

Im heutigen Leitfaden werden wir einen Scrapy Spider schreiben und ihn auf AWS Lambda bereitstellen. Was den Code angeht, ist das hier ziemlich einfach. Bei der Arbeit mit Cloud-Diensten wie Lambda gibt es viele bewegliche Teile. Wir zeigen Ihnen, wie Sie sich in diesen beweglichen Teilen zurechtfinden und wie Sie damit umgehen, wenn etwas nicht funktioniert.
Voraussetzungen
Um diese Aufgabe zu erfüllen, benötigen Sie Folgendes:
- hier
- Grundkenntnisse im Scraping mit Scrapy
Was ist Serverless?
Die serverlose Architektur wird als die Zukunft des Computing gepriesen. Die tatsächliche Laufzeit einer serverlosen Anwendung mag zwar pro Stunde teurer sein, aber wenn Sie nicht bereits für den Betrieb eines Servers bezahlen, ist Lambda eine sinnvolle Lösung.
Nehmen wir an, Ihr Scraper benötigt eine Minute für die Ausführung und Sie führen ihn einmal täglich aus. Bei einem herkömmlichen Server würden Sie für einen Monat mit 24 Stunden Betriebszeit bezahlen, obwohl Ihre tatsächliche Nutzung nur 30 Minuten beträgt. Bei Diensten wie Lambda bezahlen Sie nur für das, was Sie tatsächlich nutzen.
Vorteile
- Abrechnung: Sie zahlen nur für das, was Sie tatsächlich nutzen.
- Skalierbarkeit: Lambda skaliert automatisch, Sie müssen sich darum keine Gedanken machen.
- Serververwaltung: Sie müssen keine Zeit für die Verwaltung eines Servers aufwenden. All dies erfolgt automatisch.
Nachteile
- Latenz: Wenn Ihre Funktion im Leerlauf war, dauert es länger, bis sie gestartet ist und ausgeführt wird.
- Ausführungszeit: Lambda-Funktionen werden mit einer Standard-Zeitüberschreitung von 3 Sekunden und einer maximalen Zeit von 15 Minuten ausgeführt. Herkömmliche Server sind wesentlich flexibler.
- Portabilität: Sie sind nicht nur von der Kompatibilität des Betriebssystems abhängig, sondern auch von Ihrem Anbieter. Sie können Ihre Lambda-Funktion nicht einfach kopieren und in Azure oder Google Cloud ausführen.
Bright Data hat eine Lösung, die diese Einschränkungen nicht hat. Sehen wir uns diese als Nächstes an.
Serverlose Funktionen: Die beste Alternative
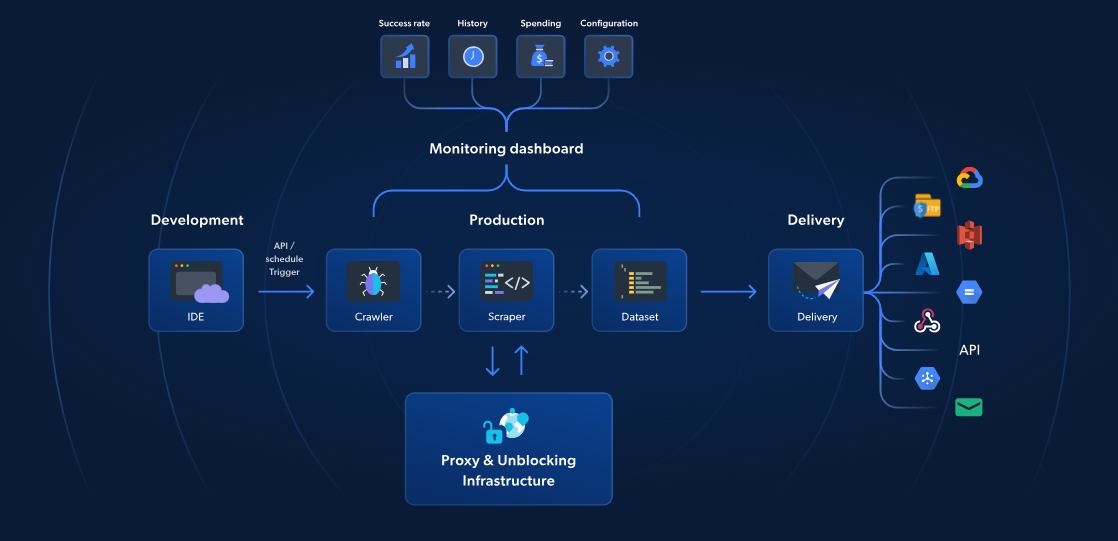
Während AWS Lambda und Scrapy serverloses Web-Scraping anbieten, bieten die serverlosen Funktionen von Bright Data eine speziell entwickelte Lösung für schnelleres und zuverlässigeres Scraping. Mit über 70 vorgefertigten JavaScript-Vorlagen, einer integrierten cloudbasierten IDE und einer KI-gestützten Lösung zum Entsperren können Sie CAPTCHAs umgehen, mühelos skalieren und sich auf die Datenextraktion konzentrieren, ohne sich um die Verwaltung der Infrastruktur kümmern zu müssen.
