
Dieser Artikel behandelt die Durchführung umfangreicher Web-Scraping-Workloads mit PySpark und Bright Data. Wenn Sie Hunderttausende von Produktseiten scrapen, Preisüberwachung auf Hunderten von Websites durchführen oder Datensätze aus Millionen von Seiten erstellen müssen, reichen Skripte auf einem einzelnen Rechner nicht aus.
Die hier vorgestellten Muster zeigen Ihnen, wie Sie die Scraping-Arbeit auf Cluster verteilen und gleichzeitig die Zuverlässigkeit der Pipeline gewährleisten können, auch wenn das Anfragevolumen steigt.
Am Ende wissen Sie, wie Sie:
- große URL-Listen mit PySpark als verteilte Datensätze behandeln
- Scraping-Workloads effizient auf Partitionsebene ausführen
- Worker entwerfen, die Wiederholungsversuche und Fehler bewältigen können, ohne den gesamten Job neu zu starten
- Proxy-Routing und Netzwerkzuverlässigkeit bei steigendem Anforderungsvolumen zu handhaben
Wenn Web-Scraping zu einem verteilten Problem wird
Die meisten Scraping-Projekte beginnen auf die gleiche Weise: Ein Entwickler schreibt ein Skript, liest eine Liste von URLs ein, sendet Anfragen und speichert die Ergebnisse.
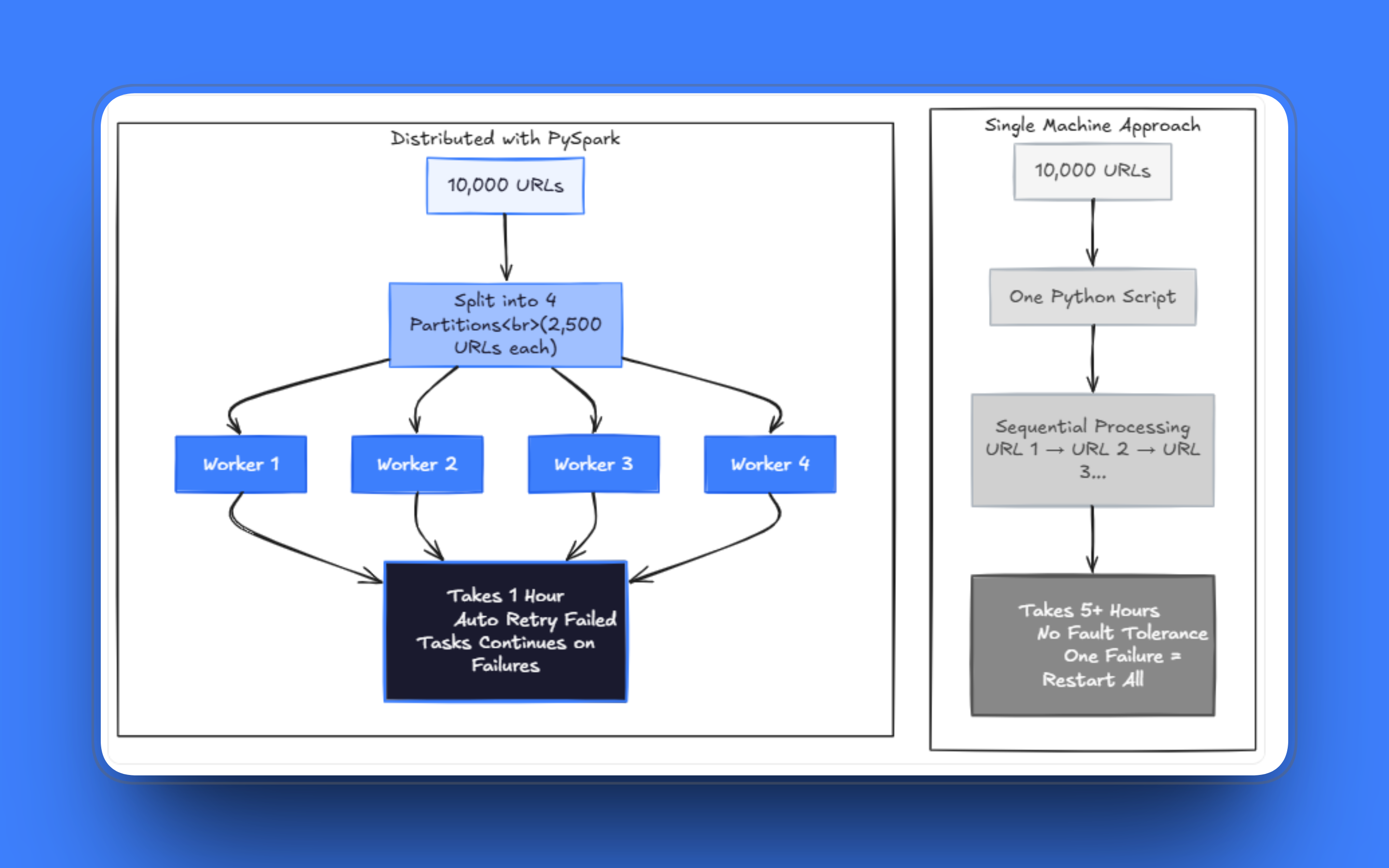
Die Schwachstellen treten zutage, sobald die Arbeitslast skaliert. Jobs, die früher Minuten dauerten, brauchen nun Stunden. Ein paar fehlgeschlagene Anfragen können einen Lauf nach der Verarbeitung von Tausenden von Seiten zum Stillstand bringen, und die Verwaltung von Wiederholungsversuchen innerhalb desselben Skripts bei gleichzeitiger Abwicklung von Abruf und