

In diesem Leitfaden erfahren Sie:
- Was
curl_cffiist und welche Funktionen es bietet - Wie es die TLS-Fingerabdruck-basierte Bot-Erkennung minimiert
- Wie man es mit Python für das Web-Scraping verwendet
- Fortgeschrittene Verwendung und Methoden
- Einen Vergleich mit ähnlichen HTTP-Clients
Lassen Sie uns eintauchen!
Was ist curl_cffi?
curl_cffi ist eine Bibliothek, die Python-Bindungen für den Fork curl-impersonate über CFFI bereitstellt. Mit anderen Worten: Es handelt sich um einen HTTP-Client, der in der Lage ist, Browser-TLS/JA3/HTTP2-Fingerabdrücke zu imitieren. Damit eignet sich die Bibliothek hervorragend, um Anti-Bot-Sperren zu umgehen, die auf TLS-Fingerabdrücken basieren.
⚙️ Funktionen
- Unterstützt JA3/TLS- und HTTP2-Fingerabdruck-Imitation, einschließlich aktueller Browser und benutzerdefinierter Fingerabdrücke
- Viel schneller als
requestsundhttpx, vergleichbar mitaiohttp - Imitiert die
Requests-API - Unterstützt
asynciofür asynchrone HTTP-Anfragen - Unterstützt Proxy-Rotation bei jeder Anfrage
- Unterstützt HTTP/2.0
- Unterstützt
WebSockets
So funktioniert es
curl_cffi basiert auf cURL Impersonate, einer Bibliothek, die TLS-Fingerabdrücke generiert, die mit realen Browsern übereinstimmen.
Wenn Sie eine HTTPS-Anfrage senden, findet ein TLS-Handshake statt, bei dem ein eindeutiger TLS-Fingerabdruck erzeugt wird. Da sich HTTP-Clients von Browsern unterscheiden, können ihre Fingerabdrücke die Automatisierung offenlegen und Anti-Bot-Abwehrmaßnahmen auslösen.
cURL Impersonate modifiziert cURL, um es an echte Browser-TLS-Fingerabdrücke anzupassen:
- Anpassungen der TLS-Bibliothek: Verwenden Sie die von Browsern verwendeten Bibliotheken für TLS-Verbindungen anstelle derjenigen von cURL.
- Konfigurationsänderungen: Passen Sie TLS-Erweiterungen und SSL-Optionen an, um Browser nachzuahmen.
- HTTP/2-Anpassung: Passen Sie die Handshake-Einstellungen des Browsers an.
- Nicht standardmäßige cURL-Flags: Legen Sie
--ciphers,--curvesund benutzerdefinierte Header für Genauigkeit fest.
Dadurch sehen die Anfragen wie Browser-Anfragen aus, was dabei hilft, die Bot-Erkennung zu umgehen. Weitere Informationen finden Sie in unserem Leitfaden zu cURL Impersonate.
