

In diesem Leitfaden erfahren Sie:
- Was ein ZoomInfo-Scraper ist und wie er funktioniert
- Welche Arten von Daten Sie automatisch aus ZoomInfo extrahieren können
- Wie Sie mit Python ein ZoomInfo-Scraping-Skript erstellen
- Wann und warum eine fortgeschrittenere Lösung erforderlich sein könnte
Lassen Sie uns loslegen!
Was ist ein ZoomInfo-Scraper?
Ein ZoomInfo-Scraper ist ein Tool zum Extrahieren von Daten aus ZoomInfo, einer führenden Plattform, die detaillierte Unternehmens- und Fachinformationen bietet. Diese Lösung automatisiert den Scraping-Prozess und ermöglicht es Ihnen, eine große Menge an Daten zu sammeln. Der Scraper nutzt Techniken wie Browser-Automatisierung, um auf der Website zu navigieren und Inhalte abzurufen.
Daten, die Sie aus ZoomInfo abrufen können
Hier sind einige der wichtigsten Daten, die Sie aus ZoomInfo extrahieren können:
- Unternehmensinformationen: Namen, Branchen, Umsatz, Hauptsitz und Mitarbeiterzahlen.
- Angaben zu Mitarbeitern: Namen, Berufsbezeichnungen, E-Mail-Adressen und Telefonnummern.
- Branchenkenntnisse: Wettbewerber, Markttrends und Unternehmenshierarchien.
ZoomInfo in Python scrapen: Schritt-für-Schritt-Anleitung
In diesem Abschnitt erfahren Sie, wie Sie einen ZoomInfo-Scraper erstellen.
Das Ziel ist es, Ihnen zu zeigen, wie Sie ein Python-Skript erstellen, das automatisch Daten von derNVIDIA ZoomInfo-Unternehmensseite sammelt.
Befolgen Sie die folgenden Schritte!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, stellen Sie sicher, dass Python 3 auf Ihrem Computer installiert ist. Ist dies nicht der Fall, laden Sie es herunter und installieren Sie es mithilfe des Assistenten.
Erstellen Sie nun mit dem folgenden Befehl einen Ordner für Ihr Projekt:
mkdir zoominfo-scraper
Das Verzeichnis „zoominfo-scraper” ist der Projektordner Ihres Python-ZoomInfo-Scrapers.
Öffnen Sie ihn und initialisieren Sie darin eine virtuelle Umgebung:
cd zoominfo-Scraper
python -m venv env
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind dafür geeignet.
Erstellen Sie eine Datei scraper.py im Projektordner, die die folgende Dateistruktur enthalten sollte:

Derzeit ist scraper.py ein leeres Python-Skript. Bald wird es die gewünschte Scraping-Logik enthalten.
Aktivieren Sie die virtuelle Umgebung im Terminal der IDE. Führen Sie unter Linux oder macOS diesen Befehl aus:
./env/bin/activate
Unter Windows führen Sie stattdessen folgenden Befehl aus:
env/Scripts/activate
Großartig, Sie haben jetzt eine Python-Umgebung für das Web-Scraping!
Schritt 2: Wählen Sie die Scraping-Bibliothek aus
Bevor Sie mit dem Programmieren beginnen, müssen Sie wissen, welche Tools für Ihr Ziel am besten geeignet sind. Dazu sollten Sie zunächst einen Vorabtest durchführen, um die Zielseite zu untersuchen. So geht’s:
- Öffnen Sie die Zielseite im Inkognito-Modus Ihres Browsers. Dadurch wird verhindert, dass zuvor gespeicherte Cookies und Einstellungen Ihre Analyse beeinflussen.
- Klicken Sie mit der rechten Maustaste auf eine beliebige Stelle der Seite und wählen Sie „Untersuchen“, um die Entwicklertools des Browsers zu öffnen.
- Navigieren Sie zur Registerkarte „Netzwerk“.
- Laden Sie die Seite neu und überprüfen Sie die Aktivitäten auf der Registerkarte „Abrufen/XHR“.
