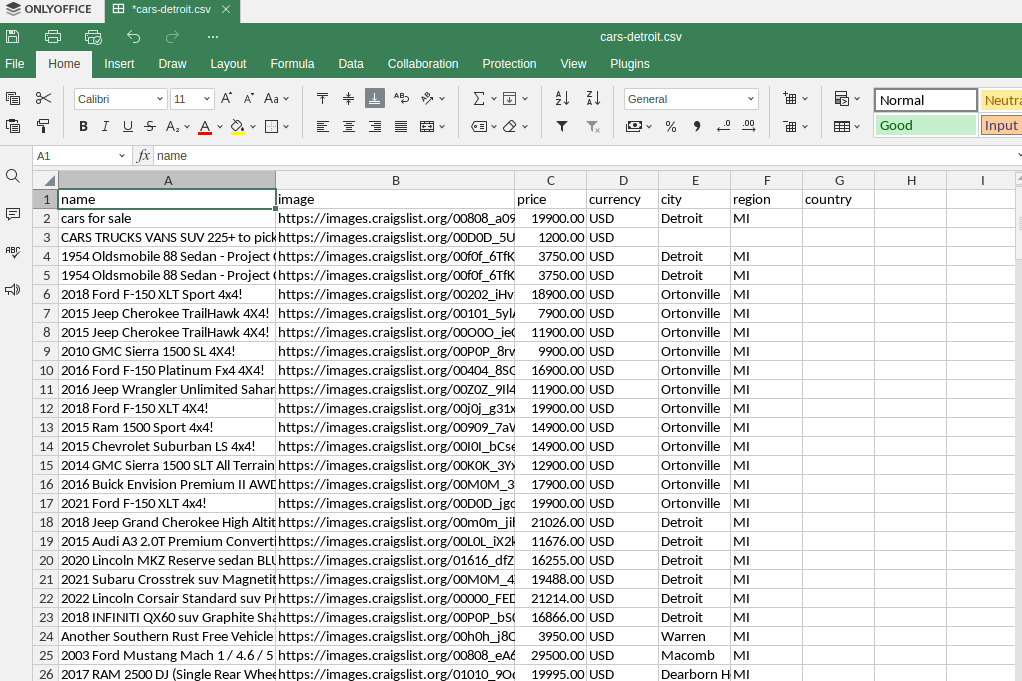
CSV-Ausgabe
Unsere CSV-Ausgabe ist sehr ähnlich. Wir erhalten eine übersichtliche Tabelle mit allen unseren Einträgen.
Umgehen Sie die Schutzmaßnahmen von Craigslist mit Web Unlocker
Wenn Sie Ihre Craigslist-Scraping-Aktivitäten ausweiten, werden Sie unweigerlich auf Hindernisse stoßen: CAPTCHAs, IP-Sperren und Anti-Bot-Erkennungssysteme, die Ihre Scraper lahmlegen können.
Der Web Unlocker von Bright Datalöst diese Herausforderungen automatisch mit einer Infrastruktur der Enterprise-Klasse, die speziell für die groß angelegte Datenerfassung entwickelt wurde.
Automatische CAPTCHA-Lösung
Anstatt CAPTCHAs manuell zu lösen oder wertvolle Daten durch blockierte Anfragen zu verlieren, übernimmt Web Unlocker diese Aufgabe für Sie:
- ✅Automatische CAPTCHA-Lösungfür reCAPTCHA, hCaptcha und mehr
- ✅Echtzeit-Fingerabdruck-Randomisierungzur Vermeidung von Erkennung
- ✅Intelligente Wiederholungslogik, die sich an die Schutzmechanismen jeder Website anpasst
- ✅99,9 % Erfolgsquoteselbst auf stark geschützten Seiten
Erfahren Sie mehr über unsereCAPTCHA-Löser-Funktionen.