Parsing wird schnell zu einem Chaos. Ich habe Teams gesehen, die diese aus einer einzigen Datei bestehenden Scraper monatelang gewartet und einen Sonderfall nach dem anderen behoben haben, obwohl das eigentliche Problem darin bestand, dass die Architektur nicht mehr zum Problem passte.
Das Scrapen von Hunderttausenden von Seiten auf einem Rechner dauert selbst mit Threading unzumutbar lange. Bei Skalierung muss man über mehrere Worker hinweg arbeiten, und das System muss auch dann weiterlaufen, wenn ein Teil der Anfragen fehlschlägt. Der Weg nach vorne besteht darin, die URL-Liste nicht mehr als geordnete Warteschlange zu betrachten, sondern als Datensatz, den man verteilen kann.
Warum PySpark hier gut geeignet ist
PySpark basiert auf der Idee, Datensätze in Partitionen aufzuteilen und diese parallel über einen Cluster von Rechnern hinweg zu verarbeiten. Das Modell lässt sich direkt auf das Web-Scraping übertragen: Jede URL ist eine Arbeitseinheit, Partitionen gruppieren URLs in Batches, und Executors verarbeiten diese Batches unabhängig voneinander.
Anstatt eine Warteschlange mit Celery oder einer selbst erstellten Multiprocessing-Konfiguration zu verwalten, bietet Spark Fehlertoleranz und Scheduling, ohne dass Sie diese selbst implementieren müssen. Wenn eine Aufgabe fehlschlägt, plant Spark sie neu ein. Wenn ein Knoten ausfällt, wird die Arbeit neu zugewiesen. Sie müssen zwar weiterhin eine sinnvolle Wiederholungslogik in Ihre Aufgaben schreiben, aber die Orchestrierungsebene wird für Sie übernommen.