So erhalten Sie einen Einblick in das Verhalten der Webseite beim Rendern:
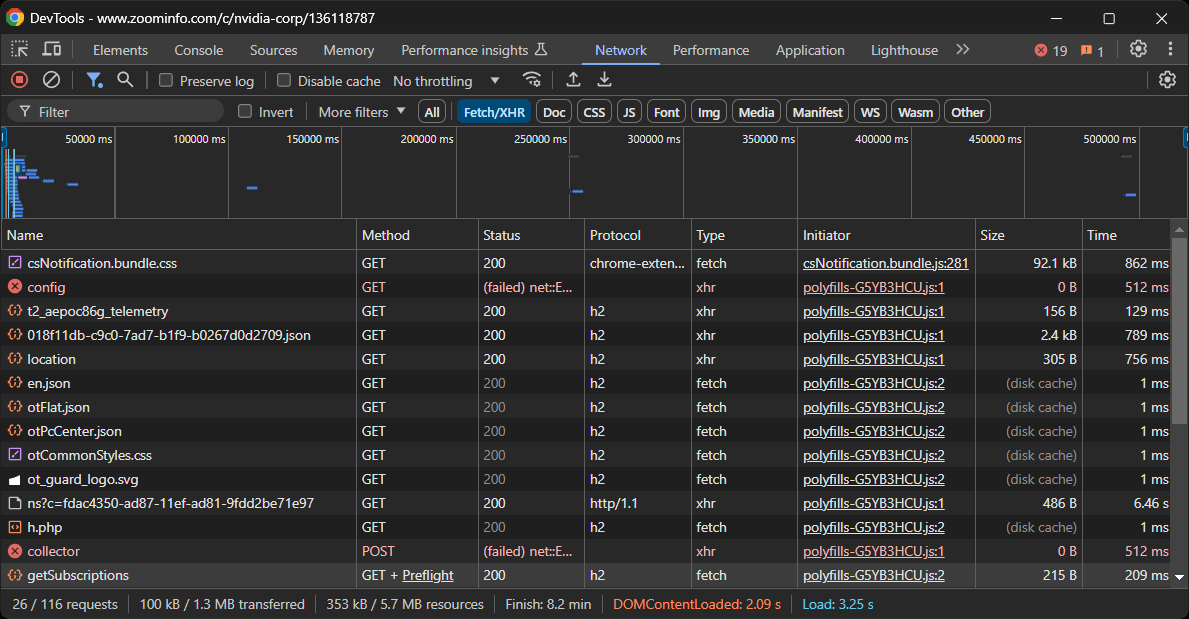
In diesem Abschnitt können Sie alle dynamischen AJAX-Anfragen anzeigen, die von der Seite gestellt werden. Überprüfen Sie jede Anfrage und Sie werden feststellen, dass keine davon relevante Daten enthält. Dies deutet darauf hin, dass die meisten Informationen auf der Seite bereits in dem vom Server zurückgegebenen HTML-Dokument eingebettet sind.
Die Ergebnisse werden Sie natürlich dazu veranlassen, einen HTTP-Client und einen HTML-Parser für das Scraping von ZoomInfo zu verwenden. Die Website verwendet jedoch strenge Anti-Bot-Technologien, die die meisten automatisierten Anfragen blockieren können, die nicht von einem Browser stammen. Der einfachste Weg, dies zu umgehen, ist die Verwendung eines Browser-Automatisierungstools wie Selenium!
Mit Selenium können Sie einen Webbrowser programmgesteuert steuern und ihn anweisen, bestimmte Aktionen auf Webseiten auszuführen, wie es echte Benutzer tun würden. Es ist an der Zeit, es zu installieren und loszulegen!
Schritt 3: Selenium installieren und konfigurieren
In Python ist Selenium über das Selenium- Pip-Paket verfügbar. Installieren Sie es in einer aktivierten virtuellen Python-Umgebung mit diesem Befehl:
pip install -U selenium
Anleitungen zur Verwendung des Tools finden Sie in unserem Tutorial zum Web-Scraping mit Selenium.
Importieren Sie Selenium in scraper.py und initialisieren Sie ein WebDriver -Objekt, um eine Chrome-Instanz zu steuern:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Erstellen Sie eine Chrome-Webtreiberinstanz.
driver = webdriver.Chrome(service=Service())
Der obige Code erstellt eine WebDriver-Instanz für den Betrieb über Chrome. Beachten Sie, dass ZoomInfo eine Anti-Scraping-Technologie verwendet, die Headless-Browser blockiert. Daher können Sie das Flag --headless nicht setzen. Als alternative Lösung sollten Sie Playwright Stealth in Betracht ziehen.
