

In diesem Blogbeitrag erfahren Sie mehr:
- Was ein OpenSea Scraper ist
- Die Arten von Daten, die Sie automatisch aus OpenSea extrahieren können
- Wie man ein OpenSea-Skript mit Python erstellt
- Wann und warum eine fortschrittlichere Lösung erforderlich sein kann
Lasst uns eintauchen!
Was ist ein OpenSea Scraper?
Ein OpenSea Scraper ist ein Tool, das für Daten von OpenSea, dem weltweit größten NFT-Marktplatz, entwickelt wurde. Das Hauptziel dieses Tools ist es, die Sammlung verschiedener NFT-bezogener Informationen zu automatisieren. In der Regel werden automatisierte Browserlösungen verwendet, um OpenSea-Daten in Echtzeit abzurufen, ohne dass manuelle Eingriffe erforderlich sind.
Daten aus OpenSea auslesen
Hier sind einige der wichtigsten Datenpunkte, die Sie von OpenSea abrufen können:
- NFT-Sammlungsname: Der Titel oder Name der NFT-Sammlung.
- Rang der Sammlung: Der Rang oder die Position der Sammlung auf der Grundlage ihrer Leistung.
- NFT-Bild: Das Bild, das mit der NFT-Sammlung oder dem Element verbunden ist.
- Mindestpreis: Der Mindestpreis, der für einen Artikel in der Sammlung angegeben wird.
- Volumen: Das gesamte Handelsvolumen der NFT-Sammlung.
- Prozentuale Veränderung: Die Preisänderung oder die prozentuale Veränderung der Wertentwicklung der Sammlung in einem bestimmten Zeitraum.
- Token-ID: Der eindeutige Bezeichner für jede NFT in der Sammlung.
- Letzter Verkaufspreis: Der letzte Verkaufspreis eines NFT in der Sammlung.
- Verkaufsverlauf: Die Transaktionshistorie für jeden NFT-Artikel, einschließlich früherer Preise und Käufer.
- Angebote: Aktive Angebote, die für eine NFT in der Sammlung abgegeben wurden.
- Ersteller-Informationen: Details über den Ersteller der NFT, wie z. B. sein Benutzername oder Profil.
- Merkmale/Attribute: Besondere Merkmale oder Eigenschaften der NFT-Gegenstände (z. B. Seltenheit, Farbe usw.).
- Beschreibung des Gegenstands: Eine kurze Beschreibung oder Information über den NFT-Artikel.
Wie man OpenSea scrappt: Schritt-für-Schritt-Anleitung
In diesem geführten Abschnitt lernen Sie, wie man einen OpenSea Scraper erstellt. Ziel ist es, ein Python-Skript zu entwickeln, das automatisch Daten zu NFT-Sammlungen aus dem Abschnitt “Top” der Seite “Spiele” sammelt:
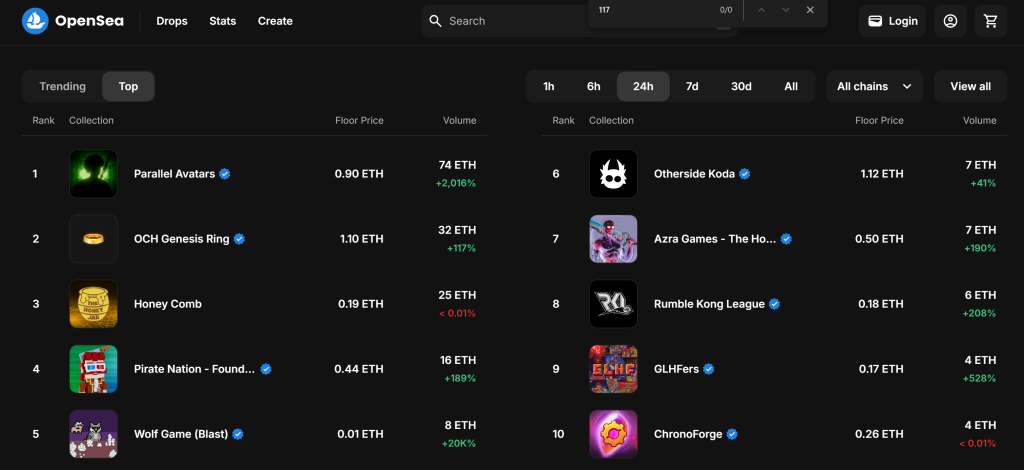
Folgen Sie den nachstehenden Schritten und sehen Sie, wie Sie OpenSea scrapen können!
Schritt 1: Projekt einrichten
Bevor Sie beginnen, vergewissern Sie sich, dass Sie Python 3 auf Ihrem Rechner installiert haben. Andernfalls laden Sie es herunter und folgen Sie den Installationsanweisungen.
