

Node.js hat sich als leistungsstarke Option für die Erstellung von Web-Scrapern etabliert und bietet Komfort sowohl für clientseitige als auch für serverseitige Entwicklungen. Dank seines umfangreichen Bibliothekskatalogs ist das Web-Scraping mit Node.js ein Kinderspiel. In diesem Artikel wird cheerio vorgestellt und seine Fähigkeiten für effizientes Web-Scraping untersucht.
Cheerio ist eine schnelle und flexible Bibliothek zum Parsing und Bearbeiten von HTML- und XML-Dokumenten. Es implementiert eine Teilmenge der jQuery-Funktionen, was bedeutet, dass jeder, der mit jQuery vertraut ist, sich mit der Syntax von cheerio sofort zurechtfinden wird. Im Hintergrund verwendet cheerio die Bibliotheken parse5 und optional htmlparser2 zum Parsing von HTML- und XML-Dokumenten.
In diesem Artikel erstellen Sie ein Projekt, das cheerio verwendet, und lernen, wie Sie Daten von dynamischen Websites und statischen Webseiten scrapen können.
Web-Scraping mit cheerio
Bevor Sie mit diesem Tutorial beginnen, stellen Sie sicher, dass Node.js auf Ihrem System installiert ist. Wenn Sie es noch nicht haben, können Sie es anhand der offiziellen Dokumentation installieren.
Nachdem Sie Node.js installiert haben, erstellen Sie ein Verzeichnis namens cheerio-demo und wechseln Sie mit cd in dieses Verzeichnis:
mkdir cheerio-demo u0026u0026 cd cheerio-demon
Initialisieren Sie dann ein npm-Projekt in dem Verzeichnis:
npm init -yn
Installieren Sie die Pakete cheerio und Axios:
npm install cheerio axiosn
Erstellen Sie eine Datei namens index.js, in der Sie den Code für dieses Tutorial schreiben werden. Öffnen Sie diese Datei dann in Ihrem bevorzugten Editor, um zu beginnen.
Als Erstes müssen Sie die erforderlichen Module importieren:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);n
In diesem Tutorial werden Sie die Seite „Books to Scrape“ scrapen, eine öffentliche Sandbox zum Testen von Scrapern. Zunächst verwenden Sie Axios, um mit dem folgenden Code eine GET-Anfrage an die Webseite zu stellen:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n n});n
Das Antwortobjekt im Callback enthält den HTML-Code der Webseite in der Eigenschaft „data “. Dieser HTML-Code muss an die Load -Funktion des Cheerio -Moduls übergeben werden. Diese Funktion gibt eine Instanz von CheerioAPI zurück, die für den Zugriff auf das DOM und dessen Bearbeitung für den Rest des Codes verwendet wird. Beachten Sie, dass die CheerioAPI- Instanz in einer Variablen namens „$“ gespeichert ist, was eine Anspielung auf die jQuery-Syntax ist:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);n});n
Elemente finden
Cheerio unterstützt die Verwendung von CSS- und XPath-Selektoren zum Auswählen von Elementen auf der Seite. Wenn Sie jQuery verwendet haben, wird Ihnen die Syntax bekannt vorkommen: Übergeben Sie den CSS-Selektor an die Funktion $(). Verwenden Sie diese Syntax, um Informationen auf der ersten Seite der Website „Books to Scrape“ zu finden und zu extrahieren.
