

Seit fast 25 Jahren ist Tripadvisor ein großartiger Ort, um alle möglichen Reiseziele im Internet zu entdecken. Heute werden wir Hotel-Daten von Tripadvisor scrapen. Tripadvisor setzt eine Vielzahl von Techniken ein, um Scraper zu blockieren, darunter:
- JavaScript-Herausforderungen
- Browser-Fingerprinting
- Dynamische Seiteninhalte
Befolgen Sie unsere Anleitung unten, und am Ende werden Sie Tripadvisor mühelos scrapen können.
Voraussetzungen
Tripadvisor verwendet verschiedene Blockierungstechniken. Der Einfachheit halber haben wir diese in der folgenden Liste aufgeführt.
- JavaScript-Challenge: Tripadvisor sendet eine einfache Challenge (in JavaScript) in Form eines CAPTCHA an Ihren Browser. Wenn Ihr Browser diese nicht lösen kann, handelt es sich wahrscheinlich um einen Bot.
- Browser-Fingerprinting: Sie senden ein Cookie an Ihren Browser und verfolgen Sie dann damit.
- Dynamischer Inhalt: Zunächst erhalten wir eine leere Seite. Dann werden eine Reihe von API-Aufrufen durchgeführt, um unsere Daten abzurufen und darzustellen.
Python Requests und BeautifulSoup reichen dafür einfach nicht aus. Wir brauchen einen echten Browser. Mit Selenium verwenden wir Webdriver, um unseren Browser tatsächlich aus einem Python-Skript heraus zu steuern. Selenium enthält bereits alles, was wir brauchen. Erfahren Sie hier mehr über Web-Scraping mit Selenium.
Installieren wir Selenium. Sie sollten auch sicherstellen, dass Sie Webdriver installiert haben. Die neueste Version von Webdriver finden Sie hier. Sie sollten sicherstellen, dass Ihre Version von Chromedriver mit Ihrer Version von Chrome übereinstimmt.
Sie können Ihre Versionsnummer mit dem folgenden Befehl überprüfen. Stellen Sie sicher, dass sie mit Ihrer Chromedriver-Version übereinstimmt.
google-chrome --version
Die Ausgabe sollte in etwa so aussehen.
Google Chrome 130.0.6723.116
Anschließend können wir Selenium mit dem folgenden Befehl installieren.
pip install selenium
Nachdem Selenium installiert ist, müssen wir nichts weiter installieren. Selenium wird alle unsere Anforderungen im Zusammenhang mit dem Scraping erfüllen. Alle anderen Pakete in diesem Tutorial sind bereits in Python enthalten.
Was soll von Tripadvisor gescrapt werden?
Schauen wir uns einmal genauer an, wie wir Hotels von Tripadvisor scrapen. Wenn wir auf Tripadvisor eine einfache Suche nach Miami durchführen, erhalten wir eine Seite, die der im folgenden Screenshot ähnelt. Wie Sie sehen, erhalten wir nicht nur Ergebnisse für Hotels, sondern für alle Kategorien.
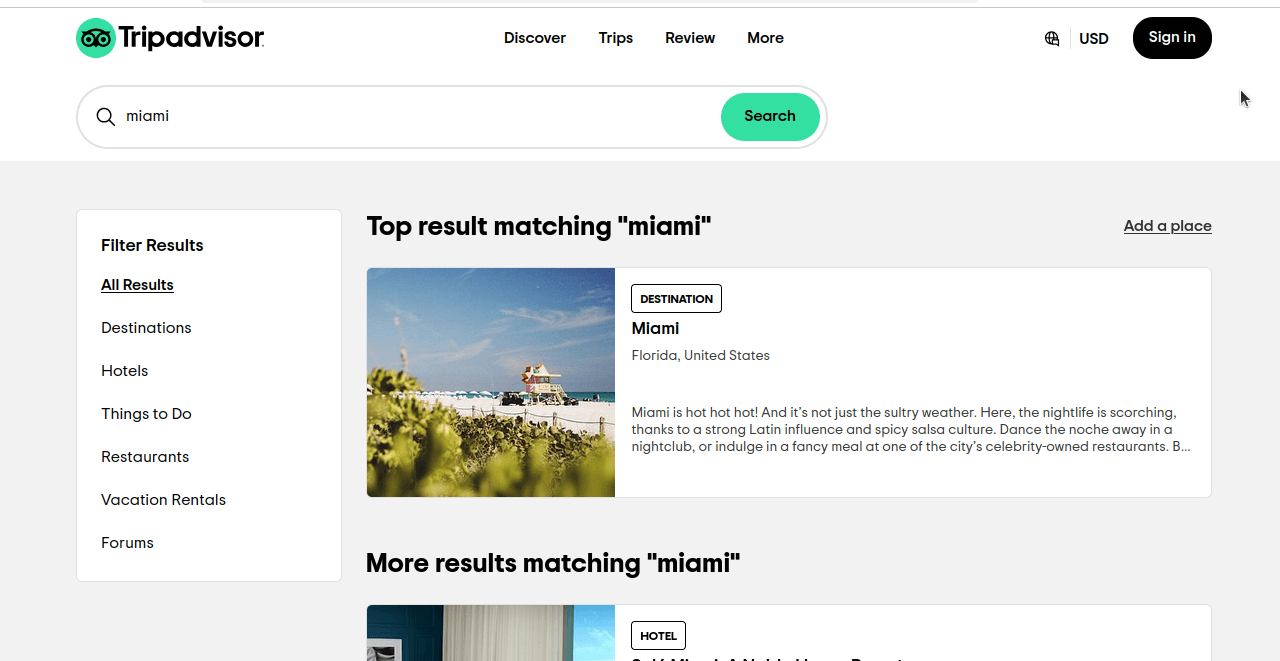
Schauen Sie sich die URL dieser Seite genauer an: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Jetzt klicken wir auf „Hotels” und sehen uns unsere URL an: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Die URLs sehen immer noch sehr ähnlich aus. Im Folgenden sehen wir uns diese URLs an, entfernen jedoch die unnötigen Teile.