Verwenden Sie den folgenden Befehl, um einen Ordner für Ihr Projekt zu erstellen:
mkdir opensea-scraper
Das Verzeichnis opensea-scraper stellt den Projektordner Ihres Python OpenSea Scrapers dar.
Navigieren Sie im Terminal dorthin, und initialisieren Sie eine virtuelle Umgebung darin:
cd opensea-scraper
python -m venv venv
Laden Sie den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition sind geeignet.
Erstellen Sie eine scraper.py-Datei im Projektordner, die nun diese Dateistruktur enthalten sollte:

Im Moment ist scraper.py ein leeres Python-Skript, aber es wird bald die gewünschte Scraping-Logik enthalten.
Aktivieren Sie im Terminal der IDE die virtuelle Umgebung. Unter Linux oder macOS starten Sie diesen Befehl:
./env/bin/activate
Unter Windows führen Sie entsprechend aus:
env/Scripts/activate
Erstaunlich, Sie haben jetzt eine Python-Umgebung für Web Scraping!
Schritt #2: Wählen Sie die Scraping-Bibliothek
Bevor Sie sich in die Programmierung stürzen, müssen Sie die besten Scraping-Tools zum Extrahieren der benötigten Daten ermitteln. Dazu sollten Sie zunächst einen Vorabtest durchführen, um zu analysieren, wie sich die Zielsite wie folgt verhält:
- Öffnen Sie die Zielseite im Inkognito-Modus, um zu verhindern, dass zuvor gespeicherte Cookies und Einstellungen Ihre Analyse beeinträchtigen.
- Klicken Sie mit der rechten Maustaste auf eine beliebige Stelle der Seite und wählen Sie “Prüfen”, um die Entwicklerwerkzeuge des Browsers zu öffnen.
- Navigieren Sie zur Registerkarte “Netzwerk”.
- Laden Sie die Seite neu und interagieren Sie mit ihr, indem Sie beispielsweise auf die Schaltflächen “1h” und “6h” klicken.
- Überwachen Sie die Aktivität auf der Registerkarte “Fetch/XHR”.
Dies gibt Ihnen Aufschluss darüber, ob die Webseite Daten dynamisch lädt und rendert:
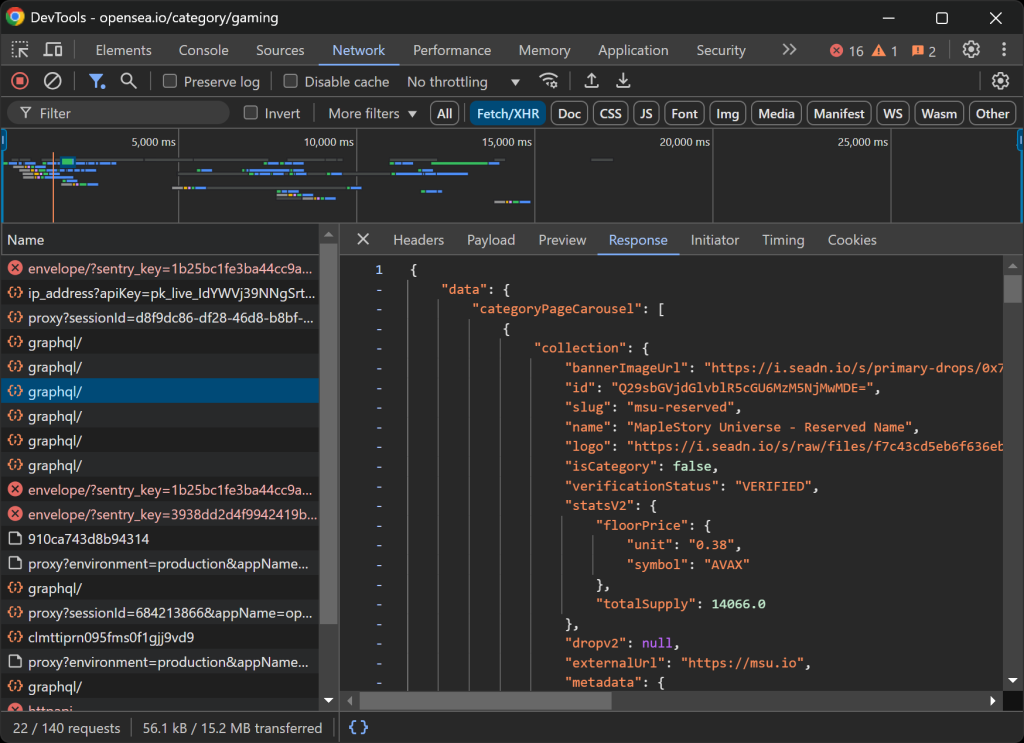
In diesem Abschnitt können Sie alle AJAX-Anfragen sehen, die die Seite in Echtzeit stellt. Wenn Sie diese Anfragen untersuchen, werden Sie feststellen, dass OpenSea dynamisch Daten vom Server abruft. Außerdem zeigt eine weitere Analyse, dass einige Schaltflächeninteraktionen das JavaScript-Rendering auslösen, um den Seiteninhalt dynamisch zu aktualisieren.