Besuchen Sie https://books.toscrape.com/ und öffnen Sie die Entwicklerkonsole. Suchen Sie die Registerkarte „Element untersuchen“, wo Sie mehr über die HTML-Struktur der Seite erfahren. In diesem Fall können Sie sehen, dass alle Informationen zu den Büchern in Artikel-Tags mit der Klasse product-pod enthalten sind:
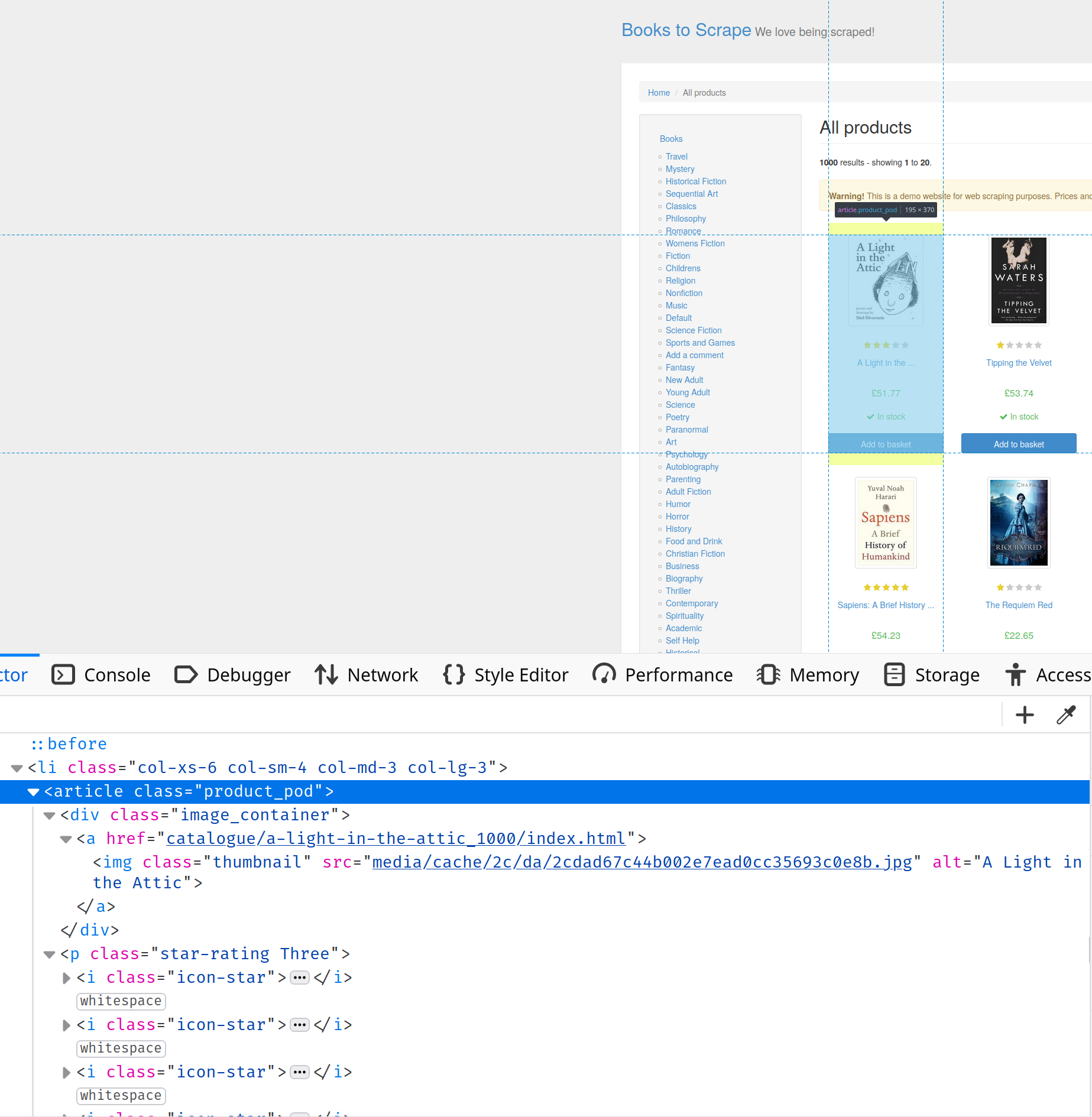
Um die Bücher auszuwählen, müssen Sie den CSS-Selektor „article.product_pod“ wie folgt verwenden:
$(u0022article.product_podu0022);n
Diese Funktion gibt eine Liste aller Elemente zurück, die mit dem Selektor übereinstimmen. Mit der Methode „each“ können Sie die Liste durchlaufen:
$(u0022article.product_podu0022).each( (i, element) =u003e {nn});n
Innerhalb der Schleife können Sie die Variable „element“ verwenden, um die Daten zu extrahieren.