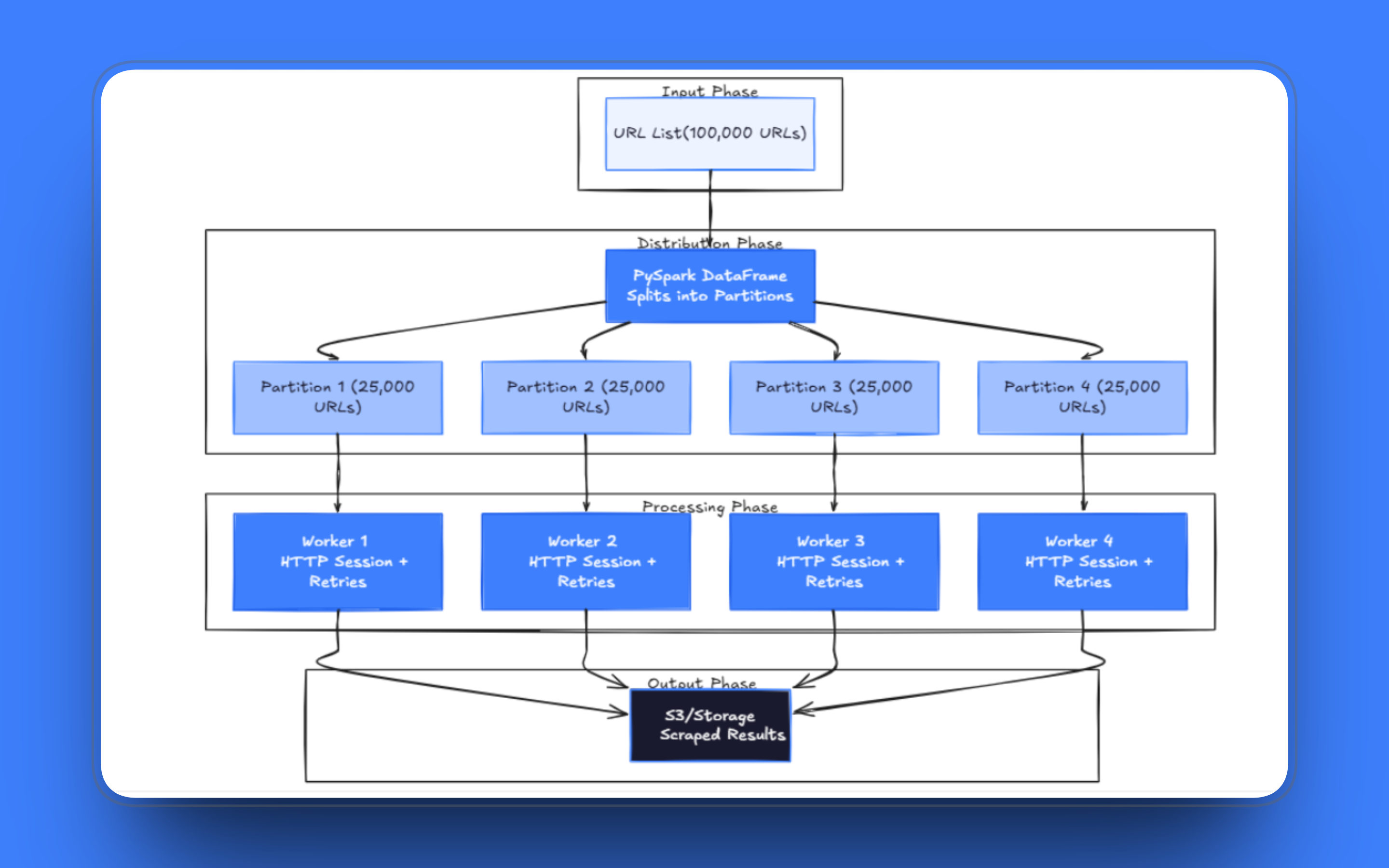
Muster 1: URLs als verteilter Datensatz
Die Grundlage jeder verteilten Scraping-Pipeline ist die Art und Weise, wie Sie die URL-Liste laden. Bei PySpark werden die URLs in einen DataFrame geladen, den Spark automatisch auf die Worker verteilt. Jede Partition enthält einen Ausschnitt der Daten, und Spark weist diese Partitionen den verfügbaren Executors zu.
Eine grundlegende Konfiguration sieht wie folgt aus:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])In der Produktion würden Sie die URL-Liste aus einer Datei, einer Datenbanktabelle oder einem Objektspeicher laden, anstatt sie fest zu codieren. Auch das Schema spielt eine Rolle, sobald Sie Metadaten wie Crawling-Priorität oder Zeitstempel der letzten Abfrage hinzufügen.
Die Anzahl der Partitionen ist die erste Optimierungsentscheidung, die Sie treffen müssen. Bei zu wenigen Partitionen warten die Worker untätig auf langsame Anfragen; bei zu vielen verbringt Spark unverhältnismäßig viel Zeit mit dem Scheduling-Overhead statt mit dem eigentlichen Abrufen.
Ein vernünftiger Ausgangspunkt für eine Scraping-Workload sind 2 bis 4 Partitionen pro Executor-Kern; passen Sie diese dann anhand der Task-Protokolle an. Wenn Executors Partitionen in weniger als einer Sekunde abschließen oder durchgehend mehr als 10 Minuten benötigen, muss die Partitionsgröße angepasst werden.
