

In diesem Blogbeitrag erfahren Sie:
- Warum TensorFlow ein ideales Tool für die Datenanalyse durch maschinelles Lernen ist.
- Auf welche Lösungen Sie sich verlassen sollten, um hochwertige Daten zu sammeln, die wertvolle Erkenntnisse für Ihr Unternehmen liefern.
- Wie Sie TensorFlow nutzen können, um eine Sentimentanalyse für Amazon-Produktbewertungen durchzuführen, die über Bright Data abgerufen wurden.
Lassen Sie uns loslegen!
Warum Daten mit TensorFlow und maschinellem Lernen analysieren?
Daten sind wertvoll, weil sie Ihnen helfen, Erkenntnisse zu gewinnen. Dies gilt insbesondere für Unternehmen, die Daten nutzen, um Entscheidungen zu treffen, Strategien anzupassen und Ergebnisse zu optimieren. Zu den gemeinsamen Zielen gehören die Verbesserung der Kundenzufriedenheit und die Optimierung der Gesamtleistung von Marketingstrategien.
Wenn es um Datenanalyse geht, ist TensorFlow eine der beliebtesten Open-Source-Bibliotheken. Es unterstützt maschinelles Lernen und künstliche Intelligenz und deckt eine Vielzahl von Aufgaben ab.
In diesem Artikel werden wir TensorFlow insbesondere für die Sentimentanalyse von Produktbewertungen einsetzen. Gleichzeitig kann dieselbe Technologie auf viele andere Anwendungsfälle angewendet werden, wie z. B. Kundenfeedback-Analyse, Empfehlungssysteme, Vorhersagemodelle und andere.
So rufen Sie Daten aus Ihrem Unternehmen ab
Unabhängig davon, wie fortschrittlich Ihre Pipeline für maschinelles Lernen oder künstliche Intelligenz ist, wissen alle Datenanalysten, dass„mehr Daten bessere Algorithmen schlagen“. Einfach ausgedrückt: Der Schlüssel zu aussagekräftigen Erkenntnissen ist die Qualität und Quantität der Daten.
Aber wie kommt man an viele gute Daten? Die Datenbeschaffung kann eine Herausforderung sein, und es ist wichtig, sich auf vertrauenswürdige Datenanbieter wie Bright Data zu verlassen.
Bright Data bietet Ihnen eine breite Palette an Datenlösungen, darunter
- Web Scraper API: Programmatischer Zugriff auf strukturierte Webdaten aus Dutzenden beliebter Domains, die per Web-Scraping abgerufen werden.
- Datensatz-Marktplatz: Aktuelle, gebrauchsfertige Datensätze mit Milliarden von Einträgen aus über 100 Websites.
- Managed Data Acquisition Services: Vollständig verwaltete Datenerfassungsdienste auf Unternehmensniveau, mit denen Sie Daten und Erkenntnisse erhalten, ohne sich um die Entwicklung oder Wartung kümmern zu müssen.
Diese Produkte richten sich an Forscher, KMUs (kleine und mittlere Unternehmen) und Großunternehmen. Im Einzelnen ermöglichen sie die Erfassung öffentlicher Webdaten für Machine-Learning-Workflows, KI-Training, Agentenentwicklung und eine Vielzahl anderer Szenarien.
So führen Sie eine Sentimentanalyse für Amazon-Produktbewertungen durch, die über Bright Data abgerufen wurden
In diesem Schritt-für-Schritt-Abschnitt verwenden Sie TensorFlow, um einen realistischen Datenanalyse-Workflow zu erstellen. Wir behandeln den praktischen Anwendungsfall der Durchführung einer Sentimentanalyse für Produktbewertungen.
Angenommen, Sie sind ein Unternehmen, das mehrere Produkte auf Amazon verkauft. Um die Kundenzufriedenheit zu verbessern, benötigen Sie einen Prozess, der regelmäßig die Bewertungen der Nutzer für jedes Produkt überwacht und eine Sentimentanalyse durchführt, um zu verstehen, was gut funktioniert und was verbessert werden muss.
In diesem Beispiel konzentrieren wir uns auf das folgende Amazon-Produkt:
Hinweis: Sie können diesen Workflow auf mehrere Amazon-Produkte ausweiten, da der Bright Data Amazon Reviews Scraper das Scraping von Bewertungen mehrerer Produkte mit unbegrenzter Skalierbarkeit unterstützt.
Dies ist ein großartiges Beispiel, da es eine große Anzahl von Bewertungen gibt, die sich gleichmäßig über alle 5 Sterne verteilen: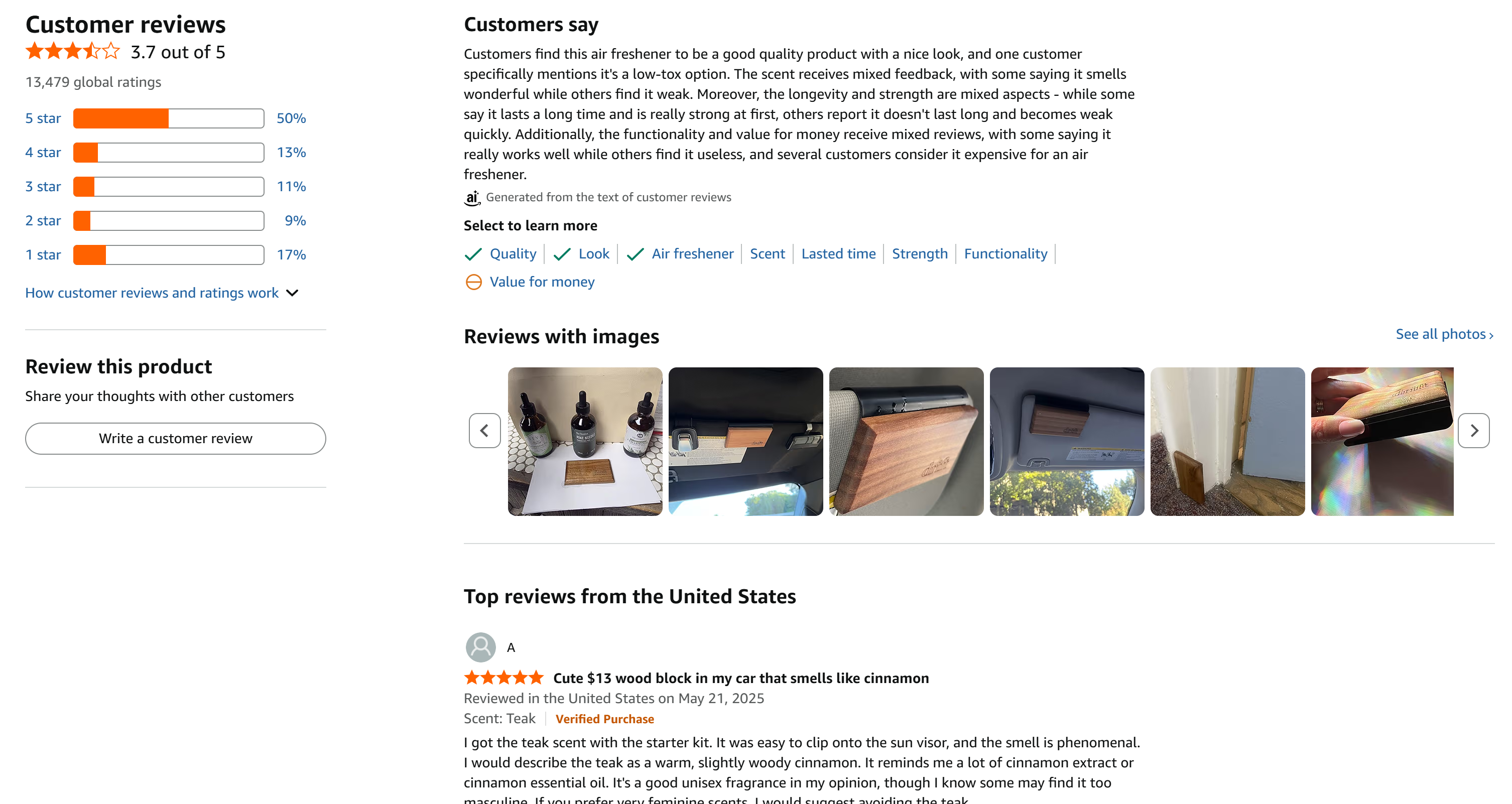
Befolgen Sie die nachstehenden Anweisungen, um einen unternehmensgerechten Prozess zur Stimmungsanalyse zu erstellen. Die Bewertungen für das Produkt werden über Bright Data abgerufen und anschließend mithilfe von Machine-Learning-Workflows in TensorFlow mit Python analysiert.
