

In diesem Leitfaden zum Web-Scraping mit Parsel in Python erfahren Sie:
- Was Parsel ist
- Warum man es für Web-Scraping verwenden sollte
- Eine Schritt-für-Schritt-Anleitung, die zeigt, wie man Parsel für Web-Scraping verwendet
- Fortgeschrittene Scraping-Szenarien mit Parsel in Python
Lassen Sie uns loslegen!
Was ist Parsel?
Parsel ist eine Python-Bibliothek für das Parsing und Extrahieren von Daten aus HTML-, XML- und JSON-Dokumenten. Es baut auf lxml auf und bietet eine höherwertige und benutzerfreundlichere Oberfläche für das Web-Scraping. Im Detail bietet es eine intuitive API, die den Prozess der Datenextraktion aus HTML- und XML-Dokumenten vereinfacht.
Warum Parsel für das Web-Scraping verwenden?
Parsel bietet interessante Funktionen für das Web-Scraping, darunter
- Unterstützung für XPath- und CSS-Selektoren: Verwenden Sie entweder XPath- oder CSS-Selektoren, um Elemente in HTML- oder XML-Dokumenten zu finden. Weitere Informationen finden Sie in unserem Leitfaden zu XPath- und CSS-Selektoren für das Web-Scraping.
- Datenextraktion: Rufen Sie Text, Attribute oder andere Inhalte aus den ausgewählten Elementen ab.
- Verkettung von Selektoren: Verketten Sie mehrere Selektoren, um Ihre Datenextraktion zu verfeinern.
- Skalierbarkeit: Die Bibliothek eignet sich sowohl für kleine als auch für große Scraping-Projekte.
Beachten Sie, dass die Bibliothek eng in Scrapy integriert ist, das sie zum Parsing und Extrahieren von Daten aus Webseiten verwendet. Parsel kann jedoch auch als eigenständige Bibliothek verwendet werden.
Verwendung von Parsel in Python für das Web-Scraping: Eine Schritt-für-Schritt-Anleitung
In diesem Abschnitt erfahren Sie, wie Sie mit Parsel in Python das Web-Scraping durchführen können. Die Zielseite ist„Hockey Teams: Forms, Searching and Pagination”:

Der Parsel-Scraper extrahiert alle Daten aus der obigen Tabelle. Befolgen Sie die folgenden Schritte und sehen Sie, wie Sie ihn erstellen können!
Voraussetzungen und Abhängigkeiten
Um dieses Tutorial nachzuvollziehen, muss Python 3.10.1 oder höher auf Ihrem Rechner installiert sein. Beachten Sie insbesondere, dass Parsel kürzlich die Unterstützung für Python 3.8 eingestellt hat.
Angenommen, Sie nennen den Hauptordner Ihres Projekts parsel_scraping/. Am Ende dieses Schritts hat der Ordner die folgende Struktur:
parsel_scraping/
├── parsel_scraper.py
└── venv/Dabei gilt:
parsel_scraper.pydie Python-Datei ist, die die Scraping-Logik enthält.venv/enthält die virtuelle Umgebung.
Sie können das Verzeichnis der virtuellen Umgebung venv/ wie folgt erstellen:
python -m venv venvUm sie zu aktivieren, führen Sie unter Windows Folgendes aus:
venvScriptsactivateEntsprechend führen Sie unter macOS und Linux Folgendes aus:
source venv/bin/activateInstallieren Sie in einer aktivierten virtuellen Umgebung die Abhängigkeiten mit:
pip install parsel requestsDiese beiden Abhängigkeiten sind:
parsel: Eine Bibliothek für das Parsing von HTML und das Extrahieren von Daten.requests: Erforderlich, daparselnur ein HTML-Parser ist. Um Web-Scraping durchzuführen, benötigen Sie außerdem einen HTTP-Client wie Requests, um die HTML-Dokumente der Seiten abzurufen, die Sie scrapen möchten.
Großartig! Jetzt haben Sie alles, was Sie benötigen, um Web-Scraping mit Parsel in Python durchzuführen.
Schritt 1: Definieren Sie die Ziel-URL und führen Sie das Parsing des Inhalts durch
Als ersten Schritt dieses Tutorials müssen Sie die Bibliotheken importieren:
import requests
from parsel import SelectorDefinieren Sie dann die Zielwebseite, rufen Sie den Inhalt mit Requests ab und führen Sie das Parsing mit Parsel aus:
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
selector = Selector(text=response.text)Der obige Ausschnitt instanziiert die Klasse Selector() aus Parsel. Diese führt das Parsing des HTML-Codes durch, der aus der Antwort der mit get() durchgeführten HTTP-Anfrage gelesen wurde.