Im Gegensatz zum Ansatz von AWS und Scrapy umfasst die Lösung von Bright Data Proxy-Verwaltung, automatische Skalierung und direkte Integration mit Speicherplattformen wie S3 oder Google Cloud. Mit Preisen ab nur 2,7 $ pro 1.000 Seitenaufrufe machen Serverless Functions fortgeschrittenes Web-Scraping einfacher, schneller und kostengünstiger.
Fahren wir nun mit unserem Scrapy- und AWS-Leitfaden fort.
Erste Schritte
Einrichten der Dienste
Nachdem Sie Ihr AWS-Konto eingerichtet haben, benötigen Sie einen S3-Bucket. Gehen Sie zur Seite „Alle Dienste“ und scrollen Sie nach unten.
Schließlich sehen Sie einen Abschnitt namens „Storage“(Speicher). Die erste Option in diesem Abschnitt heißt „S3“. Klicken Sie darauf.
Klicken Sie anschließend auf die Schaltfläche „Bucket erstellen ”.
Jetzt müssen Sie Ihrem Bucket einen Namen geben und Ihre Einstellungen auswählen. Wir verwenden einfach die Standardeinstellungen.
Wenn Sie fertig sind, klicken Sie auf die Schaltfläche „Bucket erstellen“ unten rechts auf der Seite.

Nachdem Sie ihn erstellt haben, wird Ihr Bucket auf der Registerkarte „Buckets“ unter „Amazon S3“ angezeigt.
Einrichten Ihres Projekts
Erstellen Sie einen neuen Projektordner.
mkdir scrapy_aws
Wechseln Sie in den neuen Ordner und erstellen Sie eine virtuelle Umgebung.
cd scrapy_aws
python3 -m venv venv
Aktivieren Sie die Umgebung.
source venv/bin/activate
Installieren Sie Scrapy.
pip install scrapy
Was soll gescrapt werden?
Für dynamische Websites, Anti-Bot-Maßnahmen oder groß angelegtes Scraping verwenden Sie den Scraping-Browser von Bright Data. Er automatisiert Aufgaben, umgeht CAPTCHAs und lässt sich nahtlos skalieren.
Wir verwenden books.toscrape als Zielwebsite. Es handelt sich um eine Bildungswebsite, die sich ausschließlich mit Web-Scraping befasst. Wenn Sie sich das Bild unten ansehen, ist jedes Buch ein Artikel mit dem Klassennamen product_pod. Wir möchten alle diese Elemente aus der Seite extrahieren.
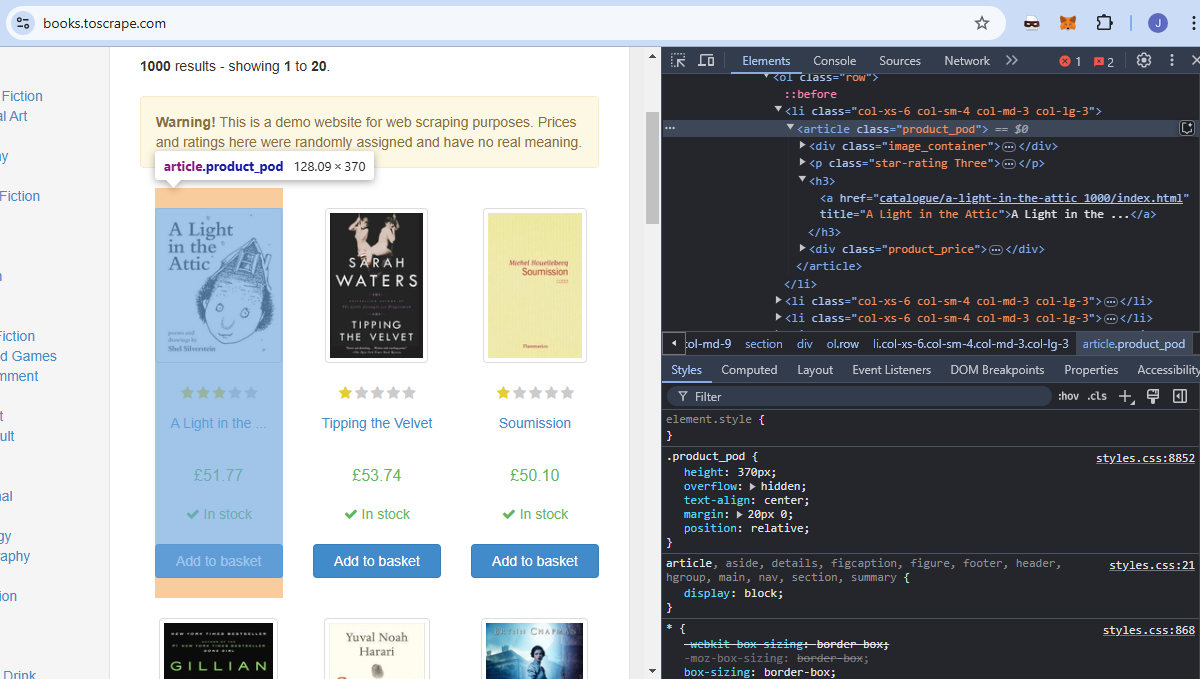
Der Titel jedes Buches ist in einem a- Element eingebettet, das in einem h3 -Element verschachtelt ist.

