

Es gibt alle möglichen großartigenTools für das Parsing. In Python sind dieMöglichkeitennahezu unbegrenzt. Bei Go hingegen haben wir nicht wirklich viel Auswahl.
Go ist eine hervorragende Sprache für Leistung und Speicherverwaltung, aber unsere Parsing-Bibliotheken sind recht begrenzt. Node Parser und Tokenizer sind zwei Optionen, die wir aus der Standardbibliothek von Go verwenden können. Wenn Sie mit der Funktionsweise von Web-Scraping noch nicht vertraut sind, lesen Siediesen Leitfaden. Folgen Sie uns und erfahren Sie, wann Sie diese Tools verwenden sollten und wann Sie eine Bibliothek eines Drittanbieters für eine umfassendere Scraping-Lösung wählen sollten.
Voraussetzungen
Grundlegende Kenntnisse von Go und Web-Scraping sind hier hilfreich, aber nicht erforderlich. Wenn Sie mit Go vertraut sind, aber mehr über den Web-Scraping-Prozess erfahren möchten, lesen Siediesen Leitfaden.
Zunächst müssen Sie sicherstellen, dass Go auf Ihrem Rechner installiert ist. Die neueste Version finden Siehier. Laden Sie die neueste Version für Ihr System herunter, und schon kann es losgehen!
Erstellen Sie einen neuen Projektordner und wechseln Sie mit cd in diesen Ordner.
mkdir goparser
cd goparser
Initialisieren Sie ein neues Go-Projekt.
go mod init goparser
Testen Ihrer Konfiguration
Fügen Sie den folgenden Code in eine neue Datei namens main.go ein.
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
Sie können die Datei mit dem folgenden Befehl ausführen.
go run main.go
Wenn alles funktioniert, sollten Sie die folgende Ausgabe erhalten.
Hallo, Welt!
Installieren Sie unsere einzige Abhängigkeit.
go get golang.org/x/net/html
Untersuchen der Seite
Quotes to Scrapeist eine Website, die speziell zum Scrapen von Tutorials entwickelt wurde. In diesem Tutorial extrahieren wir jedes Zitat und seinen Autor aus der Seite.
Um das Zitat-Objekt besser zu verstehen, sehen Sie sich den folgenden Screenshot an. Jedes Zitat ist ein Span und seine Klasse ist Text.
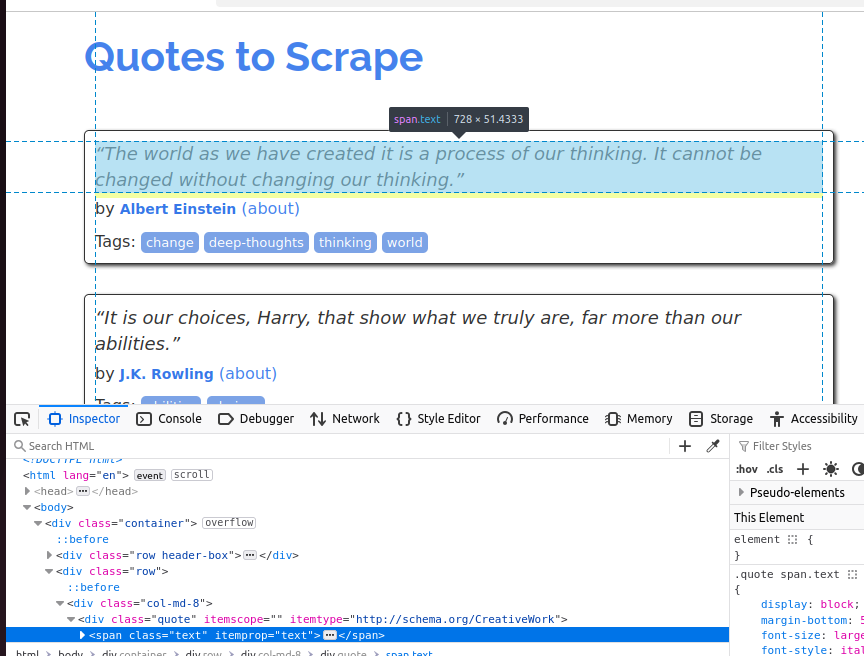
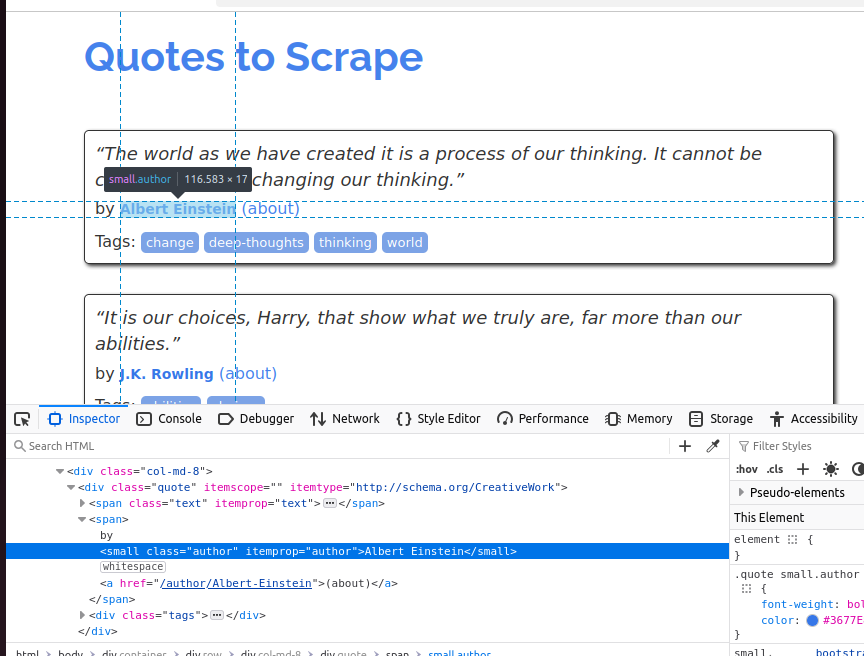
Im nächsten Screenshot untersuchen wir den Autor. Es handelt sich um ein kleines Element, dessen Klasse „author“ lautet.
Sowohl unser Node-Parser- als auch unser Tokenizer-Beispiel liefern das gleiche Ergebnis, das Sie unten sehen.
Zitat: „Die Welt, wie wir sie geschaffen haben, ist ein Produkt unseres Denkens. Sie kann nicht verändert werden, ohne unser Denken zu verändern.“