Voraussetzungen
Um diesem Tutorial folgen zu können, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.9+ lokal installiert ist.
- Ein Bright Data-Konto mit einem API-Schlüssel.
Machen Sie sich keine Sorgen, wenn Sie noch kein Bright Data-Konto haben, da Sie in den folgenden Schritten durch den Einrichtungsprozess geführt werden.
Kenntnisse über das Universal Sentence Encoder-Modell, die Funktionsweise von Vektor-Embeddings und die Funktionsweise von Keras Sequential- Modellen mit dichten neuronalen Netzwerkschichten sind sehr hilfreich, um die TensorFlow-Logik der Sentimentanalyse vollständig zu verstehen.
Schritt 1: Einrichten eines JupyterLab-Projekts
Da dieser TensorFlow-Maschinelle-Lernprozess auch Diagramme und Datenvisualisierung umfasst, ist es sinnvoll, JupyterLab als Entwicklungsumgebung zu verwenden. Anschließend kann der Code einfach in eine produktionsreife ML-Pipeline migriert werden.
Beginnen Sie zunächst mit der Erstellung eines Projektordners. Navigieren Sie dorthin:
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysisInitialisieren Sie als Nächstes eine virtuelle Umgebung innerhalb des Ordners:
python -m venv .venvNun ist es an der Zeit, die virtuelle Umgebung zu aktivieren. Führen Sie unter macOS/Linux folgenden Befehl aus:
source .venv/bin/activateUnter Windows führen Sie folgenden Befehl aus:
.venvScriptsactivateInstallieren Sie JupyterLab in der aktiven Umgebung über das jupyterlab -Paket:
pip install jupyterlabFahren Sie fort, indem Sie JupyterLab mit folgendem Befehl starten:
jupyter labSie sehen nun die JupyterLab-Oberfläche:
Definieren Sie ein neues Notebook, indem Sie auf die Schaltfläche „Python 3 (ipykernel)“ im Abschnitt „Notebook“ klicken:
Geben Sie Ihrem Notebook einen Namen und speichern Sie es.
Fertig! Sie haben nun eine Python-Umgebung eingerichtet, die sich ideal für die Entwicklung von Workflows zur Datenanalyse im Bereich maschinelles Lernen mit TensorFlow eignet.
Schritt 2: Installieren Sie die Bibliotheken
Fügen Sie einen Code-Block hinzu und installieren Sie die erforderlichen Bibliotheken mit:
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requestsFühren Sie diesen Block aus, um alle für diese Implementierung erforderlichen Bibliotheken zu installieren:
tensorflow: Zum Erstellen und Trainieren von Modellen für maschinelles Lernen.tensorflow-hub: Zum Laden vorab trainierter Modelle für maschinelles Lernen.scikit-learn: Für die Datenvorverarbeitung, Train-Test-Aufteilung, Metriken und Klassengewichtung.pandas: Zur Verarbeitung tabellarischer Daten und zur Durchführung von Aggregationen.numpy: Für numerische Berechnungen und die Verarbeitung von Arrays.matplotlib: Zum Zeichnen von Diagrammen und Visualisieren von Ergebnissen.requests: Zum Ausführen von HTTP-Anfragen und zur Interaktion mit der Bright Data Scraper API.
Fügen Sie als Nächstes einen weiteren Code-Block hinzu, um alle erforderlichen Bibliotheken zu importieren und zu konfigurieren:
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow import keras
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.utils.class_weight import compute_class_weight
from IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)Großartig! Damit sind alle Ihre nachfolgenden Codeblöcke bereit für die Abfrage von Bright Data und TensorFlow-basierte Analyse-Workflows.
Schritt 3: Erste Schritte mit dem Bright Data Amazon Reviews Scraper
Bevor Sie den Code zum Abrufen von Amazon-Bewertungsdaten schreiben, nehmen Sie sich etwas Zeit, um Ihr Bright Data-Konto einzurichten und sich mit der erforderlichen Lösung zum Scraping von Daten vertraut zu machen.
In diesem Tutorial verwenden wir die Bright Data Amazon Reviews API, mit der Sie programmgesteuert aktuelle Bewertungsdaten für ein bestimmtes Produkt scrapen können. Dies ist ideal, wenn Sie Bewertungen für Ihre eigenen Produkte überwachen möchten.