Versuchen Sie, den Titel der Bücher auf der ersten Seite zu extrahieren. Wenn Sie zur Konsole „Element untersuchen” zurückkehren, können Sie sehen, wie die Titel gespeichert sind:

Sie sehen, dass Sie ein h3 finden müssen, das ein Kind der Variablen element ist. Innerhalb des h3 gibt es ein a-Element, das den Titel des Buches enthält. Sie können die Methode find mit einem CSS-Selektor verwenden, um die Kinder eines Elements zu finden, aber zunächst müssen Sie element durch $ übergeben, um es in eine Instanz von Cheerio zu konvertieren:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);nn});n
Jetzt können Sie das a innerhalb von titleH3 finden:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022);n});n
Hinweis:
titleH3ist bereits eine Instanz vonCheerio, daher müssen Sie es nicht über$übergeben.
Text extrahieren
Nachdem Sie ein Element ausgewählt haben, können Sie den Text dieses Elements mit der Methode text abrufen.
Ändern Sie das vorherige Beispiel, um den Titel des Buches zu extrahieren, indem Sie die Methode „text“ für das Ergebnis der Methode „find“ aufrufen:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n});n
Der vollständige Code sollte wie folgt aussehen:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n });n});n
Führen Sie den Code mit node index.js aus, und Sie sollten die folgende Ausgabe sehen:
A Light in the ...nTipping the VelvetnSoumissionnSharp ObjectsnSapiens: A Brief History ...nThe Requiem RednThe Dirty Little Secrets ...nThe Coming Woman: A ...nThe Boys in the ...nThe Black MarianStarving Hearts (Triangular Trade ...nShakespeare's SonnetsnSet Me FreenScott Pilgrim's Precious Little ...nRip it Up and ...nOur Band Could Be ...nOlionMesaerion: The Best Science ...nLibertarianism for BeginnersnIt's Only the Himalayasn
Navigieren im DOM: Kinder und Geschwister finden
Nachdem Sie die Titel extrahiert haben, ist es an der Zeit, den Preis und die Verfügbarkeit jedes Buches zu extrahieren. Die Elementinspektion zeigt, dass sowohl der Preis als auch die Verfügbarkeit in einem div mit der Klasse product_price gespeichert sind. Sie können dieses div mit dem CSS-Selektor .product_price auswählen, aber da Sie CSS-Selektoren bereits behandelt haben, wird im Folgenden eine andere Möglichkeit dazu erläutert:
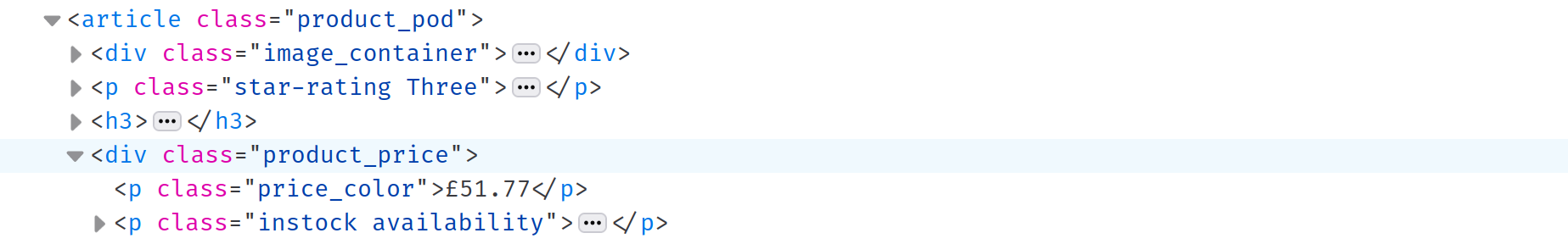
Hinweis: Das
div-Elementist ein Geschwisterelement des zuvor ausgewähltentitleH3-Elements. Durch Aufrufen dernext-MethodevontitleH3können Sie das nächste Geschwisterelement auswählen:
const priceDiv = titleH3.next();n
Sie haben bereits gesehen, dass Sie mit der find-Methode die Kinder eines Elements anhand von CSS-Selektoren finden können. Sie können auch alle Kinder mit der children- Methode auswählen und dann mit der eq-Methode ein bestimmtes Kind auswählen. Dies entspricht dem CSS-Selektor nth-child.