Dies zeigt, dass für das Scraping von OpenSea ein Browser-Automatisierungstool wie Selenium erforderlich ist!
Mit Selenium können Sie einen Webbrowser programmatisch steuern und echte Benutzerinteraktionen imitieren, um Daten effektiv zu extrahieren. Installieren wir es und fangen wir an.
Schritt #3: Selenium installieren und einrichten
Sie können Selenium über das Pip-Paket selenium beziehen. Aktivieren Sie Ihre virtuelle Umgebung und führen Sie den folgenden Befehl aus, um Selenium zu installieren:
pip install -U selenium
Eine Anleitung zur Verwendung des Browser-Automatisierungstools finden Sie in unserem Leitfaden zum Web Scraping mit Selenium.
Importieren Sie Selenium in scraper.py und initialisieren Sie ein WebDriver-Objekt zur Steuerung von Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
Das obige Snippet richtet eine WebDriver-Instanz für die Interaktion mit Chrome ein. Denken Sie daran, dass OpenSea Anti-Scraping-Maßnahmen einsetzt, die Headless-Browser erkennen und sie blockieren. Insbesondere gibt der Server eine “Access Denied”-Seite zurück.
Das bedeutet, dass Sie das --headless-Flag für diesen Scraper nicht verwenden können. Als Alternative können Sie Playwright Stealth oder SeleniumBase verwenden.
Da OpenSea sein Layout an die Fenstergröße anpasst, maximieren Sie das Browserfenster, um sicherzustellen, dass die Desktop-Version gerendert wird:
driver.maximize_window()
Abschließend sollten Sie immer sicherstellen, dass Sie den WebDriver ordnungsgemäß schließen, um Ressourcen freizugeben:
driver.quit()
Wunderbar! Sie sind nun vollständig konfiguriert, um mit dem Scannen von OpenSea zu beginnen.
Schritt #4: Besuchen Sie die Zielseite
Verwenden Sie die get() -Methode von Selenium WebDriver, um dem Browser mitzuteilen, dass er die gewünschte Seite aufrufen soll:
driver.get("https://opensea.io/category/gaming")
Ihre scraper.py-Datei sollte nun diese Zeilen enthalten:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()
Setzen Sie einen Debugging-Haltepunkt in der letzten Zeile des Skripts und führen Sie es aus. Das sollten Sie nun sehen:
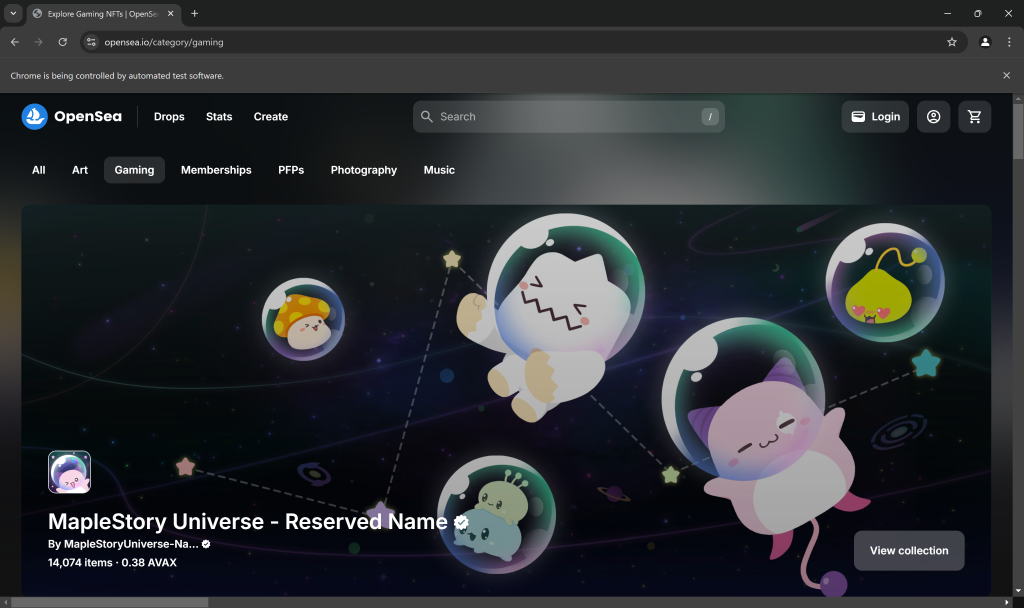
Die Meldung “Chrome wird von automatisierter Testsoftware gesteuert” bestätigt, dass Selenium Chrome wie erwartet steuert. Gut gemacht!