Einfache Integration
import requests
# Web Unlocker-Endpunkt
WEB_UNLOCKER_URL = 'https://brd.superproxy.io:33335'
AUTH = 'brd-customer-<CUSTOMER_ID>-zone-web_unlocker:<ZONE_PASSWORD>'
def scrape_with_unlocker(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
response = requests.get(
url,
Proxies={
'http': f'http://{AUTH}@{WEB_UNLOCKER_URL}',
'https': f'http://{AUTH}@{WEB_UNLOCKER_URL}'
},
verify=False
)
return response.text
# Scrape ohne sich um Blocks oder CAPTCHAs zu kümmern
listings = scrape_with_unlocker("detroit", "cars")Mit Web Unlocker erhalten Sie:
- Keine manuelle CAPTCHA-Lösung
- Keine Probleme mit der Verwaltung der Proxys
- Keine Konfiguration der IP-Rotation
- Nur saubere, zuverlässige Datenerfassung in großem Maßstab
Verwendung des Scraping-Browsers
Mit dem Scraping-Browser können wir eine Playwright-Instanz mit Proxy-Integration ausführen. Dies kann Ihr Scraping auf die nächste Stufe heben, indem Sie einen vollständigen Browser aus Ihrem Python-Skript heraus bedienen. Wenn Sie daran interessiert sind, Proxys in Playwright zu integrieren
Im folgenden Code bleibt unsere Parsing-Methode weitgehend unverändert, aber wir verwenden asyncio mit async_playwright, um einen Headless-Browser zu öffnen und die Seite tatsächlich mit diesem Browser abzurufen. Anstelle von BeautifulSoup übergeben wir unseren CSS-Selektor an die query_selector() -Methode von Playwright.
import asyncio
from playwright.async_api import async_playwright
import json
AUTH = 'brd-customer-<IHR-BENUTZERNAME>-zone-<IHR-ZONENNAME>:<IHR-PASSWORT>'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def scrape_listings(keyword, location):
print('Verbindung zum Scraping-Browser wird hergestellt...')
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
async with async_playwright() as p:
browser = await p.chromium.connect_over_cdp(SBR_WS_CDP)
context = await browser.new_context()
page = await context.new_page()
try:
print('Verbunden! Navigieren zur Webseite...')
await page.goto(url)
embedded_json_string = await page.query_selector("script[id='ld_searchpage_results']")
json_data = json.loads(await embedded_json_string.text_content())["itemListElement"]
for dirty_item in json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
if len(images) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
except Exception as e:
print(f"Failed to scrape data: {e}")
finally:
await browser.close()
return scraped_data
async def main():
QUERY = "cars"
LOCATION = "detroit"
listings = await scrape_listings(QUERY, LOCATION)
try:
with open(f"{QUERY}-Scraping-Browser.json", "w") as file:
json.dump(listings, file, indent=4)
except Exception as e:
print(f"Failed to save results {e}")
if __name__ == '__main__':
asyncio.run(main())
Verwendung eines maßgeschneiderten No-Code-Scrapers
Hier bei Bright Data bieten wir auch einen No-Code-Craigslist-Scraper an. Mit dem No-Code-Scraper legen Sie die Daten und Seiten fest, die Sie scrapen möchten. Dann erstellen und implementieren wir einen Scraper für Sie!
Klicken Sie im Abschnitt „Meine Scraper” auf „Neu” und wählen Sie „Benutzerdefinierten Scraper anfordern”.
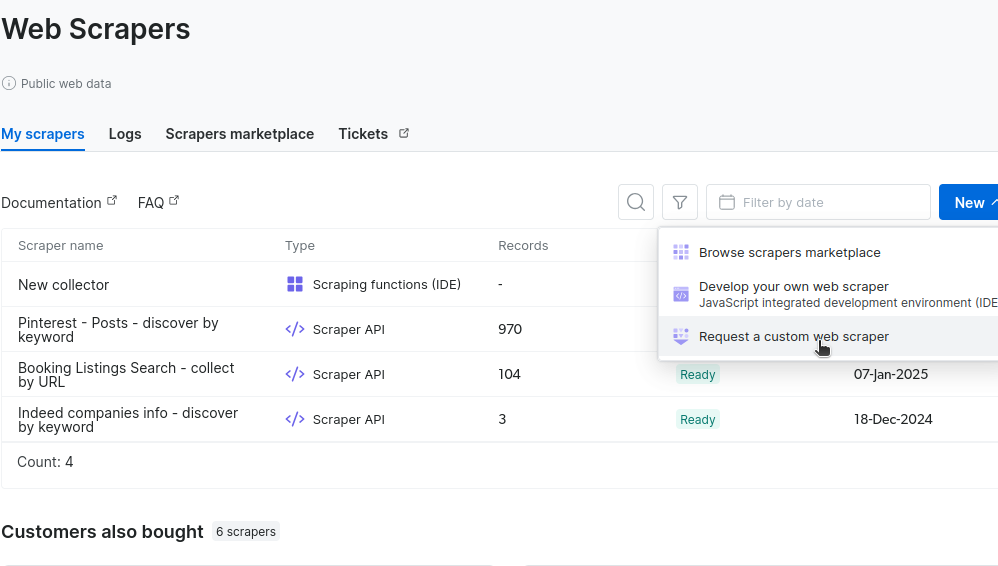
Als Nächstes werden Sie aufgefordert, einige URLs einzugeben, die das Layout Ihrer Website enthalten. In der Abbildung unten geben wir die URL für unsere Autosuche in Detroit ein. Sie können eine zweite URL für Ihre Stadt hinzufügen.