Schritt 2: Extrahieren Sie alle Zeilen aus der Tabelle
Wenn Sie die Tabelle auf der Zielwebseite im Browser untersuchen, sehen Sie den folgenden HTML-Code:
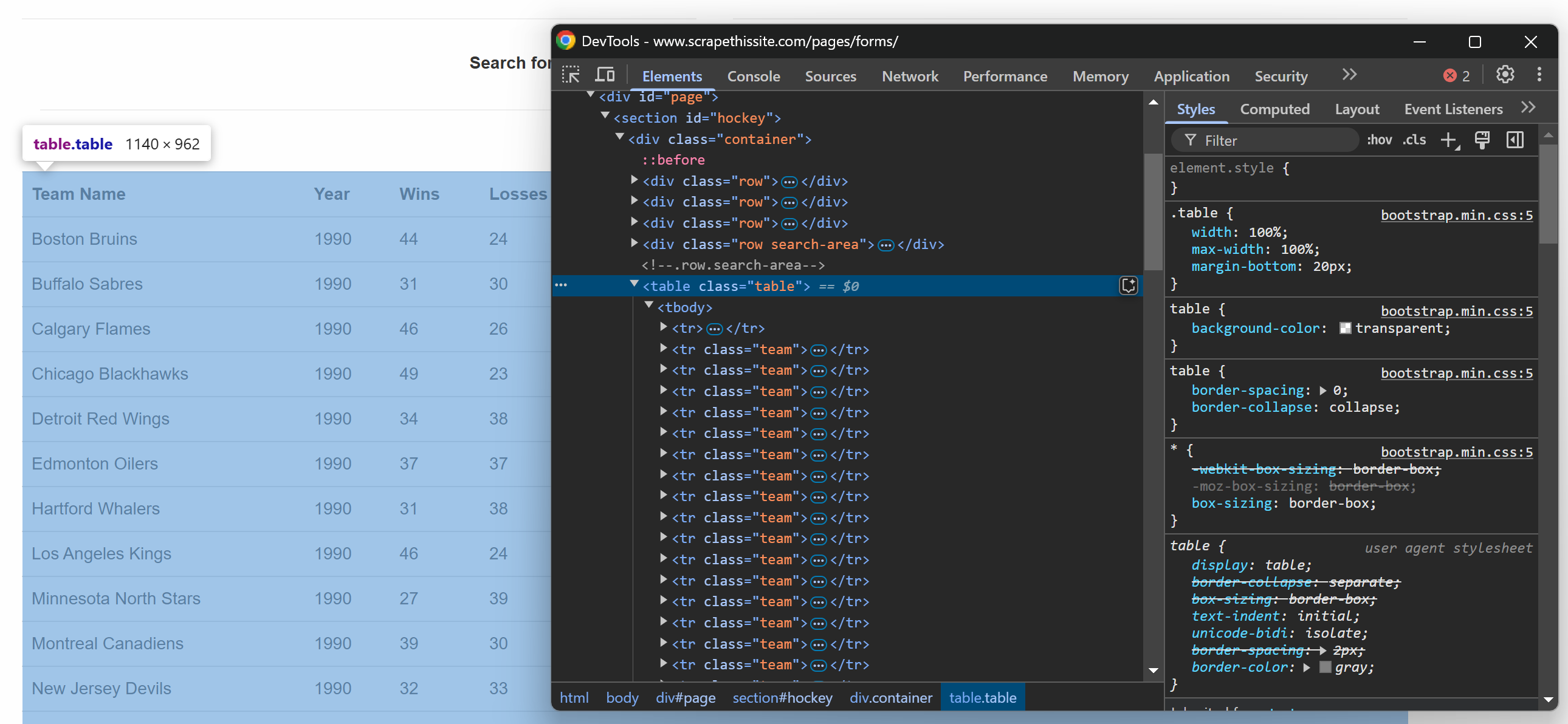
Da die Tabelle mehrere Zeilen enthält, initialisieren Sie ein Array, in dem die gescrapten Daten gespeichert werden sollen:
data = []Beachten Sie nun, dass die HTML-Tabelle eine .table -Klasse hat. Um alle Zeilen aus der Tabelle auszuwählen, können Sie die folgende Codezeile verwenden:
rows = selector.css("table.table tr.team")Hierbei wird die Methode css() verwendet, um den CSS-Selektor auf die geparste HTML-Struktur anzuwenden.