Schritt #5: Interaktion mit der Webseite
Standardmäßig werden auf der Seite “Spiele” die “aktuellen” NFT-Sammlungen angezeigt:
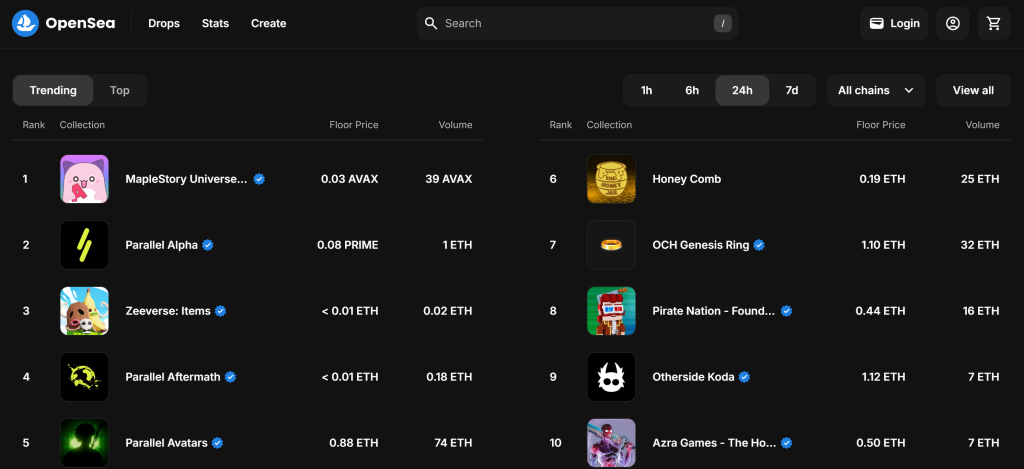
Denken Sie daran, dass Sie an der “Top”-NFT-Sammlung interessiert sind. Mit anderen Worten, Sie möchten Ihren OpenSea Scraper anweisen, auf die Schaltfläche “Top” zu klicken, wie unten dargestellt:
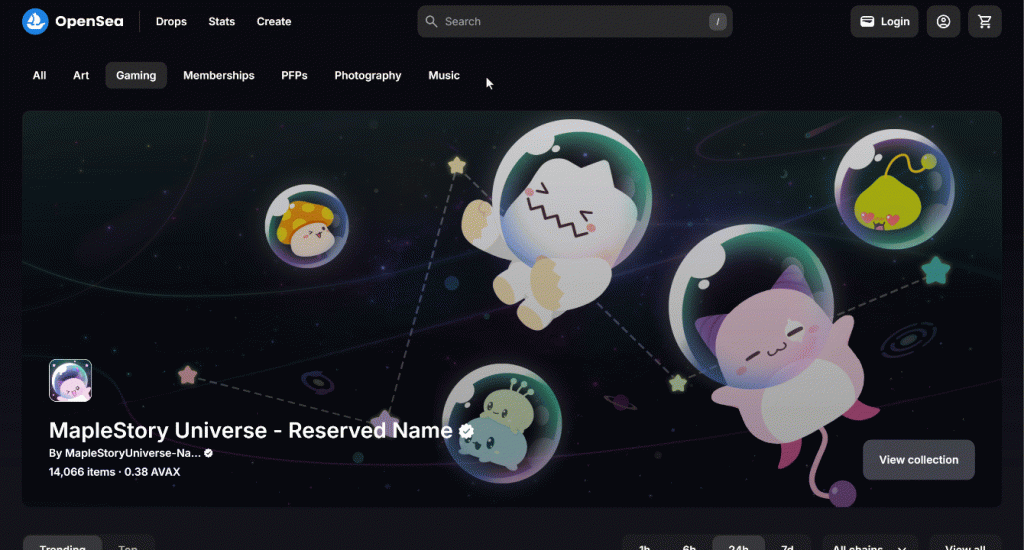
Untersuchen Sie zunächst die Schaltfläche “Oben”, indem Sie mit der rechten Maustaste darauf klicken und die Option “Untersuchen” wählen:
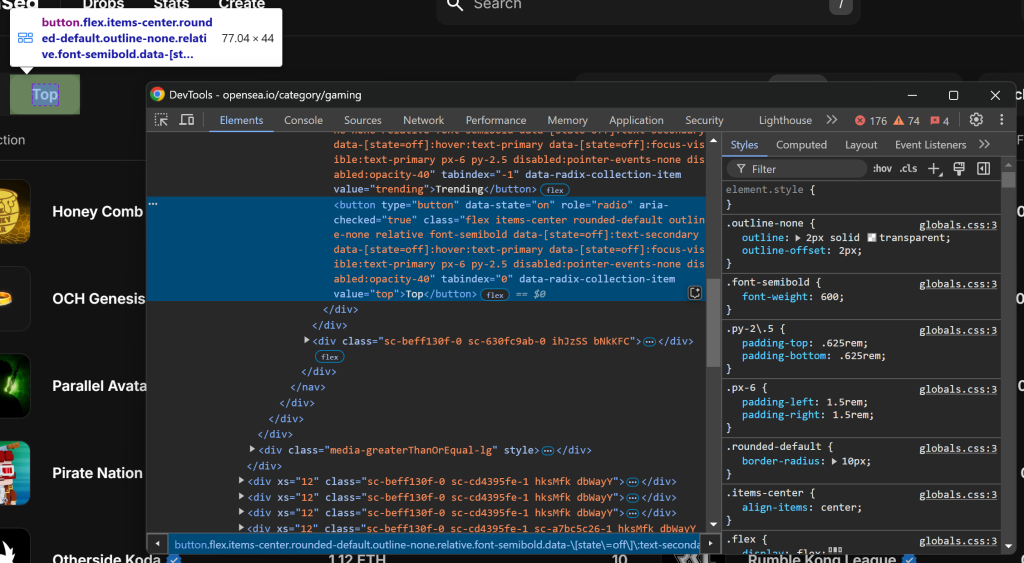
Beachten Sie, dass Sie es mit dem CSS-Selektor [value="top"] auswählen können. Verwenden Sie find_element() von Selenium, um diesen CSS-Selektor auf die Seite anzuwenden. Sobald Sie das Element ausgewählt haben, klicken Sie es mit click() an:
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
Damit der obige Code funktioniert, vergessen Sie nicht, den By-Import hinzuzufügen:
from selenium.webdriver.common.by import By
Großartig! Mit diesen Codezeilen wird die gewünschte Interaktion simuliert.
Schritt #6: Vorbereiten der NFT-Sammlungen
