

Beim Web-Scraping müssen Sie oft Anti-Bot-Mechanismen umgehen, dynamische Inhalte mit Browser-Automatisierungstools wie Puppeteer laden, Proxy-Rotation verwenden, um IP-Sperren zu vermeiden, und CAPTCHAs lösen. Selbst mit diesen Strategien bleibt die Skalierung und Aufrechterhaltung stabiler Sitzungen eine Herausforderung.
In diesem Artikel erfahren Sie, wie Sie vom herkömmlichen Proxy-basierten Scraping auf Bright Data Scraping Browser umsteigen. Erfahren Sie, wie Sie die Proxy-Verwaltung und Skalierung automatisieren und so Entwicklungskosten und Wartungsaufwand reduzieren können. Beide Methoden werden verglichen, wobei Konfiguration, Leistung, Skalierbarkeit und Komplexität behandelt werden.
Hinweis: Die Beispiele in diesem Artikel dienen nur zu Lehrzwecken. Informieren Sie sich immer über die Nutzungsbedingungen der Ziel-Website und beachten Sie die einschlägigen Gesetze und Vorschriften, bevor Sie Daten auslesen.
Voraussetzungen
Bevor Sie mit dem Lernprogramm beginnen, sollten Sie sicherstellen, dass Sie die folgenden Voraussetzungen erfüllen:
- Node.js
- Visual Studio-Code
- Ein kostenloses Bright Data-Konto, damit Sie den Scraping-Browser verwenden können
Beginnen Sie mit der Erstellung eines neuen Node.js-Projektordners, in dem Sie Ihren Code speichern können.
Öffnen Sie dann Ihr Terminal oder Ihre Shell und erstellen Sie mit den folgenden Befehlen ein neues Verzeichnis:
mkdir scraping-tutorialrncd scraping-tutorial
Initialisieren Sie ein neues Node.js-Projekt:
npm init -y
Die Option -y beantwortet automatisch alle Fragen mit Ja und erstellt eine package.json-Datei mit Standardeinstellungen.
Proxy-basiertes Web-Scraping
Bei einem typischen proxy-basierten Ansatz verwenden Sie ein Browser-Automatisierungstool wie Puppeteer, um mit Ihrer Zieldomäne zu interagieren, dynamische Inhalte zu laden und Daten zu extrahieren. Dabei integrieren Sie Proxys, um IP-Sperren zu vermeiden und die Anonymität zu wahren.
Lassen Sie uns schnell ein Web-Scraping-Skript mit Puppeteer erstellen, das Daten von einer E-Commerce-Website mit Hilfe von Proxys ausliest.
Erstellen eines Web-Scraping-Skripts mit Puppeteer
Beginnen Sie mit der Installation von Puppeteer:
npm install puppeteer
Erstellen Sie dann eine Datei namens proxy-scraper.js (Sie können sie beliebig benennen) im Ordner scraping-tutorial und fügen Sie den folgenden Code hinzu:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Launch a headless browserrn const browser = await puppeteer.launch({rn headless: true,rn });rn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Dieses Skript verwendet Puppeteer, um Buchtitel und Preise von den ersten fünf Seiten der Books to Scrape-Website abzurufen. Es startet einen Headless-Browser, öffnet eine neue Seite und navigiert durch jede Katalogseite.
Für jede Seite verwendet das Skript DOM-Selektoren in page.evaluate(), um Buchtitel und Preise zu extrahieren und die Daten in einem Array zu speichern. Sobald alle Seiten verarbeitet sind, werden die Daten auf der Konsole ausgegeben und der Browser wird geschlossen. Dieser Ansatz extrahiert effizient Daten aus einer paginierten Website.
Testen und führen Sie den Code mit dem folgenden Befehl aus:
node proxy-scraper.jsIhre Ausgabe sollte wie folgt aussehen:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrn[rn { title: 'A Light in the Attic', price: '£51.77' },rn { title: 'Tipping the Velvet', price: '£53.74' },rn { title: 'Soumission', price: '£50.10' },rn { title: 'Sharp Objects', price: '£47.82' },rn { title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },rn { title: 'The Requiem Red', price: '£22.65' },rn…output omitted…rn {rn title: 'In the Country We Love: My Family Divided',rn price: '£22.00'rn }rn]
Proxys einrichten
Proxys werden häufig in Scraping-Konfigurationen eingesetzt, um die Anfragen aufzuteilen und sie unauffindbar zu machen. Ein gängiger Ansatz besteht darin, einen Pool von Proxys zu unterhalten und diese dynamisch zu wechseln.
