

Web-Scraping ist eine Technik, bei der Daten mithilfe spezieller Tools oder Programme automatisch aus Websites extrahiert und gesammelt werden. Sie ist besonders wertvoll für Unternehmen, die ihre datengestützten Entscheidungsprozesse verbessern möchten.
Aufgrund der komplexen HTML-Strukturen, dynamischen Inhalte und vielfältigen Datenformate, die auf den meisten Websites zu finden sind, hängt die Effektivität des Web-Scraping jedoch von den verwendeten Tools ab.
Scrapy und Selenium sind leistungsstarke Tools, die das Web-Scraping erleichtern sollen. Scrapy extrahiert Daten aus statischen Websites, während Selenium die Automatisierung von Webbrowsern durchführen und Daten aus dynamischen Websites extrahieren kann.
In diesem Artikel werden Sie die beiden Tools hinsichtlich ihrer Benutzerfreundlichkeit, Leistung und Skalierbarkeit, Eignung für verschiedene Arten von Webinhalten und Integrationsmöglichkeiten vergleichen.
Benutzerfreundlichkeit
Scrapy ist ein Python-basiertes Web-Scraping-Tool, das unter Linux, Windows, macOS und Berkeley Software Distribution (BSD) ausgeführt werden kann. Scrapy ist nicht nur einfach zu bedienen, sondern bietet auch eine hochentwickelte API für Web-Scraping-Aufgaben, die den Web-Scraping-Prozess weiter vereinfachen kann.
Um Scrapy einzurichten, müssen Sie es lediglich installieren und einige Spider mit Python-Code konfigurieren (dazu sind einige Kenntnisse über Web-Scraping-Konzepte erforderlich). Wenn Sie einen Scrapy-Befehl ausführen, um ein Projekt zu starten, wird ein Ordner für Ihr Projekt erstellt. In diesem Ordner finden Sie Standard-Python-Dateien wieitems.py,pipelines.pyund settings.py. Diese Dateien sind in einer vereinfachten Struktur organisiert, sodass Sie leicht mit dem Web-Scraping beginnen können.
Scrapy bietet eine ausführliche Dokumentation mit ausgewählten Artikeln und Videos, die Ihnen bei der Beantwortung Ihrer Fragen helfen. Scrapy verfügt außerdem über eine aktive Subreddit- und Discord-Community, in der Sie sich an verschiedenen Diskussionen oder Themen beteiligen können.
Im Vergleich dazu unterstützt Selenium mehrere Programmiersprachen, darunter Java, JavaScript, Python und C#, und ist mit vielen der gleichen Betriebssysteme wie Scrapy kompatibel, darunter Windows, macOS und Linux. Im Vergleich zu Scrapy ist Selenium nicht so einfach zu erlernen und erfordert mehr Zeit, Mühe und manchmal auch Ressourcen, bevor man es beherrscht.
Um Selenium einzurichten, müssen Sie die Selenium-Bibliothek installieren und dann die WebDrivers konfigurieren, die die Browser-Automatisierung übernehmen. Wenn Sie Daten von einer dynamischen Website scrapen, für die Sie sich anmelden müssen, müssen Sie die Web-Automatisierung so einrichten, dass sie den Anmeldeprozess übernimmt, bevor Sie mit dem Scraping von Daten beginnen können.
Selenium bietet eine Vielzahl von Navigationsmethoden, die Sie anpassen können, um Elemente auf einer Webseite leicht zu finden. Darüber hinaus bietet es eine Reihe interaktiver Aktionen, darunter Klicks, Doppelklicks, Ziehen, Ablegen und Scrollen, die eine mühelose Interaktion mit Webseiten ermöglichen.
Die offizielle Selenium-Dokumentation enthält beeindruckende Richtlinien, Schritt-für-Schritt-Anleitungen und Tutorials sowohl zur Webautomatisierung als auch zum Web-Scraping.
Da Selenium ein eher allgemeines Tool für die Webautomatisierung ist, verfügt es über eine größere und vielfältigere Community. Wenn Sie bei der Arbeit mit Selenium Fragen haben, können Ihnen die offizielle Benutzergruppe und die Subreddit-Community weiterhelfen. Wenn Sie ein Problem haben, das sofort gelöst werden muss, können Sie den IRC-Chatroom nutzen.
Leistung und Skalierbarkeit
Die Effektivität der Leistung eines Web-Scraping-Tools hängt stark von seiner Geschwindigkeit ab, da das Ziel darin besteht, schnell eine erhebliche Datenmenge zu sammeln.