Jeder Preis ist in einem p-Element eingebettet, das in einem div-Element verschachtelt ist. Es hat den Klassennamen price_color.
Schreiben unseres Codes
Jetzt schreiben wir unseren Scraper und testen ihn lokal. Öffnen Sie eine neue Python-Datei und fügen Sie den folgenden Code ein. Wir haben unsere Datei aws_spider.py genannt.
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))
Sie können den Spider mit dem folgenden Befehl testen. Es sollte eine JSON-Datei mit Büchern und Preisen ausgegeben werden.
python -m scrapy runspider aws_spider.py -o books.json
Jetzt brauchen wir einen Handler. Die Aufgabe des Handlers ist einfach: Er führt den Spider aus. Hier erstellen wir zwei Handler, die im Grunde genommen identisch sind. Der Hauptunterschied besteht darin, dass wir einen lokal und einen auf Lambda ausführen.
Hier ist unser lokaler Handler, den wir lambda_function_local.py genannt haben.
import subprocess
def handler(event, context):
# Ausgabedateipfad für lokale Tests
output_file = "books.json"
# Scrapy-Spider mit dem Flag -o ausführen, um die Ausgabe in books.json zu speichern
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# Erfolgsmeldung zurückgeben
return {
'statusCode': '200',
'body': f"Scraping abgeschlossen! Ausgabe in {output_file} gespeichert",
}
# Fügen Sie diesen Block für lokale Tests hinzu.
if __name__ == "__main__":
# Simulieren Sie ein AWS Lambda-Aufrufereignis und einen Kontext.
fake_event = {}
fake_context = {}
# Rufen Sie den Handler auf und geben Sie das Ergebnis aus.
result = handler(fake_event, fake_context)
print(result)
Löschen Sie books.json. Sie können den lokalen Handler mit dem folgenden Befehl testen. Wenn alles ordnungsgemäß funktioniert, wird in Ihrem Projektordner eine neue Datei books.json angezeigt. Denken Sie daran, bucket_name durch Ihren eigenen Bucket zu ersetzen.
python lambda_function_local.py
Hier ist nun der Handler, den wir für Lambda verwenden werden. Er ist ziemlich ähnlich, hat aber einige kleine Änderungen, um unsere Daten in unserem S3-Bucket zu speichern.
import subprocess
import boto3
def handler(event, context):
# Definieren Sie die lokalen und S3-Ausgabedateipfade.
local_output_file = "/tmp/books.json" # Muss für Lambda in /tmp sein.
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # Pfad im S3-Bucket
# Scrapy-Spider ausführen und die Ausgabe lokal speichern
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# Datei auf S3 hochladen
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
return {
'statusCode': 200,
'body': f"Scraping abgeschlossen! Ausgabe hochgeladen zu s3://{bucket_name}/{s3_key}"
}
- Zunächst speichern wir unsere Daten in einer temporären Datei:
local_output_file = "/tmp/books.json". Dadurch wird verhindert, dass sie verloren gehen. - Wir laden sie mit
s3.upload_file(local_output_file, bucket_name, s3_key)in unseren Bucket hoch.
Bereitstellung in AWS Lambda
Jetzt müssen wir auf AWS Lambda bereitstellen.