Legen Sie Ihre Proxys in einem Array ab oder speichern Sie sie in einer separaten Datei, wenn Sie möchten:
const proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];
Proxy-Rotationslogik verwenden
Erweitern wir den Code um eine Logik, die bei jedem Start des Browsers das Proxy-Array durchläuft. Aktualisieren Sie proxy-scraper.js und fügen Sie den folgenden Code ein:
const puppeteer = require(u0022puppeteeru0022);rnrnconst proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];rnrn(async () =u0026gt; {rn // Choose a random proxyrn const randomProxy =rn proxies[Math.floor(Math.random() * proxies.length)];rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.launch({rn headless: true,rn args: [rn `u002du002dproxy-server=http=${randomProxy}`,rn u0022u002du002dno-sandboxu0022,rn u0022u002du002ddisable-setuid-sandboxu0022,rn u0022u002du002dignore-certificate-errorsu0022,rn ],rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(`Using proxy: ${randomProxy}`);rn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Hinweis: Anstatt die Rotation der Proxys manuell durchzuführen, können Sie eine Bibliothek wie luminati-proxy verwenden, um den Prozess zu automatisieren.
In diesem Code wird ein zufälliger Proxy aus der Proxy-Liste ausgewählt und mit der Option --proxy-server=${randomProxy} auf Puppeteer angewendet. Um eine Entdeckung zu vermeiden, wird auch ein zufälliger User-Agent-String zugewiesen. Die Scraping-Logik wird dann wiederholt, und der für das Scraping von Produktdaten verwendete Proxy wird aufgezeichnet.
Wenn Sie den Code erneut ausführen, sollten Sie eine Ausgabe wie zuvor sehen, jedoch mit einem Zusatz zum verwendeten Proxy:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrnUsing proxy: 115.147.63.59:8081rn…output omitted…
Herausforderungen beim proxy-basierten Scraping
Obwohl ein proxy-basierter Ansatz für viele Anwendungsfälle geeignet ist, können Sie mit einigen der folgenden Herausforderungen konfrontiert werden:
- Häufige Blockierungen: Proxies können blockiert werden, wenn die Website eine strenge Anti-Bot-Erkennung hat.
- Leistungsmehraufwand: Rotierende Proxys und die Wiederholung von Anfragen verlangsamen Ihre Datenerfassungspipeline.
- Komplexe Skalierbarkeit: Die Verwaltung und Rotation eines großen Proxy-Pools für optimale Leistung und Verfügbarkeit ist komplex. Es erfordert einen Lastausgleich, die Vermeidung einer übermäßigen Nutzung von Proxys, Abkühlungsphasen und die Behandlung von Ausfällen in Echtzeit. Die Herausforderung wächst mit der Anzahl der gleichzeitigen Anfragen, da das System sich der Erkennung entziehen muss, während es gleichzeitig die auf der schwarzen Liste stehenden oder unzureichend funktionierenden IPs kontinuierlich überwacht und ersetzt.
- Browser-Wartung: Die Browser-Wartung kann sowohl technisch anspruchsvoll als auch ressourcenintensiv sein. Sie müssen den Fingerabdruck des Browsers (Cookies, Kopfzeilen und andere identifizierende Attribute) ständig aktualisieren und bearbeiten, um das reale Benutzerverhalten zu imitieren und fortschrittliche Anti-Bot-Kontrollen zu umgehen.
- Cloud-Browser-Overhead: Cloud-basierte Browser verursachen zusätzlichen betrieblichen Overhead durch erhöhten Ressourcenbedarf und komplexe Infrastrukturkontrolle, was zu erhöhten Betriebskosten führt. Die Skalierung von Browser-Instanzen für eine gleichbleibende Leistung erschwert den Prozess zusätzlich.
DynamicScraping mit dem Bright Data Scraping Browser
Um diese Herausforderungen zu meistern, können Sie eine einzige API-Lösung wie den Bright Data Scraping Browser verwenden. Sie vereinfacht Ihren Betrieb, macht die manuelle Proxy-Rotation und komplexe Browser-Einstellungen überflüssig und führt häufig zu einer höheren Erfolgsquote beim Abrufen von Daten.