Denken Sie daran, den Webtreiber als letzte Zeile Ihres Scrapers zu schließen:
driver.quit()
Großartig! Sie sind nun vollständig konfiguriert, um mit dem Scraping von ZoomInfo zu beginnen.
Schritt 4: Verbindung zur Zielseite herstellen
Verwenden Sie die Methode get() eines S elenium-WebDriver-Objekts, um den Browser anzuweisen, die gewünschte Seite aufzurufen:
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
Ihre Datei scraper.py sollte nun folgende Codezeilen enthalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(service=Service())
# Verbindung zur Zielseite herstellen
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# Scraping-Logik...
# Browser schließen
driver.quit()
Setzen Sie einen Debugging-Haltepunkt in die letzte Zeile und führen Sie das Skript aus. Sie sollten nun zur Unternehmensseite von NVIDIA gelangen.
Die Meldung „Chrome wird von einer automatisierten Testsoftware gesteuert“ bestätigt, dass Selenium Chrome wie erwartet steuert. Gut gemacht!
Schritt 5: Scrapen der allgemeinen Unternehmensinformationen
Sie müssen die DOM-Struktur der Seite analysieren, um zu verstehen, wie Sie die erforderlichen Daten scrapen können. Das Ziel ist es, die HTML-Elemente zu identifizieren, die die gewünschten Daten enthalten. Beginnen Sie mit der Überprüfung der Elemente im oberen Bereich des Unternehmensinformationsabschnitts:
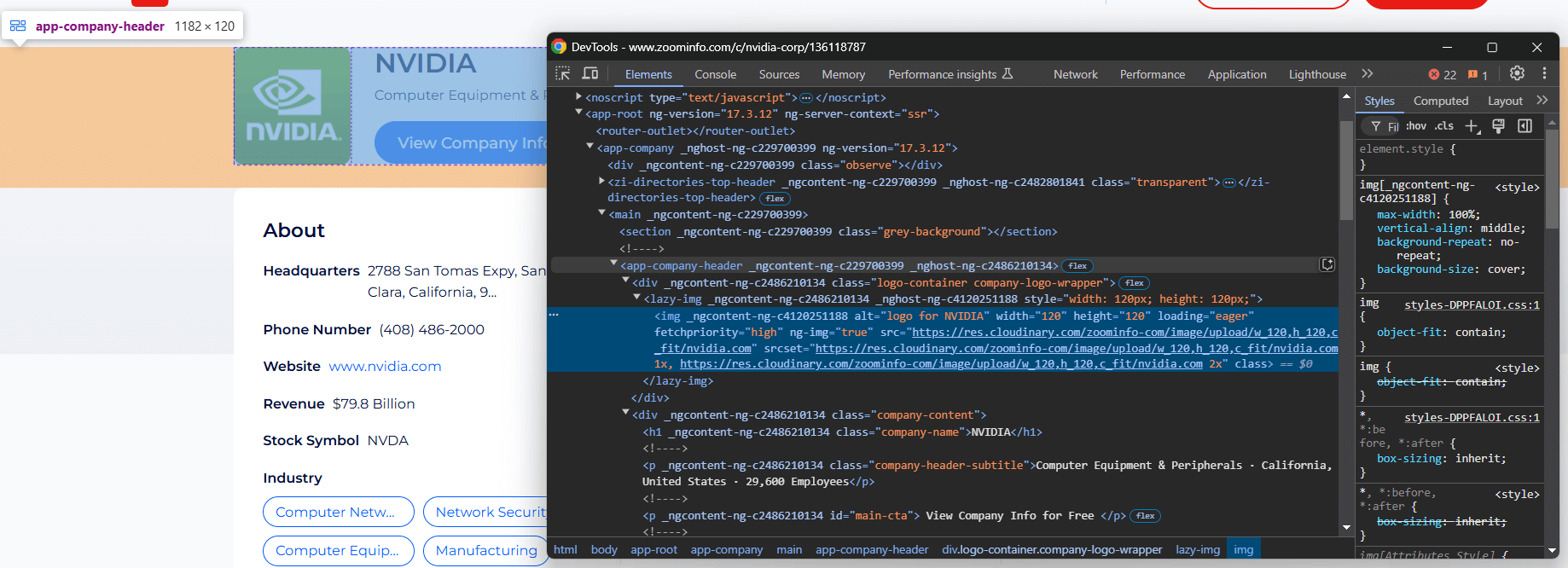
Das Element <app-company-header> enthält:
- Das Firmenbild in einem
<img>-Tag innerhalb eines<div>-Tags mit der Klasse„company-logo-wrapper“. - Den Firmennamen in einem Knoten mit der Klasse
„company-name”. - Den Untertitel des Unternehmens, der in einem Knoten mit der Klasse
„company-header-subtitle”gespeichert ist.