Erstellen Sie einen Paketord ner.
mkdir package
Kopieren Sie unsere Abhängigkeiten in den Paketordner.
cp -r venv/lib/python3.*/site-packages/* package/
Kopieren Sie die Dateien. Achten Sie darauf, dass Sie den für Lambda erstellten Handler kopieren und nicht den zuvor getesteten lokalen Handler.
cp lambda_function.py aws_spider.py package/
Komprimieren Sie den Paketordner in eine ZIP-Datei.
zip -r lambda_function.zip package/
Nachdem wir die ZIP-Datei erstellt haben, müssen wir zu AWS Lambda gehen und „Create function“ (Funktion erstellen) auswählen . Geben Sie bei Aufforderung Ihre grundlegenden Informationen wie Laufzeit (Python) und Architektur ein.
Stellen Sie sicher, dass Sie ihm die Berechtigung zum Zugriff auf Ihren S3-Bucket erteilen.
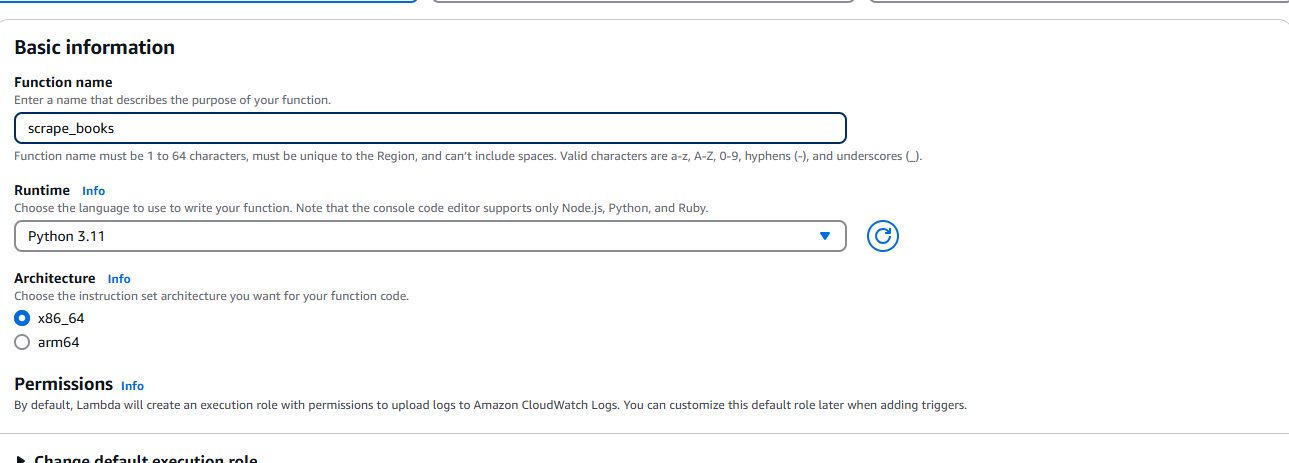
Nachdem Sie die Funktion erstellt haben, wählen Sie „Hochladen aus “ aus dem Dropdown-Menü. Dieses befindet sich in der oberen rechten Ecke der Registerkarte „Quelle“.

Wählen Sie „.zip-Datei“ und laden Sie die von Ihnen erstellte ZIP-Datei hoch.
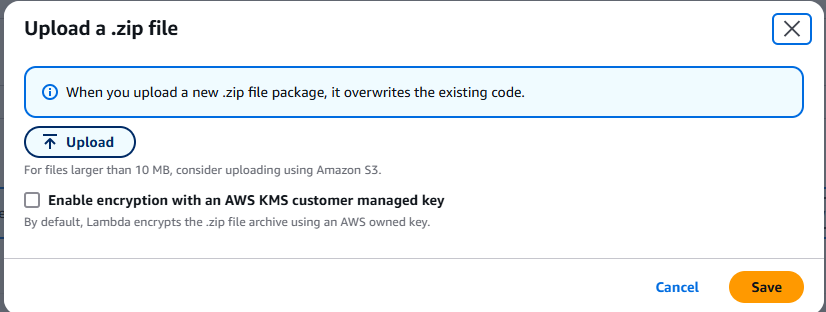
Klicken Sie auf die Schaltfläche „Test“ und warten Sie, bis Ihre Funktion ausgeführt wurde. Überprüfen Sie nach der Ausführung Ihren S3-Bucket. Dort sollte sich nun eine neue Datei namens „books.json“ befinden.