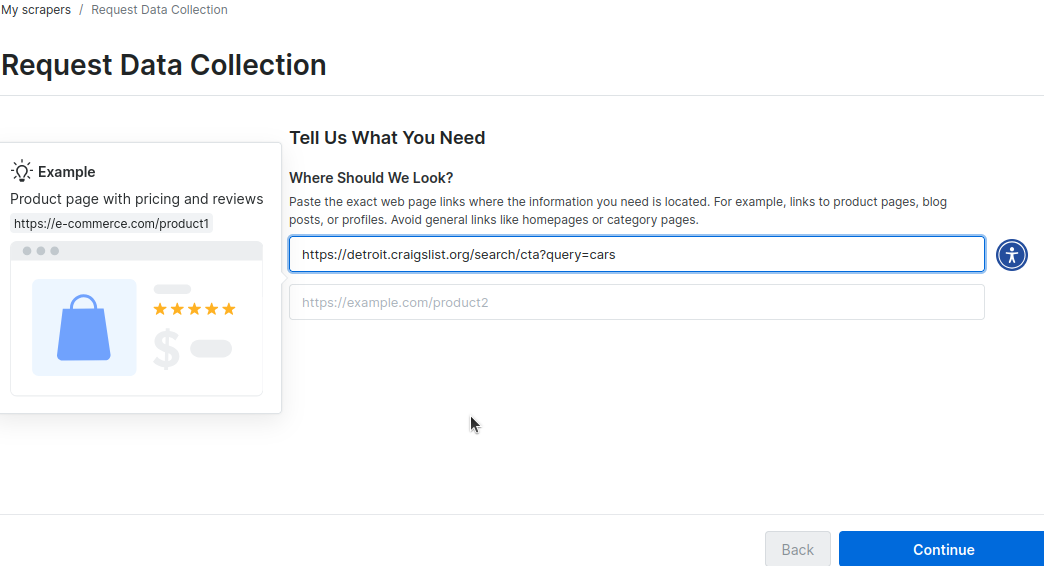
Durch unseren automatisierten Prozess scrapen wir die Websites und erstellen ein Schema, das Sie überprüfen können.
Sobald das Schema erstellt wurde, müssen Sie es überprüfen.
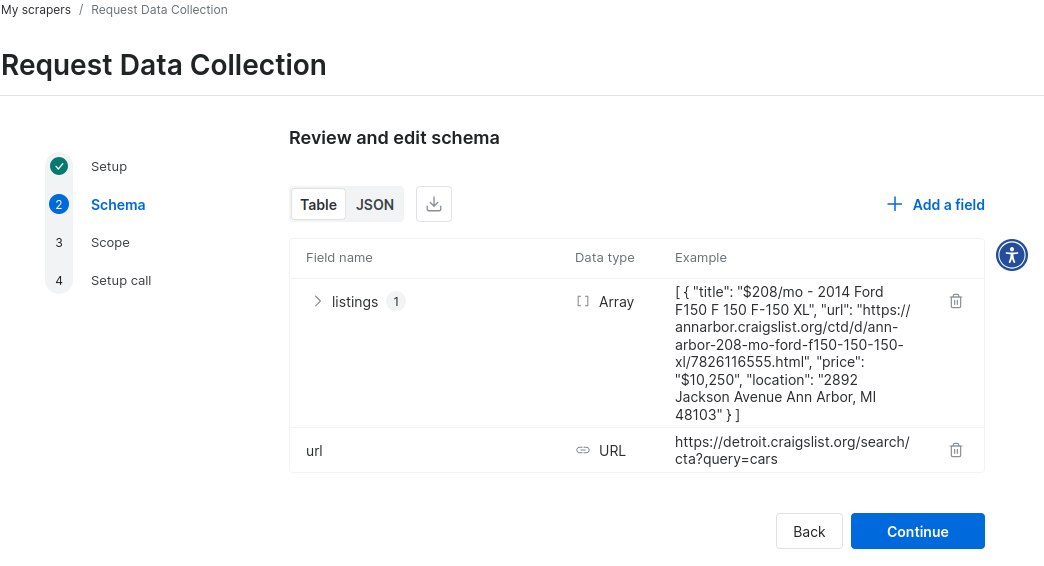
Hier ist ein Beispiel für JSON-Daten aus dem Schema für einen benutzerdefinierten Craigslist-Scraper. Innerhalb weniger Minuten steht ein funktionsfähiger Prototyp zur Verfügung.