Scrapy eignet sich hervorragend zum Scraping von Inhalten aus statischen Webseiten und ermöglicht so eine schnellere Datenextraktion als Selenium. Das liegt daran, dass Selenium auf Browser-Instanzen angewiesen ist, um verschiedene Interaktionen auszuführen, wie z. B. das Klicken auf Schaltflächen oder das Ausfüllen von Formularen.
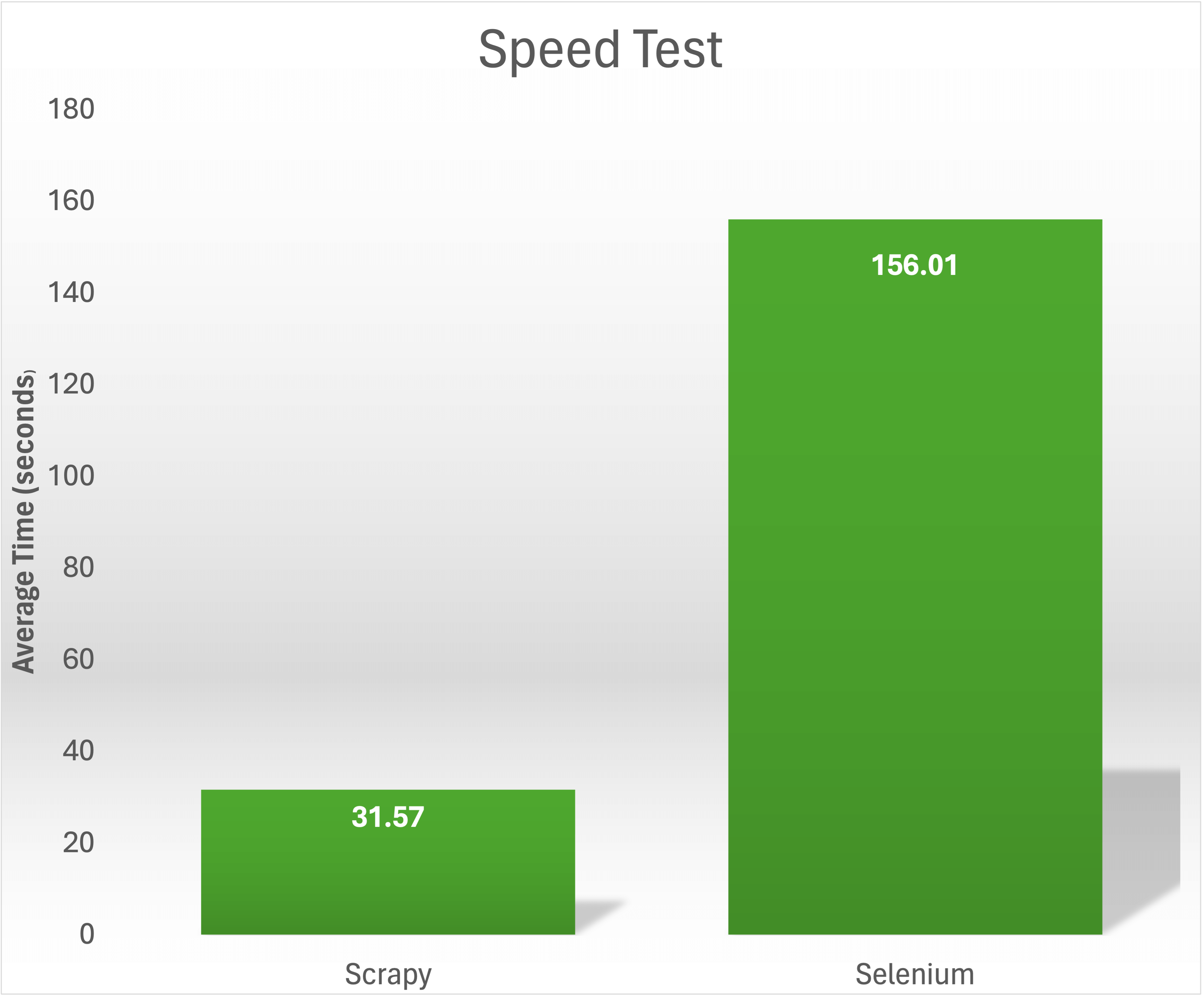
In einem Geschwindigkeitstest, bei dem die Titel und Preise von 1.000 Büchern von https://books.toscrape.com/ gesammelt wurden, konnte Scrapy die Aufgabe in 31,57 Sekunden erledigen. Im Gegensatz dazu benötigte Selenium durchschnittlich 156,01 Sekunden, um denselben Inhalt zu scrapen:
Die Scrapy-Architektur verwaltet den Speicher effizient, indem sie Antworten und Elemente in einem kontinuierlichen Prozess verarbeitet, sodass nicht ganze Webseiten auf einmal in den Speicher geladen werden müssen. Scrapy bietet außerdem integrierte Unterstützung für Caching und inkrementelles Scraping, was die Skalierbarkeit verbessert, indem redundante Anfragen minimiert und nur neue oder aktualisierte Inhalte verarbeitet werden.