Muster 2: Ausführen von Anfragen auf Partitionsebene
Der naheliegende erste Versuch besteht darin, eine Transformation auf Zeilenebene auf jede URL im DataFrame anzuwenden. Dieser Ansatz funktioniert zwar, ist aber für das Web-Scraping ungeeignet. Jede Anfrage löst einen separaten Funktionsaufruf aus, was bedeutet, dass für jede URL eine neue Verbindung hergestellt wird, sofern man nicht darauf achtet. Der Overhead summiert sich bei Millionen von Zeilen schnell.
Der richtige Ansatz ist mapPartitions(). Anstatt eine Zeile nach der anderen zu verarbeiten, übergibt diese Funktion Ihrer Funktion eine gesamte Partition als Iterator. Sie erstellen einmalig eine HTTP-Sitzung und verwenden diese für jede Anfrage in der Partition wieder. Connection Pooling über eine lang andauernde Sitzung ist deutlich schneller als der Aufbau einer neuen TCP-Verbindung für jede URL, insbesondere bei Servern, die HTTP Keep-Alive unterstützen.
from pyspark.sql import SparkSession
import requests
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception:
yield {
"url": url,
"status_code": None,
"html": None
}
results = df.rdd.mapPartitions(scrape_partition)Fehlgeschlagene Anfragen liefern einen Datensatz mit Null-Feldern zurück, anstatt eine Ausnahme auszulösen. Dieser Ansatz ist beabsichtigt. Das Weiterleiten einer Ausnahme beendet die gesamte Partitionsaufgabe, wodurch die gesamte vor dem Fehler geleistete Arbeit verloren geht. Die Rückgabe eines Null-Datensatzes hält die Partition am Laufen und bietet Ihnen eine saubere Möglichkeit, fehlgeschlagene URLs anschließend zu identifizieren und erneut zu versuchen.
Es empfiehlt sich, frühzeitig ein explizites Ausgabeschema mit StructType zu definieren, anstatt Spark dieses aus dem RDD ableiten zu lassen. Die Schema-Inferenz erfordert einen vollständigen Scan der Daten, was ressourcenintensiv ist und gelegentlich zu unerwarteten Ergebnissen führen kann, wenn der Inhalt der Antwort unerwartet leer ist.
Muster 3: Entwurf von Workern, die lange Laufzeiten bewältigen können
Ein Job, der eine Million Seiten scrapt, läuft stundenlang. Bei langen Läufen kommt es zu Verbindungsabbrüchen, DNS-Timeouts, 429-Fehlern von Servern mit Ratenbegrenzung und Servern, die gelegentlich Verbindungen mitten in einer Antwort abbrechen. Nichts davon sind Fehler in Ihrem Code; es ist einfach das, was passiert, wenn Sie HTTP-Anfragen in großem Maßstab stellen.
Die Partitionsfunktion ist der richtige Ort, um all diese Probleme zu behandeln. Wiederholungslogik, Backoff-Verzögerungen, Timeout-Einstellungen und Fehlerprotokollierung sollten alle dort untergebracht werden. Wenn Sie alles in einer einzigen Partitionsfunktion halten, bleibt der Rest der Spark-Pipeline übersichtlich und Sie können das Verhalten der Worker unabhängig testen.
import requests
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts) # exponentieller Backoff
if not success:
yield {
"url": url,
"status_code": None,
"html": None
}Hier sind einige Dinge zu beachten. Die Wiederholungsverzögerung nutzt exponentielles Backoff anstelle einer festen Wartezeit. Eine pauschale Verzögerung von 2 Sekunden ist bei gelegentlichen Netzwerkausfällen in Ordnung, verlangsamt die Worker jedoch erheblich, wenn sie auf einen Server treffen, der ständig gedrosselt wird. Protokolliere außerdem den Ausnahmetyp, bevor du den Null-Datensatz ausgibst; der Unterschied zwischen einem Verbindungszeitlimit und einem 403 Forbidden-Fehler gibt dir sehr unterschiedliche Hinweise darauf, was stromaufwärts geschieht.