In diesem Fall ist „price“ das erste Kind von „priceDiv“ und „availability“ das zweite Kind von „priceDiv“. Das bedeutet, dass Sie sie mit „priceDiv.children().eq(0)“ bzw. „priceDiv.children().eq(1)“ auswählen können. Tun Sie dies und geben Sie den Preis und die Verfügbarkeit aus:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n console.log(title, price, availability);n});n
Wenn Sie nun den Code ausführen, wird die folgende Ausgabe angezeigt:
A Light in the ... £51.77 In stocknTipping the Velvet £53.74 In stocknSoumission £50.10 In stocknSharp Objects £47.82 In stocknSapiens: A Brief History ... £54.23 In stocknThe Requiem Red £22.65 In stocknThe Dirty Little Secrets ... £33.34 In stocknThe Coming Woman: A ... £17.93 In stocknThe Boys in the ... £22.60 In stocknThe Black Maria £52.15 In stocknStarving Hearts (Triangular Trade ... £13.99 In stocknShakespeare's Sonnets £20.66 In stocknSet Me Free £17.46 In stocknScott Pilgrim's Precious Little ... £52.29 In stocknRip it Up and ... £35.02 In stocknOur Band Could Be ... £57.25 In stocknOlio £23.88 In stocknMesaerion: The Best Science ... £37.59 In stocknLibertarianism for Beginners £51.33 In stocknIt's Only the Himalayas £45.17 In stockn
Auf Attribute zugreifen
Bisher haben Sie das DOM durchsucht und Texte aus den Elementen extrahiert. Mit cheerio ist es auch möglich, Attribute aus einem Element zu extrahieren, was Sie in diesem Abschnitt tun werden. Hier extrahieren Sie die Bewertung von Büchern, indem Sie die Klassenliste der Elemente lesen.
Die Bewertung der Bücher hat eine interessante Struktur. Die Bewertungen sind in einem p-Tag enthalten. Jedes p-Tag hat genau fünf Sterne, aber die Sterne sind mit CSS basierend auf dem Klassennamen des p-Elements farbig gestaltet. In einem p mit der Klasse star-rating.Four sind beispielsweise die ersten vier Sterne gelb gefärbt, was eine Vier-Sterne-Bewertung bedeutet:

Um die Bewertung eines Buches zu extrahieren, müssen Sie die Klassennamen des p-Elements extrahieren. Der erste Schritt besteht darin, den Absatz zu finden, der die Bewertung enthält:
const ratingP = $(element).find(u0022p.star-ratingu0022);n
Indem Sie den Attributnamen an die attr-Methode übergeben, können Sie die Attribute eines Elements lesen. In diesem Fall müssen Sie die Klassenliste lesen, wie im folgenden Code gezeigt:
const starRating = ratingP.attr('class');n
Die Klassenliste hat die folgende Form: star-rating X, wobei X einer der Werte One, Two, Three, Four und Five ist. Das bedeutet, dass Sie die Klassenliste an Leerzeichen trennen und das zweite Element nehmen müssen. Der folgende Code tut dies und wandelt die textuelle Bewertung in eine numerische Bewertung um:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];n
Wenn Sie alles zusammenfügen, sieht Ihr Code wie folgt aus:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();nn const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);n});n
Die Ausgabe sieht wie folgt aus:
A Light in the ... £51.77 In stock 3nTipping the Velvet £53.74 In stock 1nSoumission £50.10 In stock 1nSharp Objects £47.82 In stock 4nSapiens: A Brief History ... £54.23 In stock 5nThe Requiem Red £22.65 In stock 1nThe Dirty Little Secrets ... £33.34 In stock 4nThe Coming Woman: A ... £17.93 In stock 3nThe Boys in the ... £22.60 In stock 4nThe Black Maria £52.15 In stock 1nStarving Hearts (Triangular Trade ... £13.99 In stock 2nShakespeare's Sonnets £20.66 In stock 4nSet Me Free £17.46 In stock 5nScott Pilgrim's Precious Little ... £52.29 In stock 5nRip it Up and ... £35.02 In stock 5nOur Band Could Be ... £57.25 In stock 3nOlio £23.88 In stock 1nMesaerion: The Best Science ... £37.59 In stock 1nLibertarianism for Beginners £51.33 In stock 2nIt's Only the Himalayas £45.17 In stock 2n
Speichern der Daten
Nachdem Sie die Daten von der Webseite gescrapt haben, möchten Sie diese in der Regel speichern. Dazu gibt es mehrere Möglichkeiten, z. B. das Speichern in einer Datei, das Speichern in einer Datenbank oder das Einspeisen in eine Datenverarbeitungs-Pipeline. In diesem Abschnitt lernen Sie die einfachste aller Möglichkeiten kennen: das Speichern von Daten in einer CSV-Datei.