Alternativ bietet Bright Data für allgemeinere Szenarien auch einen vorgefertigten Datensatz„Amazon Reviews”mit über 28,6 Millionen Bewertungen an: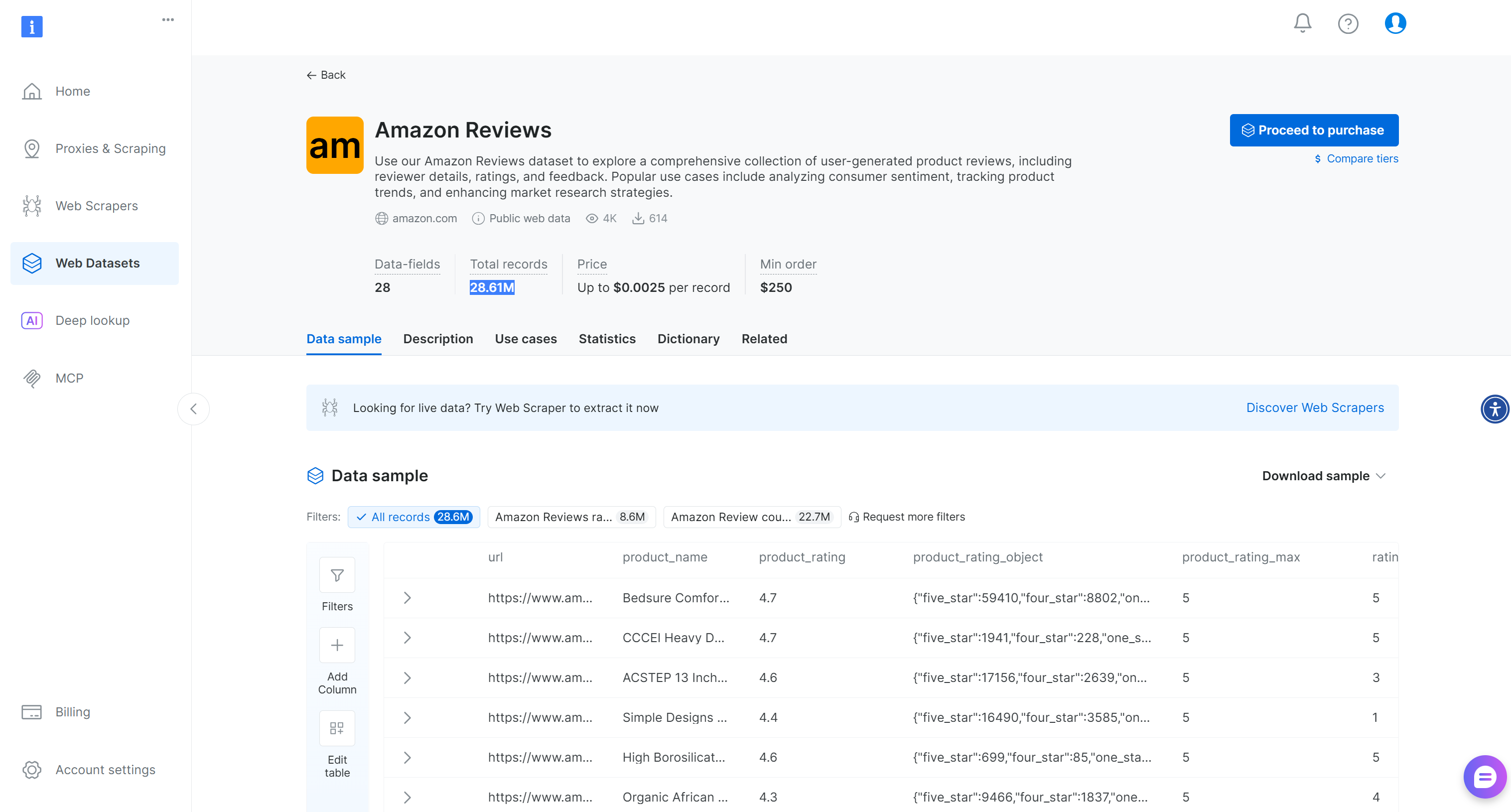
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie eines. Andernfalls melden Sie sich an und navigieren Sie zur Seite„Web Scrapers Library”Ihres Kontos:
Suchen Sie nach „amazon” und wählen Sie den Scraper „Amazon Reviews – collect by URL” aus: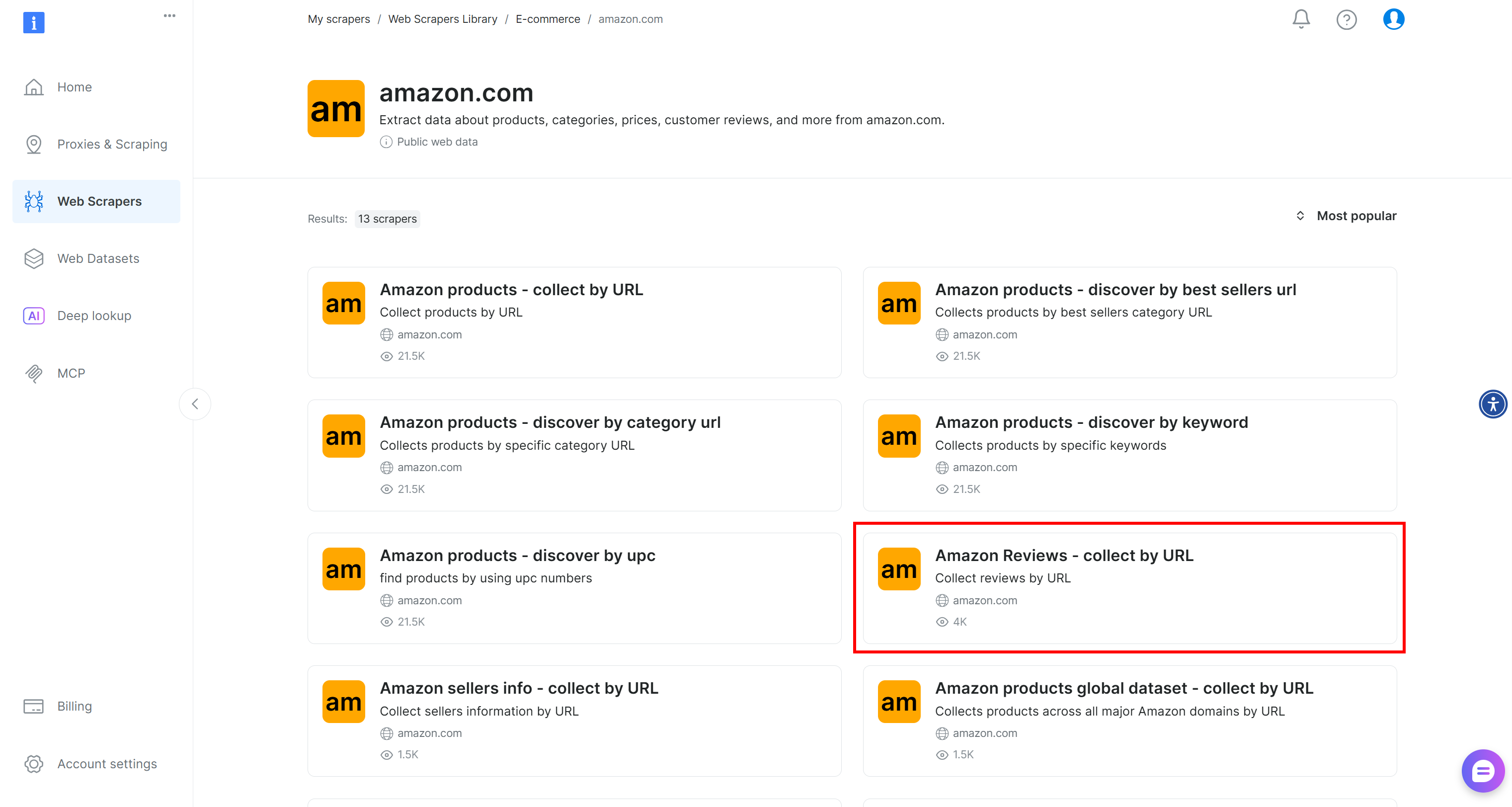
Auf dieser Seite erfahren Sie, wie Sie einen integrationsfähigen Code generieren oder den Scraper direkt über die No-Code-Webanwendung ausprobieren können.
Wählen Sie die Option „Scraper API“ und Sie gelangen zur folgenden Seite:
Überprüfen Sie hier die unterstützten Eingabeparameter und das Ausgabeformat. Dieser Datensatz gibt insbesondere eine Liste von Amazon-Rezensionen zurück und hat die ID gd_le8e811kzy4ggddlq.
Um diesen Scraper über die API aufzurufen, müssen Sie Ihre Anfragen mit Ihrem Bright Data API-Schlüssel authentifizieren. Wenn Sie noch keinen haben, folgen Sie der offiziellen Anleitung, um ihn zu generieren. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn in Kürze benötigen werden.
Großartig! Sie sind nun bereit, den Amazon-Bewertungs-Scraper von Bright Data zu verwenden und Produktbewertungsdaten für die Analyse abzurufen.
Schritt 4: Abrufen der Amazon-Produktbewertungsdaten
Erstellen Sie eine neue Notizbuchzelle und fügen Sie den folgenden Code ein:
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie dies durch Ihren Bright Data API-Schlüssel.
def trigger_snapshot(amazon_product_url):
# Lösen Sie die Bright Data Web Scraper API für eine bestimmte Amazon-Produkt-URL aus.
url = "https://api.brightdata.com/datensätze/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # ID des Scrapers „Amazon Reviews – collect by URL”
"include_errors": "true",
}
# Eingabedaten für den API-Aufruf formatieren
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # Anfrage authentifizieren
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Anfrage erfolgreich! Snapshot-ID: {snapshot_id}")
return snapshot_id
else:
print(f"Anfrage fehlgeschlagen! Statuscode: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# Die Bright Data Scraper API abfragen, bis der Snapshot bereit ist, dann speichern
snapshot_url = f"https://api.brightdata.com/datensätze/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
print(f"Abfrage des Snapshots für ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot ist fertig. Herunterladen...")
snapshot_data = response.text
# Snapshot in eine Datei schreiben
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"Snapshot in {output_file} gespeichert")
return
elif response.status_code == 202:
print(f"Snapshot noch nicht bereit. Wiederholung in {polling_timeout} Sekunden...")
time.sleep(polling_timeout)
else:
print(f"Anfrage fehlgeschlagen! Statuscode: {response.status_code}")
print(response.text)
break
# Amazon-Produkt-URL, von der Bewertungen abgerufen werden sollen
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# Snapshot auslösen und Bewertungen herunterladen
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")Ersetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_API_KEY> durch Ihren zuvor generierten Bright Data API-Schlüssel.
Der obige Code:
- Löst den Scraper für Bewertungen mithilfe
der Datensätze/v3/triggeraus, wodurch ein Scraping-Job in der Cloud von Bright Data mit dem Amazon-Bewertungs-Scraper gestartet wird. - Fragt den generierten Datensatz-Snapshot mit
datasets/v3/snapshot/{snapshot_id}ab und wartet, bis Bright Data das Scraping der Bewertungen abgeschlossen hat. - Exportiert die endgültigen Daten als CSV (da
format="csv"angegeben ist) und speichert sie lokal inproduct-reviews.csv.
Genau so funktioniert der Workflow der Web Scraper API. Weitere Informationen finden Sie in der offiziellen Bright Data-Dokumentation.