Die Zielseite zeigt die 10 wichtigsten NFT-Sammlungen für die ausgewählte Kategorie an. Da es sich um eine Liste handelt, initialisieren Sie ein leeres Array, um die ausgewerteten Informationen zu speichern:
nft_collections = []
Als Nächstes untersuchen Sie ein HTML-Element für einen NFT-Sammlungseintrag:
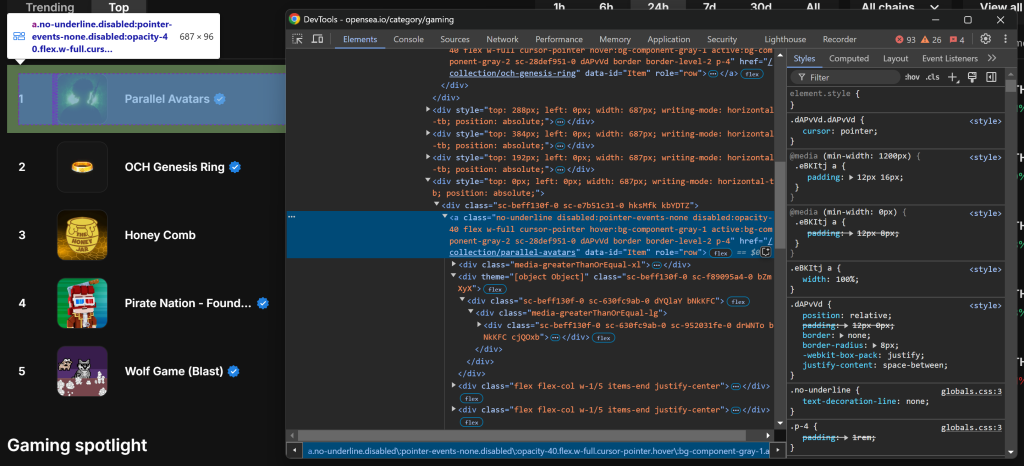
Beachten Sie, dass Sie alle Einträge der NFT-Sammlung mit dem CSS-Selektor a[data-id="Item"] auswählen können. Da einige Klassennamen in den Elementen zufällig generiert zu sein scheinen, sollten Sie sie nicht direkt ansprechen. Konzentrieren Sie sich stattdessen auf data-*-Attribute, da diese in der Regel für Tests verwendet werden und im Laufe der Zeit konsistent bleiben.
Abrufen aller NFT-Sammlungseintragselemente mit find_elements():
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
Als Nächstes durchlaufen Sie die Elemente und bereiten die Extraktion der Daten aus jedem einzelnen Element vor:
for item_element in item_elements:
# Scraping logic...
Großartig! Sie können nun mit dem Scraping von Daten aus OpenSea NFT-Elementen beginnen.