Autor: Albert Einstein
Zitat: „Es sind unsere Entscheidungen, Harry, die zeigen, wer wir wirklich sind, viel mehr als unsere Fähigkeiten.“
Autor: J.K. Rowling
Zitat: „Es gibt nur zwei Möglichkeiten, sein Leben zu leben. Die eine ist, als wäre nichts ein Wunder. Die andere ist, als ob alles ein Wunder wäre.“
Autor: Albert Einstein
Zitat: „Der Mensch, sei es ein Gentleman oder eine Dame, der keine Freude an einem guten Roman hat, muss unerträglich dumm sein.“
Autor: Jane Austen
Zitat: „Unvollkommenheit ist Schönheit, Wahnsinn ist Genialität, und es ist besser, absolut lächerlich zu sein als absolut langweilig.“
Autor: Marilyn Monroe
Zitat: „Versuche nicht, ein erfolgreicher Mensch zu werden. Werde lieber ein wertvoller Mensch.“
Autor: Albert Einstein
Zitat: „Es ist besser, für das, was man ist, gehasst zu werden, als für das, was man nicht ist, geliebt zu werden.“
Autor: André Gide
Zitat: „Ich habe nicht versagt. Ich habe nur 10.000 Wege gefunden, die nicht funktionieren.“
Autor: Thomas A. Edison
Zitat: „Eine Frau ist wie ein Teebeutel: Man weiß nie, wie stark sie ist, bis sie in heißem Wasser liegt.“
Autor: Eleanor Roosevelt
Zitat: „Ein Tag ohne Sonnenschein ist wie, na ja, die Nacht.“
Autor: Steve Martin
Daten extrahieren mit Node Parser
Mit dem Node Parser von Go können wir das DOM (Document Object Model) durchlaufen und rekursiv bearbeiten. Wenn wir den Node Parser verwenden, wandelt er die gesamte HTML-Seite in eine baumartige Struktur von Node-Objekten um, die wir nach und nach parsen können.
Im folgenden Code erstellen wir eine rekursive Funktion: processNode(). Sie benötigt einen Zeiger auf einen HTML-Knoten. Wenn der Knoten ein Span ist und seine Klasse Text ist, geben wir das Zitat auf der Konsole aus. Wenn der Knoten ein kleines Element ist und seine Klasse Autor ist, geben wir den Autor auf der Konsole aus. Dies sind dieselben Attribute, die wir zuvor bei der Überprüfung der Seite entdeckt haben.
package main
import (
"fmt"
"net/http"
"golang.org/x/net/html")
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parsing(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("Quote:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}
Die Node Parser API eignet sich hervorragend, wenn Sie das gesamte Dokument verarbeiten müssen. Aus Gründen der Speichereffizienz können wir einen Zeiger auf das eigentliche Dokument verwenden und unsere Daten während des Durchlaufens verarbeiten.