- Alle Ergebnisse:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - Hotels:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h.
ssrc ist die Abfrage, mit der wir unsere Ergebnisse auswählen. ssrc=a wird für alle Ergebnisse verwendet. ssrc=h wird für Hotels verwendet. Wenn Sie auf diesen Link https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h klicken, sollten Sie eine Seite erhalten, die der im folgenden Screenshot ähnelt.
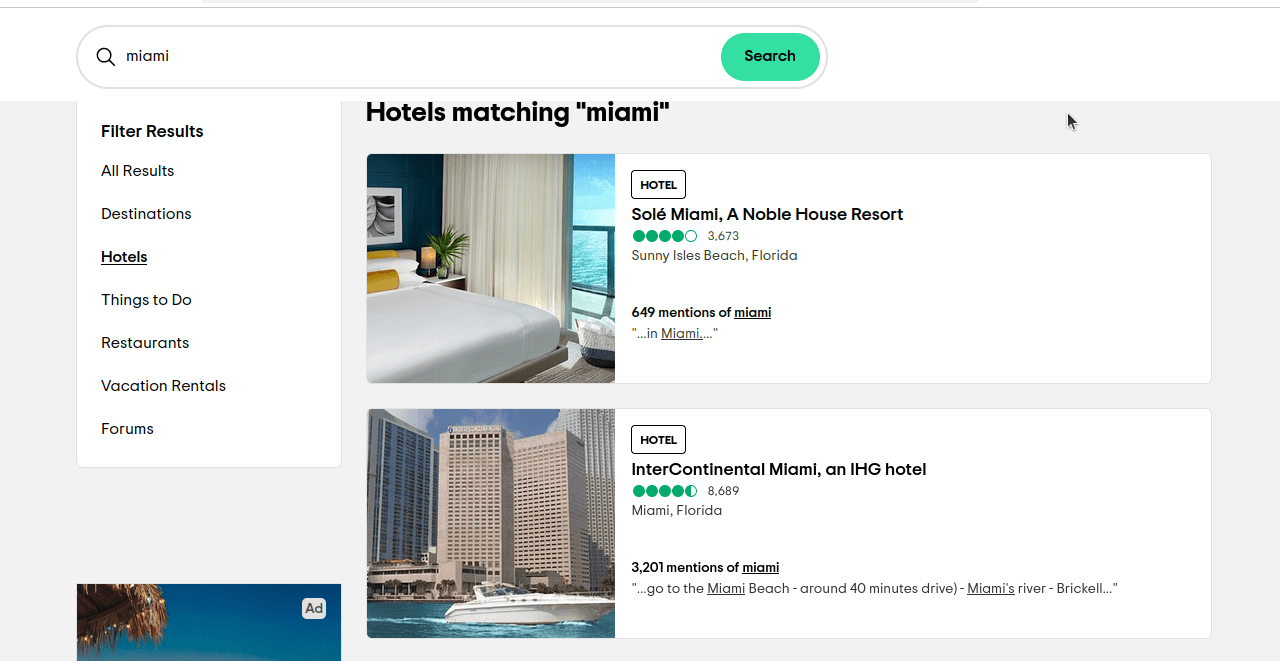
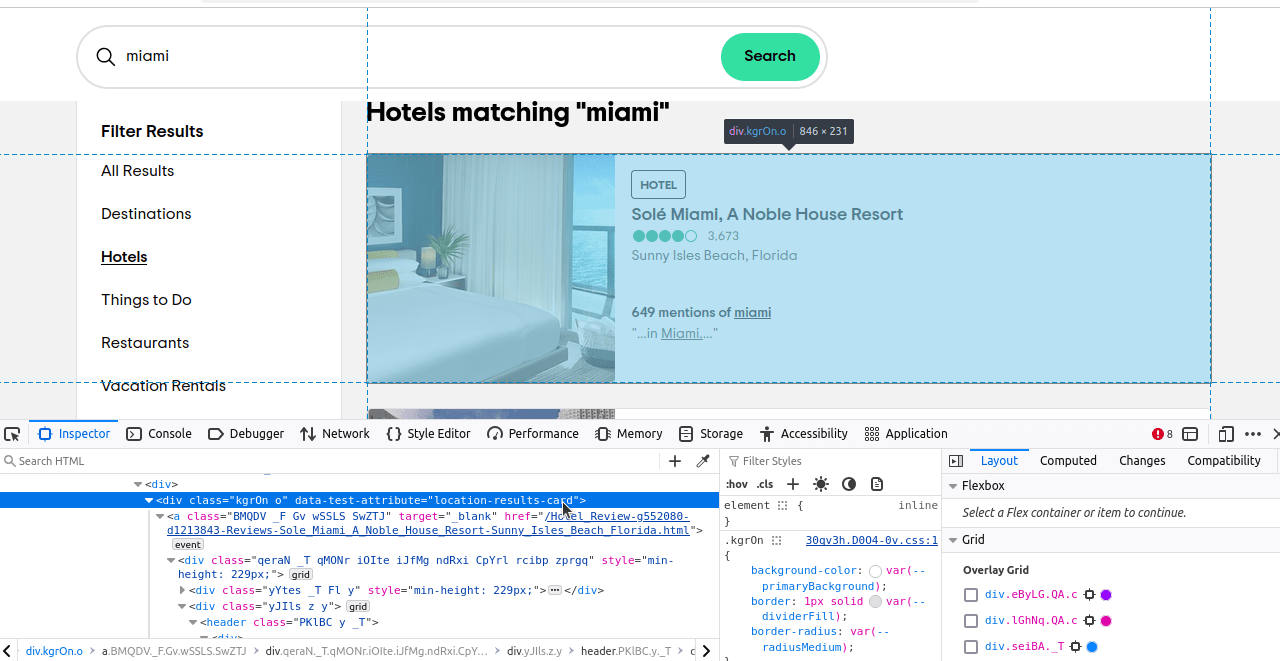
Jetzt müssen wir nur noch herausfinden, welche Elemente wir suchen möchten. Wenn Sie diese Elemente untersuchen, werden Sie feststellen, dass jedes Ergebnis ein Daten-Test-Attribut „location-results-card” hat. Das ist wirklich wichtig. Wir können dies verwenden, um unseren CSS-Selektor zu schreiben: div[data-test-attribute='location-results-card']. Wenn wir die eigentliche Seite scrapen, suchen wir nach allen Elementen auf der Seite, die diesem Selektor entsprechen.
Tripadvisor mit Vanilla Selenium scrapen
Jetzt versuchen wir, Tripadvisor mit dem guten alten Selenium zu scrapen. Wir schreiben ein Skript, das insgesamt ziemlich einfach ist. Wir brauchen eigentlich nur zwei Funktionen. Eine, um das Scraping durchzuführen, und eine, um unsere Daten in eine CSV-Datei zu schreiben. Sobald wir diese haben, fügen wir alles zu einem voll funktionsfähigen Skript zusammen.