Einrichten Ihres Bright Data-Kontos
Melden Sie sich bei Ihrem Bright Data-Konto an, navigieren Sie zu Proxies & Scraping, scrollen Sie zu Scraping-Browser, und klicken Sie auf Erste Schritte:
Behalten Sie die Standardkonfiguration bei und klicken Sie auf Hinzufügen, um eine neue Scraping-Browser-Instanz zu erstellen:
Nachdem Sie eine Scraping-Browser-Instanz erstellt haben, notieren Sie sich die Puppeteer-URL, da Sie diese bald benötigen werden:
Anpassen des Codes zur Verwendung des Bright Data Scraping Browser
Lassen Sie uns nun den Code so anpassen, dass Sie statt der rotierenden Proxys eine direkte Verbindung zum Bright Data Scraping Browser-Endpunkt herstellen.
Erstellen Sie eine neue Datei namens brightdata-scraper.js und fügen Sie den folgenden Code hinzu:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Choose a random proxyrn const SBR_WS_ENDPOINT = u0022YOUR_BRIGHT_DATA_WS_ENDPOINTu0022rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();
Stellen Sie sicher, dass Sie YOUR_BRIGHT_DATA_WS_ENDPOINT durch die URL ersetzen, die Sie im vorherigen Schritt abgerufen haben.
Dieser Code ähnelt dem vorherigen Code, aber anstatt eine Liste von Proxys zu haben und zwischen verschiedenen Proxys zu jonglieren, stellen Sie eine direkte Verbindung mit dem Bright Data-Endpunkt her.
Führen Sie den folgenden Code aus:
node brightdata-scraper.js
Ihr Output sollte derselbe sein wie zuvor, aber jetzt müssen Sie Proxys nicht mehr manuell rotieren oder Benutzeragenten konfigurieren. Der Bright Data Scraping Browser kümmert sich um alles – von der Proxy-Rotation bis zur Umgehung von CAPTCHAs – und gewährleistet so ein unterbrechungsfreies Data Scraping.
Verwandeln Sie den Code in einen Express-Endpunkt
Wenn Sie den Bright Data Scraping Browser in eine größere Anwendung integrieren möchten, können Sie ihn als Express-Endpunkt bereitstellen.
Beginnen Sie mit der Installation von Express:
npm install express
Erstellen Sie eine Datei namens server.js und fügen Sie den folgenden Code hinzu:
const express = require(u0022expressu0022);rnconst puppeteer = require(u0022puppeteeru0022);rnrnconst app = express();rnconst PORT = 3000;rnrn// Needed to parse JSON bodies:rnapp.use(express.json());rnrn// Your Bright Data Scraping Browser WebSocket endpointrnconst SBR_WS_ENDPOINT =rn u0022wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222u0022;rnrn/**rn POST /scraperrn Body example:rn {rn u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022rn }rn*/rnapp.post(u0022/scrapeu0022, async (req, res) =u0026gt; {rn const { baseUrl } = req.body;rnrn if (!baseUrl) {rn return res.status(400).json({rn success: false,rn error: 'Missing u0022baseUrlu0022 in request body.',rn });rn }rnrn try {rn // Connect to the existing Bright Data (Luminati) Scraping Browserrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rn const books = [];rnrn // Example scraping 5 pages of the base URLrn for (let i = 1; i {rn const data = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn const title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn const price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn data.push({ title, price });rn });rn return data;rn });rnrn books.push(...pageBooks);rn }rnrn // Close the browser connectionrn await browser.close();rnrn // Return JSON with the scraped datarn return res.json({rn success: true,rn books,rn });rn } catch (error) {rn console.error(u0022Scraping error:u0022, error);rn return res.status(500).json({rn success: false,rn error: error.message,rn });rn }rn});rnrn// Start the Express serverrnapp.listen(PORT, () =u0026gt; {rn console.log(`Server is listening on http://localhost:${PORT}`);rn});
In diesem Code initialisieren Sie eine Express-Anwendung, akzeptieren JSON-Payloads und definieren eine POST /scrape-Route. Clients senden einen JSON-Body, der die baseUrl enthält, die dann an den Bright Data Scraping Browser-Endpunkt mit der Ziel-URL weitergeleitet wird.