Überwachung von Jobs in der Produktion
Wenn ein Job über mehrere Stunden hinweg Millionen von URLs verarbeitet, benötigen Sie Einblick in das Geschehen während der Ausführung. Verfolgen Sie mindestens die folgenden Metriken aus jeder Partition:
def scrape_partition(rows):
session = requests.Session()
partition_stats = {
"urls_attempted": 0,
"urls_succeeded": 0,
"urls_failed": 0,
"status_codes": {}
}
for row in rows:
partition_stats["urls_attempted"] += 1
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
partition_stats["urls_succeeded"] += 1
code = response.status_code
partition_stats["status_codes"][code] =
partition_stats["status_codes"].get(code, 0) + 1
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
partition_stats["urls_failed"] += 1
yield {
"url": url,
"status_code": None,
"html": None
}
# Protokolliere Statistiken, wenn die Partitionierung abgeschlossen ist
print(f"Partitionsstatistiken: {partition_stats}")Beobachten Sie während der Ausführung des Jobs die Abschlussraten der Aufgaben in der Spark-Benutzeroberfläche. Wenn Aufgaben mit sehr unterschiedlichen Geschwindigkeiten abgeschlossen werden, sind Ihre Partitionen unausgewogen. Wenn Sie in den Protokollen regelmäßig 403- oder 429-Fehler sehen, muss Ihre Proxy-Rotation angepasst werden, oder Sie müssen Anforderungsverzögerungen hinzufügen. Das Ziel ist es, Probleme zu erkennen, während der Job noch läuft, und nicht erst sechs Stunden später, wenn er fehlschlägt.
Schreiben der Ergebnisse von den Workern (das Produktionsmuster)
Bei Jobs, die länger als eine Stunde laufen, gibt es eine Fehlerbehebungslogik, die vor einem bestimmten Fehlerfall nicht schützen kann: dem Absturz des Treiberprozesses während der Ausführung. Spark plant einzelne Aufgaben neu, wenn sie fehlschlagen, aber wenn ein Treiber ausfällt, geht der gesamte Job verloren.
Die Lösung besteht darin, die Ergebnisse nach Abschluss jeder Partition in einen persistenten Speicher zu schreiben, anstatt alles an den Treiber zurückzusenden und die Ergebnisse bis zum Abschluss des Jobs im Speicher zu behalten. Verwenden Sie foreachPartition(), das jede Partition verarbeitet und es Ihnen ermöglicht, die Ausgabe direkt vom Worker aus zu schreiben, ohne dass Daten über den Treiber zurückfließen:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import requests, time, uuid
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
spark.sparkContext.setCheckpointDir("s3://your-bucket/checkpoints/")
schema = StructType([
StructField("url", StringType(), True),
StructField("status_code", IntegerType(), True),
StructField("html", StringType(), True)
])
def scrape_and_write(rows):
session = requests.Session()
results = []
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
results.append((url, response.status_code, response.text))
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
results.append((url, None, None))
# Schreibe die Ergebnisse dieser Partition direkt vom Worker
partition_id = str(uuid.uuid4())
spark.createDataFrame(results, schema).write.mode("append").parquet(
f"s3://your-bucket/scrape-results/batch={partition_id}"
)
df.rdd.foreachPartition(scrape_and_write)Jeder Worker schreibt seine eigene Ausgabedatei unabhängig. Wenn der Driver während der Ausführung abstürzt, befinden sich die abgeschlossenen Partitionen bereits im Speicher, und nur die noch laufenden müssen erneut ausgeführt werden. Für Jobs mit nachgelagerten Spark-Transformationen der gescrapten Daten ist rdd.checkpoint() eine schlankere Alternative: Es materialisiert das RDD vor der Transformation in das Checkpoint-Verzeichnis und verhindert so, dass Spark den gesamten Scraping-Schritt erneut ausführt, falls eine spätere Phase fehlschlägt.
Muster 4: Weiterleitung von Anfragen über ein Proxy-Netzwerk
Der parallele Betrieb mehrerer Worker erhöht den Durchsatz, doch der Zielserver wird eine Flut von Anfragen aus dem IP-Bereich Ihres Clusters verzeichnen. Die meisten Websites verfügen über Rate-Limiting oder Blockierungen, die genau auf dieses Muster konzentrierten Datenverkehrs aus einem einzigen IP-Bereich ausgelegt sind. Das Weiterleiten von Anfragen über ein Residential-Proxy-Netzwerk verteilt den Traffic auf mehrere IP-Adressen, was dazu beiträgt, dass die Worker weiterlaufen, ohne Blockierungen auszulösen.