Verwendung von curl_cffi für Web-Scraping: Schritt-für-Schritt-Anleitung
Angenommen, Ihr Ziel ist es, die Seite „Keyboard“ von Walmart zu scrapen:
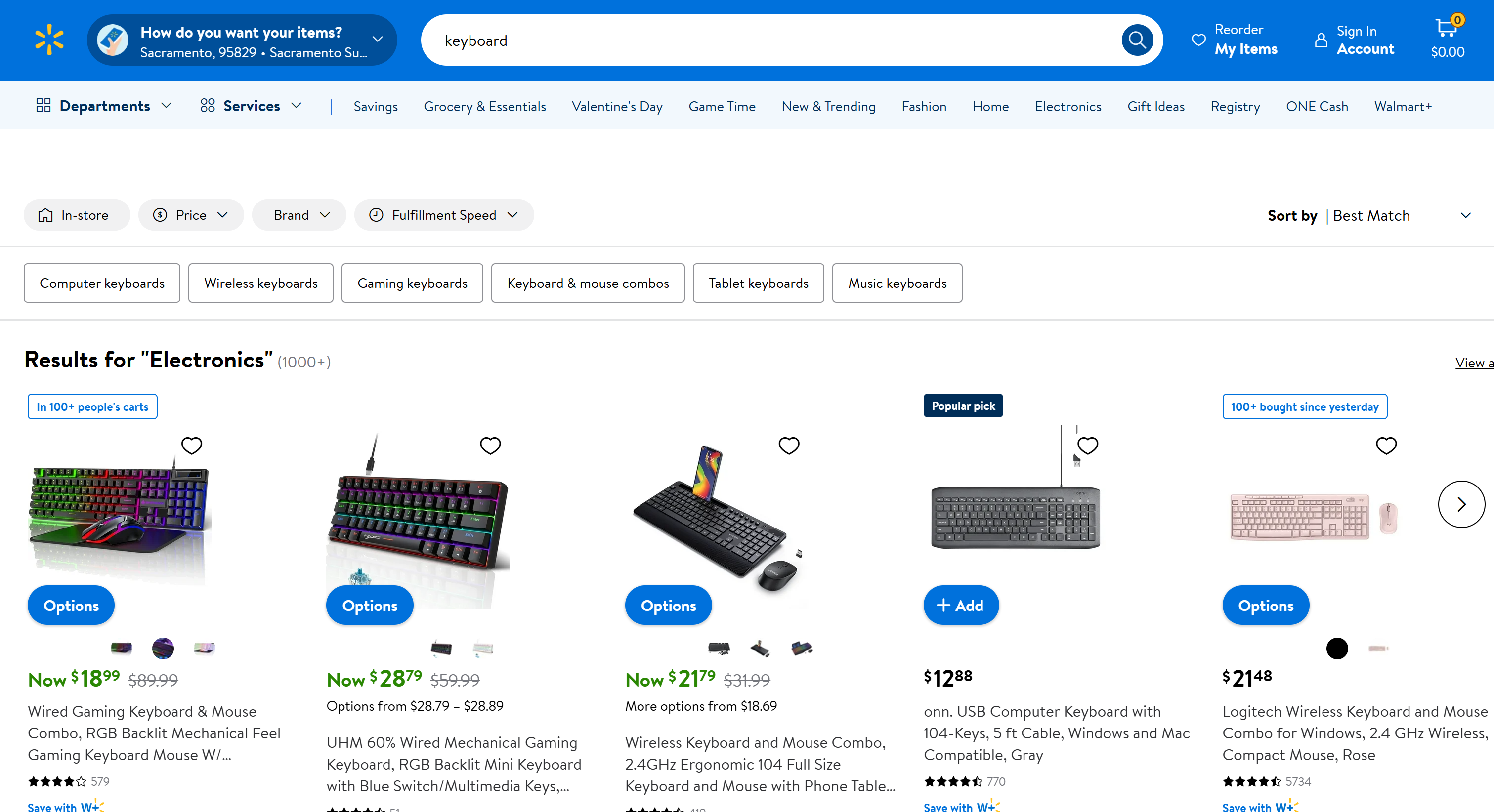
Wenn Sie versuchen, mit einem beliebigen HTTP-Client auf diese Seite zuzugreifen, erhalten Sie die folgende Fehlerseite:
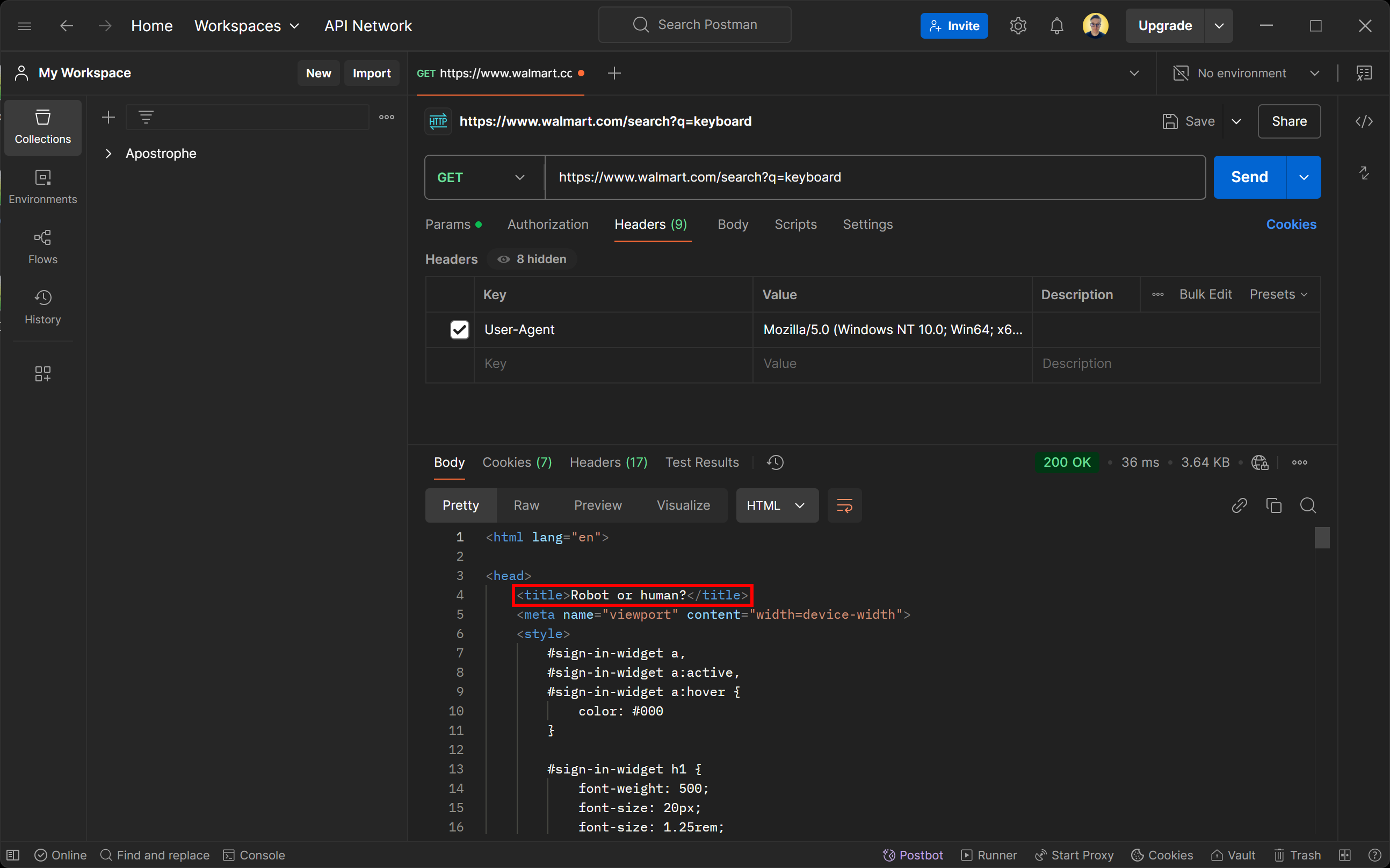
Lassen Sie sich nicht vom Antwortstatus 200 OK täuschen. Die vom Walmart-Server zurückgegebene Seite ist eigentlich eine Bot-Erkennungsseite. Sie fordert Sie ausdrücklich auf, mit einer CAPTCHA-Aufgabe zu bestätigen, dass Sie ein Mensch sind.
Sie fragen sich vielleicht, wie das möglich ist, obwohl Sie den User-Agent so eingestellt haben, dass er einen echten Browser simuliert? Die Antwort lautet: TLS-Fingerprinting!