Schritt #7: Scrapen Sie die NFT-Sammelelemente
Prüfen Sie einen NFT-Sammlungseintrag:
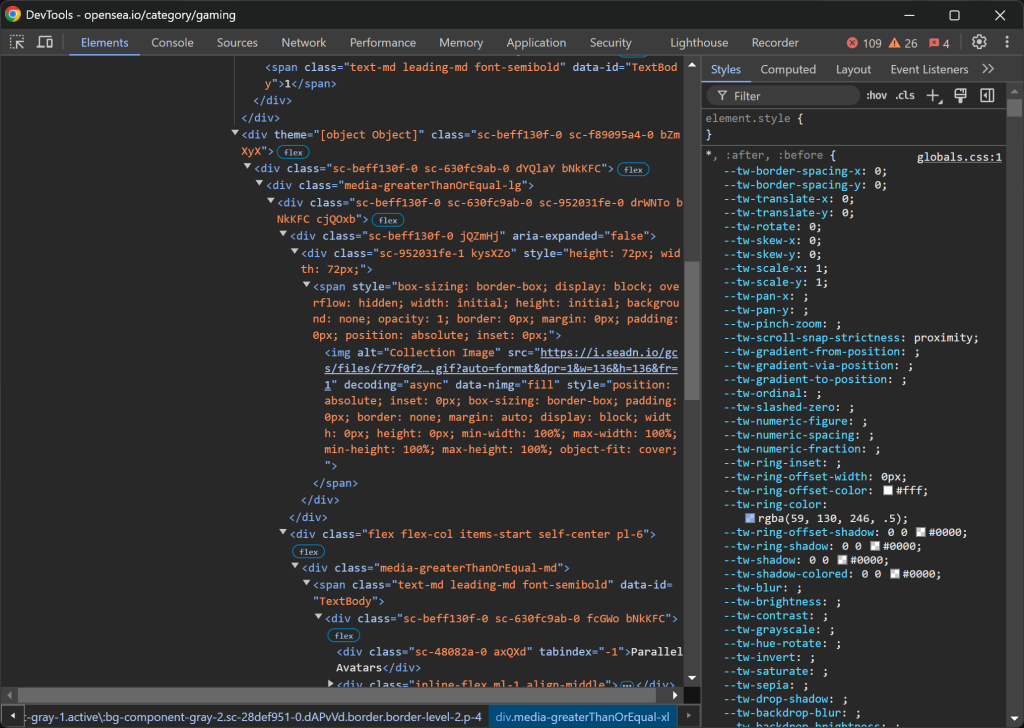
Die HTML-Struktur ist ziemlich kompliziert, aber Sie können die folgenden Details entnehmen:
- Das Sammlungsbild von
img[alt="Sammlungsbild"] - Der Sammlungsrang von
[data-id="TextBody"] - Der Name der Sammlung von
[tabindex="-1"]
Leider gibt es für diese Elemente keine eindeutigen oder stabilen Attribute, so dass Sie sich auf potenziell unsichere Selektoren verlassen müssen. Beginnen Sie mit der Implementierung der Scraping-Logik für diese ersten drei Attribute:
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
Die Eigenschaft .text ruft den Textinhalt des ausgewählten Elements ab. Da der Rang später zum Sortieren der gescrapten Daten verwendet wird, wird er in eine ganze Zahl umgewandelt. In der Zwischenzeit ruft .get_attribute("src") den Wert des src-Attributs ab und extrahiert die Bild-URL.
Konzentrieren Sie sich dann auf die Spalten .w-1/5:
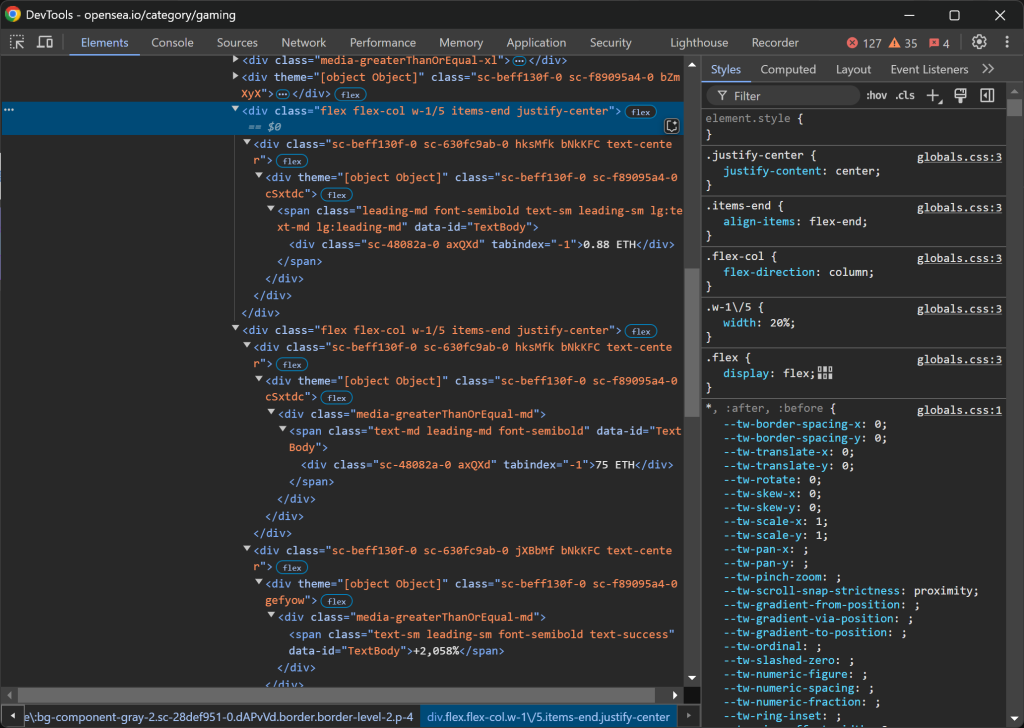
Die Daten sind wie folgt strukturiert:
- Die erste Spalte
.w-1/5enthält den Mindestpreis. - Die zweite Spalte
.w-1/5enthält das Volumen und die prozentuale Veränderung, jeweils in separaten Elementen.