Sie konfigurieren den Proxy einmal pro Sitzung innerhalb der Partitionsfunktion, und jede Anfrage, die die Sitzung stellt, wird automatisch über das Netzwerk geleitet:
import requests
BRIGHTDATA_PROXY = (
"http://brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:"
"<ZONE_PASSWORD>@brd.superproxy.io:33335"
)
def scrape_partition(rows):
session = requests.Session()
session.proxies = {
"http": BRIGHTDATA_Proxy,
"https": BRIGHTDATA_Proxy
}
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception as e:
yield {
"url": url,
"status_code": None,
"html": None
}Je nach Zonen-Konfiguration Ihrer Bright Data-Zone können Anfragen SSL-Überprüfungsfehler auslösen, da der Traffic deren Zwischenzertifikatsschicht durchläuft. Eine schnelle Abhilfe besteht darin, verify=False zu übergeben und fortzufahren, doch dieser Ansatz deaktiviert die Zertifikatsvalidierung vollständig, was bedeutet, dass Ihre Worker eine kompromittierte Verbindung zwischen dem Proxy und dem Ziel nicht mehr erkennen können.
Die richtige Lösung besteht darin, das CA-Zertifikat von Bright Data herunterzuladen und es über verify='/path/to/brightdata-ca.crt' zu übergeben, wodurch die vollständige Validierung erhalten bleibt. Ebenfalls erwähnenswert: Die Proxy-URL im Beispiel sollte in der Produktion aus einer Umgebungsvariablen oder einem Secrets-Manager bezogen werden. In einer verteilten Umgebung werden diese Anmeldedaten serialisiert und an jeden Worker-Knoten gesendet, sodass ein Datenleck mehr Informationen preisgibt als auf einem einzelnen Rechner.
Für Ziele, die JavaScript-gerenderte Inhalte bereitstellen, reicht das Routing über einen Standard-Proxy nicht aus. Der Scraping-Browser von Bright Data übernimmt die Ausführung von JavaScript, die CAPTCHA-Lösung und das Browser-Fingerprinting und lässt sich in Playwright und Puppeteer integrieren. Die Struktur der Partitionsfunktion bleibt unverändert; Sie tauschen lediglich die Anforderungssitzung gegen eine Playwright-Browserinstanz aus, die auf den Endpunkt des Scraping-Browsers verweist.
Behebung häufiger Probleme
Einige Probleme treten in der Produktion regelmäßig auf. Wenn Partitionierungsaufgaben wiederholt zeitlich auslaufen, überprüfen Sie zunächst die Partitionsgröße. Partitionen mit mehr als 10.000 URLs überschreiten das Standard-Timeout von Spark, wenn Anfragen langsam sind. Teilen Sie die Partition entweder in kleinere Batches auf oder erhöhen Sie spark.task.maxFailures und spark.network.timeout.
Wenn trotz der Verwendung von Proxys 429-Fehler auftreten, bedeutet dies, dass mehrere Worker gleichzeitig auf dieselbe Domain zugreifen. Fügen Sie zufällige Verzögerungen zwischen den Anfragen ein:
import random
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
time.sleep(random.uniform(1, 3))
# ... restliche Scraping-LogikSpeicherfehler bei Executors bedeuten in der Regel, dass Sie das vollständige HTML vor dem Schreiben ansammeln. Schreiben Sie die Ergebnisse häufiger, oder parsen und verwerfen Sie das HTML innerhalb der Partitionsfunktion, wenn Sie nur extrahierte Felder benötigen.
Partitionen, die mit sehr unterschiedlichen Geschwindigkeiten fertig werden, deuten auf eine unausgewogene Verteilung hin. Führen Sie eine Neupartitionierung mit einer höheren Anzahl durch, um langsame Domains auf die Worker zu verteilen.
Zusammenfassung
Diese Muster bieten Ihnen eine Grundlage, die auch bei Skalierung Bestand hat: Verteilen Sie die URL-Liste, führen Sie Anfragen auf Partitionsebene aus, erstellen Sie Worker, die lange Laufzeiten überstehen, und leiten Sie den Traffic über ein Proxy-Netzwerk, das auch bei steigendem Volumen nicht blockiert wird.
Produktionsaufträge erfordern explizite Schemata, Checkpoints und einen ordnungsgemäßen Umgang mit Geheimnissen, aber die strukturellen Entscheidungen sind unabhängig von der Größe dieselben. Was das Netzwerk und die Infrastruktur betrifft, deckt Bright Data den Großteil dessen ab, was Sie sonst selbst aufbauen und warten müssten.