Jetzt ist es an der Zeit, die ausgewählten Zeilen zu durchlaufen und Daten daraus zu extrahieren!
Schritt 3: Durchlaufen der Zeilen
Überprüfen Sie wie zuvor eine Zeile innerhalb der Tabelle:
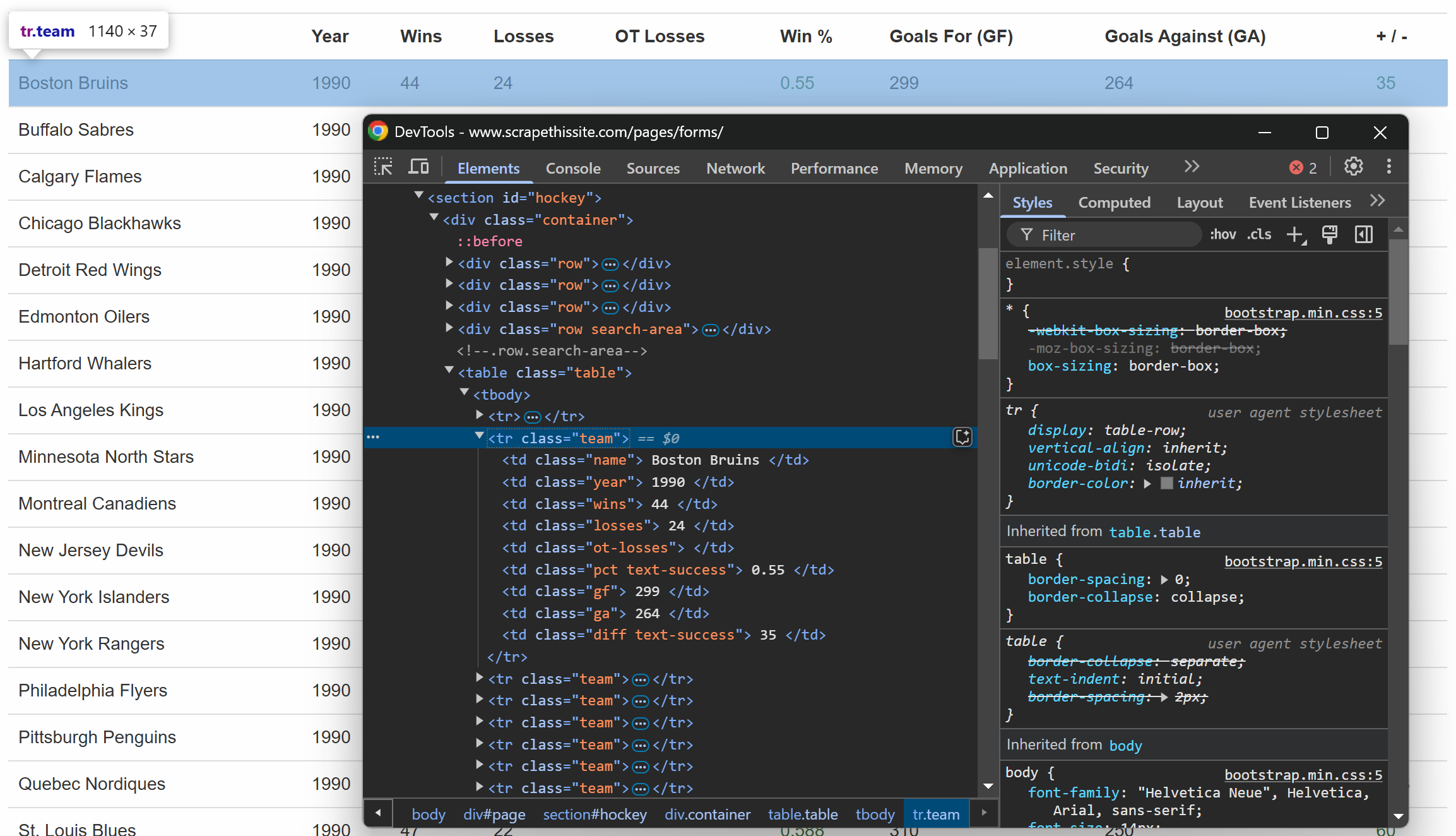
Sie werden feststellen, dass jede Zeile die folgenden Informationen in speziellen Spalten enthält:
- Teamname → innerhalb des Elements
.name - Saisonjahr → im Element
.year - Anzahl der Siege → im Element
.wins - Anzahl der Niederlagen → im Element
.losses - Niederlagen in der Verlängerung → im Element
.ot-losses - Gewinnquote → innerhalb des Elements
.pct - Erzielte Tore (Goals For – GF) → innerhalb des Elements
.gf - Gegentore (Goals Against – GA) → innerhalb des Elements
.ga - Tordifferenz → innerhalb des Elements
.diff
Sie können alle diese Informationen mit der folgenden Logik extrahieren:
for row in rows:
# Daten aus jeder Spalte extrahieren
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Die extrahierten Daten anhängen
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip()
})Der obige Code bewirkt Folgendes:
- Die Methode
get()wählt Textknoten mithilfe von CSS3-Pseudo-Elementen aus. - Die Methode
strip()entfernt alle führenden und nachfolgenden Leerzeichen. - Die Methode
append()hängt den Inhalt an dieDatenliste an.