{
"type": "object",
"fields": {
"listings": {
"type": "array",
"active": true,
"items": {
"type": "object",
"fields": {
"title": {
"type": "text",
"active": true,
"sample_value": "$208/mo - 2014 Ford F150 F 150 F-150 XL"
},
„url“: {
„type“: „url“,
„active”: true,
„sample_value”: „https://annarbor.craigslist.org/ctd/d/ann-arbor-208-mo-ford-f150-150-150-xl/7826116555.html”
},
"price": {
"type": "price",
"active": true,
"sample_value": "$10,250"
},
"location": {
"type": "text",
"active": true,
"sample_value": "2892 Jackson Avenue Ann Arbor, MI 48103"
}
}
}
},
"url": {
"type": "url",
"required": true,
"active": true,
"sample_value": "https://detroit.craigslist.org/search/cta?query=cars"
}
}
}
Als Nächstes legen Sie den Umfang der Sammlung fest. Wir müssen nicht die gesamte Website von Craigslist oder nur einen bestimmten Bereich scrapen, daher geben wir URLs ein, um einen Scrape zu starten.
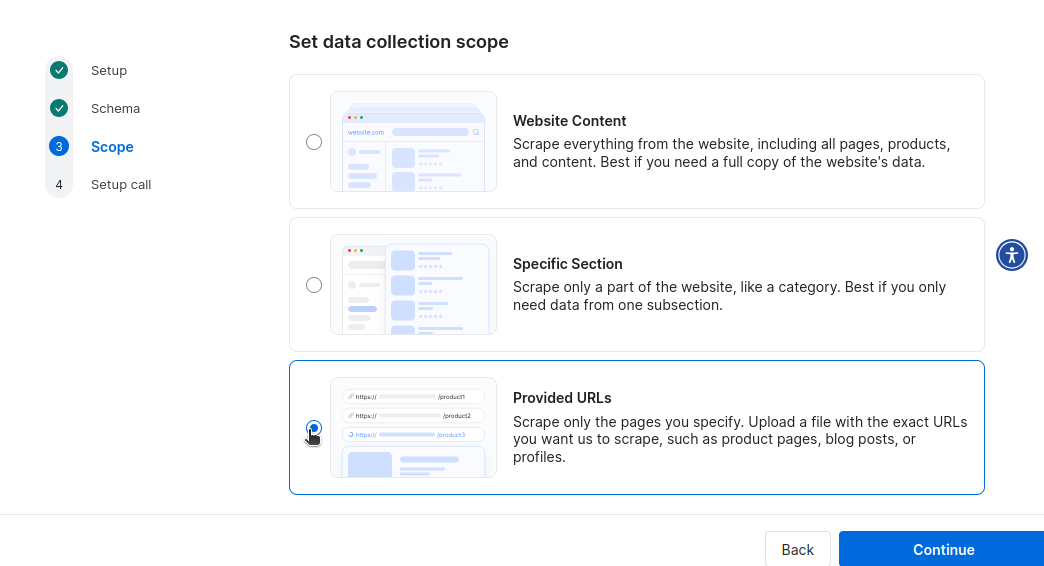
Schließlich werden Sie aufgefordert, einen Termin mit einem unserer Experten für die Bereitstellung zu vereinbaren. Sie können monatlich 300 $ für Wartung und Instandhaltung zahlen oder eine einmalige Bereitstellungsgebühr von 1.000 $ entrichten.
Fazit
Wenn Sie Craigslist scrapen, können Sie jetzt Python für eine schnelle und effiziente Datenverarbeitung nutzen. Sie wissen, wie man die Daten parst und bereinigt. Sie haben auch gelernt, wie man sie mit CSV und JSON speichert. Wenn Sie die volle Browserfunktionalität benötigen, können Sie Scraping-Browser nutzen, um diese Anforderungen mit vollständiger Proxy-Integration zu erfüllen. Wenn Sie Ihren Scraping-Prozess vollständig automatisieren möchten, wissen Sie jetzt auch, wie Sie unseren No-Code Scraper einsetzen können.
Wenn Sie den Scraping-Prozess komplett überspringen möchten, bietet Bright Data außerdem gebrauchsfertige Craigslist-Datensätze an. Melden Sie sich jetzt an und starten Sie noch heute Ihre kostenlose Testversion!