Sehen Sie sich write_to_csv() an. Es benötigt zwei Argumente: data und page_number. data kann entweder ein dict oder ein Array von dict-Objekten sein, die wir schreiben möchten. page_number wird verwendet, um unseren Dateinamen zu schreiben. Wir verwenden Path(filename).exists(), um zu überprüfen, ob unsere Datei existiert. mode ist der Modus, den wir zum Öffnen der Datei verwenden. Wenn die Datei existiert, setzen wir unseren Modus auf „a“ oder append. Wenn die Datei nicht existiert, belassen wir unseren Modus auf dem Standardwert „w“( write). Diese beiden Modi stellen sicher, dass wir immer eine Datei haben und dass die vorhandene Datei nicht überschrieben wird.
Einzelne Funktionen
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page} erfolgreich in CSV geschrieben...")
- Zu Beginn der Funktion überprüfen wir, ob unsere
DateneineListesind. Ist dies nicht der Fall, konvertieren wir sie in eine Liste. f"tripadvisor-{page_number}.csv"bildet unseren Dateinamen.- Unser
Standardmodusist„w“, aber wenn die Datei bereits existiert, ändern wir unseren Modus zu„a“. csv.DictWriter(file, fieldnames=data[0].keys())initialisiert unseren Dateischreiber.- Wenn wir uns im Schreibmodus befinden, verwenden wir die Schlüssel unseres ersten Objekts für unsere Kopfzeilen. Wenn wir die Datei anhängen, ist dies nicht erforderlich.
- Nachdem die Datei eingerichtet wurde, verwenden wir
writer.writerows(data), um unsere Daten in eine CSV-Datei zu schreiben.