Starten Sie Ihren neuen Express-Server:
node server.js
Um den Endpunkt zu testen, können Sie ein Tool wie Postman (oder einen anderen REST-Client Ihrer Wahl) verwenden, oder Sie können curl von Ihrem Terminal oder Ihrer Shell wie folgt verwenden:
curl -X POST http://localhost/scrape rn-H 'Content-Type: application/json' rn-d '{u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022}'rn
Ihre Ausgabe sollte wie folgt aussehen:
{rn u0022successu0022: true,rn u0022booksu0022: [rn {rn u0022titleu0022: u0022A Light in the Atticu0022,rn u0022priceu0022: u0022£51.77u0022rn },rn {rn u0022titleu0022: u0022Tipping the Velvetu0022,rn u0022priceu0022: u0022£53.74u0022rn },rn {rn u0022titleu0022: u0022Soumissionu0022,rn u0022priceu0022: u0022£50.10u0022rn },rn {rn u0022titleu0022: u0022Sharp Objectsu0022,rn u0022priceu0022: u0022£47.82u0022rn },rn {rn u0022titleu0022: u0022Sapiens: A Brief History of Humankindu0022,rn u0022priceu0022: u0022£54.23u0022rn },rn {rn u0022titleu0022: u0022The Requiem Redu0022,rn u0022priceu0022: u0022£22.65u0022rn },rn {rn u0022titleu0022: u0022The Dirty Little Secrets of Getting Your Dream Jobu0022,rn u0022priceu0022: u0022£33.34u0022rn },rn {rn u0022titleu0022: u0022The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhullu0022,rn u0022priceu0022: u0022£17.93u0022rn },rn rn ... output omitted...rn rn {rn u0022titleu0022: u0022Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)u0022,rn u0022priceu0022: u0022£53.90u0022rn },rn {rn u0022titleu0022: u0022Joinu0022,rn u0022priceu0022: u0022£35.67u0022rn },rn {rn u0022titleu0022: u0022In the Country We Love: My Family Dividedu0022,rn u0022priceu0022: u0022£22.00u0022rn }rn ]rn}
Das folgende Diagramm zeigt den Unterschied zwischen der manuellen Einrichtung (rotierender Proxy) und dem Ansatz des Bright Data Scraping Browser:
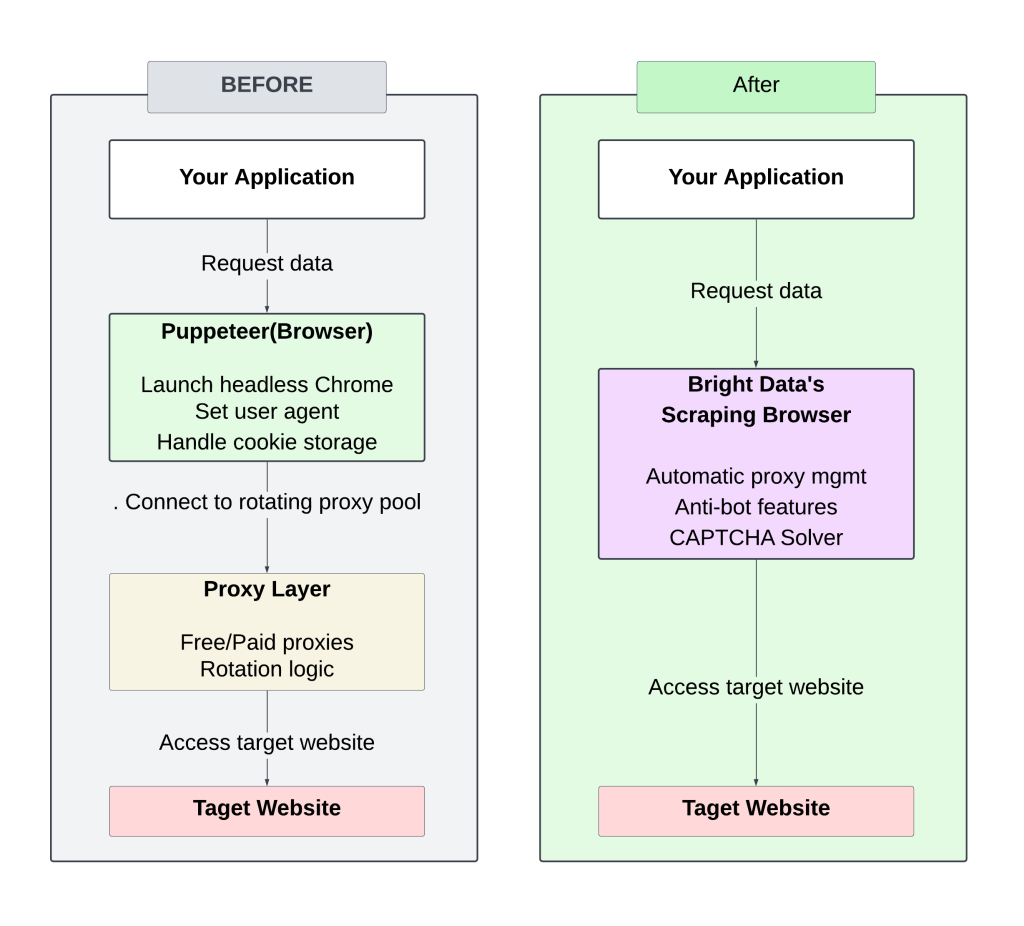
Die Verwaltung manuell rotierender Proxys erfordert ständige Aufmerksamkeit und Abstimmung, was zu häufigen Blockaden und begrenzter Skalierbarkeit führt.