Sehen wir uns nun an, wie Sie mit curl_cffi Anti-Bot-Maßnahmen umgehen und problemlos Web-Scraping durchführen können.
Schritt 1: Projekt einrichten
Stellen Sie zunächst sicher, dass Python 3+ auf Ihrem Rechner installiert ist. Falls nicht, laden Sie es von der offiziellen Website herunter und befolgen Sie die Installationsanweisungen.
Erstellen Sie dann mit diesem Befehl ein Verzeichnis für Ihr curl_cffi -Scraping-Projekt:
mkdir curl-cfii-scraper
Navigieren Sie in dieses Verzeichnis und richten Sie darin eine virtuelle Umgebung ein:
cd curl-cfii-Scraper
python -m venv env
Öffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind beide gute Optionen.
Erstellen Sie nun eine Datei namens scraper.py im Projektordner. Diese ist zunächst leer, aber Sie werden bald die Scraping-Logik hinzufügen.
Aktivieren Sie die virtuelle Umgebung im Terminal Ihrer IDE. Unter Linux oder macOS verwenden Sie:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Großartig! Sie sind nun vollständig eingerichtet und können loslegen.
Schritt 2: Installieren Sie curl_cffi
Installieren Sie in einer aktivierten virtuellen Umgebung den HTTP-Client über das curl-cffi -Pip-Paket:
pip install curl-cffi
Im Hintergrund lädt diese Bibliothek automatisch die curl-Impersonation-Binärdateien für Windows, macOS und Linux herunter.
Schritt 3: Verbindung zur Zielseite herstellen
Importieren Sie Anfragen aus curl_cffi:
from curl_cffi import requests
Dieses Objekt stellt eine hochrangige API bereit, die der Python Requests-Bibliothek ähnelt.
Sie können es verwenden, um eine GET-HTTP-Anfrage an die Zielseite wie folgt auszuführen:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
Das Argument impersonate="chrome" weist curl_cffi an, die HTTP-Anfrage so aussehen zu lassen, als käme sie von der neuesten Version von Chrome. Infolgedessen behandelt Walmart die automatisierte Anfrage wie eine normale Browseranfrage und gibt die Standardwebseite anstelle einer Anti-Bot-Seite zurück.
Sie können auf den HTML-Inhalt der Zielseite zugreifen mit:
html = response.text
Wenn Sie html ausdrucken, sehen Sie Folgendes:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>Elektronik – Walmart.com</title>
<!-- der Kürze halber ausgelassen ... -->
Großartig! Das ist der HTML-Code der regulären Walmart-Produktseite „Tastatur”.
Schritt 4: Fügen Sie die Logik zum Extrahieren der Daten hinzu
curl_cffi ist lediglich ein HTTP-Client, mit dem Sie den HTML-Code einer Seite abrufen können. Wenn Sie Web-Scraping durchführen möchten, benötigen Sie zusätzlich eine Bibliothek für das HTML-Parsing wie BeautifulSoup. Weitere Informationen finden Sie in unserem Leitfaden zum BeautifulSoup-Web-Scraping.
Installieren Sie BeautifulSoup in der aktivierten virtuellen Umgebung:
pip install beautifulsoup4
Importieren Sie es in scraper.py:
from bs4 import BeautifulSoup
Verwenden Sie es dann, um den HTML-Code der Seite zu parsen:
soup = BeautifulSoup(response.text, "html.parser")
„html.parser” ist der Standard-HTML-Parser aus der Python-Standardbibliothek, der von BeautifulSoup zum Parsing der HTML-Zeichenfolge verwendet wird. Nun enthält soup alle Methoden, die Sie benötigen, um HTML-Elemente auf der Seite auszuwählen und Daten aus ihnen zu extrahieren.