Sehen wir uns nun unsere Scraping-Funktion an. Diese Funktion benötigt nur ein Argument, unsere page_number…ziemlich selbsterklärend. Wir beginnen mit der Einrichtung einiger benutzerdefinierter ChromeOptions. Wir fügen Argumente hinzu, um unseren Browser headless zu machen und einen gefälschten User-Agent zu verwenden. Dies sollte unseren Browser hoffentlich so gut maskieren, dass Tripadvisor uns durchlässt. Anschließend verwenden wir webdriver, um unseren Browser zu starten und zur Suchergebnisseite zu navigieren. Wir verwenden sleep(5), damit wir 5 Sekunden warten können, bis der Inhalt geladen ist, und damit wir auch eher wie ein normaler Benutzer wirken. Wir verwenden den CSS-Selektor, den wir zuvor im Abschnitt „Was soll gescrapt werden?“ erwähnt haben. Wenn wir keine hotel_cards haben, machen wir einen Screenshot und beenden die Funktion vorzeitig. Wenn wir hotel_cards haben, extrahieren wir deren Daten und fügen sie unserem scraped_data-Array hinzu. Sobald wir mit dem Scrapen der Daten fertig sind, schreiben wir alles in eine CSV-Datei.
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Verbindung zum Scraping-Browser wird hergestellt...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Verbunden! Seite wird gescrapt...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
„location”: data_array[3],
„location_mentions”: data_array[4].split(„ ”)[0],
„review_summary”: data_array[5]
}
scraped_data.append(hotel_dict)
print(f„Karte {index} erfolgreich gescrapt”)
print(f"Seite {page_number} gescrapt")
write_to_csv(scraped_data, page_number)
Tripadvisor-Daten scrapen
Wenn wir alles zusammenfügen, erhalten wir ein Skript wie dieses. Sie können den folgenden Code gerne kopieren und in Ihre eigene Python-Datei einfügen.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page} erfolgreich in CSV geschrieben...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Verbindung zum Scraping-Browser wird hergestellt...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Verbunden! Seite wird gescrapt...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Karte {index} erfolgreich gescrapt")
print(f"Seite {page_number} gescrapt")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
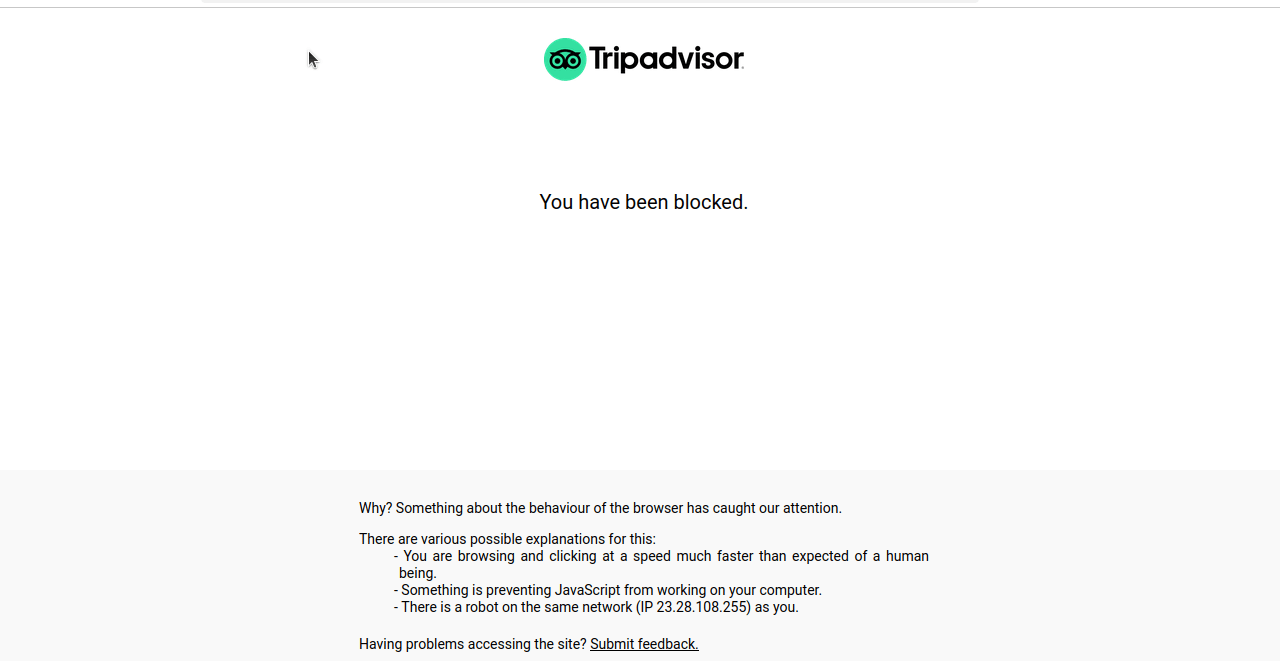
Wenn wir diesen Code ausführen, erhalten wir in den meisten Fällen einen Blockbildschirm oder ein CAPTCHA, wie Sie im folgenden Screenshot sehen können.