Großartig! Die Logik zum Parsen der Daten ist fertig.
Schritt 4: Daten ausgeben und Programm ausführen
Als letzten Schritt drucken Sie die gescrapten Daten in der CLI aus:
# Extrahierte Daten ausgeben
print("Daten von der Seite:")
for entry in data:
print(entry)Führen Sie das Programm aus:
python parsel_scraper.pyDies ist das erwartete Ergebnis:
Erstaunlich! Das sind genau die Daten auf der Seite, jedoch in einem strukturierten Format.
Schritt 5: Paginierung verwalten
Bis zum vorherigen Schritt haben Sie die Daten von der Hauptseite der Ziel-URL abgerufen. Was ist, wenn Sie nun alle Daten abrufen möchten? Dazu müssen Sie die Paginierung verwalten, indem Sie einige Änderungen am Code vornehmen.
Zunächst müssen Sie den vorherigen Code in eine Funktion wie diese einkapseln:
def scrape_page(url):
# Seiteninhalt abrufen
response = requests.get(url)
# HTML-Inhalt parsen
selector = Selector(text=response.text)
# Scraping-Logik...
return dataSehen Sie sich nun das HTML-Element an, das die Paginierung verwaltet:
Dieses enthält eine Liste aller Seiten, wobei jede Seite eine in ein <a> -Element eingebettete URL hat. Kapseln Sie die Logik zum Abrufen aller Paginierungs-URLs in einer Funktion:
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Die erste Seite abrufen, um Paginierungslinks zu extrahieren
response = requests.get(base_url)
# Die Seite analysieren
selector = Selector(text=response.text)
# Extrahieren Sie alle Seitenlinks aus dem Paginierungsbereich.
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Passen Sie den Selektor basierend auf der HTML-Struktur an.
unique_links = list(set(page_links)) # Entferne gegebenenfalls Duplikate
# Erstelle vollständige URLs für alle Seiten
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urlsDiese Funktion führt Folgendes aus:
- Die Methode
getall()ruft alle Paginierungslinks ab. - Die Methode
list(set())entfernt Duplikate, um zu verhindern, dass dieselbe Seite zweimal aufgerufen wird. - Die Methode
urljoin()aus der Bibliothekurlib.parsekonvertiert alle relativen URLs in absolute URLs, damit sie für weitere HTTP-Anfragen verwendet werden können.
Damit der obige Code funktioniert, müssen Sie urljoin aus der Python-Standardbibliothek importieren:
from urllib.parse import urljoin Jetzt kannst du alle Seiten mit folgendem Code scrapen:
# Speicherort für die gescrapten Daten
data = []
# Alle Seiten-URLs abrufen
page_urls = get_all_page_urls()
# Durchlaufen Sie sie und wenden Sie die Scraping-Logik an
for url in page_urls:
# Scrapen Sie die aktuelle Seite
page_data = scrape_page(url)
# Fügen Sie die gescrapten Daten zur Liste hinzu
data.extend(page_data)
# Drucken Sie die extrahierten Daten
print("Daten von allen Seiten:")
for entry in data:
print(entry)Der obige Ausschnitt:
- Ruft alle Seiten-URLs ab, indem die Funktion
get_all_page_urls()aufgerufen wird. - Scrape die Daten von jeder Seite, indem die Funktion
scrape_page()aufgerufen wird. Anschließend werden die Ergebnisse mit der Methodeextend()zusammengefasst. - Gibt die gescrapten Daten aus.