Da in diesem Beispiel das Parsing der Daten nicht im Vordergrund steht, werden wir nur den Seitentitel scrapen. Sie können ihn über einen CSS-Selektor mit der Methode find() auswählen und dann mit dem Attribut text auf seinen Text zugreifen:
title_element = soup.find("title")
title = title_element.text
Weitere Informationen zu fortgeschritteneren Scraping-Verfahren finden Sie in unserem Leitfaden zum Scraping von Walmart.
Drucken Sie abschließend den Seitentitel aus:
print(title)
Großartig! Sie haben eine grundlegende Logik für Web-Scraping implementiert.
Schritt 5: Alles zusammenfügen
Dies ist Ihr endgültiges curl_cffi -Web-Scraping-Skript:
from curl_cffi import requests
from bs4 import BeautifulSoup
# Senden Sie eine GET-Anfrage an die Walmart-Suchseite für „keyboard”
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# Extrahieren Sie den HTML-Code aus der Seite
html = response.text
# Den Antwortinhalt mit BeautifulSoup analysieren
soup = BeautifulSoup(response.text, "html.parser")
# Den Titel-Tag mit einem CSS-Selektor suchen und ausgeben
title_element = soup.find("title")
# Daten daraus extrahieren
title = title_element.text
# Komplexere Scraping-Logik...
# Die gescrapten Daten ausgeben
print(title)
Starten Sie es mit dem folgenden Befehl:
python3 Scraper.py
Oder, gleichwertig, unter Windows:
python Scraper.py
Das Ergebnis lautet:
Elektronik – Walmart.com
Wenn Sie das Argument impersonate="chrome" entfernen, erhalten Sie stattdessen:
Roboter oder Mensch?
Dies zeigt, wie wichtig die Browser-Identitätsfälschung ist, wenn es darum geht, Anti-Scraping-Maßnahmen zu umgehen.
Mission erfüllt!
curl_cffi: Fortgeschrittene Verwendung
Nachdem Sie nun wissen, wie die Bibliothek funktioniert, können Sie sich mit einigen fortgeschritteneren Szenarien befassen.
Auswahl der Browser-Identitätswechsel
curl_cffi unterstützt die Imitation mehrerer Browser. Jeder Browser ist mit einer eindeutigen Bezeichnung verknüpft, die Sie wie folgt an das Argument „impersonate” übergeben können:
response = requests.get("<YOUR_URL>", impersonate="<BROWSER_LABEL>")
Hier sind die Bezeichnungen für die unterstützten Browser:
chrome99,chrome100,chrome101,chrome104,chrome107,chrome110,chrome116,chrome119,chrome120,chrome123,chrome124,chrome131chrome99_android,chrome131_androidedge99,edge101safari15_3,safari15_5,safari17_0,safari17_2_ios,safari18_0,safari18_0_ios
Hinweise:
- Um immer die neuesten Browserversionen zu imitieren, können Sie einfach
Chrome,SafariundSafari_iosverwenden. - Firefox ist derzeit nicht verfügbar, da nur WebKit-basierte Browser unterstützt werden.
- Browser-Versionen werden nur hinzugefügt, wenn sich ihre Fingerabdrücke ändern. Wenn eine Version, z. B.
chrome122, übersprungen wird, können Sie sie dennoch imitieren, indem Sie die Header der vorherigen Version verwenden. - Verwenden Sie für Nicht-Browser-Ziele
ja3,akamaiund ähnliche Argumente, um Ihre eigenen benutzerdefinierten TLS-Fingerabdrücke anzugeben. Weitere Informationen finden Sie in der Dokumentation zur Imitation.
Sitzungsverwaltung
Genau wie die Requests-Bibliothek unterstützt auch curl-cfii Sitzungen. Mit Sitzungs-Objekten können Sie bestimmte Parameter über mehrere Anfragen hinweg beibehalten, z. B. Cookies, Header oder andere sitzungsspezifische Daten.