Wenn Sie den Code-Block ausführen, sollte etwa Folgendes angezeigt werden:
Anschließend erscheint eine Datei namens product-reviews.csv in Ihrem Projektordner. Öffnen Sie diese Datei, um die gescraped Bewertungen in strukturierter Form anzuzeigen: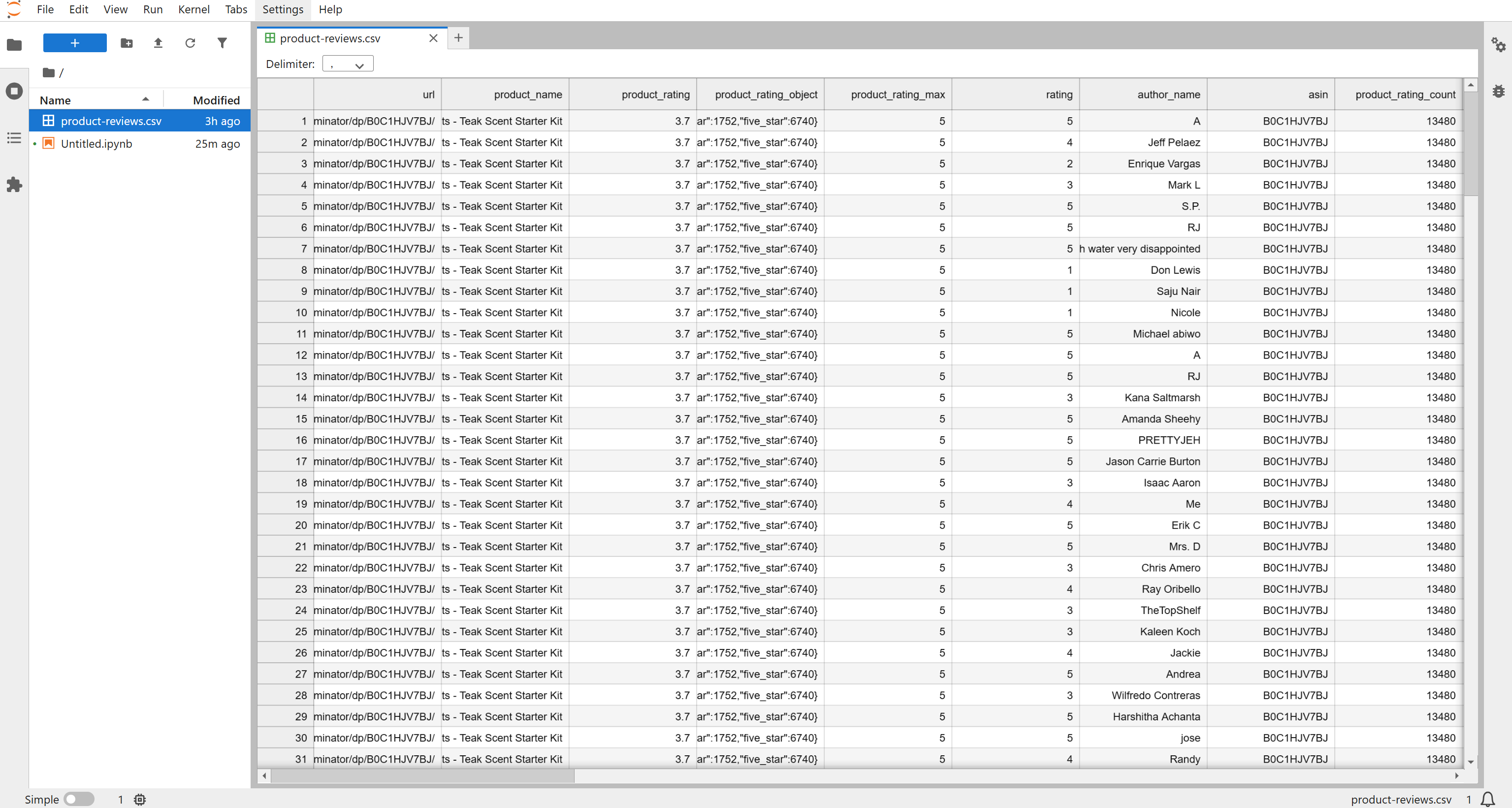
Standardmäßig gibt der Scraper die letzten ~200 Bewertungen zurück, aber Sie können die API-Eingaben anpassen, um bei Bedarf mehr zu erhalten. Für dieses Tutorial sind die 196 abgerufenen Bewertungen mehr als ausreichend, um die Sentiment-Analyse-Pipeline zu vervollständigen.
Cool! Sie haben nun aktuelle Amazon-Produktbewertungsdaten, die für die TensorFlow-Analyse bereitstehen.
Schritt 5: Erkunden Sie die gescrapten Daten
Laden Sie zunächst die gescraped Daten aus der Datei „product-reviews.csv “:
# Laden Sie Produktbewertungen aus der mit Bright Data generierten CSV-Datei.
df = pd.read_csv("product-reviews.csv")
# Konvertieren Sie die Veröffentlichungsdaten der Bewertungen in Datums- und Zeitangaben.
df["date"] = pd.to_datetime(df["review_posted_date"])
# Bewertungen mit fehlendem Text löschen
df = df.dropna(subset=["review_text"])
# Bewertungen nach Veröffentlichungsdatum sortieren (aufsteigend)
df = df.sort_values(by="date", ascending=True)
print(f"{len(df)} Bewertungen geladen.")Führen Sie diese Zelle aus, um die Gesamtzahl der geladenen Bewertungen anzuzeigen:
196 Bewertungen geladen.Analysieren Sie als Nächstes die Verteilung der Bewertungen:
print(df["rating"].value_counts())Sie sollten ein Ergebnis erhalten, das in etwa so aussieht:
Bewertung
1 74
2 31
3 16
4 12
5 63Wie oben gezeigt, sind die Bewertungen ziemlich gleichmäßig über den Bereich von 1 bis 5 Sternen verteilt. Um diese Verteilung besser zu visualisieren, verwenden Sie ein Balkendiagramm mit Matplotlib:
# Berechnen Sie die Anzahl der Bewertungen pro Bewertung (1–5 Sterne)
rating_counts = df["rating"].value_counts().sort_index()
# Zeichnen Sie die Bewertungsverteilung als Balkendiagramm
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("Bewertungsverteilung (1–5 Sterne)")
plt.xlabel("Sterne")
plt.ylabel("Anzahl")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()Sie erhalten ein Diagramm, das dem untenstehenden ähnelt: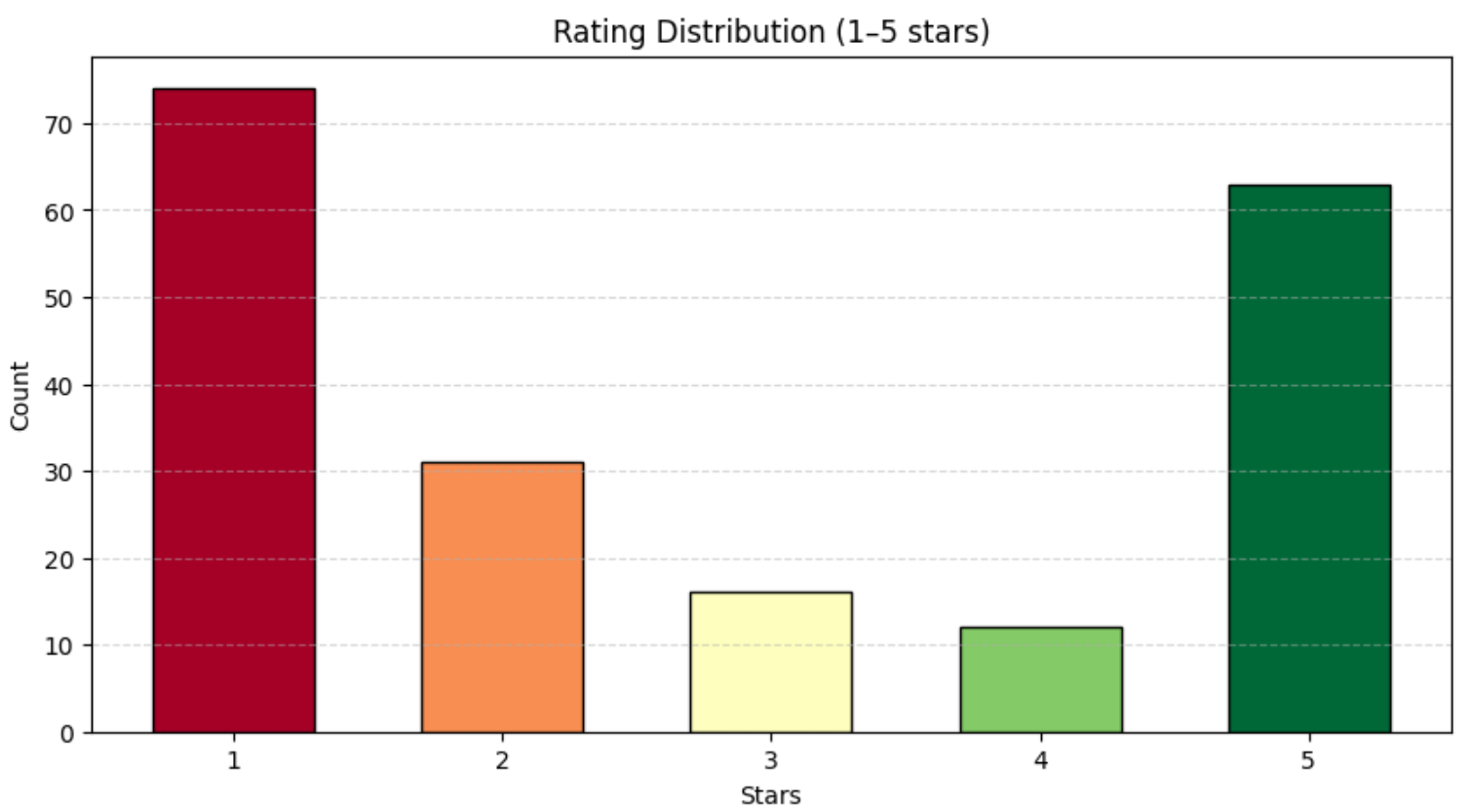
Perfekt! Sie haben nun ein klares, umfassendes Verständnis des Amazon-Bewertungsdatensatzes, den Sie gerade abgerufen haben. Diese Grundlage ist unerlässlich, bevor Sie mit dem Modelltraining und der Sentimentanalyse fortfahren können.