Fantastisch! Die Parsel-Paginierungslogik ist nun implementiert.
Schritt 6: Alles zusammenfügen
Nachfolgend finden Sie den aktuellen Inhalt der Datei parsel_scraper.py:
import requests
from parsel import Selector
from urllib.parse import urljoin
def scrape_page(url):
# Seiteninhalt abrufen
response = requests.get(url)
# HTML-Inhalt analysieren
selector = Selector(text=response.text)
# Speicherort für die extrahierten Daten
data = []
# Alle Zeilen im Tabellenkörper auswählen
rows = selector.css("table.table tr.team")
# Jede Zeile durchlaufen und Daten daraus scrapen
for row in rows:
# Daten aus jeder Spalte extrahieren
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Die extrahierten Daten an die Liste anhängen
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip(),
})
return data
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Die erste Seite abrufen, um die Paginierungslinks zu extrahieren
response = requests.get(base_url)
# Die Seite analysieren
selector = Selector(text=response.text)
# Extrahieren aller Seitenlinks aus dem Paginierungsbereich
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Selektor basierend auf HTML-Struktur anpassen
unique_links = list(set(page_links)) # Duplikate entfernen, falls vorhanden
# Vollständige URLs für alle Seiten erstellen
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urls
# Speicherort für die gescraped Daten
data = []
# Alle Seiten-URLs abrufen
page_urls = get_all_page_urls()
# Diese durchlaufen und die Scraping-Logik anwenden
for url in page_urls:
# Aktuelle Seite scrapen
page_data = scrape_page(url)
# Die gescrapten Daten zur Liste hinzufügen
data.extend(page_data)
# Die extrahierten Daten ausgeben
print("Daten von allen Seiten:")
for entry in data:
print(entry)Sehr gut! Sie haben Ihr erstes Scraping-Projekt mit Parsel abgeschlossen.
Fortgeschrittene Web-Scraping-Szenarien mit Parsel in Python
Im vorherigen Abschnitt haben Sie gelernt, wie Sie Parsel in Python verwenden, um Daten aus einer Zielwebseite mithilfe von CSS-Selektoren zu extrahieren. Nun ist es an der Zeit, einige fortgeschrittenere Szenarien zu betrachten!
Elemente anhand von Text auswählen
Parsel bietet verschiedene Abfragemethoden, um den Text aus HTML mithilfe von XPath abzurufen. In diesem Fall wird die Funktion text() verwendet, um den Textinhalt eines Elements zu extrahieren.
Stellen Sie sich vor, Sie haben folgenden HTML-Code:
<html>
<body>
<h1>Willkommen bei Parsel</h1>
<p>Dies ist ein Absatz.</p>
<p>Ein weiterer Absatz.</p>
</body>
</html>Sie können den gesamten Text wie folgt abrufen:
from parsel import Selector
html = """
<html>
<body>
<h1>Willkommen bei Parsel</h1>
<p>Dies ist ein Absatz.</p>
<p>Ein weiterer Absatz.</p>
</body>
</html>
"""
selector = Selector(text=html)
# Text aus dem <h1>-Tag extrahieren
h1_text = selector.xpath("//h1/text()").get()
print("H1-Text:", h1_text)
# Text aus allen <p>-Tags extrahieren
p_texts = selector.xpath("//p/text()").getall()
print("Absatz-Textknoten:", p_texts)Dieser Ausschnitt lokalisiert die Tags <p> und <h1> und extrahiert den Text aus ihnen mit text(), was zu folgendem Ergebnis führt:
H1-Text: Willkommen bei Parsel
Absatz-Textknoten: ['Dies ist ein Absatz.', 'Ein weiterer Absatz.']Eine weitere nützliche Funktion ist contains(), mit der Elemente gefunden werden können, die einen bestimmten Text enthalten. Angenommen, Sie haben folgenden HTML-Code:
<html>
<body>
<p>Dies ist ein Testabsatz.</p>
<p>Ein weiterer Testabsatz.</p>
<p>Unabhängiger Inhalt.</p>
</body>
</html>Sie möchten nun den Text aus den Absätzen extrahieren, die nur das Wort „test“ enthalten. Dazu können Sie den folgenden Code verwenden:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Absätze extrahieren, die das Wort „test” enthalten
test_paragraphs = selector.xpath("//p[contains(text(), 'test')]/text()").getall()
print("Absätze, die 'test' enthalten": test_paragraphs)Der Xpath p[contains(text(), 'test')]/text() sorgt dafür, dass nur der Absatz abgefragt wird, der „test“ enthält. Das Ergebnis lautet:
Absätze, die „test” enthalten: ['Dies ist ein Testabsatz.', 'Ein weiterer Testabsatz.']Was aber, wenn Sie den Text abfangen möchten, der mit einem bestimmten Wert einer Zeichenfolge beginnt? Nun, Sie können die Funktion starts-with() verwenden! Betrachten Sie diesen HTML-Code:
<html>
<body>
<p>Start here.</p>
<p>Start again.</p>
<p>End here.</p>
</body>
</html>Um den Text aus den Absätzen abzurufen, die mit dem Wort „start” beginnen, verwenden Sie p[starts-with(text(), 'Start')]/text() wie folgt:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extrahieren Sie Absätze, deren Text mit „Start” beginnt.
start_paragraphs = selector.xpath("//p[starts-with(text(), 'Start')]/text()").getall()
print("Absätze, die mit 'Start' beginnen": start_paragraphs)Der obige Ausschnitt erzeugt:
Absätze, die mit „Start” beginnen: ['Start here.', 'Start again.']Erfahren Sie mehr über CSS- und XPath-Selektoren.
Verwendung regulärer Ausdrücke
Mit Parsel können Sie Text für erweiterte Bedingungen abrufen, indem Sie reguläre Ausdrücke mit der Funktion re:test() verwenden.
Betrachten Sie diesen HTML-Code:
<html>
<body>
<p>Artikel 12345</p>
<p>Artikel ABCDE</p>
<p>Ein Absatz</p>
<p>2026 ist das aktuelle Jahr</p>
</body>
</html>Um den Text aus den Absätzen zu extrahieren, die nur numerische Werte enthalten, können Sie re:test() wie folgt verwenden:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extrahieren Sie Absätze, deren Text einem numerischen Muster entspricht.
numeric_items = selector.xpath("//p[re:test(text(), 'd+')]/text()").getall()
print("Numerische Elemente:", numeric_items)Das Ergebnis lautet:
Numerische Elemente: ['Element 12345', '2026 ist das aktuelle Jahr']Eine weitere typische Verwendung von regulären Ausdrücken ist das Abfangen von E-Mail-Adressen. Damit kann Text aus Absätzen extrahiert werden, die nur E-Mail-Adressen enthalten. Betrachten Sie beispielsweise den folgenden HTML-Code:
<html>
<body>
<p>Kontaktieren Sie uns unter [email protected]</p>
<p>Senden Sie eine E-Mail an [email protected]</p>
<p>Hier keine E-Mail-Adresse.</p>
</body>
</html>Im Folgenden wird gezeigt, wie Sie mit re:test() Knoten auswählen können, die E-Mail-Adressen enthalten:
from parsel import Selector
selector = Selector(text=html)
# Absätze extrahieren, die E-Mail-Adressen enthalten
emails = selector.xpath("//p[re:test(text(), '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}')]/text()").getall()
print("E-Mail-Übereinstimmungen:", emails)Das Ergebnis lautet:
E-Mail-Übereinstimmungen: ['Kontaktieren Sie uns unter [email protected]', 'Senden Sie eine E-Mail an [email protected]']Navigieren in der HTML-Struktur
Mit Parsel können Sie mit XPath durch den HTML-Baum navigieren, egal wie verschachtelt dieser ist.