So können Sie eine Sitzung mit den Python-Bindings für die cURL Impersonate-Bibliothek definieren:
# Neue Sitzung erstellen
session = requests.Session()
# Dieser Endpunkt setzt ein Cookie auf dem Server.
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# Die Cookies der Sitzung ausgeben, um zu überprüfen, ob sie gespeichert wurden.
print(session.cookies)
Die Ausgabe des obigen Skripts lautet:
<Cookies[<Cookie userId=5 for httpbin.org />]>
Das Ergebnis beweist, dass die Sitzung den Status über mehrere Anfragen hinweg beibehält, z. B. durch Speichern der vom Server definierten Cookies.
Proxy-Integration
Genau wie die Requests -Bibliothek unterstützt curl_cffi die Proxy-Integration über ein Proxies -Objekt:
# Definieren Sie Ihre Proxy-URL.
proxy = "YOUR_PROXY_URL"
# Erstellen Sie ein Wörterbuch mit Proxys für HTTP und HTTPS.
proxies = {"http": proxy, "https": proxy}
# Stellen Sie eine Anfrage unter Verwendung eines Proxys und eines Browser-Identitätswechsels
response = requests.get("<YOUR_URL>", impersonate="chrome", proxies=proxies)
Da die zugrunde liegende API der von Requests sehr ähnlich ist, lesen Sie bitte unsere Anleitung zur Verwendung eines Proxys in Requests.
Asynchrone API
curl_cffi unterstützt asynchrone Anfragen über asyncio mithilfe des AsyncSession -Objekts:
from curl_cffi.requests import AsyncSession
import asyncio
# Definieren Sie eine asynchrone Funktion, um den asynchronen Code auszuführen.
async def fetch_data():
async with AsyncSession() as session:
# Führen Sie die asynchrone GET-Anfrage aus.
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# Den Antworttext ausgeben
print(response.text)
# Die asynchrone Funktion ausführen
asyncio.run(fetch_data())
Die Verwendung von AsyncSession erleichtert die effiziente Bearbeitung mehrerer asynchroner Anfragen, was für die Beschleunigung des Web-Scrapings von entscheidender Bedeutung ist.
WebSockets-Verbindung
curl_cffi unterstützt auch WebSocketsüber die WebSocket -Klasse:
from curl_cffi.requests import WebSocket
# Callback-Funktion zum Verarbeiten eingehender Nachrichten definieren
def on_message(ws, message):
print(message)
# Initialisieren Sie die WebSocket-Verbindung mit dem Callback
ws = WebSocket(on_message=on_message)
# Stellen Sie eine Verbindung zu einem Beispiel-WebSocket-Server her und warten Sie auf Nachrichten
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")
Dies ist besonders nützlich, um Echtzeitdaten von Websites oder APIs zu scrapen, die WebSocket verwenden, um Daten dynamisch zu füllen. Beispiele hierfür sind Websites mit Finanzmarktdaten, Live-Sportergebnissen oder Live-Chats.
Anstatt gerenderte Seiten zu scrapen, können Sie direkt auf den WebSocket-Kanal zugreifen, um Daten effizient abzurufen.
Hinweis: Dank der AsyncWebSocket -Klasse können Sie WebSocketsasynchron verwenden.