Installieren Sie dazu das Paket node-csv:
npm install csvn
Importieren Sie in index.js die Module fs und csv-stringify:
const fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);n
Um eine lokale Datei zu schreiben, müssen Sie einen WriteStream erstellen:
const filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);n
Deklarieren Sie die Spaltennamen, die als Kopfzeilen zur CSV-Datei hinzugefügt werden:
const columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];n
Erstellen Sie einen Stringifier mit den Spaltennamen:
const stringifier = stringify({ header: true, columns: columns });n
Innerhalb der each -Funktion verwenden Sie den Stringifier, um die Daten zu schreiben:
$(u0022article.product_podu0022).each( (i, element) =u003e {n ...nn const data = { title, rating, price, availability };n stringifier.write(data);nn});n
Schließlich müssen Sie außerhalb der each -Funktion den Inhalt des Stringifiers in die Variable writableStream schreiben:
stringifier.pipe(writableStream);n
Zu diesem Zeitpunkt sollte Ihr Code wie folgt aussehen:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nconst fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);nnconst filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);nnconst columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];nconst stringifier = stringify({ header: true, columns: columns });nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();n n const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);nn const data = { title, rating, price, availability };n stringifier.write(data);nn });nn stringifier.pipe(writableStream);nn});n
Führen Sie den Code aus, woraufhin eine Datei „scraped_data.csv” mit den gescrapten Daten erstellt werden sollte:
title,rating,price,availabilitynA Light in the ...,3,£51.77,In stocknTipping the Velvet,1,£53.74,In stocknSoumission,1,£50.10,In stocknSharp Objects,4,£47.82,In stocknSapiens: A Brief History ...,5,£54.23,In stocknThe Requiem Red,1,£22.65,In stocknThe Dirty Little Secrets ...,4,£33.34,In stocknThe Coming Woman: A ...,3,£17.93,In stocknThe Boys in the ...,4,£22.60,In stocknThe Black Maria,1,£52.15,In stocknStarving Hearts (Triangular Trade ...,2,£13.99,In stocknShakespeare's Sonnets,4,£20.66,In stocknSet Me Free,5,£17.46,In stocknScott Pilgrim's Precious Little ...,5,£52.29,In stocknRip it Up and ...,5,£35.02,In stocknOur Band Could Be ...,3,£57.25,In stocknOlio,1,£23.88,In stocknMesaerion: The Best Science ...,1,£37.59,In stocknLibertarianism for Beginners,2,£51.33,In stocknIt's Only the Himalayas,2,£45.17,In stockn
Fazit
Wie Sie hier gesehen haben, erleichtert die Cheerio-Bibliothek das Web-Scraping mit ihrer jQuery-ähnlichen Syntax und ihrer blitzschnellen Ausführung. In diesem Artikel haben Sie Folgendes gelernt:
- Laden und Parsing einer HTML-Webseite mit cheerio
- Elemente mit CSS-Selektoren finden
- Extrahieren von Daten aus Elementen
- Navigieren im DOM
- Gesammelte Daten in einem lokalen Dateispeicher speichern
Den vollständigen Code finden Sie auf GitHub.
Cheerio ist jedoch nur ein HTML-Parser und kann daher keinen JavaScript-Code ausführen. Das bedeutet, dass Sie es nicht zum Web-Scraping dynamischer Webseiten und Single-Page-Anwendungen verwenden können. Um diese zu scrapen, müssen Sie über Cheerio hinaus nach komplexeren Tools wie Selenium oder Playwright suchen. Und hier kommt Bright Data ins Spiel. Zu den umfangreichen Lösungen für Web-Scraping von Bright Data gehören ein Selenium Scraping Browser und ein Playwright Scraping Browser. Weitere Informationen zu den Produkten finden Sie in unserer Dokumentation zum Scraping-Browser.