Betrachten Sie diesen HTML-Code:
<html>
<body>
<div>
<h1>Titel</h1>
<p>Erster Absatz</p>
</div>
</body>
</html>Sie können alle übergeordneten Elemente des Knotens <p> wie folgt abrufen:
from parsel import Selector
selector = Selector(text=html)
# Wählen Sie das übergeordnete Element des <p>-Tags aus.
parent_of_p = selector.xpath("//p/parent::*").get()
print("Übergeordnetes Element von <p>:", parent_of_p)Ergebnis:
Übergeordnetes Element von <p>: <div>
<h1>Titel</h1>
<p>Erster Absatz</p>
</div>Auf ähnliche Weise können Sie auch gleichrangige Elemente verwalten. Angenommen, Sie haben den folgenden HTML-Code:
<html>
<body>
<ul>
<li>Element 1</li>
<li>Element 2</li>
<li>Element 3</li>
</ul>
</body>
</html>Mit following-sibling können Sie Geschwisterknoten wie folgt abrufen:
from parsel import Selector
selector = Selector(text=html)
# Wählen Sie das nächste Geschwisterelement des ersten <li>-Elements aus.
next_sibling = selector.xpath("//li[1]/following-sibling::li[1]/text()").get()
print("Nächstes Geschwisterelement des ersten <li>:", next_sibling)
# Wählen Sie alle Geschwisterelemente des ersten <li>-Elements aus.
all_siblings = selector.xpath("//li[1]/following-sibling::li/text()").getall()
print("Alle Geschwisterelemente des ersten <li>:", all_siblings)Das Ergebnis lautet:
Nächstes Geschwisterelement des ersten <li>: Element 2
Alle Geschwisterelemente des ersten <li>: ['Element 2', 'Element 3']Parsel-Alternativen für HTML-Parsing in Python
Parsel ist eine der in Python verfügbaren Bibliotheken für Web-Scraping, aber es ist nicht die einzige. Nachfolgend finden Sie weitere bekannte und weit verbreitete Bibliotheken:
- Beautiful Soup: Eine Python-Bibliothek, die das Scraping von Informationen aus Webseiten vereinfacht. In unserem Leitfaden zum Web-Scraping mit Beautiful Soup erfahren Sie, wie Sie diese Bibliothek verwenden können.
lxml: Eine Python-Bindung für die Bibliothekenlibxml2undlibxslt. Sehen Sie sich die Funktionsweise in unserem Tutorial zu lxml für das Parsing von Webdaten an.- PyQuery: Eine Bibliothek, mit der Sie jQuery-Abfragen für XML-Dokumente durchführen können. Damit gehört sie zu den fünf besten Python-HTML-Parsern.
- Scrapy: Ein Open-Source- und kollaboratives Framework zum Extrahieren der benötigten Daten aus Websites. Erfahren Sie, wie Sie Scrapy für das Web-Scraping verwenden.
html.parser: Ein Modul aus der Python-Standardbibliothek, das eine Klasse für das Parsing von Text-HTML- und XTHML-Inhalten bereitstellt.html5-parser: Eine schnelle Implementierung von HTML 5 in Python.
Fazit
In diesem Artikel haben Sie etwas über Parsel in Python gelernt und erfahren, wie Sie es für das Web-Scraping verwenden können. Sie haben mit den Grundlagen begonnen und dann komplexere Szenarien erkundet.
Unabhängig davon, welche Python-Scraping-Bibliothek Sie verwenden, besteht die größte Hürde darin, dass die meisten Websites ihre Daten mit Anti-Bot- und Anti-Scraping-Maßnahmen schützen. Diese Abwehrmaßnahmen können automatisierte Anfragen identifizieren und blockieren, wodurch herkömmliche Scraping-Techniken unwirksam werden.
Glücklicherweise bietet Bright Data eine Reihe von Lösungen, um solche Probleme zu vermeiden:
- Web Unlocker: Eine API, die Anti-Scraping-Schutzmaßnahmen umgeht und mit minimalem Aufwand sauberen HTML-Code von jeder Webseite liefert.
- Scraping-Browser: Ein cloudbasierter, steuerbarer Browser mit JavaScript-Rendering. Er übernimmt automatisch CAPTCHAs, Browser-Fingerprinting, Wiederholungsversuche und vieles mehr für Sie. Er lässt sich nahtlos in Panther oder Selenium PHP integrieren.
- Web Scraper APIs: Endpunkte für den programmatischen Zugriff auf strukturierte Webdaten aus Dutzenden beliebter Domains.
Sie möchten sich nicht mit Web-Scraping beschäftigen, sind aber dennoch an Online-Daten interessiert? Entdecken Sie unsere gebrauchsfertigen Datensätze!
Melden Sie sich jetzt bei Bright Data an und starten Sie die Gratis-Testversion, um unsere Scraping-Lösungen zu testen.