curl_cffi vs Requests vs AIOHTTP vs HTTPX für Web-Scraping
Nachfolgend finden Sie eine Übersichtstabelle zum Vergleich von curl_cffi mit anderen beliebten Python-HTTP-Clients für das Web-Scraping:
| Funktion | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| Sync-API | ✔️ | ✔️ | ❌ | ✔️ |
| Asynchrone API | ✔️ | ❌ | ✔️ | ✔️ |
Unterstützung für **WebSockets** |
✔️ | ❌ | ✔️ | ❌ |
| Verbindungspooling | ✔️ | ✔️ | ✔️ | ✔️ |
| Unterstützung für HTTP/2 | ✔️ | ❌ | ❌ | ✔️ |
**User-Agent** -Anpassung |
✔️ | ✔️ | ✔️ | ✔️ |
| TLS-Fingerabdruck-Spoofing | ✔️ | ❌ | ❌ | ❌ |
| Geschwindigkeit | Hoch | Mittel | Hoch | Mittel |
| Wiederholungsmechanismus | ❌ | Verfügbar über HTTP-Adapter |
Nur über eine Drittanbieter-Bibliothek verfügbar | Verfügbar über integrierte Transports |
| Proxy-Integration | ✔️ | ✔️ | ✔️ | ✔️ |
| Cookie-Handhabung | ✔️ | ✔️ | ✔️ | ✔️ |
curl_cffi Alternativen für Web-Scraping
curl_cffi erfordert einen manuellen Ansatz für das Web-Scraping, bei dem Sie den Großteil des Codes selbst schreiben müssen. Dies eignet sich zwar für einfache statische Websites, kann jedoch zu Problemen führen, wenn dynamische oder besser gesicherte Websites das Ziel sind.
Bright Data bietet eine Reihe von curl_cffi -Alternativen für das Web-Scraping:
- Scraping-Browser-API: Vollständig verwaltete Cloud-Browser-Instanzen, die in Puppeteer, Selenium und Playwright integriert sind. Diese Browser bieten eine integrierte CAPTCHA-Lösung und automatische Rotation von Proxies, wodurch Anti-Bot-Abwehrmaßnahmen umgangen werden und die Interaktion mit Websites wie bei echten Benutzern erfolgt.
- Web Scraper APIs: Vorkonfigurierte Endpunkte zum Abrufen aktueller, strukturierter Daten aus über 100 beliebten Domains. Diese APIs sind ethisch und konform und ermöglichen eine einfache Datenextraktion mit HTTPX oder jedem anderen HTTP-Client.
- No-Code-Scraper: Ein intuitiver On-Demand-Datenerfassungsdienst, der das Codieren überflüssig macht. Er bietet Kontrolle, Skalierbarkeit und Flexibilität, ohne dass Sie sich mit Infrastruktur, Proxys oder Anti-Scraping-Hürden auseinandersetzen müssen.
- Datensätze: Greifen Sie auf vorgefertigte Datensätze von verschiedenen Websites zu oder passen Sie Datensammlungen an Ihre Anforderungen an.
Diese Lösungen vereinfachen das Scraping, indem sie robuste, skalierbare und konforme Datenextraktions-Tools bieten, die den manuellen Aufwand reduzieren.
Fazit
In diesem Artikel haben Sie erfahren, wie Sie die Bibliothek curl_cffi für das Web-Scraping verwenden können. Sie haben ihren Zweck, ihre wichtigsten Funktionen und ihre Vorteile kennengelernt. Dieser HTTP-Client zeichnet sich als schnelle und zuverlässige Option für Anfragen aus, die echte Browser imitieren.
Automatisierte HTTP-Anfragen können jedoch Ihre öffentliche IP-Adresse offenlegen und so möglicherweise Ihre Identität und Ihren Standort preisgeben, was ein Datenschutzrisiko darstellt. Um Ihre Sicherheit und Anonymität zu schützen, ist eine der effektivsten Lösungen die Verwendung eines Proxy-Servers, um Ihre IP-Adresse zu verbergen.
Bright Data kontrolliert die besten Proxy-Server der Welt und bedient Fortune-500-Unternehmen sowie mehr als 20.000 Kunden. Das Angebot umfasst eine breite Palette von Proxy-Typen:
- Datacenter-Proxys – Über 770.000 Rechenzentrums-IPs.
- Residential-Proxys – Über 72 Millionen Residential-IPs in mehr als 195 Ländern.
- ISP-Proxys – Über 700.000 ISP-IPs.
- Mobile-Proxy – Über 7 Millionen mobile IPs.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Proxys und Scraping-Lösungen zu testen!