Schritt 6: Weisen Sie den Bewertungen einen Sentiment-Analyse-Wert zu
Bevor Sie maschinelles Lernen anwenden, ist es hilfreich, die Sentimentklassifizierung zu vereinfachen, indem Sie die 3-Sterne-Bewertungen ignorieren. Der Grund dafür ist, dass diese Bewertungen in der Regel neutral sind und kein klar positives oder negatives Sentiment zum Ausdruck bringen.
Würden sie beibehalten, müsste das Modell ein dreistufiges Problem (positiv/neutral/negativ) lernen, was mehr Daten und eine komplexere Modellierung erfordert. Stattdessen wandeln wir die Aufgabe in eine binäre Sentimentklassifizierung um, indem wir Folgendes berücksichtigen:
- 4–5-Sterne-Bewertungen als „positiv“ (
1); - 1–2-Sterne-Bewertungen als „negativ“ (
0).
Vor diesem Hintergrund implementieren wir die Logik der Stimmungsanalyse in TensorFlow wie folgt:
# Neutrale Bewertungen (Bewertung=3) für eine klare binäre Sentimentanalyse verwerfen
df = df[df["rating"] != 3]
# Bewertungen dem Sentiment zuordnen: 1=positiv (>=4), 0=negativ (<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# Universal Sentence Encoder-Einbettungen laden
print("Universal Sentence Encoder-Einbettungen werden geladen...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # fixed float32
y = df["sentiment_label"].values
# Datensätze in Trainings- und Validierungssätze aufteilen
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# Klassengewichte berechnen, um Klassenungleichgewichte zu behandeln
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# Zunächst einen einfachen dichten Klassifikator mit Eingabeschicht erstellen
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# Erzwinge den Aufbau des Modells, um ein Zurückverfolgen zu vermeiden.
_ = model(X_emb[:1])
# Trainieren Sie das Modell
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# Vorhersage für Validierungssatz und Auswertung
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("nSentiment Model Classification Report:")
print(classification_report(y_val, y_pred))
# Vorhersage für den vollständigen Datensatz und Speichern der Sentiment-Werte
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()Dieser Codeblock stützt sich auf den Universal Sentence Encoder, um jede Bewertung in einen semantischen Vektor umzuwandeln. Falls Sie mit diesem Modell nicht vertraut sind: Der Universal Sentence Encoder ist ein Modell von Google, das Text in 512-dimensionale Einbettungsvektoren für Aufgaben der natürlichen Sprachverarbeitung wie Klassifizierung, semantische Ähnlichkeit und andere umwandelt.
Diese Einbettungen erfassen Bedeutungen wie Tonfall, Stimmung und Absicht, die in jeder Bewertung zum Ausdruck kommen. Anschließend verwendet das Keras Sequential-Modell vollständig verbundene (Dense) Schichten, um Muster in den Einbettungen zu lernen, die positive von negativen Stimmungen unterscheiden. Das Ergebnis ist ein Wahrscheinlichkeitswert, wobei
- Werte nahe
1,0eine positive Stimmung anzeigen; - Werte nahe
0,0eine negative Stimmung anzeigen.
Das Modell weist jeder Bewertung einen dieser Werte zu. Der Klassifizierungsbericht aus dem Validierungssatz lautet:
Sentiment-Modell-Klassifizierungsbericht:
Genauigkeit Rückruf F1-Score Unterstützung
0 0,91 0,95 0,93 21
1 0,93 0,87 0,90 15
Genauigkeit 0,92 36
Makro-Durchschnitt 0,92 0,91 0,91 36
Gewichteter Durchschnitt 0,92 0,92 0,92 36Dies zeigt, dass:
- Das Modell erreicht eine Genauigkeit von 92 % bei unbekannten Validierungsdaten.
- Präzision und Recall sind sowohl für positive als auch für negative Klassen durchweg stark.
- Die Trainings- und Validierungsgenauigkeit liegen nahe beieinander, was darauf hindeutet, dass das Modell nicht signifikant überangepasst ist.
Um den Trainingsprozess des maschinellen Lernens besser zu veranschaulichen, können Sie ein Diagramm wie das folgende hinzufügen:
plt.plot(history.history["accuracy"], label="Train Accuracy")
plt.plot(history.history["val_accuracy"], label="Validation Accuracy")
plt.title("Sentiment Model Training Performance")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()Dadurch wird der gesamte Trainingsverlauf angezeigt: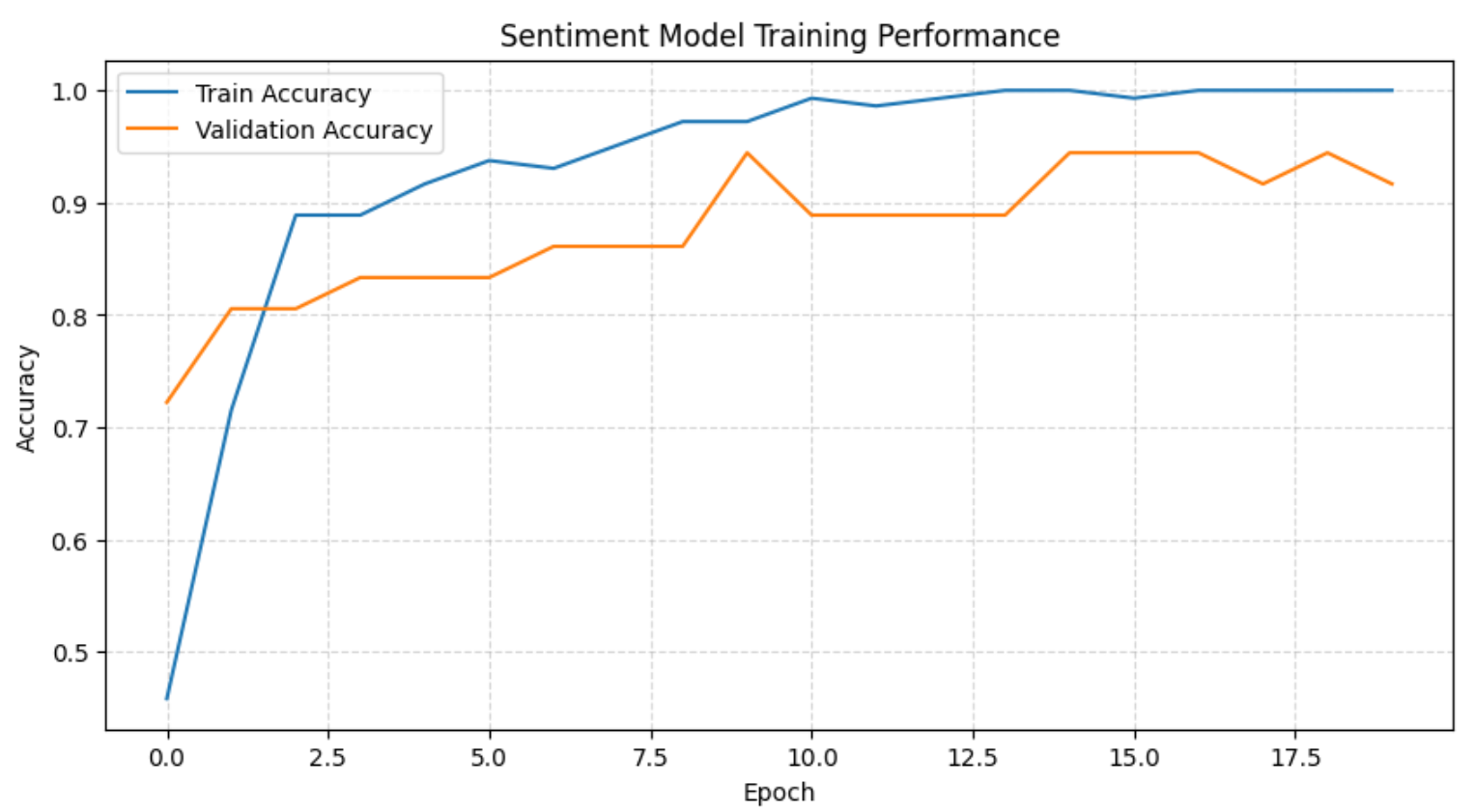
Das obige Diagramm zeigt zusammen mit den Trainingsprotokollen, dass das Modell innerhalb der ersten paar Epochen schnell die Sentimentgrenze lernt, bevor es sich mit einer starken Validierungsgenauigkeit stabilisiert. Im Verlauf des Trainings erreicht die Genauigkeit des Trainingssatzes 100 %, während die Validierungsgenauigkeit konstant hoch bleibt, was angesichts der Größe der Datensätze nur auf eine leichte und akzeptable Überanpassung hindeutet.