Fortgeschrittene Techniken
Im Folgenden werden einige der fortgeschritteneren Techniken vorgestellt, die in unserem Skript verwendet werden. Wir werden uns hauptsächlich damit befassen, wie die Paginierung gehandhabt wird, und einige Techniken vorstellen, mit denen sich eine Sperrung verhindern lässt.
Umgang mit Paginierung
Sehen Sie sich die von uns verwendete URL an: https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}. Unsere Paginierung wird mit dem Offset-Parameter gehandhabt. Wir erhalten 30 Ergebnisse pro Seite. page_number*30 multipliziert unsere Seitenzahl mit den Ergebnissen pro Seite (30). Seite 0 liefert die Ergebnisse 1 bis 30. Seite 2 enthält die Ergebnisse 31 bis 60 … und so weiter.
Sehen Sie sich auch unser Hauptprogramm genauer an. PAGES enthält die Anzahl der Seiten, die wir scrapen möchten. Wenn Sie die ersten fünf Seiten der Daten scrapen möchten, ändern Sie einfach PAGES = 1 in PAGES = 5.
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Blockierung mindern
Mit Vanilla Selenium verwenden wir einige Techniken, um zu verhindern, dass wir blockiert werden. Wir verwenden sowohl einen gefälschten User-Agent als auch sleep(5). Diese Sleep-Funktion ermöglicht das Laden der Seite und verteilt unsere Anfragen, wenn wir mehrere Seiten scrapen.
Hier ist unser User-Agent. Dieser teilt Tripadvisor mit, dass unser Browser mit Chrome 130.0.0.0 und Safari 537.36 kompatibel ist. Wenn Tripadvisor dies liest, sendet uns ihr Server eine Seite zurück, die mit diesen Browsern kompatibel ist.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36
Es ist jedoch immer noch möglich, dass Sie entdeckt werden und Ihr Scraper blockiert wird. Um die Blockierung konsequent zu umgehen, benötigen wir etwas Stärkeres als Vanilla Selenium.
Erwägen Sie die Verwendung von Bright Data
Bright Data bietet alle möglichen Lösungen, um die Blockierungen zu umgehen, auf die wir mit Vanilla Selenium gestoßen sind. Scraping-Browser gibt uns die Möglichkeit, eine Remote-Instanz von Selenium zu betreiben, wobei wir ausschließlich die besten Proxys von Bright Data verwenden. Zunächst gehen wir den Anmeldeprozess durch. Anschließend passen wir unser vorheriges Skript so an, dass es mit Scraping-Browser läuft.
Erstellen eines Kontos
Gehen Sie zunächst auf unsere Seite für den Scraping-Browser. Klicken Sie dort auf „Gratis testen”. Sie können ein Konto mit Google, Github oder Ihrer E-Mail-Adresse erstellen.
Sobald Sie Ihr Konto erstellt haben, werden Sie zum Dashboard weitergeleitet. Klicken Sie auf „Hinzufügen”.
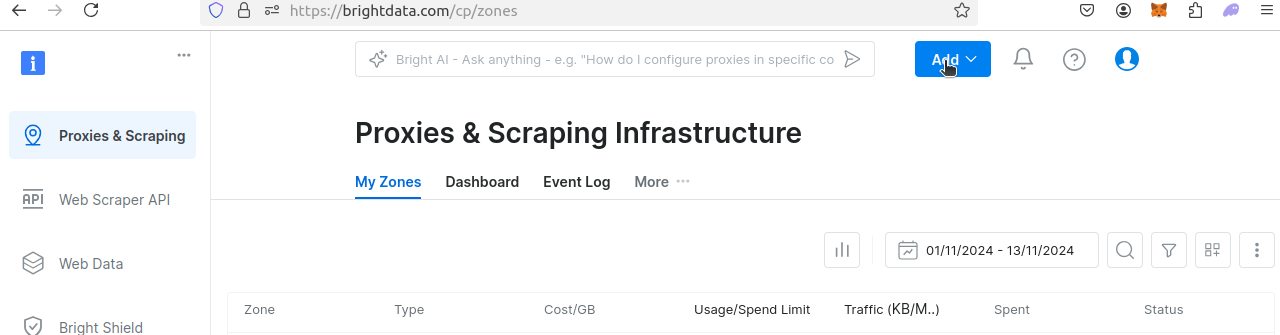
Es sollte ein Dropdown-Menü ähnlich dem unten abgebildeten erscheinen. Klicken Sie auf „Scraping-Browser“.