Extrahieren Sie diese Werte nach der folgenden Logik:
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
Beachten Sie, dass Sie .w-1/5 nicht direkt verwenden können, sondern dass Sie / mit abschließen müssen.
Jetzt geht’s los! Die OpenSea-Scraping-Logik zum Abrufen von NFT-Sammlungen ist abgeschlossen.
Schritt Nr. 8: Sammeln der gescrapten Daten
Sie haben die ausgewerteten Daten auf mehrere Variablen verteilt. Füllen Sie ein neues nft_collection-Objekt mit diesen Daten:
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
Vergessen Sie dann nicht, sie dem Array nft_collections hinzuzufügen:
nft_collections.append(nft_collection)
Außerhalb der for-Schleife sortieren Sie die ausgewerteten Daten in aufsteigender Reihenfolge:
nft_collections.sort(key=lambda x: x["rank"])
Fantastisch! Es bleibt nur noch, diese Informationen in eine für Menschen lesbare Datei wie CSV zu exportieren.
Schritt #9: Exportieren Sie die gescrapten Daten in CSV
Python verfügt über integrierte Unterstützung für den Export von Daten in Formate wie CSV. Erreichen Sie dies mit diesen Codezeilen:
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
Dieses Snippet exportiert die gesammelten Daten aus der Liste nft_collections in eine CSV-Datei namens nft_collections.csv. Es verwendet das csv-Modul von Python, um ein Writer-Objekt zu erstellen, das die Daten in ein strukturiertes Format schreibt. Jeder Eintrag wird als Zeile mit Spaltenüberschriften gespeichert, die den Wörterbuchschlüsseln in der nft_collections-Liste entsprechen.
Importieren Sie csv aus der Python-Standardbibliothek mit:
imprort csv
Schritt Nr. 10: Alles zusammenfügen
Dies ist der endgültige Code für Ihren OpenSea Scraper:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()
Et voilà! In weniger als 100 Zeilen Code können Sie ein einfaches Python-Skript zum Scannen von OpenSea erstellen.
Starten Sie es mit dem folgenden Befehl im Terminal:
python scraper.py
Nach einiger Zeit erscheint die Datei nft_collections.csv im Projektordner:
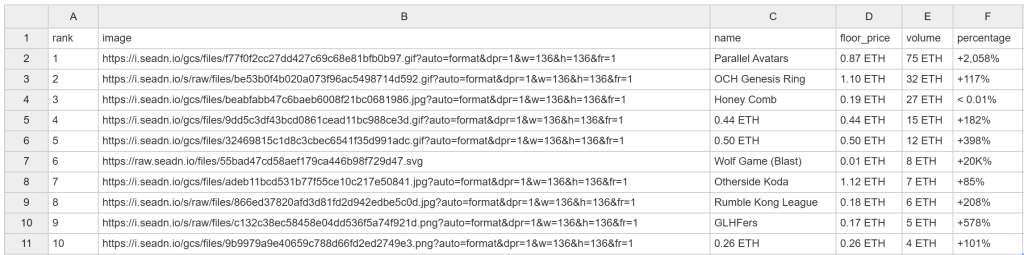
Herzlichen Glückwunsch! Sie haben soeben OpenSea wie geplant gekratzt.
OpenSea-Daten mühelos freischalten
OpenSea bietet viel mehr als nur eine Rangliste der NFT-Sammlungen. Es bietet auch detaillierte Seiten für jede NFT-Sammlung und die einzelnen Artikel darin. Da die NFT-Preise häufig schwanken, muss Ihr Scraping-Skript automatisch und häufig laufen, um frische Daten zu erfassen. Die meisten OpenSea-Seiten sind jedoch durch strenge Anti-Scraping-Maßnahmen geschützt, was das Abrufen von Daten erschwert.