Darüber hinaus bietet Scrapy Optionen zur Feinabstimmung der Speichernutzung durch Einstellungen wie gleichzeitige Anfragen, Tiefenbegrenzungen und Element-Pipelines. Mit diesen Funktionen können Sie den Speicherverbrauch entsprechend den spezifischen Anforderungen Ihres Web-Scraping-Projekts optimieren.
Selenium verbraucht in der Regel eine erhebliche Menge an Speicher, wenn es mit JavaScript-lastigen Websites interagiert, was zu einem höheren Speicherverbrauch führt. Dies kann sich negativ auf die Skalierbarkeit und Leistung auswirken, insbesondere bei groß angelegten Scraping-Projekten.
Die in Scrapy integrierte Middleware namens HTTPCacheMiddleware speichert Anfragen der Spider und die dazugehörigen Antworten im Cache. Sie können das Caching aktivieren, indem Sie den folgenden Code zurDatei settings.pyin Ihrem Projekt hinzufügen:
# HTTP-Caching aktivieren und konfigurieren (standardmäßig deaktiviert)
HTTPCACHE_ENABLED = True
Die Skalierung von Selenium für das Scraping großer Datenmengen erfordert die Bereitstellung mehrerer Instanzen über verteilte Systeme hinweg, was zu einem erhöhten Ressourcenbedarf, z. B. an RAM und CPU, führt.
Eignung für verschiedene Arten von Webinhalten
Die meisten Websites im Internet verfügen entweder über dynamische oder statische Webseiten. Schauen wir uns einmal an, wie Scrapy und Selenium mit beiden Arten von Webseiten umgehen.
Dynamische Webseiten
Die meisten dynamischen Webseiten basieren auf JavaScript-Frameworks wie Angular und React, um Inhalte zu aktualisieren, ohne die gesamte Seite neu zu laden.
Selenium kann dynamische Inhalte von verschiedenen Websites scrapen, aber Scrapy unterstützt von Haus aus nicht das Scraping von dynamischen Inhalten, die mit JavaScript generiert wurden. Sie können Scrapy mit Tools wie Selenium und Splash integrieren, um diese Funktionalität zu erhalten.
Statische Webseiten
Statische Webseiten bieten im Vergleich zu dynamischen Seiten in der Regel nur begrenzte Interaktionsmöglichkeiten, sodass Benutzer in der Regel nur Inhalte anzeigen oder auf Links klicken können.
Wie bereits erwähnt, kann Selenium statische Seiten scrapen, aber es ist nicht das effizienteste Tool für diese Aufgabe. Im Gegensatz dazu eignet sich Scrapy hervorragend zum Scrapen statischer Daten und bietet eine reibungslose und effiziente Erfahrung beim Sammeln der gewünschten Informationen.
Integrationsmöglichkeiten
Scrapy lässt sich problemlos in die meisten Python-Tools integrieren, darunter Datenbanken wie MySQL, PostgreSQL und MongoDB, um die gescrapte Daten zu speichern. Sie können sogar objektrelationale Mapper (ORMs) wie SQLAlchemy verwenden, um den Prozess der Datenspeicherung in relationalen Datenbanken zu vereinfachen. Wenn Sie Ihre Daten weiter verarbeiten und analysieren möchten, können Sie pandas verwenden, eine beliebte Bibliothek zur Datenmanipulation und -analyse für Python.
Scrapy kann auch in Web-Frameworks wie Django und Flask integriert werden, um Webanwendungen zu erstellen, die Web-Scraping-Funktionen enthalten. Darüber hinaus ermöglicht die Integration mit FastAPI die Erstellung von leistungsstarken Web-APIs mit asynchroner Unterstützung, die sich für die effiziente Bearbeitung von Scraping-Anfragen eignen.