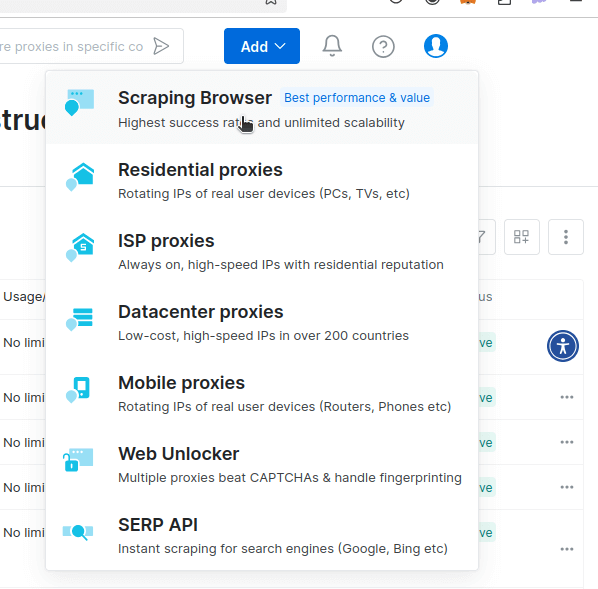
Nun gelangen Sie zu der Seite, auf der Sie den Scraping-Browser einrichten können. Wir verwenden einfach die Standardeinstellungen. Standardmäßig verfügt der Scraping-Browser über einen integrierten CAPTCHA-Löser.
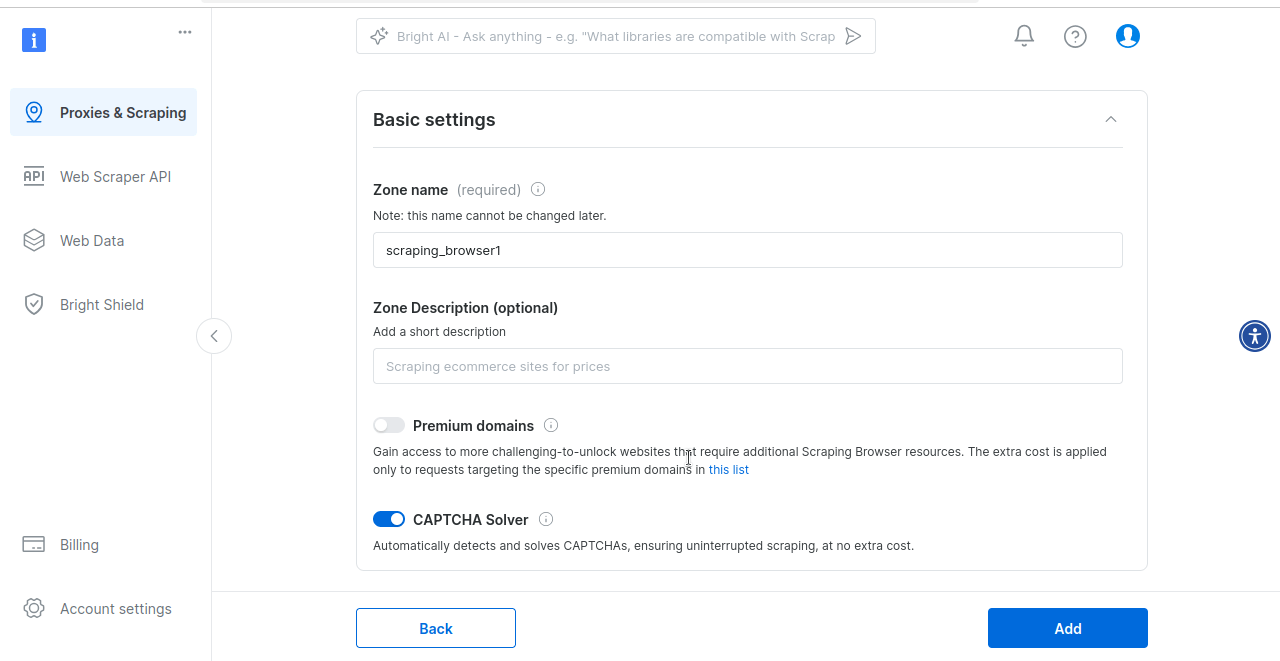
Schließlich werden Sie aufgefordert, Ihre Scraping-Browser -Zone zu erstellen. Wenn Sie bereit sind, den Scraping-Browser auszuprobieren, klicken Sie auf „Ja“.