Wie wir bereits festgestellt haben, ist die Verwendung von Headless Browsern keine Option, was bedeutet, dass Sie Ressourcen verschwenden, um die Browserinstanz geöffnet zu halten. Wenn Sie versuchen, mit anderen Elementen auf der Seite zu interagieren, könnten Sie außerdem auf Probleme stoßen:
Beispielsweise kann das Laden der Daten stecken bleiben, und die AJAX-Anfragen im Browser können blockiert werden, was zu einem 403 Forbidden-Fehler führt:
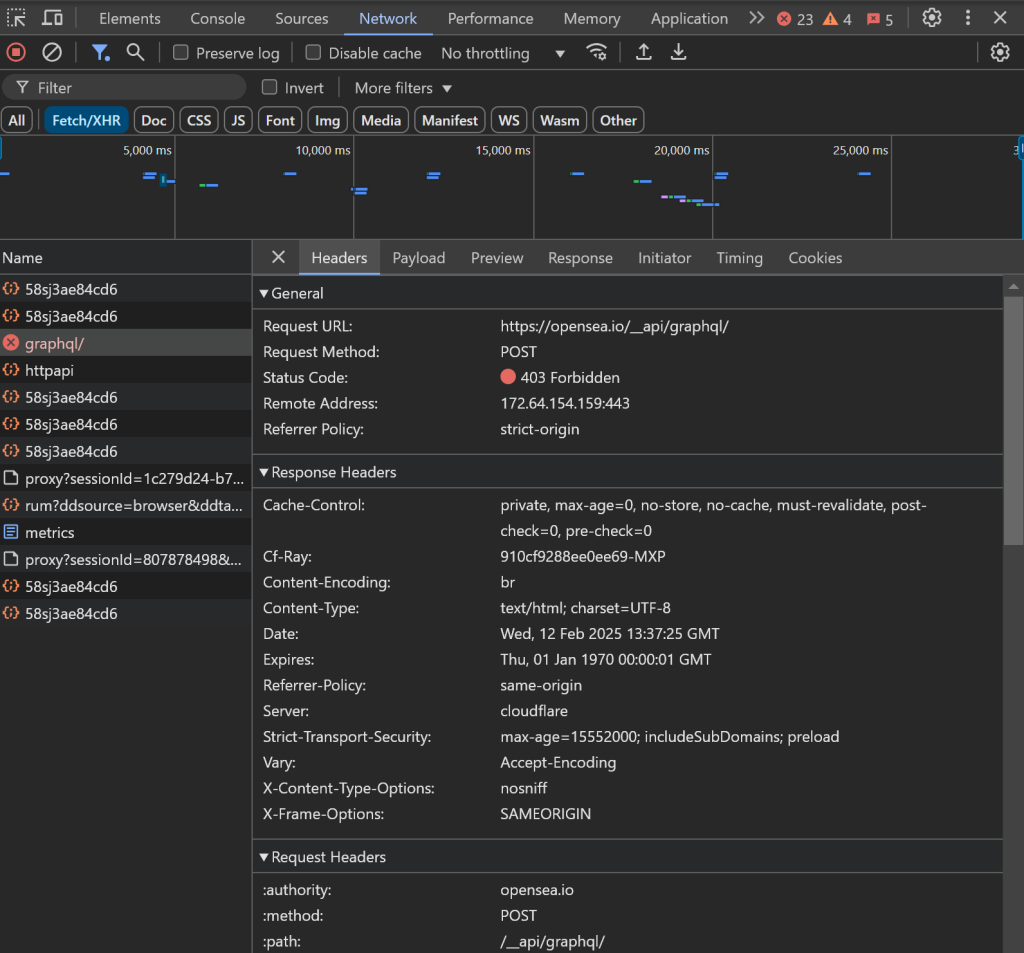
Dies geschieht aufgrund der fortschrittlichen Anti-Bot-Maßnahmen, die von OpenSea implementiert wurden, um Scraping-Bots zu blockieren.
Diese Probleme machen das Scrapen von OpenSea ohne die richtigen Werkzeuge zu einer frustrierenden Erfahrung. Die Lösung? Verwenden Sie den speziellen OpenSea Scraper von Bright Data, mit dem Sie Daten von der Website über einfache API-Aufrufe oder ohne Code abrufen können, ohne Gefahr zu laufen, gesperrt zu werden!
Schlussfolgerung
In diesem Schritt-für-Schritt-Tutorial haben Sie gelernt, was ein OpenSea Scraper ist und welche Arten von Daten er sammeln kann. Außerdem haben Sie ein Python-Skript zum Scrapen von OpenSea NFT-Daten erstellt, und das alles mit weniger als 100 Zeilen Code.
Die Herausforderung liegt in den strengen Anti-Bot-Maßnahmen von OpenSea, die automatisierte Browser-Interaktionen blockieren. Umgehen Sie diese Probleme mit unserem OpenSea Scraper, einem Tool, das Sie ganz einfach entweder mit API oder ohne Code integrieren können, um öffentliche NFT-Daten abzurufen, einschließlich Name, Beschreibung, Token-ID, aktueller Preis, letzter Verkaufspreis, Verlauf, Angebote und vieles mehr.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und nutzen Sie unsere Scraper-APIs!