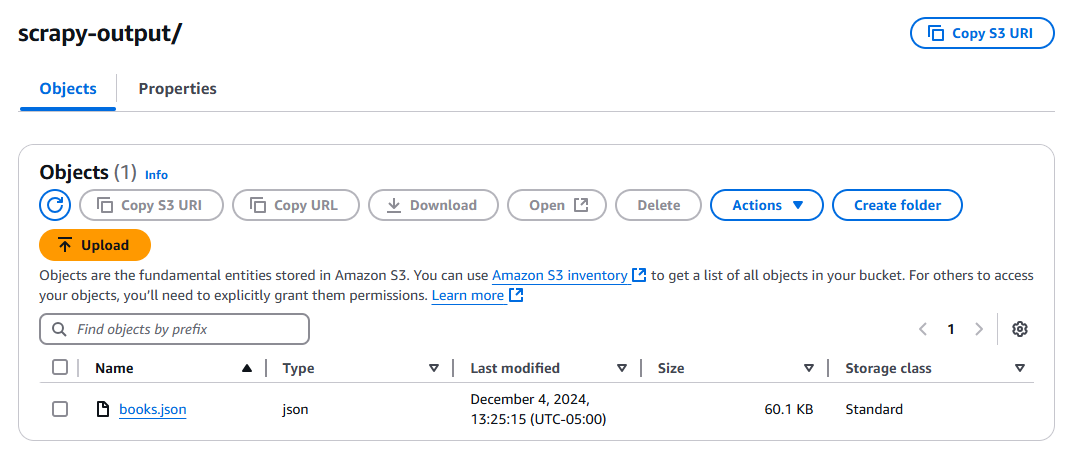
Tipps zur Fehlerbehebung
Scrapy kann nicht gefunden werden
Möglicherweise erhalten Sie eine Fehlermeldung, dass Scrapy nicht gefunden werden kann. In diesem Fall müssen Sie Folgendes zu Ihrem Befehlsarray in subprocess.run() hinzufügen.

Allgemeine Probleme mit Abhängigkeiten
Sie müssen sicherstellen, dass Ihre Python-Versionen identisch sind. Überprüfen Sie Ihre lokale Python-Installation.
python --version
Wenn dieser Befehl eine andere Version als Ihre Lambda-Funktion ausgibt, ändern Sie Ihre Lambda-Konfiguration entsprechend.
Handler-Probleme

Ihr Handler sollte mit der Funktion übereinstimmen, die Sie in lambda_function.py geschrieben haben. Wie Sie oben sehen können, haben wir lambda_function.handler. lambda_function steht für den Namen Ihrer Python-Datei. handler ist der Name der Funktion.
Kann nicht in S3 schreiben
Beim Speichern der Ausgabe können Probleme mit den Berechtigungen auftreten. In diesem Fall müssen Sie diese Berechtigungen zu Ihrer Lambda-Instanz hinzufügen.
Gehen Sie zur IAM-Konsole und suchen Sie nach Ihrer Lambda-Funktion. Klicken Sie darauf und dann auf das Dropdown-Menü „Berechtigungen hinzufügen “.
Klicken Sie auf „Richtlinien anhängen“.
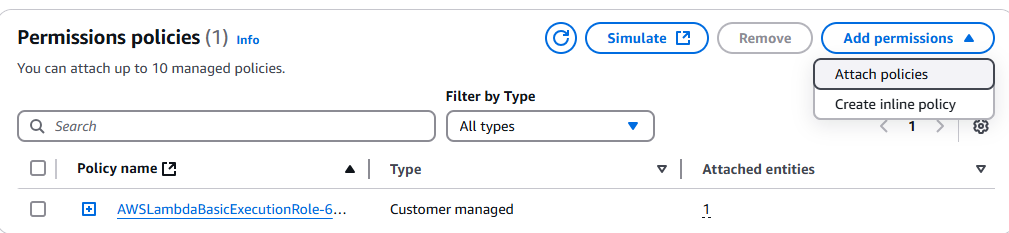
Wählen Sie „AmazonS3FullAccess“ aus.
Fazit
Sie haben es geschafft! Jetzt sollten Sie sich in der als AWS-Konsole bekannten UI-Hölle zurechtfinden können. Sie wissen, wie man einen Crawler mit Scrapy schreibt. Sie wissen, wie man die Umgebung mit Linux oder WSL paketiert, um die Binärkompatibilität mit Amazon Linux sicherzustellen.
Wenn Sie kein Fan von manuellem Web-Scraping sind, sehen Sie sich unsere Web-Scraper-APIs und vorgefertigte Datensätze an. Melden Sie sich jetzt an, um gratis zu testen!