Visualisieren Sie abschließend die vorhergesagten Sentiment-Wahrscheinlichkeiten:
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("Verteilung der vorhergesagten Sentiment-Werte")
plt.xlabel("Sentiment-Wert")
plt.ylabel("Anzahl")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()Das Ergebnis lautet: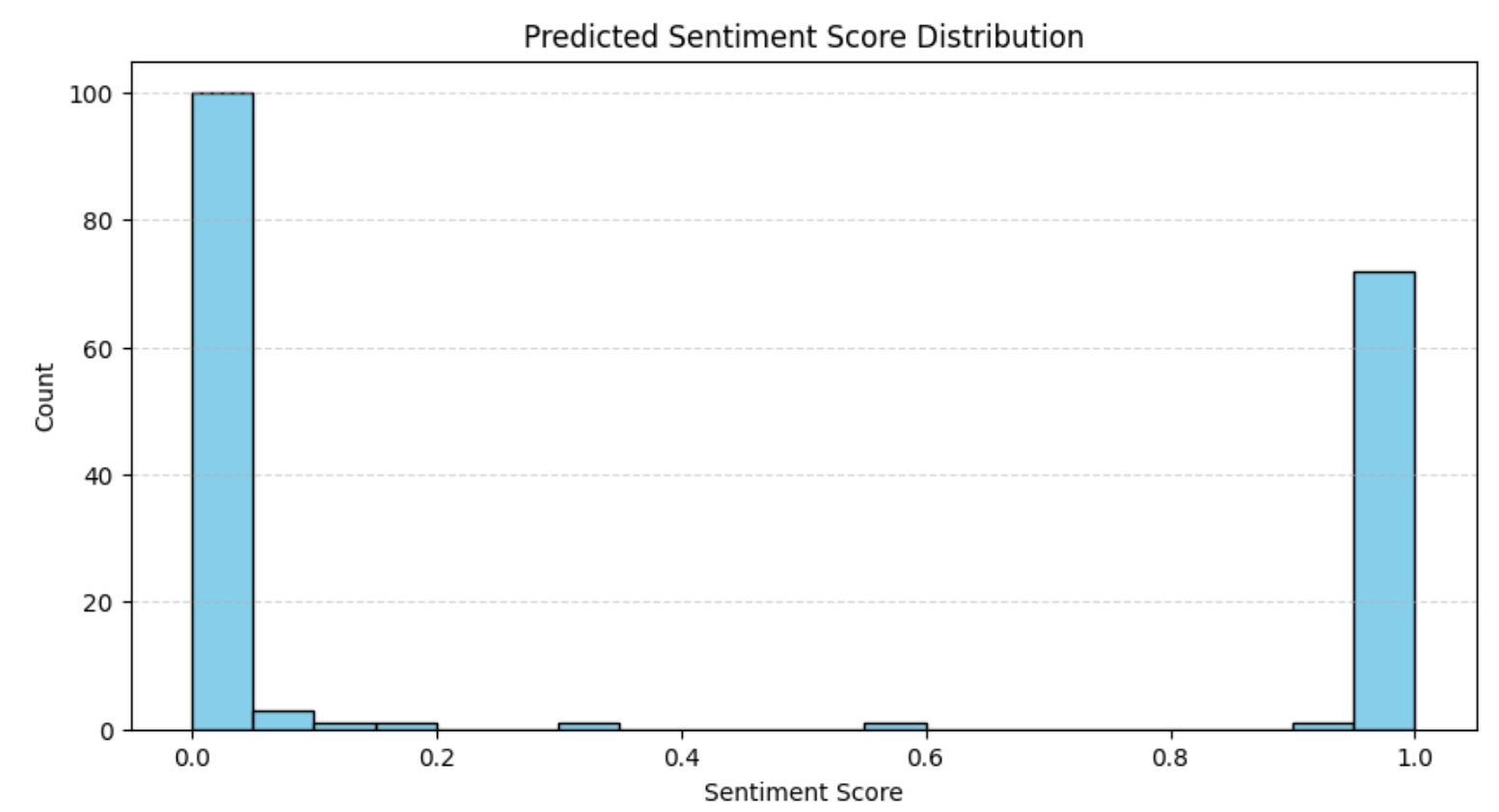
Die Verteilung stimmt mit unseren früheren Beobachtungen in der Bewertungsanalyse überein, d. h. die meisten Bewertungen sind entweder sehr positiv oder sehr negativ. Dieses Muster ist auf E-Commerce-Plattformen häufig anzutreffen, wo polarisierte Meinungen tendenziell dominieren.
Fantastisch! Die Sentimentanalyse ist abgeschlossen.