Verwenden Sie Selenium, um diese Elemente zu finden und Daten daraus zu sammeln:
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
Damit der Code funktioniert, vergessen Sie nicht, By zu importieren:
from selenium.webdriver.common.by import By
Beachten Sie, dass die Methode find_element() einen Knoten anhand der angegebenen Knotenauswahlstrategie auswählt. Oben haben wir CSS-Selektoren verwendet. Erfahren Sie mehr über den Unterschied zwischen XPath- und CSS-Selektoren.
Anschließend können Sie mit dem Textattribut auf den Inhalt des Knotens zugreifen. Verwenden Sie zum Zugriff auf ein Attribut die Methode get_attribute().
Drucken Sie die gescrapten Daten aus:
print(logo_url)
print(name)
print(subtitle)
Das Ergebnis sieht wie folgt aus:
https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com
NVIDIA
Computerausrüstung und Peripheriegeräte · Kalifornien, Vereinigte Staaten · 29.600 Mitarbeiter
Wow! Der ZoomInfo-Scraper funktioniert hervorragend.
Schritt 6: Scrapen Sie die Informationen unter „Über uns“
Konzentrieren Sie sich auf den Abschnitt „Über uns” der Unternehmensseite:
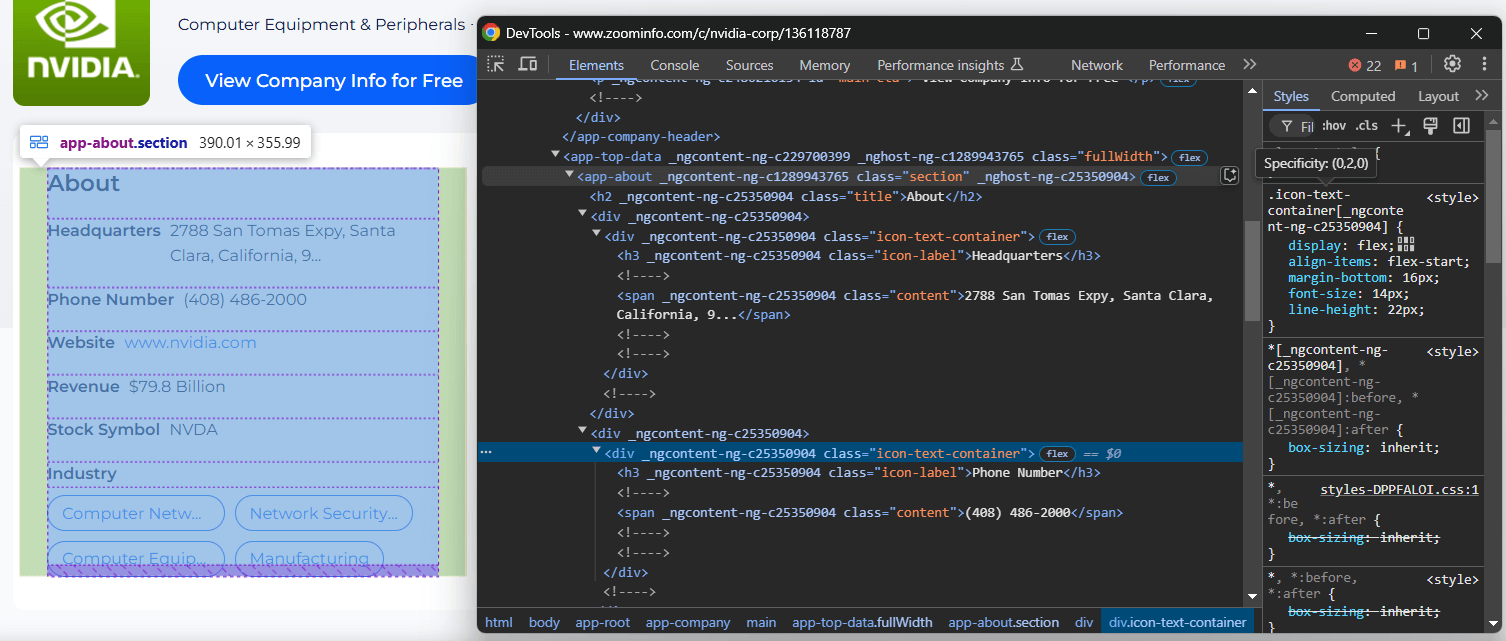
Der Knoten <app-about> enthält Elemente mit generischen Klassen und scheinbar zufällig generierten Attributen. Da sich diese Attribute mit jedem Build ändern können, sollten Sie es vermeiden, sich beim Scrapen auf sie zu verlassen.