Extrahieren von Daten mit Tokenizer
Der Tokenizer verarbeitet die Seite etwas anders. Mit html.NewTokenizer(resp.Body) wird aus unserem Antworttext ein Tokenizer-Objekt erstellt. Anschließend wählen wir aus, welche Tokens (HTML-Tags, Textinhalte oder Attribute) wir aus der Seite extrahieren möchten.
Bei der Verarbeitung jedes Tokens haben wir zwei boolesche Objekte: inQuote und inAuthor. Befindet sich das Token innerhalb eines Zitats oder eines Autors, schneiden wir es zu und geben seine Daten auf der Konsole aus. Die Ausgabe dieses Codes ist zwar dieselbe, aber die Funktionsweise ist tatsächlich sehr unterschiedlich. Mit Node Parser verarbeiten wir unsere Daten nacheinander, während wir den Baum durchlaufen. Mit Tokenizer verarbeiten wir sie in einzelnen Blöcken.
Im folgenden Code legen wir zwei Start-Tokens fest: span und small. Wenn unser Chunk ein span-Element ist und seine Klasse text lautet, geben wir ihn auf der Konsole aus. Wenn unser Chunk ein small ist und seine Klasse author lautet, geben wir ihn ebenfalls auf der Konsole aus. Alle anderen Tokens (HTML-Tags) auf der Seite werden vollständig ignoriert.
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("Zitat:", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("Autor:", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}
Tokenizer ist etwas niedriger angesiedelt als der Node Parser, aber auch weitaus effizienter. Wir müssen nur die relevanten Tokens (HTML-Tags) verarbeiten, anstatt das gesamte Dokument zu durchlaufen. Dies eignet sich am besten für die Verarbeitung großer Datenmengen aus Datenströmen. Mit Tokenizer müssen Sie nur die relevanten Daten verarbeiten, anstatt die gesamte Seite.
Alternativen von Drittanbietern
Sowohl Node Parser als auch Tokenizer sind im Vergleich zu den Tools, die Sie mit Python und JavaScript erhalten, ziemlich niedrigschwellig. Hier sind einige Tools von Drittanbietern, die das Scraping etwas vereinfachen können.
Goquery
Goquerywurde als Go-Alternative zu Jquery entwickelt und ist eine ausgezeichnete Wahl, wenn Sie einen intuitiveren Parser suchen. Mit Goquery erhalten Sie Unterstützung für DOM-Traversal und CSS-Selektoren. Dies ähnelt viel mehr den Lösungen, die Sie vielleicht aus anderen Sprachen gewohnt sind.
htmlquery
Ähnlich wie Goquery ermöglichthtmlquerydie Verwendung von DOM-Traversal und Selektoren. Bei htmlquery verwenden wir jedoch XPath-Selektoren anstelle von CSS-Selektoren. Die Wahl zwischen Goquery und htmlquery sollte wirklich davon abhängen, welche Art von Selektor Sie bevorzugen.
Colly
Collyist ein vollwertiges Web-Scraping-Framework für Go. Mit Colly erhalten wir Unterstützung für CSS-Selektoren, Parallelität und vieles mehr. Sie können es sich als Go-Alternative zuScrapy vorstellen. Wenn Sie an der Verwendung von Colly interessiert sind, finden Siehier ein großartiges Tutorial dazu.
Bright Data Web Scraper
Mit unseremWeb Scraperkönnen Sie den Scraping-Prozess komplett umgehen. Mit Web Scraper scrapen wir die Seite und geben Ihnen die Daten im JSON-Format zurück. Dies ist eine ausgezeichnete Wahl, wenn Sie nur eine API-Anfrage stellen und mit Ihrer Arbeit fortfahren möchten, anstatt das DOM zu durchlaufen, Tokens zu schreiben oder Selektoren zu schreiben. Unser Web Scraper ist keine Go-Bibliothek, sondern ein API-Dienst. Wenn Sie wissen, wie man mit einer REST-API umgeht, ist dies eine wirklich einfache Möglichkeit, Ihren Prozess des Web-Scrapings zu automatisieren.
Fazit
Jetzt wissen Sie, wie Sie HTML mit Go parsen können. Für umfassendere Kenntnisse lesen Sie unseren Leitfaden zurProxy-Integration in Go. Wenn Sie eine gesamte Seite durchlaufen möchten, verwenden Sie Node Parser. Wenn Sie nur relevante Daten von einer Seite parsen möchten, probieren Sie den Tokenizer aus. Wenn keines dieser Tools Ihren Anforderungen entspricht, gibt es eine Vielzahl von Tools von Drittanbietern wie die Web Scrapers von Bright Data. Melden Sie sich jetzt an und starten Sie das Gratis-Testen!