Schritt 7: Untersuchen Sie die Sentimentanalyse im Zeitverlauf
Nachdem nun jede Bewertung einen Sentiment-Score hat, visualisieren Sie, wie sich das Kunden-Sentiment im letzten Jahr entwickelt hat. Wenden Sie einen 7-Tage-Rolling-Trend auf das tägliche durchschnittliche Sentiment an, um tägliche Schwankungen auszugleichen:
# Tägliche durchschnittliche Stimmung vorbereiten
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# Nach letztem Jahr filtern
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# 7-Tage-Rolling-Trend berechnen
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# Eine X-Achsenbeschriftung pro Monat festlegen
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # Monatsbeginn
)
# Tägliche Stimmung und gleitender Trend darstellen
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="Tägliche Stimmung")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="7-Tage-gleitender Trend")
# X-Achsenbeschriftungen festlegen
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("Tägliche durchschnittliche Stimmung (letztes Jahr) + Trend")
plt.xlabel("Datum")
plt.ylabel("Stimmungswert")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()Dies erzeugt das folgende Diagramm zur Stimmungsentwicklung im Zeitverlauf: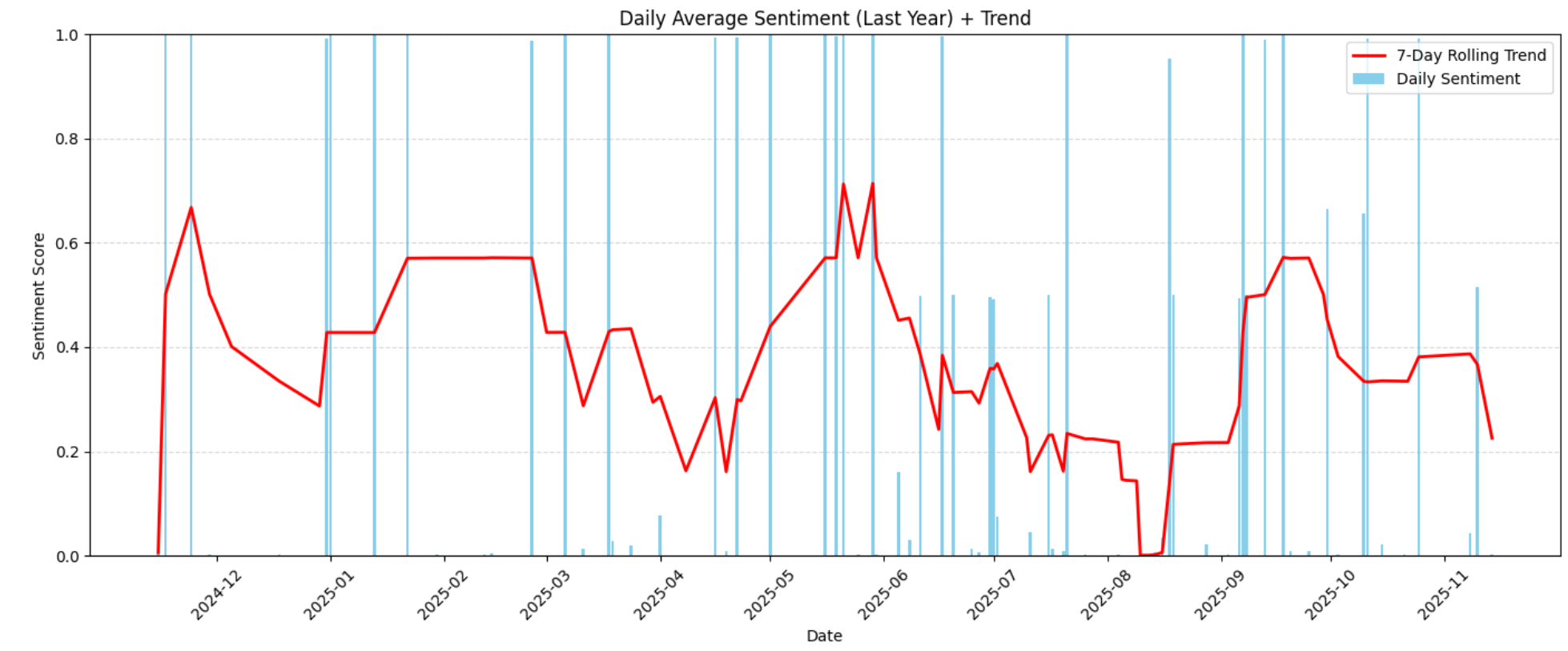
Die Visualisierung hebt die im Laufe des Jahres zunehmenden oder abnehmenden Stimmungsmuster hervor. Anhand dieser Trends können Sie erkennen, wann sich die Kundenzufriedenheit verbessert oder verschlechtert hat und ob externe Faktoren (Produktänderungen, Verzögerungen, Mängel, Preisaktualisierungen) zu Veränderungen in der Stimmung geführt haben könnten.
Beispielsweise können Sie in der Grafik deutlich sehen, dass die Stimmung zwischen Juni 2026 und Mitte August 2026 stark gesunken ist, von mäßig positiv (etwa 0,6) auf extrem negativ (nahe 0,0):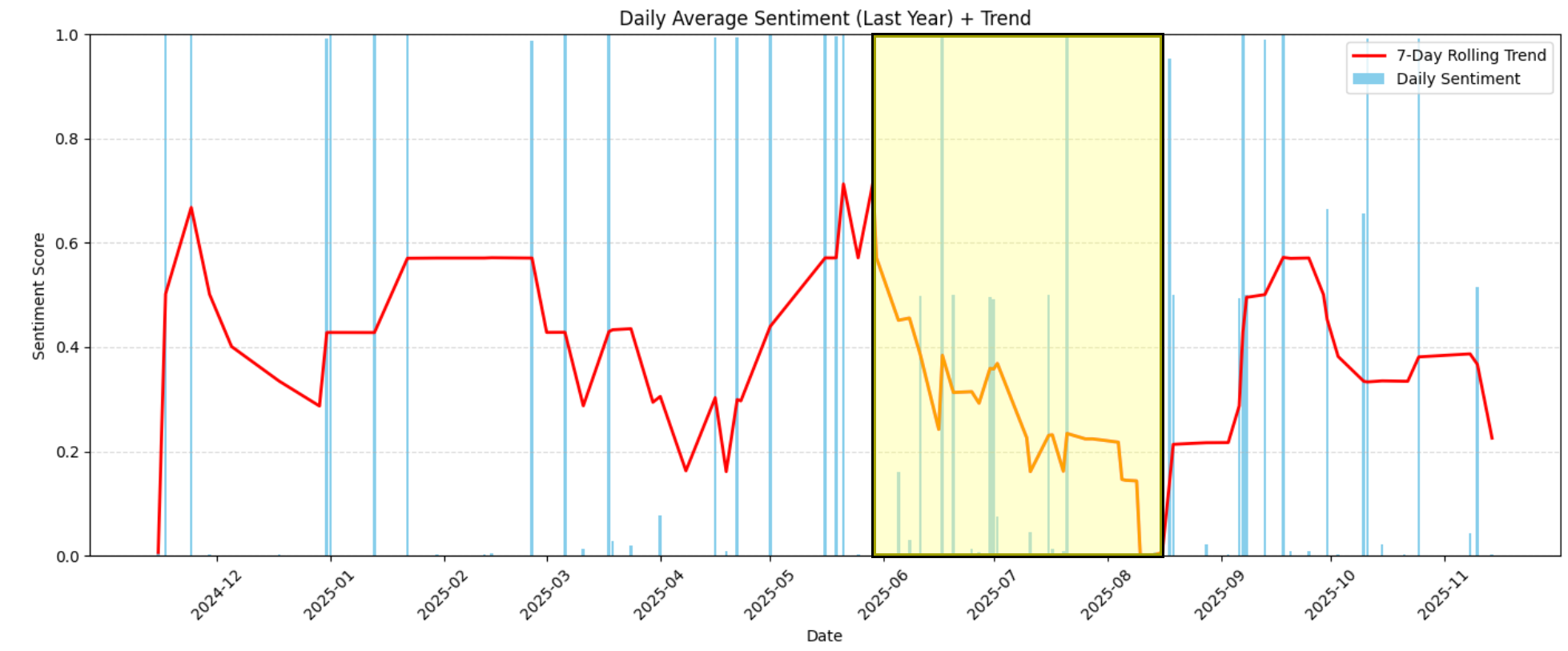
Um zu verstehen, was in diesem Zeitraum passiert ist, beschränken Sie den Datensatz auf diese Daten:
# Filterung der Bewertungen zwischen Juni 2026 und Mitte August 2026
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"Anzahl der Bewertungen im Zeitraum: {len(df_filtered)}")Wie die Ausgabe zeigt, gibt es in diesem Zeitraum 34 Bewertungen:
Anzahl der Bewertungen im Zeitraum: 34Als Nächstes fassen Sie zusammen, wie sich die Stimmung über die Bewertungen verteilt:
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("nRating summary:")
print(rating_summary)Das Ergebnis wäre:
Bewertungszusammenfassung:
Bewertung Anzahl der Bewertungen Durchschnittliche Stimmung
0 1 16 0,004767
1 2 11 0,048928
2 4 2 0,998977
3 5 5 0,993221Dies sagt uns, dass 27 von 34 Bewertungen 1 oder 2 Sterne hatten und ihre Stimmungswerte extrem nahe bei 0,0 liegen.