Um die Informationen aus diesem Abschnitt zu scrapen, wählen Sie zunächst den Knoten <app-about> aus:
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
Konzentrieren Sie sich nun auf alle .icon-text-container-Elemente innerhalb von <app-about>. Überprüfen Sie dann deren Beschriftungen (.icon-label), um die spezifischen Elemente zu identifizieren, die Sie interessieren. Wenn die Beschriftung übereinstimmt, extrahieren Sie die Daten aus dem .content-Element. Kapseln Sie diese Logik in einer Funktion:
def scrape_about_node(text_container_elements, text_label):
# Durchlaufen Sie diese, um Daten aus den
# spezifischen Knoten von Interesse zu extrahieren.
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# Wählen Sie das Inhaltselement aus und extrahieren Sie Daten daraus.
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
Anschließend können Sie die „Über”-Informationen mit folgendem Befehl scrapen:
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
Als Nächstes zielen Sie auf die Branchen- und Unternehmens-Tags ab.
Wählen Sie die Unternehmensbranche mit h3 .incon-label und die Tags mit zi-directories-chips a aus. Scrapen Sie die Daten daraus mit:
industry_element = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [tag_element.text for tag_element in tag_elements]
Unglaublich! Die Logik zum Scraping der ZoomInfo-Daten ist fertig.
Schritt 7: Sammeln Sie die gescraped Daten
Derzeit sind die gesammelten Daten auf mehrere Variablen verteilt. Füllen Sie ein neues Unternehmensobjekt mit diesen Daten:
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
Drucken Sie die gesammelten Daten aus, um sicherzustellen, dass sie die gewünschten Informationen enthalten
print(items)
Dies führt zu folgender Ausgabe:
{'logo_url': 'https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com', 'name': 'NVIDIA', 'subtitle': 'Computerausrüstung und Peripheriegeräte · Kalifornien, Vereinigte Staaten · 29.600 Mitarbeiter', 'headquarters': '2788 San Tomas Expy, Santa Clara, Kalifornien, 95051, Vereinigte Staaten', 'phone_number': '(408) 486-2000', 'revenue': '79,8 Milliarden US-Dollar', 'stock_symbol': 'NVDA', 'industry': 'Hauptsitz', 'tags': ['Computernetzwerkausrüstung', 'Netzwerksicherheitshardware und -software', 'Computerausrüstung und Peripheriegeräte', 'Fertigung']}
Fantastisch! Jetzt müssen diese Informationen nur noch in eine für Menschen lesbare Datei wie JSON exportiert werden.
Schritt 8: In JSON exportieren
Exportieren Sie das Unternehmen in eine Datei „company.json” mit:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
Zunächst erstellt open() eine Ausgabedatei namens company.json. Anschließend wandelt json.dump() die Firma in ihre JSON-Darstellung um und schreibt sie in die Ausgabedatei.
Denken Sie daran, json aus der Python-Standardbibliothek zu importieren:
import json
Schritt 9: Alles zusammenfügen
Nachfolgend finden Sie die endgültige Datei scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
def scrape_about_node(text_container_elements, text_label):
# iterate through them to scrape data from the
# specific nodes of interest
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# Wähle das Inhaltselement aus und extrahiere Daten daraus.