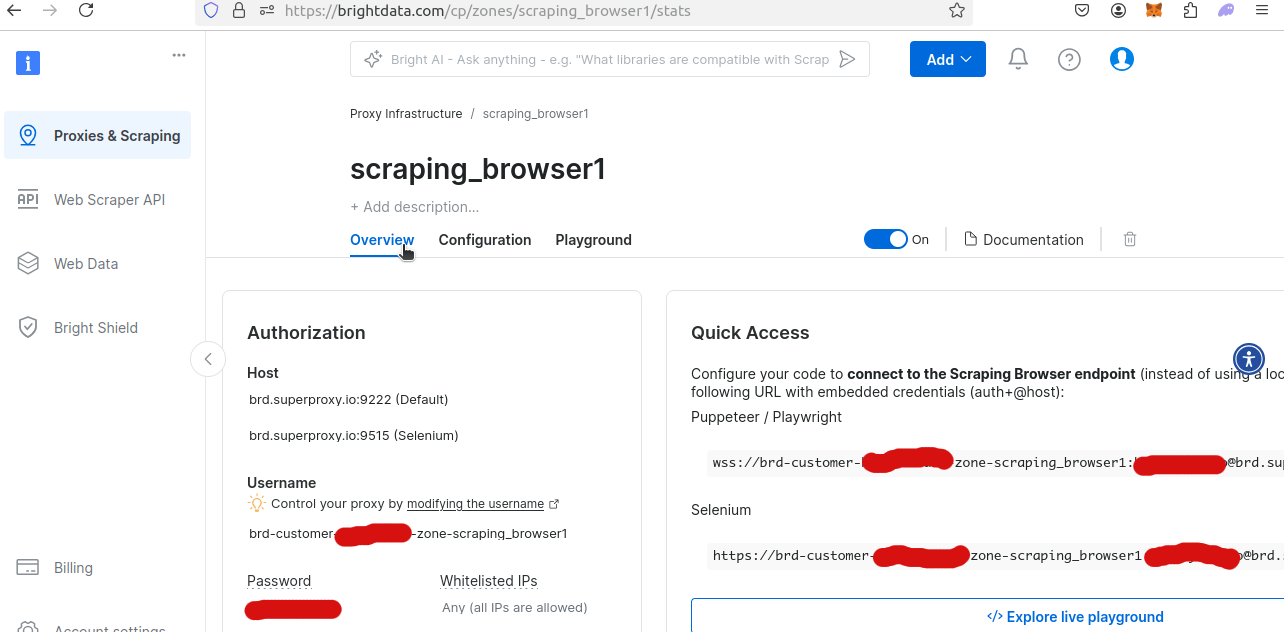
Wenn Sie sich die Übersicht Ihrer neuen Scraping-Browser-Zone ansehen, erhalten Sie Ihren eindeutigen Benutzernamen und Ihr Passwort. Diese benötigen Sie, um von Ihrem Python-Skript aus auf den Scraping-Browser zuzugreifen.
Extrahieren Sie unsere Daten mit Bright Data Scraping-Browser
Unser Code-Beispiel unten wurde so geändert, dass Remote Webdriver mit Scraping-Browser verwendet wird. Ersetzen Sie YOUR_USERNAME, YOUR_ZONE_NAME und YOUR_PASSWORD durch Ihren tatsächlichen Benutzernamen, Ihre Zone und Ihr Passwort!
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-IHR_BENUTZERNAME-zone-IHR_ZONENNAME:IHR_PASSWORT"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"{page} erfolgreich in CSV geschrieben...")
def scrape_page(page_number: int):
print("Verbindung zum Scraping-Browser wird hergestellt...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Verbunden! Seite wird gescrapt...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("Keine Hotelkarten gefunden! Screenshot erstellen und beenden.")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = card.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Karte {index} erfolgreich gescrapt")
print(f"Seite {page_number} gescrapt")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Dieses Beispiel ähnelt unserem Beispiel mit Vanilla Selenium, es gibt jedoch einige kleine Unterschiede, die hier zu beachten sind. Diese betreffen hauptsächlich die Tatsache, dass wir Remote Webdriver anstelle von Standard Webdriver verwenden.
- Wir richten eine Remote-Webdriver-Instanz mit unserer Proxy-Verbindung ein:
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515". - Unsere Fehlerbehandlung wurde leicht geändert:
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png"). Wir verwenden jetztdriver.get_screenshot_as_file()anstelle vondriver.save_screenshot().
Abgesehen von einigen geringfügigen Anpassungen für unsere Remote-Proxy-Verbindung ist unser Code für den Scraping-Browser mit Selenium praktisch identisch mit dem für Vanilla Selenium. Der größte Unterschied: Der Scraping-Browser liefert unsere Ergebnisse auf einfache Weise.
Bei der Ausführung dieses Codes kann die folgende Fehlermeldung angezeigt werden. Dies kann bei einer Remote-Verbindung vorkommen. Versuchen Sie in diesem Fall, das Skript erneut auszuführen. Manchmal sind mehrere Versuche erforderlich, um eine stabile Verbindung herzustellen.
urllib3.exceptions.ProtocolError: ('Verbindung abgebrochen.', RemoteDisconnected('Remote-Ende hat Verbindung ohne Antwort geschlossen'))
Wenn Ihr Skript erfolgreich ausgeführt wurde, sollten Sie die folgende Ausgabe erhalten.
Verbindung zum Scraping-Browser wird hergestellt...
-------------------------------
Verbindung hergestellt! Seite wird gescrapt...