Im Gegensatz dazu bietet Selenium Browser-Treiber, die als Vermittler zwischen den Selenium WebDriver-APIs und den Browsern fungieren. Sie können einen WebDriver herunterladen und installieren, um ihn in den Webbrowser Ihrer Wahl zu integrieren. Selenium bietet derzeit Browser-Treiber für Chrome, Edge, Firefox und Safari.
Selenium kann auch zum automatischen Testen der Funktionen von Webanwendungen verwendet werden. Beachten Sie jedoch, dass es kein integriertes Testframework hat. Sie können Selenium mit anderen gängigen Testframeworks integrieren, darunter CodeceptJS, Helium und Selenide.
Selenium wurde früher mit CI-Tools wie Jenkins und Travis CI integriert, um die automatische Ausführung von Automatisierungsskripten als Teil der Continuous Integration/Continuous Delivery (CI/CD)-Pipeline zu ermöglichen. Heute wird jedoch alles mit GitHub Actions ausgeführt, die kontinuierliche Test- und Bereitstellungsprozesse unterstützen.
Scrapy kann mit verschiedenen Proxy-Dienstanbietern wie Bright Data integriert werden, indem die Proxy-IP und der Port als Anfrageparameter übergeben werden. Diese Methode wird empfohlen, wenn Sie einen bestimmten Proxy für Ihr Projekt verwenden möchten.
Wenn Sie beispielsweise eine Integration mit einem Proxy-Server wünschen, können Sie denBefehl pip3 install scrapyverwenden,umScrapy wie folgt zu installieren:
#import scrapy module
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# Verbindung mit Proxy herstellen
meta={"proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
for book in response.css(".book-card"):
yield {
"title": book.css(".title ::text").get(),
"price": book.css(".price-wrapper ::text").get(),
}
Hier importieren Sie Scrapy und definieren eine Klassenamens BookSpider, die von der Spider-Klasse von Scrapyabgeleitet ist, um eine Liste von Büchern von der Website zu scrapen.DieMethodestart_requests()initiiert Anfragen mit angegebenen URLs und Proxys, unddieMethodeparse()extrahiert Buchtitel und Preise mithilfe von CSS-Selektoren.
Im Gegensatz dazu unterstützt Selenium eine einfache Proxy-Integration über verschiedene Browser-Treiber wie ChromeDriver und geckodriver. Sie müssen lediglich Selenium WebDriver so konfigurieren, dass seine HTTP-Anfragen über einen Proxy-Server geleitet werden.
Sie können Selenium beispielsweise mit Proxys integrieren, indem Sie die von Bright Data bereitgestellte Proxy-IP und den Port wie folgt angeben:
#import selenium modules
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
# Proxy configuration
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Selenium-Optionen: Integration mit Proxy-Anmeldedaten von Bright Data
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Selenium-Webdriver-Instanziierung
driver = webdriver.Chrome(options=options)
# Anwendungsbeispiel: Scraping einer Webseite
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# Schließen des Treibers
driver.quit()
Hier importieren Sie die erforderlichen Selenium-Module und richten die Proxy-Konfiguration ein. Anschließend konfigurieren Sie Chrome für die Verwendung definierter Proxy-Server, instanziieren einen WebDriver, scrapen eine Webseite („https://example.com“), drucken den Quellcode der Seite und schließen den WebDriver, um den Vorgang abzuschließen.
Fazit
In diesem Artikel haben Sie zwei beliebte Web-Scraping-Tools verglichen: Scrapy und Selenium.
Scrapy ist ein benutzerfreundliches Python-basiertes Scraping-Tool, das sich ideal für die Datenextraktion aus statischen Websites eignet. Im Gegensatz dazu bietet Selenium Automatisierungs- und Scraping-Funktionen in mehreren Programmiersprachen, unterstützt verschiedene Webbrowser und ist die bessere Option für das Scraping dynamischer und mit JavaScript gerenderter Inhalte.
Unabhängig davon, für welches Tool Sie sich entscheiden, empfiehlt es sich, eine Datenplattform wie Bright Data zu verwenden. Damit können Sie Ihre Web-Scraping-Skripte um Funktionen erweitern, um geografische Beschränkungen und Blockierungen zu umgehen und CAPTCHAs zu lösen. Sie können auch die Bright Data API und das SDK nutzen, um ein breiteres Spektrum an Scraping-Anforderungen zu erfüllen und so die Effizienz, Geschwindigkeit, Genauigkeit und Skalierbarkeit Ihres Web-Scraping-Projekts sicherzustellen. Möchten Sie Ihre Datenerfassung noch weiter ausbauen? Kaufen Sie einen benutzerdefinierten Datensatz (kostenlose Muster verfügbar).