Der Bright Data Scraping Browser rationalisiert den Prozess, indem er die Verwaltung von Proxys oder Headern überflüssig macht und gleichzeitig durch eine optimierte Infrastruktur schnellere Antwortzeiten ermöglicht. Die integrierten Anti-Bot-Strategien erhöhen die Erfolgsquoten und machen es weniger wahrscheinlich, dass Sie blockiert oder markiert werden.
Der gesamte Code für dieses Tutorial ist in diesem GitHub-Repository verfügbar.
ROI berechnen
Der Wechsel von einer manuellen Proxy-basierten Scraping-Einrichtung zum Bright Data Scraping Browser kann die Entwicklungszeit und -kosten erheblich senken.
Traditionelle Einrichtung
Das tägliche Scraping von Nachrichten-Websites erfordert Folgendes:
- Anfängliche Entwicklung: ~50 Stunden ($5.000 USD bei $100 USD/Stunde)
- Laufende Wartung: ~10 Stunden/Monat ($1.000 USD) für Code-Updates, Infrastruktur, Skalierung und Proxy-Management
- Proxy/IP-Kosten: ~$250 USD/Monat (variiert je nach IP-Bedarf)
Geschätzte monatliche Gesamtkosten: ~$1.250 USD
Bright Data Scraping Browser Einrichtung
- Entwicklungszeit: 5-10 Stunden ($1.000 USD)
- Wartung: ~2-4 Stunden/Monat ($200 USD)
- Kein Proxy- oder Infrastrukturmanagement erforderlich
- Bright Data Servicekosten:
- Traffic-Nutzung: $8.40 USD/GB(z.B. 30GB/Monat = $252 USD)
Geschätzte monatliche Gesamtkosten: ~$450 USD
Durch die Automatisierung der Proxy-Verwaltung und die Skalierung des Bright Data Scraping Browsers werden sowohl die anfänglichen Entwicklungskosten als auch die laufenden Wartungskosten gesenkt, wodurch das Scraping großer Datenmengen effizienter und kostengünstiger wird.
Schlussfolgerung
Durch den Wechsel von einer herkömmlichen Proxy-basierten Web Scraping-Konfiguration zum Bright Data Scraping Browser entfällt die lästige Proxy-Rotation und die manuelle Anti-Bot-Behandlung.
Neben dem Abrufen von HTML bietet Bright Data auch zusätzliche Tools zur Optimierung der Datenextraktion:
- Web Scraper für eine saubere Datenextraktion
- Web Unlocker API zum Scrapen schwierigerer Websites
- Datensätze für den Zugriff auf vorab gesammelte, strukturierte Daten
Diese Lösungen können Ihren Scraping-Prozess vereinfachen, die Arbeitslast verringern und die Skalierbarkeit verbessern.