Karte 0 erfolgreich gescrapt
Karte 1 erfolgreich gescrapt
Karte 2 erfolgreich gescrapt
Karte 3 erfolgreich gescrapt
Karte 4 erfolgreich gescrapt
Karte 5 erfolgreich gescrapt
Karte 6 erfolgreich gescrapt
Karte 7 erfolgreich gescrapt
Karte 8 erfolgreich gescrapt
Karte 9 erfolgreich gescrapt
Karte 10 erfolgreich gescrapt
Karte 11 erfolgreich gescrapt
Karte 12 erfolgreich gescrapt
Karte 13 erfolgreich gescrapt
Karte 14 erfolgreich gescrappt
Karte 15 erfolgreich gescrappt
Karte 16 erfolgreich gescrappt
Karte 17 erfolgreich gescrappt
Karte 18 erfolgreich gescrappt
Karte 19 erfolgreich gescrappt
Karte 20 erfolgreich gescrappt
Karte 21 erfolgreich gescrappt
Karte 22 erfolgreich gescrappt
Karte 23 erfolgreich gescrappt
Karte 24 erfolgreich gescrapt
Karte 25 erfolgreich gescrapt
Karte 26 erfolgreich gescrapt
Karte 27 erfolgreich gescrapt
Karte 28 erfolgreich gescrapt
Karte 29 erfolgreich gescrapt
Seite 0 gescrapt
Schreiben in CSV...
Daten in CSV-Datei schreiben...
0 erfolgreich in CSV geschrieben...
Hier ist ein Screenshot unserer CSV-Daten mit ONLYOFFICE.
Bild wird nicht angezeigt Mögliche Ursachen
- Die Bilddatei ist möglicherweise beschädigt
- Der Server, auf dem das Bild gehostet wird, ist nicht verfügbar
- Der Bildpfad ist falsch
- Das Bildformat wird nicht unterstützt
Alternativer Ansatz: Datensätze
Wenn Sie keinen Scraper programmieren möchten oder Daten in größerem Umfang benötigen, sollten Sie die strukturierten Datensätze von Tripadvisor in Betracht ziehen. Unsere Datensätze bieten gut organisierte, hochwertige Daten, die auf Ihre Bedürfnisse zugeschnitten sind. Damit können Sie mühelos Reisetrends analysieren, die Preise Ihrer Mitbewerber beobachten und das Kundenerlebnis optimieren.
Mit einem Tripadvisor-Datensatz haben Sie Zugriff auf wichtige Datenpunkte wie Hotelnamen, Bewertungen, Ausstattungsmerkmale, Preise und mehr – alles in flexiblen Formaten (z. B. JSON, CSV, Parquet) und aktualisiert nach einem Zeitplan, der zu Ihrem Arbeitsablauf passt. Das Beste daran ist, dass diese Datensätze zu 100 % konform und skalierbar sind, wodurch Sie Zeit und Ressourcen sparen und gleichzeitig die Genauigkeit gewährleisten.
Wichtige Vorteile:
- Greifen Sie auf alle wichtigen Tripadvisor-Datenpunkte zu, ohne sich mit Sperren herumschlagen zu müssen.
- Passen Sie Datensätze mit Filtern und benutzerdefinierten Formatierungen an Ihre spezifischen Bedürfnisse an.
- Automatisieren Sie die Datenlieferung an Plattformen wie Snowflake, S3 oder Azure.
Konzentrieren Sie sich auf die Analyse der Daten, nicht auf deren Erfassung – überlassen Sie uns den schwierigen Teil. Entdecken Sie noch heute unsere Tripadvisor-Datensätze!
Fazit
Von JavaScript-Herausforderungen bis hin zu vollständig dynamischen Inhalten kann Tripadvisor ein wirklich schwieriges Ziel für das Scraping sein. Nachdem Sie nun unseren Leitfaden gelesen haben, sollte es etwas einfacher sein. Zu diesem Zeitpunkt sollten Sie verstanden haben, dass Sie Selenium verwenden können, um einen Browser sowohl lokal als auch über eine Remote-Sitzung zu steuern. Mit Headless-Browsern (wie Selenium) haben Sie auch die Möglichkeit, einen Screenshot Ihrer Daten zu machen. Dies erleichtert die Fehlerbehebung unseres Scrapers erheblich. Sie wissen nun, wie Sie Hoteldaten extrahieren und wie Sie eine CSV-Datei mit einfachem Python schreiben können, ohne etwas anderes installieren zu müssen!
Wenn Sie in großem Umfang scrapen möchten, bietet Bright Data eine Vielzahl von Produkten, die Ihnen dabei helfen. Der Scraping-Browser bietet Ihnen die besten Tools für alle Aufgaben im Zusammenhang mit Scraping. Sie können einen echten Browser mit einer stabilen Proxy-Verbindung mit einem Headless-Browser Ihrer Wahl steuern. Sie müssen sich auch nie um CAPTCHAs kümmern!
Oder Sie wählen den besten Weg, um an Daten zu kommen – kaufen Sie einen gebrauchsfertigen Tripadvisor-Datensatz. Melden Sie sich jetzt an, um gratis zu testen!