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
# Chrome-Webtreiberinstanz erstellen
driver = webdriver.Chrome(service=Service())
# Verbindung zur Zielseite herstellen
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# Unternehmensinformationen scrapen
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
# Daten aus dem Abschnitt „Über uns” extrahieren
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
text_container_elements = about_element.find_elements(By.CSS_SELECTOR, ".icon-text-container")
headquarters = scrape_about_node(text_container_elements, „Headquarters”)
phone_number = scrape_about_node(text_container_elements, „Phone Number”)
revenue = scrape_about_node(text_container_elements, „Revenue”)
stock_symbol = scrape_about_node(text_container_elements, „Stock Symbol”)
# Unternehmen, Branche und Tags scrapen
Branchenelement = Über-Element.find_element(By.CSS_SELECTOR, „h3.icon-label”)
Branche = Branchenelement.text
Tag-Elemente = Über-Element.find_elements(By.CSS_SELECTOR, „zi-directories-chips a”)
tags = [tag_element.text for tag_element in tag_elements]
# die gescrapten Daten sammeln
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
# exportiere die gescrapten Daten nach JSON
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# schließe den Browser
driver.quit()
Mit nur etwas mehr als 70 Zeilen Code haben Sie gerade ein Skript zum Scrapen von ZoomInfo-Daten in Python erstellt!
Starten Sie den Scraper mit dem folgenden Befehl:
python3 script.py
Oder unter Windows:
python script.py
Eine Datei namens „company.json” wird im Ordner Ihres Projekts angezeigt. Öffnen Sie diese Datei, um folgenden Inhalt anzuzeigen:
{
"logo_url": "https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com",
"name": "NVIDIA",
"subtitle": "Computer Equipment & Peripherals · Kalifornien, Vereinigte Staaten · 29.600 Mitarbeiter",
"headquarters": "2788 San Tomas Expy, Santa Clara, Kalifornien, 95051, Vereinigte Staaten",
"phone_number": "(408) 486-2000",
"revenue": "$79,8 Milliarden",
„Aktienkürzel“: „NVDA“,
„Branche“: „Hauptsitz“,
„Tags“: [
„Computernetzwerkausrüstung“,
„Netzwerksicherheitshardware und -software“,
„Computerausrüstung und Peripheriegeräte“,
„Fertigung“
]
}Herzlichen Glückwunsch, Mission abgeschlossen!
ZoomInfo-Daten ganz einfach freischalten
ZoomInfo bietet viel mehr als nur Unternehmensübersichten – es liefert eine Fülle nützlicher Informationen. Das Problem ist, dass das Scraping dieser Daten eine ziemliche Herausforderung sein kann, da die meisten Seiten unter der ZoomInfo-Domain durch Anti-Bot-Maßnahmen geschützt sind.
Wenn Sie versuchen, mit Selenium oder anderen Browser-Automatisierungstools auf diese Seiten zuzugreifen, werden Sie wahrscheinlich auf eine CAPTCHA -Seite stoßen, die Ihre Versuche blockiert.
Als ersten Schritt sollten Sie unsere Anleitung zum Umgehen von CAPTCHAs in Python befolgen. Aufgrund der strengen Ratenbegrenzung der Website kann es jedoch weiterhin zu 429 Too Many Requests-Fehlern kommen. In solchen Fällen können Sie einen Proxy in Selenium integrieren, um Ihre Exit-IP zu rotieren.
Diese Probleme zeigen, wie schnell das Scraping von ZoomInfo ohne die richtigen Tools zu einem frustrierenden Prozess werden kann. Außerdem führt die Tatsache, dass Sie keine Headless-Browser verwenden können, dazu, dass Ihr Scraping-Skript langsam und ressourcenintensiv ist.
Die Lösung? Verwenden Sie die spezielle ZoomInfo Scraper API von Bright Data, um Daten von der Zielwebsite über einfache API-Aufrufe abzurufen, ohne blockiert zu werden!
Fazit
In dieser Schritt-für-Schritt-Anleitung haben Sie gelernt, was ein ZoomInfo-Scraper ist und welche Arten von Daten er abrufen kann. Außerdem haben Sie ein Python-Skript erstellt, um ZoomInfo nach Unternehmensübersichtsdaten zu durchsuchen, wofür weniger als 100 Zeilen Code erforderlich waren.
Die Herausforderung besteht darin, dass ZoomInfo strenge Anti-Bot-Maßnahmen wie CAPTCHAs, Browser-Fingerprinting und IP-Sperren einsetzt, um automatisierte Skripte zu blockieren. Mit unserer ZoomInfo Scraper API gehören all diese Herausforderungen der Vergangenheit an.
Wenn Web-Scraping nichts für Sie ist, Sie aber dennoch an Unternehmens- oder Mitarbeiterdaten interessiert sind, entdecken Sie unsere ZoomInfo-Datensätze!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unsere Scraper-APIs auszuprobieren oder unsere Datensätze zu erkunden.