Zeichnen Sie die Beziehung zwischen Bewertungen und Sentiment auf:
# Stimmungen vs. Bewertungen in einem Diagramm darstellen
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="Anzahl der Bewertungen")
ax1.set_xlabel("Bewertung")
ax1.set_ylabel("Anzahl der Bewertungen", Farbe="skyblue")
ax1.tick_params(Achse="y", Beschriftungsfarbe="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="Durchschnittliche Stimmung")
ax2.set_ylabel("Durchschnittliche Stimmungsbewertung", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("Stimmungsanalyse vs. Bewertung (01.06.2026 bis 15.08.2026)")
fig.tight_layout()
plt.show()Das Ergebnis ist folgende Grafik: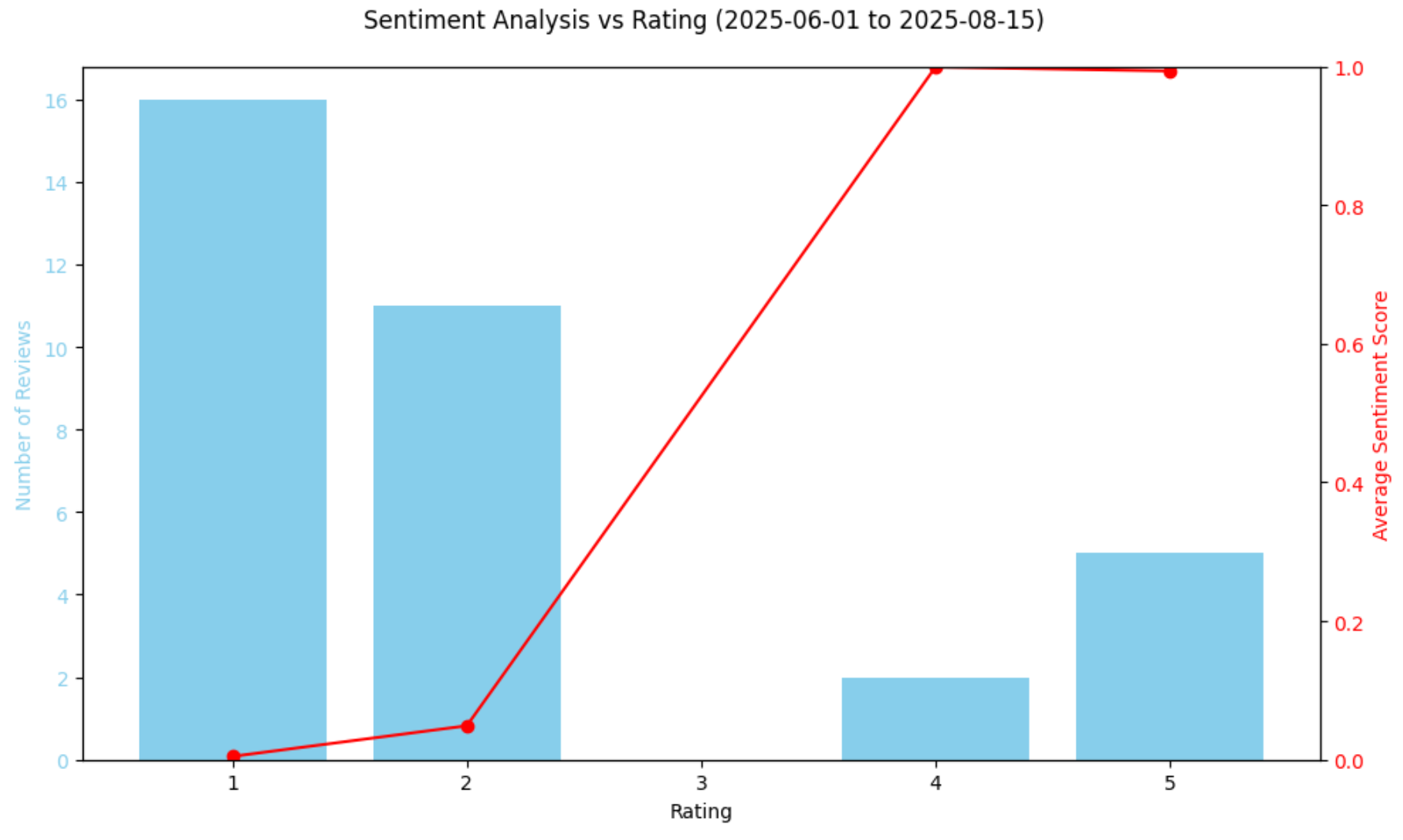
Das obige Diagramm bestätigt den starken Rückgang der Stimmung, wobei die meisten Bewertungen in diesem Zeitraum äußerst negativ ausfielen. Interessanterweise bewertet das Modell 4-Sterne-Bewertungen anhand seiner Stimmungsanalyse-Werte etwas positiver als 5-Sterne-Bewertungen. Dies ist kein Fehler, da es widerspiegelt, dass eine Sternebewertung allein nicht immer den emotionalen Ton widerspiegelt. Einige 5-Sterne-Bewertungen können dennoch Bedenken enthalten, während einige 4-Sterne-Bewertungen eine äußerst positive Sprache verwenden.
Schließlich geben Sternebewertungen zwar einen schnellen Überblick über die Meinung der Kunden, aber sie erfassen nicht immer alle Nuancen des Bewertungstextes. Durch den Vergleich der vom Modell vorhergesagten Stimmungswerte mit den numerischen Bewertungen können Sie sehen, ob die Sprache in den Bewertungen mit den vergebenen Sternen übereinstimmt. Dies hilft dabei, Anomalien zu identifizieren, wie z. B. negative Formulierungen in ansonsten hoch bewerteten Bewertungen oder subtile Positivität in niedriger bewerteten Bewertungen.
Lassen Sie uns dieses interessante Muster in den sinkenden Bewertungsergebnissen weiter analysieren!
Schritt 8: Lesen Sie die relevanten Bewertungen
Der letzte Schritt, um wirklich zu verstehen, was während des Rückgangs der Bewertungen von Juni 2026 bis Mitte August 2026 passiert ist, besteht darin, diese direkt zu überprüfen. Das erreichen Sie mit:
# Wählen Sie relevante Spalten aus
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# Zeigen Sie die Tabelle über HTML im Notizbuch an
display(HTML(df_table.to_html(index=False)))Das Ergebnis ist die folgende HTML-Tabelle:

Wie Sie sehen können, bemängeln die meisten Bewertungen in diesem Zeitraum, dass der Duft schnell verfliegt oder nicht stark genug ist. Dies deutet auf mögliche Produktionsprobleme bei den in diesen Wochen ausgelieferten Produkten hin.
Diese Erkenntnis ist äußerst wertvoll, da sie es Ihnen ermöglicht, den Produktionsprozess zu untersuchen, wiederkehrende Probleme zu beheben und möglicherweise unzufriedene Kunden mit Lösungen wie Gutscheinen oder Rabatten anzusprechen.
Hinweis: Dieser Bewertungsanalyseprozess könnte auch mithilfe eines LLM weiter automatisiert werden, wodurch er zu einer vollständig autonomen, produktionsreifen Pipeline wird.
Et voilà! Dank der Scraping-Funktionen von Bright Data haben Sie Amazon-Produktdaten abgerufen. Anschließend haben Sie TensorFlow für die Sentimentanalyse eingesetzt, die Trends untersucht und die Gründe für den Rückgang der Bewertungen innerhalb eines bestimmten Zeitraums ermittelt.
Fazit
In diesem Artikel haben Sie gesehen, wie Sie mit Bright Data Bewertungsdaten von einem Amazon-Produkt abrufen und diese verarbeiten können, um mithilfe von Machine-Learning-Workflows, die mit TensorFlow in einem Python-Notebook erstellt wurden, Trends in der Sentimentanalyse zu identifizieren.
Das hier vorgestellte Projekt erfüllt die Anforderungen kleiner und mittlerer Unternehmen oder Konzerne, die nach Möglichkeiten suchen, Nutzerbewertungen zu überwachen und die Kundenzufriedenheit zu verbessern. Eine solche Analyse wäre ohne die von Bright Data für Unternehmen angebotenen Datendienste nicht möglich.
Zu diesen Lösungen gehören ein umfangreicher Marktplatz für Datensätze und Scraper-APIs, mit denen Sie alte oder frisch aktualisierte Daten aus über 100 Domänen sammeln können, darunter Amazon, LinkedIn, Yahoo Finance und viele andere. Diese Daten können Sie in TensorFlow oder ähnliche Technologien einspeisen, um sie mittels maschinellem Lernen zu analysieren.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Scraper-APIs auszuprobieren oder unsere Datensätze zu erkunden!




